 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RIT-Eyes: Rendering of near-eye images for eye-tracking applications
Jun 05, 2020
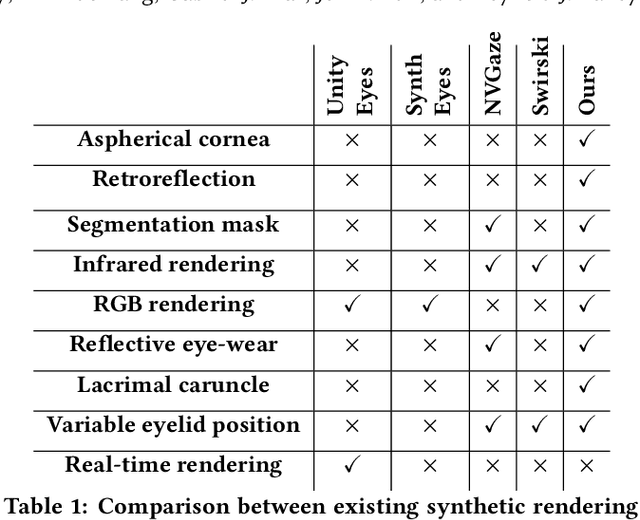
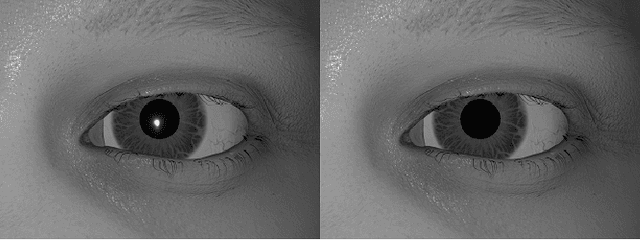
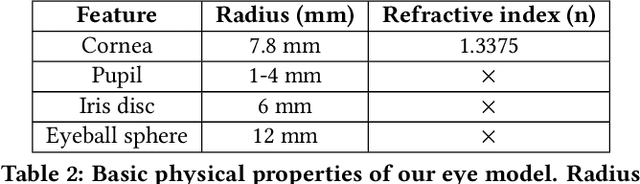
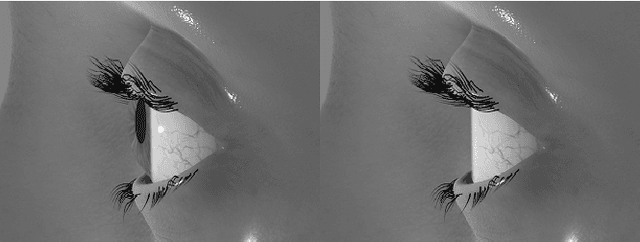
Deep neural networks for video-based eye tracking have demonstrated resilience to noisy environments, stray reflections, and low resolution. However, to train these networks, a large number of manually annotated images are required. To alleviate the cumbersome process of manual labeling, computer graphics rendering is employed to automatically generate a large corpus of annotated eye images under various conditions. In this work, we introduce a synthetic eye image generation platform that improves upon previous work by adding features such as an active deformable iris, an aspherical cornea, retinal retro-reflection, gaze-coordinated eye-lid deformations, and blinks. To demonstrate the utility of our platform, we render images reflecting the represented gaze distributions inherent in two publicly available datasets, NVGaze and OpenEDS. We also report on the performance of two semantic segmentation architectures (SegNet and RITnet) trained on rendered images and tested on the original datasets.
Robust Face Verification via Disentangled Representations
Jun 05, 2020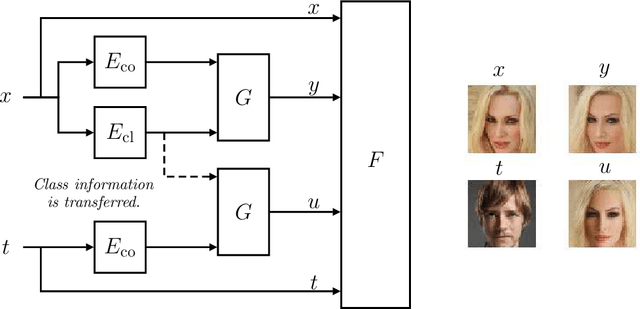
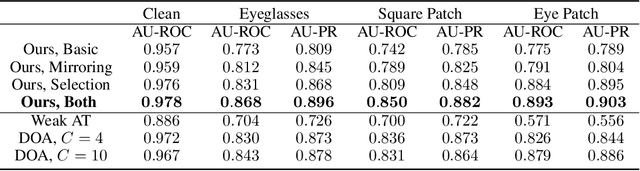
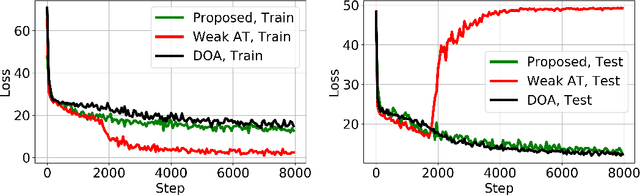
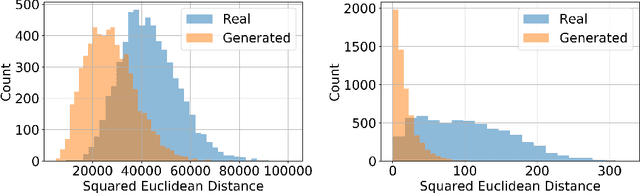
We introduce a robust algorithm for face verification, i.e., deciding whether twoimages are of the same person or not. Our approach is a novel take on the idea ofusing deep generative networks for adversarial robustness. We use the generativemodel during training as an online augmentation method instead of a test-timepurifier that removes adversarial noise. Our architecture uses a contrastive loss termand a disentangled generative model to sample negative pairs. Instead of randomlypairing two real images, we pair an image with its class-modified counterpart whilekeeping its content (pose, head tilt, hair, etc.) intact. This enables us to efficientlysample hard negative pairs for the contrastive loss. We experimentally show that, when coupled with adversarial training, the proposed scheme converges with aweak inner solver and has a higher clean and robust accuracy than state-of-the-art-methods when evaluated against white-box physical attacks.
LiDAR Iris for Loop-Closure Detection
Jan 02, 2020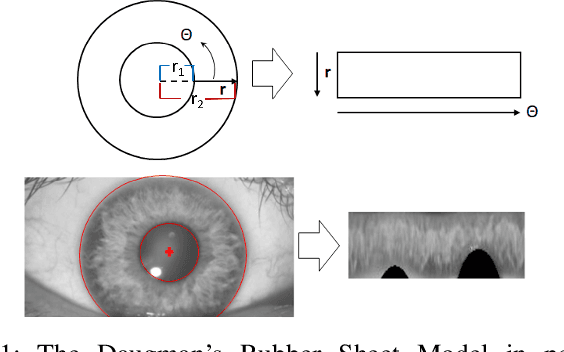

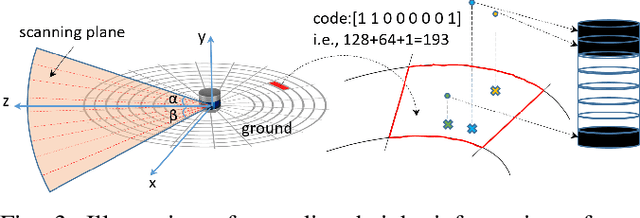
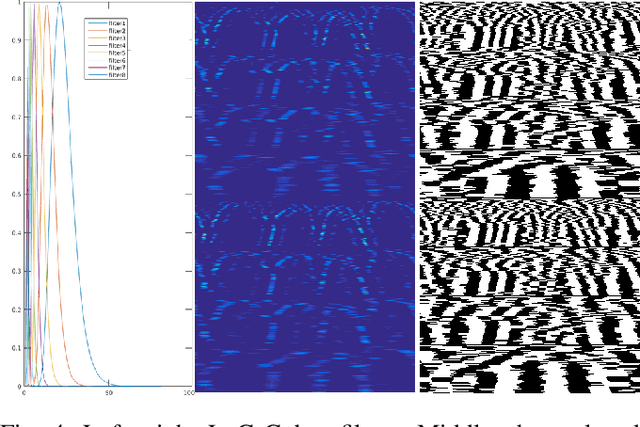
In this paper, a global descriptor for a LiDAR point cloud, called LiDAR Iris, is proposed for fast and accurate loop-closure detection. A binary signature image can be obtained for each point cloud after a couple of LoG-Gabor filtering and thresholding operations on the LiDAR-Iris image representation. Given two point clouds, the similarity of them can be calculated as the hamming-distance of two corresponding binary signature images extracted from the two point clouds, respectively. Our LiDAR-Iris method can achieve a pose-invariant loop-closure detection with the Fourier transform of the LiDAR-Iris representation if assuming a 3D (x,y,yaw) pose space, although our method can generally be applied to a 6D pose space by re-aligning point cloud with an additional IMU sensor. Experimental results on five road-scene sequences demonstrate its excellent performance in loop-closure detection.
Distortion Estimation Through Explicit Modeling of the Refractive Surface
Sep 24, 2019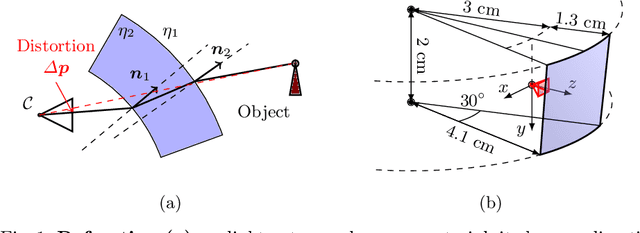
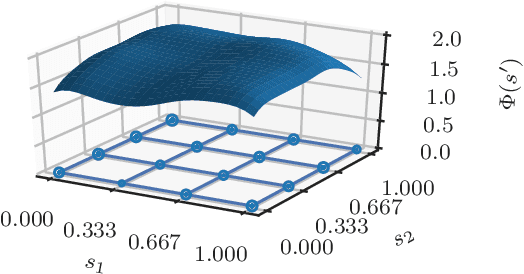
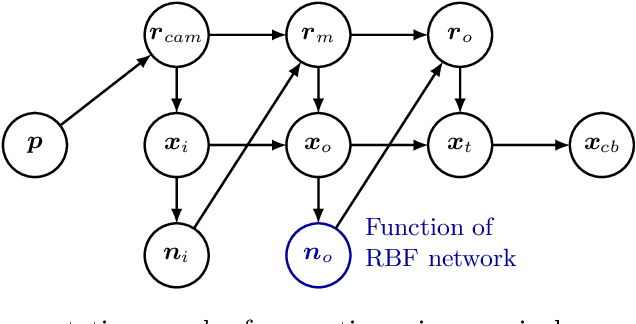

Precise calibration is a must for high reliance 3D computer vision algorithms. A challenging case is when the camera is behind a protective glass or transparent object: due to refraction, the image is heavily distorted; the pinhole camera model alone can not be used and a distortion correction step is required. By directly modeling the geometry of the refractive media, we build the image generation process by tracing individual light rays from the camera to a target. Comparing the generated images to their distorted - observed - counterparts, we estimate the geometry parameters of the refractive surface via model inversion by employing an RBF neural network. We present an image collection methodology that produces data suited for finding the distortion parameters and test our algorithm on synthetic and real-world data. We analyze the results of the algorithm.
* Accepted to ICANN 2019
Sparse Generative Adversarial Network
Aug 20, 2019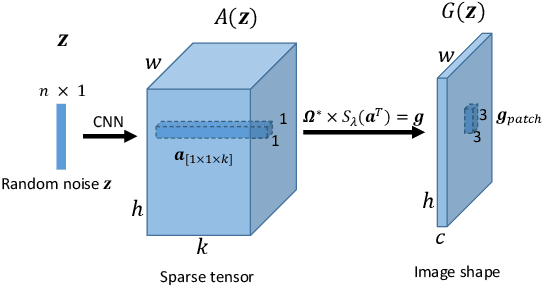
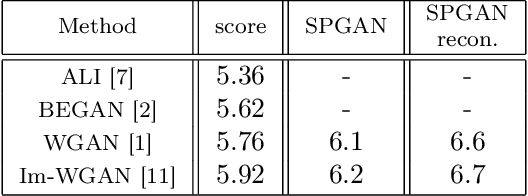
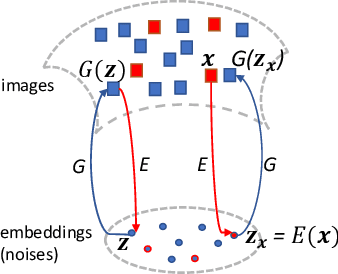
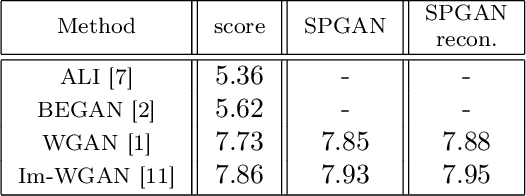
We propose a new approach to Generative Adversarial Networks (GANs) to achieve an improved performance with additional robustness to its so-called and well recognized mode collapse. We first proceed by mapping the desired data onto a frame-based space for a sparse representation to lift any limitation of small support features prior to learning the structure. To that end we start by dividing an image into multiple patches and modifying the role of the generative network from producing an entire image, at once, to creating a sparse representation vector for each image patch. We synthesize an entire image by multiplying generated sparse representations to a pre-trained dictionary and assembling the resulting patches. This approach restricts the output of the generator to a particular structure, obtained by imposing a Union of Subspaces (UoS) model to the original training data, leading to more realistic images, while maintaining a desired diversity. To further regularize GANs in generating high-quality images and to avoid the notorious mode-collapse problem, we introduce a third player in GANs, called reconstructor. This player utilizes an auto-encoding scheme to ensure that first, the input-output relation in the generator is injective and second each real image corresponds to some input noise. We present a number of experiments, where the proposed algorithm shows a remarkably higher inception score compared to the equivalent conventional GANs.
How Much Can We Really Trust You? Towards Simple, Interpretable Trust Quantification Metrics for Deep Neural Networks
Sep 12, 2020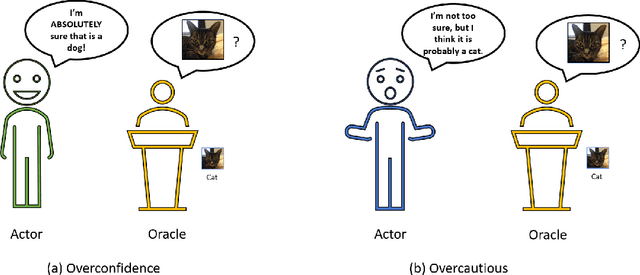

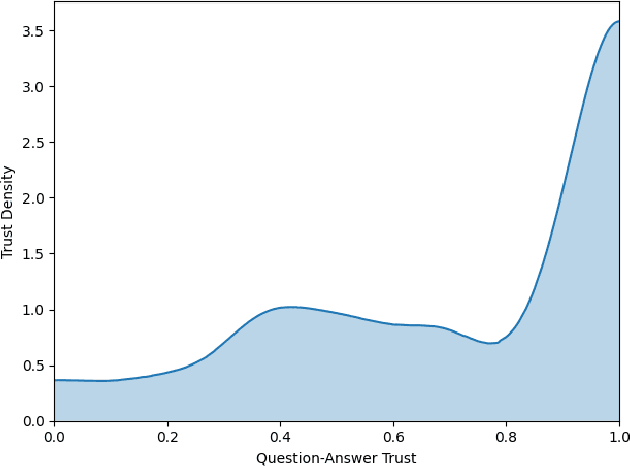
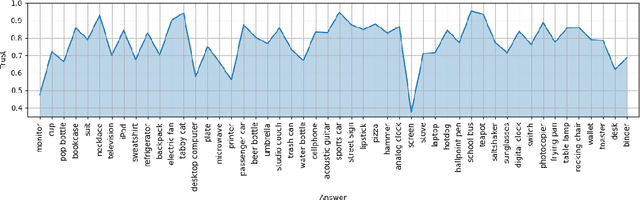
A critical step to building trustworthy deep neural networks is trust quantification, where we ask the question: How much can we trust a deep neural network? In this study, we take a step towards simple, interpretable metrics for trust quantification by introducing a suite of metrics for assessing the overall trustworthiness of deep neural networks based on their behaviour when answering a set of questions. We conduct a thought experiment and explore two key questions about trust in relation to confidence: 1) How much trust do we have in actors who give wrong answers with great confidence?, and 2) How much trust do we have in actors who give right answers hesitantly? Based on insights gained, we introduce the concept of question-answer trust to quantify trustworthiness of an individual answer based on confident behaviour under correct and incorrect answer scenarios, and the concept of trust density to characterize the distribution of overall trust for an individual answer scenario. We further introduce the concept of trust spectrum for representing overall trust with respect to the spectrum of possible answer scenarios across correctly and incorrectly answered questions. Finally, we introduce NetTrustScore, a scalar metric summarizing overall trustworthiness. The suite of metrics aligns with past social psychology studies that study the relationship between trust and confidence. Leveraging these metrics, we quantify the trustworthiness of several well-known deep neural network architectures for image recognition to get a deeper understanding of where trust breaks down. The proposed metrics are by no means perfect, but the hope is to push the conversation towards better metrics to help guide practitioners and regulators in producing, deploying, and certifying deep learning solutions that can be trusted to operate in real-world, mission-critical scenarios.
Explaining Away Attacks Against Neural Networks
Mar 06, 2020



We investigate the problem of identifying adversarial attacks on image-based neural networks. We present intriguing experimental results showing significant discrepancies between the explanations generated for the predictions of a model on clean and adversarial data. Utilizing this intuition, we propose a framework which can identify whether a given input is adversarial based on the explanations given by the model. Code for our experiments can be found here: https://github.com/seansaito/Explaining-Away-Attacks-Against-Neural-Networks.
Patch based Colour Transfer using SIFT Flow
May 18, 2020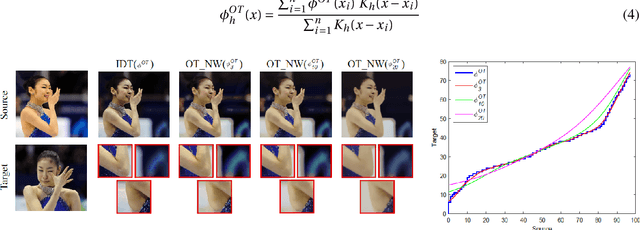
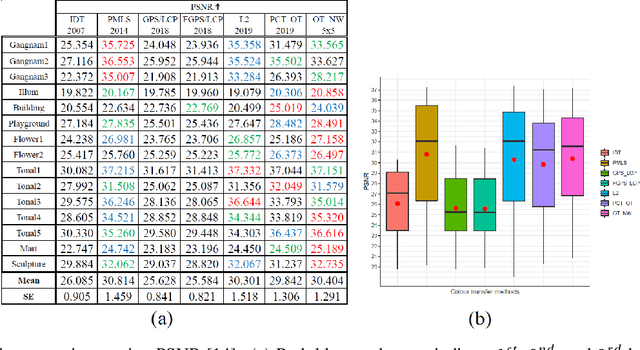
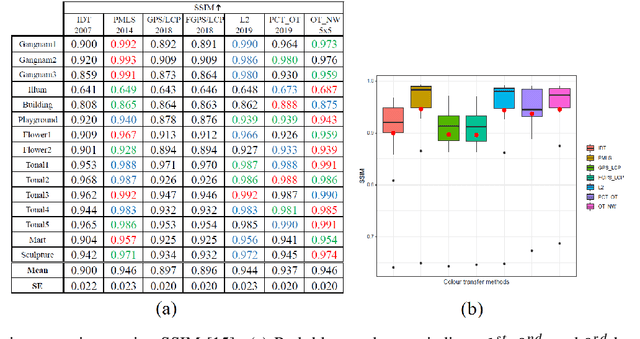
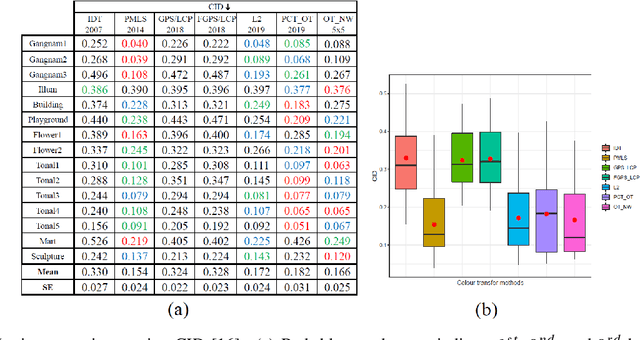
We propose a new colour transfer method with Optimal Transport (OT) to transfer the colour of a sourceimage to match the colour of a target image of the same scene that may exhibit large motion changes betweenimages. By definition OT does not take into account any available information about correspondences whencomputing the optimal solution. To tackle this problem we propose to encode overlapping neighborhoodsof pixels using both their colour and spatial correspondences estimated using motion estimation. We solvethe high dimensional problem in 1D space using an iterative projection approach. We further introducesmoothing as part of the iterative algorithms for solving optimal transport namely Iterative DistributionTransport (IDT) and its variant the Sliced Wasserstein Distance (SWD). Experiments show quantitative andqualitative improvements over previous state of the art colour transfer methods.
S3NAS: Fast NPU-aware Neural Architecture Search Methodology
Sep 04, 2020As the application area of convolutional neural networks (CNN) is growing in embedded devices, it becomes popular to use a hardware CNN accelerator, called neural processing unit (NPU), to achieve higher performance per watt than CPUs or GPUs. Recently, automated neural architecture search (NAS) emerges as the default technique to find a state-of-the-art CNN architecture with higher accuracy than manually-designed architectures for image classification. In this paper, we present a fast NPU-aware NAS methodology, called S3NAS, to find a CNN architecture with higher accuracy than the existing ones under a given latency constraint. It consists of three steps: supernet design, Single-Path NAS for fast architecture exploration, and scaling. To widen the search space of the supernet structure that consists of stages, we allow stages to have a different number of blocks and blocks to have parallel layers of different kernel sizes. For a fast neural architecture search, we apply a modified Single-Path NAS technique to the proposed supernet structure. In this step, we assume a shorter latency constraint than the required to reduce the search space and the search time. The last step is to scale up the network maximally within the latency constraint. For accurate latency estimation, an analytical latency estimator is devised, based on a cycle-level NPU simulator that runs an entire CNN considering the memory access overhead accurately. With the proposed methodology, we are able to find a network in 3 hours using TPUv3, which shows 82.72% top-1 accuracy on ImageNet with 11.66 ms latency. Code are released at https://github.com/cap-lab/S3NAS
Robotic Grasp Manipulation Using Evolutionary Computing and Deep Reinforcement Learning
Jan 15, 2020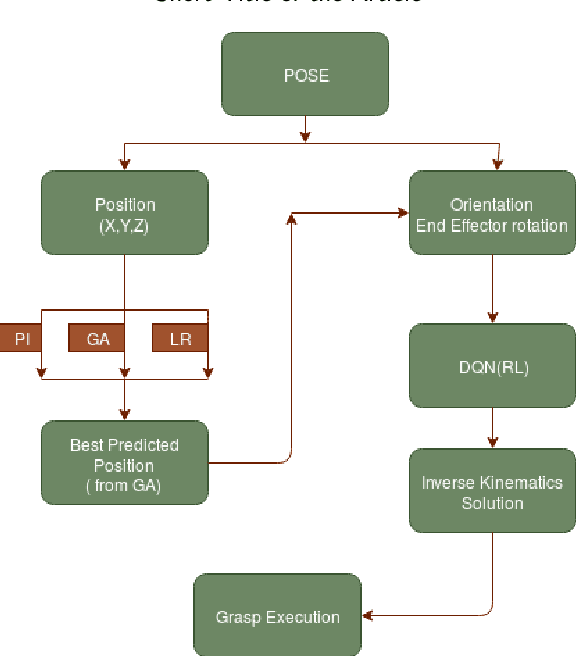
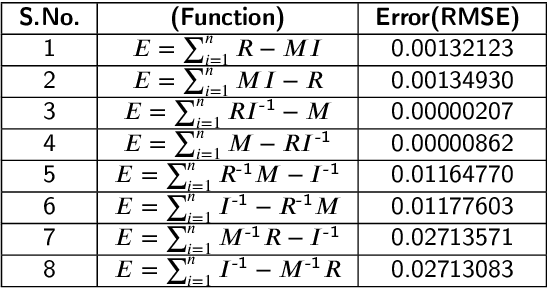
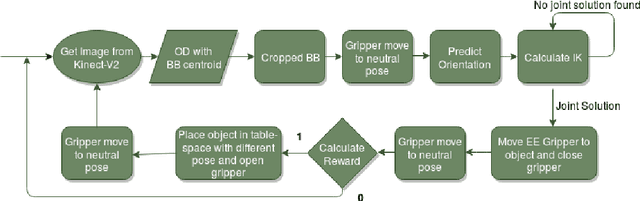

Intelligent Object manipulation for grasping is a challenging problem for robots. Unlike robots, humans almost immediately know how to manipulate objects for grasping due to learning over the years. A grown woman can grasp objects more skilfully than a child because of learning skills developed over years, the absence of which in the present day robotic grasping compels it to perform well below the human object grasping benchmarks. In this paper we have taken up the challenge of developing learning based pose estimation by decomposing the problem into both position and orientation learning. More specifically, for grasp position estimation, we explore three different methods - a Genetic Algorithm (GA) based optimization method to minimize error between calculated image points and predicted end-effector (EE) position, a regression based method (RM) where collected data points of robot EE and image points have been regressed with a linear model, a PseudoInverse (PI) model which has been formulated in the form of a mapping matrix with robot EE position and image points for several observations. Further for grasp orientation learning, we develop a deep reinforcement learning (DRL) model which we name as Grasp Deep Q-Network (GDQN) and benchmarked our results with Modified VGG16 (MVGG16). Rigorous experimentations show that due to inherent capability of producing very high-quality solutions for optimization problems and search problems, GA based predictor performs much better than the other two models for position estimation. For orientation learning results indicate that off policy learning through GDQN outperforms MVGG16, since GDQN architecture is specially made suitable for the reinforcement learning. Based on our proposed architectures and algorithms, the robot is capable of grasping all rigid body objects having regular shapes.