 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Overview of Deep Semi-Supervised Learning
Jun 09, 2020

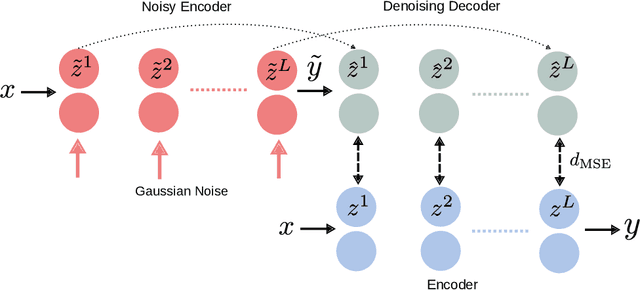

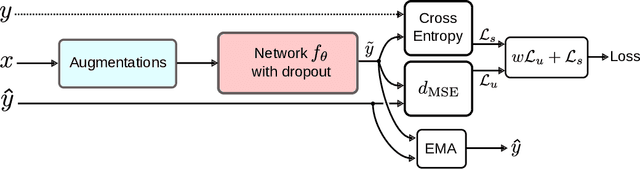
Deep neural networks demonstrated their ability to provide remarkable performances on particular supervised learning tasks (e.g., image classification) when trained on extensive collections of labeled data (e.g., ImageNet). However, creating such large datasets requires a considerable amount of resources, time, and effort. Such resources may not be available in many practical cases, limiting the adoption and application of many deep learning methods. In a search for more data-efficient deep learning methods to overcome this need for large annotated datasets, we a rising research interest in recent years with regards to the application of semi-supervised learning to deep neural nets as a possible alternative, by developing novel methods and adopting existing semi-supervised learning frameworks for a deep learning setting. In this paper, we provide a comprehensive overview of deep semi-supervised learning, starting with an introduction to semi-supervised learning. Followed by a summarization of the dominant semi-supervised approaches in deep learning.
Emergence of Object Segmentation in Perturbed Generative Models
May 29, 2019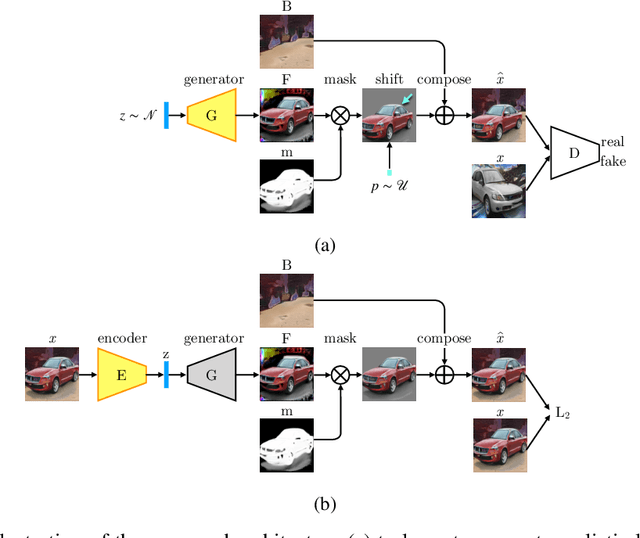
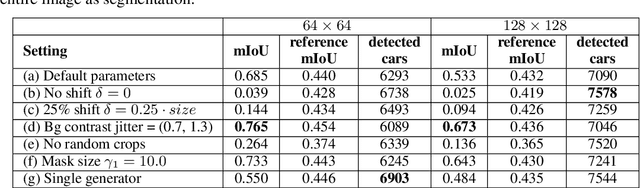


We introduce a novel framework to build a model that can learn how to segment objects from a collection of images without any human annotation. Our method builds on the observation that the location of object segments can be perturbed locally relative to a given background without affecting the realism of a scene. Our approach is to first train a generative model of a layered scene. The layered representation consists of a background image, a foreground image and the mask of the foreground. A composite image is then obtained by overlaying the masked foreground image onto the background. The generative model is trained in an adversarial fashion against a discriminator, which forces the generative model to produce realistic composite images. To force the generator to learn a representation where the foreground layer corresponds to an object, we perturb the output of the generative model by introducing a random shift of both the foreground image and mask relative to the background. Because the generator is unaware of the shift before computing its output, it must produce layered representations that are realistic for any such random perturbation. Finally, we learn to segment an image by defining an autoencoder consisting of an encoder, which we train, and the pre-trained generator as the decoder, which we freeze. The encoder maps an image to a feature vector, which is fed as input to the generator to give a composite image matching the original input image. Because the generator outputs an explicit layered representation of the scene, the encoder learns to detect and segment objects. We demonstrate this framework on real images of several object categories.
Breaking the Limits of Remote Sensing by Simulation and Deep Learning for Flood and Debris Flow Mapping
Jun 09, 2020
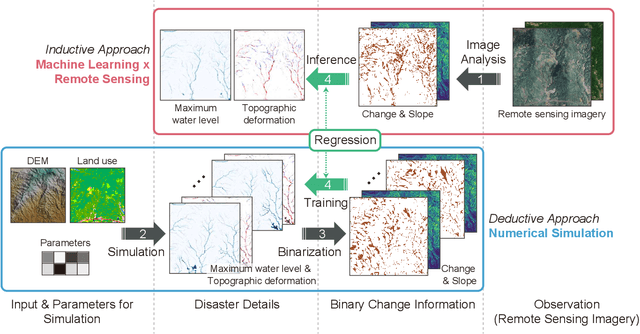
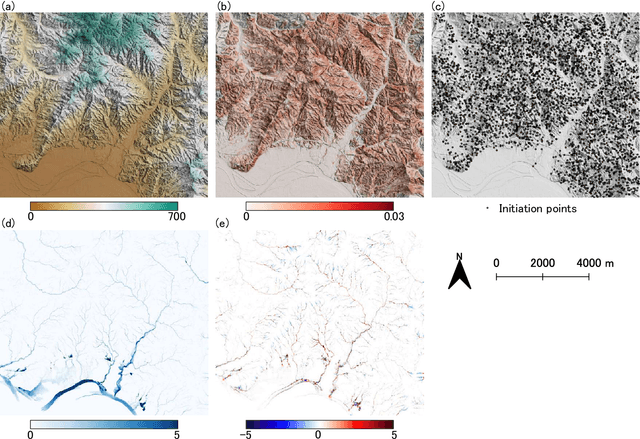
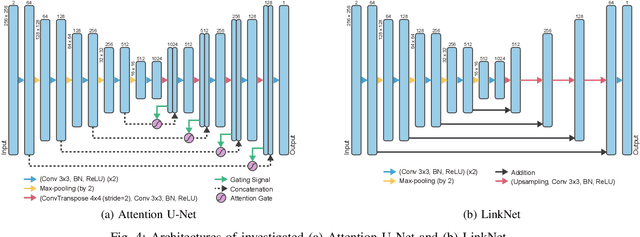
We propose a framework that estimates inundation depth (maximum water level) and debris-flow-induced topographic deformation from remote sensing imagery by integrating deep learning and numerical simulation. A water and debris flow simulator generates training data for various artificial disaster scenarios. We show that regression models based on Attention U-Net and LinkNet architectures trained on such synthetic data can predict the maximum water level and topographic deformation from a remote sensing-derived change detection map and a digital elevation model. The proposed framework has an inpainting capability, thus mitigating the false negatives that are inevitable in remote sensing image analysis. Our framework breaks the limits of remote sensing and enables rapid estimation of inundation depth and topographic deformation, essential information for emergency response, including rescue and relief activities. We conduct experiments with both synthetic and real data for two disaster events that caused simultaneous flooding and debris flows and demonstrate the effectiveness of our approach quantitatively and qualitatively.
Remix: Rebalanced Mixup
Jul 08, 2020
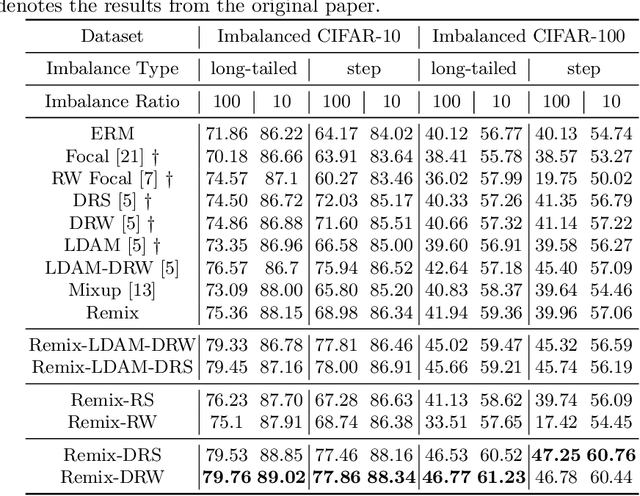
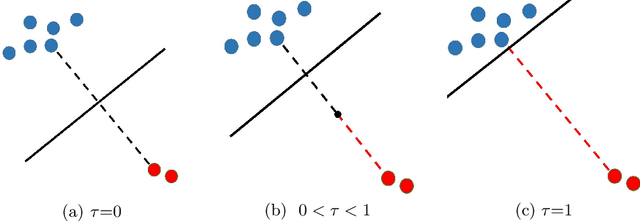
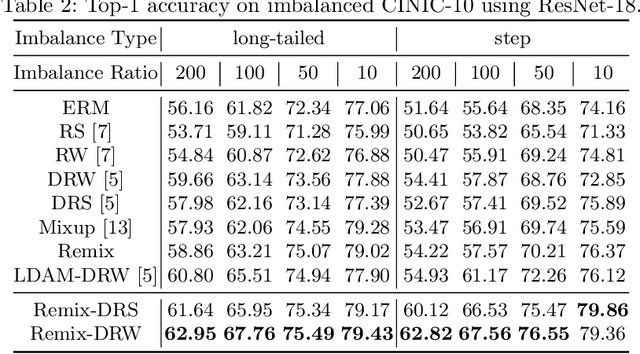
Deep image classifiers often perform poorly when training data are heavily class-imbalanced. In this work, we propose a new regularization technique, Remix, that relaxes Mixup's formulation and enables the mixing factors of features and labels to be disentangled. Specifically, when mixing two samples, while features are mixed up proportionally in the same fashion as Mixup methods, Remix assigns the label in favor of the minority class by providing a disproportionately higher weight to the minority class. By doing so, the classifier learns to push the decision boundaries towards the majority classes and balances the generalization error between majority and minority classes. We have studied the state of the art regularization techniques such as Mixup, Manifold Mixup and CutMix under class-imbalanced regime, and shown that the proposed Remix significantly outperforms these state-of-the-arts and several re-weighting and re-sampling techniques, on the imbalanced datasets constructed by CIFAR-10, CIFAR-100, and CINIC-10. We have also evaluated Remix on a real-world large-scale imbalanced dataset, iNaturalist 2018. The experimental results confirmed that Remix provides consistent and significant improvements over the previous state-of-the-arts.
Automated fetal brain extraction from clinical Ultrasound volumes using 3D Convolutional Neural Networks
Nov 19, 2019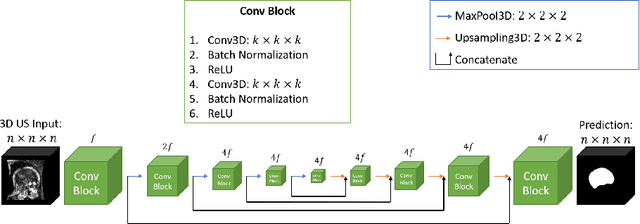
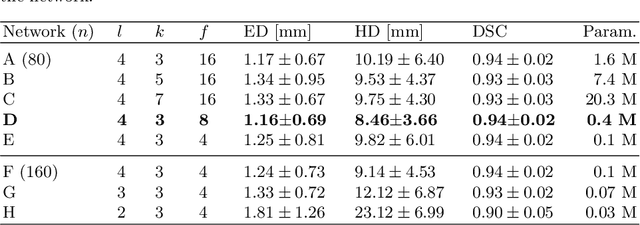
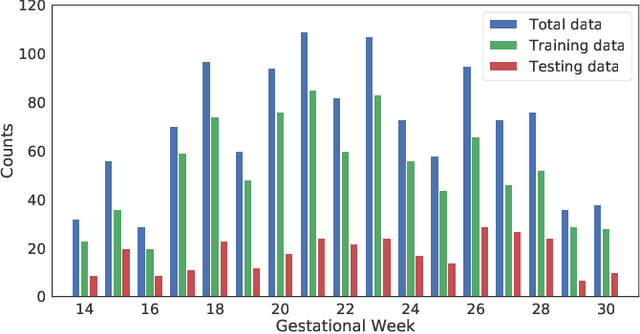
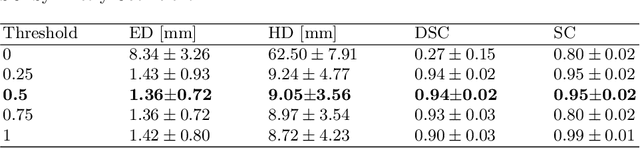
To improve the performance of most neuroimiage analysis pipelines, brain extraction is used as a fundamental first step in the image processing. But in the case of fetal brain development, there is a need for a reliable US-specific tool. In this work we propose a fully automated 3D CNN approach to fetal brain extraction from 3D US clinical volumes with minimal preprocessing. Our method accurately and reliably extracts the brain regardless of the large data variation inherent in this imaging modality. It also performs consistently throughout a gestational age range between 14 and 31 weeks, regardless of the pose variation of the subject, the scale, and even partial feature-obstruction in the image, outperforming all current alternatives.
Improving Image Classification with Location Context
May 14, 2015
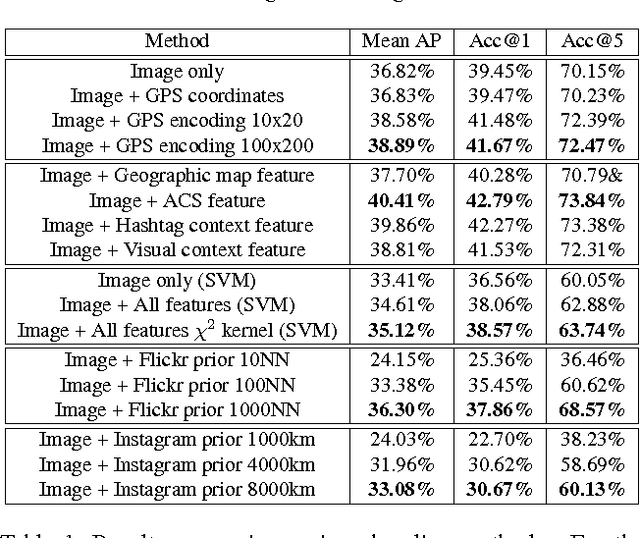
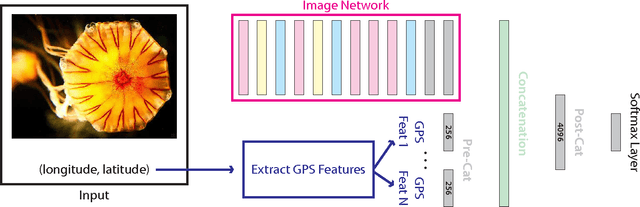
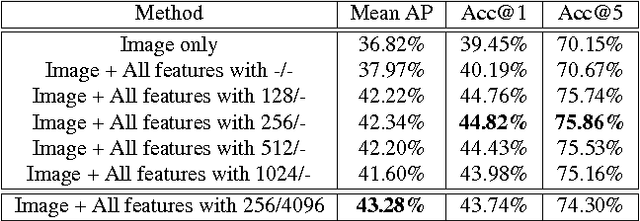
With the widespread availability of cellphones and cameras that have GPS capabilities, it is common for images being uploaded to the Internet today to have GPS coordinates associated with them. In addition to research that tries to predict GPS coordinates from visual features, this also opens up the door to problems that are conditioned on the availability of GPS coordinates. In this work, we tackle the problem of performing image classification with location context, in which we are given the GPS coordinates for images in both the train and test phases. We explore different ways of encoding and extracting features from the GPS coordinates, and show how to naturally incorporate these features into a Convolutional Neural Network (CNN), the current state-of-the-art for most image classification and recognition problems. We also show how it is possible to simultaneously learn the optimal pooling radii for a subset of our features within the CNN framework. To evaluate our model and to help promote research in this area, we identify a set of location-sensitive concepts and annotate a subset of the Yahoo Flickr Creative Commons 100M dataset that has GPS coordinates with these concepts, which we make publicly available. By leveraging location context, we are able to achieve almost a 7% gain in mean average precision.
Learned Proximal Networks for Quantitative Susceptibility Mapping
Aug 11, 2020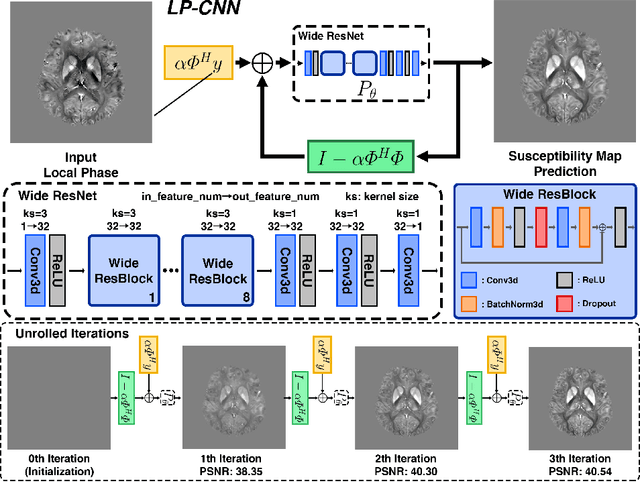
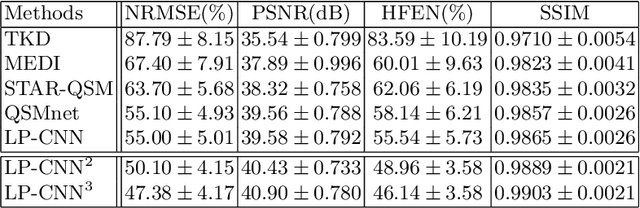
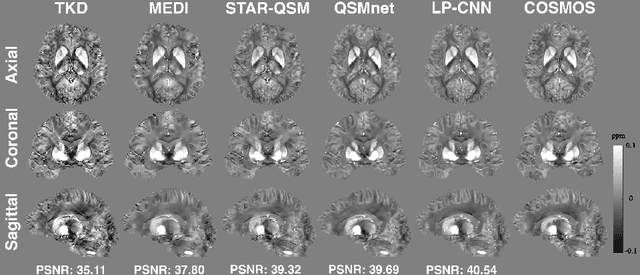

Quantitative Susceptibility Mapping (QSM) estimates tissue magnetic susceptibility distributions from Magnetic Resonance (MR) phase measurements by solving an ill-posed dipole inversion problem. Conventional single orientation QSM methods usually employ regularization strategies to stabilize such inversion, but may suffer from streaking artifacts or over-smoothing. Multiple orientation QSM such as calculation of susceptibility through multiple orientation sampling (COSMOS) can give well-conditioned inversion and an artifact free solution but has expensive acquisition costs. On the other hand, Convolutional Neural Networks (CNN) show great potential for medical image reconstruction, albeit often with limited interpretability. Here, we present a Learned Proximal Convolutional Neural Network (LP-CNN) for solving the ill-posed QSM dipole inversion problem in an iterative proximal gradient descent fashion. This approach combines the strengths of data-driven restoration priors and the clear interpretability of iterative solvers that can take into account the physical model of dipole convolution. During training, our LP-CNN learns an implicit regularizer via its proximal, enabling the decoupling between the forward operator and the data-driven parameters in the reconstruction algorithm. More importantly, this framework is believed to be the first deep learning QSM approach that can naturally handle an arbitrary number of phase input measurements without the need for any ad-hoc rotation or re-training. We demonstrate that the LP-CNN provides state-of-the-art reconstruction results compared to both traditional and deep learning methods while allowing for more flexibility in the reconstruction process.
Low-dimensional Manifold Constrained Disentanglement Network for Metal Artifact Reduction
Jul 08, 2020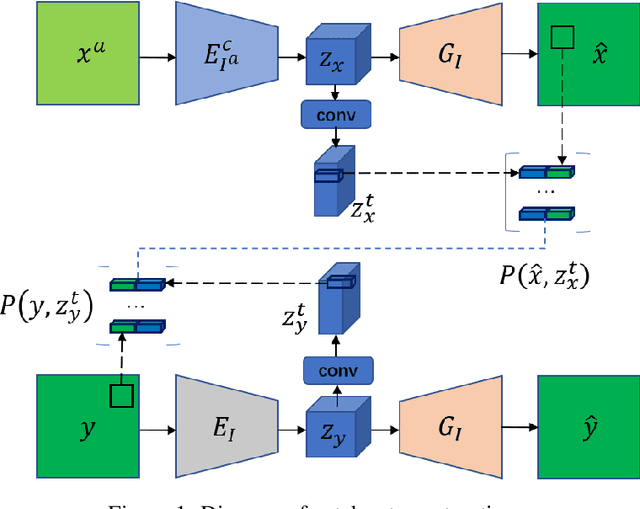
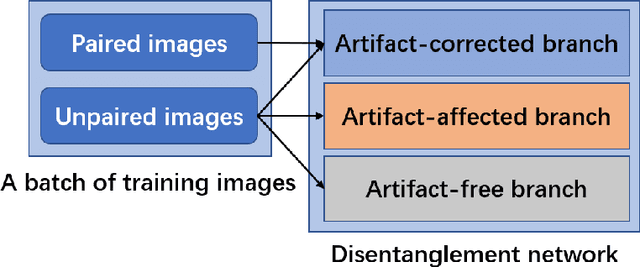
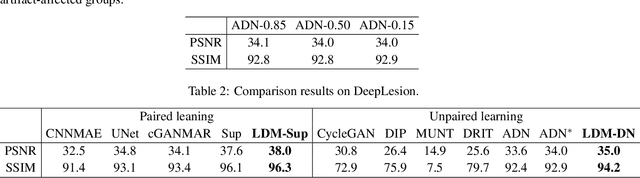
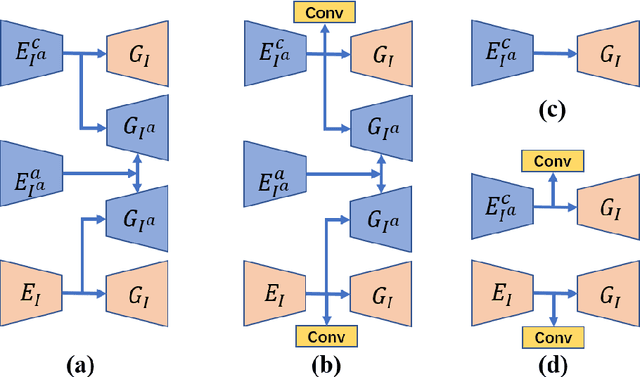
Deep neural network based methods have achieved promising results for CT metal artifact reduction (MAR), most of which use many synthesized paired images for training. As synthesized metal artifacts in CT images may not accurately reflect the clinical counterparts, an artifact disentanglement network (ADN) was proposed with unpaired clinical images directly, producing promising results on clinical datasets. However, without sufficient supervision, it is difficult for ADN to recover structural details of artifact-affected CT images based on adversarial losses only. To overcome these problems, here we propose a low-dimensional manifold (LDM) constrained disentanglement network (DN), leveraging the image characteristics that the patch manifold is generally low-dimensional. Specifically, we design an LDM-DN learning algorithm to empower the disentanglement network through optimizing the synergistic network loss functions while constraining the recovered images to be on a low-dimensional patch manifold. Moreover, learning from both paired and unpaired data, an efficient hybrid optimization scheme is proposed to further improve the MAR performance on clinical datasets. Extensive experiments demonstrate that the proposed LDM-DN approach can consistently improve the MAR performance in paired and/or unpaired learning settings, outperforming competing methods on synthesized and clinical datasets.
Event-based Asynchronous Sparse Convolutional Networks
Mar 20, 2020

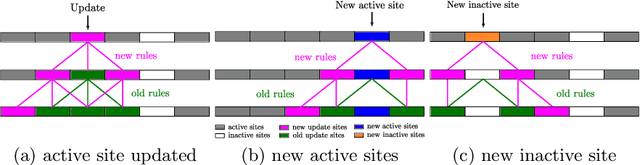
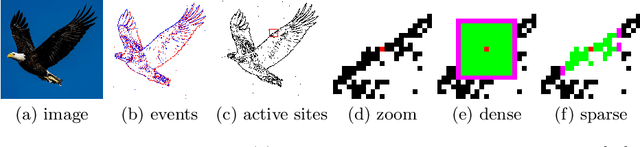
Event cameras are bio-inspired sensors that respond to per-pixel brightness changes in the form of asynchronous and sparse "events". Recently, pattern recognition algorithms, such as learning-based methods, have made significant progress with event cameras by converting events into synchronous dense, image-like representations and applying traditional machine learning methods developed for standard cameras. However, these approaches discard the spatial and temporal sparsity inherent in event data at the cost of higher computational complexity and latency. In this work, we present a general framework for converting models trained on synchronous image-like event representations into asynchronous models with identical output, thus directly leveraging the intrinsic asynchronous and sparse nature of the event data. We show both theoretically and experimentally that this drastically reduces the computational complexity and latency of high-capacity, synchronous neural networks without sacrificing accuracy. In addition, our framework has several desirable characteristics: (i) it exploits spatio-temporal sparsity of events explicitly, (ii) it is agnostic to the event representation, network architecture, and task, and (iii) it does not require any train-time change, since it is compatible with the standard neural networks' training process. We thoroughly validate the proposed framework on two computer vision tasks: object detection and object recognition. In these tasks, we reduce the computational complexity up to 20 times with respect to high-latency neural networks. At the same time, we outperform state-of-the-art asynchronous approaches up to 24% in prediction accuracy.
Art2Real: Unfolding the Reality of Artworks via Semantically-Aware Image-to-Image Translation
Nov 26, 2018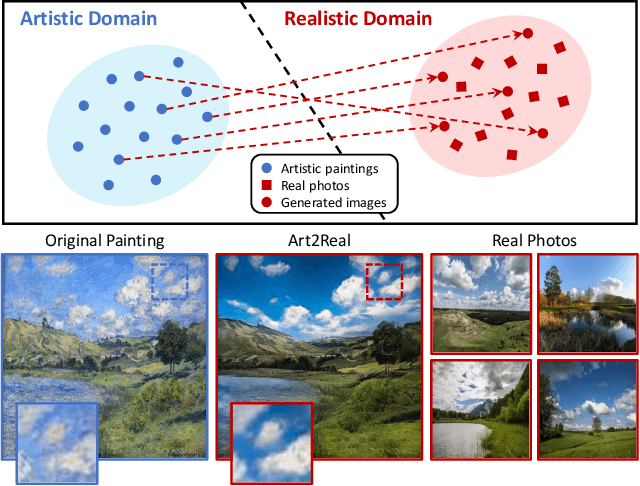
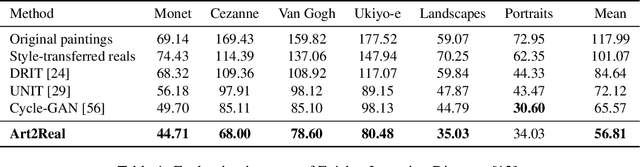
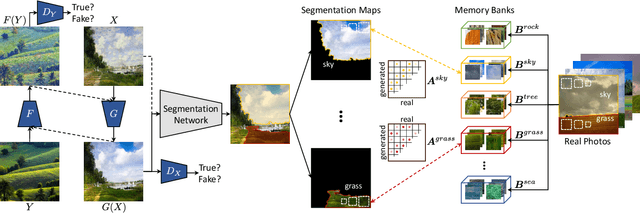

The applicability of computer vision to real paintings and artworks has been rarely investigated, even though a vast heritage would greatly benefit from techniques which can understand and process data from the artistic domain. This is partially due to the small amount of annotated artistic data, which is not even comparable to that of natural images captured by cameras. In this paper, we propose a semantic-aware architecture which can translate artworks to photo-realistic visualizations, thus reducing the gap between visual features of artistic and realistic data. Our architecture can generate natural images by retrieving and learning details from real photos through a similarity matching strategy which leverages a weakly-supervised semantic understanding of the scene. Experimental results show that the proposed technique leads to increased realism and to a reduction in domain shift, which improves the performance of pre-trained architectures for classification, detection, and segmentation. Code will be made publicly available.