 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Classifying Suspicious Content in Tor Darknet
May 20, 2020
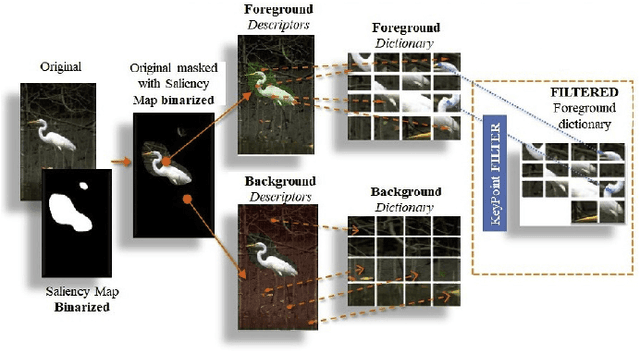


One of the tasks of law enforcement agencies is to find evidence of criminal activity in the Darknet. However, visiting thousands of domains to locate visual information containing illegal acts manually requires a considerable amount of time and resources. Furthermore, the background of the images can pose a challenge when performing classification. To solve this problem, in this paper, we explore the automatic classification Tor Darknet images using Semantic Attention Keypoint Filtering, a strategy that filters non-significant features at a pixel level that do not belong to the object of interest, by combining saliency maps with Bag of Visual Words (BoVW). We evaluated SAKF on a custom Tor image dataset against CNN features: MobileNet v1 and Resnet50, and BoVW using dense SIFT descriptors, achieving a result of 87.98% accuracy and outperforming all other approaches.
ALPS: Active Learning via Perturbations
Apr 20, 2020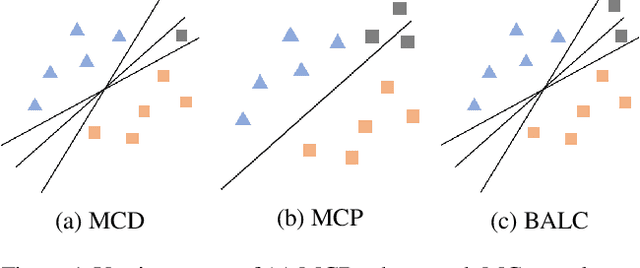
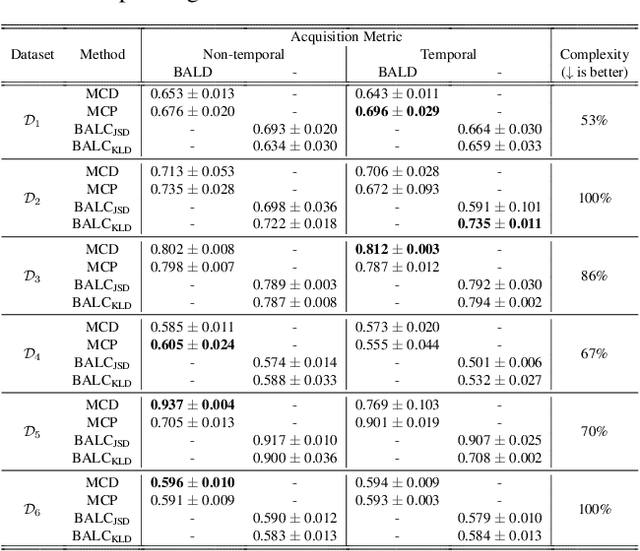
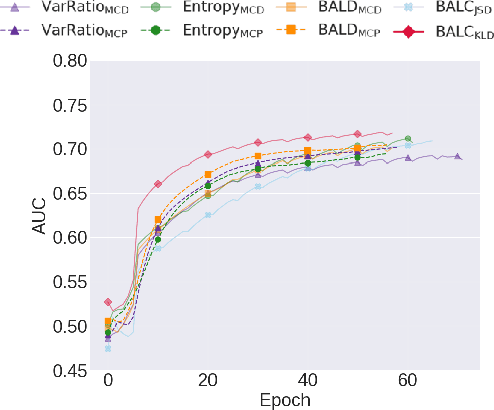
Small, labelled datasets in the presence of larger, unlabelled datasets pose challenges to data-hungry deep learning algorithms. Such scenarios are prevalent in healthcare where labelling is expensive, time-consuming, and requires expert medical professionals. To tackle this challenge, we propose a family of active learning methodologies and acquisition functions dependent upon input and parameter perturbations which we call Active Learning via Perturbations (ALPS). We test our methods on six diverse time-series and image datasets and illustrate their benefit in the presence and absence of an oracle. We also show that acquisition functions that incorporate temporal information have the potential to predict the ability of networks to generalize.
IntegralAction: Pose-driven Feature Integration for Robust Human Action Recognition in Videos
Jul 13, 2020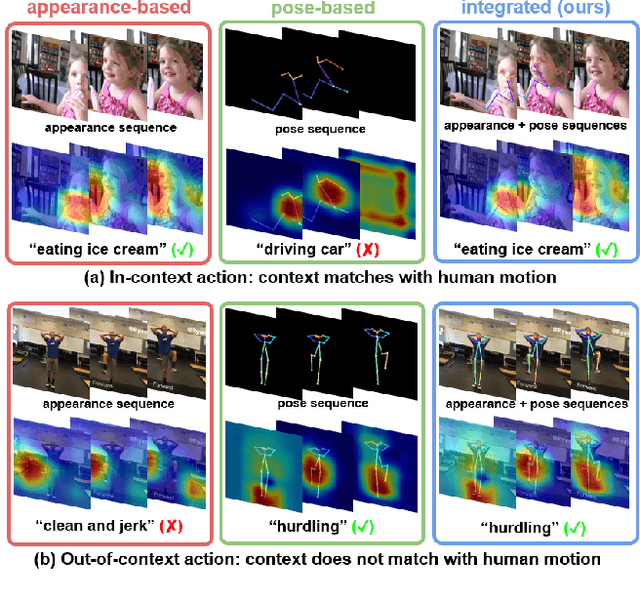
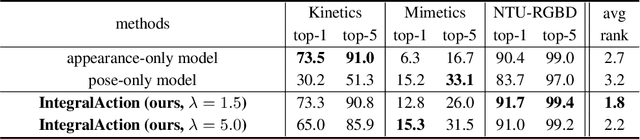
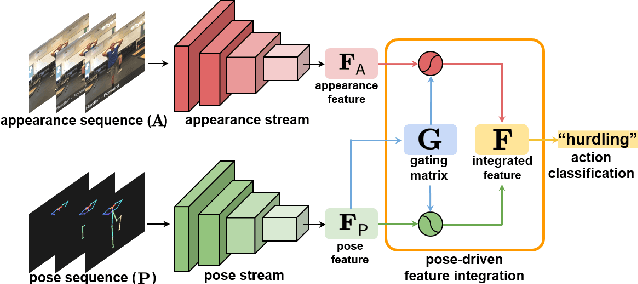
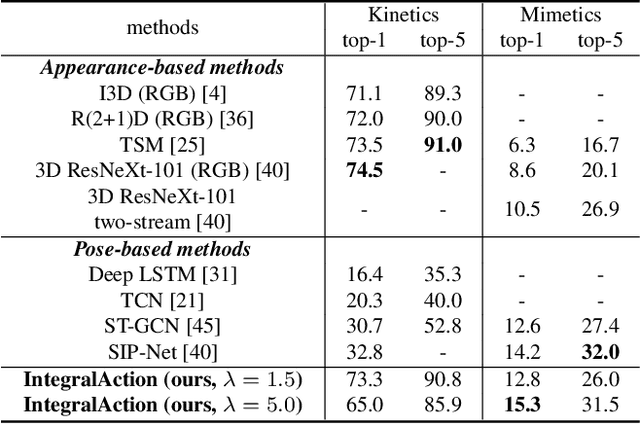
Most current action recognition methods heavily rely on appearance information by taking an RGB sequence of entire image regions as input. While being effective in exploiting contextual information around humans, e.g., human appearance and scene category, they are easily fooled by out-of-context action videos where the contexts do not exactly match with target actions. In contrast, pose-based methods, which takes a sequence of human skeletons only as input, suffer from inaccurate pose estimation or ambiguity of human pose per se. Integrating these two approaches has turned out to be non-trivial; training a model with both appearance and pose ends up with a strong bias towards appearance and does not generalize well to unseen videos. To address this problem, we propose to learn pose-driven feature integration that dynamically combines appearance and pose streams by observing pose features on the fly. The main idea is to let the pose stream decide how much and which appearance information is used in integration based on whether the given pose information is reliable or not. We show that the proposed IntegralAction achieves highly robust performance across in-context and out-of-context action video datasets.
How Much Can We Really Trust You? Towards Simple, Interpretable Trust Quantification Metrics for Deep Neural Networks
Sep 12, 2020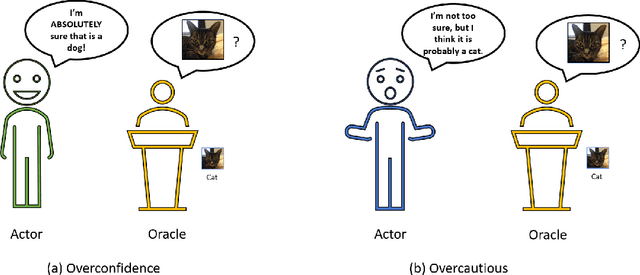

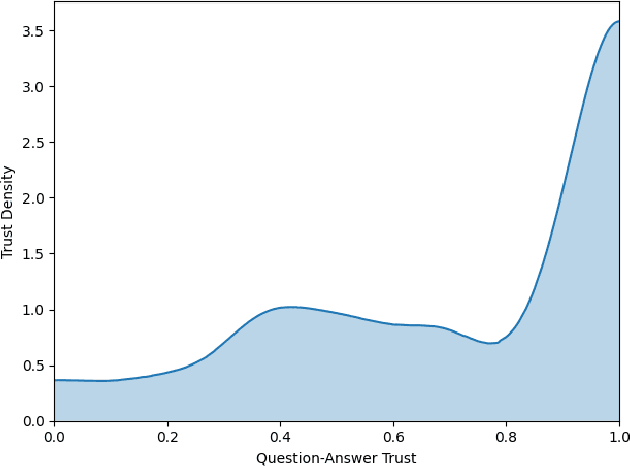
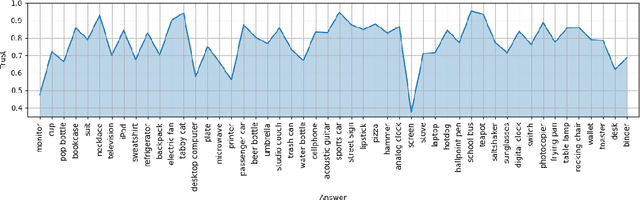
A critical step to building trustworthy deep neural networks is trust quantification, where we ask the question: How much can we trust a deep neural network? In this study, we take a step towards simple, interpretable metrics for trust quantification by introducing a suite of metrics for assessing the overall trustworthiness of deep neural networks based on their behaviour when answering a set of questions. We conduct a thought experiment and explore two key questions about trust in relation to confidence: 1) How much trust do we have in actors who give wrong answers with great confidence?, and 2) How much trust do we have in actors who give right answers hesitantly? Based on insights gained, we introduce the concept of question-answer trust to quantify trustworthiness of an individual answer based on confident behaviour under correct and incorrect answer scenarios, and the concept of trust density to characterize the distribution of overall trust for an individual answer scenario. We further introduce the concept of trust spectrum for representing overall trust with respect to the spectrum of possible answer scenarios across correctly and incorrectly answered questions. Finally, we introduce NetTrustScore, a scalar metric summarizing overall trustworthiness. The suite of metrics aligns with past social psychology studies that study the relationship between trust and confidence. Leveraging these metrics, we quantify the trustworthiness of several well-known deep neural network architectures for image recognition to get a deeper understanding of where trust breaks down. The proposed metrics are by no means perfect, but the hope is to push the conversation towards better metrics to help guide practitioners and regulators in producing, deploying, and certifying deep learning solutions that can be trusted to operate in real-world, mission-critical scenarios.
Unsupervised Vehicle Counting via Multiple Camera Domain Adaptation
Apr 20, 2020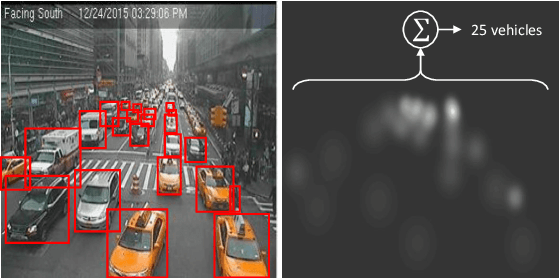
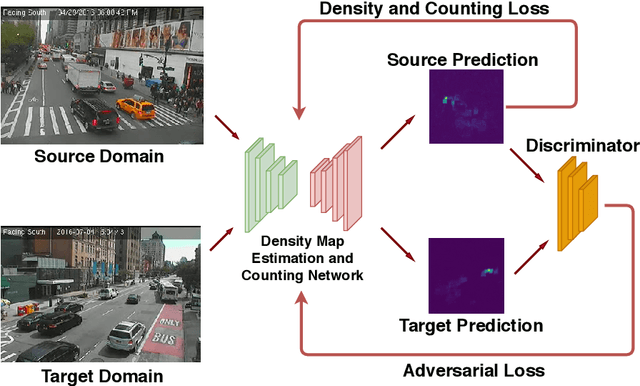
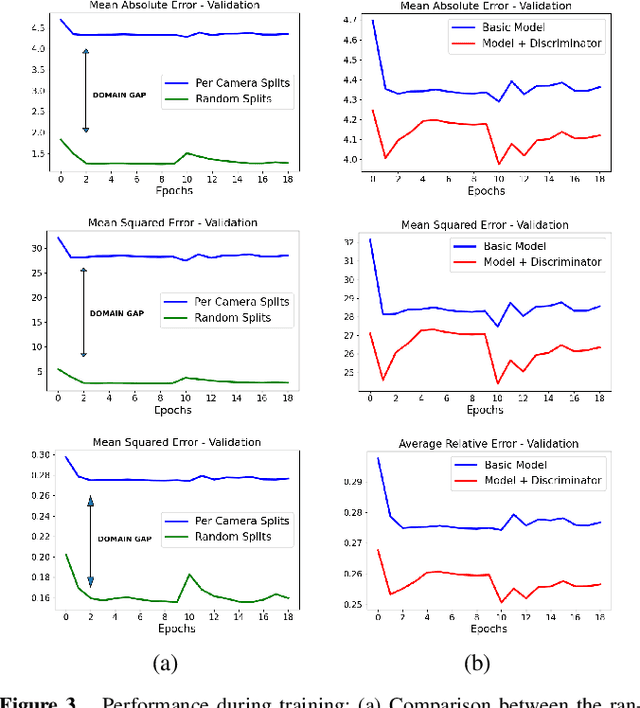
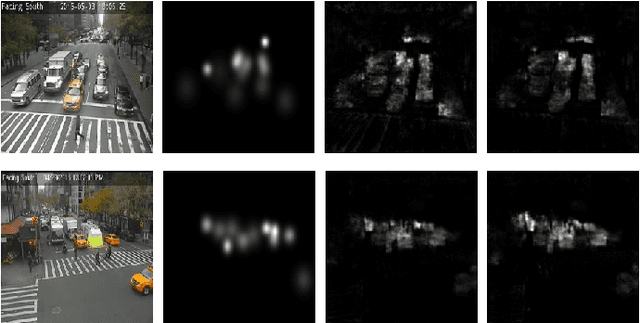
Monitoring vehicle flow in cities is a crucial issue to improve the urban environment and quality of life of citizens. Images are the best sensing modality to perceive and asses the flow of vehicles in large areas. Current technologies for vehicle counting in images hinge on large quantities of annotated data, preventing their scalability to city-scale as new cameras are added to the system. This is a recurrent problem when dealing with physical systems and a key research area in Machine Learning and AI. We propose and discuss a new methodology to design image-based vehicle density estimators with few labeled data via multiple camera domain adaptations.
A Practical Guide to CNNs and Fisher Vectors for Image Instance Retrieval
Aug 25, 2015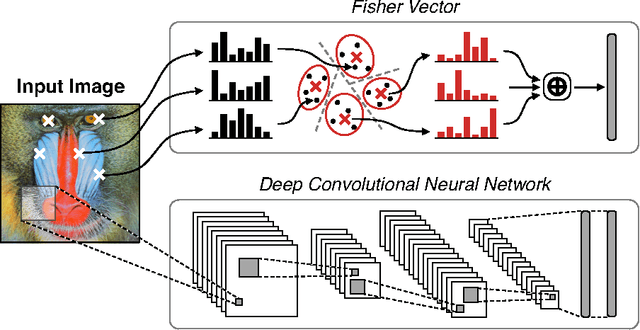
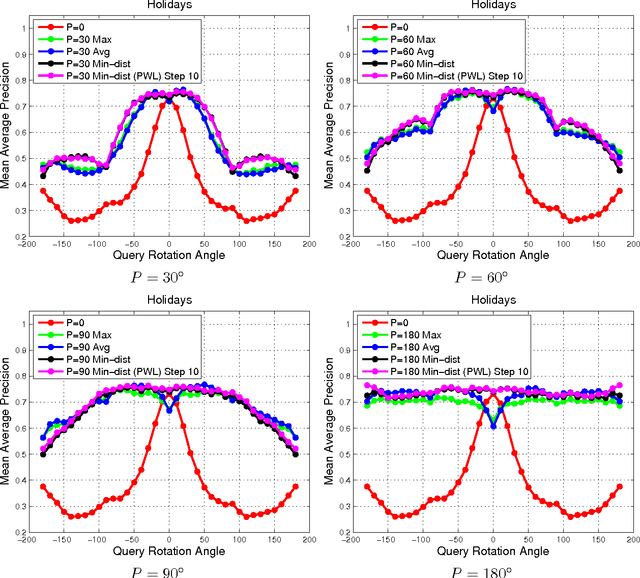
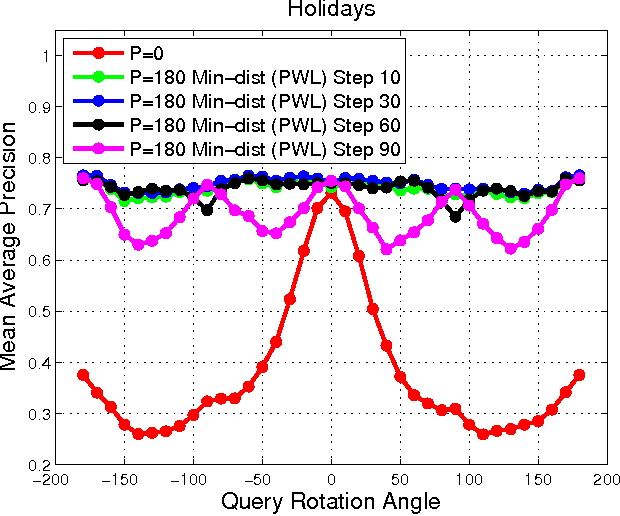
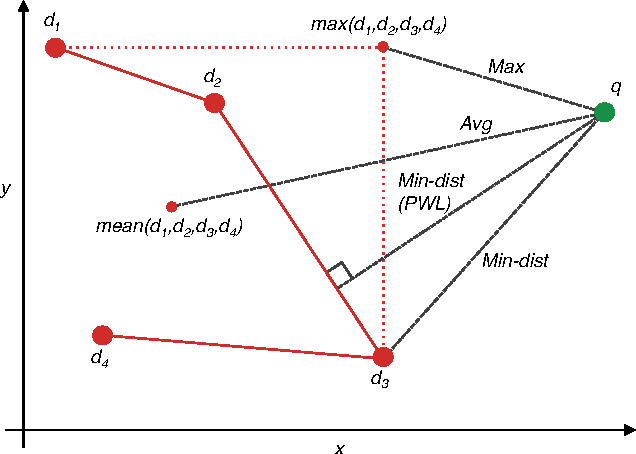
With deep learning becoming the dominant approach in computer vision, the use of representations extracted from Convolutional Neural Nets (CNNs) is quickly gaining ground on Fisher Vectors (FVs) as favoured state-of-the-art global image descriptors for image instance retrieval. While the good performance of CNNs for image classification are unambiguously recognised, which of the two has the upper hand in the image retrieval context is not entirely clear yet. In this work, we propose a comprehensive study that systematically evaluates FVs and CNNs for image retrieval. The first part compares the performances of FVs and CNNs on multiple publicly available data sets. We investigate a number of details specific to each method. For FVs, we compare sparse descriptors based on interest point detectors with dense single-scale and multi-scale variants. For CNNs, we focus on understanding the impact of depth, architecture and training data on retrieval results. Our study shows that no descriptor is systematically better than the other and that performance gains can usually be obtained by using both types together. The second part of the study focuses on the impact of geometrical transformations such as rotations and scale changes. FVs based on interest point detectors are intrinsically resilient to such transformations while CNNs do not have a built-in mechanism to ensure such invariance. We show that performance of CNNs can quickly degrade in presence of rotations while they are far less affected by changes in scale. We then propose a number of ways to incorporate the required invariances in the CNN pipeline. Overall, our work is intended as a reference guide offering practically useful and simply implementable guidelines to anyone looking for state-of-the-art global descriptors best suited to their specific image instance retrieval problem.
GramGAN: Deep 3D Texture Synthesis From 2D Exemplars
Jun 29, 2020

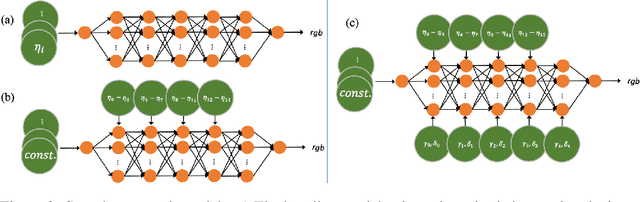

We present a novel texture synthesis framework, enabling the generation of infinite, high-quality 3D textures given a 2D exemplar image. Inspired by recent advances in natural texture synthesis, we train deep neural models to generate textures by non-linearly combining learned noise frequencies. To achieve a highly realistic output conditioned on an exemplar patch, we propose a novel loss function that combines ideas from both style transfer and generative adversarial networks. In particular, we train the synthesis network to match the Gram matrices of deep features from a discriminator network. In addition, we propose two architectural concepts and an extrapolation strategy that significantly improve generalization performance. In particular, we inject both model input and condition into hidden network layers by learning to scale and bias hidden activations. Quantitative and qualitative evaluations on a diverse set of exemplars motivate our design decisions and show that our system performs superior to previous state of the art. Finally, we conduct a user study that confirms the benefits of our framework.
Conceptual Design of Human-Drone Communication in Collaborative Environments
Apr 30, 2020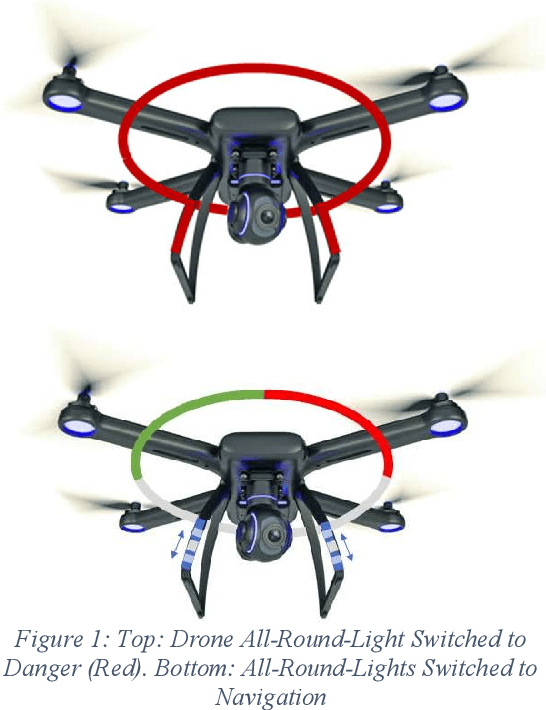
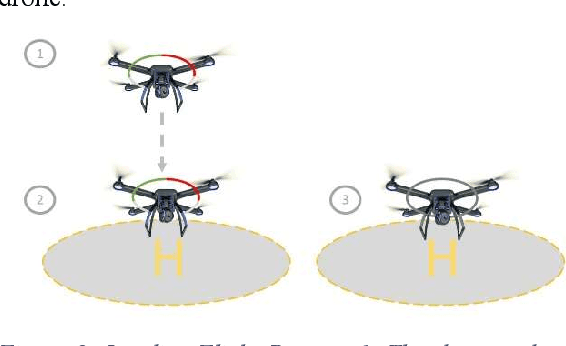
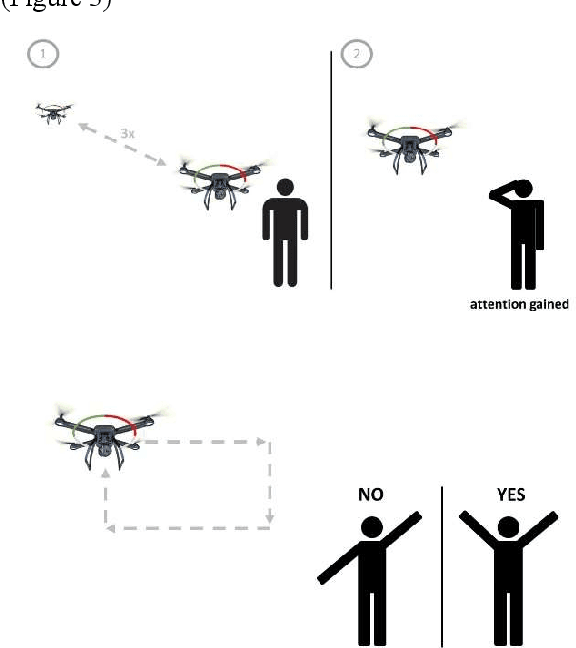
Autonomous robots and drones will work collaboratively and cooperatively in tomorrow's industry and agriculture. Before this becomes a reality, some form of standardised communication between man and machine must be established that specifically facilitates communication between autonomous machines and both trained and untrained human actors in the working environment. We present preliminary results on a human-drone and a drone-human language situated in the agricultural industry where interactions with trained and untrained workers and visitors can be expected. We present basic visual indicators enhanced with flight patterns for drone-human interaction and human signaling based on aircraft marshaling for humane-drone interaction. We discuss preliminary results on image recognition and future work.
JHU-CROWD++: Large-Scale Crowd Counting Dataset and A Benchmark Method
Apr 07, 2020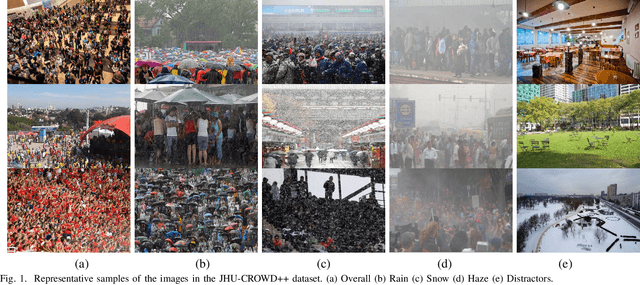
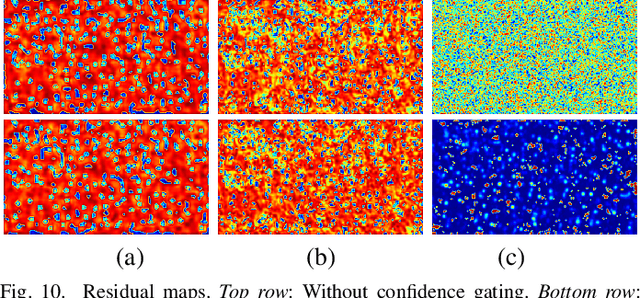
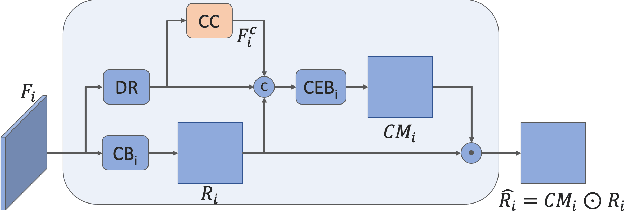

Due to its variety of applications in the real-world, the task of single image-based crowd counting has received a lot of interest in the recent years. Recently, several approaches have been proposed to address various problems encountered in crowd counting. These approaches are essentially based on convolutional neural networks that require large amounts of data to train the network parameters. Considering this, we introduce a new large scale unconstrained crowd counting dataset (JHU-CROWD++) that contains "4,372" images with "1.51 million" annotations. In comparison to existing datasets, the proposed dataset is collected under a variety of diverse scenarios and environmental conditions. Specifically, the dataset includes several images with weather-based degradations and illumination variations, making it a very challenging dataset. Additionally, the dataset consists of a rich set of annotations at both image-level and head-level. Several recent methods are evaluated and compared on this dataset. The dataset can be downloaded from http://www.crowd-counting.com . Furthermore, we propose a novel crowd counting network that progressively generates crowd density maps via residual error estimation. The proposed method uses VGG16 as the backbone network and employs density map generated by the final layer as a coarse prediction to refine and generate finer density maps in a progressive fashion using residual learning. Additionally, the residual learning is guided by an uncertainty-based confidence weighting mechanism that permits the flow of only high-confidence residuals in the refinement path. The proposed Confidence Guided Deep Residual Counting Network (CG-DRCN) is evaluated on recent complex datasets, and it achieves significant improvements in errors.
S3NAS: Fast NPU-aware Neural Architecture Search Methodology
Sep 04, 2020As the application area of convolutional neural networks (CNN) is growing in embedded devices, it becomes popular to use a hardware CNN accelerator, called neural processing unit (NPU), to achieve higher performance per watt than CPUs or GPUs. Recently, automated neural architecture search (NAS) emerges as the default technique to find a state-of-the-art CNN architecture with higher accuracy than manually-designed architectures for image classification. In this paper, we present a fast NPU-aware NAS methodology, called S3NAS, to find a CNN architecture with higher accuracy than the existing ones under a given latency constraint. It consists of three steps: supernet design, Single-Path NAS for fast architecture exploration, and scaling. To widen the search space of the supernet structure that consists of stages, we allow stages to have a different number of blocks and blocks to have parallel layers of different kernel sizes. For a fast neural architecture search, we apply a modified Single-Path NAS technique to the proposed supernet structure. In this step, we assume a shorter latency constraint than the required to reduce the search space and the search time. The last step is to scale up the network maximally within the latency constraint. For accurate latency estimation, an analytical latency estimator is devised, based on a cycle-level NPU simulator that runs an entire CNN considering the memory access overhead accurately. With the proposed methodology, we are able to find a network in 3 hours using TPUv3, which shows 82.72% top-1 accuracy on ImageNet with 11.66 ms latency. Code are released at https://github.com/cap-lab/S3NAS