 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Holistically-Attracted Wireframe Parsing
Mar 03, 2020

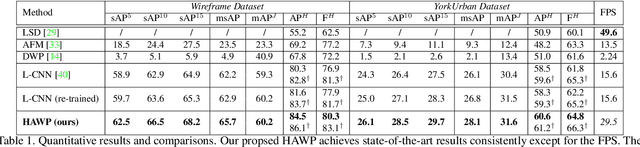
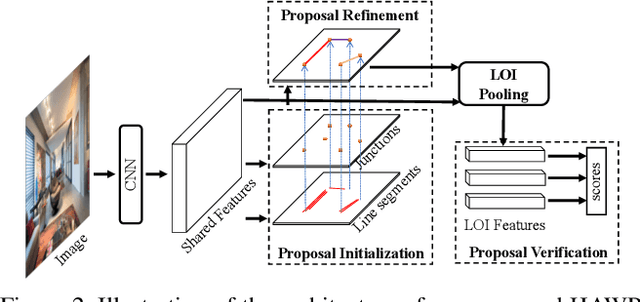
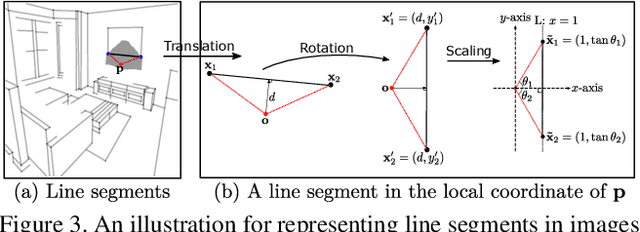
This paper presents a fast and parsimonious parsing method to accurately and robustly detect a vectorized wireframe in an input image with a single forward pass. The proposed method is end-to-end trainable, consisting of three components: (i) line segment and junction proposal generation, (ii) line segment and junction matching, and (iii) line segment and junction verification. For computing line segment proposals, a novel exact dual representation is proposed which exploits a parsimonious geometric reparameterization for line segments and forms a holistic 4-dimensional attraction field map for an input image. Junctions can be treated as the "basins" in the attraction field. The proposed method is thus called Holistically-Attracted Wireframe Parser (HAWP). In experiments, the proposed method is tested on two benchmarks, the Wireframe dataset, and the YorkUrban dataset. On both benchmarks, it obtains state-of-the-art performance in terms of accuracy and efficiency. For example, on the Wireframe dataset, compared to the previous state-of-the-art method L-CNN, it improves the challenging mean structural average precision (msAP) by a large margin ($2.8\%$ absolute improvements) and achieves 29.5 FPS on single GPU ($89\%$ relative improvement). A systematic ablation study is performed to further justify the proposed method.
Cross-Identity Motion Transfer for Arbitrary Objects through Pose-Attentive Video Reassembling
Jul 17, 2020
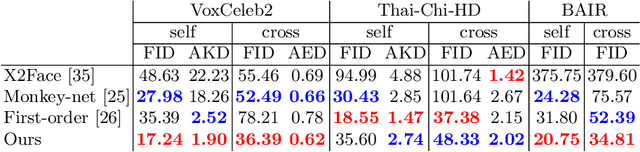
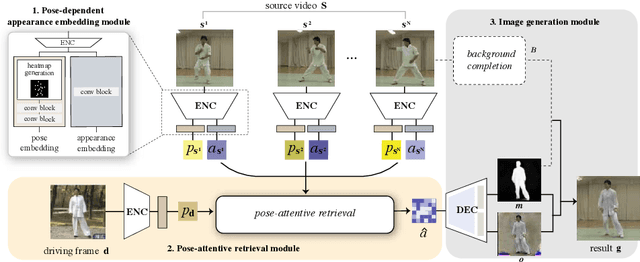
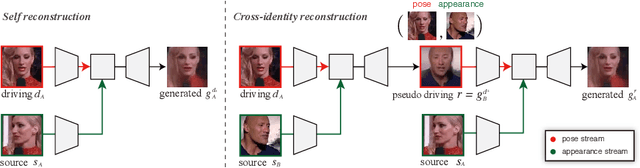
We propose an attention-based networks for transferring motions between arbitrary objects. Given a source image(s) and a driving video, our networks animate the subject in the source images according to the motion in the driving video. In our attention mechanism, dense similarities between the learned keypoints in the source and the driving images are computed in order to retrieve the appearance information from the source images. Taking a different approach from the well-studied warping based models, our attention-based model has several advantages. By reassembling non-locally searched pieces from the source contents, our approach can produce more realistic outputs. Furthermore, our system can make use of multiple observations of the source appearance (e.g. front and sides of faces) to make the results more accurate. To reduce the training-testing discrepancy of the self-supervised learning, a novel cross-identity training scheme is additionally introduced. With the training scheme, our networks is trained to transfer motions between different subjects, as in the real testing scenario. Experimental results validate that our method produces visually pleasing results in various object domains, showing better performances compared to previous works.
Interpolation between Residual and Non-Residual Networks
Jun 10, 2020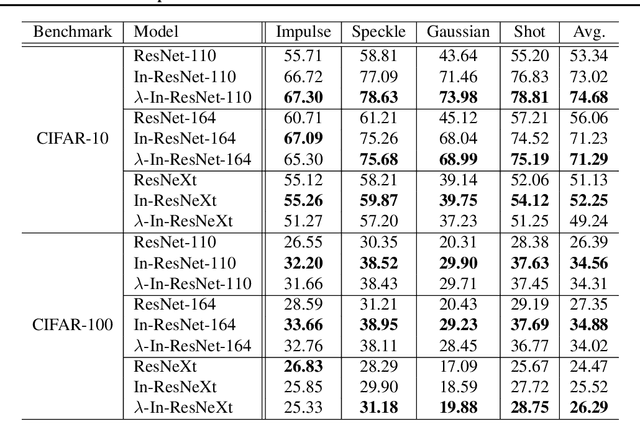
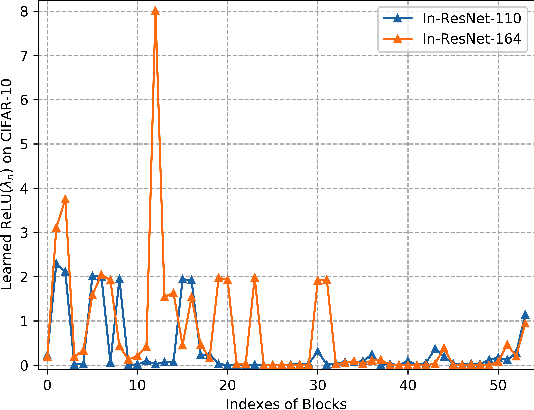
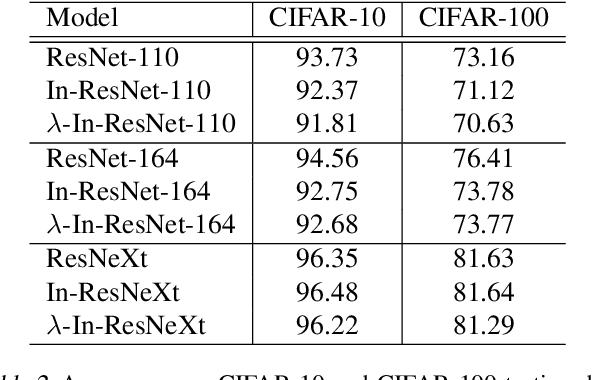
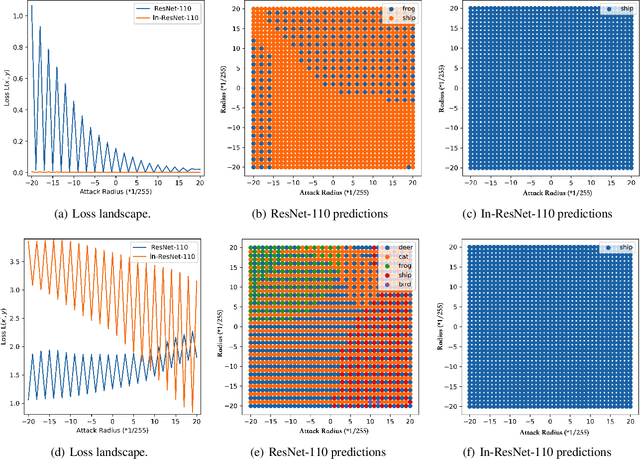
Although ordinary differential equations (ODEs) provide insights for designing network architectures, its relationship with the non-residual convolutional neural networks (CNNs) is still unclear. In this paper, we present a novel ODE model by adding a damping term. It can be shown that the proposed model can recover both a ResNet and a CNN by adjusting an interpolation coefficient. Therefore, the damped ODE model provides a unified framework for the interpretation of residual and non-residual networks. The Lyapunov analysis reveals better stability of the proposed model, and thus yields robustness improvement of the learned networks. Experiments on a number of image classification benchmarks show that the proposed model substantially improves the accuracy of ResNet and ResNeXt over the perturbed inputs from both stochastic noise and adversarial attack methods. Moreover, the loss landscape analysis demonstrates the improved robustness of our method along the attack direction.
Correcting Data Imbalance for Semi-Supervised Covid-19 Detection Using X-ray Chest Images
Aug 20, 2020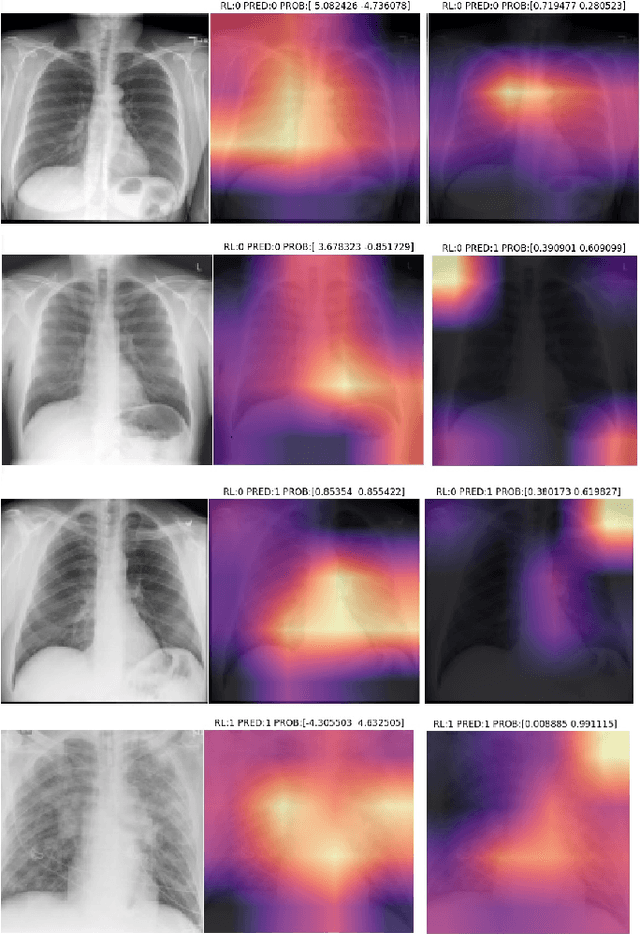
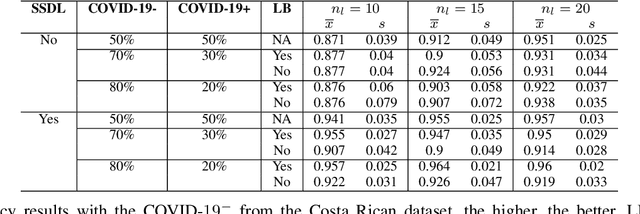
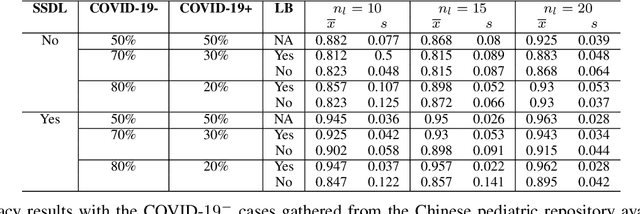
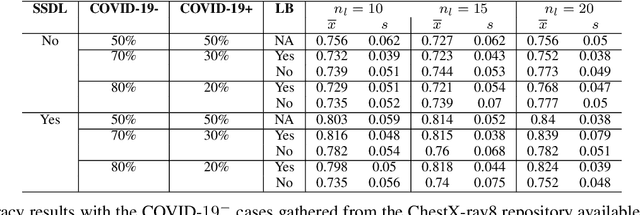
The Corona Virus (COVID-19) is an internationalpandemic that has quickly propagated throughout the world. The application of deep learning for image classification of chest X-ray images of Covid-19 patients, could become a novel pre-diagnostic detection methodology. However, deep learning architectures require large labelled datasets. This is often a limitation when the subject of research is relatively new as in the case of the virus outbreak, where dealing with small labelled datasets is a challenge. Moreover, in the context of a new highly infectious disease, the datasets are also highly imbalanced,with few observations from positive cases of the new disease. In this work we evaluate the performance of the semi-supervised deep learning architecture known as MixMatch using a very limited number of labelled observations and highly imbalanced labelled dataset. We propose a simple approach for correcting data imbalance, re-weight each observationin the loss function, giving a higher weight to the observationscorresponding to the under-represented class. For unlabelled observations, we propose the usage of the pseudo and augmentedlabels calculated by MixMatch to choose the appropriate weight. The MixMatch method combined with the proposed pseudo-label based balance correction improved classification accuracy by up to 10%, with respect to the non balanced MixMatch algorithm, with statistical significance. We tested our proposed approach with several available datasets using 10, 15 and 20 labelledobservations. Additionally, a new dataset is included among thetested datasets, composed of chest X-ray images of Costa Rican adult patients
Fast Low-rank Representation based Spatial Pyramid Matching for Image Classification
Oct 02, 2015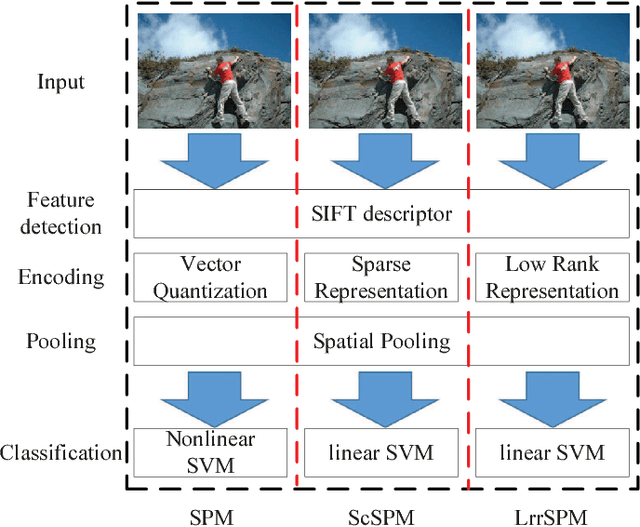

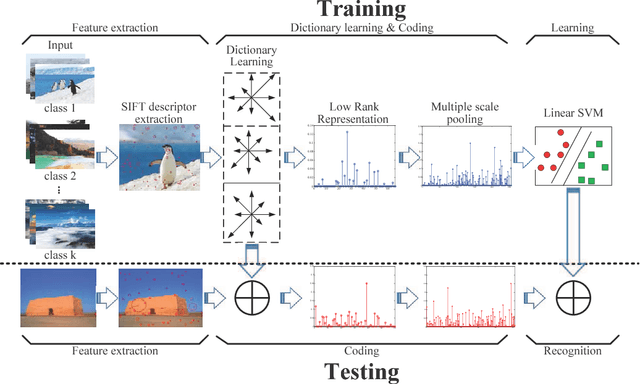
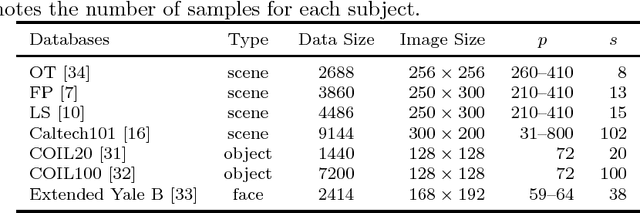
Spatial Pyramid Matching (SPM) and its variants have achieved a lot of success in image classification. The main difference among them is their encoding schemes. For example, ScSPM incorporates Sparse Code (SC) instead of Vector Quantization (VQ) into the framework of SPM. Although the methods achieve a higher recognition rate than the traditional SPM, they consume more time to encode the local descriptors extracted from the image. In this paper, we propose using Low Rank Representation (LRR) to encode the descriptors under the framework of SPM. Different from SC, LRR considers the group effect among data points instead of sparsity. Benefiting from this property, the proposed method (i.e., LrrSPM) can offer a better performance. To further improve the generalizability and robustness, we reformulate the rank-minimization problem as a truncated projection problem. Extensive experimental studies show that LrrSPM is more efficient than its counterparts (e.g., ScSPM) while achieving competitive recognition rates on nine image data sets.
* accepted into knowledge based systems, 2015
Randomly Weighted, Untrained Neural Tensor Networks Achieve Greater Relational Expressiveness
Jun 01, 2020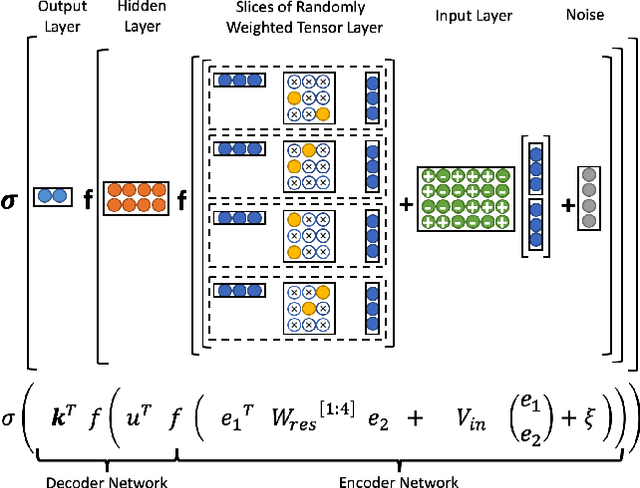
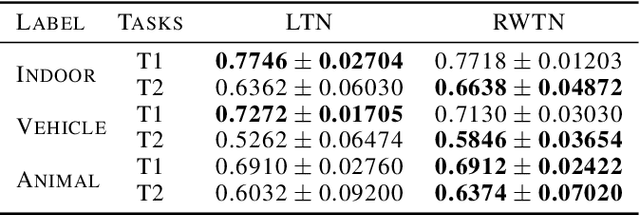
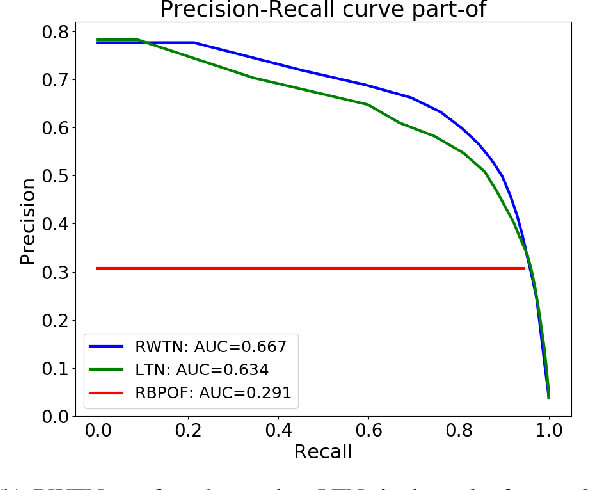
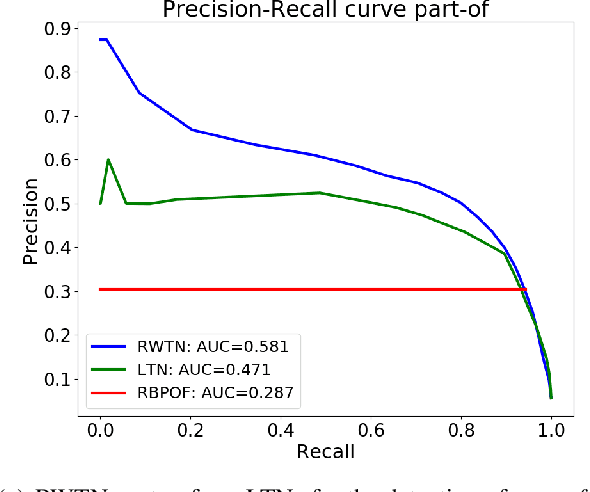
Neural Tensor Networks (NTNs), which are structured to encode the degree of relationship among pairs of entities, are used in Logic Tensor Networks (LTNs) to facilitate Statistical Relational Learning (SRL) in first-order logic. In this paper, we propose Randomly Weighted Tensor Networks (RWTNs), which incorporate randomly drawn, untrained tensors into an NTN encoder network with a trained decoder network. We show that RWTNs meet or surpass the performance of traditionally trained LTNs for Semantic Image Interpretation (SII) tasks that have been used as a representative example of how LTNs utilize reasoning over first-order logic to exceed the performance of solely data-driven methods. We demonstrate that RWTNs outperform LTNs for the detection of the relevant part-of relations between objects, and we show that RWTNs can achieve similar performance as LTNs for object classification while using fewer parameters for learning.
Interferometric Graph Transform: a Deep Unsupervised Graph Representation
Jun 10, 2020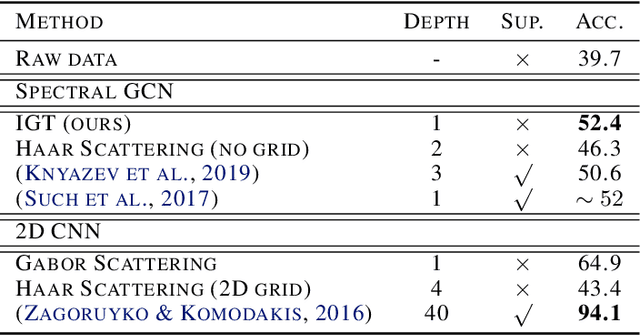

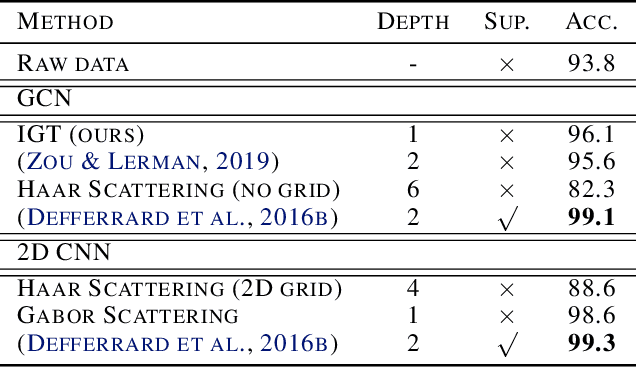
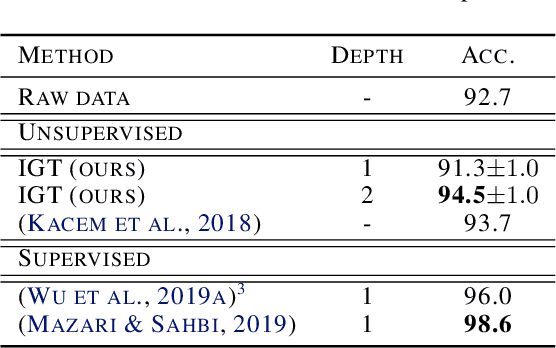
We propose the Interferometric Graph Transform (IGT), which is a new class of deep unsupervised graph convolutional neural network for building graph representations. Our first contribution is to propose a generic, complex-valued spectral graph architecture obtained from a generalization of the Euclidean Fourier transform. We show that our learned representation consists of both discriminative and invariant features, thanks to a novel greedy concave objective. From our experiments, we conclude that our learning procedure exploits the topology of the spectral domain, which is normally a flaw of spectral methods, and in particular our method can recover an analytic operator for vision tasks. We test our algorithm on various and challenging tasks such as image classification (MNIST, CIFAR-10), community detection (Authorship, Facebook graph) and action recognition from 3D skeletons videos (SBU, NTU), exhibiting a new state-of-the-art in spectral graph unsupervised settings.
Sparse Coding Approach for Multi-Frame Image Super Resolution
Feb 17, 2014
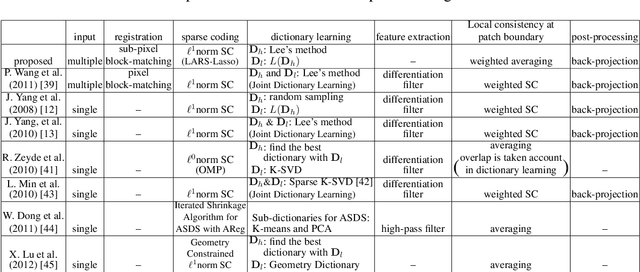
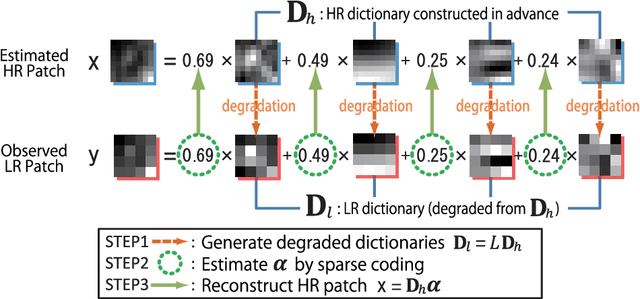
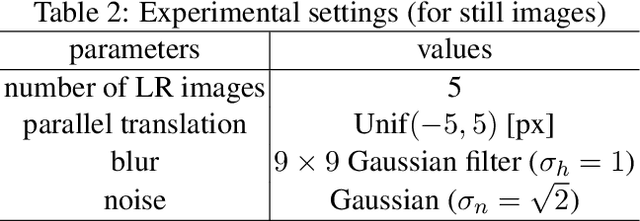
An image super-resolution method from multiple observation of low-resolution images is proposed. The method is based on sub-pixel accuracy block matching for estimating relative displacements of observed images, and sparse signal representation for estimating the corresponding high-resolution image. Relative displacements of small patches of observed low-resolution images are accurately estimated by a computationally efficient block matching method. Since the estimated displacements are also regarded as a warping component of image degradation process, the matching results are directly utilized to generate low-resolution dictionary for sparse image representation. The matching scores of the block matching are used to select a subset of low-resolution patches for reconstructing a high-resolution patch, that is, an adaptive selection of informative low-resolution images is realized. When there is only one low-resolution image, the proposed method works as a single-frame super-resolution method. The proposed method is shown to perform comparable or superior to conventional single- and multi-frame super-resolution methods through experiments using various real-world datasets.
Scalable Change Retrieval Using Deep 3D Neural Codes
Apr 07, 2019
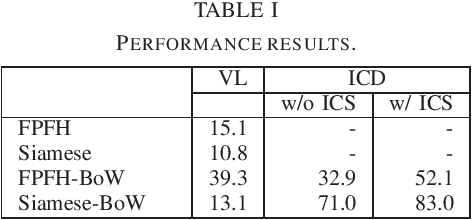
We present a novel scalable framework for image change detection (ICD) from an on-board 3D imagery system. We argue that existing ICD systems are constrained by the time required to align a given query image with individual reference image coordinates. We utilize an invariant coordinate system (ICS) to replace the time-consuming image alignment with an offline pre-processing procedure. Our key contribution is an extension of the traditional image comparison-based ICD tasks to setups of the image retrieval (IR) task. We replace each component of the 3D ICD system, i.e., (1) image modeling, (2) image alignment, and (3) image differencing, with significantly efficient variants from the bag-of-words (BoW) IR paradigm. Further, we train a deep 3D feature extractor in an unsupervised manner using an unsupervised Siamese network and automatically collected training data. We conducted experiments on a challenging cross-season ICD task using a publicly available dataset and thereby validate the efficacy of the proposed approach.
Transfer Learning for Brain Tumor Segmentation
Dec 28, 2019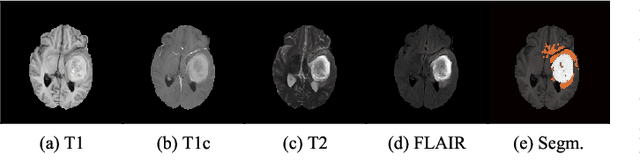
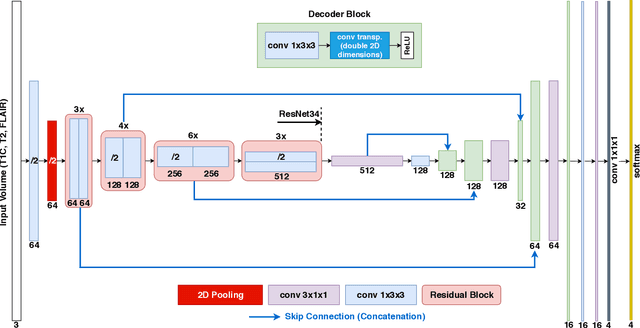
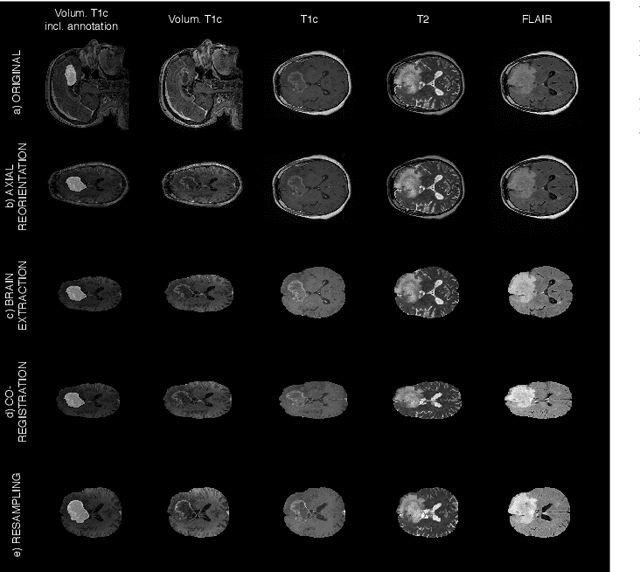
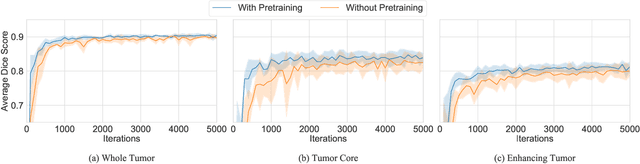
Gliomas are the most common malignant brain tumors that are treated with chemoradiotherapy and surgery. Magnetic Resonance Imaging (MRI) is used by radiotherapists to manually segment brain lesions and to observe their development throughout the therapy. The manual image segmentation process is time-consuming and results tend to vary among different human raters. Therefore, there is a substantial demand for automatic image segmentation algorithms that produce a reliable and accurate segmentation of various brain tissue types. Recent advances in deep learning have led to convolutional neural network architectures that excel at various visual recognition tasks. They have been successfully applied to the medical context including medical image segmentation. In particular, fully convolutional networks (FCNs) such as the U-Net produce state-of-the-art results in the automatic segmentation of brain tumors. MRI brain scans are volumetric and exist in various co-registered modalities that serve as input channels for these FCN architectures. Training algorithms for brain tumor segmentation on this complex input requires large amounts of computational resources and is prone to overfitting. In this work, we construct FCNs with pretrained convolutional encoders. We show that we can stabilize the training process this way and produce more robust predictions. We evaluate our methods on publicly available data as well as on a privately acquired clinical dataset. We also show that the impact of pretraining is even higher for predictions on the clinical data.