 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Restoration Using Joint Statistical Modeling in Space-Transform Domain
May 11, 2014




This paper presents a novel strategy for high-fidelity image restoration by characterizing both local smoothness and nonlocal self-similarity of natural images in a unified statistical manner. The main contributions are three-folds. First, from the perspective of image statistics, a joint statistical modeling (JSM) in an adaptive hybrid space-transform domain is established, which offers a powerful mechanism of combining local smoothness and nonlocal self-similarity simultaneously to ensure a more reliable and robust estimation. Second, a new form of minimization functional for solving image inverse problem is formulated using JSM under regularization-based framework. Finally, in order to make JSM tractable and robust, a new Split-Bregman based algorithm is developed to efficiently solve the above severely underdetermined inverse problem associated with theoretical proof of convergence. Extensive experiments on image inpainting, image deblurring and mixed Gaussian plus salt-and-pepper noise removal applications verify the effectiveness of the proposed algorithm.
Cross-Domain Conditional Generative Adversarial Networks for Stereoscopic Hyperrealism in Surgical Training
Jun 24, 2019

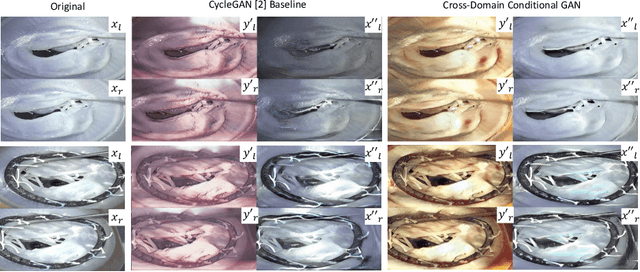
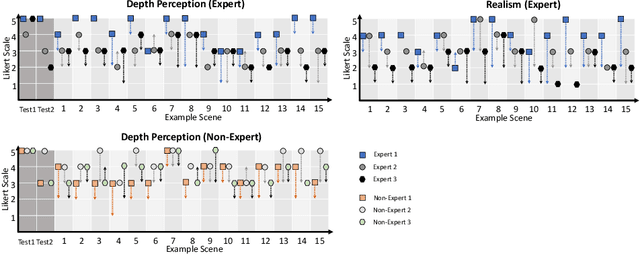
Phantoms for surgical training are able to mimic cutting and suturing properties and patient-individual shape of organs, but lack a realistic visual appearance that captures the heterogeneity of surgical scenes. In order to overcome this in endoscopic approaches, hyperrealistic concepts have been proposed to be used in an augmented reality-setting, which are based on deep image-to-image transformation methods. Such concepts are able to generate realistic representations of phantoms learned from real intraoperative endoscopic sequences. Conditioned on frames from the surgical training process, the learned models are able to generate impressive results by transforming unrealistic parts of the image (e.g.\ the uniform phantom texture is replaced by the more heterogeneous texture of the tissue). Image-to-image synthesis usually learns a mapping $G:X~\to~Y$ such that the distribution of images from $G(X)$ is indistinguishable from the distribution $Y$. However, it does not necessarily force the generated images to be consistent and without artifacts. In the endoscopic image domain this can affect depth cues and stereo consistency of a stereo image pair, which ultimately impairs surgical vision. We propose a cross-domain conditional generative adversarial network approach (GAN) that aims to generate more consistent stereo pairs. The results show substantial improvements in depth perception and realism evaluated by 3 domain experts and 3 medical students on a 3D monitor over the baseline method. In 84 of 90 instances our proposed method was preferred or rated equal to the baseline.
Improving Sample Efficiency in Model-Free Reinforcement Learning from Images
Oct 07, 2019
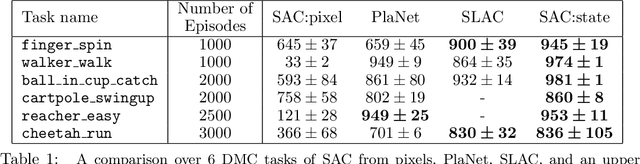
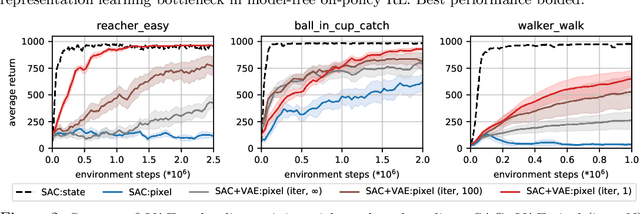
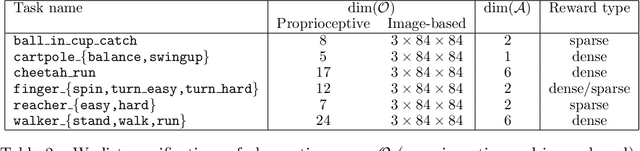
Training an agent to solve control tasks directly from high-dimensional images with model-free reinforcement learning (RL) has proven difficult. The agent needs to learn a latent representation together with a control policy to perform the task. Fitting a high-capacity encoder using a scarce reward signal is not only sample inefficient, but also prone to suboptimal convergence. Two ways to improve sample efficiency are to extract relevant features for the task and use off-policy algorithms. We dissect various approaches of learning good latent features, and conclude that the image reconstruction loss is the essential ingredient that enables efficient and stable representation learning in image-based RL. Following these findings, we devise an off-policy actor-critic algorithm with an auxiliary decoder that trains end-to-end and matches state-of-the-art performance across both model-free and model-based algorithms on many challenging control tasks. We release our code to encourage future research on image-based RL.
Corpus Creation for Sentiment Analysis in Code-Mixed Tamil-English Text
May 30, 2020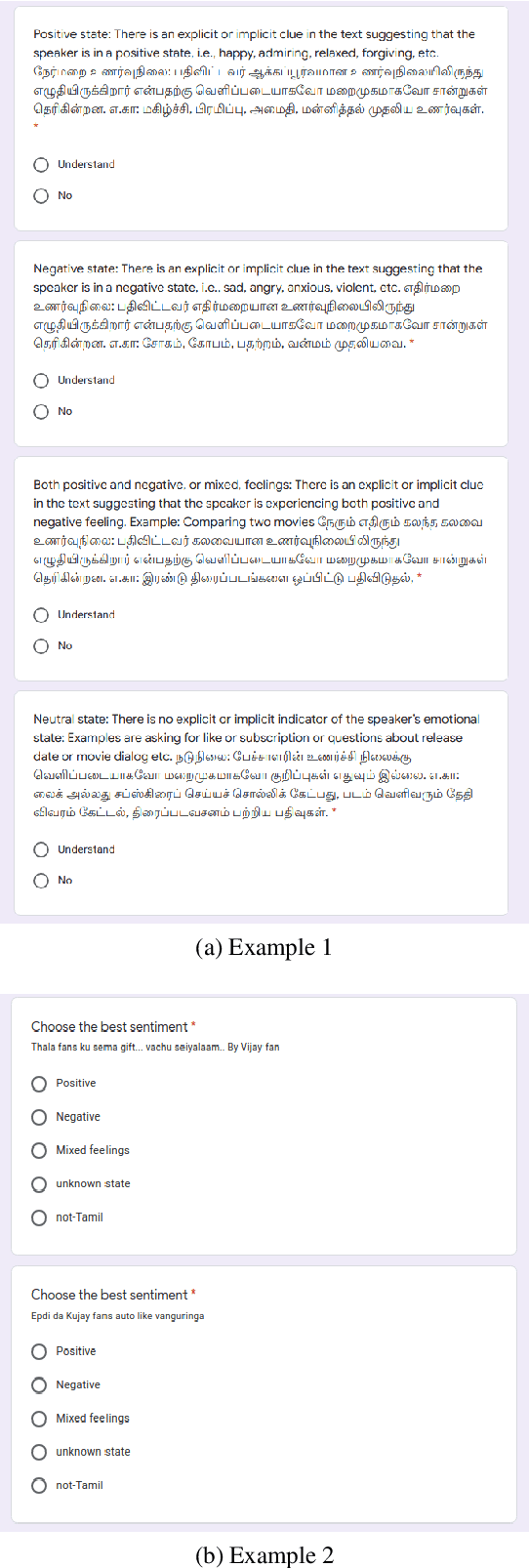

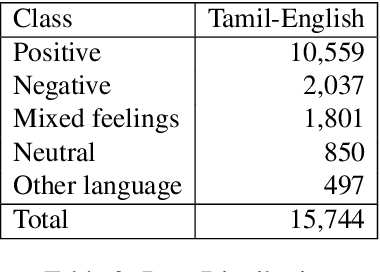
Understanding the sentiment of a comment from a video or an image is an essential task in many applications. Sentiment analysis of a text can be useful for various decision-making processes. One such application is to analyse the popular sentiments of videos on social media based on viewer comments. However, comments from social media do not follow strict rules of grammar, and they contain mixing of more than one language, often written in non-native scripts. Non-availability of annotated code-mixed data for a low-resourced language like Tamil also adds difficulty to this problem. To overcome this, we created a gold standard Tamil-English code-switched, sentiment-annotated corpus containing 15,744 comment posts from YouTube. In this paper, we describe the process of creating the corpus and assigning polarities. We present inter-annotator agreement and show the results of sentiment analysis trained on this corpus as a benchmark.
FakeLocator: Robust Localization of GAN-Based Face Manipulations via Semantic Segmentation Networks with Bells and Whistles
Feb 21, 2020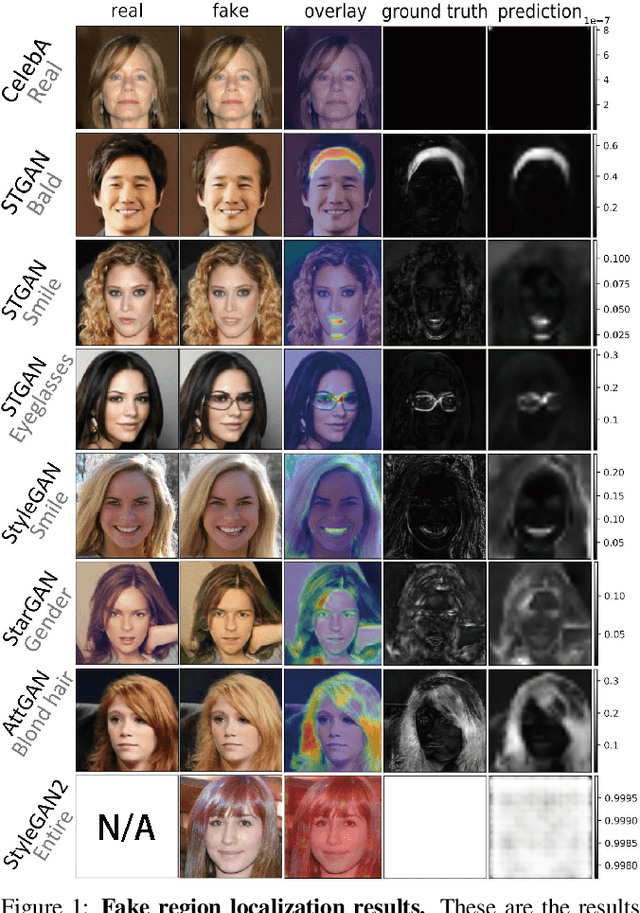
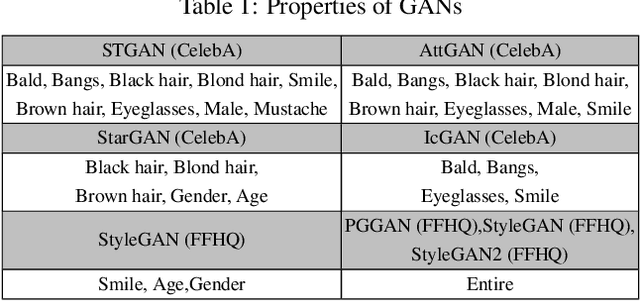
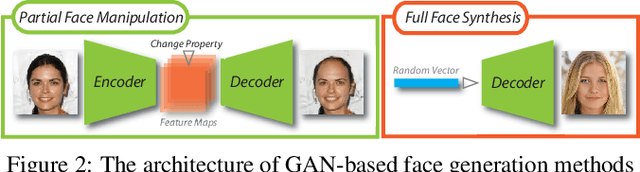
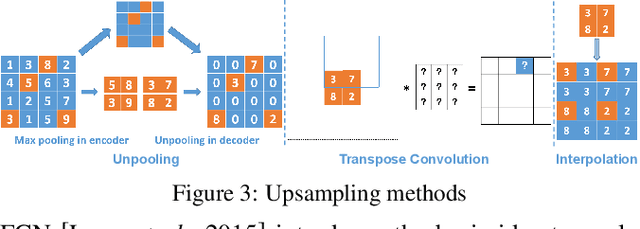
Nowadays, full face synthesis and partial face manipulation by virtue of the generative adversarial networks (GANs) have raised wide public concern. In the digital media forensics area, detecting and ultimately locating the image forgery have become imperative. Although many methods focus on fake detection, only a few put emphasis on the localization of the fake regions. Through analyzing the imperfection in the upsampling procedures of the GAN-based methods and recasting the fake localization problem as a modified semantic segmentation one, our proposed FakeLocator can obtain high localization accuracy, at full resolution, on manipulated facial images. To the best of our knowledge, this is the very first attempt to solve the GAN-based fake localization problem with a semantic segmentation map. As an improvement, the real-numbered segmentation map proposed by us preserves more information of fake regions. For this new type segmentation map, we also find suitable loss functions for it. Experimental results on the CelebA and FFHQ databases with seven different SOTA GAN-based face generation methods show the effectiveness of our method. Compared with the baseline, our method performs several times better on various metrics. Moreover, the proposed method is robust against various real-world facial image degradations such as JPEG compression, low-resolution, noise, and blur.
Deep Learning Techniques for Inverse Problems in Imaging
May 12, 2020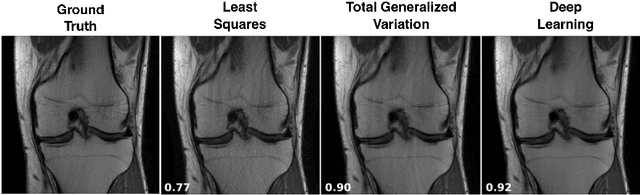
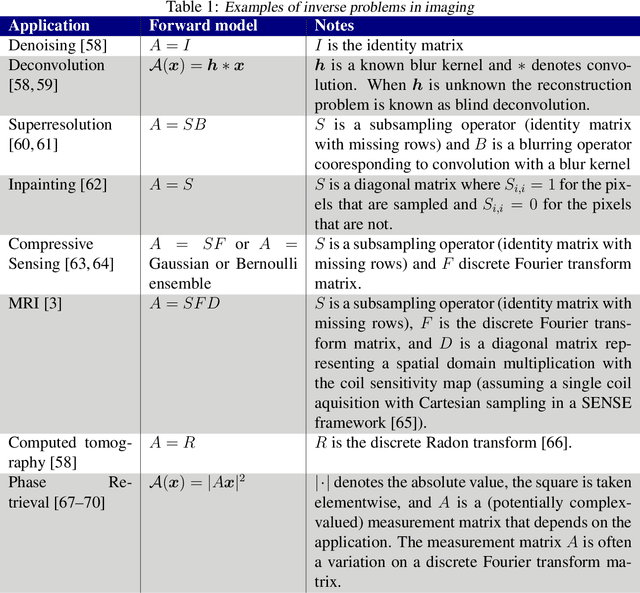

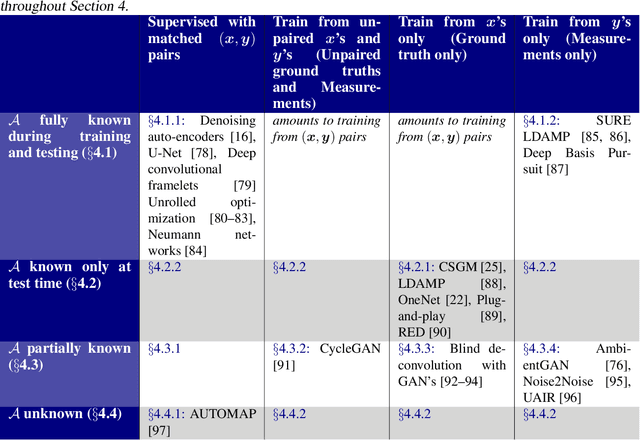
Recent work in machine learning shows that deep neural networks can be used to solve a wide variety of inverse problems arising in computational imaging. We explore the central prevailing themes of this emerging area and present a taxonomy that can be used to categorize different problems and reconstruction methods. Our taxonomy is organized along two central axes: (1) whether or not a forward model is known and to what extent it is used in training and testing, and (2) whether or not the learning is supervised or unsupervised, i.e., whether or not the training relies on access to matched ground truth image and measurement pairs. We also discuss the trade-offs associated with these different reconstruction approaches, caveats and common failure modes, plus open problems and avenues for future work.
Towards Emergent Language Symbolic Semantic Segmentation and Model Interpretability
Jul 18, 2020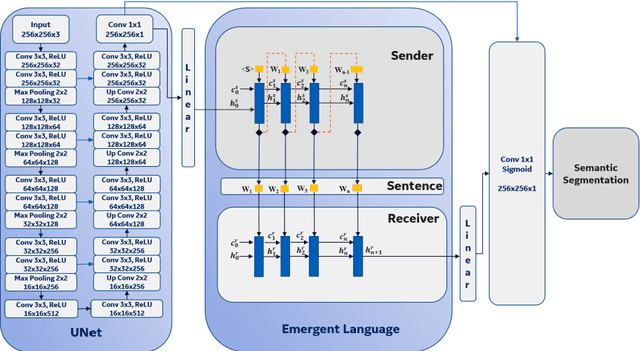
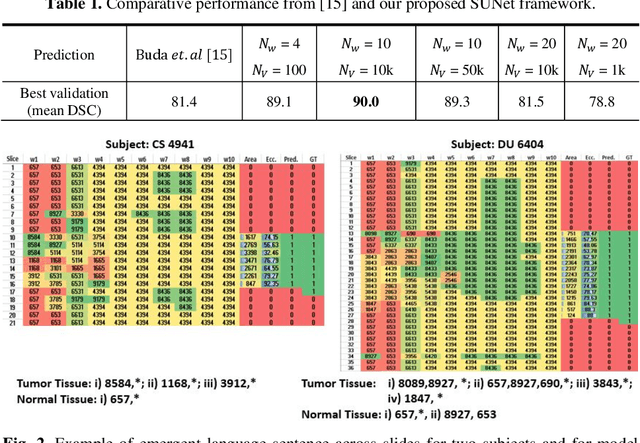
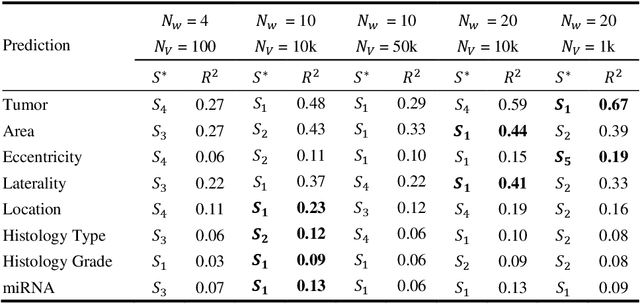
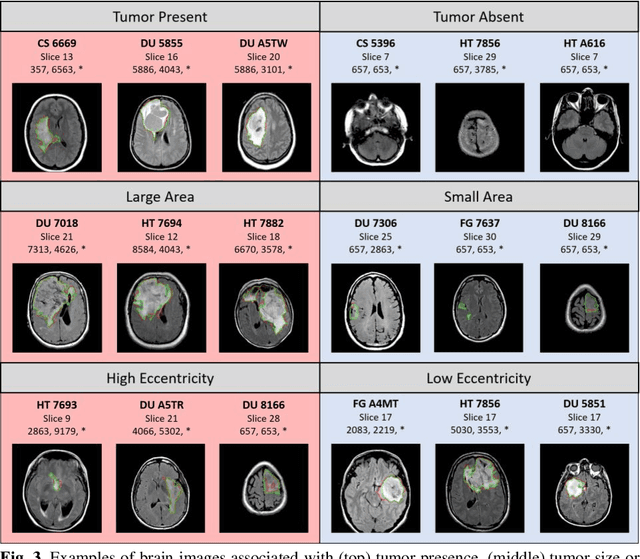
Recent advances in methods focused on the grounding problem have resulted in techniques that can be used to construct a symbolic language associated with a specific domain. Inspired by how humans communicate complex ideas through language, we developed a generalized Symbolic Semantic ($\text{S}^2$) framework for interpretable segmentation. Unlike adversarial models (e.g., GANs), we explicitly model cooperation between two agents, a Sender and a Receiver, that must cooperate to achieve a common goal. The Sender receives information from a high layer of a segmentation network and generates a symbolic sentence derived from a categorical distribution. The Receiver obtains the symbolic sentences and co-generates the segmentation mask. In order for the model to converge, the Sender and Receiver must learn to communicate using a private language. We apply our architecture to segment tumors in the TCGA dataset. A UNet-like architecture is used to generate input to the Sender network which produces a symbolic sentence, and a Receiver network co-generates the segmentation mask based on the sentence. Our Segmentation framework achieved similar or better performance compared with state-of-the-art segmentation methods. In addition, our results suggest direct interpretation of the symbolic sentences to discriminate between normal and tumor tissue, tumor morphology, and other image characteristics.
Object Tracking through Residual and Dense LSTMs
Jun 22, 2020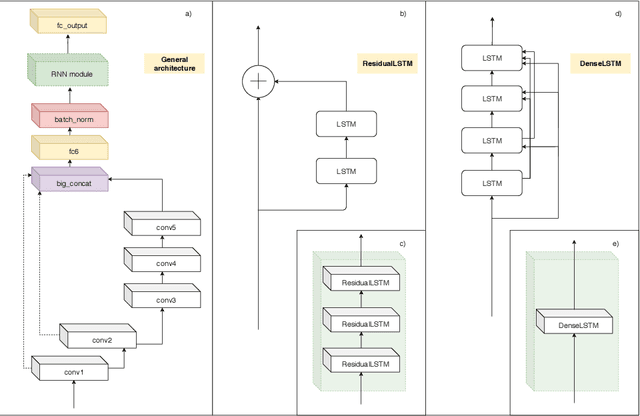

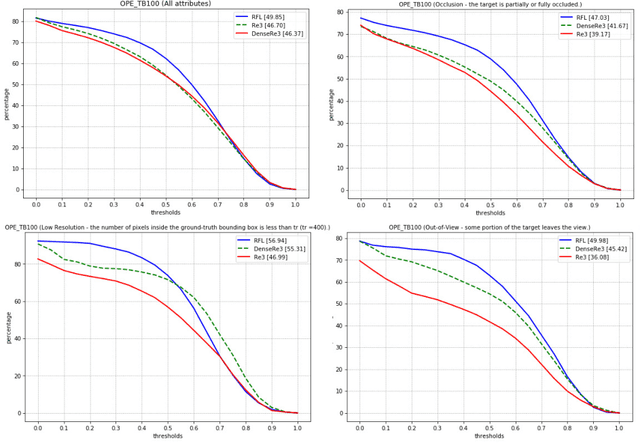
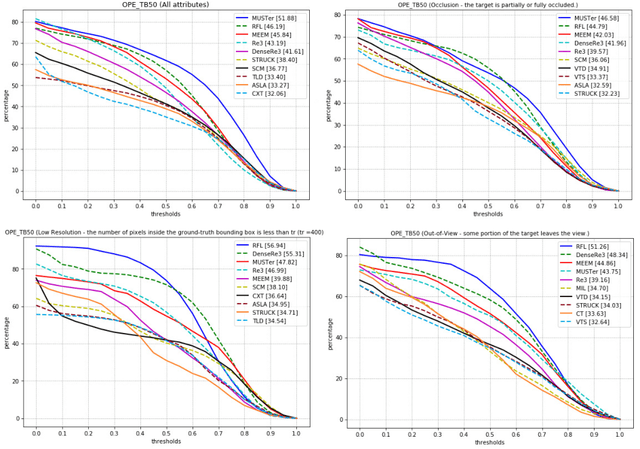
Visual object tracking task is constantly gaining importance in several fields of application as traffic monitoring, robotics, and surveillance, to name a few. Dealing with changes in the appearance of the tracked object is paramount to achieve high tracking accuracy, and is usually achieved by continually learning features. Recently, deep learning-based trackers based on LSTMs (Long Short-Term Memory) recurrent neural networks have emerged as a powerful alternative, bypassing the need to retrain the feature extraction in an online fashion. Inspired by the success of residual and dense networks in image recognition, we propose here to enhance the capabilities of hybrid trackers using residual and/or dense LSTMs. By introducing skip connections, it is possible to increase the depth of the architecture while ensuring a fast convergence. Experimental results on the Re3 tracker show that DenseLSTMs outperform Residual and regular LSTM, and offer a higher resilience to nuisances such as occlusions and out-of-view objects. Our case study supports the adoption of residual-based RNNs for enhancing the robustness of other trackers.
Challenge report: Recognizing Families In the Wild Data Challenge
May 30, 2020
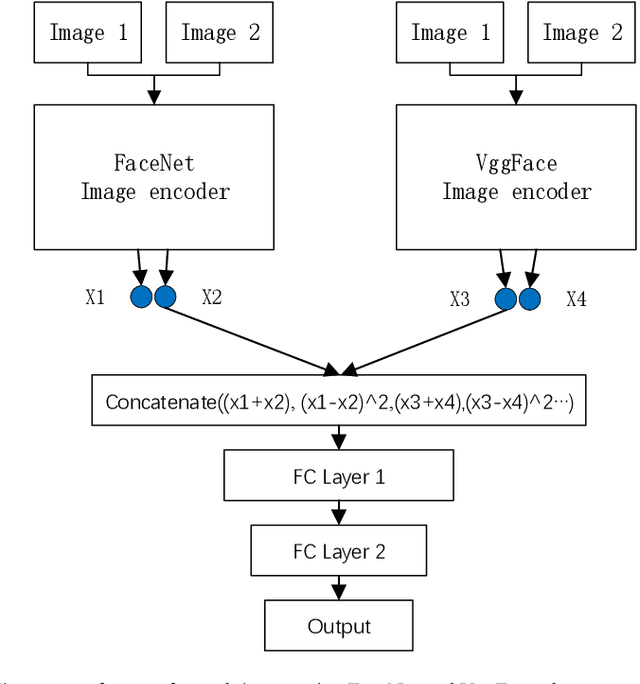
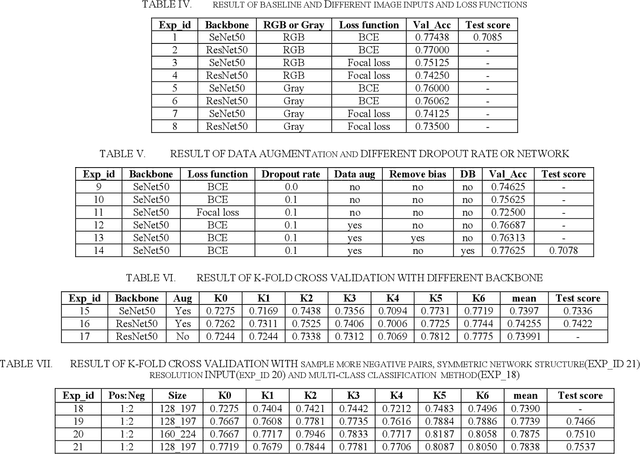
This paper is a brief report to our submission to the Recognizing Families In the Wild Data Challenge (4th Edition), in conjunction with FG 2020 Forum. Automatic kinship recognition has attracted many researchers' attention for its full application, but it is still a very challenging task because of the limited information that can be used to determine whether a pair of faces are blood relatives or not. In this paper, we studied previous methods and proposed our method. We try many methods, like deep metric learning-based, to extract deep embedding feature for every image, then determine if they are blood relatives by Euclidean distance or method based on classes. Finally, we find some tricks like sampling more negative samples and high resolution that can help get better performance. Moreover, we proposed a symmetric network with a binary classification based method to get our best score in all tasks.
DeepHAZMAT: Hazardous Materials Sign Detection and Segmentation with Restricted Computational Resources
Jul 18, 2020



One of the most challenging and non-trivial tasks in robot-based rescue operations is the Hazardous Materials or HAZMATs sign detection in the operation field, to prevent further unexpected disasters. Each Hazmat sign has a specific meaning that the rescue robot should detect and interpret it to take a safe action, accordingly. Accurate Hazmat detection and real-time processing are the two most important factors in such robotics applications. Furthermore, we also have to cope with some secondary challenges such as image distortion and restricted CPU and computational resources which are embedded in a rescue robot. In this paper, we propose a CNN-Based pipeline called DeepHAZMAT for detecting and segmenting Hazmats in four steps; 1) optimising the number of input images that are fed into the CNN network, 2) using the YOLOv3-tiny structure to collect the required visual information from the hazardous areas, 3) Hazmat sign segmentation and separation from the background using GrabCut technique, and 4) post-processing the result with morphological operators and convex hull algorithm. In spite of the utilisation of a very limited memory and CPU resources, the experimental results show the proposed method has successfully maintained a better performance in terms of detection-speed and detection-accuracy, compared with the state-of-the-art methods.