 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Traffic Lane Detection using FCN
Apr 19, 2020

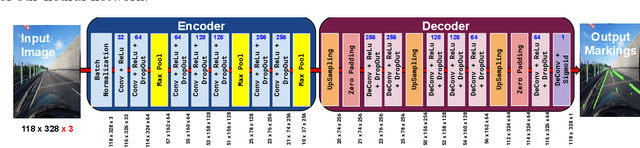
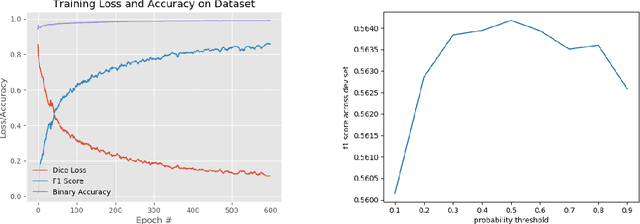

Automatic lane detection is a crucial technology that enables self-driving cars to properly position themselves in a multi-lane urban driving environments. However, detecting diverse road markings in various weather conditions is a challenging task for conventional image processing or computer vision techniques. In recent years, the application of Deep Learning and Neural Networks in this area has proven to be very effective. In this project, we designed an Encoder- Decoder, Fully Convolutional Network for lane detection. This model was applied to a real-world large scale dataset and achieved a level of accuracy that outperformed our baseline model.
Supervised Learning with First-to-Spike Decoding in Multilayer Spiking Neural Networks
Aug 16, 2020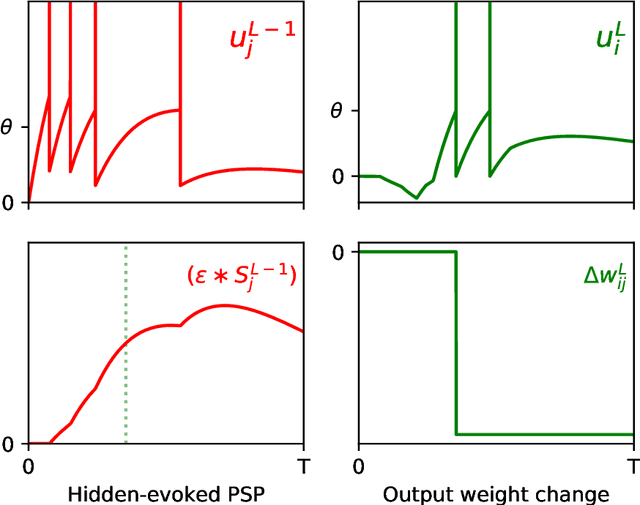
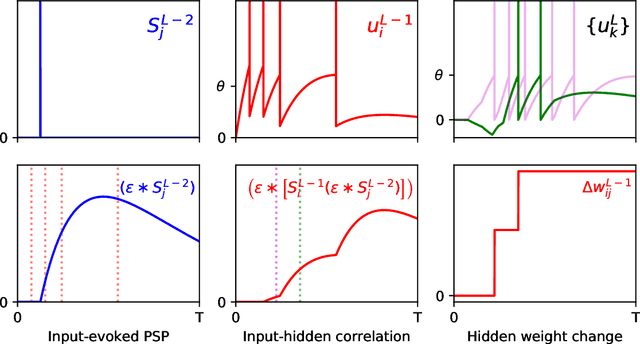
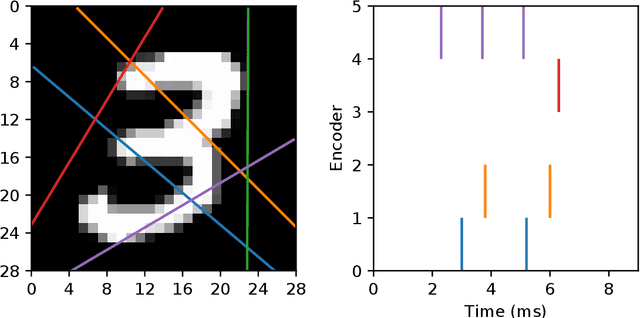
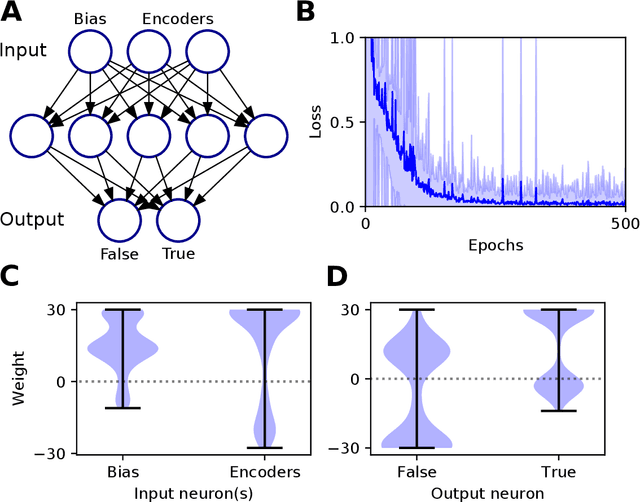
Experimental studies support the notion of spike-based neuronal information processing in the brain, with neural circuits exhibiting a wide range of temporally-based coding strategies to rapidly and efficiently represent sensory stimuli. Accordingly, it would be desirable to apply spike-based computation to tackling real-world challenges, and in particular transferring such theory to neuromorphic systems for low-power embedded applications. Motivated by this, we propose a new supervised learning method that can train multilayer spiking neural networks to solve classification problems based on a rapid, first-to-spike decoding strategy. The proposed learning rule supports multiple spikes fired by stochastic hidden neurons, and yet is stable by relying on first-spike responses generated by a deterministic output layer. In addition to this, we also explore several distinct, spike-based encoding strategies in order to form compact representations of presented input data. We demonstrate the classification performance of the learning rule as applied to several benchmark datasets, including MNIST. The learning rule is capable of generalising from the data, and is successful even when used with constrained network architectures containing few input and hidden layer neurons. Furthermore, we highlight a novel encoding strategy, termed `scanline encoding', that can transform image data into compact spatiotemporal patterns for subsequent network processing. Designing constrained, but optimised, network structures and performing input dimensionality reduction has strong implications for neuromorphic applications.
Plug-and-Play Rescaling Based Crowd Counting in Static Images
Jan 06, 2020
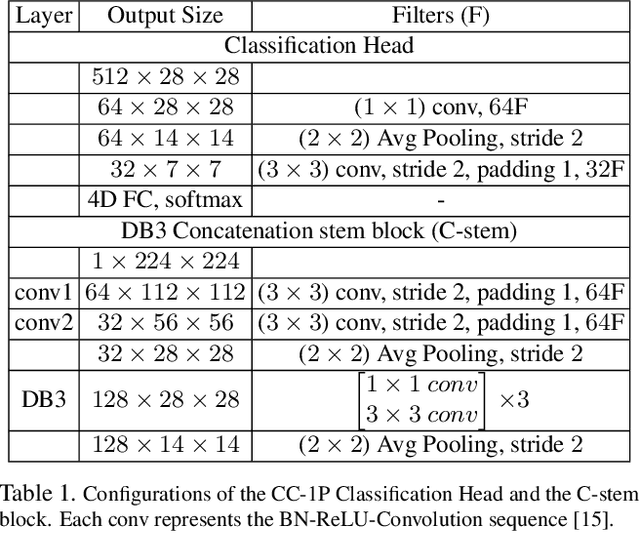
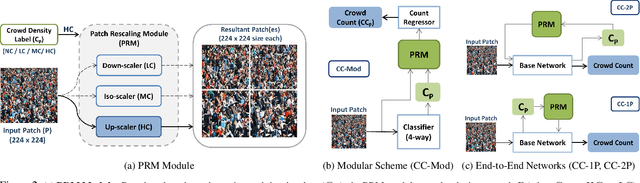
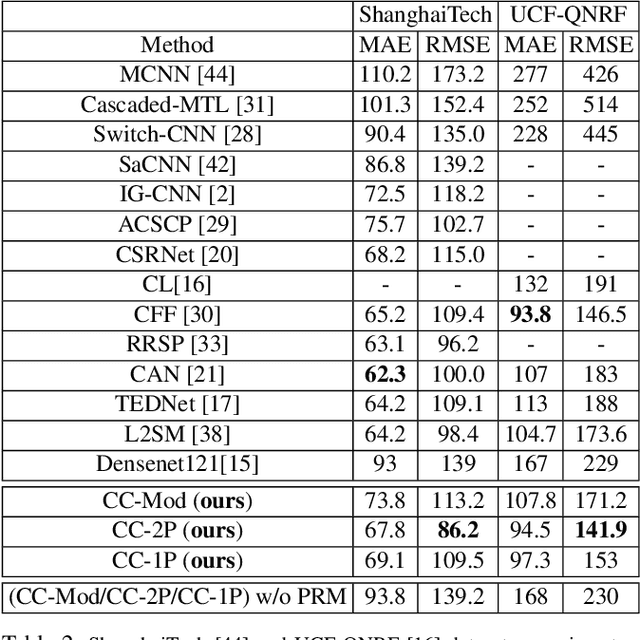
Crowd counting is a challenging problem especially in the presence of huge crowd diversity across images and complex cluttered crowd-like background regions, where most previous approaches do not generalize well and consequently produce either huge crowd underestimation or overestimation. To address these challenges, we propose a new image patch rescaling module (PRM) and three independent PRM employed crowd counting methods. The proposed frameworks use the PRM module to rescale the image regions (patches) that require special treatment, whereas the classification process helps in recognizing and discarding any cluttered crowd-like background regions which may result in overestimation. Experiments on three standard benchmarks and cross-dataset evaluation show that our approach outperforms the state-of-the-art models in the RMSE evaluation metric with an improvement up to 10.4%, and possesses superior generalization ability to new datasets.
BRM Localization: UAV Localization in GNSS-Denied Environments Based on Matching of Numerical Map and UAV Images
Aug 05, 2020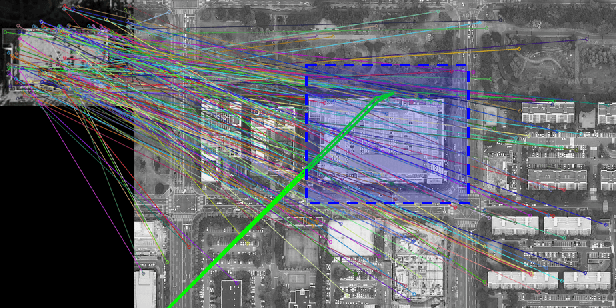
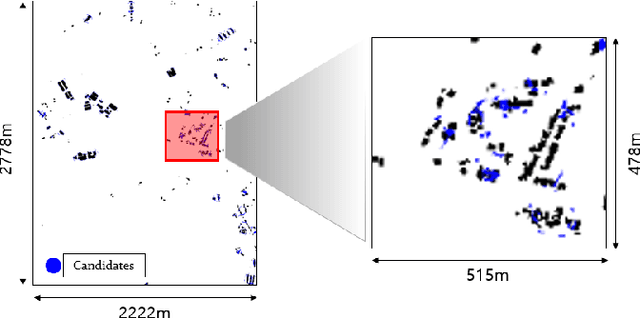
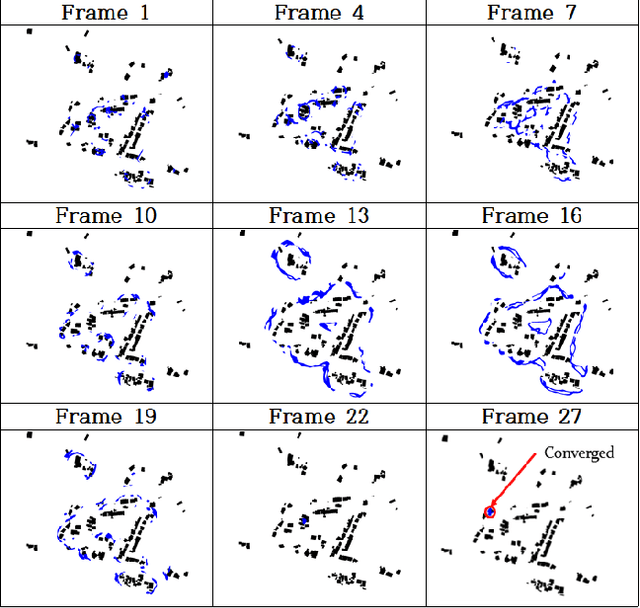
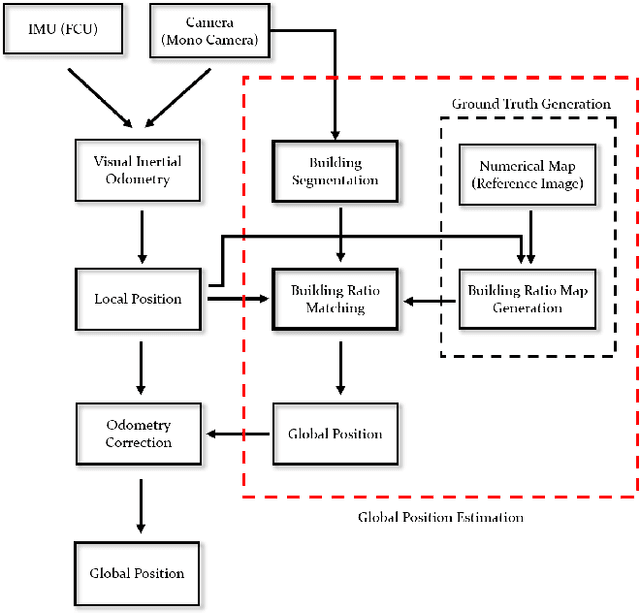
Localization is one of the most important technologies needed to use Unmanned Aerial Vehicles (UAVs) in actual fields. Currently, most UAVs use GNSS to estimate their position. Recently, there have been attacks that target the weaknesses of UAVs that use GNSS, such as interrupting GNSS signal to crash the UAVs or sending fake GNSS signals to hijack the UAVs. To avoid this kind of situation, this paper proposes an algorithm that deals with the localization problem of the UAV in GNSS-denied environments. We propose a localization method, named as BRM (Building Ratio Map based) localization, for a UAV by matching an existing numerical map with UAV images. The building area is extracted from the UAV images. The ratio of buildings that occupy in the corresponding image frame is calculated and matched with the building information on the numerical map. The position estimation is started in the range of several km^2 area, so that the position estimation can be performed without knowing the exact initial coordinate. Only freely available maps are used for training data set and matching the ground truth. Finally, we get real UAV images, IMU data, and GNSS data from UAV flight to show that the proposed method can achieve better performance than the conventional methods.
Regularized Adaptation for Stable and Efficient Continuous-Level Learning
Mar 11, 2020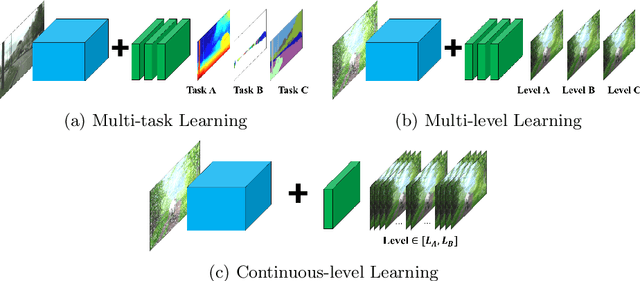

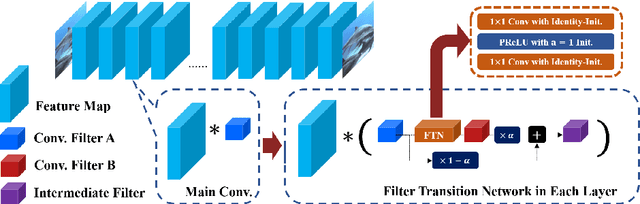

In Convolutional Neural Network (CNN) based image processing, most of the studies propose networks that are optimized for a single-level (or a single-objective); thus, they underperform on other levels and must be retrained for delivery of optimal performance. Using multiple models to cover multiple levels involves very high computational costs. To solve these problems, recent approaches train the networks on two different levels and propose their own interpolation methods to enable the arbitrary intermediate levels. However, many of them fail to adapt hard tasks or interpolate smoothly, or the others still require large memory and computational cost. In this paper, we propose a novel continuous-level learning framework using a Filter Transition Network (FTN) which is a non-linear module that easily adapt to new levels, and is regularized to prevent undesirable side-effects. Additionally, for stable learning of FTN, we newly propose a method to initialize non-linear CNNs with identity mappings. Furthermore, FTN is extremely lightweight module since it is a data-independent module, which means it is not affected by the spatial resolution of the inputs. Extensive results for various image processing tasks indicate that the performance of FTN is stable in terms of adaptation and interpolation, and comparable to that of the other heavy frameworks.
Max-Fusion U-Net for Multi-Modal Pathology Segmentation with Attention and Dynamic Resampling
Sep 05, 2020



Automatic segmentation of multi-sequence (multi-modal) cardiac MR (CMR) images plays a significant role in diagnosis and management for a variety of cardiac diseases. However, the performance of relevant algorithms is significantly affected by the proper fusion of the multi-modal information. Furthermore, particular diseases, such as myocardial infarction, display irregular shapes on images and occupy small regions at random locations. These facts make pathology segmentation of multi-modal CMR images a challenging task. In this paper, we present the Max-Fusion U-Net that achieves improved pathology segmentation performance given aligned multi-modal images of LGE, T2-weighted, and bSSFP modalities. Specifically, modality-specific features are extracted by dedicated encoders. Then they are fused with the pixel-wise maximum operator. Together with the corresponding encoding features, these representations are propagated to decoding layers with U-Net skip-connections. Furthermore, a spatial-attention module is applied in the last decoding layer to encourage the network to focus on those small semantically meaningful pathological regions that trigger relatively high responses by the network neurons. We also use a simple image patch extraction strategy to dynamically resample training examples with varying spacial and batch sizes. With limited GPU memory, this strategy reduces the imbalance of classes and forces the model to focus on regions around the interested pathology. It further improves segmentation accuracy and reduces the mis-classification of pathology. We evaluate our methods using the Myocardial pathology segmentation (MyoPS) combining the multi-sequence CMR dataset which involves three modalities. Extensive experiments demonstrate the effectiveness of the proposed model which outperforms the related baselines.
* 13 pages, 7 figures, conference paper
Scan-based Semantic Segmentation of LiDAR Point Clouds: An Experimental Study
Apr 06, 2020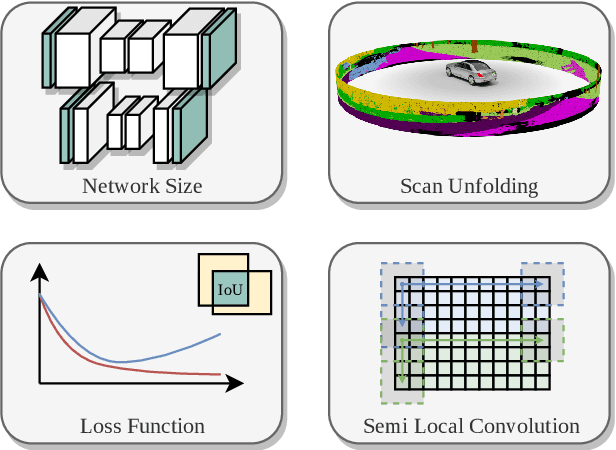
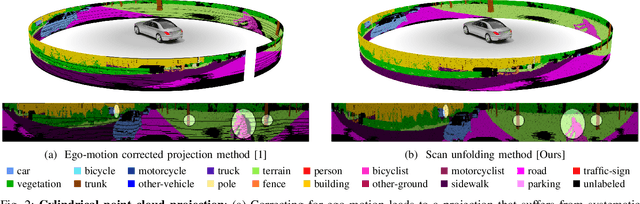
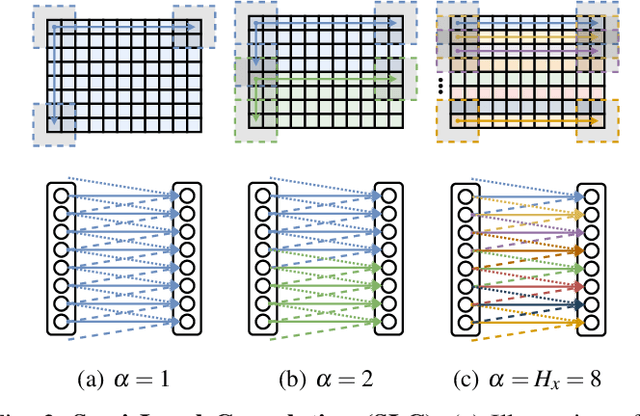
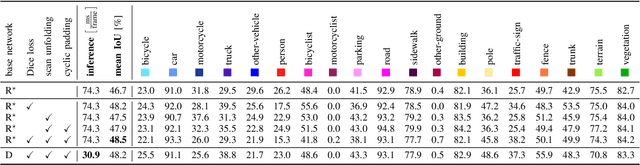
Autonomous vehicles need to have a semantic understanding of the three-dimensional world around them in order to reason about their environment. State of the art methods use deep neural networks to predict semantic classes for each point in a LiDAR scan. A powerful and efficient way to process LiDAR measurements is to use two-dimensional, image-like projections. In this work, we perform a comprehensive experimental study of image-based semantic segmentation architectures for LiDAR point clouds. We demonstrate various techniques to boost the performance and to improve runtime as well as memory constraints. First, we examine the effect of network size and suggest that much faster inference times can be achieved at a very low cost to accuracy. Next, we introduce an improved point cloud projection technique that does not suffer from systematic occlusions. We use a cyclic padding mechanism that provides context at the horizontal field-of-view boundaries. In a third part, we perform experiments with a soft Dice loss function that directly optimizes for the intersection-over-union metric. Finally, we propose a new kind of convolution layer with a reduced amount of weight-sharing along one of the two spatial dimensions, addressing the large difference in appearance along the vertical axis of a LiDAR scan. We propose a final set of the above methods with which the model achieves an increase of 3.2% in mIoU segmentation performance over the baseline while requiring only 42% of the original inference time.
User independent Emotion Recognition with Residual Signal-Image Network
Aug 10, 2019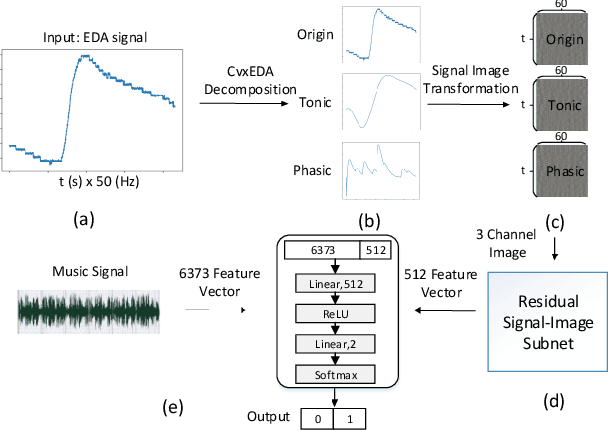
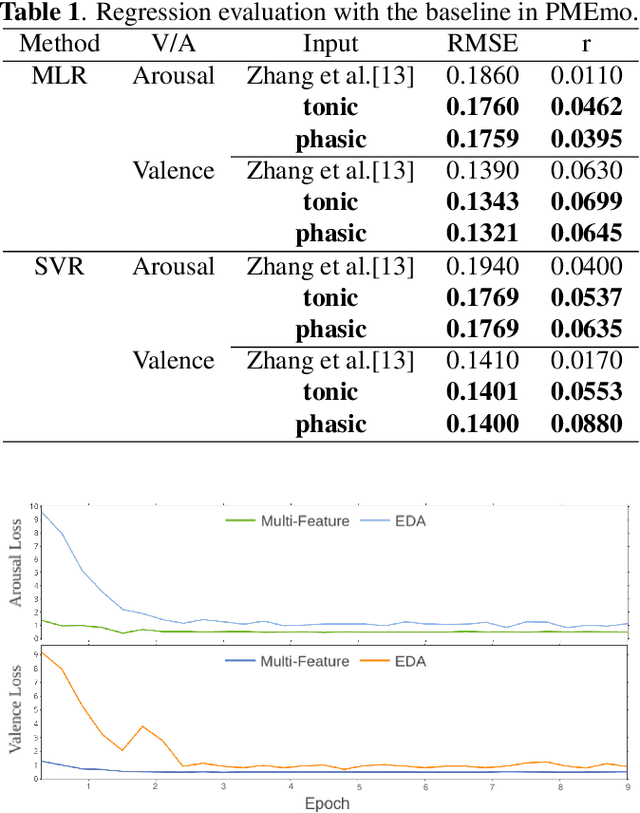
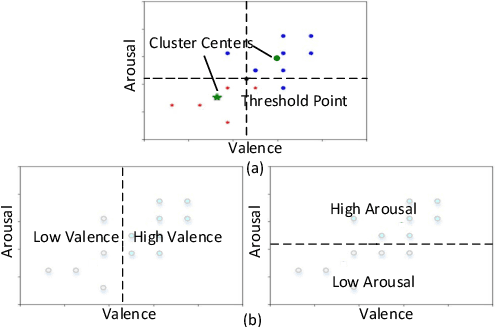
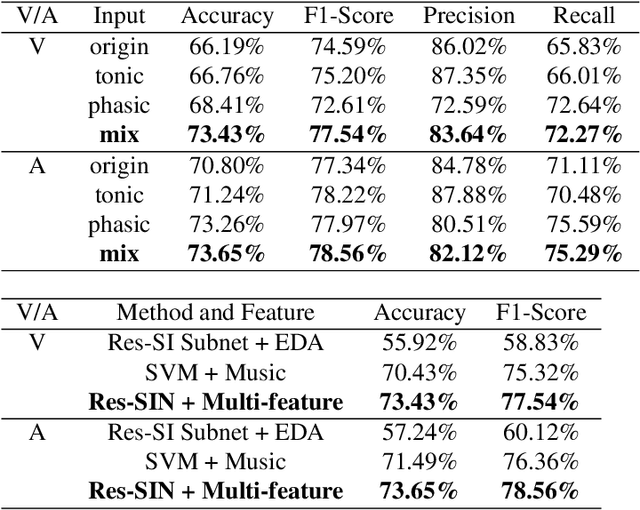
User independent emotion recognition with large scale physiological signals is a tough problem. There exist many advanced methods but they are conducted under relatively small datasets with dozens of subjects. Here, we propose Res-SIN, a novel end-to-end framework using Electrodermal Activity(EDA) signal images to classify human emotion. We first apply convex optimization-based EDA (cvxEDA) to decompose signals and mine the static and dynamic emotion changes. Then, we transform decomposed signals to images so that they can be effectively processed by CNN frameworks. The Res-SIN combines individual emotion features and external emotion benchmarks to accelerate convergence. We evaluate our approach on the PMEmo dataset, the currently largest emotional dataset containing music and EDA signals. To the best of author's knowledge, our method is the first attempt to classify large scale subject-independent emotion with 7962 pieces of EDA signals from 457 subjects. Experimental results demonstrate the reliability of our model and the binary classification accuracy of 73.65% and 73.43% on arousal and valence dimension can be used as a baseline.
Learning-Based Human Segmentation and Velocity Estimation Using Automatic Labeled LiDAR Sequence for Training
Mar 11, 2020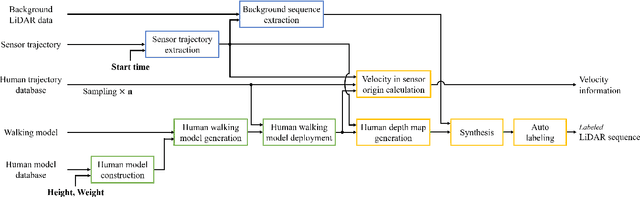


In this paper, we propose an automatic labeled sequential data generation pipeline for human segmentation and velocity estimation with point clouds. Considering the impact of deep neural networks, state-of-the-art network architectures have been proposed for human recognition using point clouds captured by Light Detection and Ranging (LiDAR). However, one disadvantage is that legacy datasets may only cover the image domain without providing important label information and this limitation has disturbed the progress of research to date. Therefore, we develop an automatic labeled sequential data generation pipeline, in which we can control any parameter or data generation environment with pixel-wise and per-frame ground truth segmentation and pixel-wise velocity information for human recognition. Our approach uses a precise human model and reproduces a precise motion to generate realistic artificial data. We present more than 7K video sequences which consist of 32 frames generated by the proposed pipeline. With the proposed sequence generator, we confirm that human segmentation performance is improved when using the video domain compared to when using the image domain. We also evaluate our data by comparing with data generated under different conditions. In addition, we estimate pedestrian velocity with LiDAR by only utilizing data generated by the proposed pipeline.
Selective Image Super-Resolution
Oct 27, 2010
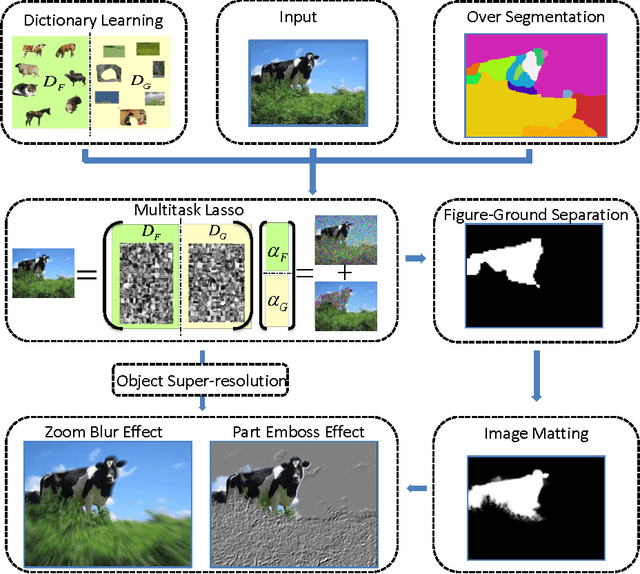
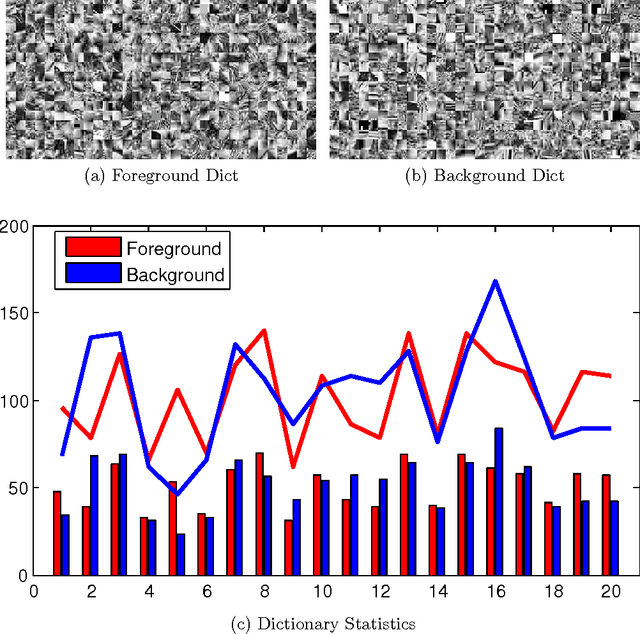

In this paper we propose a vision system that performs image Super Resolution (SR) with selectivity. Conventional SR techniques, either by multi-image fusion or example-based construction, have failed to capitalize on the intrinsic structural and semantic context in the image, and performed "blind" resolution recovery to the entire image area. By comparison, we advocate example-based selective SR whereby selectivity is exemplified in three aspects: region selectivity (SR only at object regions), source selectivity (object SR with trained object dictionaries), and refinement selectivity (object boundaries refinement using matting). The proposed system takes over-segmented low-resolution images as inputs, assimilates recent learning techniques of sparse coding (SC) and grouped multi-task lasso (GMTL), and leads eventually to a framework for joint figure-ground separation and interest object SR. The efficiency of our framework is manifested in our experiments with subsets of the VOC2009 and MSRC datasets. We also demonstrate several interesting vision applications that can build on our system.