 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Emergent Language Symbolic Semantic Segmentation and Model Interpretability
Jul 18, 2020
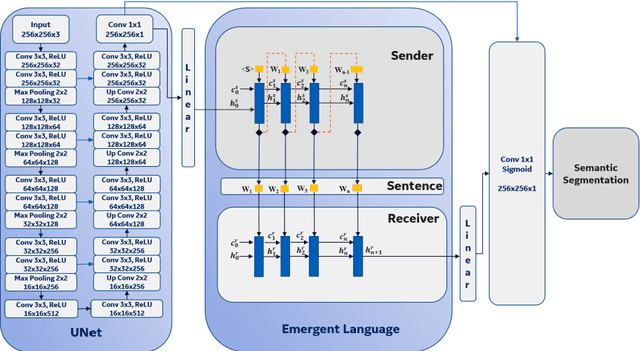
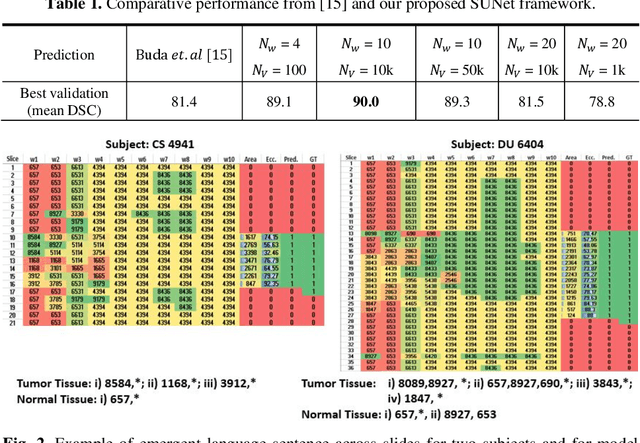
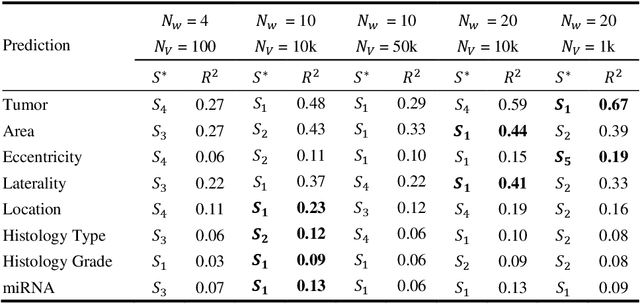
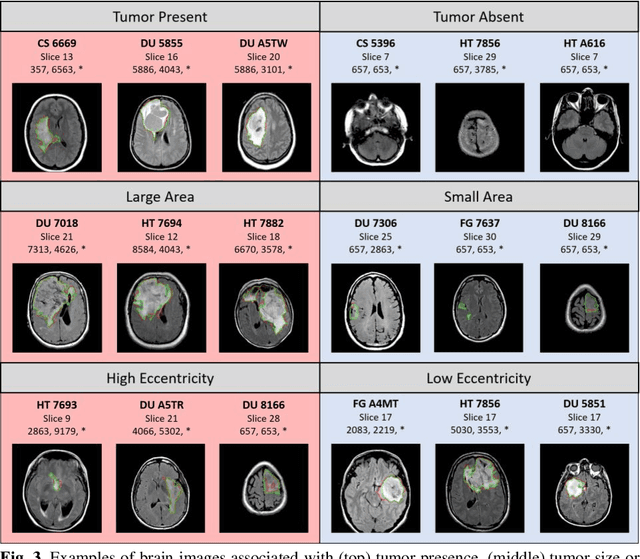
Recent advances in methods focused on the grounding problem have resulted in techniques that can be used to construct a symbolic language associated with a specific domain. Inspired by how humans communicate complex ideas through language, we developed a generalized Symbolic Semantic ($\text{S}^2$) framework for interpretable segmentation. Unlike adversarial models (e.g., GANs), we explicitly model cooperation between two agents, a Sender and a Receiver, that must cooperate to achieve a common goal. The Sender receives information from a high layer of a segmentation network and generates a symbolic sentence derived from a categorical distribution. The Receiver obtains the symbolic sentences and co-generates the segmentation mask. In order for the model to converge, the Sender and Receiver must learn to communicate using a private language. We apply our architecture to segment tumors in the TCGA dataset. A UNet-like architecture is used to generate input to the Sender network which produces a symbolic sentence, and a Receiver network co-generates the segmentation mask based on the sentence. Our Segmentation framework achieved similar or better performance compared with state-of-the-art segmentation methods. In addition, our results suggest direct interpretation of the symbolic sentences to discriminate between normal and tumor tissue, tumor morphology, and other image characteristics.
Image Denoising Using Low Rank Minimization With Modified Noise Estimation
Apr 24, 2015
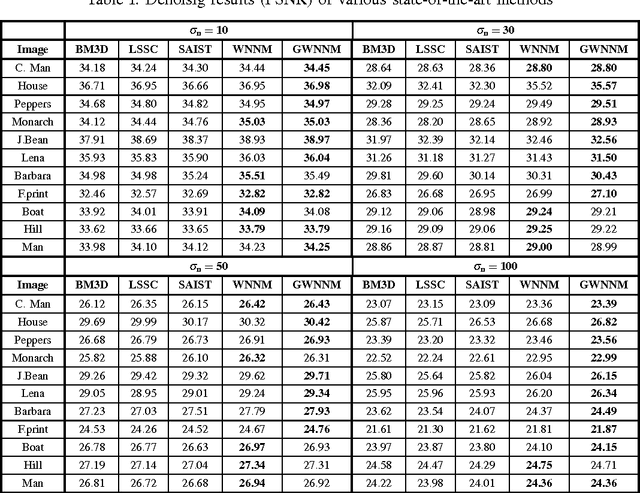
Recently, the application of low rank minimization to image denoising has shown remarkable denoising results which are equivalent or better than those of the existing state-of-the-art algorithms. However, due to iterative nature of low rank optimization, estimation of residual noise is an essential requirement after each iteration. Currently, this noise is estimated by using the filtered noise in the previous iteration without considering the geometric structure of the given image. This estimate may be affected in the presence of moderate and severe levels of noise. To obtain a more reliable estimate of residual noise, we propose a modified algorithm (GWNNM) which includes the contribution of the geometric structure of an image to the existing noise estimation. Furthermore, the proposed algorithm exploits the difference of large and small singular values to enhance the edges and textures during the denoising process. Consequently, the proposed modifications achieve significant improvements in the denoising results of the existing low rank optimization algorithms.
WHENet: Real-time Fine-Grained Estimation for Wide Range Head Pose
May 20, 2020
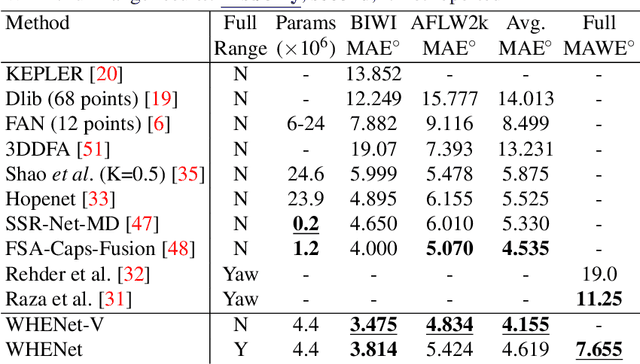
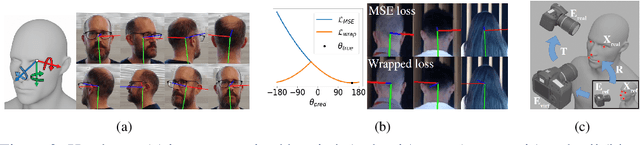
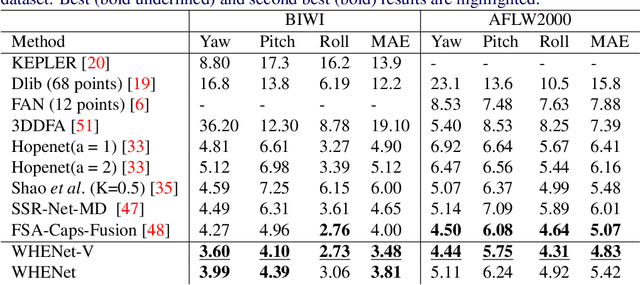
We present an end-to-end head-pose estimation network designed to predict Euler angles through the full range head yaws from a single RGB image. Existing methods perform well for frontal views but few target head pose from all viewpoints. This has applications in autonomous driving and retail. Our network builds on multi-loss approaches with changes to loss functions and training strategies adapted to wide range estimation. Additionally, we extract ground truth labelings of anterior views from a current panoptic dataset for the first time. The resulting Wide Headpose Estimation Network (WHENet) is the first fine-grained modern method applicable to the full-range of head yaws (hence wide) yet also meets or beats state-of-the-art methods for frontal head pose estimation. Our network is compact and efficient for mobile devices and applications.
Turbulence Enrichment using Generative Adversarial Networks
Mar 04, 2020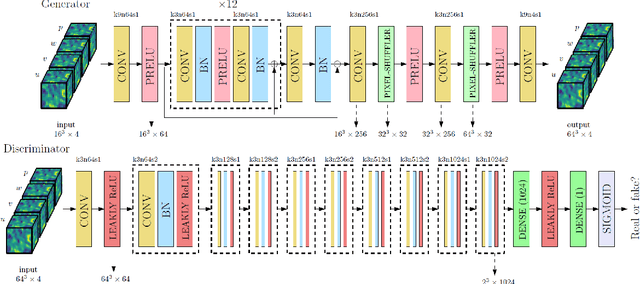
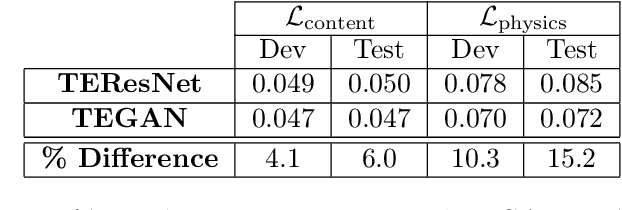
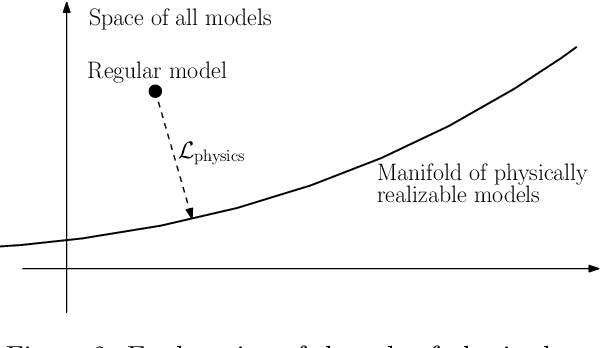
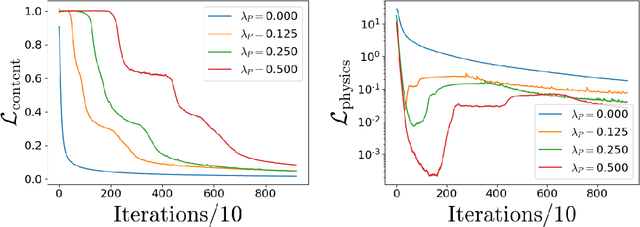
Generative Adversarial Networks (GANs) have been widely used for generating photo-realistic images. A variant of GANs called super-resolution GAN (SRGAN) has already been used successfully for image super-resolution where low resolution images can be upsampled to a $4\times$ larger image that is perceptually more realistic. However, when such generative models are used for data describing physical processes, there are additional known constraints that models must satisfy including governing equations and boundary conditions. In general, these constraints may not be obeyed by the generated data. In this work, we develop physics-based methods for generative enrichment of turbulence. We incorporate a physics-informed learning approach by a modification to the loss function to minimize the residuals of the governing equations for the generated data. We have analyzed two trained physics-informed models: a supervised model based on convolutional neural networks (CNN) and a generative model based on SRGAN: Turbulence Enrichment GAN (TEGAN), and show that they both outperform simple bicubic interpolation in turbulence enrichment. We have also shown that using the physics-informed learning can also significantly improve the model's ability in generating data that satisfies the physical governing equations. Finally, we compare the enriched data from TEGAN to show that it is able to recover statistical metrics of the flow field including energy metrics and well as inter-scale energy dynamics and flow morphology.
Deep convolutional tensor network
May 29, 2020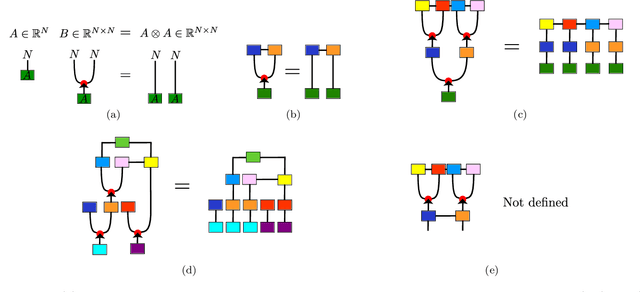

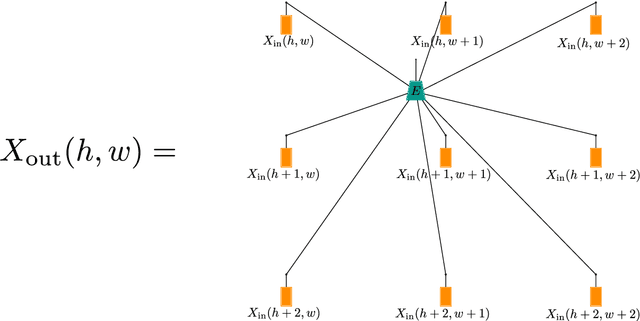
Tensor networks are linear algebraic representations of quantum many-body states based on their entanglement structure. People are exploring their applications to machine learning. Deep convolutional neural networks achieve state of the art results in computer vision and other areas. Supposedly this happens because of parameter sharing, locality, and deepness. We devise a novel tensor network based model called Deep convolutional tensor network (DCTN) for image classification, which has parameter sharing, locality, and deepness. It is based on the Entangled plaquette states (EPS) tensor network. We show how Entangled plaquette states can be implemented as a backpropagatable layer which can be used in neural networks. We test our model on FashionMNIST dataset and find that deepness increases overfitting and decreases test accuracy. Also, we find that the shallow version performs well considering its low parameter count. We discuss how hyperparameters of DCTN affect its training and overfitting.
DeepHAZMAT: Hazardous Materials Sign Detection and Segmentation with Restricted Computational Resources
Jul 18, 2020



One of the most challenging and non-trivial tasks in robot-based rescue operations is the Hazardous Materials or HAZMATs sign detection in the operation field, to prevent further unexpected disasters. Each Hazmat sign has a specific meaning that the rescue robot should detect and interpret it to take a safe action, accordingly. Accurate Hazmat detection and real-time processing are the two most important factors in such robotics applications. Furthermore, we also have to cope with some secondary challenges such as image distortion and restricted CPU and computational resources which are embedded in a rescue robot. In this paper, we propose a CNN-Based pipeline called DeepHAZMAT for detecting and segmenting Hazmats in four steps; 1) optimising the number of input images that are fed into the CNN network, 2) using the YOLOv3-tiny structure to collect the required visual information from the hazardous areas, 3) Hazmat sign segmentation and separation from the background using GrabCut technique, and 4) post-processing the result with morphological operators and convex hull algorithm. In spite of the utilisation of a very limited memory and CPU resources, the experimental results show the proposed method has successfully maintained a better performance in terms of detection-speed and detection-accuracy, compared with the state-of-the-art methods.
Contextual-Relation Consistent Domain Adaptation for Semantic Segmentation
Jul 05, 2020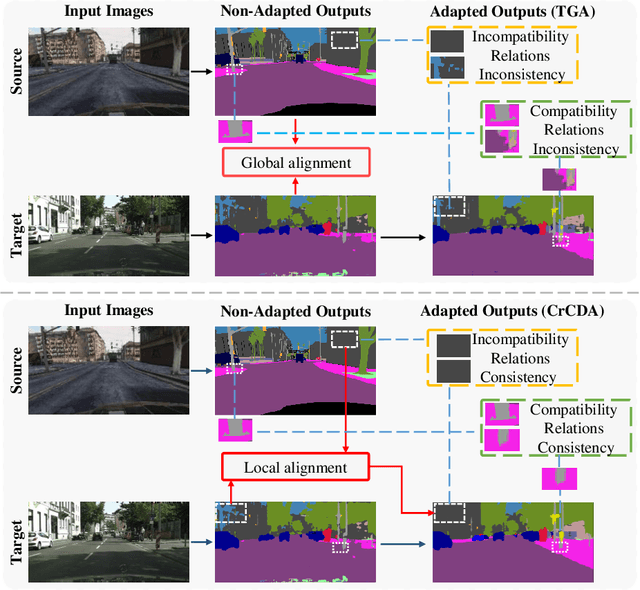
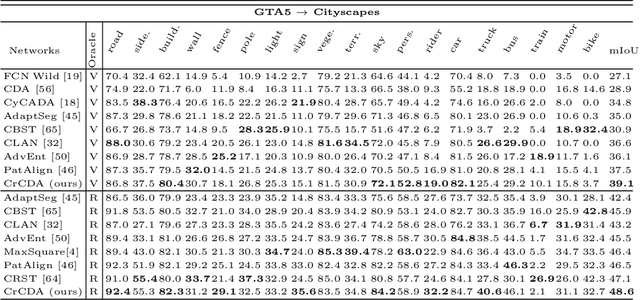
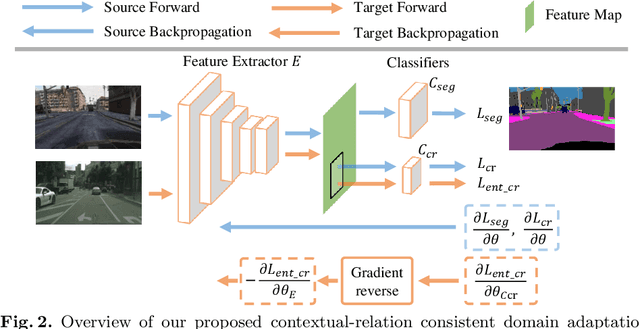
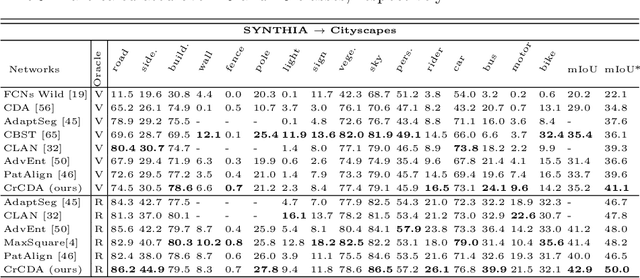
Recent advances in unsupervised domain adaptation for semantic segmentation have shown great potentials to relieve the demand of expensive per-pixel annotations. However, most existing works address the domain discrepancy by aligning the data distributions of two domains at a global image level whereas the local consistencies are largely neglected. This paper presents an innovative local contextual-relation consistent domain adaptation (CrCDA) technique that aims to achieve local-level consistencies during the global-level alignment. The idea is to take a closer look at region-wise feature representations and align them for local-level consistencies. Specifically, CrCDA learns and enforces the prototypical local contextual-relations explicitly in the feature space of a labelled source domain while transferring them to an unlabelled target domain via backpropagation-based adversarial learning. An adaptive entropy max-min adversarial learning scheme is designed to optimally align these hundreds of local contextual-relations across domain without requiring discriminator or extra computation overhead. The proposed CrCDA has been evaluated extensively over two challenging domain adaptive segmentation tasks (e.g., GTA5 to Cityscapes and SYNTHIA to Cityscapes), and experiments demonstrate its superior segmentation performance as compared with state-of-the-art methods.
Adaptive Learning Rates with Maximum Variation Averaging
Jun 21, 2020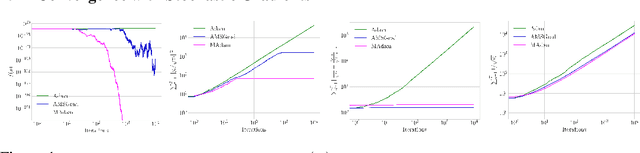

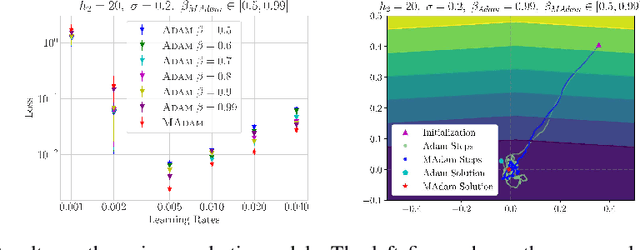

Adaptive gradient methods such as RMSProp and Adam use exponential moving estimate of the squared gradient to compute element-wise adaptive step sizes and handle noisy gradients. However, Adam can have undesirable convergence behavior in some problems due to unstable or extreme adaptive learning rates. Methods such as AMSGrad and AdaBound have been proposed to stabilize the adaptive learning rates of Adam in the later stage of training, but they do not outperform Adam in some practical tasks such as training Transformers. In this paper, we propose an adaptive learning rate rule in which the running mean squared gradient is replaced by a weighted mean, with weights chosen to maximize the estimated variance of each coordinate. This gives a worst-case estimate for the local gradient variance, taking smaller steps when large curvatures or noisy gradients are present, resulting in more desirable convergence behavior than Adam. We analyze and demonstrate the improved efficacy of our adaptive averaging approach on image classification, neural machine translation and natural language understanding tasks.
Weakly Supervised Lesion Localization With Probabilistic-CAM Pooling
May 29, 2020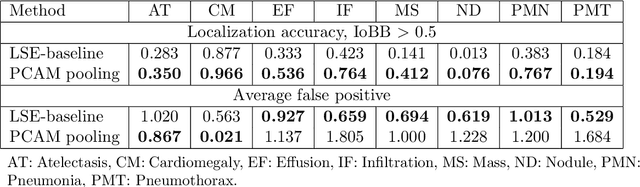
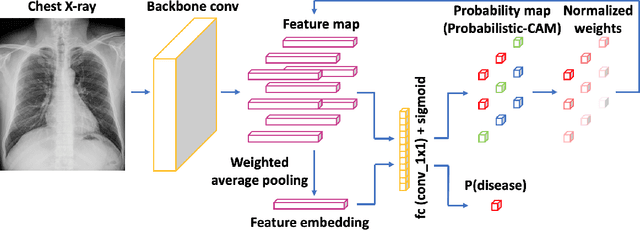
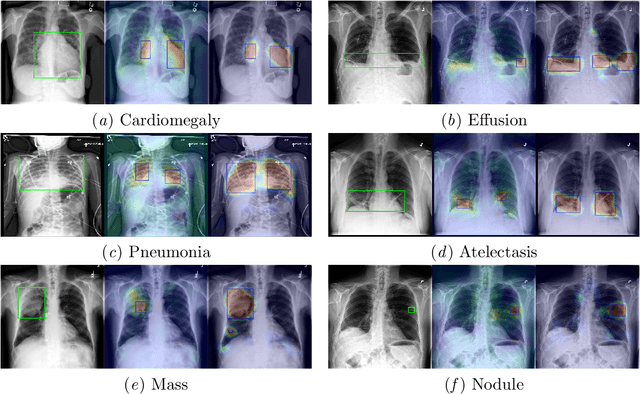
Localizing thoracic diseases on chest X-ray plays a critical role in clinical practices such as diagnosis and treatment planning. However, current deep learning based approaches often require strong supervision, e.g. annotated bounding boxes, for training such systems, which is infeasible to harvest in large-scale. We present Probabilistic Class Activation Map (PCAM) pooling, a novel global pooling operation for lesion localization with only image-level supervision. PCAM pooling explicitly leverages the excellent localization ability of CAM during training in a probabilistic fashion. Experiments on the ChestX-ray14 dataset show a ResNet-34 model trained with PCAM pooling outperforms state-of-the-art baselines on both the classification task and the localization task. Visual examination on the probability maps generated by PCAM pooling shows clear and sharp boundaries around lesion regions compared to the localization heatmaps generated by CAM. PCAM pooling is open sourced at https://github.com/jfhealthcare/Chexpert.
Improving Sample Efficiency in Model-Free Reinforcement Learning from Images
Oct 02, 2019
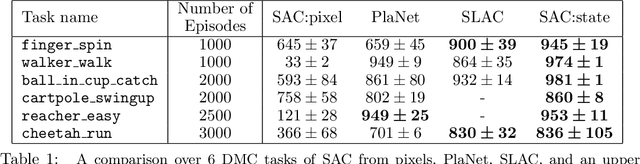
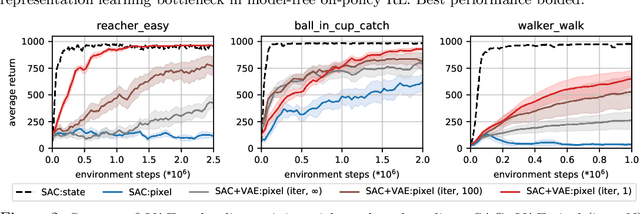
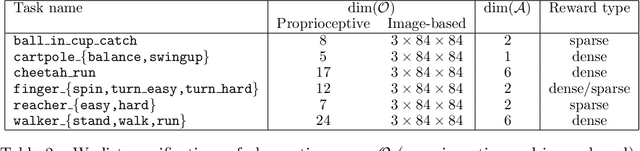
Training an agent to solve control tasks directly from high-dimensional images with model-free reinforcement learning (RL) has proven difficult. The agent needs to learn a latent representation together with a control policy to perform the task. Fitting a high-capacity encoder using a scarce reward signal is not only sample inefficient, but also prone to suboptimal convergence. Two ways to improve sample efficiency are to extract relevant features for the task and use off-policy algorithms. We dissect various approaches of learning good latent features, and conclude that the image reconstruction loss is the essential ingredient that enables efficient and stable representation learning in image-based RL. Following these findings, we devise an off-policy actor-critic algorithm with an auxiliary decoder that trains end-to-end and matches state-of-the-art performance across both model-free and model-based algorithms on many challenging control tasks. We release our code to encourage future research on image-based RL.