 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extensions to the Proximal Distance of Method of Constrained Optimization
Sep 02, 2020
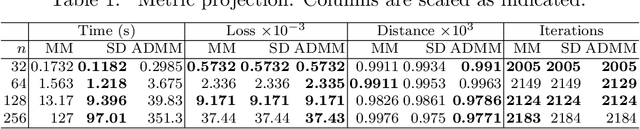

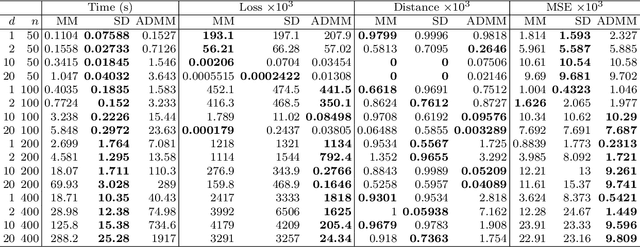
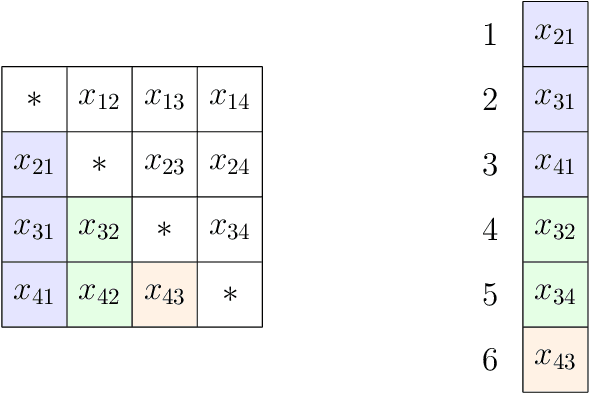
The current paper studies the problem of minimizing a loss $f(\boldsymbol{x})$ subject to constraints of the form $\boldsymbol{D}\boldsymbol{x} \in S$, where $S$ is a closed set, convex or not, and $\boldsymbol{D}$ is a fusion matrix. Fusion constraints can capture smoothness, sparsity, or more general constraint patterns. To tackle this generic class of problems, we combine the Beltrami-Courant penalty method of optimization with the proximal distance principle. The latter is driven by minimization of penalized objectives $f(\boldsymbol{x})+\frac{\rho}{2}\text{dist}(\boldsymbol{D}\boldsymbol{x},S)^2$ involving large tuning constants $\rho$ and the squared Euclidean distance of $\boldsymbol{D}\boldsymbol{x}$ from $S$. The next iterate $\boldsymbol{x}_{n+1}$ of the corresponding proximal distance algorithm is constructed from the current iterate $\boldsymbol{x}_n$ by minimizing the majorizing surrogate function $f(\boldsymbol{x})+\frac{\rho}{2}\|\boldsymbol{D}\boldsymbol{x}-\mathcal{P}_S(\boldsymbol{D}\boldsymbol{x}_n)\|^2$. For fixed $\rho$ and convex $f(\boldsymbol{x})$ and $S$, we prove convergence, provide convergence rates, and demonstrate linear convergence under stronger assumptions. We also construct a steepest descent (SD) variant to avoid costly linear system solves. To benchmark our algorithms, we adapt the alternating direction method of multipliers (ADMM) and compare on extensive numerical tests including problems in metric projection, convex regression, convex clustering, total variation image denoising, and projection of a matrix to one that has a good condition number. Our experiments demonstrate the superior speed and acceptable accuracy of the steepest variant on high-dimensional problems. Julia code to replicate all of our experiments can be found at https://github.com/alanderos91/ProximalDistanceAlgorithms.jl.
Quantization in Relative Gradient Angle Domain For Building Polygon Estimation
Jul 10, 2020
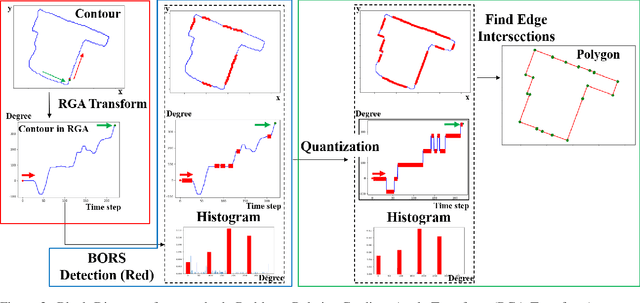
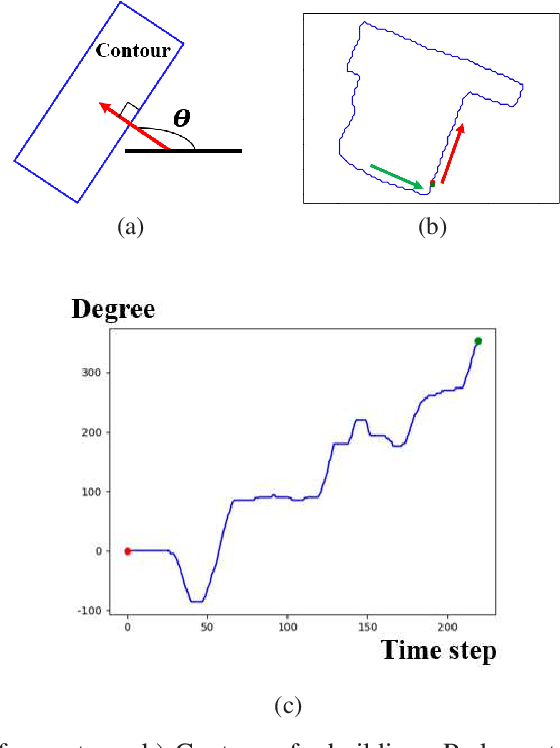
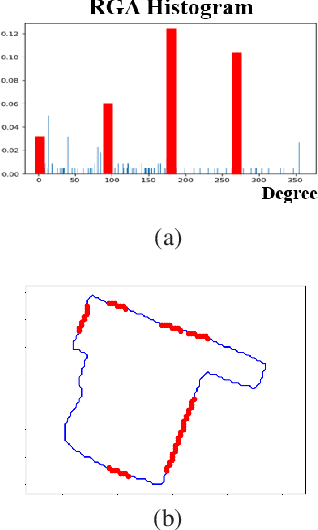
Building footprint extraction in remote sensing data benefits many important applications, such as urban planning and population estimation. Recently, rapid development of Convolutional Neural Networks (CNNs) and open-sourced high resolution satellite building image datasets have pushed the performance boundary further for automated building extractions. However, CNN approaches often generate imprecise building morphologies including noisy edges and round corners. In this paper, we leverage the performance of CNNs, and propose a module that uses prior knowledge of building corners to create angular and concise building polygons from CNN segmentation outputs. We describe a new transform, Relative Gradient Angle Transform (RGA Transform) that converts object contours from time vs. space to time vs. angle. We propose a new shape descriptor, Boundary Orientation Relation Set (BORS), to describe angle relationship between edges in RGA domain, such as orthogonality and parallelism. Finally, we develop an energy minimization framework that makes use of the angle relationship in BORS to straighten edges and reconstruct sharp corners, and the resulting corners create a polygon. Experimental results demonstrate that our method refines CNN output from a rounded approximation to a more clear-cut angular shape of the building footprint.
Deep Convolutional Features for Image Based Retrieval and Scene Categorization
Sep 20, 2015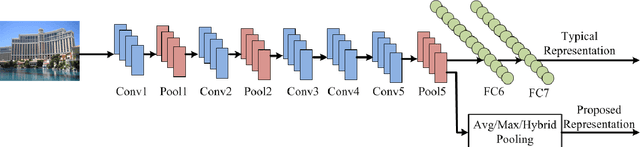
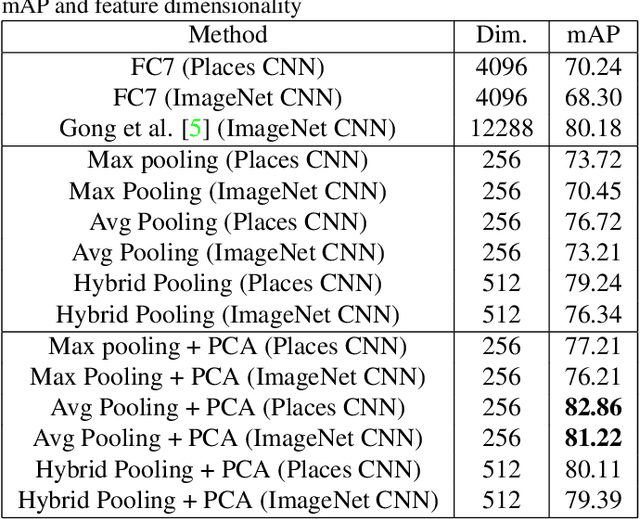


Several recent approaches showed how the representations learned by Convolutional Neural Networks can be repurposed for novel tasks. Most commonly it has been shown that the activation features of the last fully connected layers (fc7 or fc6) of the network, followed by a linear classifier outperform the state-of-the-art on several recognition challenge datasets. Instead of recognition, this paper focuses on the image retrieval problem and proposes a examines alternative pooling strategies derived for CNN features. The presented scheme uses the features maps from an earlier layer 5 of the CNN architecture, which has been shown to preserve coarse spatial information and is semantically meaningful. We examine several pooling strategies and demonstrate superior performance on the image retrieval task (INRIA Holidays) at the fraction of the computational cost, while using a relatively small memory requirements. In addition to retrieval, we see similar efficiency gains on the SUN397 scene categorization dataset, demonstrating wide applicability of this simple strategy. We also introduce and evaluate a novel GeoPlaces5K dataset from different geographical locations in the world for image retrieval that stresses more dramatic changes in appearance and viewpoint.
Cloud Removal in Satellite Images Using Spatiotemporal Generative Networks
Dec 14, 2019
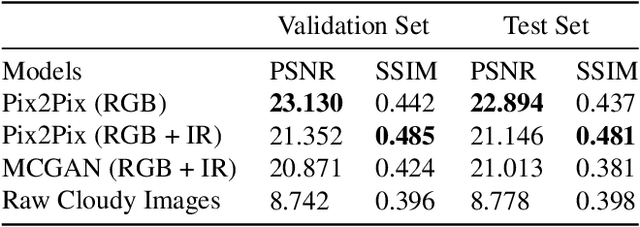
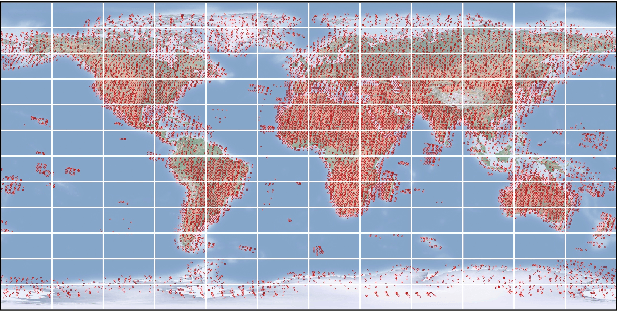
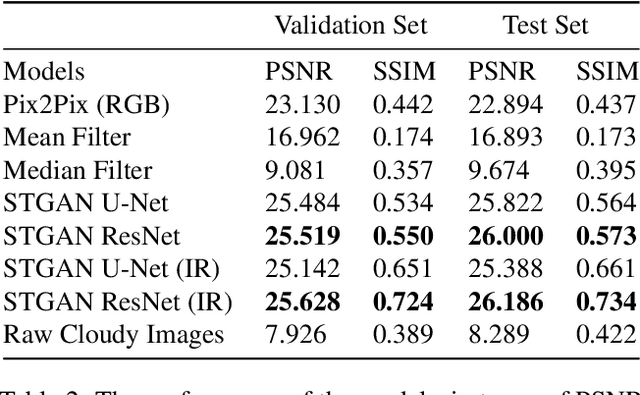
Satellite images hold great promise for continuous environmental monitoring and earth observation. Occlusions cast by clouds, however, can severely limit coverage, making ground information extraction more difficult. Existing pipelines typically perform cloud removal with simple temporal composites and hand-crafted filters. In contrast, we cast the problem of cloud removal as a conditional image synthesis challenge, and we propose a trainable spatiotemporal generator network (STGAN) to remove clouds. We train our model on a new large-scale spatiotemporal dataset that we construct, containing 97640 image pairs covering all continents. We demonstrate experimentally that the proposed STGAN model outperforms standard models and can generate realistic cloud-free images with high PSNR and SSIM values across a variety of atmospheric conditions, leading to improved performance in downstream tasks such as land cover classification.
Training Multiscale-CNN for Large Microscopy Image Classification in One Hour
Oct 03, 2019
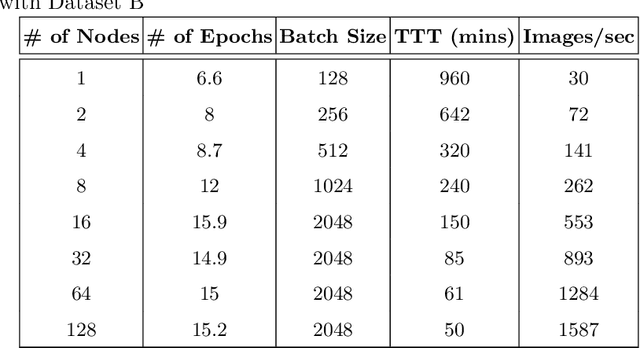
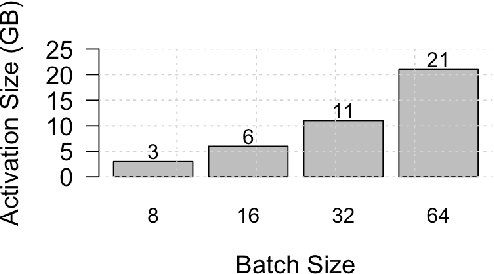
Existing approaches to train neural networks that use large images require to either crop or down-sample data during pre-processing, use small batch sizes, or split the model across devices mainly due to the prohibitively limited memory capacity available on GPUs and emerging accelerators. These techniques often lead to longer time to convergence or time to train (TTT), and in some cases, lower model accuracy. CPUs, on the other hand, can leverage significant amounts of memory. While much work has been done on parallelizing neural network training on multiple CPUs, little attention has been given to tune neural network training with large images on CPUs. In this work, we train a multi-scale convolutional neural network (M-CNN) to classify large biomedical images for high content screening in one hour. The ability to leverage large memory capacity on CPUs enables us to scale to larger batch sizes without having to crop or down-sample the input images. In conjunction with large batch sizes, we find a generalized methodology of linearly scaling of learning rate and train M-CNN to state-of-the-art (SOTA) accuracy of 99% within one hour. We achieve fast time to convergence using 128 two socket Intel Xeon 6148 processor nodes with 192GB DDR4 memory connected with 100Gbps Intel Omnipath architecture.
* 15 pages, 10 figures
LiDAR Iris for Loop-Closure Detection
Jan 02, 2020

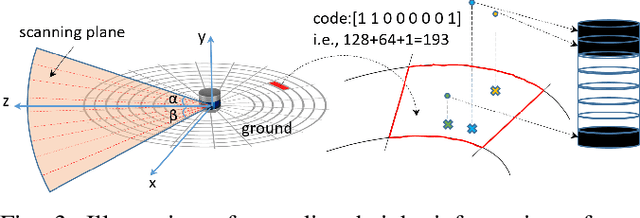
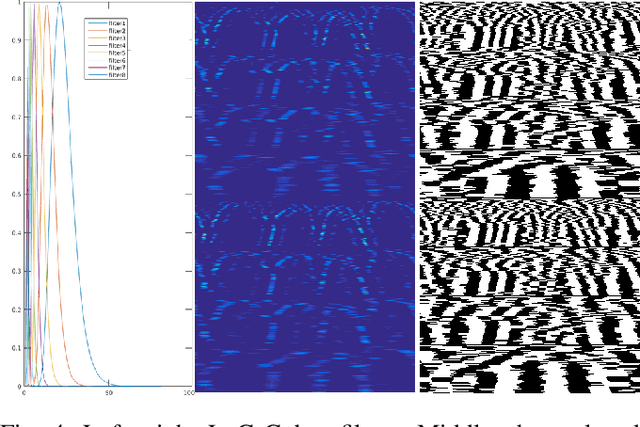
In this paper, a global descriptor for a LiDAR point cloud, called LiDAR Iris, is proposed for fast and accurate loop-closure detection. A binary signature image can be obtained for each point cloud after a couple of LoG-Gabor filtering and thresholding operations on the LiDAR-Iris image representation. Given two point clouds, the similarity of them can be calculated as the hamming-distance of two corresponding binary signature images extracted from the two point clouds, respectively. Our LiDAR-Iris method can achieve a pose-invariant loop-closure detection with the Fourier transform of the LiDAR-Iris representation if assuming a 3D (x,y,yaw) pose space, although our method can generally be applied to a 6D pose space by re-aligning point cloud with an additional IMU sensor. Experimental results on five road-scene sequences demonstrate its excellent performance in loop-closure detection.
GANSpace: Discovering Interpretable GAN Controls
Apr 06, 2020
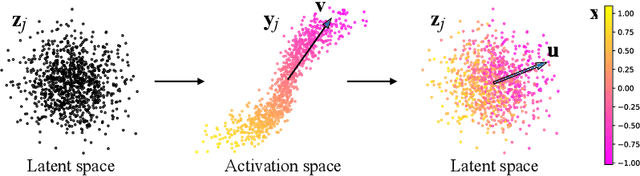


This paper describes a simple technique to analyze Generative Adversarial Networks (GANs) and create interpretable controls for image synthesis, such as change of viewpoint, aging, lighting, and time of day. We identify important latent directions based on Principal Components Analysis (PCA) applied in activation space. Then, we show that interpretable edits can be defined based on layer-wise application of these edit directions. Moreover, we show that BigGAN can be controlled with layer-wise inputs in a StyleGAN-like manner. A user may identify a large number of interpretable controls with these mechanisms. We demonstrate results on GANs from various datasets.
Robotic Grasp Manipulation Using Evolutionary Computing and Deep Reinforcement Learning
Jan 15, 2020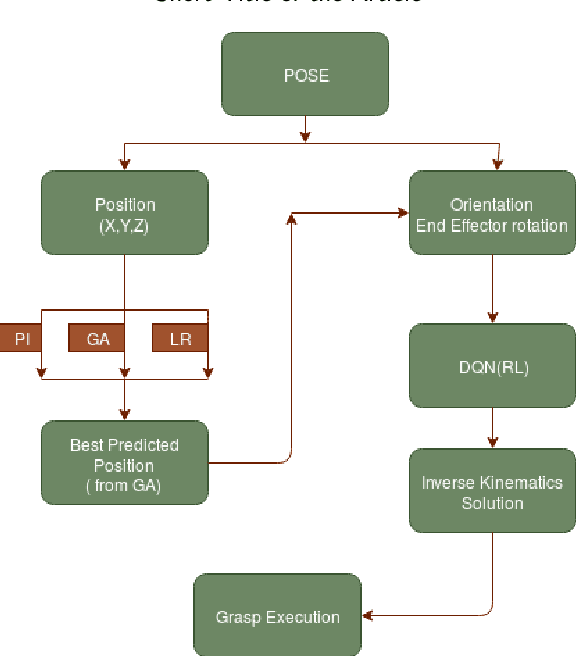
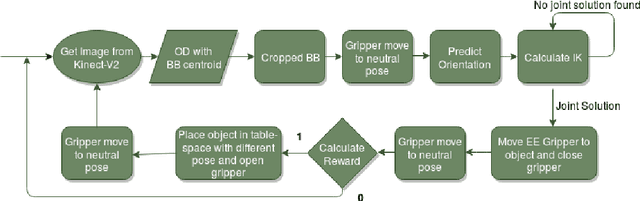

Intelligent Object manipulation for grasping is a challenging problem for robots. Unlike robots, humans almost immediately know how to manipulate objects for grasping due to learning over the years. A grown woman can grasp objects more skilfully than a child because of learning skills developed over years, the absence of which in the present day robotic grasping compels it to perform well below the human object grasping benchmarks. In this paper we have taken up the challenge of developing learning based pose estimation by decomposing the problem into both position and orientation learning. More specifically, for grasp position estimation, we explore three different methods - a Genetic Algorithm (GA) based optimization method to minimize error between calculated image points and predicted end-effector (EE) position, a regression based method (RM) where collected data points of robot EE and image points have been regressed with a linear model, a PseudoInverse (PI) model which has been formulated in the form of a mapping matrix with robot EE position and image points for several observations. Further for grasp orientation learning, we develop a deep reinforcement learning (DRL) model which we name as Grasp Deep Q-Network (GDQN) and benchmarked our results with Modified VGG16 (MVGG16). Rigorous experimentations show that due to inherent capability of producing very high-quality solutions for optimization problems and search problems, GA based predictor performs much better than the other two models for position estimation. For orientation learning results indicate that off policy learning through GDQN outperforms MVGG16, since GDQN architecture is specially made suitable for the reinforcement learning. Based on our proposed architectures and algorithms, the robot is capable of grasping all rigid body objects having regular shapes.
Large-scale Gastric Cancer Screening and Localization Using Multi-task Deep Neural Network
Oct 12, 2019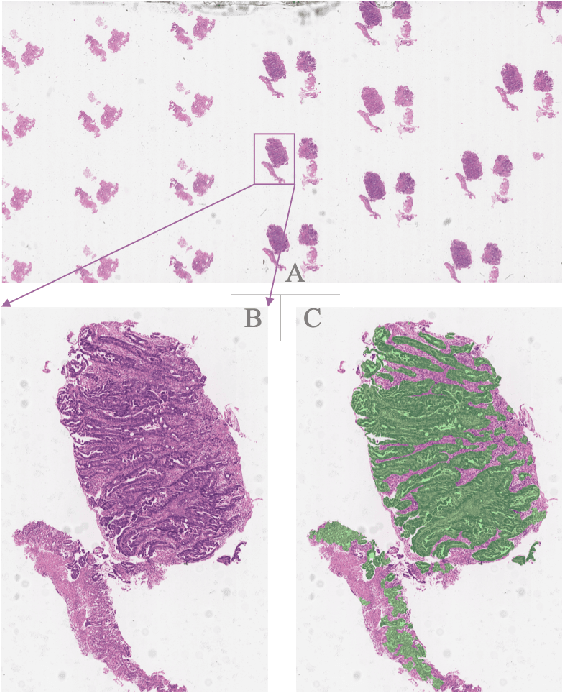
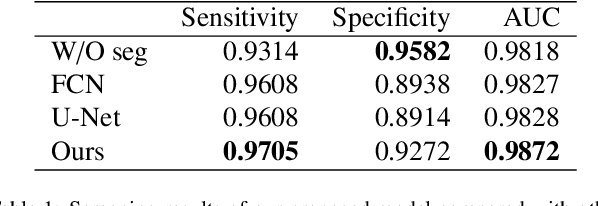
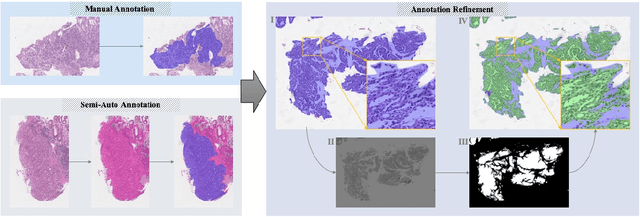
Gastric cancer is one of the most common cancers, which ranks third among the leading causes of cancer death. Biopsy of gastric mucosal is a standard procedure in gastric cancer screening test. However, manual pathological inspection is labor-intensive and time-consuming. Besides, it is challenging for an automated algorithm to locate the small lesion regions in the gigapixel whole-slide image and make the decision correctly. To tackle these issues, we collected large-scale whole-slide image dataset with detailed lesion region annotation and designed a whole-slide image analyzing framework consisting of 3 networks which could not only determine the screen result but also present the suspicious areas to the pathologist for reference. Experiments demonstrated that our proposed framework achieves sensitivity of 97.05% and specificity of 92.72% in screening task and Dice coefficient of 0.8331 in segmentation task. Furthermore, we tested our best model in real-world scenario on 10, 316 whole-slide images collected from 4 medical centers.
FastPET: Near Real-Time PET Reconstruction from Histo-Images Using a Neural Network
Feb 11, 2020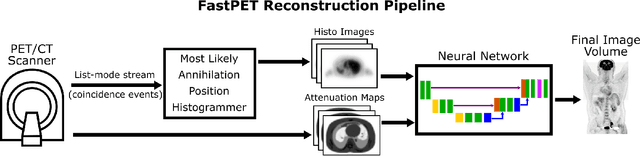
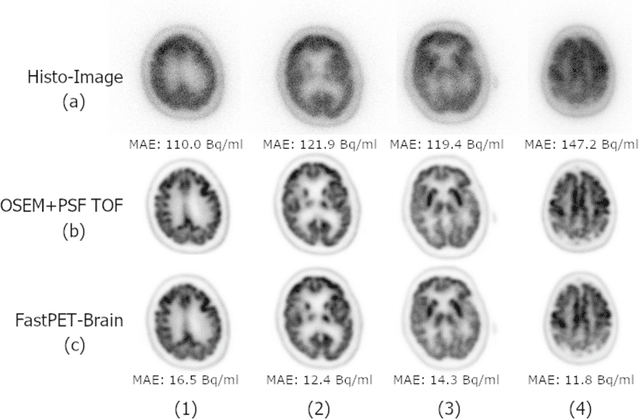

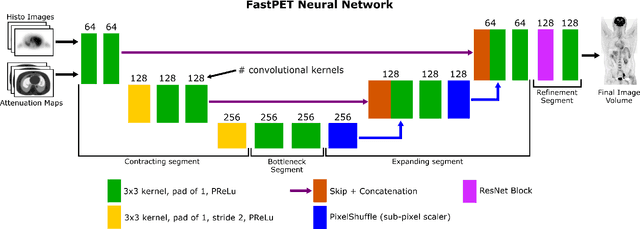
Direct reconstruction of positron emission tomography (PET) data using deep neural networks is a growing field of research. Initial results are promising, but often the networks are complex, memory utilization inefficient, produce relatively small image sizes (e.g. 128x128), and low count rate reconstructions are of varying quality. This paper proposes FastPET, a novel direct reconstruction convolutional neural network that is architecturally simple, memory space efficient, produces larger images (e.g. 440x440) and is capable of processing a wide range of count densities. FastPET operates on noisy and blurred histo-images reconstructing clinical-quality multi-slice image volumes 800x faster than ordered subsets expectation maximization (OSEM). Patient data studies show a higher contrast recovery value than for OSEM with equivalent variance and a higher overall signal-to-noise ratio with both cases due to FastPET's lower noise images. This work also explored the application to low dose PET imaging and found FastPET able to produce images comparable to normal dose with only 50% and 25% counts. We additionally explored the effect of reducing the anatomical region by training specific FastPET variants on brain and chest images and found narrowing the data distribution led to increased performance.