 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AdaScale SGD: A User-Friendly Algorithm for Distributed Training
Jul 09, 2020
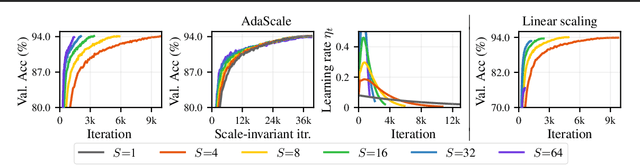

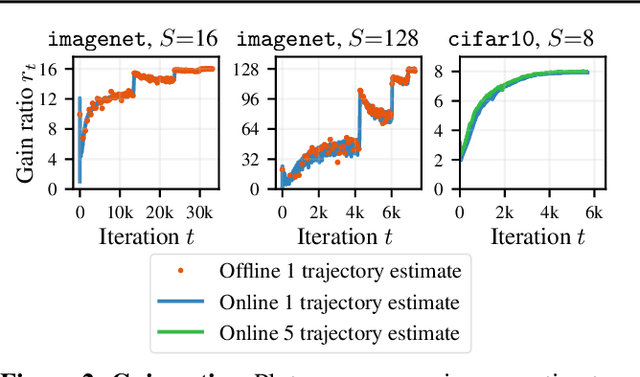
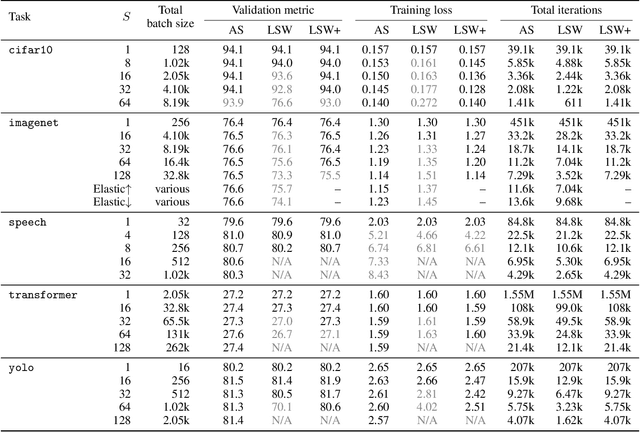
When using large-batch training to speed up stochastic gradient descent, learning rates must adapt to new batch sizes in order to maximize speed-ups and preserve model quality. Re-tuning learning rates is resource intensive, while fixed scaling rules often degrade model quality. We propose AdaScale SGD, an algorithm that reliably adapts learning rates to large-batch training. By continually adapting to the gradient's variance, AdaScale automatically achieves speed-ups for a wide range of batch sizes. We formally describe this quality with AdaScale's convergence bound, which maintains final objective values, even as batch sizes grow large and the number of iterations decreases. In empirical comparisons, AdaScale trains well beyond the batch size limits of popular "linear learning rate scaling" rules. This includes large-batch training with no model degradation for machine translation, image classification, object detection, and speech recognition tasks. AdaScale's qualitative behavior is similar to that of "warm-up" heuristics, but unlike warm-up, this behavior emerges naturally from a principled mechanism. The algorithm introduces negligible computational overhead and no new hyperparameters, making AdaScale an attractive choice for large-scale training in practice.
TACO: Trash Annotations in Context for Litter Detection
Mar 17, 2020
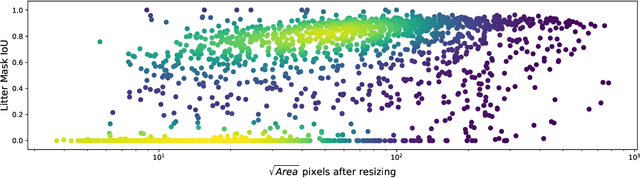


TACO is an open image dataset for litter detection and segmentation, which is growing through crowdsourcing. Firstly, this paper describes this dataset and the tools developed to support it. Secondly, we report instance segmentation performance using Mask R-CNN on the current version of TACO. Despite its small size (1500 images and 4784 annotations), our results are promising on this challenging problem. However, to achieve satisfactory trash detection in the wild for deployment, TACO still needs much more manual annotations. These can be contributed using: http://tacodataset.org/
What am I Searching for: Zero-shot Target Identity Inference in Visual Search
May 25, 2020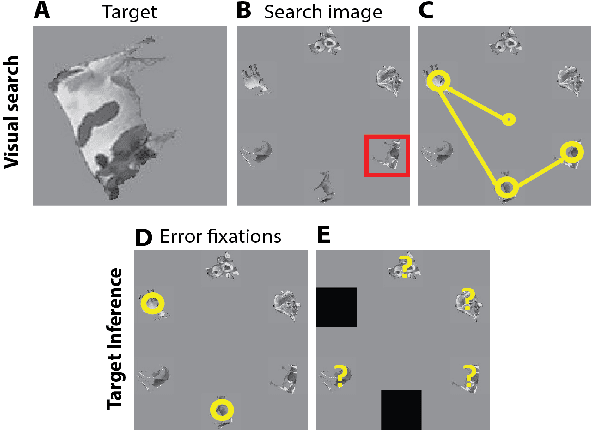
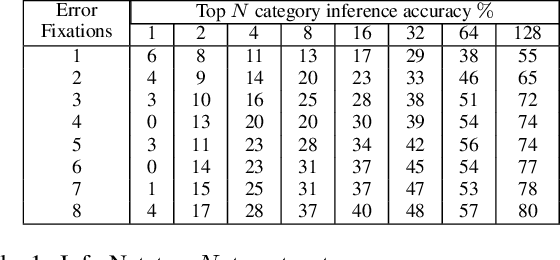
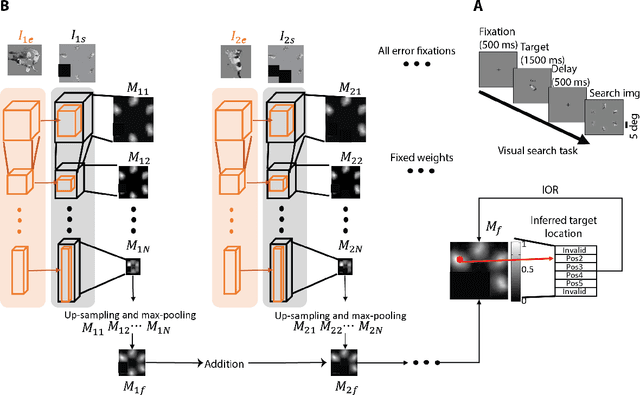
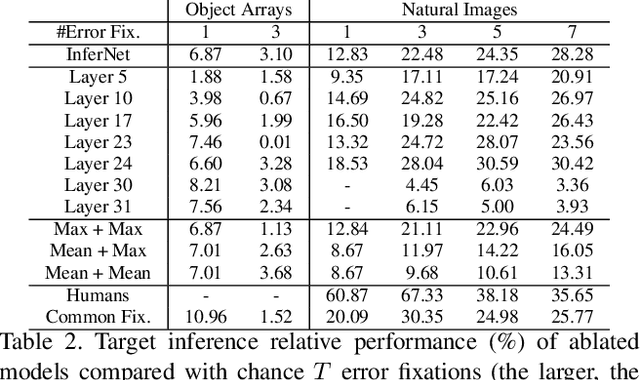
Can we infer intentions from a person's actions? As an example problem, here we consider how to decipher what a person is searching for by decoding their eye movement behavior. We conducted two psychophysics experiments where we monitored eye movements while subjects searched for a target object. We defined the fixations falling on \textit{non-target} objects as "error fixations". Using those error fixations, we developed a model (InferNet) to infer what the target was. InferNet uses a pre-trained convolutional neural network to extract features from the error fixations and computes a similarity map between the error fixations and all locations across the search image. The model consolidates the similarity maps across layers and integrates these maps across all error fixations. InferNet successfully identifies the subject's goal and outperforms competitive null models, even without any object-specific training on the inference task.
LeafGAN: An Effective Data Augmentation Method for Practical Plant Disease Diagnosis
Feb 24, 2020
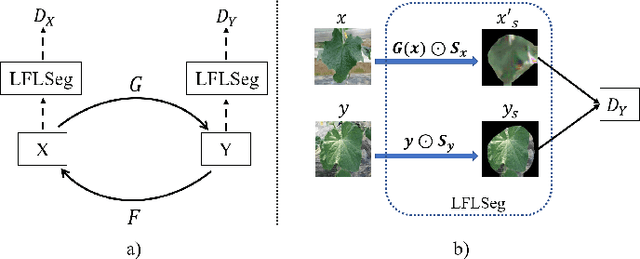


Many applications for the automated diagnosis of plant disease have been developed based on the success of deep learning techniques. However, these applications often suffer from overfitting, and the diagnostic performance is drastically decreased when used on test datasets from new environments. The typical reasons for this are that the symptoms to be detected are unclear or faint, and there are limitations related to data diversity. In this paper, we propose LeafGAN, a novel image-to-image translation system with own attention mechanism. LeafGAN generates a wide variety of diseased images via transformation from healthy images, as a data augmentation tool for improving the performance of plant disease diagnosis. Thanks to its own attention mechanism, our model can transform only relevant areas from images with a variety of backgrounds, thus enriching the versatility of the training images. Experiments with five-class cucumber disease classification show that data augmentation with vanilla CycleGAN cannot help to improve the generalization, i.e. disease diagnostic performance increased by only 0.7% from the baseline. In contrast, LeafGAN boosted the diagnostic performance by 7.4%. We also visually confirmed the generated images by our LeafGAN were much better quality and more convincing than those generated by vanilla CycleGAN.
Assignment Flow for Order-Constrained OCT Segmentation
Sep 10, 2020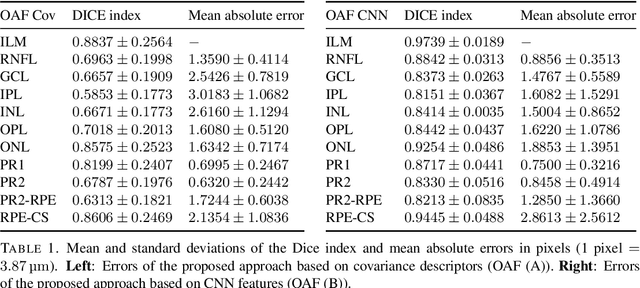

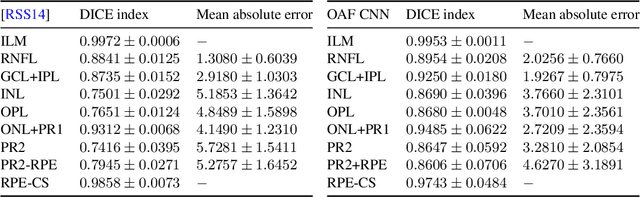
At the present time Optical Coherence Tomography (OCT) is among the most commonly used non-invasive imaging methods for the acquisition of large volumetric scans of human retinal tissues and vasculature. To resolve decisive information from extracted OCT volumes and to make it applicable for further diagnostic analysis, the exact identification of retinal layer thicknesses serves as an essential task be done for each patient separately. However, the manual examination of multiple OCT scans in a row is a demanding and time consuming task, which results in a lengthy qualification process and is frequently confounded in the presence of tissue-dependent speckle noise. Therefore, the elaboration of automated segmentation models has become an important task in the field of medical image processing. We propose a novel, purely data driven \textit{geometric approach to order-constrained 3D OCT retinal cell layer segmentation} which takes as input data in any metric space and comes along with basic operations that can be effectively computed in parallel. As opposed to many established retina detection methods, our presented formulation avoids the use of any shape prior and accomplishes the natural order of the retina in a purely geometric way. This makes the approach unbiased and hence suited for the detection of local anatomical changes of retinal tissue structure. To demonstrate robustness of the proposed approach, we compare two different choices of features on a data set of manually annotated 3D OCT volumes of healthy human retina. The quality of computed segmentations is compared to the state of the art in terms of mean absolute error and the Dice similarity coefficient. The results indicate a great potential for applying our method to the classification of diseased retina and opens a new research direction regarding the joint segmentation of retinal cell layers and blood vessel structures.
Deep Networks with Fast Retraining
Aug 13, 2020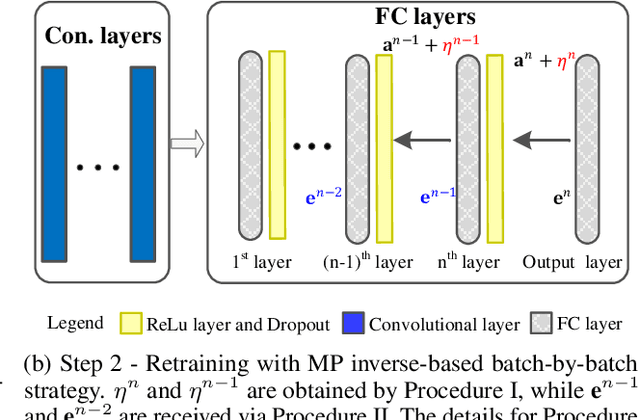
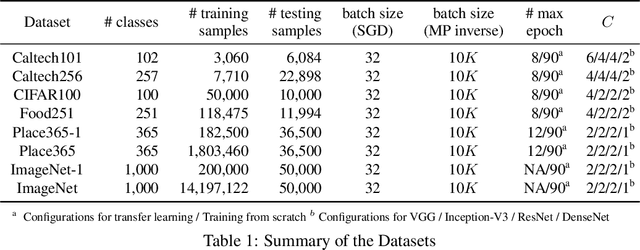
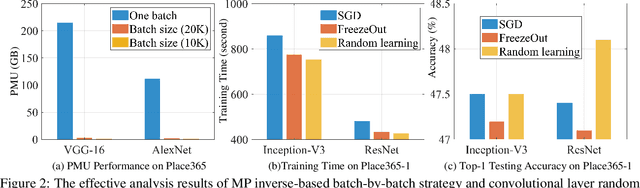
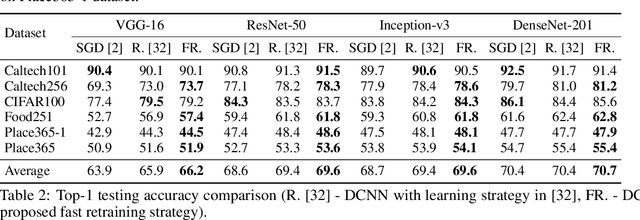
Recent wor [1] has utilized Moore-Penrose (MP) inverse in deep convolutional neural network (DCNN) training, which achieves better generalization performance over the DCNN with a stochastic gradient descent (SGD) pipeline. However, the MP technique cannot be processed in the GPU environment due to its high demands of computational resources. This paper proposes a fast DCNN learning strategy with MP inverse to achieve better testing performance without introducing a large calculation burden. We achieve this goal through an SGD and MP inverse-based two-stage training procedure. In each training epoch, a random learning strategy that controls the number of convolutional layers trained in backward pass is utilized, and an MP inverse-based batch-by-batch learning strategy is developed that enables the network to be implemented with GPU acceleration and to refine the parameters in dense layer. Through experiments on image classification datasets with various training images ranging in amount from 3,060 (Caltech101) to 1,803,460 (Place365), we empirically demonstrate that the fast retraining is a unified strategy that can be utilized in all DCNNs. Our method obtains up to 1% Top-1 testing accuracy boosts over the state-of-the-art DCNN learning pipeline, yielding a savings in training time of 15% to 25% over the work in [1]. [1] Y. Yang, J. Wu, X. Feng, and A. Thangarajah, "Recomputation of dense layers for the perfor-238mance improvement of dcnn," IEEE Trans. Pattern Anal. Mach. Intell., 2019.
Q-CapsNets: A Specialized Framework for Quantizing Capsule Networks
Apr 15, 2020
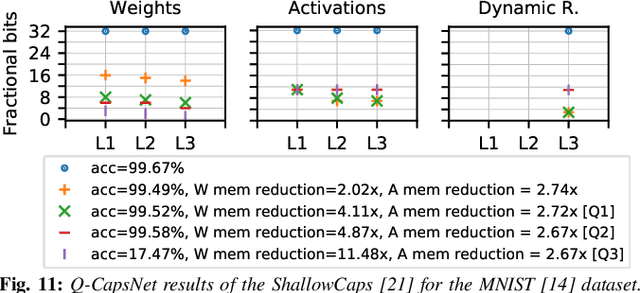
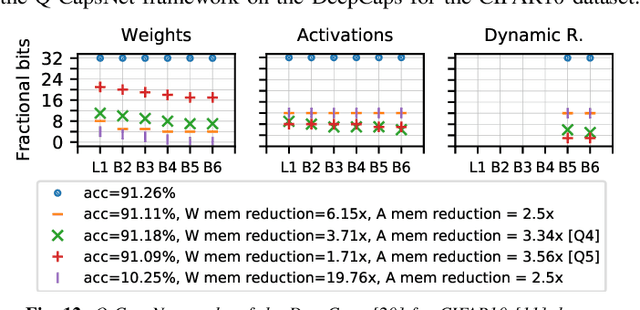
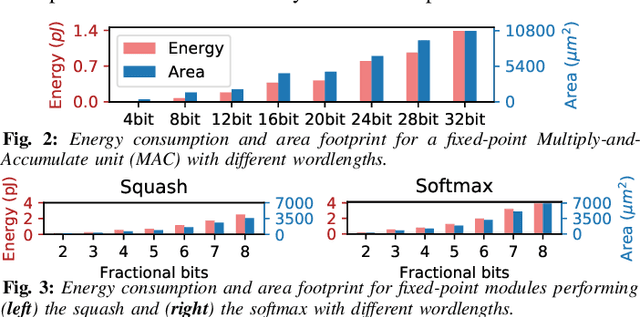
Capsule Networks (CapsNets), recently proposed by the Google Brain team, have superior learning capabilities in machine learning tasks, like image classification, compared to the traditional CNNs. However, CapsNets require extremely intense computations and are difficult to be deployed in their original form at the resource-constrained edge devices. This paper makes the first attempt to quantize CapsNet models, to enable their efficient edge implementations, by developing a specialized quantization framework for CapsNets. We evaluate our framework for several benchmarks. On a deep CapsNet model for the CIFAR10 dataset, the framework reduces the memory footprint by 6.2x, with only 0.15% accuracy loss. We will open-source our framework at https://git.io/JvDIF.
Empirical evaluation of full-reference image quality metrics on MDID database
Oct 02, 2019
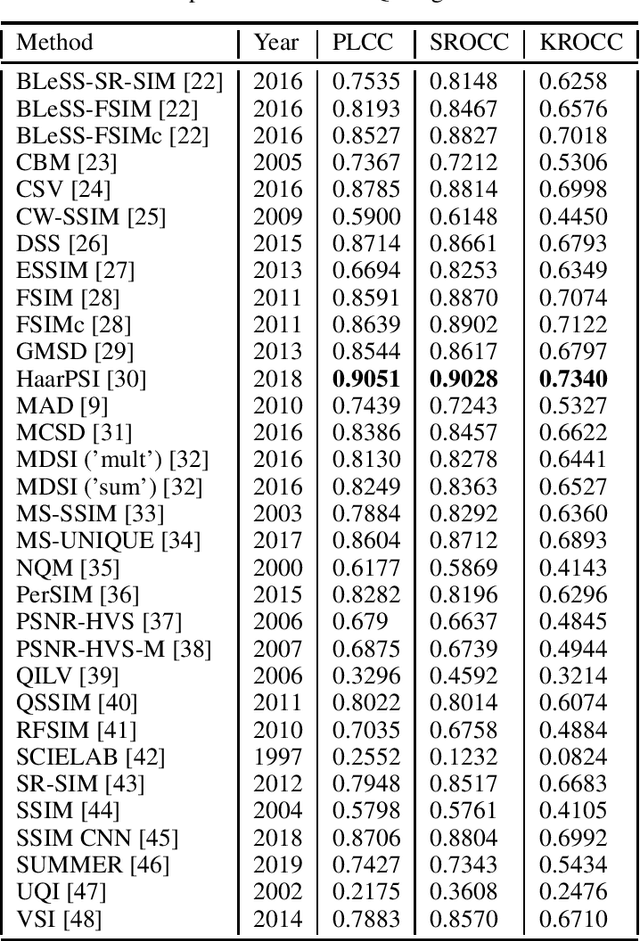
In this study, our goal is to give a comprehensive evaluation of 32 state-of-the-art FR-IQA metrics using the recently published MDID. This database contains distorted images derived from a set of reference, pristine images using random types and levels of distortions. Specifically, Gaussian noise, Gaussian blur, contrast change, JPEG noise, and JPEG2000 noise were considered.
Edge-aware Graph Representation Learning and Reasoning for Face Parsing
Jul 22, 2020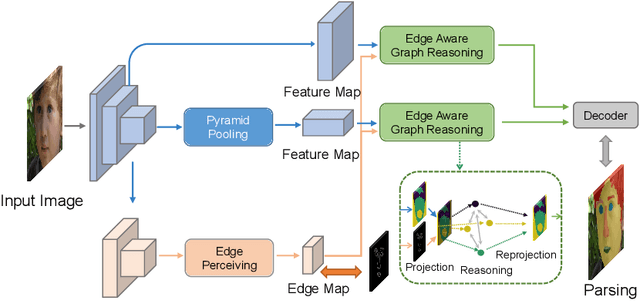
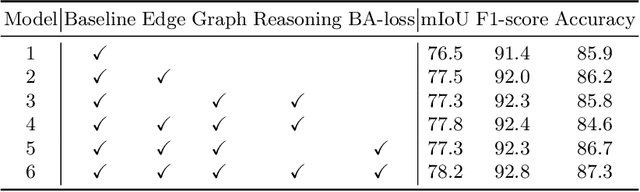
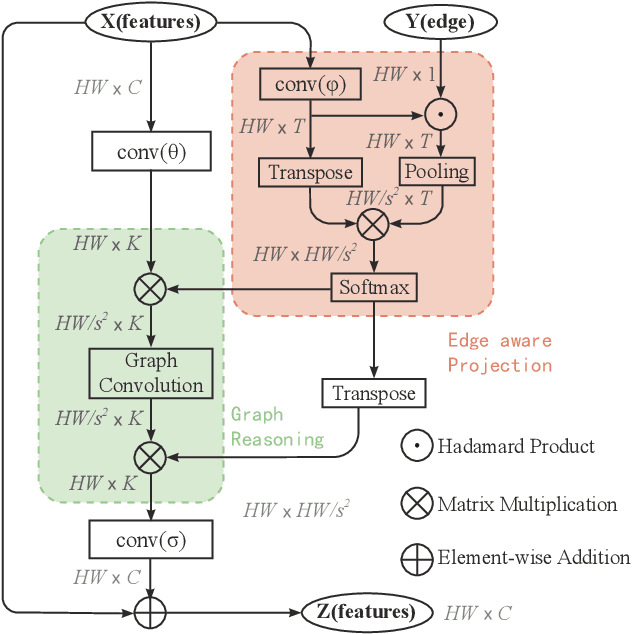

Face parsing infers a pixel-wise label to each facial component, which has drawn much attention recently. Previous methods have shown their efficiency in face parsing, which however overlook the correlation among different face regions. The correlation is a critical clue about the facial appearance, pose, expression etc., and should be taken into account for face parsing. To this end, we propose to model and reason the region-wise relations by learning graph representations, and leverage the edge information between regions for optimized abstraction. Specifically, we encode a facial image onto a global graph representation where a collection of pixels ("regions") with similar features are projected to each vertex. Our model learns and reasons over relations between the regions by propagating information across vertices on the graph. Furthermore, we incorporate the edge information to aggregate the pixel-wise features onto vertices, which emphasizes on the features around edges for fine segmentation along edges. The finally learned graph representation is projected back to pixel grids for parsing. Experiments demonstrate that our model outperforms state-of-the-art methods on the widely used Helen dataset, and also exhibits the superior performance on the large-scale CelebAMask-HQ and LaPa dataset. The code is available at https://github.com/tegusi/EAGRNet.
Cross-Domain Conditional Generative Adversarial Networks for Stereoscopic Hyperrealism in Surgical Training
Jun 24, 2019

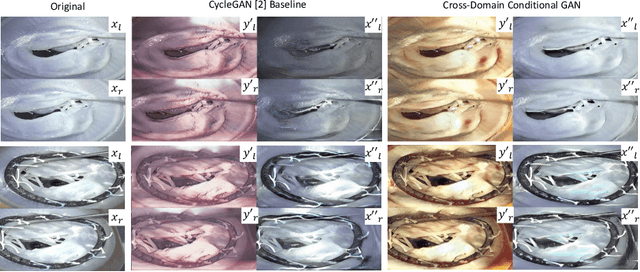
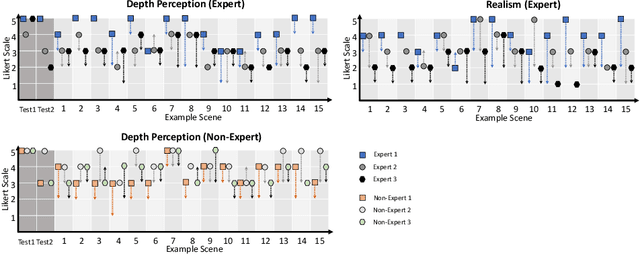
Phantoms for surgical training are able to mimic cutting and suturing properties and patient-individual shape of organs, but lack a realistic visual appearance that captures the heterogeneity of surgical scenes. In order to overcome this in endoscopic approaches, hyperrealistic concepts have been proposed to be used in an augmented reality-setting, which are based on deep image-to-image transformation methods. Such concepts are able to generate realistic representations of phantoms learned from real intraoperative endoscopic sequences. Conditioned on frames from the surgical training process, the learned models are able to generate impressive results by transforming unrealistic parts of the image (e.g.\ the uniform phantom texture is replaced by the more heterogeneous texture of the tissue). Image-to-image synthesis usually learns a mapping $G:X~\to~Y$ such that the distribution of images from $G(X)$ is indistinguishable from the distribution $Y$. However, it does not necessarily force the generated images to be consistent and without artifacts. In the endoscopic image domain this can affect depth cues and stereo consistency of a stereo image pair, which ultimately impairs surgical vision. We propose a cross-domain conditional generative adversarial network approach (GAN) that aims to generate more consistent stereo pairs. The results show substantial improvements in depth perception and realism evaluated by 3 domain experts and 3 medical students on a 3D monitor over the baseline method. In 84 of 90 instances our proposed method was preferred or rated equal to the baseline.