 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Blind Inpainting of Large-scale Masks of Thin Structures with Adversarial and Reinforcement Learning
Dec 05, 2019
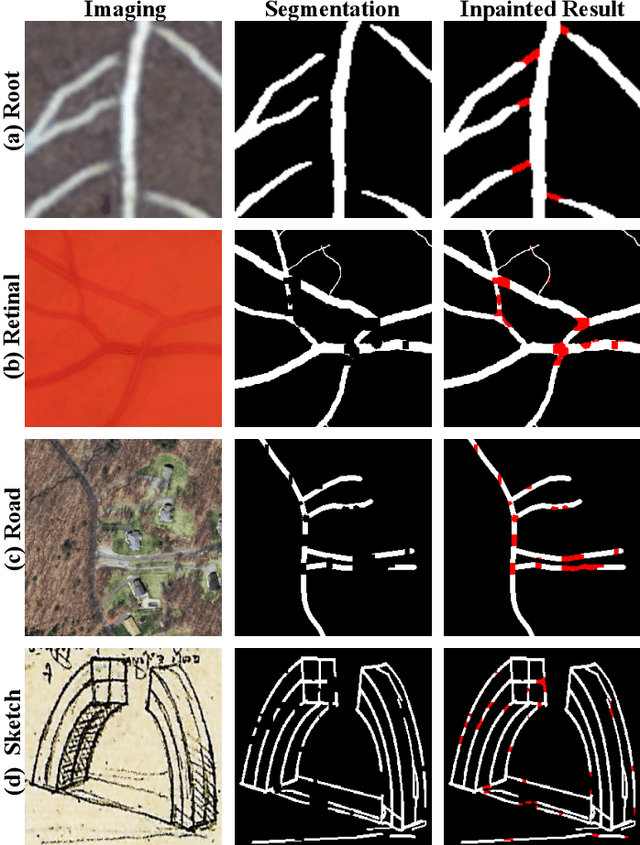
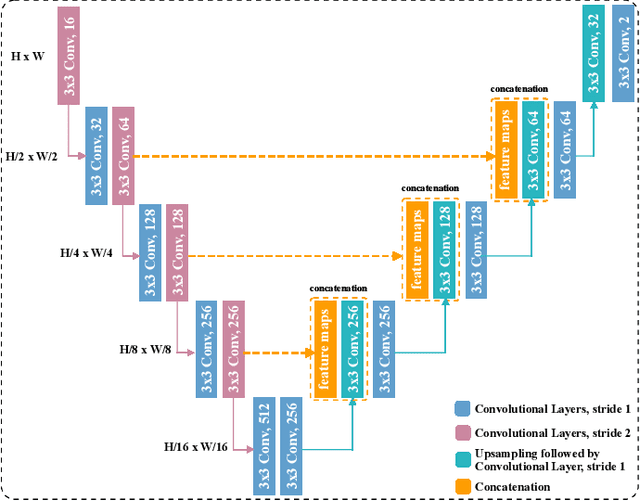
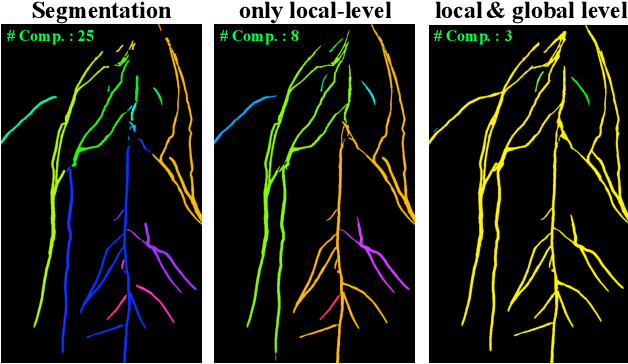
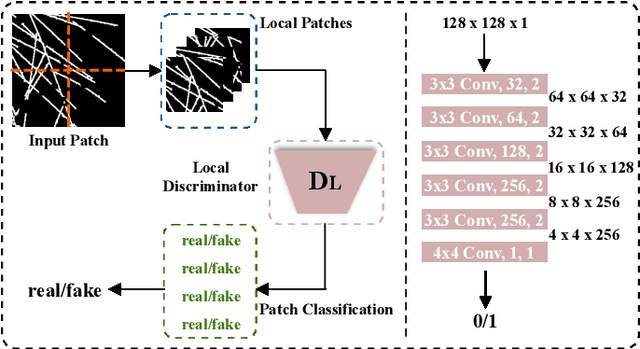
Several imaging applications (vessels, retina, plant roots, road networks from satellites) require the accurate segmentation of thin structures for subsequent analysis. Discontinuities (gaps) in the extracted foreground may hinder down-stream image-based analysis of biomarkers, organ structure and topology. In this paper, we propose a general post-processing technique to recover such gaps in large-scale segmentation masks. We cast this problem as a blind inpainting task, where the regions of missing lines in the segmentation masks are not known to the algorithm, which we solve with an adversarially trained neural network. One challenge of using large images is the memory capacity of current GPUs. The typical approach of dividing a large image into smaller patches to train the network does not guarantee global coherence of the reconstructed image that preserves structure and topology. We use adversarial training and reinforcement learning (Policy Gradient) to endow the model with both global context and local details. We evaluate our method in several datasets in medical imaging, plant science, and remote sensing. Our experiments demonstrate that our model produces the most realistic and complete inpainted results, outperforming other approaches. In a dedicated study on plant roots we find that our approach is also comparable to human performance. Implementation available at \url{https://github.com/Hhhhhhhhhhao/Thin-Structure-Inpainting}.
Image Co-localization by Mimicking a Good Detector's Confidence Score Distribution
Jul 23, 2016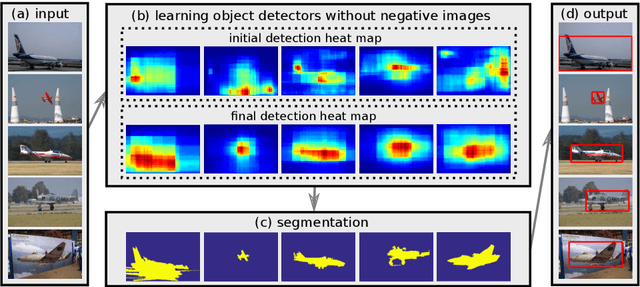

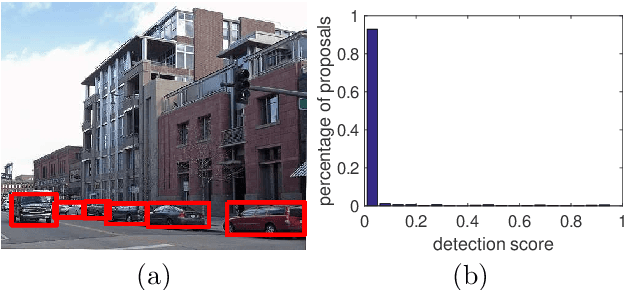
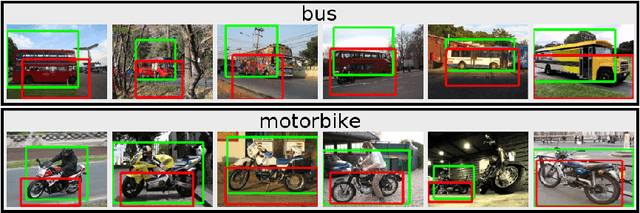
Given a set of images containing objects from the same category, the task of image co-localization is to identify and localize each instance. This paper shows that this problem can be solved by a simple but intriguing idea, that is, a common object detector can be learnt by making its detection confidence scores distributed like those of a strongly supervised detector. More specifically, we observe that given a set of object proposals extracted from an image that contains the object of interest, an accurate strongly supervised object detector should give high scores to only a small minority of proposals, and low scores to most of them. Thus, we devise an entropy-based objective function to enforce the above property when learning the common object detector. Once the detector is learnt, we resort to a segmentation approach to refine the localization. We show that despite its simplicity, our approach outperforms state-of-the-art methods.
DeepWarp: Photorealistic Image Resynthesis for Gaze Manipulation
Jul 26, 2016
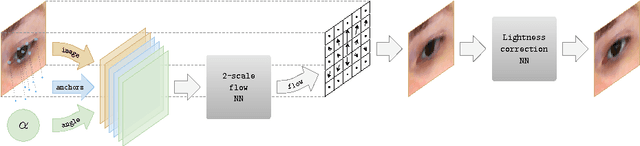
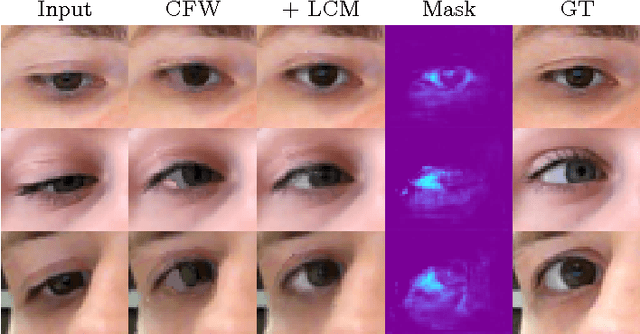
In this work, we consider the task of generating highly-realistic images of a given face with a redirected gaze. We treat this problem as a specific instance of conditional image generation and suggest a new deep architecture that can handle this task very well as revealed by numerical comparison with prior art and a user study. Our deep architecture performs coarse-to-fine warping with an additional intensity correction of individual pixels. All these operations are performed in a feed-forward manner, and the parameters associated with different operations are learned jointly in the end-to-end fashion. After learning, the resulting neural network can synthesize images with manipulated gaze, while the redirection angle can be selected arbitrarily from a certain range and provided as an input to the network.
Eelgrass beds and oyster farming at a lagoon before and after the Great East Japan Earthquake 2011: potential to apply deep learning at a coastal area
Sep 06, 2019
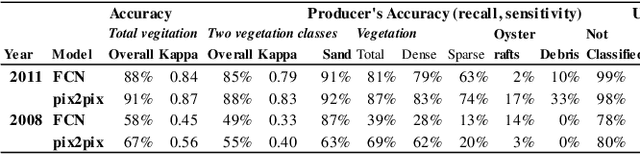
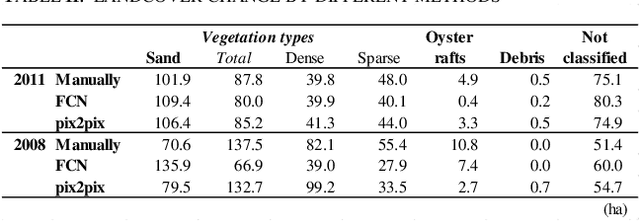
There is a small number of case studies of automatic land cover classification on the coastal area. Here, I test extraction of seagrass beds, sandy area, oyster farming rafts at Mangoku-ura Lagoon, Miyagi, Japan by comparing manual tracing, simple image segmentation, and image transformation using deep learning. The result was used to extract the changes before and after the earthquake and tsunami. The output resolution was best in the image transformation method, which showed more than 69% accuracy for vegetation classification by an assessment using random points on independent test data. The distribution of oyster farming rafts was detected by the segmentation model. Assessment of the change before and after the earthquake by the manual tracing and image transformation result revealed increase of sand area and decrease of the vegetation. By the segmentation model only the decrease of the oyster farming was detected. These results demonstrate the potential to extract the spatial pattern of these elements after an earthquake and tsunami. Index Terms: Great East Japan Earthquake of 2011, Land use land cover (LULC), Zosteracea seagrass, cultured oyster, deep learning, Mangoku Bay
HoughNet: Integrating near and long-range evidence for bottom-up object detection
Jul 05, 2020
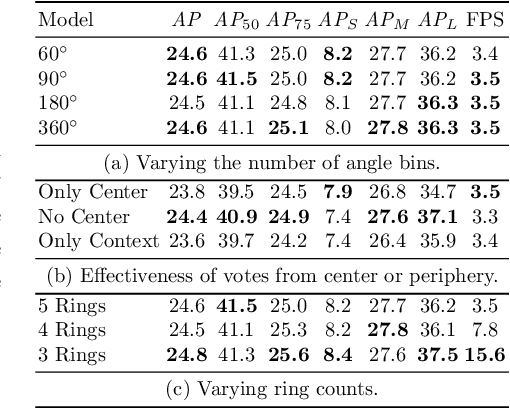
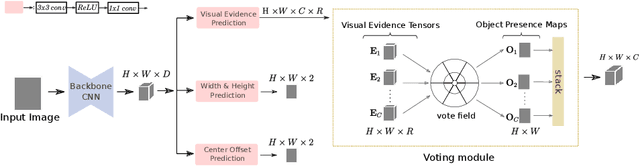
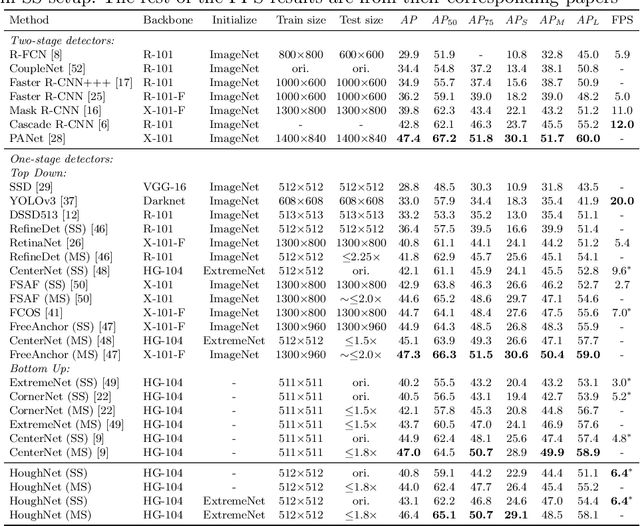
This paper presents HoughNet, a one-stage, anchor-free, voting-based, bottom-up object detection method. Inspired by the Generalized Hough Transform, HoughNet determines the presence of an object at a certain location by the sum of the votes cast on that location. Votes are collected from both near and long-distance locations based on a log-polar vote field. Thanks to this voting mechanism, HoughNet is able to integrate both near and long-range, class-conditional evidence for visual recognition, thereby generalizing and enhancing current object detection methodology, which typically relies on only local evidence. On the COCO dataset, HoughNet achieves 46.4 AP (and 65.1 AP_50), performing on par with the state-of-the-art in bottom-up object detection and outperforming most major one-stage and two-stage methods. We further validate the effectiveness of our proposal in another task, namely, "labels to photo" image generation by integrating the voting module of HoughNet to two different GAN models and showing that the accuracy is significantly improved in both cases. Code is available at: https://github.com/nerminsamet/houghnet
BiHand: Recovering Hand Mesh with Multi-stage Bisected Hourglass Networks
Aug 12, 20203D hand estimation has been a long-standing research topic in computer vision. A recent trend aims not only to estimate the 3D hand joint locations but also to recover the mesh model. However, achieving those goals from a single RGB image remains challenging. In this paper, we introduce an end-to-end learnable model, BiHand, which consists of three cascaded stages, namely 2D seeding stage, 3D lifting stage, and mesh generation stage. At the output of BiHand, the full hand mesh will be recovered using the joint rotations and shape parameters predicted from the network. Inside each stage, BiHand adopts a novel bisecting design which allows the networks to encapsulate two closely related information (e.g. 2D keypoints and silhouette in 2D seeding stage, 3D joints, and depth map in 3D lifting stage, joint rotations and shape parameters in the mesh generation stage) in a single forward pass. As the information represents different geometry or structure details, bisecting the data flow can facilitate optimization and increase robustness. For quantitative evaluation, we conduct experiments on two public benchmarks, namely the Rendered Hand Dataset (RHD) and the Stereo Hand Pose Tracking Benchmark (STB). Extensive experiments show that our model can achieve superior accuracy in comparison with state-of-the-art methods, and can produce appealing 3D hand meshes in several severe conditions.
Regression-Based Image Alignment for General Object Categories
Jul 08, 2014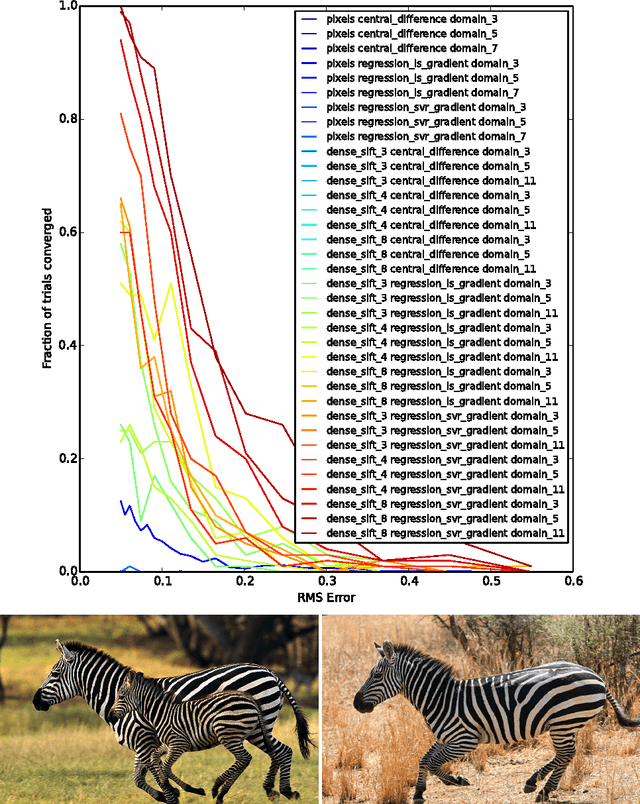


Gradient-descent methods have exhibited fast and reliable performance for image alignment in the facial domain, but have largely been ignored by the broader vision community. They require the image function be smooth and (numerically) differentiable -- properties that hold for pixel-based representations obeying natural image statistics, but not for more general classes of non-linear feature transforms. We show that transforms such as Dense SIFT can be incorporated into a Lucas Kanade alignment framework by predicting descent directions via regression. This enables robust matching of instances from general object categories whilst maintaining desirable properties of Lucas Kanade such as the capacity to handle high-dimensional warp parametrizations and a fast rate of convergence. We present alignment results on a number of objects from ImageNet, and an extension of the method to unsupervised joint alignment of objects from a corpus of images.
Explaining The Behavior Of Black-Box Prediction Algorithms With Causal Learning
Jun 03, 2020


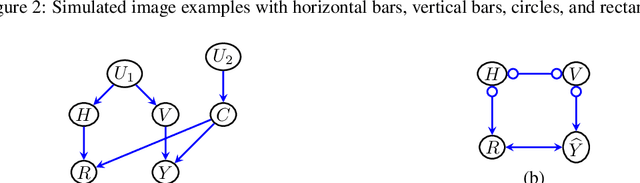
We propose to explain the behavior of black-box prediction methods (e.g., deep neural networks trained on image pixel data) using causal graphical models. Specifically, we explore learning the structure of a causal graph where the nodes represent prediction outcomes along with a set of macro-level "interpretable" features, while allowing for arbitrary unmeasured confounding among these variables. The resulting graph may indicate which of the interpretable features, if any, are possible causes of the prediction outcome and which may be merely associated with prediction outcomes due to confounding. The approach is motivated by a counterfactual theory of causal explanation wherein good explanations point to factors which are "difference-makers" in an interventionist sense. The resulting analysis may be useful in algorithm auditing and evaluation, by identifying features which make a causal difference to the algorithm's output.
Aerial image geolocalization from recognition and matching of roads and intersections
May 26, 2016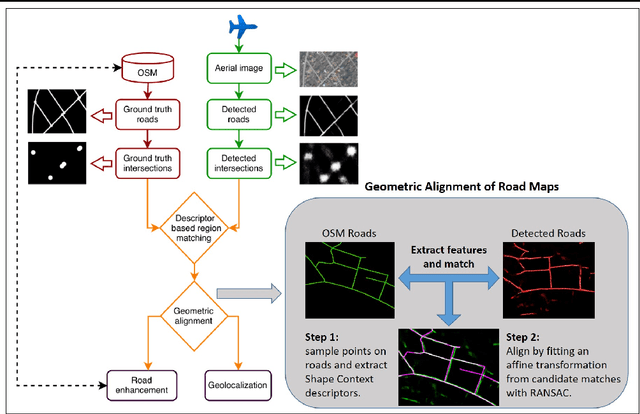
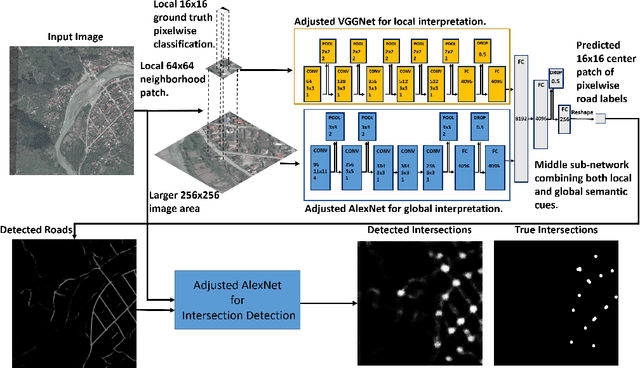
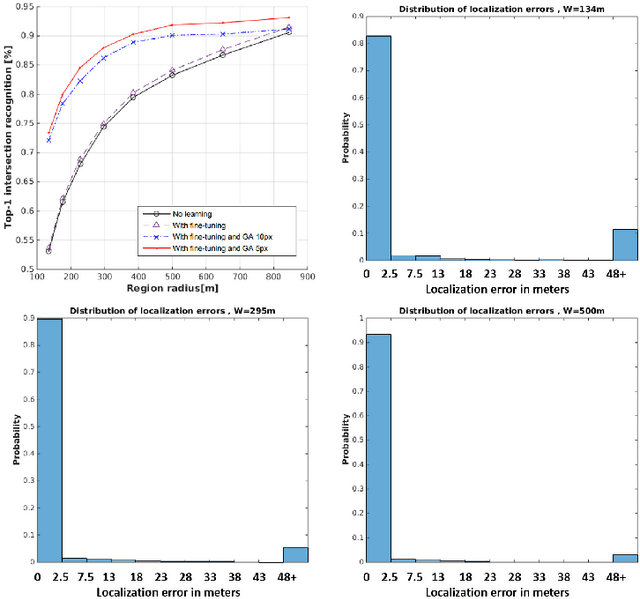

Aerial image analysis at a semantic level is important in many applications with strong potential impact in industry and consumer use, such as automated mapping, urban planning, real estate and environment monitoring, or disaster relief. The problem is enjoying a great interest in computer vision and remote sensing, due to increased computer power and improvement in automated image understanding algorithms. In this paper we address the task of automatic geolocalization of aerial images from recognition and matching of roads and intersections. Our proposed method is a novel contribution in the literature that could enable many applications of aerial image analysis when GPS data is not available. We offer a complete pipeline for geolocalization, from the detection of roads and intersections, to the identification of the enclosing geographic region by matching detected intersections to previously learned manually labeled ones, followed by accurate geometric alignment between the detected roads and the manually labeled maps. We test on a novel dataset with aerial images of two European cities and use the publicly available OpenStreetMap project for collecting ground truth roads annotations. We show in extensive experiments that our approach produces highly accurate localizations in the challenging case when we train on images from one city and test on the other and the quality of the aerial images is relatively poor. We also show that the the alignment between detected roads and pre-stored manual annotations can be effectively used for improving the quality of the road detection results.
Pan-Cancer Diagnostic Consensus Through Searching Archival Histopathology Images Using Artificial Intelligence
Nov 20, 2019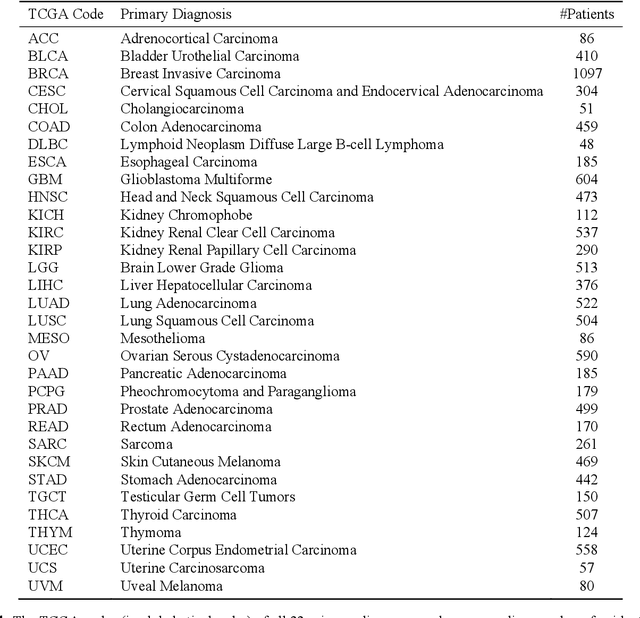
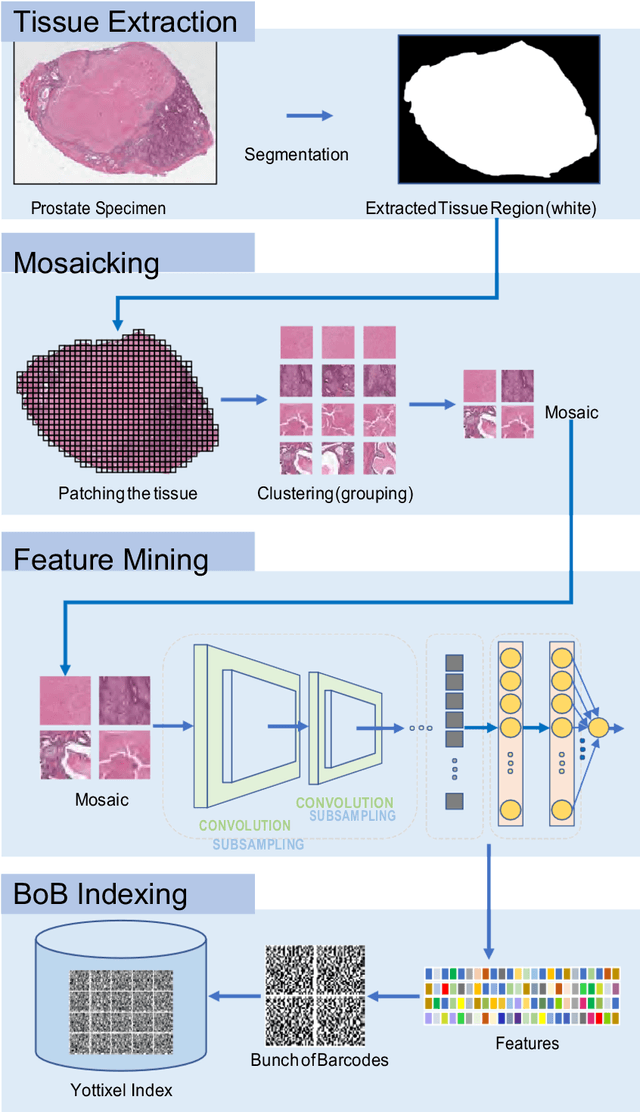
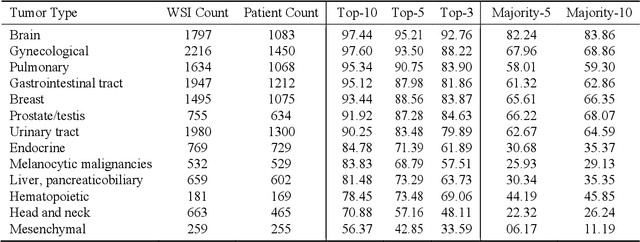
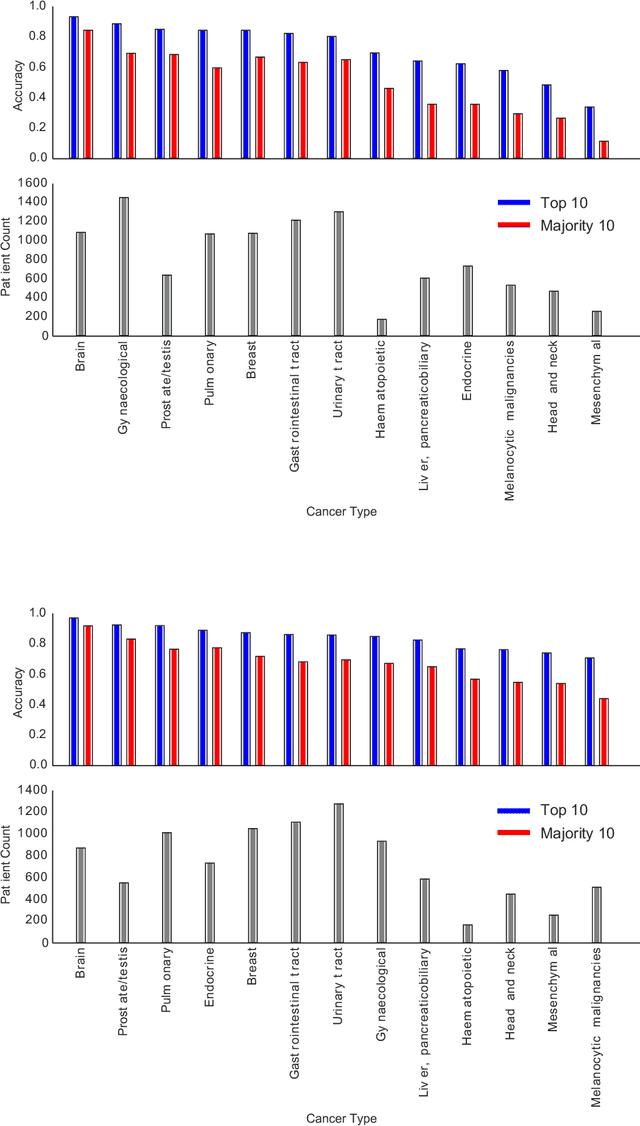
The emergence of digital pathology has opened new horizons for histopathology and cytology. Artificial-intelligence algorithms are able to operate on digitized slides to assist pathologists with diagnostic tasks. Whereas machine learning involving classification and segmentation methods have obvious benefits for image analysis in pathology, image search represents a fundamental shift in computational pathology. Matching the pathology of new patients with already diagnosed and curated cases offers pathologist a novel approach to improve diagnostic accuracy through visual inspection of similar cases and computational majority vote for consensus building. In this study, we report the results from searching the largest public repository (The Cancer Genome Atlas [TCGA] program by National Cancer Institute, USA) of whole slide images from almost 11,000 patients depicting different types of malignancies. For the first time, we successfully indexed and searched almost 30,000 high-resolution digitized slides constituting 16 terabytes of data comprised of 20 million 1000x1000 pixels image patches. The TCGA image database covers 25 anatomic sites and contains 32 cancer subtypes. High-performance storage and GPU power were employed for experimentation. The results were assessed with conservative "majority voting" to build consensus for subtype diagnosis through vertical search and demonstrated high accuracy values for both frozen sections slides (e.g., bladder urothelial carcinoma 93%, kidney renal clear cell carcinoma 97%, and ovarian serous cystadenocarcinoma 99%) and permanent histopathology slides (e.g., prostate adenocarcinoma 98%, skin cutaneous melanoma 99%, and thymoma 100%). The key finding of this validation study was that computational consensus appears to be possible for rendering diagnoses if a sufficiently large number of searchable cases are available for each cancer subtype.