 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Survey on Sparse Coded Features for Content Based Face Image Retrieval
Feb 20, 2014
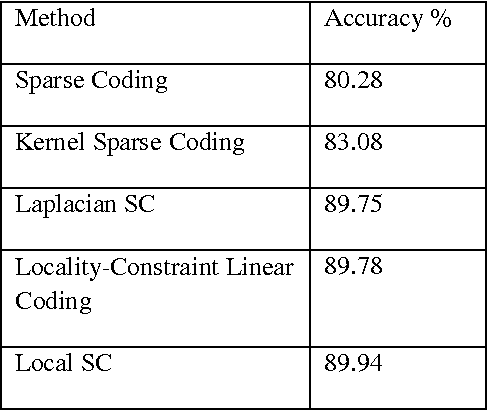
Content based image retrieval, a technique which uses visual contents of image to search images from large scale image databases according to users' interests. This paper provides a comprehensive survey on recent technology used in the area of content based face image retrieval. Nowadays digital devices and photo sharing sites are getting more popularity, large human face photos are available in database. Multiple types of facial features are used to represent discriminality on large scale human facial image database. Searching and mining of facial images are challenging problems and important research issues. Sparse representation on features provides significant improvement in indexing related images to query image.
* 4 pages,3 figures,1 table, Published with International Journal of Computer Trends and Technology (IJCTT)
Robust Technique for Representative Volume Element Identification in Noisy Microtomography Images of Porous Materials Based on Pores Morphology and Their Spatial Distribution
Jul 06, 2020
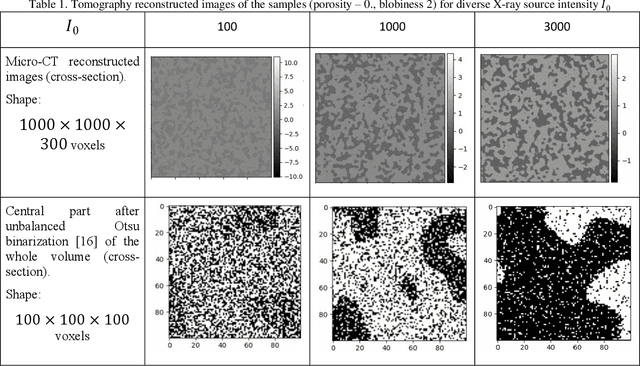
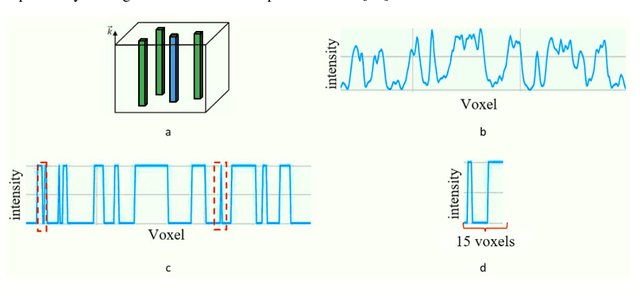
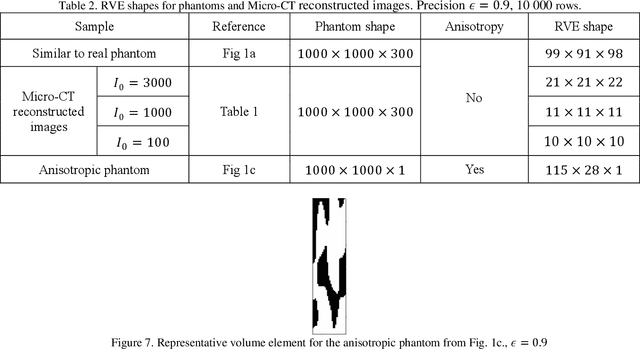
Microtomography is a powerful method of materials investigation. It enables to obtain physical properties of porous media non-destructively that is useful in studies. One of the application ways is a calculation of porosity, pore sizes, surface area, and other parameters of metal-ceramic (cermet) membranes which are widely spread in the filtration industry. The microtomography approach is efficient because all of those parameters are calculated simultaneously in contrast to the conventional techniques. Nevertheless, the calculations on Micro-CT reconstructed images appear to be time-consuming, consequently representative volume element should be chosen to speed them up. This research sheds light on representative elementary volume identification without consideration of any physical parameters such as porosity, etc. Thus, the volume element could be found even in noised and grayscale images. The proposed method is flexible and does not overestimate the volume size in the case of anisotropic samples. The obtained volume element could be used for computations of the domain's physical characteristics if the image is filtered and binarized, or for selections of optimal filtering parameters for denoising procedure.
AnalogNet: Convolutional Neural Network Inference on Analog Focal Plane Sensor Processors
Jun 21, 2020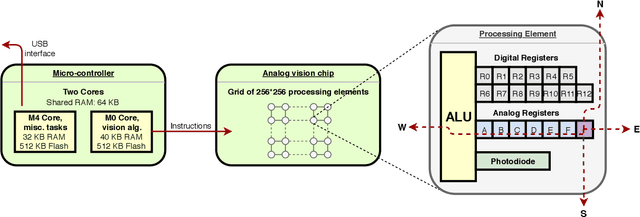
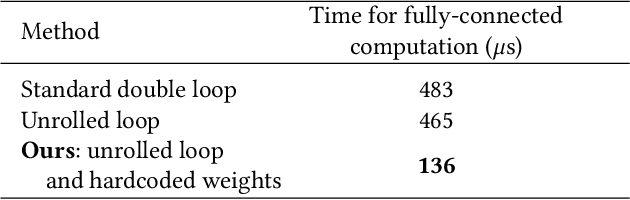


We present a high-speed, energy-efficient Convolutional Neural Network (CNN) architecture utilising the capabilities of a unique class of devices known as analog Focal Plane Sensor Processors (FPSP), in which the sensor and the processor are embedded together on the same silicon chip. Unlike traditional vision systems, where the sensor array sends collected data to a separate processor for processing, FPSPs allow data to be processed on the imaging device itself. This unique architecture enables ultra-fast image processing and high energy efficiency, at the expense of limited processing resources and approximate computations. In this work, we show how to convert standard CNNs to FPSP code, and demonstrate a method of training networks to increase their robustness to analog computation errors. Our proposed architecture, coined AnalogNet, reaches a testing accuracy of 96.9% on the MNIST handwritten digits recognition task, at a speed of 2260 FPS, for a cost of 0.7 mJ per frame.
TENet: Triple Excitation Network for Video Salient Object Detection
Jul 20, 2020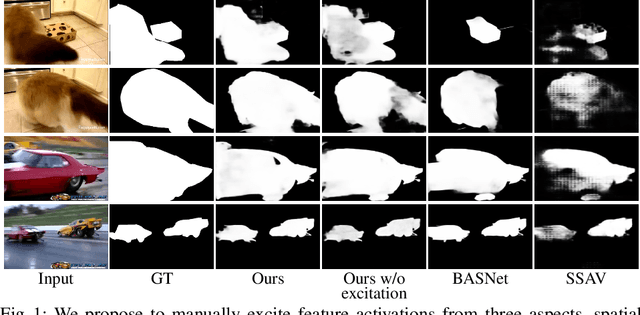
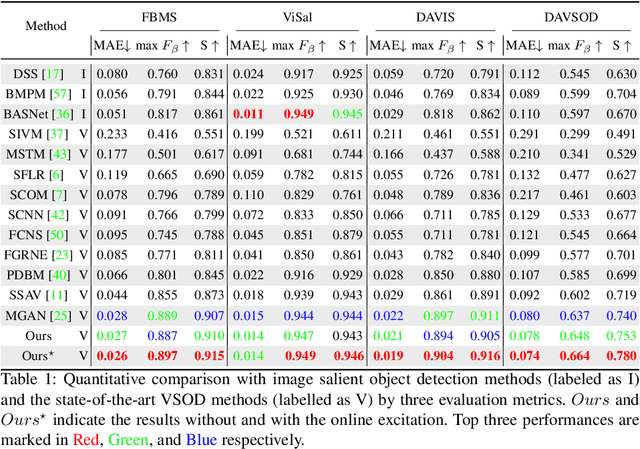
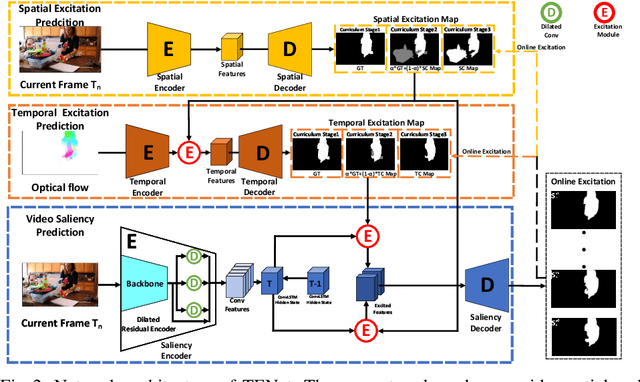
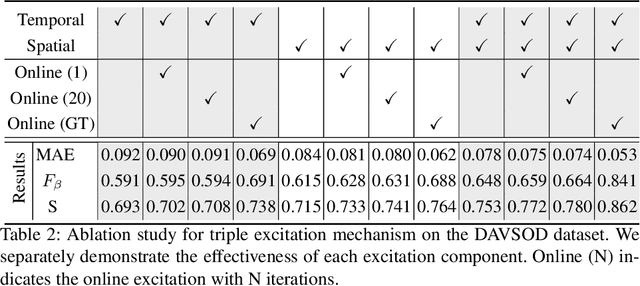
In this paper, we propose a simple yet effective approach, named Triple Excitation Network, to reinforce the training of video salient object detection (VSOD) from three aspects, spatial, temporal, and online excitations. These excitation mechanisms are designed following the spirit of curriculum learning and aim to reduce learning ambiguities at the beginning of training by selectively exciting feature activations using ground truth. Then we gradually reduce the weight of ground truth excitations by a curriculum rate and replace it by a curriculum complementary map for better and faster convergence. In particular, the spatial excitation strengthens feature activations for clear object boundaries, while the temporal excitation imposes motions to emphasize spatio-temporal salient regions. Spatial and temporal excitations can combat the saliency shifting problem and conflict between spatial and temporal features of VSOD. Furthermore, our semi-curriculum learning design enables the first online refinement strategy for VSOD, which allows exciting and boosting saliency responses during testing without re-training. The proposed triple excitations can easily plug in different VSOD methods. Extensive experiments show the effectiveness of all three excitation methods and the proposed method outperforms state-of-the-art image and video salient object detection methods.
Fixed smooth convolutional layer for avoiding checkerboard artifacts in CNNs
Feb 06, 2020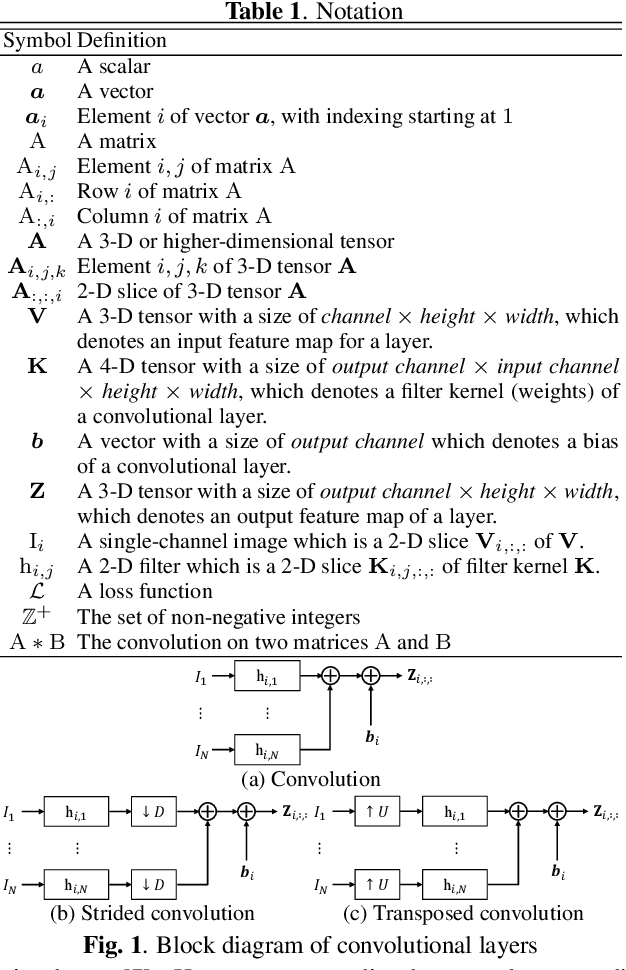
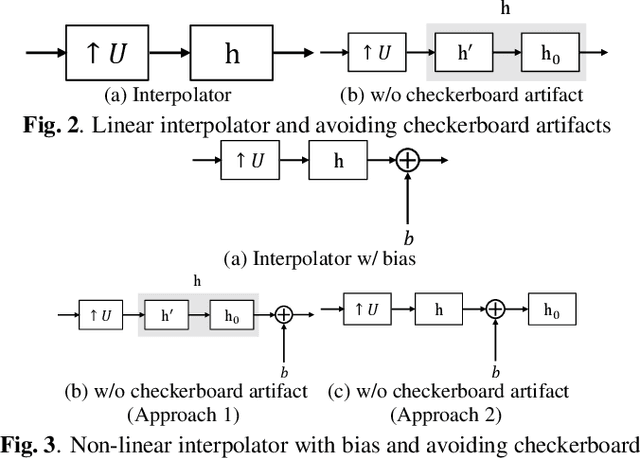

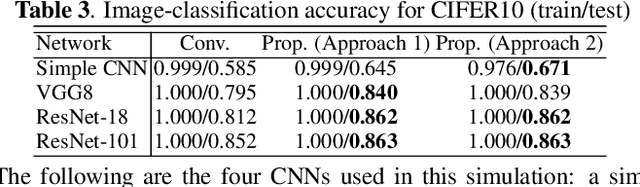
In this paper, we propose a fixed convolutional layer with an order of smoothness not only for avoiding checkerboard artifacts in convolutional neural networks (CNNs) but also for enhancing the performance of CNNs, where the smoothness of its filter kernel can be controlled by a parameter. It is well-known that a number of CNNs generate checkerboard artifacts in both of two process: forward-propagation of upsampling layers and backward-propagation of strided convolutional layers. The proposed layer can perfectly prevent checkerboard artifacts caused by strided convolutional layers or upsampling layers including transposed convolutional layers. In an image-classification experiment with four CNNs: a simple CNN, VGG8, ResNet-18, and ResNet-101, applying the fixed layers to these CNNs is shown to improve the classification performance of all CNNs. In addition, the fixed layer are applied to generative adversarial networks (GANs), for the first time. From image-generation results, a smoother fixed convolutional layer is demonstrated to enable us to improve the quality of images generated with GANs.
Walk the Lines: Object Contour Tracing CNN for Contour Completion of Ships
Apr 14, 2020
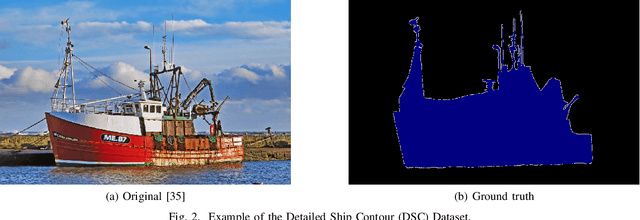
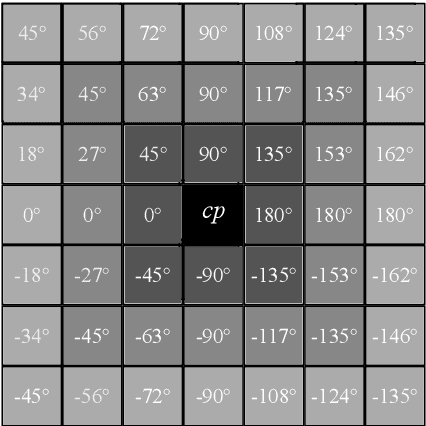
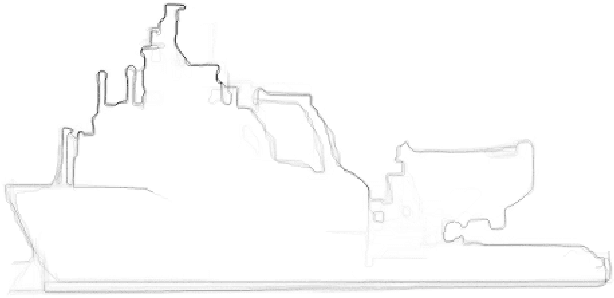
We develop a new contour tracing algorithm to enhance the results of the latest object contour detectors. The goal is to achieve a perfectly closed, 1 pixel wide and detailed object contour, since this type of contour could be analyzed using methods such as Fourier descriptors. Convolutional Neural Networks (CNNs) are rarely used for contour tracing. However, we find CNNs are tailor-made for this task and that's why we present the Walk the Lines (WtL) algorithm, a standard regression CNN trained to follow object contours. To make the first step, we train the CNN only on ship contours, but the principle is also applicable to other objects. Input data are the image and the associated object contour prediction of the recently published RefineContourNet. The WtL gets a center pixel, which defines an input section and an angle for rotating this section. Ideally, the center pixel moves on the contour, while the angle describes upcoming directional contour changes. The WtL predicts its steps pixelwise in a selfrouting way. To obtain a complete object contour the WtL runs in parallel at different image locations and the traces of its individual paths are summed. In contrast to the comparable Non-Maximum Suppression method, our approach produces connected contours with finer details. Finally, the object contour is binarized under the condition of being closed. In case all procedures work as desired, excellent ship segmentations with high IoUs are produced, showing details such as antennas and ship superstructures that are easily omitted by other segmentation methods.
Let me join you! Real-time F-formation recognition by a socially aware robot
Aug 23, 2020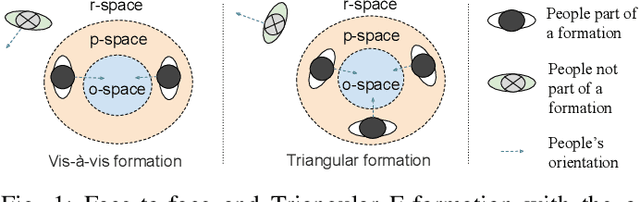
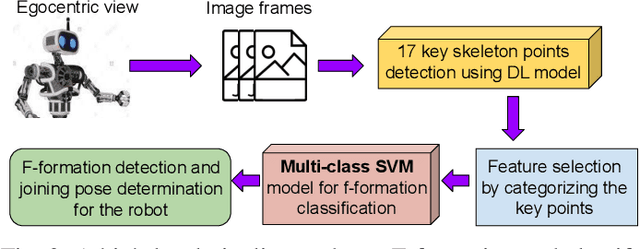

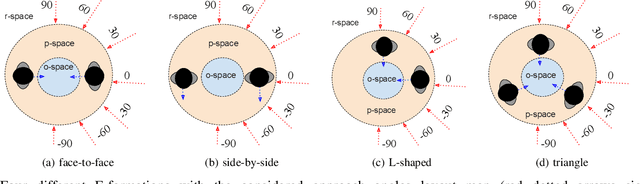
This paper presents a novel architecture to detect social groups in real-time from a continuous image stream of an ego-vision camera. F-formation defines social orientations in space where two or more person tends to communicate in a social place. Thus, essentially, we detect F-formations in social gatherings such as meetings, discussions, etc. and predict the robot's approach angle if it wants to join the social group. Additionally, we also detect outliers, i.e., the persons who are not part of the group under consideration. Our proposed pipeline consists of -- a) a skeletal key points estimator (a total of 17) for the detected human in the scene, b) a learning model (using a feature vector based on the skeletal points) using CRF to detect groups of people and outlier person in a scene, and c) a separate learning model using a multi-class Support Vector Machine (SVM) to predict the exact F-formation of the group of people in the current scene and the angle of approach for the viewing robot. The system is evaluated using two data-sets. The results show that the group and outlier detection in a scene using our method establishes an accuracy of 91%. We have made rigorous comparisons of our systems with a state-of-the-art F-formation detection system and found that it outperforms the state-of-the-art by 29% for formation detection and 55% for combined detection of the formation and approach angle.
Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image
Feb 26, 2018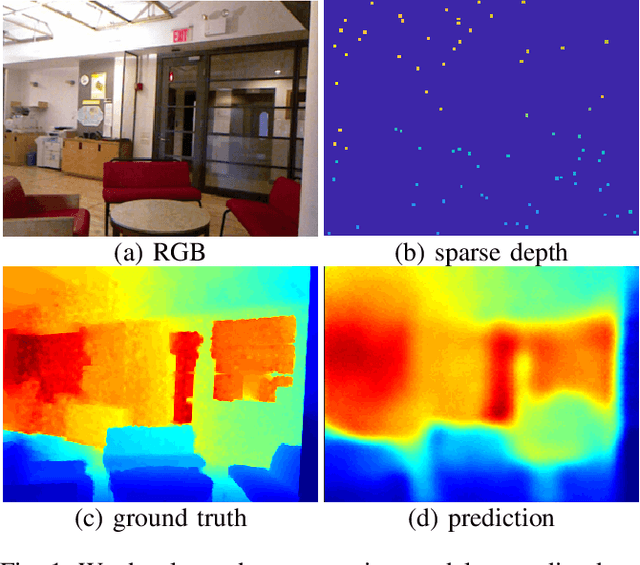
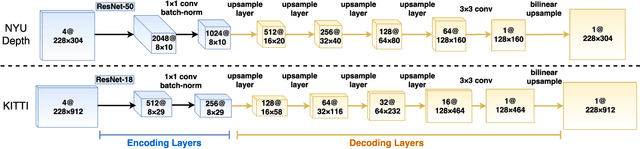
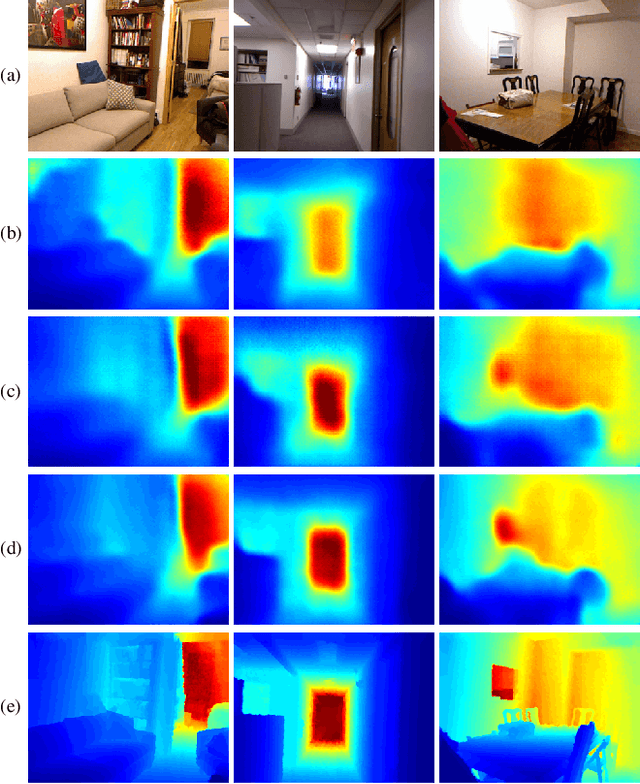
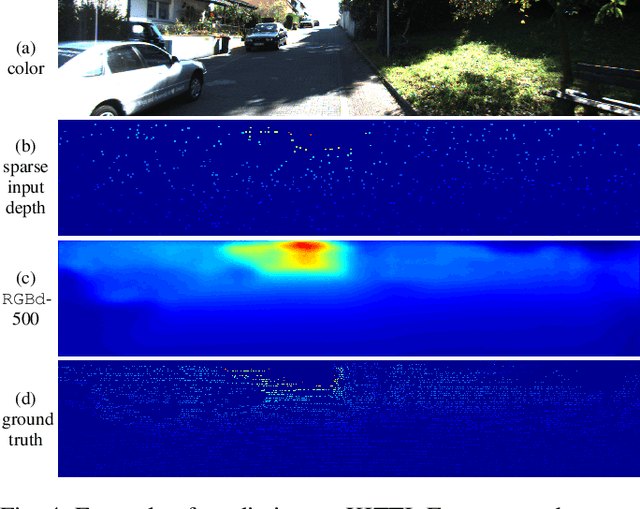
We consider the problem of dense depth prediction from a sparse set of depth measurements and a single RGB image. Since depth estimation from monocular images alone is inherently ambiguous and unreliable, to attain a higher level of robustness and accuracy, we introduce additional sparse depth samples, which are either acquired with a low-resolution depth sensor or computed via visual Simultaneous Localization and Mapping (SLAM) algorithms. We propose the use of a single deep regression network to learn directly from the RGB-D raw data, and explore the impact of number of depth samples on prediction accuracy. Our experiments show that, compared to using only RGB images, the addition of 100 spatially random depth samples reduces the prediction root-mean-square error by 50% on the NYU-Depth-v2 indoor dataset. It also boosts the percentage of reliable prediction from 59% to 92% on the KITTI dataset. We demonstrate two applications of the proposed algorithm: a plug-in module in SLAM to convert sparse maps to dense maps, and super-resolution for LiDARs. Software and video demonstration are publicly available.
Semantics-aware Adaptive Knowledge Distillation for Sensor-to-Vision Action Recognition
Sep 02, 2020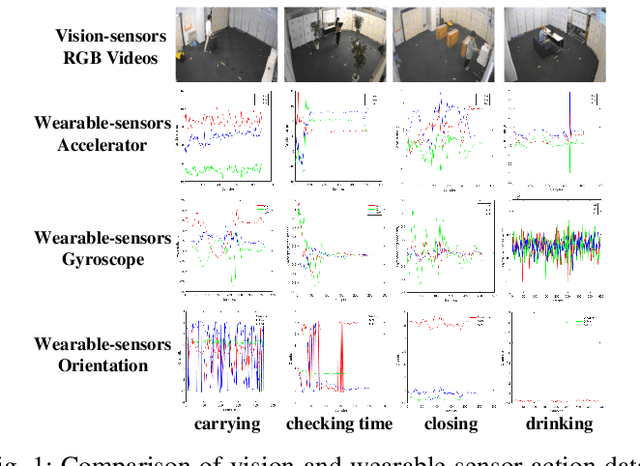
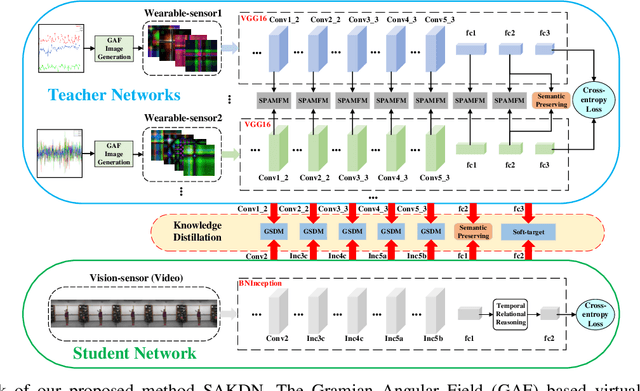
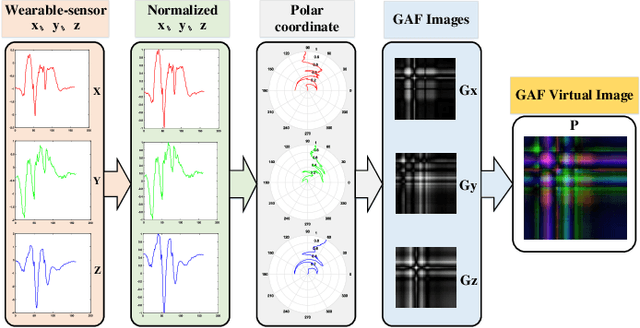
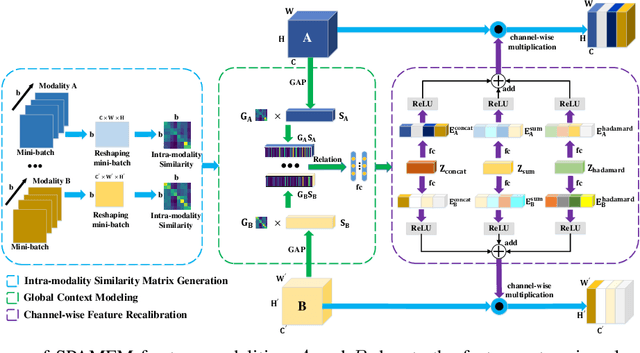
Existing vision-based action recognition is susceptible to occlusion and appearance variations, while wearable sensors can alleviate these challenges by capturing human motion with one-dimensional time-series signals (e.g. acceleration, gyroscope and orientation). For the same action, the knowledge learned from vision sensors (videos or images) and wearable sensors, may be related and complementary. However, there exists significantly large modality difference between action data captured by wearable-sensor and vision-sensor in data dimension, data distribution and inherent information content. In this paper, we propose a novel framework, named Semantics-aware Adaptive Knowledge Distillation Networks (SAKDN), to enhance action recognition in vision-sensor modality (videos) by adaptively transferring and distilling the knowledge from multiple wearable sensors. The SAKDN uses multiple wearable-sensors as teacher modalities and uses RGB videos as student modality. Specifically, we transform one-dimensional time-series signals of wearable sensors to two-dimensional images by designing a gramian angular field based virtual image generation model. Then, we build a novel Similarity-Preserving Adaptive Multi-modal Fusion Module (SPAMFM) to adaptively fuse intermediate representation knowledge from different teacher networks. To fully exploit and transfer the knowledge of multiple well-trained teacher networks to the student network, we propose a novel Graph-guided Semantically Discriminative Mapping (GSDM) loss, which utilizes graph-guided ablation analysis to produce a good visual explanation highlighting the important regions across modalities and concurrently preserving the interrelations of original data. Experimental results on Berkeley-MHAD, UTD-MHAD and MMAct datasets well demonstrate the effectiveness of our proposed SAKDN.
Scene Text Magnifier
Jul 05, 2019

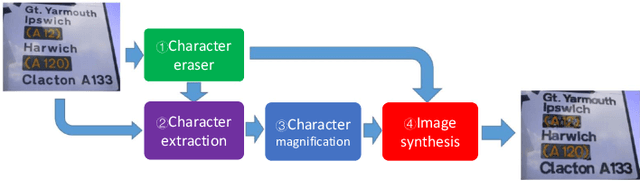
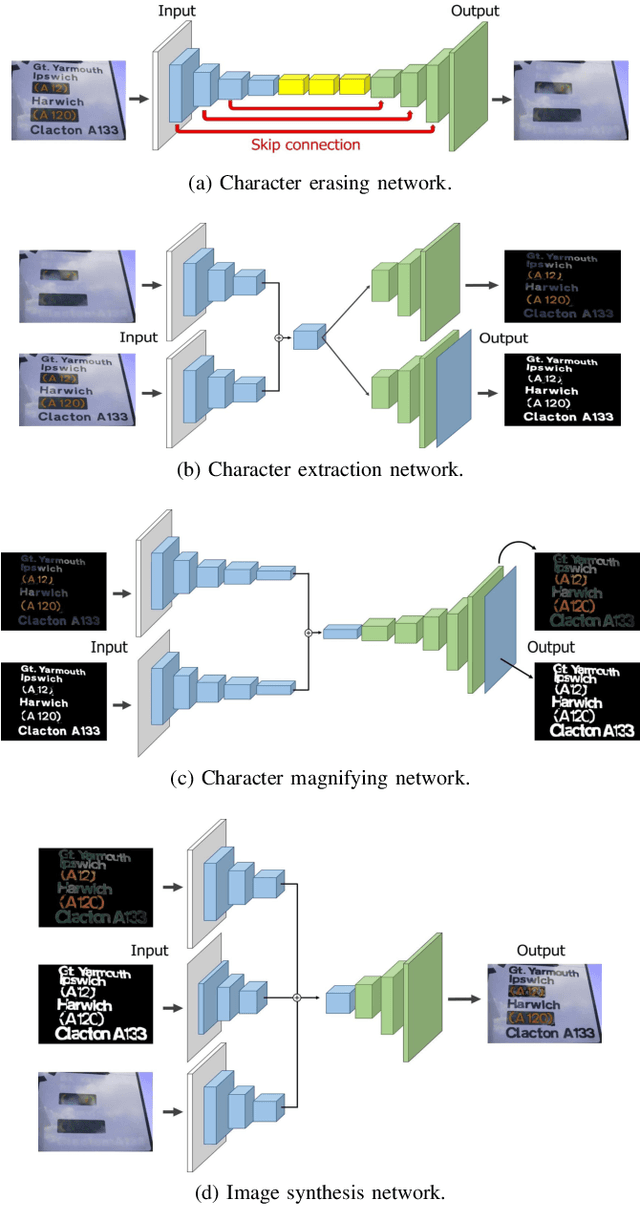
Scene text magnifier aims to magnify text in natural scene images without recognition. It could help the special groups, who have myopia or dyslexia to better understand the scene. In this paper, we design the scene text magnifier through interacted four CNN-based networks: character erasing, character extraction, character magnify, and image synthesis. The architecture of the networks are extended based on the hourglass encoder-decoders. It inputs the original scene text image and outputs the text magnified image while keeps the background unchange. Intermediately, we can get the side-output results of text erasing and text extraction. The four sub-networks are first trained independently and fine-tuned in end-to-end mode. The training samples for each stage are processed through a flow with original image and text annotation in ICDAR2013 and Flickr dataset as input, and corresponding text erased image, magnified text annotation, and text magnified scene image as output. To evaluate the performance of text magnifier, the Structural Similarity is used to measure the regional changes in each character region. The experimental results demonstrate our method can magnify scene text effectively without effecting the background.