 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Artificial Intelligence in the Battle against Coronavirus (COVID-19): A Survey and Future Research Directions
Jul 30, 2020
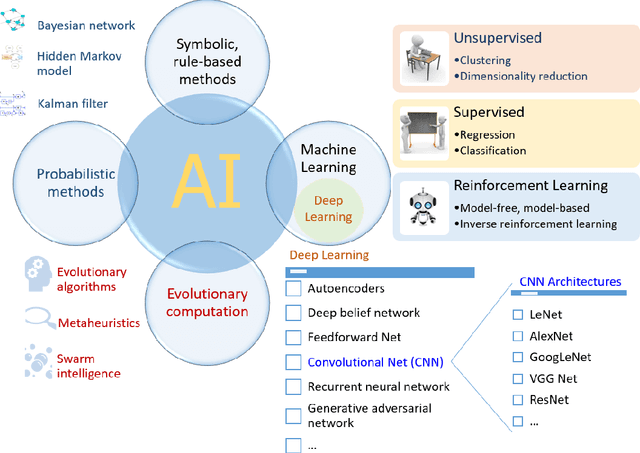
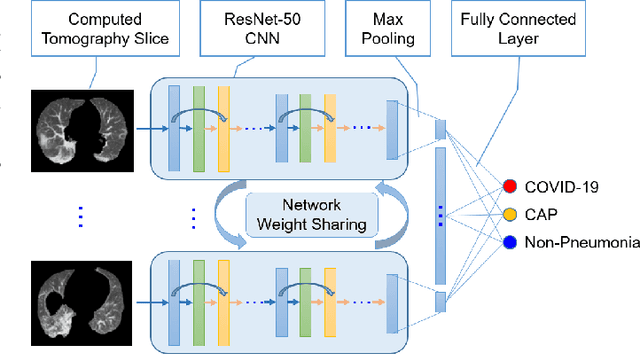
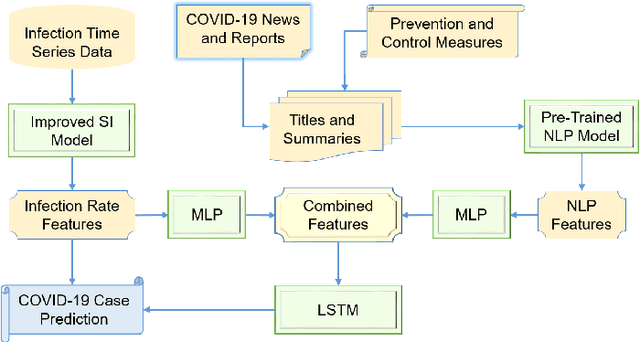
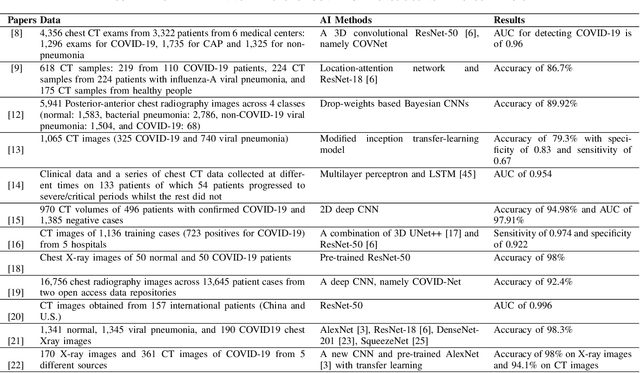
Artificial intelligence (AI) has been applied widely in our daily lives in a variety of ways with numerous successful stories. AI has also contributed to dealing with the coronavirus disease (COVID-19) pandemic, which has been happening around the globe. This paper presents a survey of AI methods being used in various applications in the fight against the COVID-19 outbreak and outlines the crucial roles of AI research in this unprecedented battle. We touch on a number of areas where AI plays as an essential component, from medical image processing, data analytics, text mining and natural language processing, the Internet of Things, to computational biology and medicine. A summary of COVID-19 related data sources that are available for research purposes is also presented. Research directions on exploring the potentials of AI and enhancing its capabilities and power in the battle are thoroughly discussed. We highlight 13 groups of problems related to the COVID-19 pandemic and point out promising AI methods and tools that can be used to solve those problems. It is envisaged that this study will provide AI researchers and the wider community an overview of the current status of AI applications and motivate researchers in harnessing AI potentials in the fight against COVID-19.
Deep Context-Aware Kernel Networks
Dec 29, 2019
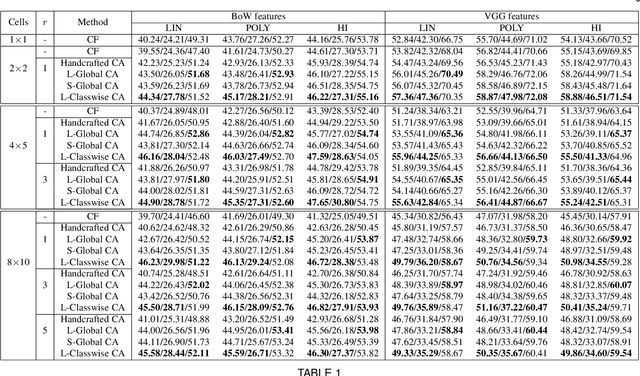
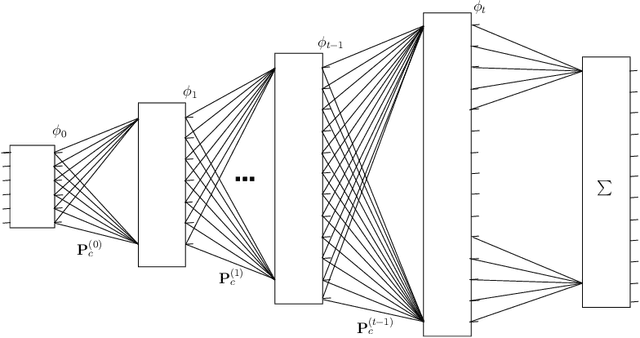
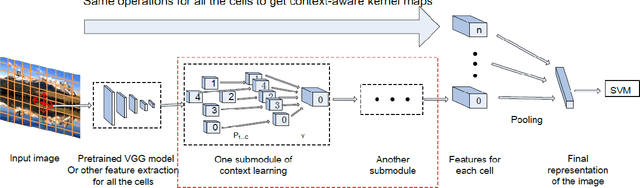
Context plays a crucial role in visual recognition as it provides complementary clues for different learning tasks including image classification and annotation. As the performances of these tasks are currently reaching a plateau, any extra knowledge, including context, should be leveraged in order to seek significant leaps in these performances. In the particular scenario of kernel machines, context-aware kernel design aims at learning positive semi-definite similarity functions which return high values not only when data share similar contents, but also similar structures (a.k.a contexts). However, the use of context in kernel design has not been fully explored; indeed, context in these solutions is handcrafted instead of being learned. In this paper, we introduce a novel deep network architecture that learns context in kernel design. This architecture is fully determined by the solution of an objective function mixing a content term that captures the intrinsic similarity between data, a context criterion which models their structure and a regularization term that helps designing smooth kernel network representations. The solution of this objective function defines a particular deep network architecture whose parameters correspond to different variants of learned contexts including layerwise, stationary and classwise; larger values of these parameters correspond to the most influencing contextual relationships between data. Extensive experiments conducted on the challenging ImageCLEF Photo Annotation and Corel5k benchmarks show that our deep context networks are highly effective for image classification and the learned contexts further enhance the performance of image annotation.
Transfer Learning of Photometric Phenotypes in Agriculture Using Metadata
Apr 01, 2020

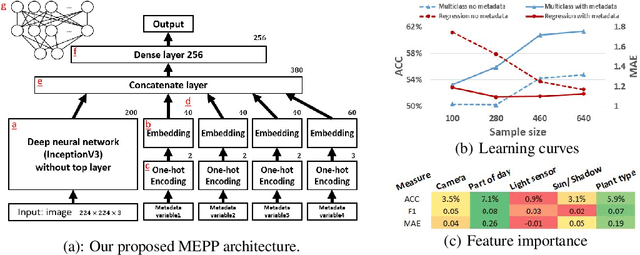
Estimation of photometric plant phenotypes (e.g., hue, shine, chroma) in field conditions is important for decisions on the expected yield quality, fruit ripeness, and need for further breeding. Estimating these from images is difficult due to large variances in lighting conditions, shadows, and sensor properties. We combine the image and metadata regarding capturing conditions embedded into a network, enabling more accurate estimation and transfer between different conditions. Compared to a state-of-the-art deep CNN and a human expert, metadata embedding improves the estimation of the tomato's hue and chroma.
Auto-pooling: Learning to Improve Invariance of Image Features from Image Sequences
Mar 18, 2013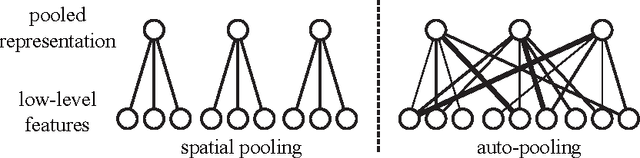
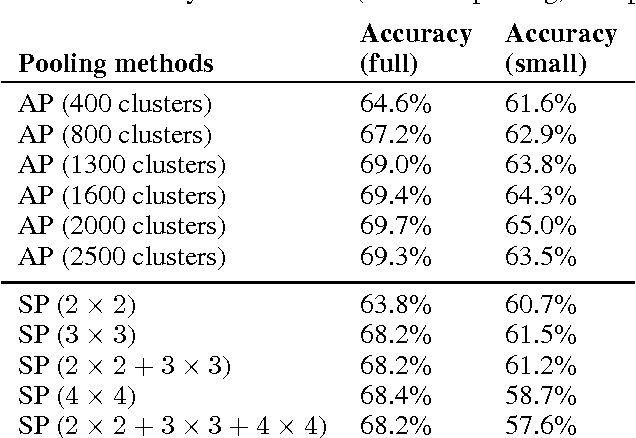
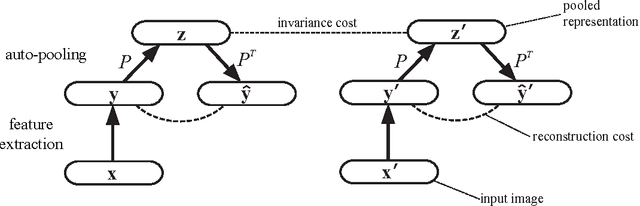
Learning invariant representations from images is one of the hardest challenges facing computer vision. Spatial pooling is widely used to create invariance to spatial shifting, but it is restricted to convolutional models. In this paper, we propose a novel pooling method that can learn soft clustering of features from image sequences. It is trained to improve the temporal coherence of features, while keeping the information loss at minimum. Our method does not use spatial information, so it can be used with non-convolutional models too. Experiments on images extracted from natural videos showed that our method can cluster similar features together. When trained by convolutional features, auto-pooling outperformed traditional spatial pooling on an image classification task, even though it does not use the spatial topology of features.
GANDALF: Generative Adversarial Networks with Discriminator-Adaptive Loss Fine-tuning for Alzheimer's Disease Diagnosis from MRI
Aug 10, 2020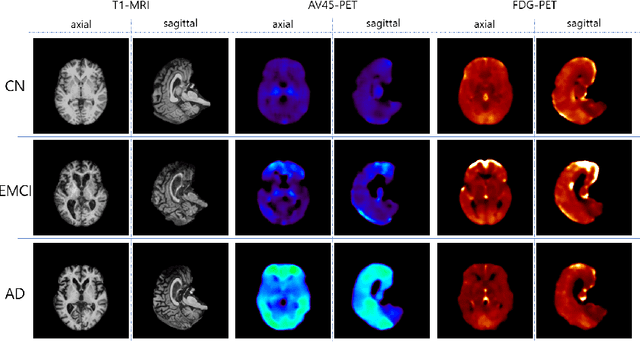
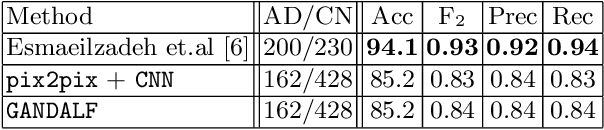
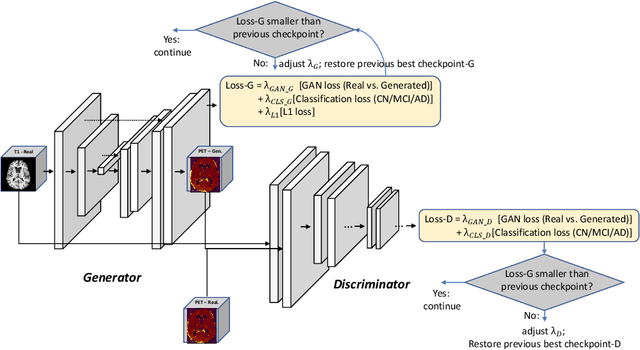
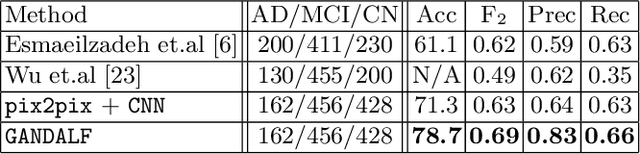
Positron Emission Tomography (PET) is now regarded as the gold standard for the diagnosis of Alzheimer's Disease (AD). However, PET imaging can be prohibitive in terms of cost and planning, and is also among the imaging techniques with the highest dosage of radiation. Magnetic Resonance Imaging (MRI), in contrast, is more widely available and provides more flexibility when setting the desired image resolution. Unfortunately, the diagnosis of AD using MRI is difficult due to the very subtle physiological differences between healthy and AD subjects visible on MRI. As a result, many attempts have been made to synthesize PET images from MR images using generative adversarial networks (GANs) in the interest of enabling the diagnosis of AD from MR. Existing work on PET synthesis from MRI has largely focused on Conditional GANs, where MR images are used to generate PET images and subsequently used for AD diagnosis. There is no end-to-end training goal. This paper proposes an alternative approach to the aforementioned, where AD diagnosis is incorporated in the GAN training objective to achieve the best AD classification performance. Different GAN lossesare fine-tuned based on the discriminator performance, and the overall training is stabilized. The proposed network architecture and training regime show state-of-the-art performance for three- and four- class AD classification tasks.
From Multiview Image Curves to 3D Drawings
Sep 18, 2016

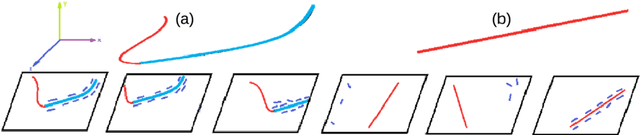
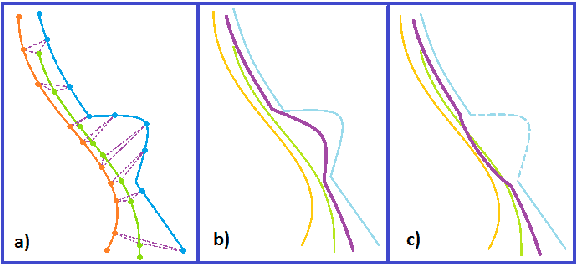
Reconstructing 3D scenes from multiple views has made impressive strides in recent years, chiefly by correlating isolated feature points, intensity patterns, or curvilinear structures. In the general setting - without controlled acquisition, abundant texture, curves and surfaces following specific models or limiting scene complexity - most methods produce unorganized point clouds, meshes, or voxel representations, with some exceptions producing unorganized clouds of 3D curve fragments. Ideally, many applications require structured representations of curves, surfaces and their spatial relationships. This paper presents a step in this direction by formulating an approach that combines 2D image curves into a collection of 3D curves, with topological connectivity between them represented as a 3D graph. This results in a 3D drawing, which is complementary to surface representations in the same sense as a 3D scaffold complements a tent taut over it. We evaluate our results against truth on synthetic and real datasets.
* Expanded ECCV 2016 version with tweaked figures and including an overview of the supplementary material available at multiview-3d-drawing.sourceforge.net
System to Integrate Fairness Transparently: An Industry Approach
Jun 10, 2020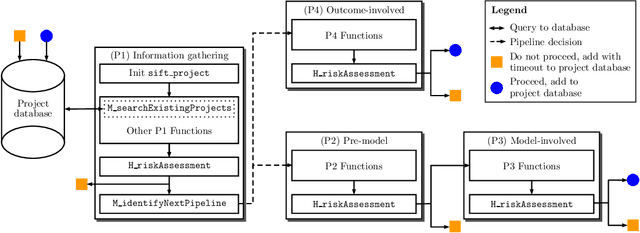
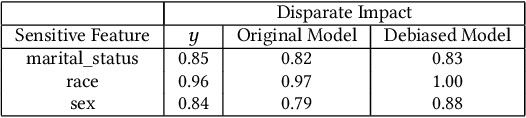
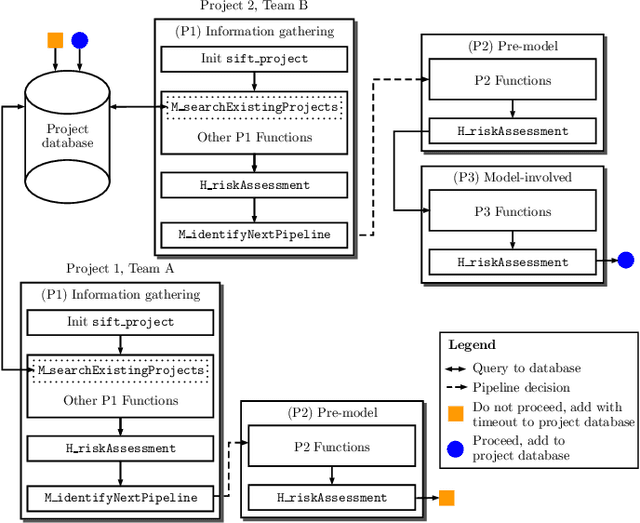
There have been significant research efforts to address the issue of unintentional bias in Machine Learning (ML). Many well-known companies have dealt with the fallout after the deployment of their products due to this issue. In an industrial context, enterprises have large-scale ML solutions for a broad class of use cases deployed for different swaths of customers. Trading off the cost of detecting and mitigating bias across this landscape over the lifetime of each use case against the risk of impact to the brand image is a key consideration. We propose a framework for industrial uses that addresses their methodological and mechanization needs. Our approach benefits from prior experience handling security and privacy concerns as well as past internal ML projects. Through significant reuse of bias handling ability at every stage in the ML development lifecycle to guide users we can lower overall costs of reducing bias.
Joint Training of Variational Auto-Encoder and Latent Energy-Based Model
Jun 10, 2020

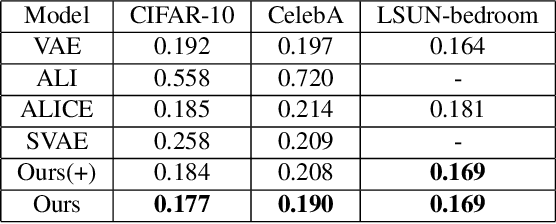

This paper proposes a joint training method to learn both the variational auto-encoder (VAE) and the latent energy-based model (EBM). The joint training of VAE and latent EBM are based on an objective function that consists of three Kullback-Leibler divergences between three joint distributions on the latent vector and the image, and the objective function is of an elegant symmetric and anti-symmetric form of divergence triangle that seamlessly integrates variational and adversarial learning. In this joint training scheme, the latent EBM serves as a critic of the generator model, while the generator model and the inference model in VAE serve as the approximate synthesis sampler and inference sampler of the latent EBM. Our experiments show that the joint training greatly improves the synthesis quality of the VAE. It also enables learning of an energy function that is capable of detecting out of sample examples for anomaly detection.
TopoAL: An Adversarial Learning Approach for Topology-Aware Road Segmentation
Jul 17, 2020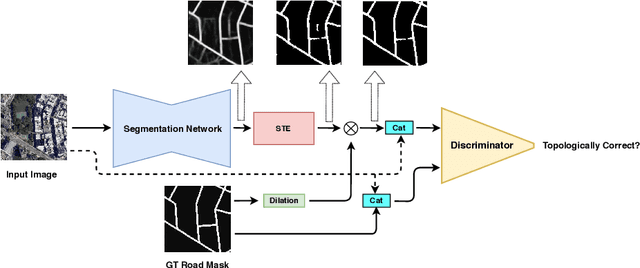
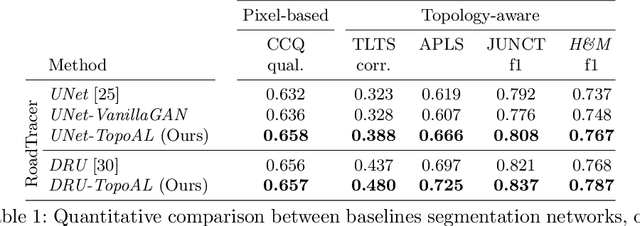

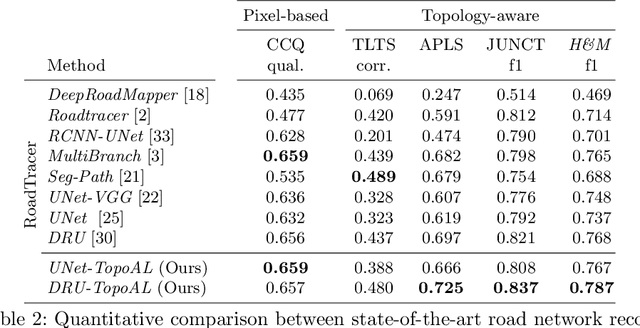
Most state-of-the-art approaches to road extraction from aerial images rely on a CNN trained to label road pixels as foreground and remainder of the image as background. The CNN is usually trained by minimizing pixel-wise losses, which is less than ideal to produce binary masks that preserve the road network's global connectivity. To address this issue, we introduce an Adversarial Learning (AL) strategy tailored for our purposes. A naive one would treat the segmentation network as a generator and would feed its output along with ground-truth segmentations to a discriminator. It would then train the generator and discriminator jointly. We will show that this is not enough because it does not capture the fact that most errors are local and need to be treated as such. Instead, we use a more sophisticated discriminator that returns a label pyramid describing what portions of the road network are correct at several different scales. This discriminator and the structured labels it returns are what gives our approach its edge and we will show that it outperforms state-of-the-art ones on the challenging RoadTracer dataset.
Attributed Relational SIFT-based Regions Graph (ARSRG): concepts and applications
Dec 20, 2019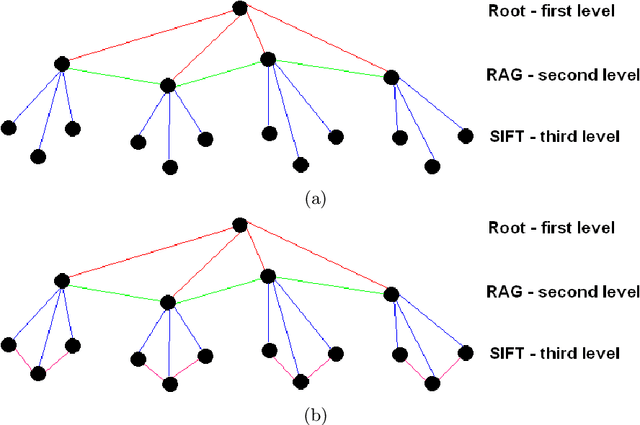
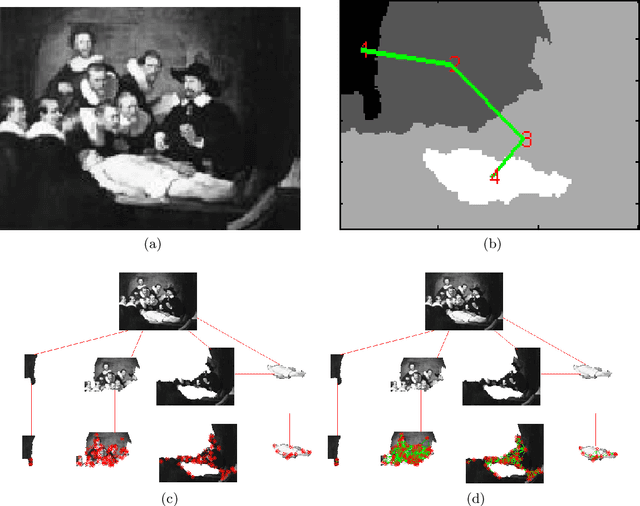


Graphs are widely adopted tools for encoding information. Generally, they are applied to disparate research fields where data needs to be represented in terms of local and spatial connections. In this context, a structure for ditigal image representation, called Attributed Relational SIFT-based Regions Graph (ARSRG), previously introduced, is presented. ARSRG has not been explored in detail in previous works and for this reason the goal is to investigate unknown aspects. The study is divided into two parts. A first, theoretical, introducing formal definitions, not yet specified previously, with purpose to clarify its structural configuration. A second, experimental, which provides fundamental elements about its adaptability and flexibility regarding different applications. The theoretical vision combined with the experimental one shows how the structure is adaptable to image representation including contents of different nature.