 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pixel Invisibility: Detecting Objects Invisible in Color Images
Jun 16, 2020

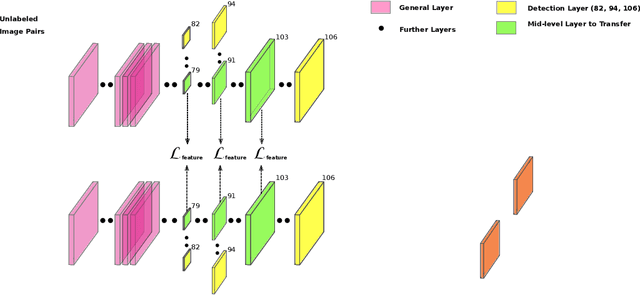

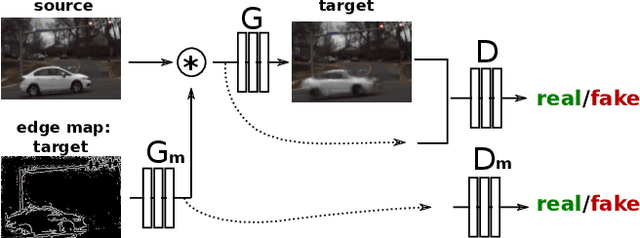
Despite recent success of object detectors using deep neural networks, their deployment on safety-critical applications such as self-driving cars remains questionable. This is partly due to the absence of reliable estimation for detectors' failure under operational conditions such as night, fog, dusk, dawn and glare. Such unquantifiable failures could lead to safety violations. In order to solve this problem, we created an algorithm that predicts a pixel-level invisibility map for color images that does not require manual labeling - that computes the probability that a pixel/region contains objects that are invisible in color domain, during various lighting conditions such as day, night and fog. We propose a novel use of cross modal knowledge distillation from color to infra-red domain using weakly-aligned image pairs from the day and construct indicators for the pixel-level invisibility based on the distances of their intermediate-level features. Quantitative experiments show the great performance of our pixel-level invisibility mask and also the effectiveness of distilled mid-level features on object detection in infra-red imagery.
Automatically Discovering and Learning New Visual Categories with Ranking Statistics
Feb 13, 2020
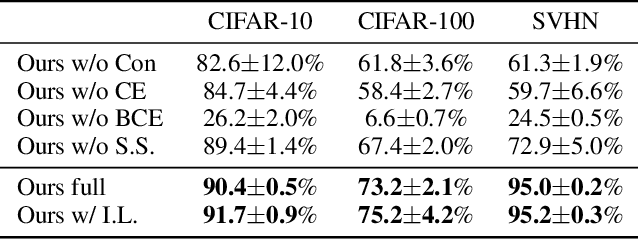
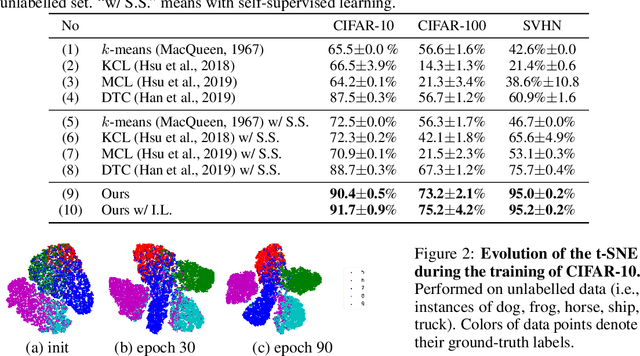
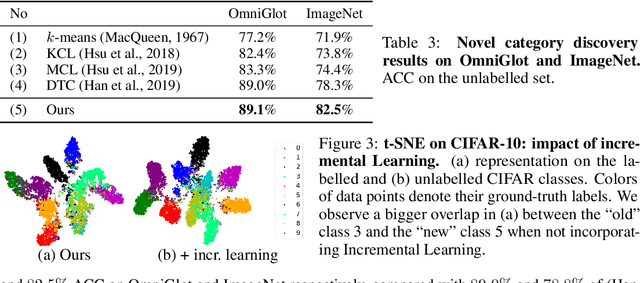
We tackle the problem of discovering novel classes in an image collection given labelled examples of other classes. This setting is similar to semi-supervised learning, but significantly harder because there are no labelled examples for the new classes. The challenge, then, is to leverage the information contained in the labelled images in order to learn a general-purpose clustering model and use the latter to identify the new classes in the unlabelled data. In this work we address this problem by combining three ideas: (1) we suggest that the common approach of bootstrapping an image representation using the labeled data only introduces an unwanted bias, and that this can be avoided by using self-supervised learning to train the representation from scratch on the union of labelled and unlabelled data; (2) we use rank statistics to transfer the model's knowledge of the labelled classes to the problem of clustering the unlabelled images; and, (3) we train the data representation by optimizing a joint objective function on the labelled and unlabelled subsets of the data, improving both the supervised classification of the labelled data, and the clustering of the unlabelled data. We evaluate our approach on standard classification benchmarks and outperform current methods for novel category discovery by a significant margin.
Approximate Fisher Kernels of non-iid Image Models for Image Categorization
Oct 03, 2015
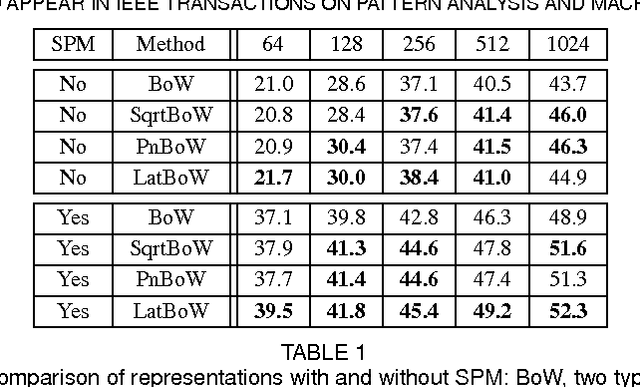

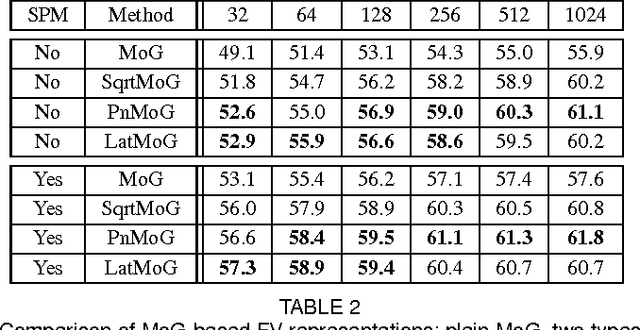
The bag-of-words (BoW) model treats images as sets of local descriptors and represents them by visual word histograms. The Fisher vector (FV) representation extends BoW, by considering the first and second order statistics of local descriptors. In both representations local descriptors are assumed to be identically and independently distributed (iid), which is a poor assumption from a modeling perspective. It has been experimentally observed that the performance of BoW and FV representations can be improved by employing discounting transformations such as power normalization. In this paper, we introduce non-iid models by treating the model parameters as latent variables which are integrated out, rendering all local regions dependent. Using the Fisher kernel principle we encode an image by the gradient of the data log-likelihood w.r.t. the model hyper-parameters. Our models naturally generate discounting effects in the representations; suggesting that such transformations have proven successful because they closely correspond to the representations obtained for non-iid models. To enable tractable computation, we rely on variational free-energy bounds to learn the hyper-parameters and to compute approximate Fisher kernels. Our experimental evaluation results validate that our models lead to performance improvements comparable to using power normalization, as employed in state-of-the-art feature aggregation methods.
* IEEE Transactions on Pattern Analysis and Machine Intelligence, in press, 2015
A new design of a flying robot, with advanced computer vision techniques to perform self-maintenance of smart grids
May 05, 2020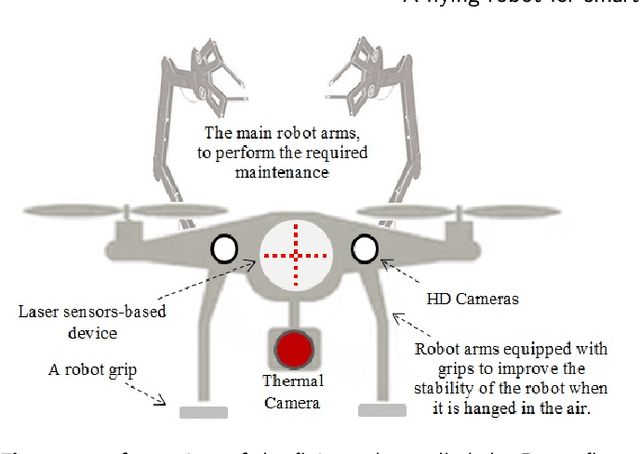
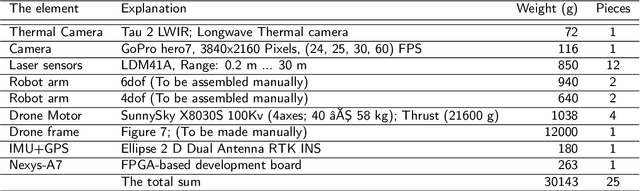
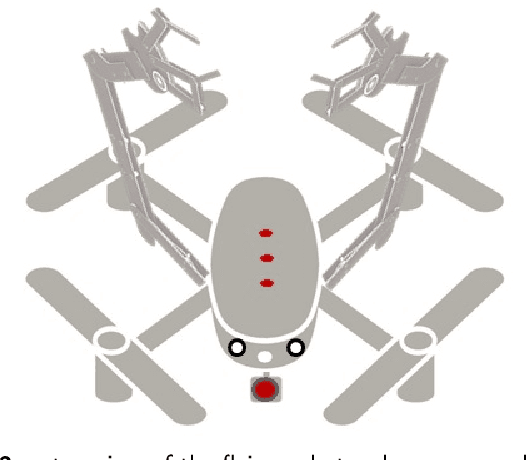

In this paper, we present a full design of a flying robot to investigate the state of power grid components and to perform the appropriate maintenance procedures according to each fail or defect that could be recognized. To realize this purpose; different types of sensors including thermal and aerial vision-based systems are employed in this design. The main features and technical specifications of this robot are presented and discussed here in detail. Some essential and advanced computer vision techniques are exploited in this work to take some readings and measurements from the robot's surroundings. From each given image, many sub-images containing different electrical components are extracted using a new region proposal approach that relies on Discrete Wavelet Transform, to be classified later by utilizing a Convolutional Neural Network.
Simplifying Models with Unlabeled Output Data
Jun 29, 2020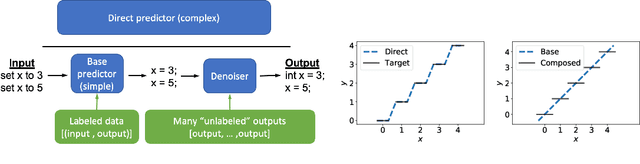


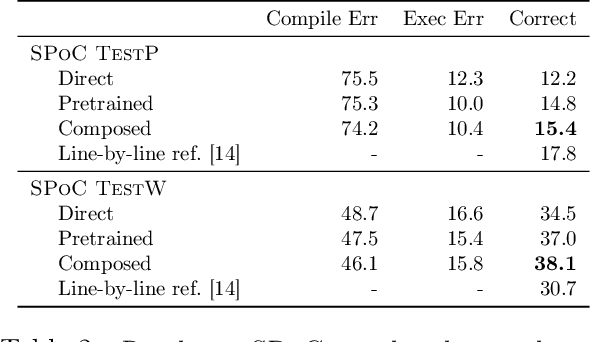
We focus on prediction problems with high-dimensional outputs that are subject to output validity constraints, e.g. a pseudocode-to-code translation task where the code must compile. For these problems, labeled input-output pairs are expensive to obtain, but "unlabeled" outputs, i.e. outputs without corresponding inputs, are freely available and provide information about output validity (e.g. code on GitHub). In this paper, we present predict-and-denoise, a framework that can leverage unlabeled outputs. Specifically, we first train a denoiser to map possibly invalid outputs to valid outputs using synthetic perturbations of the unlabeled outputs. Second, we train a predictor composed with this fixed denoiser. We show theoretically that for a family of functions with a discrete valid output space, composing with a denoiser reduces the complexity of a 2-layer ReLU network needed to represent the function and that this complexity gap can be arbitrarily large. We evaluate the framework empirically on several datasets, including image generation from attributes and pseudocode-to-code translation. On the SPoC~pseudocode-to-code dataset, our framework improves the proportion of code outputs that pass all test cases by 3-4% over a baseline Transformer.
An Inception Inspired Deep Network to Analyse Fundus Images
Nov 20, 2019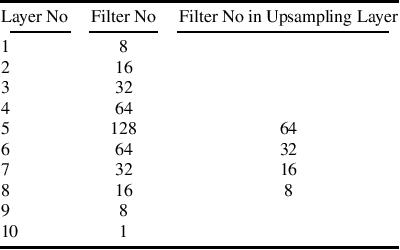
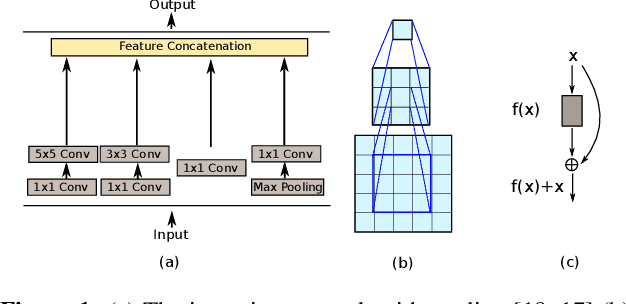
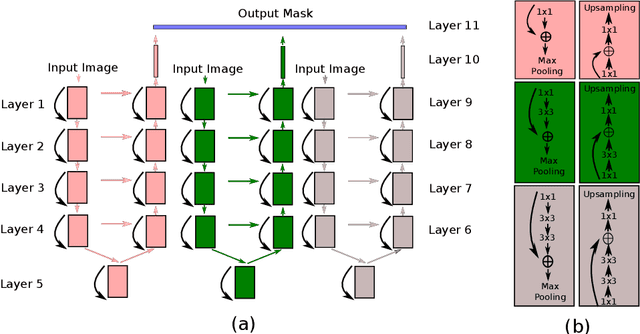
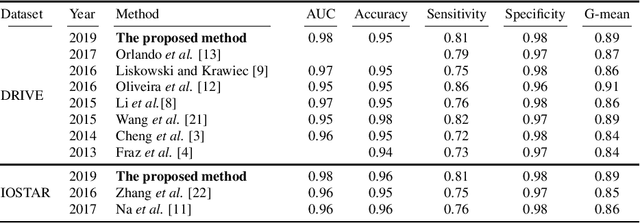
A fundus image usually contains the optic disc, pathologies and other structures in addition to vessels to be segmented. This study proposes a deep network for vessel segmentation, whose architecture is inspired by inception modules. The network contains three sub-networks, each with a different filter size, which are connected in the last layer of the proposed network. According to experiments conducted in the DRIVE and IOSTAR, the performance of our network is found to be better than or comparable to that of the previous methods. We also observe that the sub-networks pay attention to different parts of an input image when producing an output map in the last layer of the proposed network; though, training of the proposed network is not constrained for this purpose.
Fast Low-rank Shared Dictionary Learning for Image Classification
Jul 16, 2017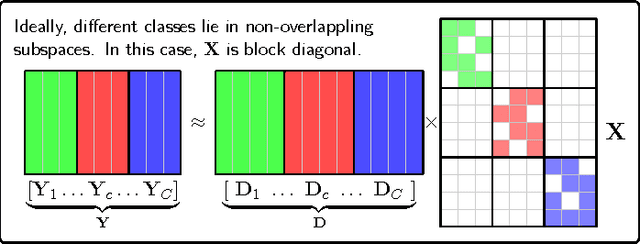
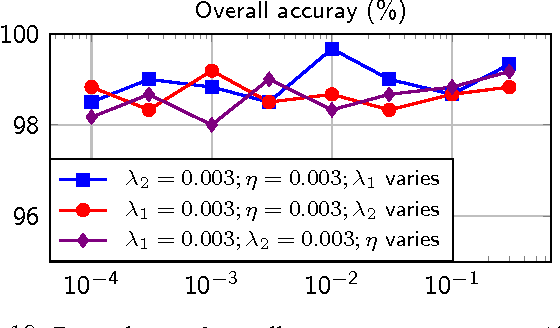

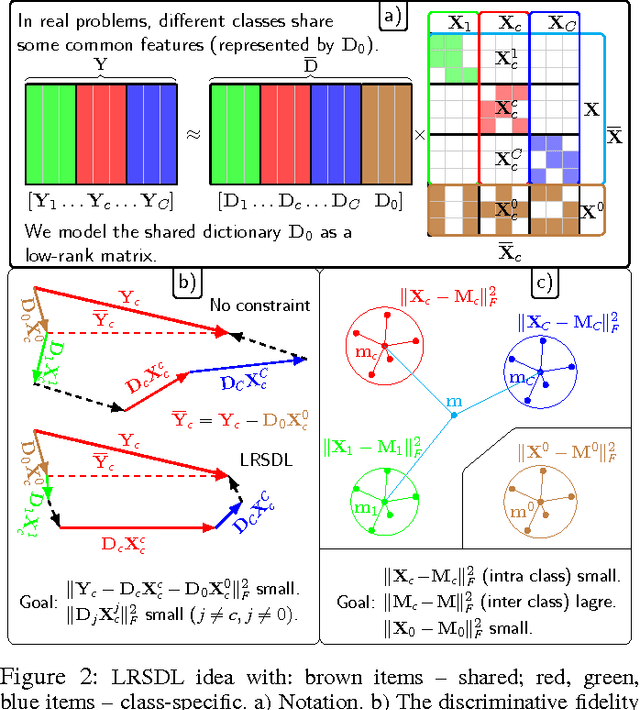
Despite the fact that different objects possess distinct class-specific features, they also usually share common patterns. This observation has been exploited partially in a recently proposed dictionary learning framework by separating the particularity and the commonality (COPAR). Inspired by this, we propose a novel method to explicitly and simultaneously learn a set of common patterns as well as class-specific features for classification with more intuitive constraints. Our dictionary learning framework is hence characterized by both a shared dictionary and particular (class-specific) dictionaries. For the shared dictionary, we enforce a low-rank constraint, i.e. claim that its spanning subspace should have low dimension and the coefficients corresponding to this dictionary should be similar. For the particular dictionaries, we impose on them the well-known constraints stated in the Fisher discrimination dictionary learning (FDDL). Further, we develop new fast and accurate algorithms to solve the subproblems in the learning step, accelerating its convergence. The said algorithms could also be applied to FDDL and its extensions. The efficiencies of these algorithms are theoretically and experimentally verified by comparing their complexities and running time with those of other well-known dictionary learning methods. Experimental results on widely used image datasets establish the advantages of our method over state-of-the-art dictionary learning methods.
Adversarial Graph Representation Adaptation for Cross-Domain Facial Expression Recognition
Aug 03, 2020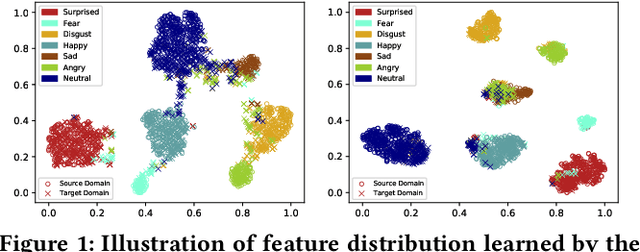
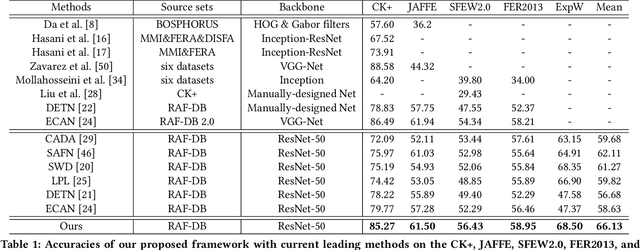
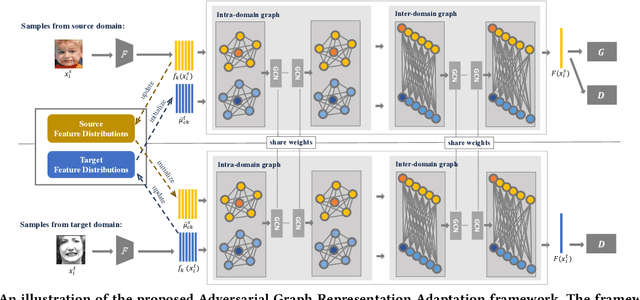
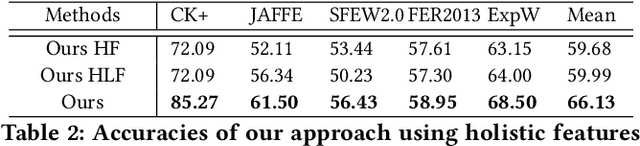
Data inconsistency and bias are inevitable among different facial expression recognition (FER) datasets due to subjective annotating process and different collecting conditions. Recent works resort to adversarial mechanisms that learn domain-invariant features to mitigate domain shift. However, most of these works focus on holistic feature adaptation, and they ignore local features that are more transferable across different datasets. Moreover, local features carry more detailed and discriminative content for expression recognition, and thus integrating local features may enable fine-grained adaptation. In this work, we propose a novel Adversarial Graph Representation Adaptation (AGRA) framework that unifies graph representation propagation with adversarial learning for cross-domain holistic-local feature co-adaptation. To achieve this, we first build a graph to correlate holistic and local regions within each domain and another graph to correlate these regions across different domains. Then, we learn the per-class statistical distribution of each domain and extract holistic-local features from the input image to initialize the corresponding graph nodes. Finally, we introduce two stacked graph convolution networks to propagate holistic-local feature within each domain to explore their interaction and across different domains for holistic-local feature co-adaptation. In this way, the AGRA framework can adaptively learn fine-grained domain-invariant features and thus facilitate cross-domain expression recognition. We conduct extensive and fair experiments on several popular benchmarks and show that the proposed AGRA framework achieves superior performance over previous state-of-the-art methods.
Disentangling Human Error from the Ground Truth in Segmentation of Medical Images
Aug 03, 2020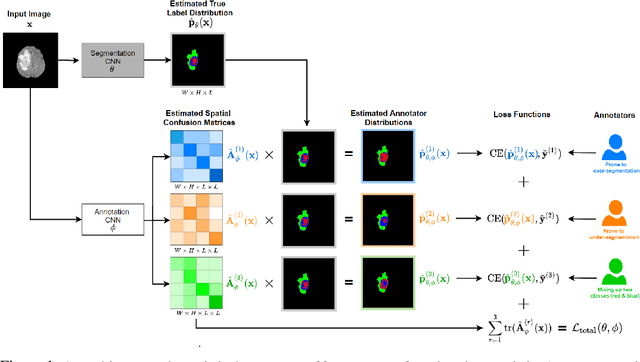



Recent years have seen increasing use of supervised learning methods for segmentation tasks. However, the predictive performance of these algorithms depends on the quality of labels. This problem is particularly pertinent in the medical image domain, where both the annotation cost and inter-observer variability are high. In a typical label acquisition process, different human experts provide their estimates of the 'true' segmentation labels under the influence of their own biases and competence levels. Treating these noisy labels blindly as the ground truth limits the performance that automatic segmentation algorithms can achieve. In this work, we present a method for jointly learning, from purely noisy observations alone, the reliability of individual annotators and the true segmentation label distributions, using two coupled CNNs. The separation of the two is achieved by encouraging the estimated annotators to be maximally unreliable while achieving high fidelity with the noisy training data. We first define a toy segmentation dataset based on MNIST and study the properties of the proposed algorithm. We then demonstrate the utility of the method on three public medical imaging segmentation datasets with simulated (when necessary) and real diverse annotations: 1) MSLSC (multiple-sclerosis lesions); 2) BraTS (brain tumours); 3) LIDC-IDRI (lung abnormalities). In all cases, our method outperforms competing methods and relevant baselines particularly in cases where the number of annotations is small and the amount of disagreement is large. The experiments also show strong ability to capture the complex spatial characteristics of annotators' mistakes.
Spectral DiffuserCam: lensless snapshot hyperspectral imaging with a spectral filter array
Jun 15, 2020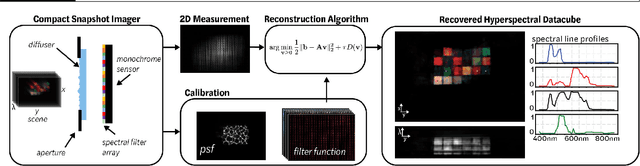
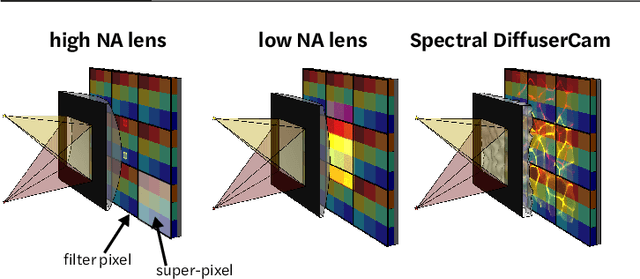
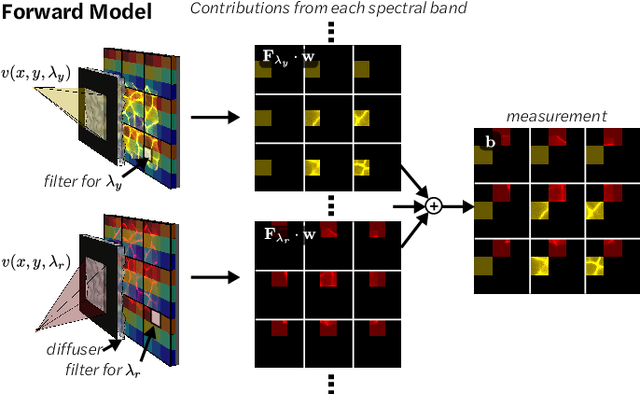
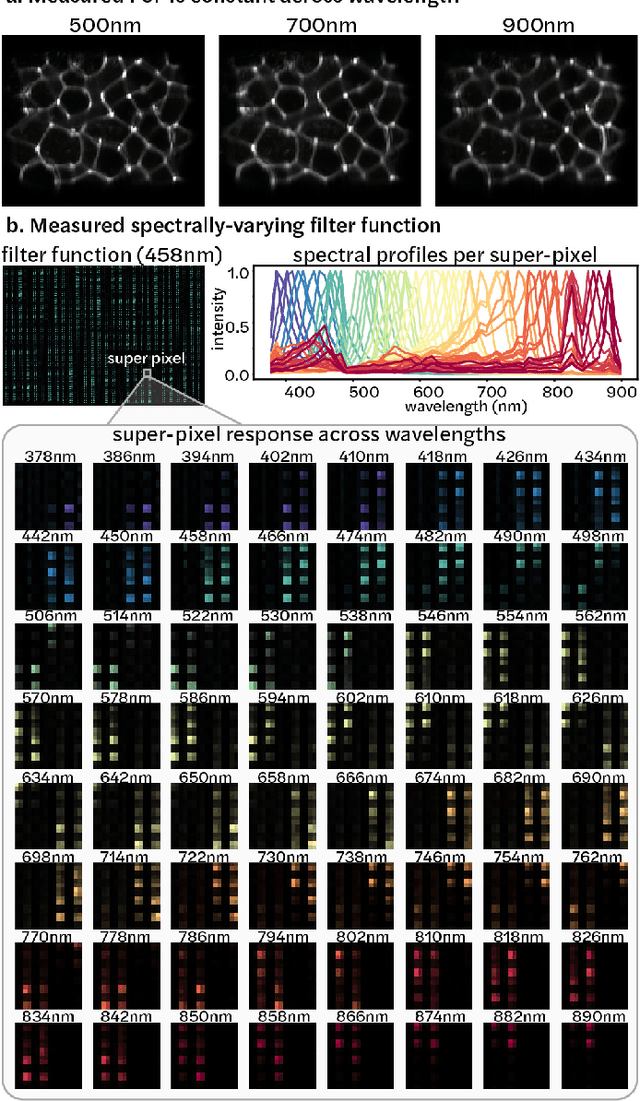
Hyperspectral imaging is useful for applications ranging from medical diagnostics to crop monitoring; however, traditional scanning hyperspectral imagers are prohibitively slow and expensive for widespread adoption. Snapshot techniques exist but are often confined to bulky benchtop setups or have low spatio-spectral resolution. In this paper, we propose a novel, compact, and inexpensive computational camera for snapshot hyperspectral imaging. Our system consists of a repeated spectral filter array placed directly on the image sensor and a diffuser placed close to the sensor. Each point in the world maps to a unique pseudorandom pattern on the spectral filter array, which encodes multiplexed spatio-spectral information. A sparsity-constrained inverse problem solver then recovers the hyperspectral volume with good spatio-spectral resolution. By using a spectral filter array, our hyperspectral imaging framework is flexible and can be designed with contiguous or non-contiguous spectral filters that can be chosen for a given application. We provide theory for system design, demonstrate a prototype device, and present experimental results with high spatio-spectral resolution.