 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FastPET: Near Real-Time PET Reconstruction from Histo-Images Using a Neural Network
Feb 11, 2020
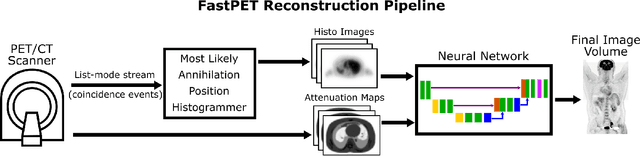
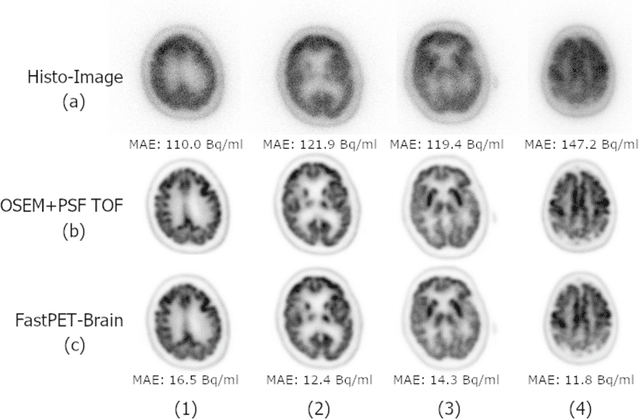

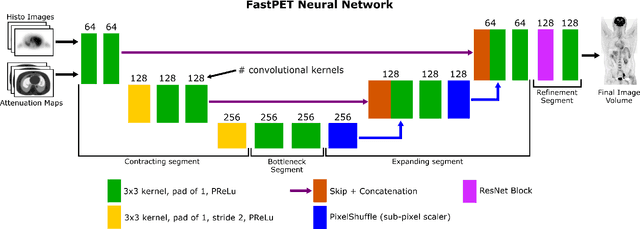
Direct reconstruction of positron emission tomography (PET) data using deep neural networks is a growing field of research. Initial results are promising, but often the networks are complex, memory utilization inefficient, produce relatively small image sizes (e.g. 128x128), and low count rate reconstructions are of varying quality. This paper proposes FastPET, a novel direct reconstruction convolutional neural network that is architecturally simple, memory space efficient, produces larger images (e.g. 440x440) and is capable of processing a wide range of count densities. FastPET operates on noisy and blurred histo-images reconstructing clinical-quality multi-slice image volumes 800x faster than ordered subsets expectation maximization (OSEM). Patient data studies show a higher contrast recovery value than for OSEM with equivalent variance and a higher overall signal-to-noise ratio with both cases due to FastPET's lower noise images. This work also explored the application to low dose PET imaging and found FastPET able to produce images comparable to normal dose with only 50% and 25% counts. We additionally explored the effect of reducing the anatomical region by training specific FastPET variants on brain and chest images and found narrowing the data distribution led to increased performance.
CameraNet: A Two-Stage Framework for Effective Camera ISP Learning
Aug 08, 2019



Traditional image signal processing (ISP) pipeline consists of a set of individual image processing components onboard a camera to reconstruct a high-quality sRGB image from the sensor raw data. Due to the hand-crafted nature of the ISP components, traditional ISP pipeline has limited reconstruction quality under challenging scenes. Recently, the convolutional neural networks (CNNs) have demonstrated their competitiveness in solving many individual image processing problems, such as image denoising, demosaicking, white balance and contrast enhancement. However, it remains a question whether a CNN model can address the multiple tasks inside an ISP pipeline simultaneously. We make a good attempt along this line and propose a novel framework, which we call CameraNet, for effective and general ISP pipeline learning. The CameraNet is composed of two CNN modules to account for two sets of relatively uncorrelated subtasks in an ISP pipeline: restoration and enhancement. To train the two-stage CameraNet model, we specify two groundtruths that can be easily created in the common workflow of photography. CameraNet is trained to progressively address the restoration and the enhancement subtasks with its two modules. Experiments show that the proposed CameraNet achieves consistently compelling reconstruction quality on three benchmark datasets and outperforms traditional ISP pipelines.
Annealing Genetic GAN for Minority Oversampling
Aug 05, 2020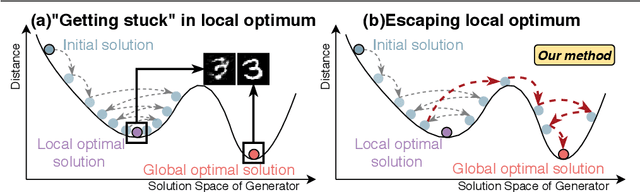

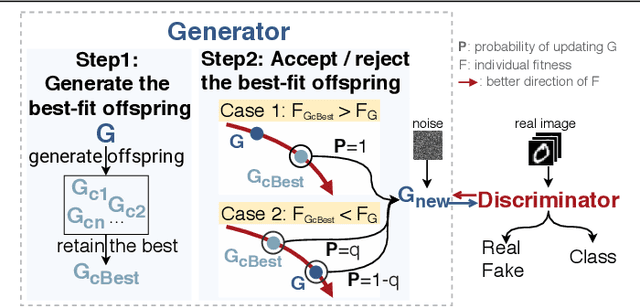
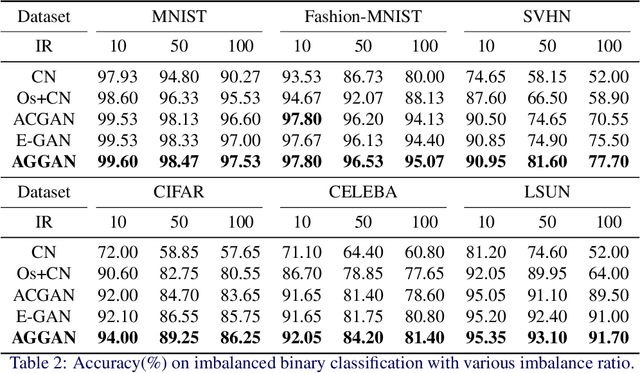
The key to overcome class imbalance problems is to capture the distribution of minority class accurately. Generative Adversarial Networks (GANs) have shown some potentials to tackle class imbalance problems due to their capability of reproducing data distributions given ample training data samples. However, the scarce samples of one or more classes still pose a great challenge for GANs to learn accurate distributions for the minority classes. In this work, we propose an Annealing Genetic GAN (AGGAN) method, which aims to reproduce the distributions closest to the ones of the minority classes using only limited data samples. Our AGGAN renovates the training of GANs as an evolutionary process that incorporates the mechanism of simulated annealing. In particular, the generator uses different training strategies to generate multiple offspring and retain the best. Then, we use the Metropolis criterion in the simulated annealing to decide whether we should update the best offspring for the generator. As the Metropolis criterion allows a certain chance to accept the worse solutions, it enables our AGGAN steering away from the local optimum. According to both theoretical analysis and experimental studies on multiple imbalanced image datasets, we prove that the proposed training strategy can enable our AGGAN to reproduce the distributions of minority classes from scarce samples and provide an effective and robust solution for the class imbalance problem.
Learning Disentangled Representations via Independent Subspaces
Aug 26, 2019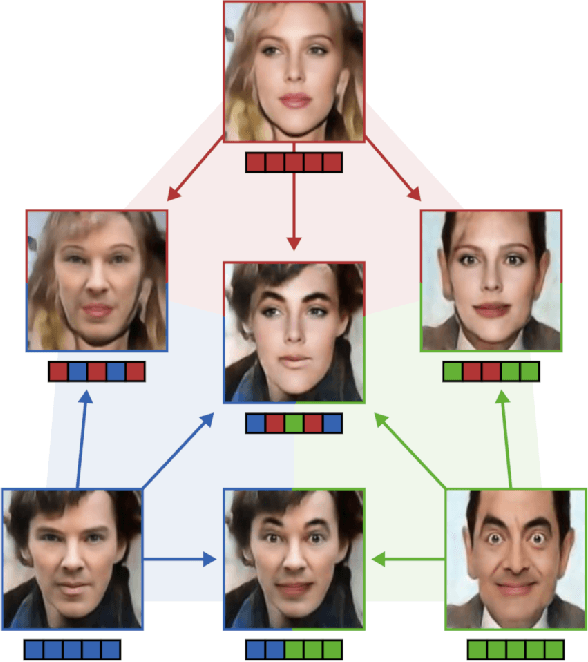
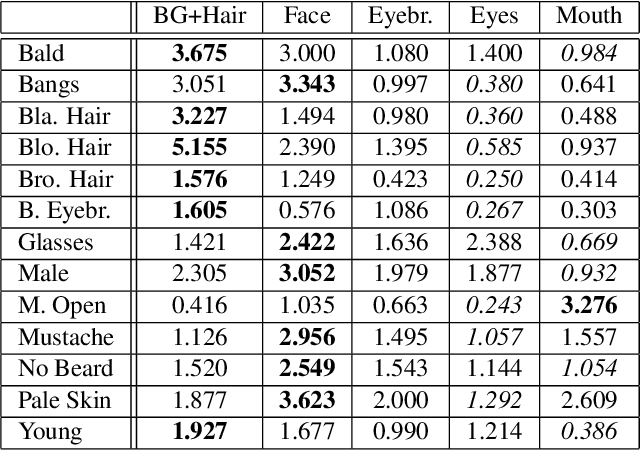
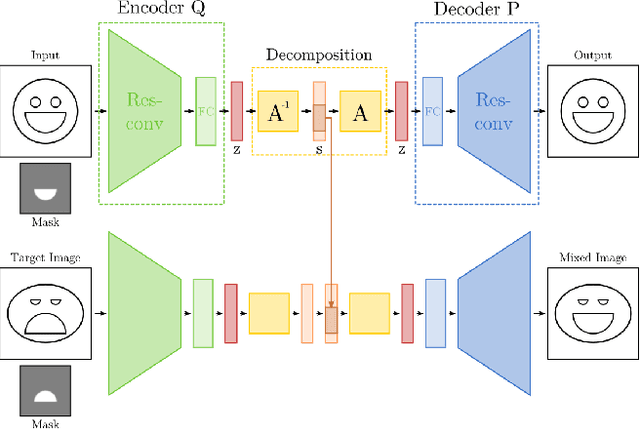
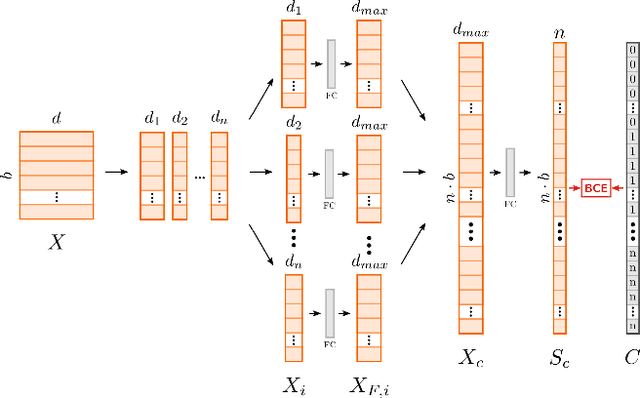
Image generating neural networks are mostly viewed as black boxes, where any change in the input can have a number of globally effective changes on the output. In this work, we propose a method for learning disentangled representations to allow for localized image manipulations. We use face images as our example of choice. Depending on the image region, identity and other facial attributes can be modified. The proposed network can transfer parts of a face such as shape and color of eyes, hair, mouth, etc.~directly between persons while all other parts of the face remain unchanged. The network allows to generate modified images which appear like realistic images. Our model learns disentangled representations by weak supervision. We propose a localized resnet autoencoder optimized using several loss functions including a loss based on the semantic segmentation, which we interpret as masks, and a loss which enforces disentanglement by decomposition of the latent space into statistically independent subspaces. We evaluate the proposed solution w.r.t. disentanglement and generated image quality. Convincing results are demonstrated using the CelebA dataset.
Improved Slice-wise Tumour Detection in Brain MRIs by Computing Dissimilarities between Latent Representations
Jul 24, 2020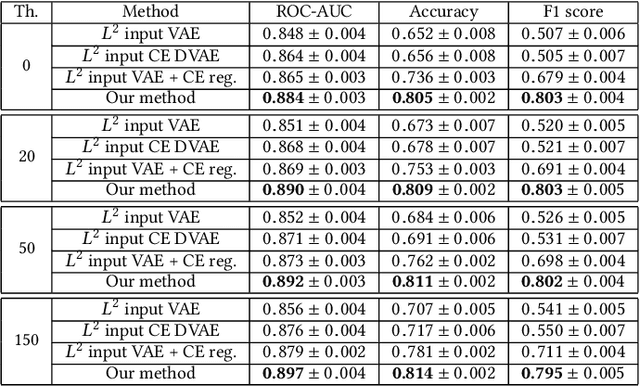
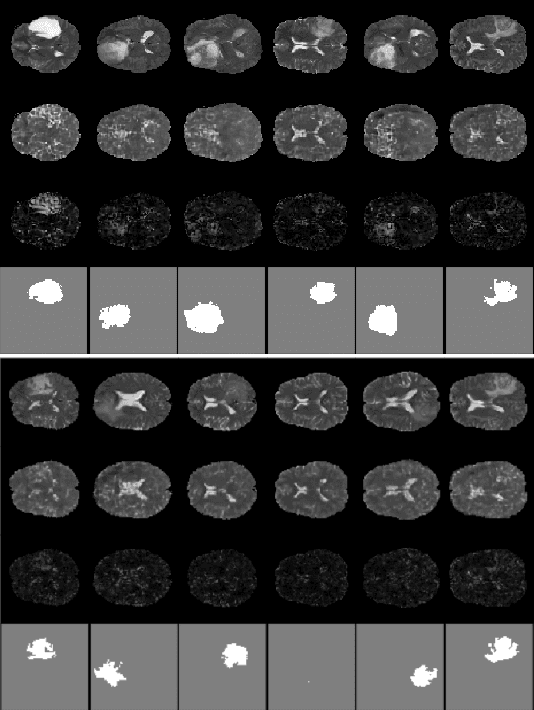

Anomaly detection for Magnetic Resonance Images (MRIs) can be solved with unsupervised methods by learning the distribution of healthy images and identifying anomalies as outliers. In presence of an additional dataset of unlabelled data containing also anomalies, the task can be framed as a semi-supervised task with negative and unlabelled sample points. Recently, in Albu et al., 2020, we have proposed a slice-wise semi-supervised method for tumour detection based on the computation of a dissimilarity function in the latent space of a Variational AutoEncoder, trained on unlabelled data. The dissimilarity is computed between the encoding of the image and the encoding of its reconstruction obtained through a different autoencoder trained only on healthy images. In this paper we present novel and improved results for our method, obtained by training the Variational AutoEncoders on a subset of the HCP and BRATS-2018 datasets and testing on the remaining individuals. We show that by training the models on higher resolution images and by improving the quality of the reconstructions, we obtain results which are comparable with different baselines, which employ a single VAE trained on healthy individuals. As expected, the performance of our method increases with the size of the threshold used to determine the presence of an anomaly.
GANSpace: Discovering Interpretable GAN Controls
Apr 06, 2020
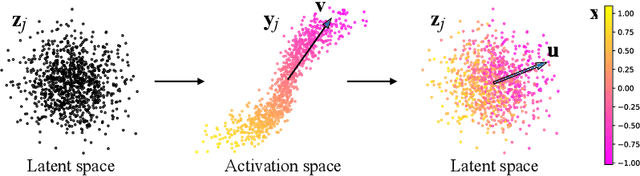


This paper describes a simple technique to analyze Generative Adversarial Networks (GANs) and create interpretable controls for image synthesis, such as change of viewpoint, aging, lighting, and time of day. We identify important latent directions based on Principal Components Analysis (PCA) applied in activation space. Then, we show that interpretable edits can be defined based on layer-wise application of these edit directions. Moreover, we show that BigGAN can be controlled with layer-wise inputs in a StyleGAN-like manner. A user may identify a large number of interpretable controls with these mechanisms. We demonstrate results on GANs from various datasets.
Empirical evaluation of full-reference image quality metrics on MDID database
Oct 04, 2019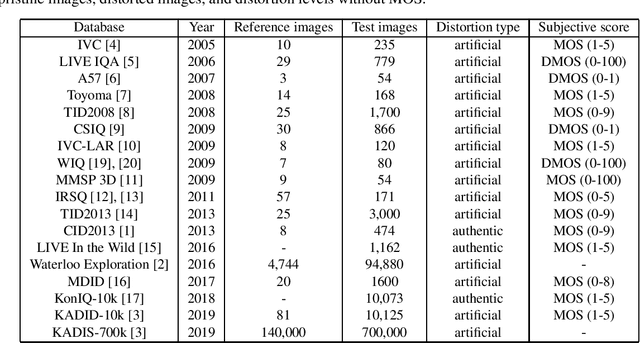
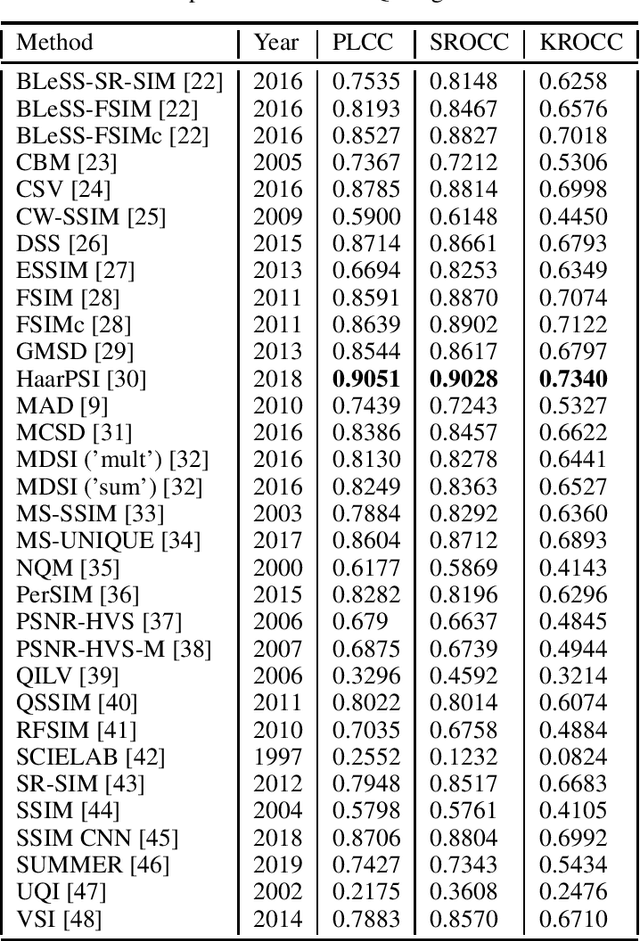
In this study, our goal is to give a comprehensive evaluation of 32 state-of-the-art FR-IQA metrics using the recently published MDID. This database contains distorted images derived from a set of reference, pristine images using random types and levels of distortions. Specifically, Gaussian noise, Gaussian blur, contrast change, JPEG noise, and JPEG2000 noise were considered.
Detecting Photoshopped Faces by Scripting Photoshop
Jun 13, 2019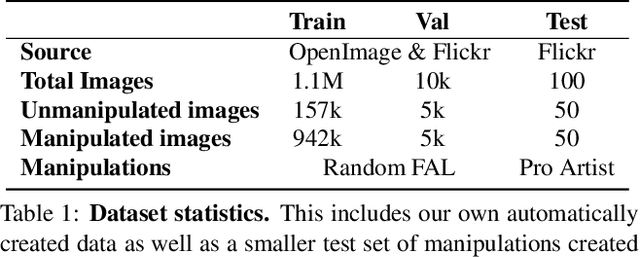

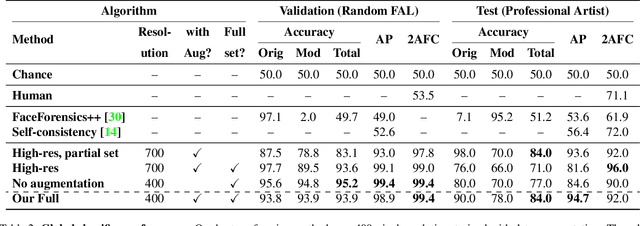
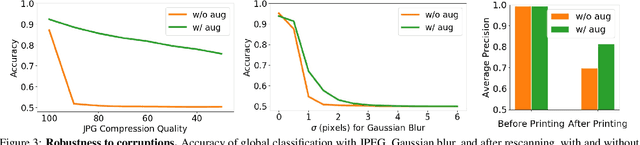
Most malicious photo manipulations are created using standard image editing tools, such as Adobe Photoshop. We present a method for detecting one very popular Photoshop manipulation -- image warping applied to human faces -- using a model trained entirely using fake images that were automatically generated by scripting Photoshop itself. We show that our model outperforms humans at the task of recognizing manipulated images, can predict the specific location of edits, and in some cases can be used to "undo" a manipulation to reconstruct the original, unedited image. We demonstrate that the system can be successfully applied to real, artist-created image manipulations.
Learning to estimate label uncertainty for automatic radiology report parsing
Oct 01, 2019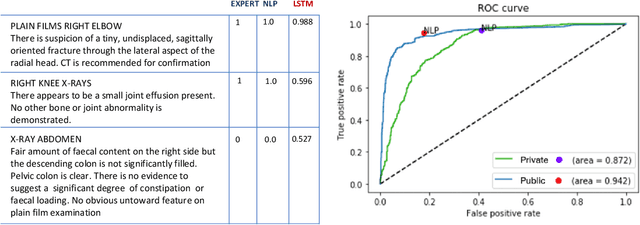
Bootstrapping labels from radiology reports has become the scalable alternative to provide inexpensive ground truth for medical imaging. Because of the domain specific nature, state-of-the-art report labeling tools are predominantly rule-based. These tools, however, typically yield a binary 0 or 1 prediction that indicates the presence or absence of abnormalities. These hard targets are then used as ground truth to train image models in the downstream, forcing models to express high degree of certainty even on cases where specificity is low. This could negatively impact the statistical efficiency of image models. We address such an issue by training a Bidirectional Long-Short Term Memory Network to augment heuristic-based discrete labels of X-ray reports from all body regions and achieve performance comparable or better than domain-specific NLP, but with additional uncertainty estimates which enable finer downstream image model training.
Look Locally Infer Globally: A Generalizable Face Anti-Spoofing Approach
Jun 04, 2020
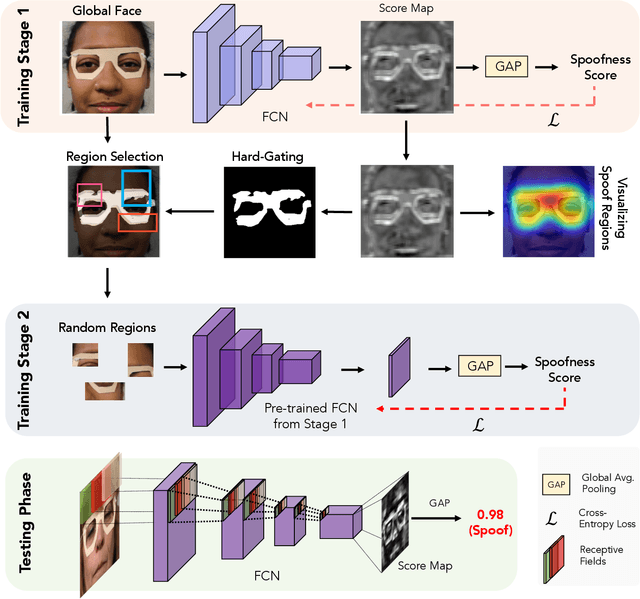
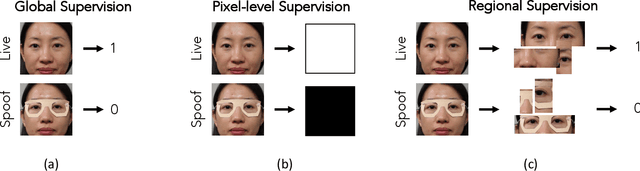

State-of-the-art spoof detection methods tend to overfit to the spoof types seen during training and fail to generalize to unknown spoof types. Given that face anti-spoofing is inherently a local task, we propose a face anti-spoofing framework, namely Self-Supervised Regional Fully Convolutional Network (SSR-FCN), that is trained to learn local discriminative cues from a face image in a self-supervised manner. The proposed framework improves generalizability while maintaining the computational efficiency of holistic face anti-spoofing approaches (< 4 ms on a Nvidia GTX 1080Ti GPU). The proposed method is interpretable since it localizes which parts of the face are labeled as spoofs. Experimental results show that SSR-FCN can achieve TDR = 65% @ 2.0% FDR when evaluated on a dataset comprising of 13 different spoof types under unknown attacks while achieving competitive performances under standard benchmark datasets (Oulu-NPU, CASIA-MFSD, and Replay-Attack).