 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distortion Estimation Through Explicit Modeling of the Refractive Surface
Sep 24, 2019
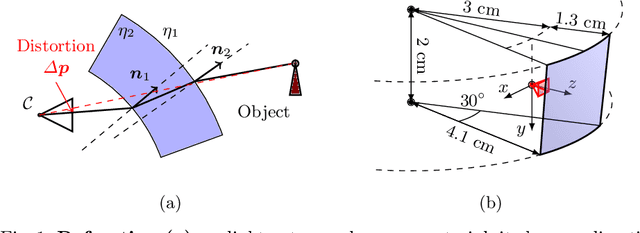
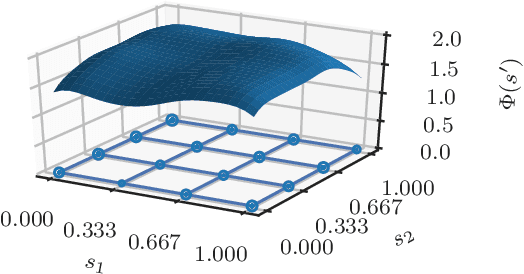
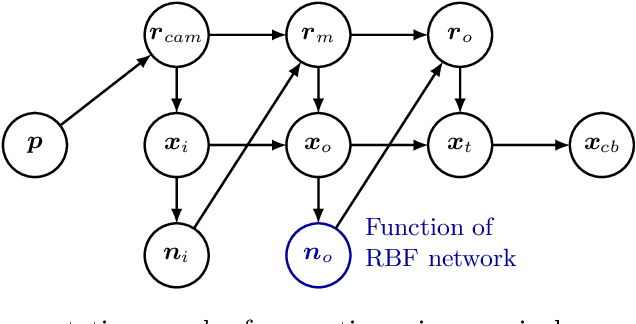

Precise calibration is a must for high reliance 3D computer vision algorithms. A challenging case is when the camera is behind a protective glass or transparent object: due to refraction, the image is heavily distorted; the pinhole camera model alone can not be used and a distortion correction step is required. By directly modeling the geometry of the refractive media, we build the image generation process by tracing individual light rays from the camera to a target. Comparing the generated images to their distorted - observed - counterparts, we estimate the geometry parameters of the refractive surface via model inversion by employing an RBF neural network. We present an image collection methodology that produces data suited for finding the distortion parameters and test our algorithm on synthetic and real-world data. We analyze the results of the algorithm.
* Accepted to ICANN 2019
When Relation Networks meet GANs: Relation GANs with Triplet Loss
Feb 25, 2020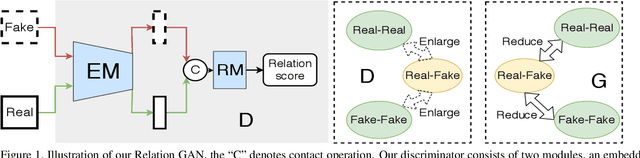
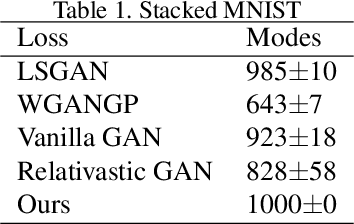
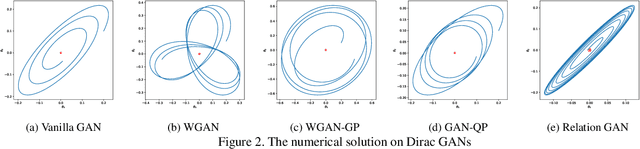
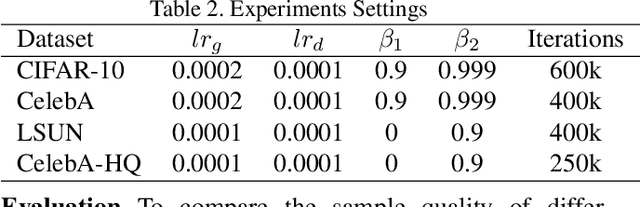
Though recent research has achieved remarkable progress in generating realistic images with generative adversarial networks (GANs), the lack of training stability is still a lingering concern of most GANs, especially on high-resolution inputs and complex datasets. Since the randomly generated distribution can hardly overlap with the real distribution, training GANs often suffers from the gradient vanishing problem. A number of approaches have been proposed to address this issue by constraining the discriminator's capabilities using empirical techniques, like weight clipping, gradient penalty, spectral normalization etc. In this paper, we provide a more principled approach as an alternative solution to this issue. Instead of training the discriminator to distinguish real and fake input samples, we investigate the relationship between paired samples by training the discriminator to separate paired samples from the same distribution and those from different distributions. To this end, we explore a relation network architecture for the discriminator and design a triplet loss which performs better generalization and stability. Extensive experiments on benchmark datasets show that the proposed relation discriminator and new loss can provide significant improvement on variable vision tasks including unconditional and conditional image generation and image translation. Our source codes are available on the website: \url{https://github.com/JosephineRabbit/Relation-GAN}
Domain Independent Unsupervised Learning to grasp the Novel Objects
Jan 09, 2020
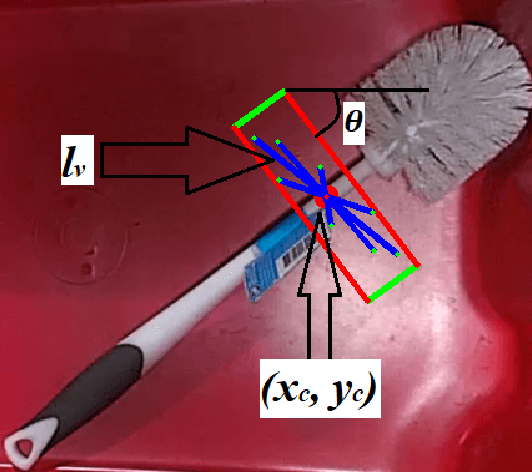
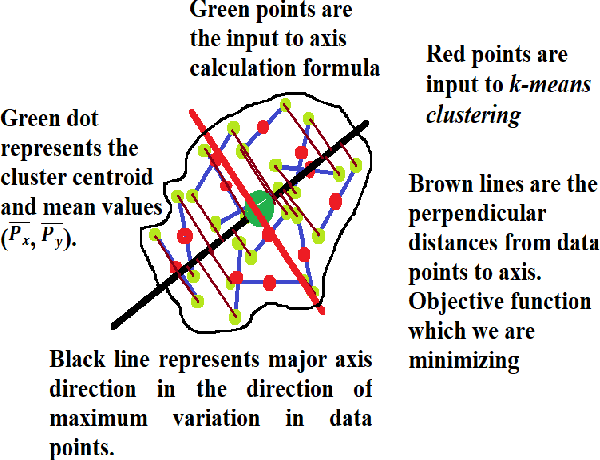
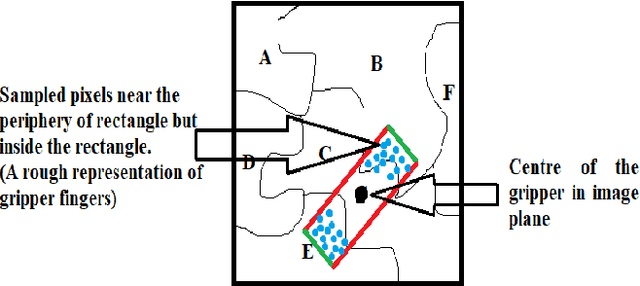
One of the main challenges in the vision-based grasping is the selection of feasible grasp regions while interacting with novel objects. Recent approaches exploit the power of the convolutional neural network (CNN) to achieve accurate grasping at the cost of high computational power and time. In this paper, we present a novel unsupervised learning based algorithm for the selection of feasible grasp regions. Unsupervised learning infers the pattern in data-set without any external labels. We apply k-means clustering on the image plane to identify the grasp regions, followed by an axis assignment method. We define a novel concept of Grasp Decide Index (GDI) to select the best grasp pose in image plane. We have conducted several experiments in clutter or isolated environment on standard objects of Amazon Robotics Challenge 2017 and Amazon Picking Challenge 2016. We compare the results with prior learning based approaches to validate the robustness and adaptive nature of our algorithm for a variety of novel objects in different domains.
Retinopathy of Prematurity Stage Diagnosis Using Object Segmentation and Convolutional Neural Networks
Apr 03, 2020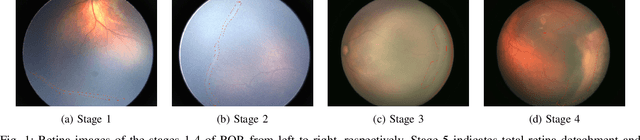
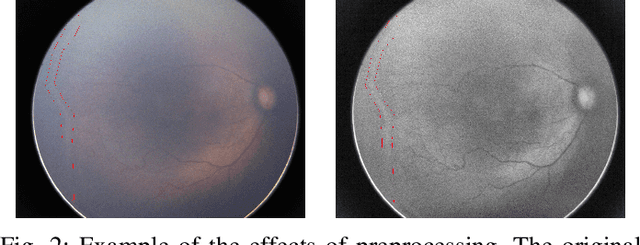
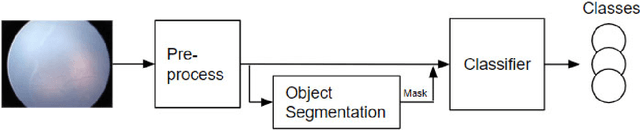
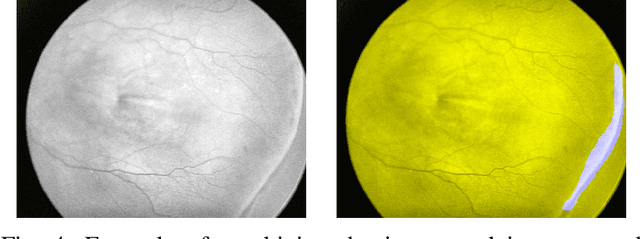
Retinopathy of Prematurity (ROP) is an eye disorder primarily affecting premature infants with lower weights. It causes proliferation of vessels in the retina and could result in vision loss and, eventually, retinal detachment, leading to blindness. While human experts can easily identify severe stages of ROP, the diagnosis of earlier stages, which are the most relevant to determining treatment choice, are much more affected by variability in subjective interpretations of human experts. In recent years, there has been a significant effort to automate the diagnosis using deep learning. This paper builds upon the success of previous models and develops a novel architecture, which combines object segmentation and convolutional neural networks (CNN) to construct an effective classifier of ROP stages 1-3 based on neonatal retinal images. Motivated by the fact that the formation and shape of a demarcation line in the retina is the distinguishing feature between earlier ROP stages, our proposed system first trains an object segmentation model to identify the demarcation line at a pixel level and adds the resulting mask as an additional "color" channel in the original image. Then, the system trains a CNN classifier based on the processed images to leverage information from both the original image and the mask, which helps direct the model's attention to the demarcation line. In a number of careful experiments comparing its performance to previous object segmentation systems and CNN-only systems trained on our dataset, our novel architecture significantly outperforms previous systems in accuracy, demonstrating the effectiveness of our proposed pipeline.
Blind Deblurring Using GANs
Jul 27, 2019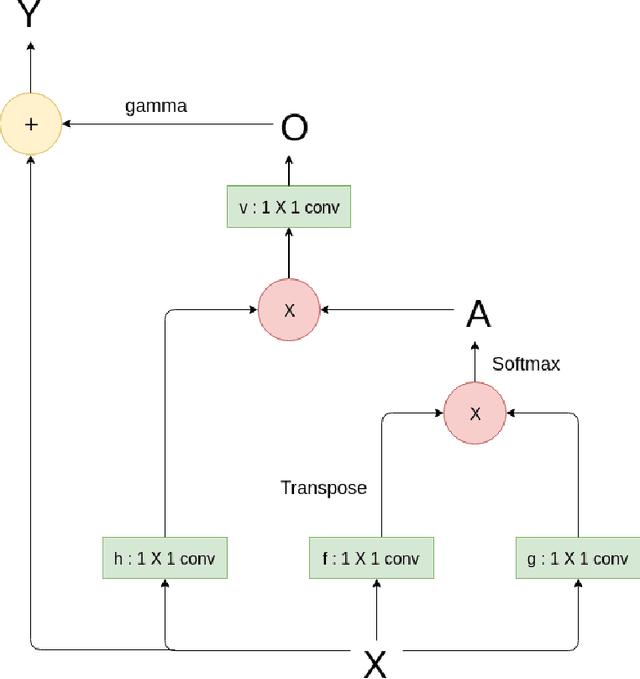

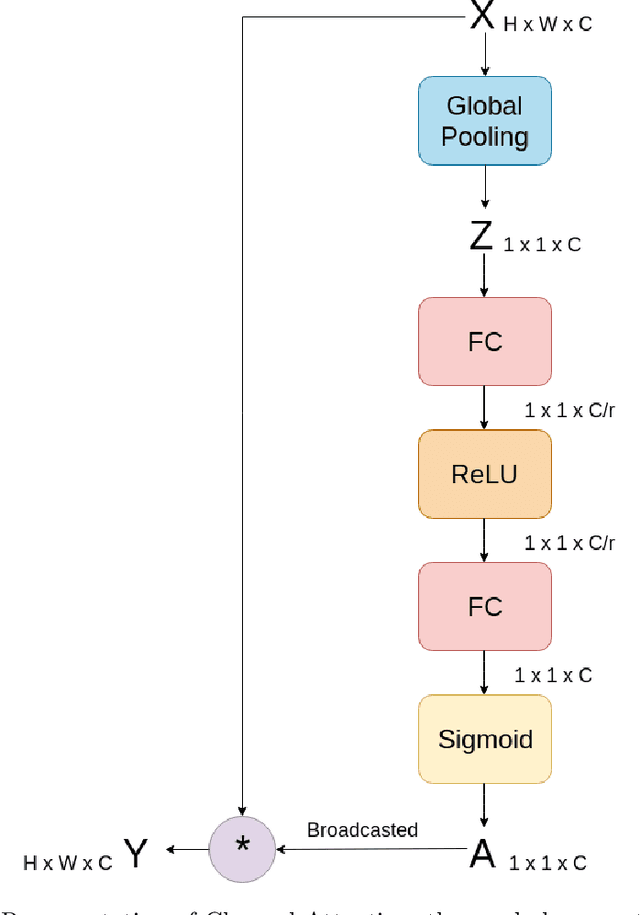

Deblurring is the task of restoring a blurred image to a sharp one, retrieving the information lost due to the blur. In blind deblurring we have no information regarding the blur kernel. As deblurring can be considered as an image to image translation task, deep learning based solutions, including the ones which use GAN (Generative Adversarial Network), have been proven effective for deblurring. Most of them have an encoder-decoder structure. Our objective is to try different GAN structures and improve its performance through various modifications to the existing structure for supervised deblurring. In supervised deblurring we have pairs of blurred and their corresponding sharp images, while in the unsupervised case we have a set of blurred and sharp images but their is no correspondence between them. Modifications to the structures is done to improve the global perception of the model. As blur is non-uniform in nature, for deblurring we require global information of the entire image, whereas convolution used in CNN is able to provide only local perception. Deep models can be used to improve global perception but due to large number of parameters it becomes difficult for it to converge and inference time increases, to solve this we propose the use of attention module (non-local block) which was previously used in language translation and other image to image translation tasks in deblurring. Use of residual connection also improves the performance of deblurring as features from the lower layers are added to the upper layers of the model. It has been found that classical losses like L1, L2, and perceptual loss also help in training of GANs when added together with adversarial loss. We also concatenate edge information of the image to observe its effects on deblurring. We also use feedback modules to retain long term dependencies
Rethinking CNN Models for Audio Classification
Jul 22, 2020
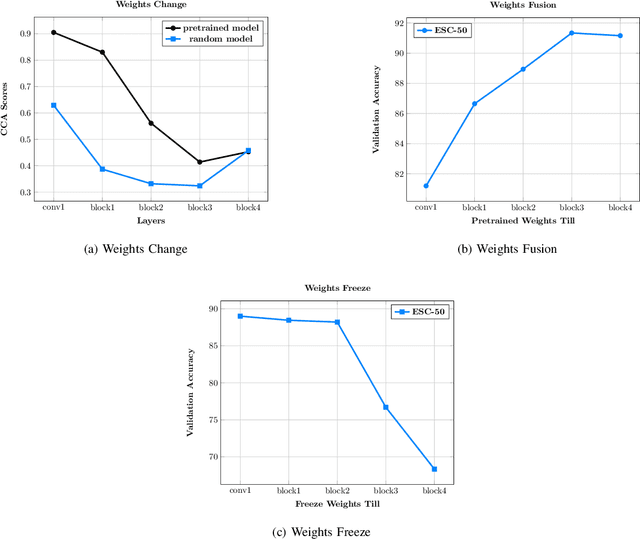
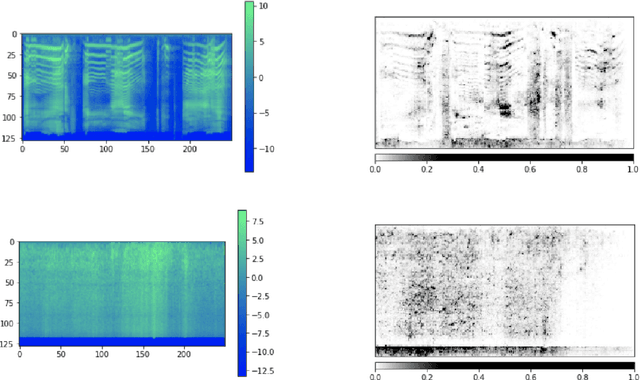
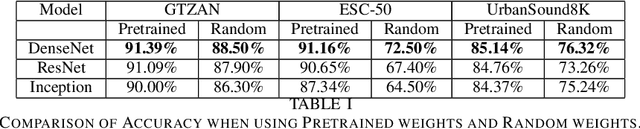
In this paper, we show that ImageNet-Pretrained standard deep CNN models can be used as strong baseline networks for audio classification. Even though there is a significant difference between audio Spectrogram and standard ImageNet image samples, transfer learning assumptions still hold firmly. To understand what enables the ImageNet pretrained models to learn useful audio representations, we systematically study how much of pretrained weights is useful for learning spectrograms. We show (1) that for a given standard model using pretrained weights is better than using randomly initialized weights (2) qualitative results of what the CNNs learn from the spectrograms by visualizing the gradients. Besides, we show that even though we use the pretrained model weights for initialization, there is variance in performance in various output runs of the same model. This variance in performance is due to the random initialization of linear classification layer and random mini-batch orderings in multiple runs. This brings significant diversity to build stronger ensemble models with an overall improvement in accuracy. An ensemble of ImageNet pretrained DenseNet achieves 92.89% validation accuracy on the ESC-50 dataset and 87.42% validation accuracy on the UrbanSound8K dataset which is the current state-of-the-art on both of these datasets.
iCVI-ARTMAP: Accelerating and improving clustering using adaptive resonance theory predictive mapping and incremental cluster validity indices
Aug 22, 2020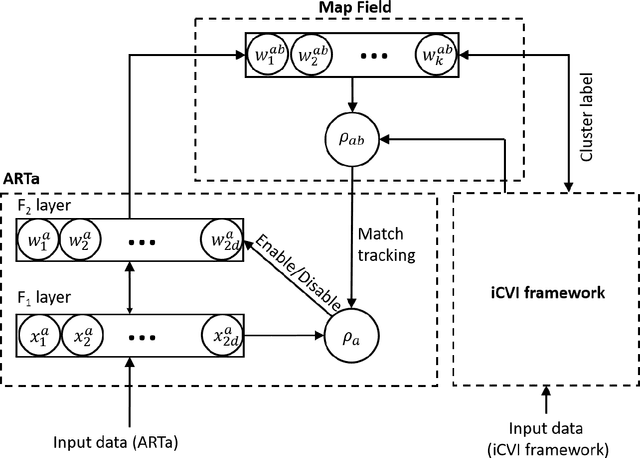

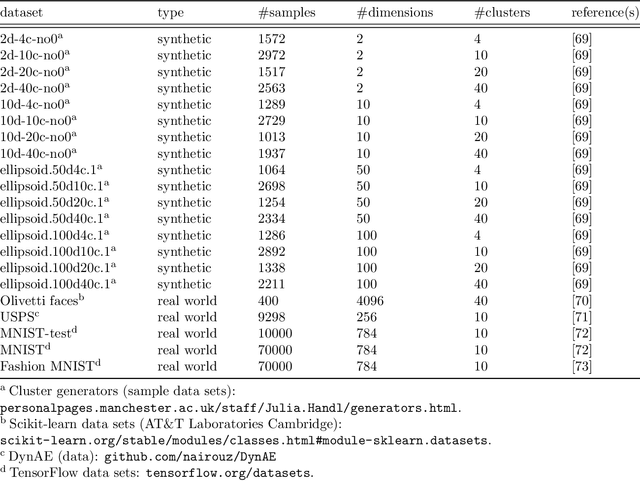

This paper presents an adaptive resonance theory predictive mapping (ARTMAP) model which uses incremental cluster validity indices (iCVIs) to perform unsupervised learning, namely iCVI-ARTMAP. Incorporating iCVIs to the decision-making and many-to-one mapping capabilities of ARTMAP can improve the choices of clusters to which samples are incrementally assigned. These improvements are accomplished by intelligently performing the operations of swapping sample assignments between clusters, splitting and merging clusters, and caching the values of variables when iCVI values need to be recomputed. Using recursive formulations enables iCVI-ARTMAP to considerably reduce the computational burden associated with cluster validity index (CVI)-based offline clustering. Depending on the iCVI and the data set, it can achieve running times up to two orders of magnitude shorter than when using batch CVI computations. In this work, the incremental versions of Calinski-Harabasz, WB-index, Xie-Beni, Davies-Bouldin, Pakhira-Bandyopadhyay-Maulik, and negentropy increment were integrated into fuzzy ARTMAP. Experimental results show that, with proper choice of iCVI, iCVI-ARTMAP outperformed fuzzy adaptive resonance theory (ART), dual vigilance fuzzy ART, kmeans, spectral clustering, Gaussian mixture models and hierarchical agglomerative clustering algorithms in most of the synthetic benchmark data sets. It also performed competitively on real world image benchmark data sets when clustering on projections and on latent spaces generated by a deep clustering model. Naturally, the performance of iCVI-ARTMAP is subject to the selected iCVI and its suitability to the data at hand; fortunately, it is a general model wherein other iCVIs can be easily embedded.
Modelling the Distribution of 3D Brain MRI using a 2D Slice VAE
Jul 09, 2020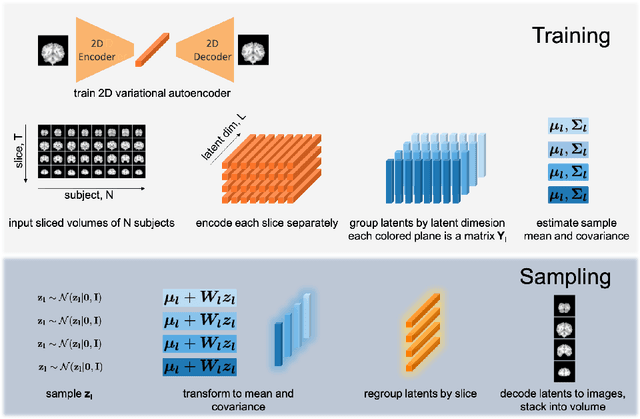
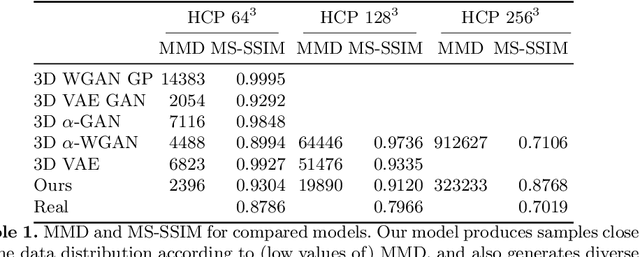
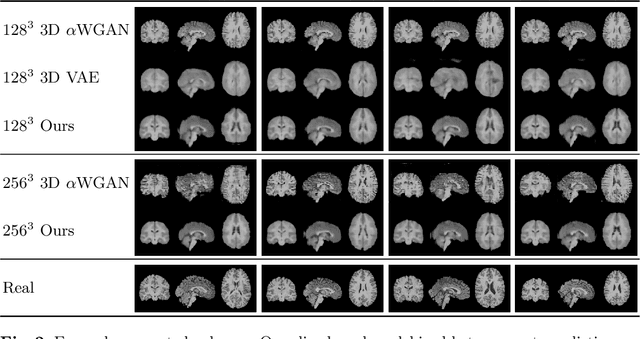
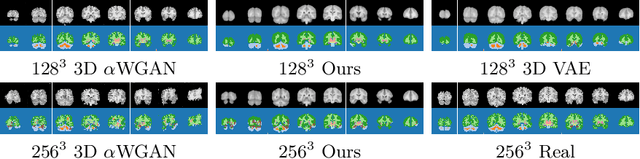
Probabilistic modelling has been an essential tool in medical image analysis, especially for analyzing brain Magnetic Resonance Images (MRI). Recent deep learning techniques for estimating high-dimensional distributions, in particular Variational Autoencoders (VAEs), opened up new avenues for probabilistic modeling. Modelling of volumetric data has remained a challenge, however, because constraints on available computation and training data make it difficult effectively leverage VAEs, which are well-developed for 2D images. We propose a method to model 3D MR brain volumes distribution by combining a 2D slice VAE with a Gaussian model that captures the relationships between slices. We do so by estimating the sample mean and covariance in the latent space of the 2D model over the slice direction. This combined model lets us sample new coherent stacks of latent variables to decode into slices of a volume. We also introduce a novel evaluation method for generated volumes that quantifies how well their segmentations match those of true brain anatomy. We demonstrate that our proposed model is competitive in generating high quality volumes at high resolutions according to both traditional metrics and our proposed evaluation.
What am I Searching for: Zero-shot Target Identity Inference in Visual Search
May 25, 2020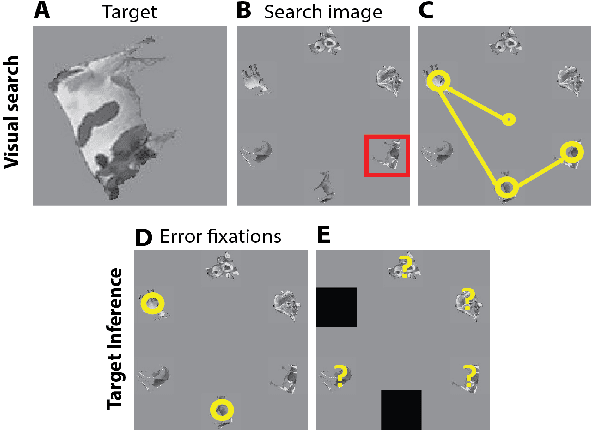
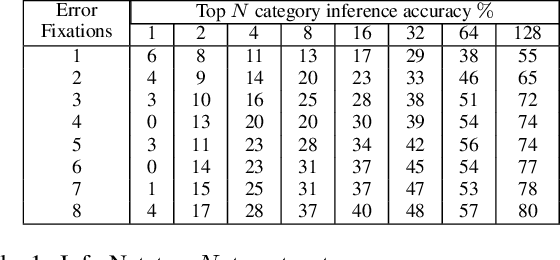
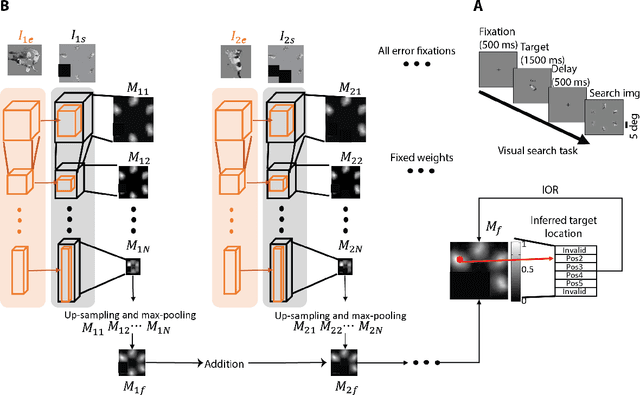
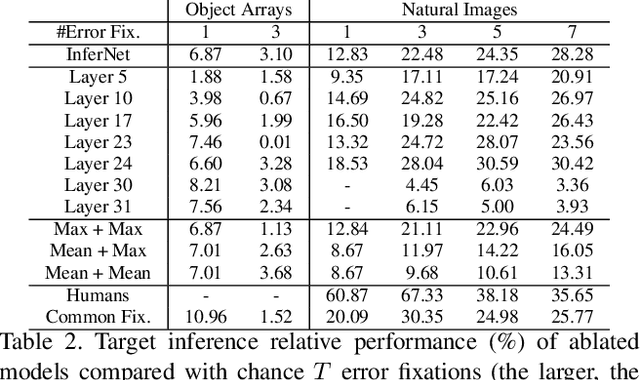
Can we infer intentions from a person's actions? As an example problem, here we consider how to decipher what a person is searching for by decoding their eye movement behavior. We conducted two psychophysics experiments where we monitored eye movements while subjects searched for a target object. We defined the fixations falling on \textit{non-target} objects as "error fixations". Using those error fixations, we developed a model (InferNet) to infer what the target was. InferNet uses a pre-trained convolutional neural network to extract features from the error fixations and computes a similarity map between the error fixations and all locations across the search image. The model consolidates the similarity maps across layers and integrates these maps across all error fixations. InferNet successfully identifies the subject's goal and outperforms competitive null models, even without any object-specific training on the inference task.
Sparse Generative Adversarial Network
Aug 20, 2019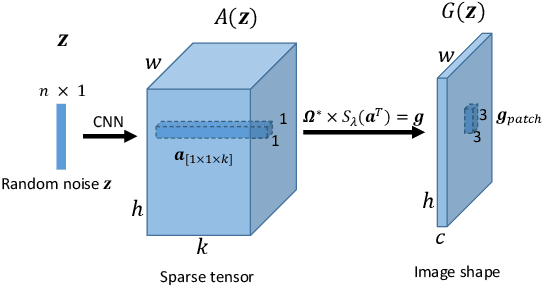
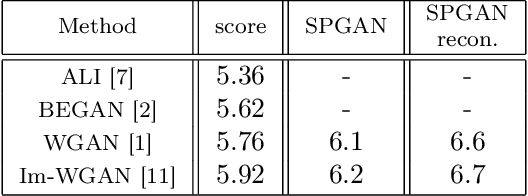
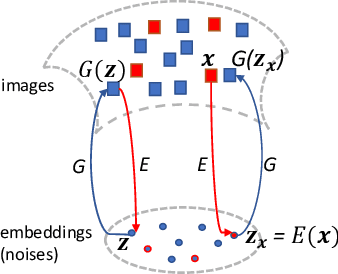
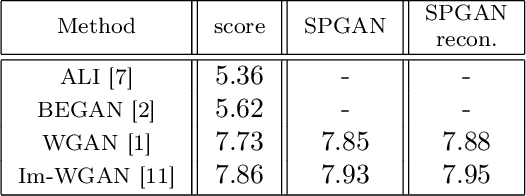
We propose a new approach to Generative Adversarial Networks (GANs) to achieve an improved performance with additional robustness to its so-called and well recognized mode collapse. We first proceed by mapping the desired data onto a frame-based space for a sparse representation to lift any limitation of small support features prior to learning the structure. To that end we start by dividing an image into multiple patches and modifying the role of the generative network from producing an entire image, at once, to creating a sparse representation vector for each image patch. We synthesize an entire image by multiplying generated sparse representations to a pre-trained dictionary and assembling the resulting patches. This approach restricts the output of the generator to a particular structure, obtained by imposing a Union of Subspaces (UoS) model to the original training data, leading to more realistic images, while maintaining a desired diversity. To further regularize GANs in generating high-quality images and to avoid the notorious mode-collapse problem, we introduce a third player in GANs, called reconstructor. This player utilizes an auto-encoding scheme to ensure that first, the input-output relation in the generator is injective and second each real image corresponds to some input noise. We present a number of experiments, where the proposed algorithm shows a remarkably higher inception score compared to the equivalent conventional GANs.