 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Region-Based Image Querying
Jun 23, 2010
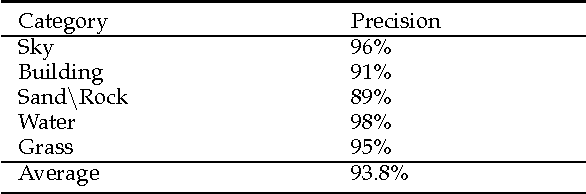

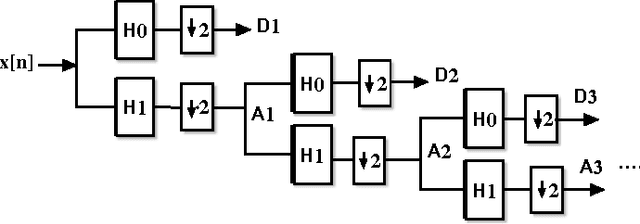
Retrieving images from large and varied repositories using visual contents has been one of major research items, but a challenging task in the image management community. In this paper we present an efficient approach for region-based image classification and retrieval using a fast multi-level neural network model. The advantages of this neural model in image classification and retrieval domain will be highlighted. The proposed approach accomplishes its goal in three main steps. First, with the help of a mean-shift based segmentation algorithm, significant regions of the image are isolated. Secondly, color and texture features of each region are extracted by using color moments and 2D wavelets decomposition technique. Thirdly the multi-level neural classifier is trained in order to classify each region in a given image into one of five predefined categories, i.e., "Sky", "Building", "SandnRock", "Grass" and "Water". Simulation results show that the proposed method is promising in terms of classification and retrieval accuracy results. These results compare favorably with the best published results obtained by other state-of-the-art image retrieval techniques.
* IEEE Publication Format, https://sites.google.com/site/journalofcomputing/
Disease Detection from Lung X-ray Images based on Hybrid Deep Learning
Mar 02, 2020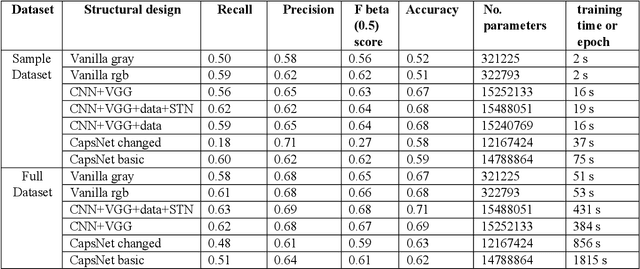
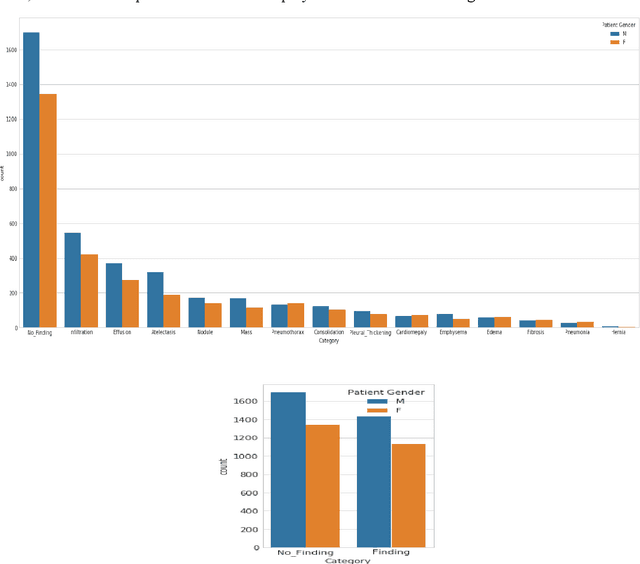
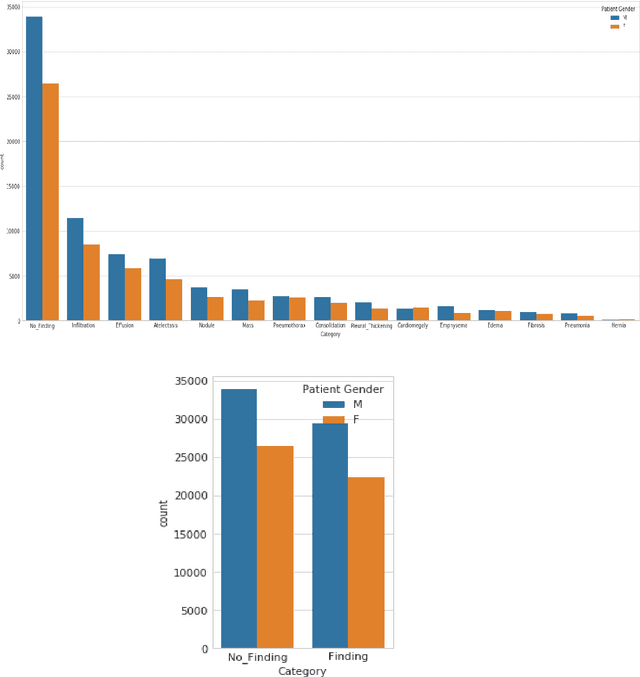
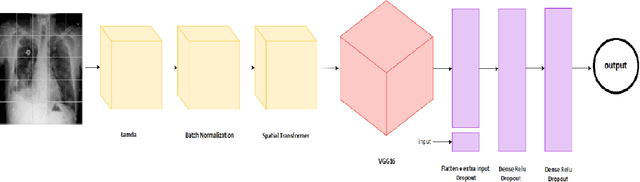
Lung Disease can be considered as the second most common type of disease for men and women. Many people die of lung disease such as lung cancer, Asthma, CPD (Chronic pulmonary disease) etc. in every year. Early detection of lung cancer can lessen the probability of deaths. In this paper, a chest X ray image dataset has been used in order to diagnosis properly and analysis the lung disease. For binary classification, some important is selected. The criteria include precision, recall, F beta score and accuracy. The fusion of AI and cancer diagnosis are acquiring huge interest as a cancer diagnostic tool. In recent days, deep learning based AI for example Convolutional neural network (CNN) can be successfully applied for disease classification and prediction. This paper mainly focuses the performance of Vanilla neural network, CNN, fusion of CNN and Visual Geometry group based neural network (VGG), fusion of CNN, VGG, STN and finally Capsule network. Normally basic CNN has poor performance for rotated, tilted or other abnormal image orientation. As a result, hybrid systems have been exhibited in order to enhance the accuracy with the maintenance of less training time. All models have been implemented in two groups of data sets: full dataset and sample dataset. Therefore, a comparative analysis has been developed in this paper. Some visualization of the attributes of the dataset has also been showed in this paper
Deep Learning Models for Visual Inspection on Automotive Assembling Line
Jul 02, 2020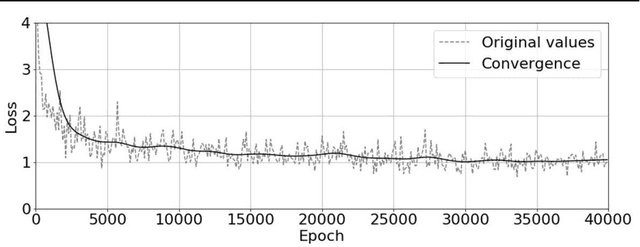


Automotive manufacturing assembly tasks are built upon visual inspections such as scratch identification on machined surfaces, part identification and selection, etc, which guarantee product and process quality. These tasks can be related to more than one type of vehicle that is produced within the same manufacturing line. Visual inspection was essentially human-led but has recently been supplemented by the artificial perception provided by computer vision systems (CVSs). Despite their relevance, the accuracy of CVSs varies accordingly to environmental settings such as lighting, enclosure and quality of image acquisition. These issues entail costly solutions and override part of the benefits introduced by computer vision systems, mainly when it interferes with the operating cycle time of the factory. In this sense, this paper proposes the use of deep learning-based methodologies to assist in visual inspection tasks while leaving very little footprints in the manufacturing environment and exploring it as an end-to-end tool to ease CVSs setup. The proposed approach is illustrated by four proofs of concept in a real automotive assembly line based on models for object detection, semantic segmentation, and anomaly detection.
* arXiv admin note: text overlap with arXiv:1802.08717, arXiv:1703.05921 by other authors
End-to-end Optimized Video Compression with MV-Residual Prediction
May 26, 2020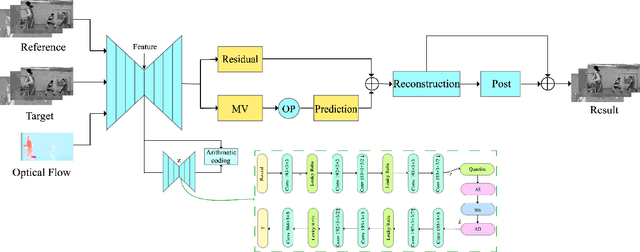

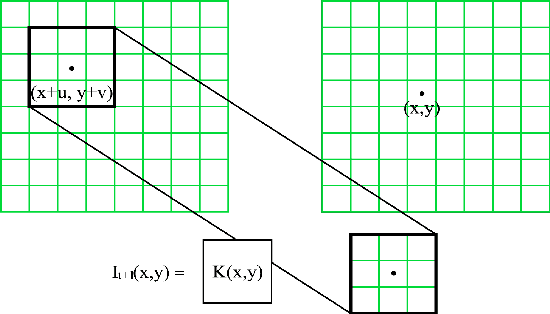
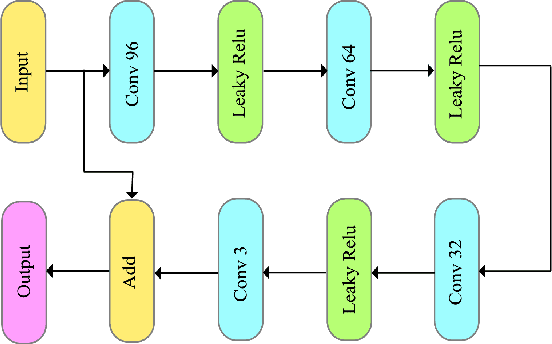
We present an end-to-end trainable framework for P-frame compression in this paper. A joint motion vector (MV) and residual prediction network MV-Residual is designed to extract the ensembled features of motion representations and residual information by treating the two successive frames as inputs. The prior probability of the latent representations is modeled by a hyperprior autoencoder and trained jointly with the MV-Residual network. Specially, the spatially-displaced convolution is applied for video frame prediction, in which a motion kernel for each pixel is learned to generate predicted pixel by applying the kernel at a displaced location in the source image. Finally, novel rate allocation and post-processing strategies are used to produce the final compressed bits, considering the bits constraint of the challenge. The experimental results on validation set show that the proposed optimized framework can generate the highest MS-SSIM for P-frame compression competition.
ktrain: A Low-Code Library for Augmented Machine Learning
Apr 19, 2020We present ktrain, a low-code Python library that makes machine learning more accessible and easier to apply. As a wrapper to TensorFlow and many other libraries (e.g., transformers, scikit-learn, stellargraph), it is designed to make sophisticated, state-of-the-art machine learning models simple to build, train, inspect, and deploy by both beginners and experienced practitioners. Featuring modules that support text data (e.g., text classification, sequence-tagging, open-domain question-answering), vision data (e.g., image classification), and graph data (e.g., node classification, link prediction), ktrain presents a simple unified interface enabling one to quickly solve a wide range of tasks in as little as three or four "commands" or lines of code.
Disentangling Human Error from the Ground Truth in Segmentation of Medical Images
Aug 06, 2020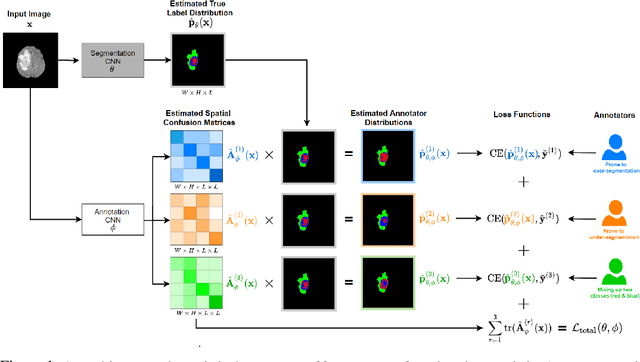



Recent years have seen increasing use of supervised learning methods for segmentation tasks. However, the predictive performance of these algorithms depends on the quality of labels. This problem is particularly pertinent in the medical image domain, where both the annotation cost and inter-observer variability are high. In a typical label acquisition process, different human experts provide their estimates of the 'true' segmentation labels under the influence of their own biases and competence levels. Treating these noisy labels blindly as the ground truth limits the performance that automatic segmentation algorithms can achieve. In this work, we present a method for jointly learning, from purely noisy observations alone, the reliability of individual annotators and the true segmentation label distributions, using two coupled CNNs. The separation of the two is achieved by encouraging the estimated annotators to be maximally unreliable while achieving high fidelity with the noisy training data. We first define a toy segmentation dataset based on MNIST and study the properties of the proposed algorithm. We then demonstrate the utility of the method on three public medical imaging segmentation datasets with simulated (when necessary) and real diverse annotations: 1) MSLSC (multiple-sclerosis lesions); 2) BraTS (brain tumours); 3) LIDC-IDRI (lung abnormalities). In all cases, our method outperforms competing methods and relevant baselines particularly in cases where the number of annotations is small and the amount of disagreement is large. The experiments also show strong ability to capture the complex spatial characteristics of annotators' mistakes.
Localization and Mapping of Sparse Geologic Features with Unpiloted Aircraft Systems
Jul 02, 2020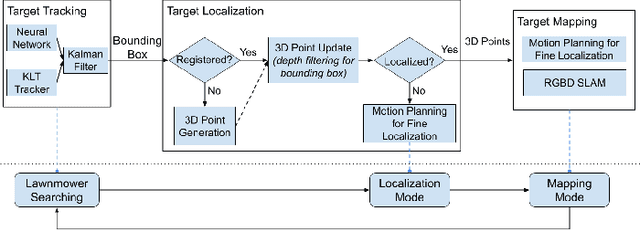

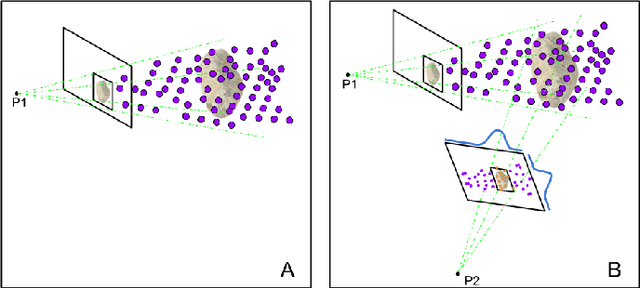
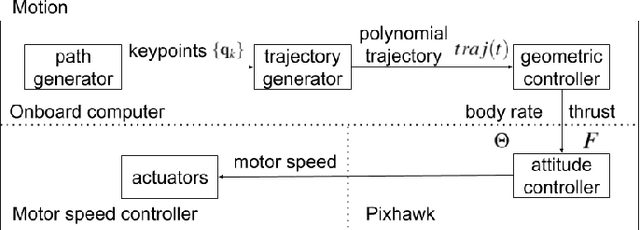
Robotic mapping is attractive in many science applications that involve environmental surveys. This paper presents a system for localization and mapping of sparsely distributed surface features such as precariously balanced rocks (PBRs), whose geometric fragility (stability) parameters provide valuable information on earthquake processes. With geomorphology as the test domain, we carry out a lawnmower search pattern using an Unpiloted Aerial Vehicle (UAV) equipped with a GPS module, stereo camera, and onboard computers. Once a target is detected by a deep neural network, we track its bounding box in the image coordinates by applying a Kalman filter that fuses the deep learning detection with KLT tracking. The target is localized in world coordinates using depth filtering where a set of 3D points are filtered by object bounding boxes from different camera perspectives. The 3D points also provide a strong prior on target shape, which is used for UAV path planning to accurately map the target using RGBD SLAM. After target mapping, the UAS resumes the lawnmower search pattern to locate the next target. Our end goal is a real-time mapping methodology for sparsely distributed surface features on earth or on extraterrestrial surfaces.
Deep 3D Pan via adaptive "t-shaped" convolutions with global and local adaptive dilations
Oct 09, 2019
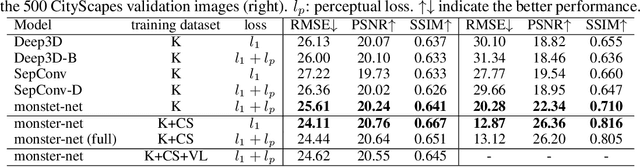
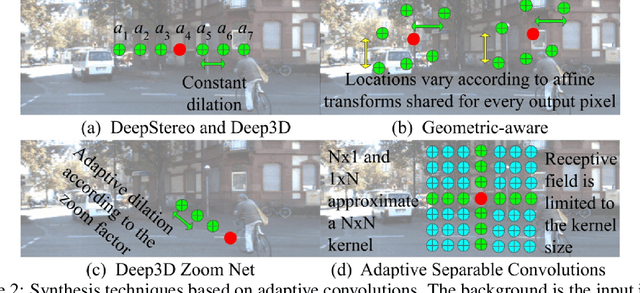
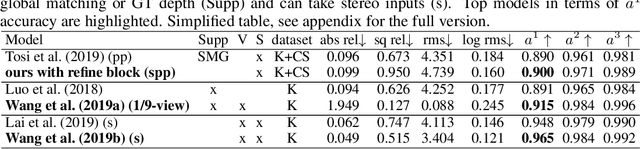
Recent advances in deep learning have shown promising results in many low-level vision tasks. However, solving the single-image-based view synthesis is still an open problem. In particular, the generation of new images at parallel camera views given a single input image is of great interest, as it enables 3D visualization of the 2D input scenery. We propose a novel network architecture to perform stereoscopic view synthesis at arbitrary camera positions along the X-axis, or Deep 3D Pan, with "t-shaped" adaptive kernels equipped with globally and locally adaptive dilations. Our proposed network architecture, the monster-net, is devised with a novel "t-shaped" adaptive kernel with globally and locally adaptive dilation, which can efficiently incorporate global camera shift into and handle local 3D geometries of the target image's pixels for the synthesis of naturally looking 3D panned views when a 2-D input image is given. Extensive experiments were performed on the KITTI, CityScapes and our VICLAB_STEREO indoors dataset to prove the efficacy of our method. Our monster-net significantly outperforms the state-of-the-art method, SOTA, by a large margin in all metrics of RMSE, PSNR, and SSIM. Our proposed monster-net is capable of reconstructing more reliable image structures in synthesized images with coherent geometry. Moreover, the disparity information that can be extracted from the "t-shaped" kernel is much more reliable than that of the SOTA for the unsupervised monocular depth estimation task, confirming the effectiveness of our method.
RGB-IR Cross-modality Person ReID based on Teacher-Student GAN Model
Jul 15, 2020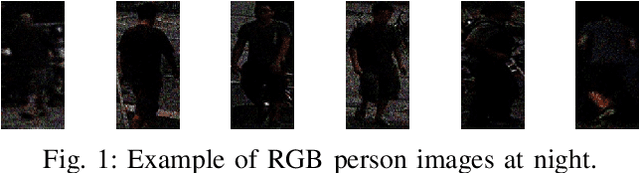
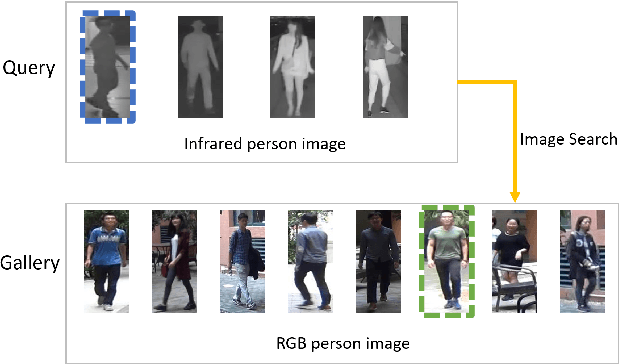
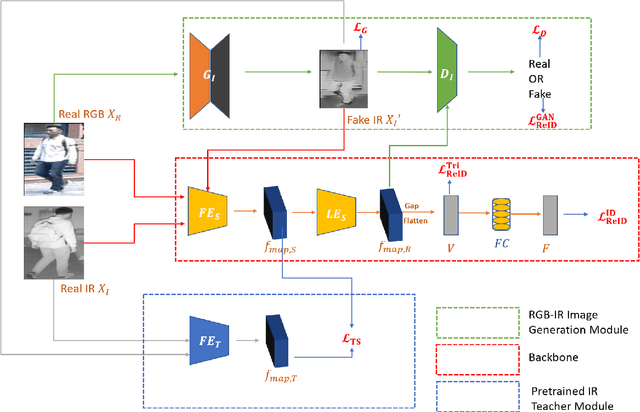

RGB-Infrared (RGB-IR) person re-identification (ReID) is a technology where the system can automatically identify the same person appearing at different parts of a video when light is unavailable. The critical challenge of this task is the cross-modality gap of features under different modalities. To solve this challenge, we proposed a Teacher-Student GAN model (TS-GAN) to adopt different domains and guide the ReID backbone to learn better ReID information. (1) In order to get corresponding RGB-IR image pairs, the RGB-IR Generative Adversarial Network (GAN) was used to generate IR images. (2) To kick-start the training of identities, a ReID Teacher module was trained under IR modality person images, which is then used to guide its Student counterpart in training. (3) Likewise, to better adapt different domain features and enhance model ReID performance, three Teacher-Student loss functions were used. Unlike other GAN based models, the proposed model only needs the backbone module at the test stage, making it more efficient and resource-saving. To showcase our model's capability, we did extensive experiments on the newly-released SYSU-MM01 RGB-IR Re-ID benchmark and achieved superior performance to the state-of-the-art with 49.8% Rank-1 and 47.4% mAP.
Variational Quantum Singular Value Decomposition
Jun 03, 2020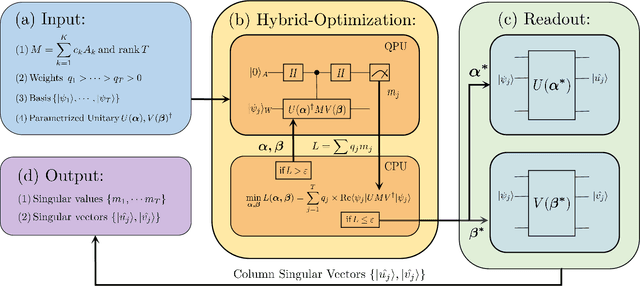
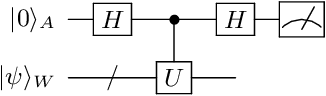
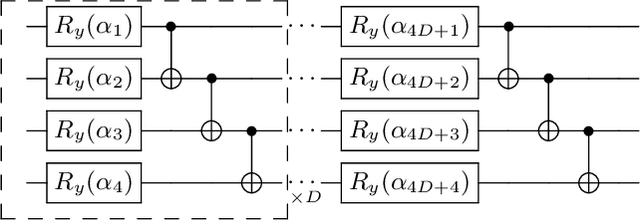
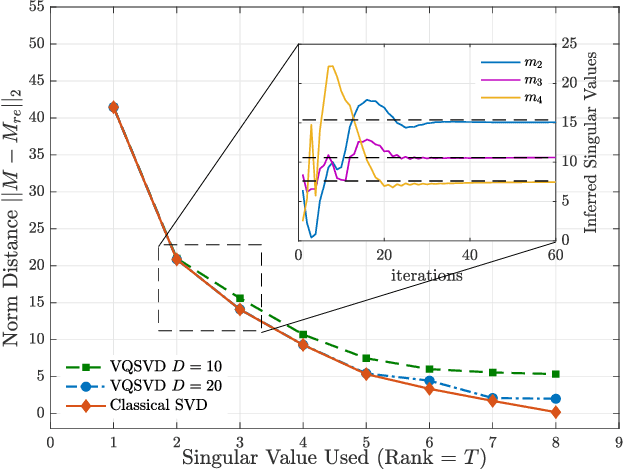
Singular value decomposition is central to many problems in both engineering and scientific fields. Several quantum algorithms have been proposed to determine the singular values and their associated singular vectors of a given matrix. Although these quantum algorithms are promising, the required quantum subroutines and resources are too costly on near-term quantum devices. In this work, we propose a variational quantum algorithm for singular value decomposition (VQSVD). By exploiting the variational principles for singular values and the Ky Fan Theorem, we design a novel loss function such that two quantum neural networks or parameterized quantum circuits could be trained to learn the singular vectors and output the corresponding singular values. We further conduct numerical simulations of the algorithm for singular-value decomposition of random matrices as well as its applications in image compression of handwritten digits. Finally, we discuss the applications of our algorithm in systems of linear equations, least squares estimation, and recommendation systems.