 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convolutional Networks with MuxOut Layers as Multi-rate Systems for Image Upscaling
May 22, 2017
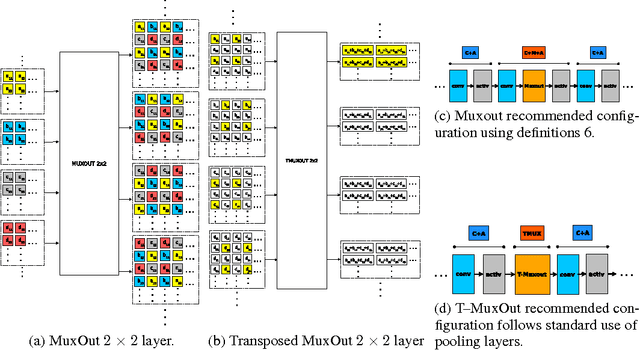

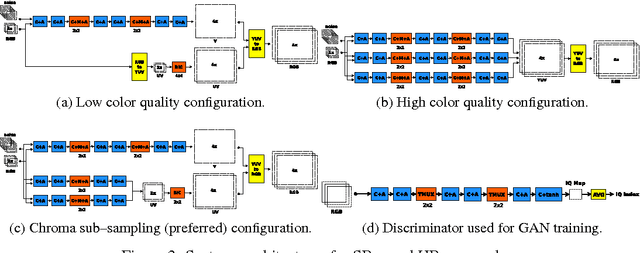
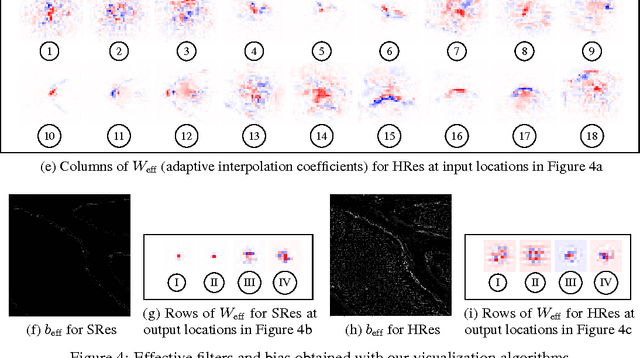
We interpret convolutional networks as adaptive filters and combine them with so-called MuxOut layers to efficiently upscale low resolution images. We formalize this interpretation by deriving a linear and space-variant structure of a convolutional network when its activations are fixed. We introduce general purpose algorithms to analyze a network and show its overall filter effect for each given location. We use this analysis to evaluate two types of image upscalers: deterministic upscalers that target the recovery of details from original content; and second, a new generation of upscalers that can sample the distribution of upscale aliases (images that share the same downscale version) that look like real content.
A Method for Estimating Reflectance map and Material using Deep Learning with Synthetic Dataset
Jan 15, 2020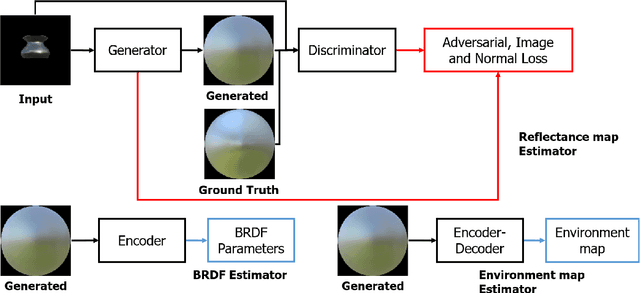
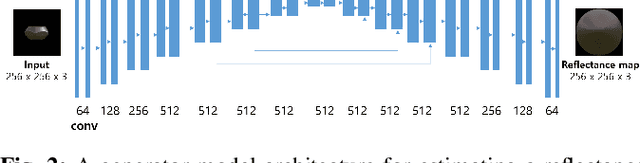
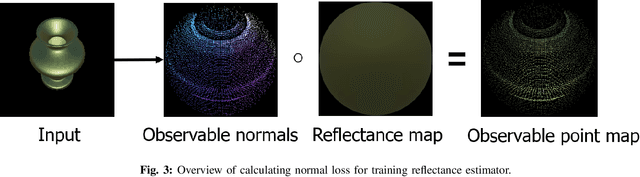
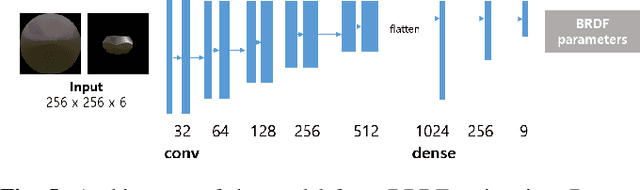
The process of decomposing target images into their internal properties is a difficult task due to the inherent ill-posed nature of the problem. The lack of data required to train a network is a one of the reasons why the decomposing appearance task is difficult. In this paper, we propose a deep learning-based reflectance map prediction system for material estimation of target objects in the image, so as to alleviate the ill-posed problem that occurs in this image decomposition operation. We also propose a network architecture for Bidirectional Reflectance Distribution Function (BRDF) parameter estimation, environment map estimation. We also use synthetic data to solve the lack of data problems. We get out of the previously proposed Deep Learning-based network architecture for reflectance map, and we newly propose to use conditional Generative Adversarial Network (cGAN) structures for estimating the reflectance map, which enables better results in many applications. To improve the efficiency of learning in this structure, we newly utilized the loss function using the normal map of the target object.
Deep Learning-based Denoising of Mammographic Images using Physics-driven Data Augmentation
Dec 11, 2019


Mammography is using low-energy X-rays to screen the human breast and is utilized by radiologists to detect breast cancer. Typically radiologists require a mammogram with impeccable image quality for an accurate diagnosis. In this study, we propose a deep learning method based on Convolutional Neural Networks (CNNs) for mammogram denoising to improve the image quality. We first enhance the noise level and employ Anscombe Transformation (AT) to transform Poisson noise to white Gaussian noise. With this data augmentation, a deep residual network is trained to learn the noise map of the noisy images. We show, that the proposed method can remove not only simulated but also real noise. Furthermore, we also compare our results with state-of-the-art denoising methods, such as BM3D and DNCNN. In an early investigation, we achieved qualitatively better mammogram denoising results.
DeepHAZMAT: Hazardous Materials Sign Detection and Segmentation with Restricted Computational Resources
Jul 13, 2020



One of the most challenging and non-trivial tasks in robotics-based rescue operations is Hazardous Materials or HAZMATs sign detection within the operation field, in order to prevent other unexpected disasters. Each Hazmat sign has a specific meaning that the rescue robot should detect and interpret it to take a safe action, accordingly. Accurate Hazmat detection and real-time processing are the two most important factors in such robotics applications. Furthermore, we also have to cope with some secondary challengers such as image distortion problems and restricted CPU and computational resources which are embedded in a rescue robot. In this paper, we propose a CNN-Based pipeline called DeepHAZMAT for detecting and segmenting Hazmats in four steps; 1) optimising the number of input images that are fed into the CNN network, 2) using the YOLOv3-tiny structure to collect the required visual information from the hazardous areas, 3) Hazmat sign segmentation and separation from the background using GrabCut technique, and 4) post-processing the result with morphological operators and convex hall algorithm. In spite of the utilisation of a very limited memory and CPU resources, the experimental results show the proposed method has successfully maintained a better performance in terms of detection-speed and detection-accuracy, compared with the state-of-the-art methods.
Point-Set Anchors for Object Detection, Instance Segmentation and Pose Estimation
Jul 13, 2020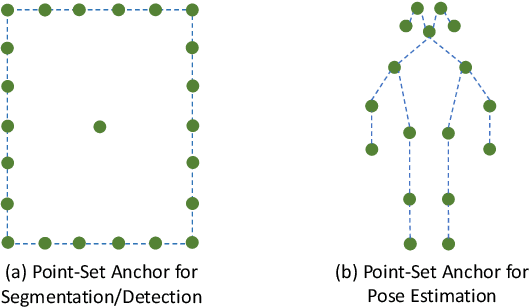


A recent approach for object detection and human pose estimation is to regress bounding boxes or human keypoints from a central point on the object or person. While this center-point regression is simple and efficient, we argue that the image features extracted at a central point contain limited information for predicting distant keypoints or bounding box boundaries, due to object deformation and scale/orientation variation. To facilitate inference, we propose to instead perform regression from a set of points placed at more advantageous positions. This point set is arranged to reflect a good initialization for the given task, such as modes in the training data for pose estimation, which lie closer to the ground truth than the central point and provide more informative features for regression. As the utility of a point set depends on how well its scale, aspect ratio and rotation matches the target, we adopt the anchor box technique of sampling these transformations to generate additional point-set candidates. We apply this proposed framework, called Point-Set Anchors, to object detection, instance segmentation, and human pose estimation. Our results show that this general-purpose approach can achieve performance competitive with state-of-the-art methods for each of these tasks.
BiNet: Degraded-Manuscript Binarization in Diverse Document Textures and Layouts using Deep Encoder-Decoder Networks
Nov 13, 2019
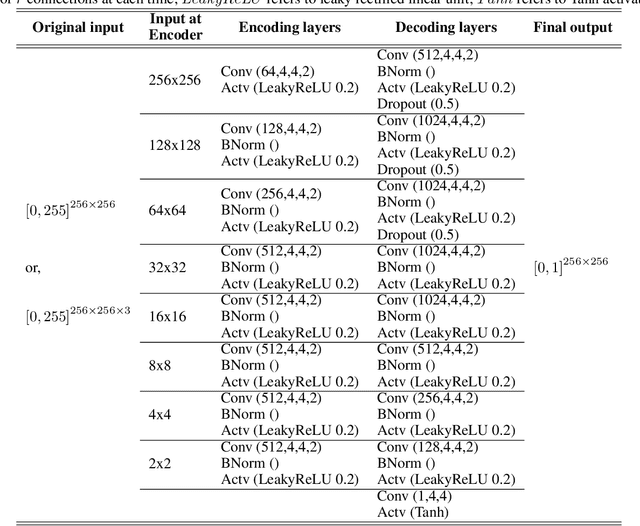

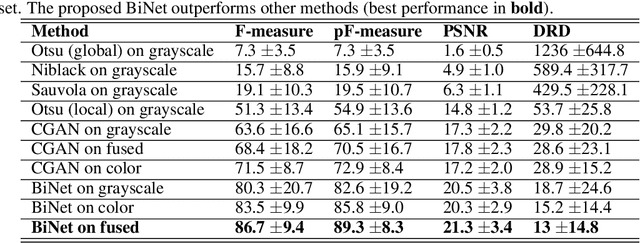
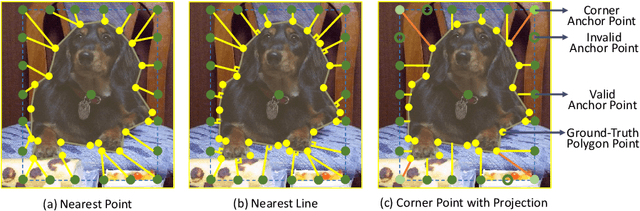
Handwritten document-image binarization is a semantic segmentation process to differentiate ink pixels from background pixels. It is one of the essential steps towards character recognition, writer identification, and script-style evolution analysis. The binarization task itself is challenging due to the vast diversity of writing styles, inks, and paper materials. It is even more difficult for historical manuscripts due to the aging and degradation of the documents over time. One of such manuscripts is the Dead Sea Scrolls (DSS) image collection, which poses extreme challenges for the existing binarization techniques. This article proposes a new binarization technique for the DSS images using the deep encoder-decoder networks. Although the artificial neural network proposed here is primarily designed to binarize the DSS images, it can be trained on different manuscript collections as well. Additionally, the use of transfer learning makes the network already utilizable for a wide range of handwritten documents, making it a unique multi-purpose tool for binarization. Qualitative results and several quantitative comparisons using both historical manuscripts and datasets from handwritten document image binarization competition (H-DIBCO and DIBCO) exhibit the robustness and the effectiveness of the system. The best performing network architecture proposed here is a variant of the U-Net encoder-decoders.
Q-CapsNets: A Specialized Framework for Quantizing Capsule Networks
Apr 17, 2020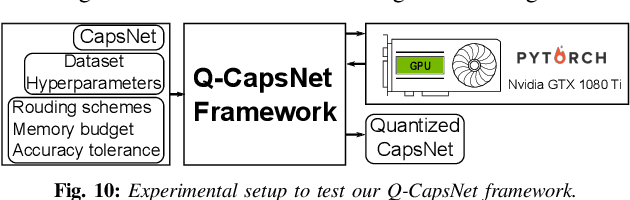
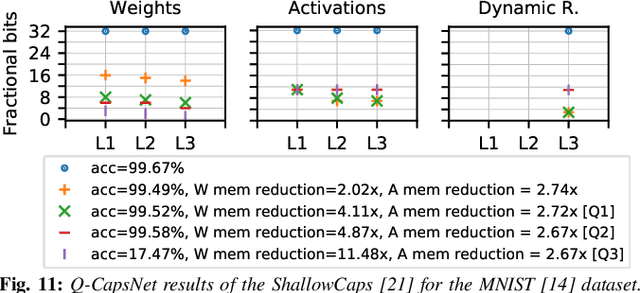
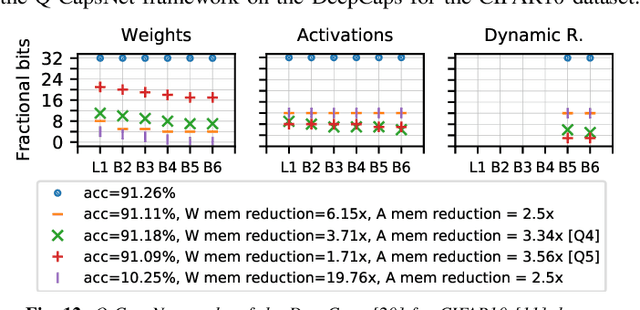
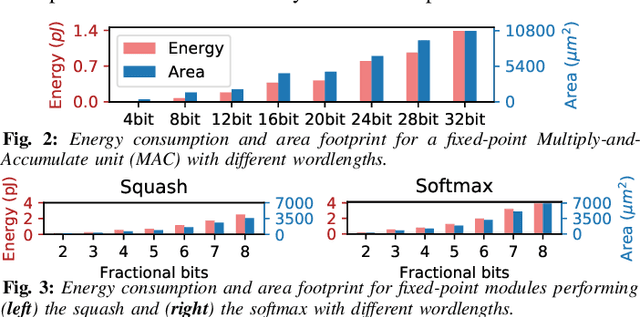
Capsule Networks (CapsNets), recently proposed by the Google Brain team, have superior learning capabilities in machine learning tasks, like image classification, compared to the traditional CNNs. However, CapsNets require extremely intense computations and are difficult to be deployed in their original form at the resource-constrained edge devices. This paper makes the first attempt to quantize CapsNet models, to enable their efficient edge implementations, by developing a specialized quantization framework for CapsNets. We evaluate our framework for several benchmarks. On a deep CapsNet model for the CIFAR10 dataset, the framework reduces the memory footprint by 6.2x, with only 0.15% accuracy loss. We will open-source our framework at https://git.io/JvDIF in August 2020.
Transfer Learning from Partial Annotations for Whole Brain Segmentation
Aug 28, 2019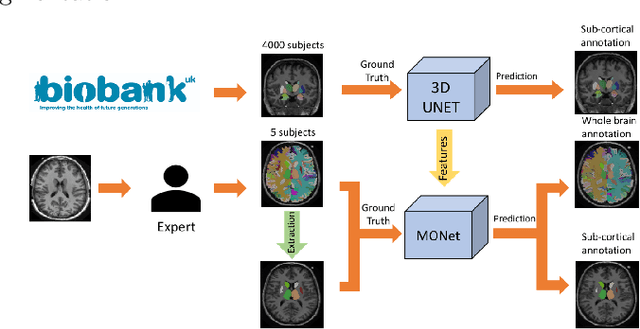

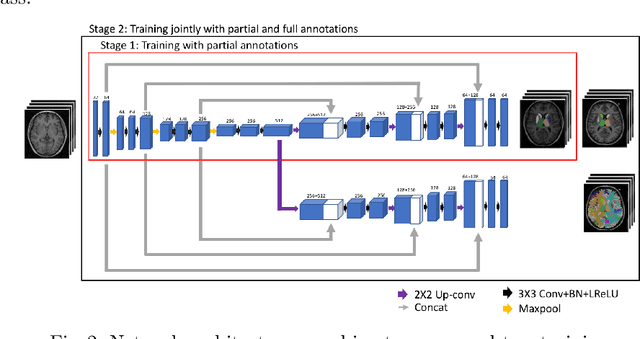
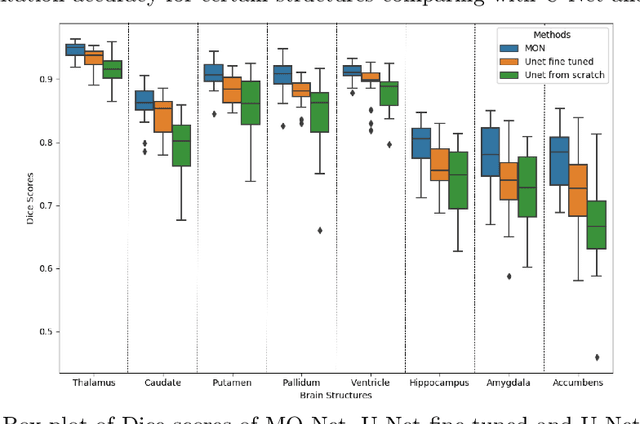
Brain MR image segmentation is a key task in neuroimaging studies. It is commonly conducted using standard computational tools, such as FSL, SPM, multi-atlas segmentation etc, which are often registration-based and suffer from expensive computation cost. Recently, there is an increased interest using deep neural networks for brain image segmentation, which have demonstrated advantages in both speed and performance. However, neural networks-based approaches normally require a large amount of manual annotations for optimising the massive amount of network parameters. For 3D networks used in volumetric image segmentation, this has become a particular challenge, as a 3D network consists of many more parameters compared to its 2D counterpart. Manual annotation of 3D brain images is extremely time-consuming and requires extensive involvement of trained experts. To address the challenge with limited manual annotations, here we propose a novel multi-task learning framework for brain image segmentation, which utilises a large amount of automatically generated partial annotations together with a small set of manually created full annotations for network training. Our method yields a high performance comparable to state-of-the-art methods for whole brain segmentation.
OR-UNet: an Optimized Robust Residual U-Net for Instrument Segmentation in Endoscopic Images
Apr 27, 2020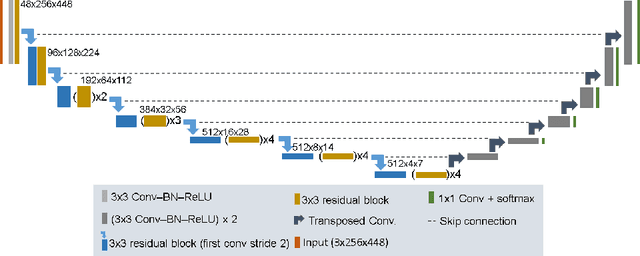
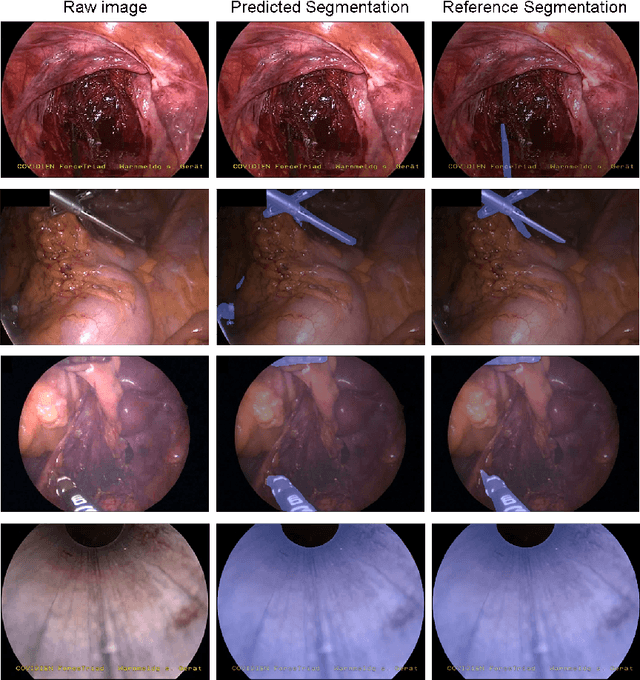
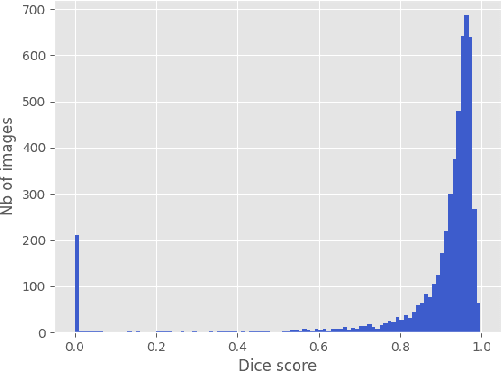
Segmentation of endoscopic images is an essential processing step for computer and robotics-assisted interventions. The Robust-MIS challenge provides the largest dataset of annotated endoscopic images to date, with 5983 manually annotated images. Here we describe OR-UNet, our optimized robust residual 2D U-Net for endoscopic image segmentation. As the name implies, the network makes use of residual connections in the encoder. It is trained with the sum of Dice and cross-entropy loss and deep supervision. During training, extensive data augmentation is used to increase the robustness. In an 8-fold cross-validation on the training images, our model achieved a mean (median) Dice score of 87.41 (94.35). We use the eight models from the cross-validation as an ensemble on the test set.
Sperm Detection and Tracking in Phase-Contrast Microscopy Image Sequences using Deep Learning and Modified CSR-DCF
Feb 13, 2020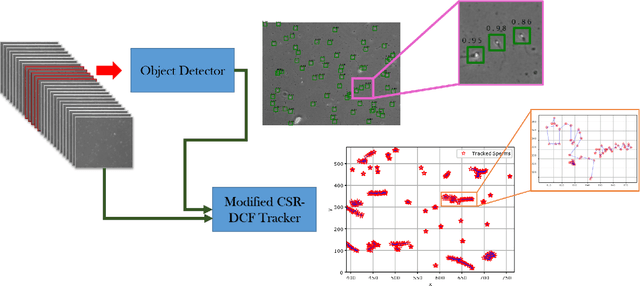
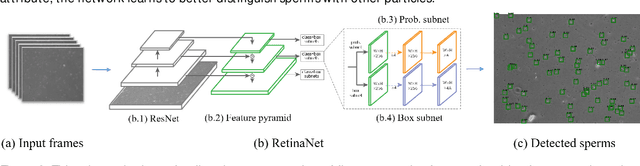
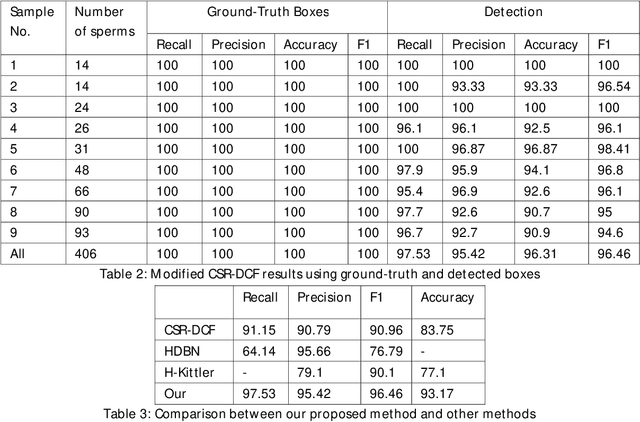
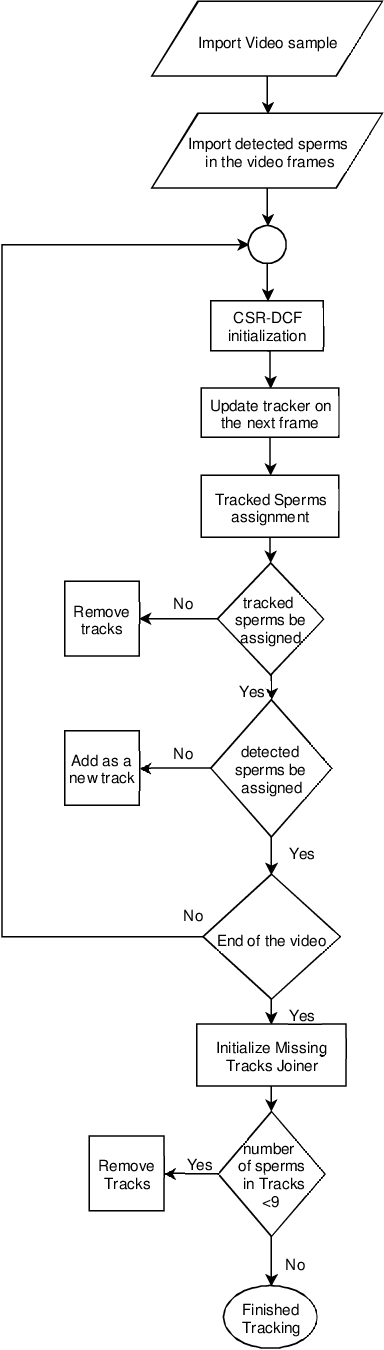
Nowadays, computer-aided sperm analysis (CASA) systems have made a big leap in extracting the characteristics of spermatozoa for studies or measuring human fertility. The first step in sperm characteristics analysis is sperm detection in the frames of the video sample. In this article, we used a deep fully convolutional network, as the object detector. Sperms are small objects with few attributes, that makes the detection more difficult in high-density samples and especially when there are other particles in semen, which could be like sperm heads. One of the main attributes of sperms is their movement, but this attribute cannot be extracted when only one frame would be fed to the network. To improve the performance of the sperm detection network, we concatenated some consecutive frames to use as the input of the network. With this method, the motility attribute has also been extracted, and then with the help of deep convolutional layers, we have achieved high accuracy in sperm detection. In the tracking phase, we modify the CSR-DCF algorithm. This method also has shown excellent results in sperm tracking even in high-density sperm samples, occlusions, sperm colliding, and when sperms exit from a frame and re-enter in the next frames. The average precision of the detection phase is 99.1%, and the F1 score of the tracking method evaluation is 97.06%. These results can be a great help in studies investigating sperm behavior and analyzing fertility possibility.