 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-supervised Learning with a Teacher-student Network for Generalized Attribute Prediction
Jul 14, 2020

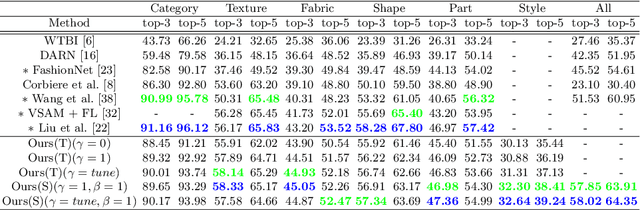

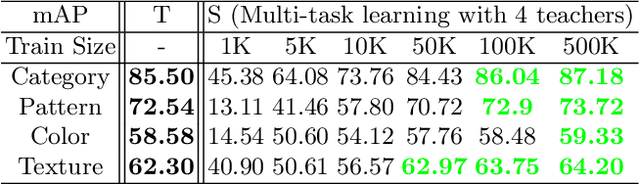
This paper presents a study on semi-supervised learning to solve the visual attribute prediction problem. In many applications of vision algorithms, the precise recognition of visual attributes of objects is important but still challenging. This is because defining a class hierarchy of attributes is ambiguous, so training data inevitably suffer from class imbalance and label sparsity, leading to a lack of effective annotations. An intuitive solution is to find a method to effectively learn image representations by utilizing unlabeled images. With that in mind, we propose a multi-teacher-single-student (MTSS) approach inspired by the multi-task learning and the distillation of semi-supervised learning. Our MTSS learns task-specific domain experts called teacher networks using the label embedding technique and learns a unified model called a student network by forcing a model to mimic the distributions learned by domain experts. Our experiments demonstrate that our method not only achieves competitive performance on various benchmarks for fashion attribute prediction, but also improves robustness and cross-domain adaptability for unseen domains.
Detecting Transaction-based Tax Evasion Activities on Social Media Platforms Using Multi-modal Deep Neural Networks
Jul 27, 2020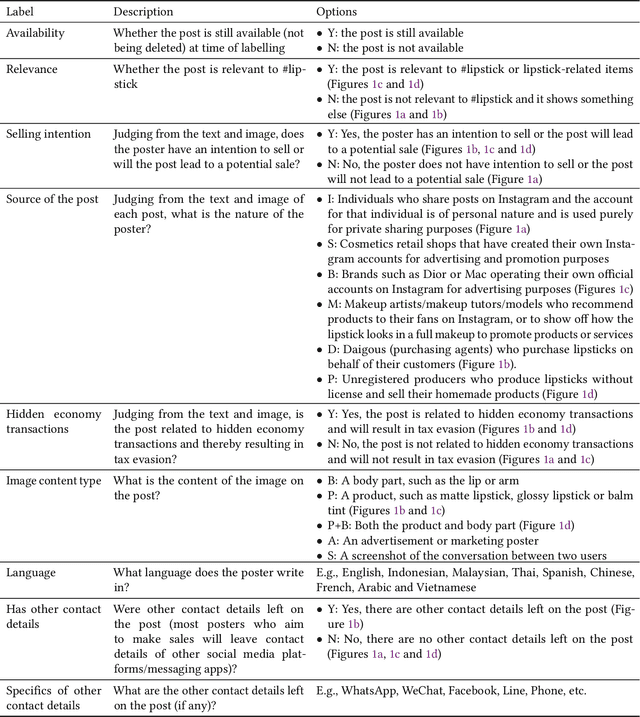

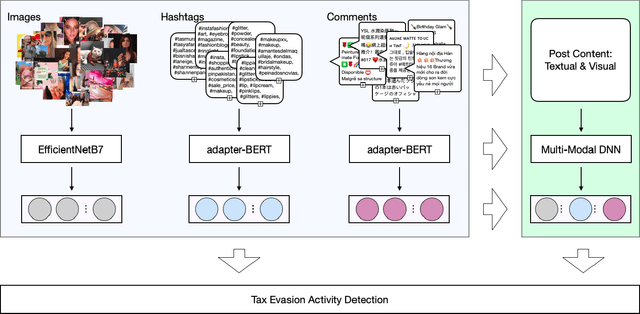
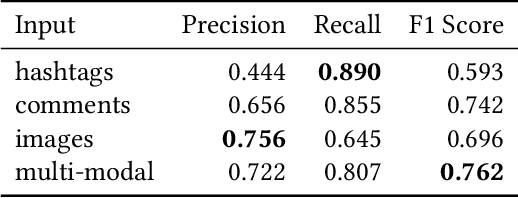
Social media platforms now serve billions of users by providing convenient means of communication, content sharing and even payment between different users. Due to such convenient and anarchic nature, they have also been used rampantly to promote and conduct business activities between unregistered market participants without paying taxes. Tax authorities worldwide face difficulties in regulating these hidden economy activities by traditional regulatory means. This paper presents a machine learning based Regtech tool for international tax authorities to detect transaction-based tax evasion activities on social media platforms. To build such a tool, we collected a dataset of 58,660 Instagram posts and manually labelled 2,081 sampled posts with multiple properties related to transaction-based tax evasion activities. Based on the dataset, we developed a multi-modal deep neural network to automatically detect suspicious posts. The proposed model combines comments, hashtags and image modalities to produce the final output. As shown by our experiments, the combined model achieved an AUC of 0.808 and F1 score of 0.762, outperforming any single modality models. This tool could help tax authorities to identify audit targets in an efficient and effective manner, and combat social e-commerce tax evasion in scale.
DETCID: Detection of Elongated Touching Cells with Inhomogeneous Illumination using a Deep Adversarial Network
Jul 13, 2020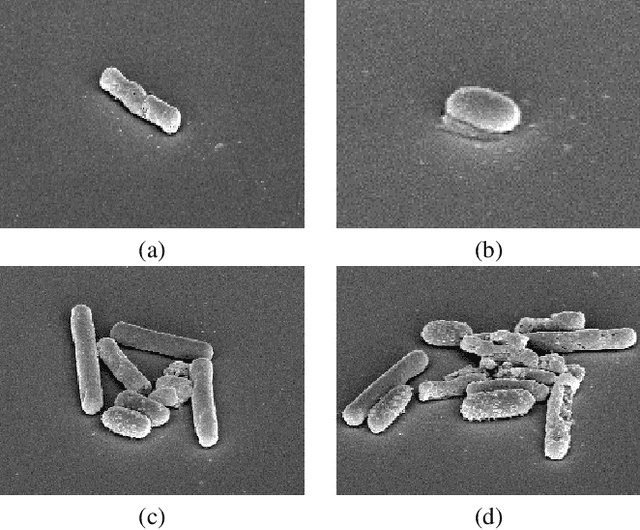
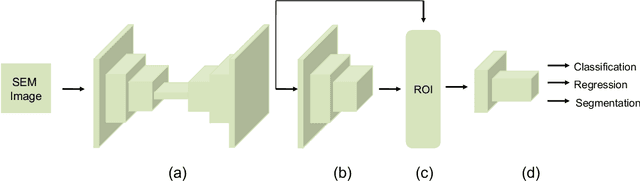
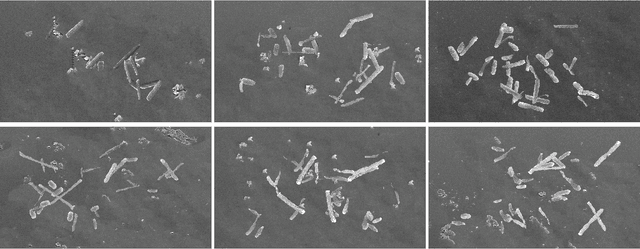

Clostridioides difficile infection (C. diff) is the most common cause of death due to secondary infection in hospital patients in the United States. Detection of C. diff cells in scanning electron microscopy (SEM) images is an important task to quantify the efficacy of the under-development treatments. However, detecting C. diff cells in SEM images is a challenging problem due to the presence of inhomogeneous illumination and occlusion. An Illumination normalization pre-processing step destroys the texture and adds noise to the image. Furthermore, cells are often clustered together resulting in touching cells and occlusion. In this paper, DETCID, a deep cell detection method using adversarial training, specifically robust to inhomogeneous illumination and occlusion, is proposed. An adversarial network is developed to provide region proposals and pass the proposals to a feature extraction network. Furthermore, a modified IoU metric is developed to allow the detection of touching cells in various orientations. The results indicate that DETCID outperforms the state-of-the-art in detection of touching cells in SEM images by at least 20 percent improvement of mean average precision.
FedGAN: Federated Generative AdversarialNetworks for Distributed Data
Jun 12, 2020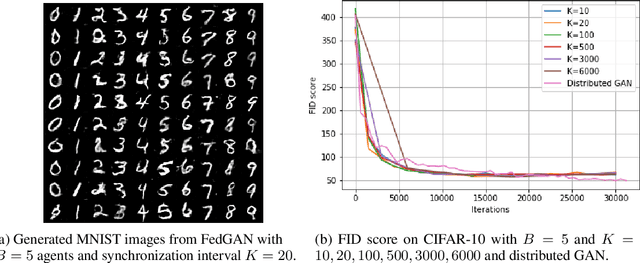
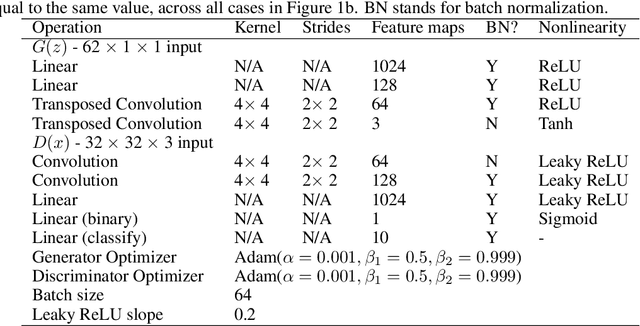
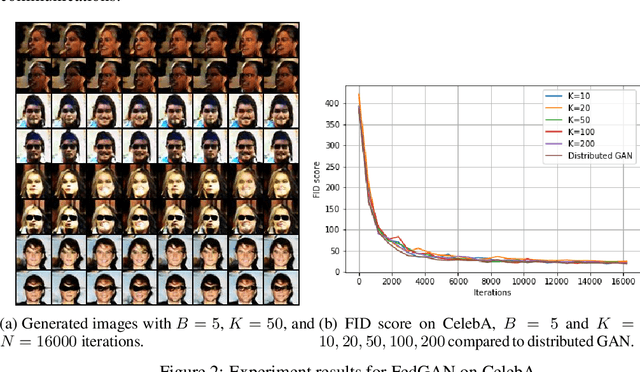
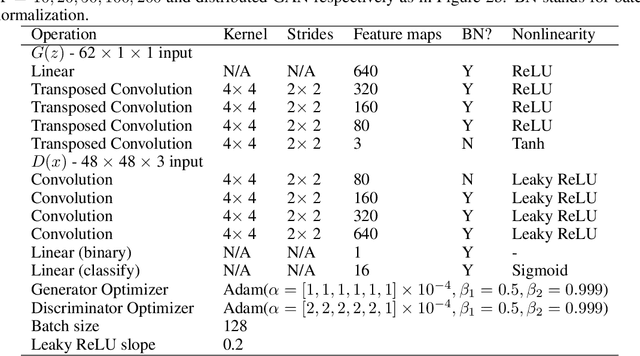
We propose Federated Generative Adversarial Network (FedGAN) for training a GAN across distributed sources of non-independent-and-identically-distributed data sources subject to communication and privacy constraints. Our algorithm uses local generators and discriminators which are periodically synced via an intermediary that averages and broadcasts the generator and discriminator parameters. We theoretically prove the convergence of FedGAN with both equal and two time-scale updates of generator and discriminator, under standard assumptions, using stochastic approximations and communication efficient stochastic gradient descents. We experiment FedGAN on toy examples (2D system, mixed Gaussian, and Swiss role), image datasets (MNIST, CIFAR-10, and CelebA), and time series datasets (household electricity consumption and electric vehicle charging sessions). We show FedGAN converges and has similar performance to general distributed GAN, while reduces communication complexity. We also show its robustness to reduced communications.
A Survey on Impact of Transient Faults on BNN Inference Accelerators
Apr 10, 2020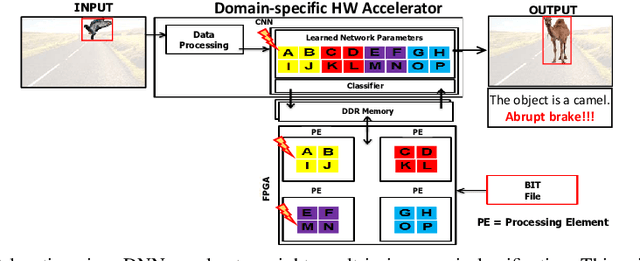
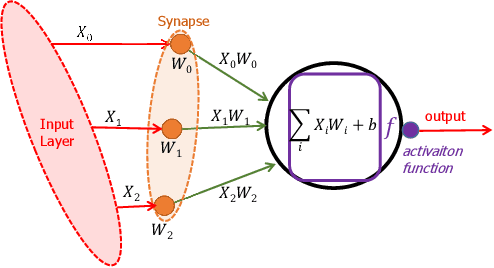
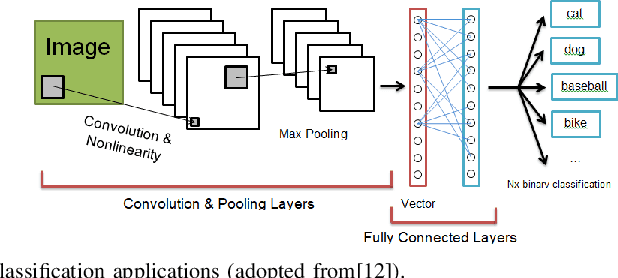
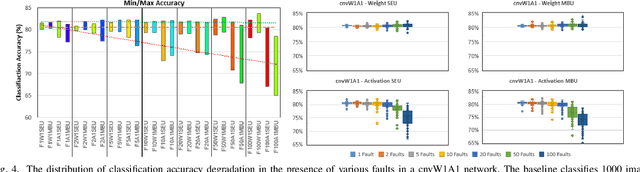
Over past years, the philosophy for designing the artificial intelligence algorithms has significantly shifted towards automatically extracting the composable systems from massive data volumes. This paradigm shift has been expedited by the big data booming which enables us to easily access and analyze the highly large data sets. The most well-known class of big data analysis techniques is called deep learning. These models require significant computation power and extremely high memory accesses which necessitate the design of novel approaches to reduce the memory access and improve power efficiency while taking into account the development of domain-specific hardware accelerators to support the current and future data sizes and model structures.The current trends for designing application-specific integrated circuits barely consider the essential requirement for maintaining the complex neural network computation to be resilient in the presence of soft errors. The soft errors might strike either memory storage or combinational logic in the hardware accelerator that can affect the architectural behavior such that the precision of the results fall behind the minimum allowable correctness. In this study, we demonstrate that the impact of soft errors on a customized deep learning algorithm called Binarized Neural Network might cause drastic image misclassification. Our experimental results show that the accuracy of image classifier can drastically drop by 76.70% and 19.25% in lfcW1A1 and cnvW1A1 networks,respectively across CIFAR-10 and MNIST datasets during the fault injection for the worst-case scenarios
Direct Energy-resolving CT Imaging via Energy-integrating CT images using a Unified Generative Adversarial Network
Oct 14, 2019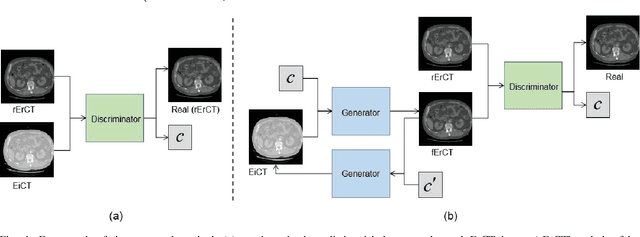
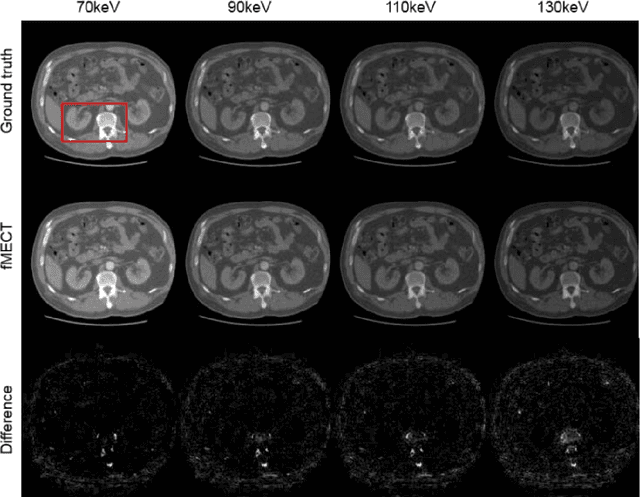
Energy-resolving computed tomography (ErCT) has the ability to acquire energy-dependent measurements simultaneously and quantitative material information with improved contrast-to-noise ratio. Meanwhile, ErCT imaging system is usually equipped with an advanced photon counting detector, which is expensive and technically complex. Therefore, clinical ErCT scanners are not yet commercially available, and they are in various stage of completion. This makes the researchers less accessible to the ErCT images. In this work, we investigate to produce ErCT images directly from existing energy-integrating CT (EiCT) images via deep neural network. Specifically, different from other networks that produce ErCT images at one specific energy, this model employs a unified generative adversarial network (uGAN) to concurrently train EiCT datasets and ErCT datasets with different energies and then performs image-to-image translation from existing EiCT images to multiple ErCT image outputs at various energy bins. In this study, the present uGAN generates ErCT images at 70keV, 90keV, 110keV, and 130keV simultaneously from EiCT images at140kVp. We evaluate the present uGAN model on a set of over 1380 CT image slices and show that the present uGAN model can produce promising ErCT estimation results compared with the ground truth qualitatively and quantitatively.
Split Computing for Complex Object Detectors: Challenges and Preliminary Results
Jul 27, 2020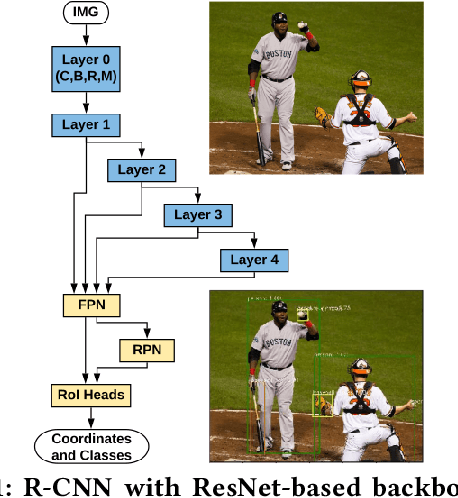
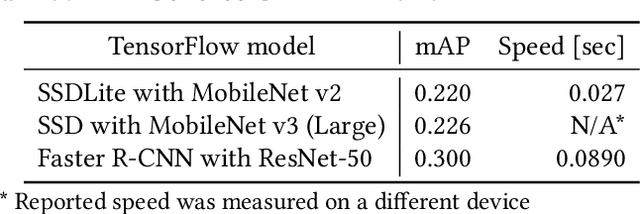
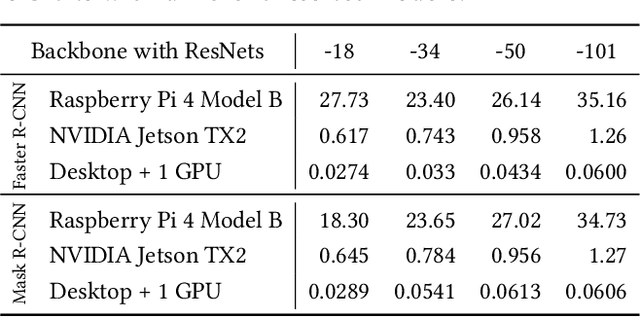
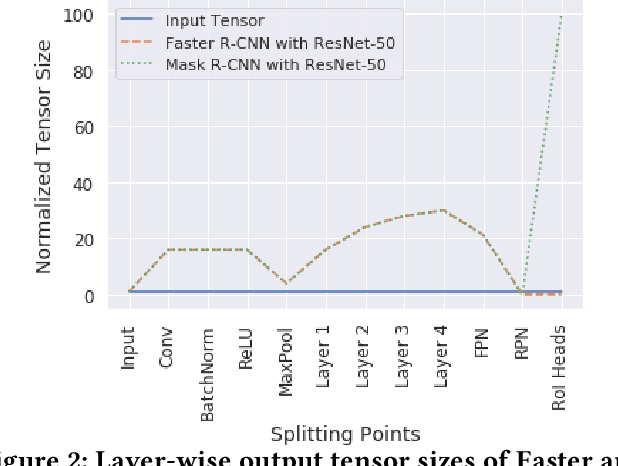
Following the trends of mobile and edge computing for DNN models, an intermediate option, split computing, has been attracting attentions from the research community. Previous studies empirically showed that while mobile and edge computing often would be the best options in terms of total inference time, there are some scenarios where split computing methods can achieve shorter inference time. All the proposed split computing approaches, however, focus on image classification tasks, and most are assessed with small datasets that are far from the practical scenarios. In this paper, we discuss the challenges in developing split computing methods for powerful R-CNN object detectors trained on a large dataset, COCO 2017. We extensively analyze the object detectors in terms of layer-wise tensor size and model size, and show that naive split computing methods would not reduce inference time. To the best of our knowledge, this is the first study to inject small bottlenecks to such object detectors and unveil the potential of a split computing approach. The source code and trained models' weights used in this study are available at https://github.com/yoshitomo-matsubara/hnd-ghnd-object-detectors .
Geometry-Inspired Top-k Adversarial Perturbations
Jun 28, 2020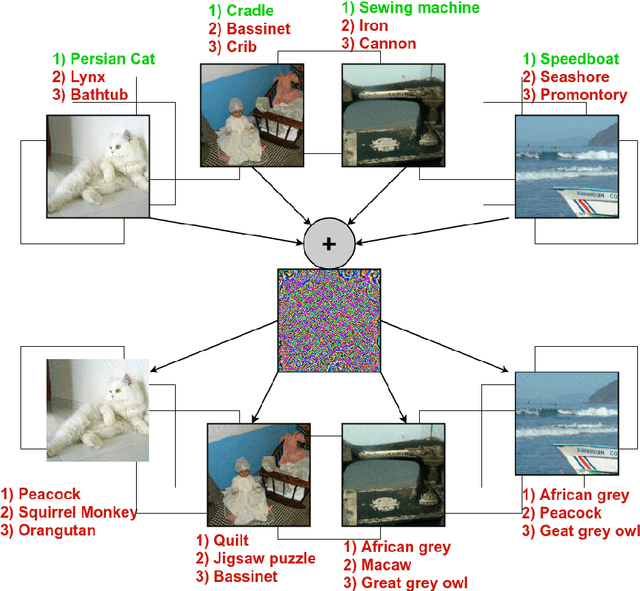

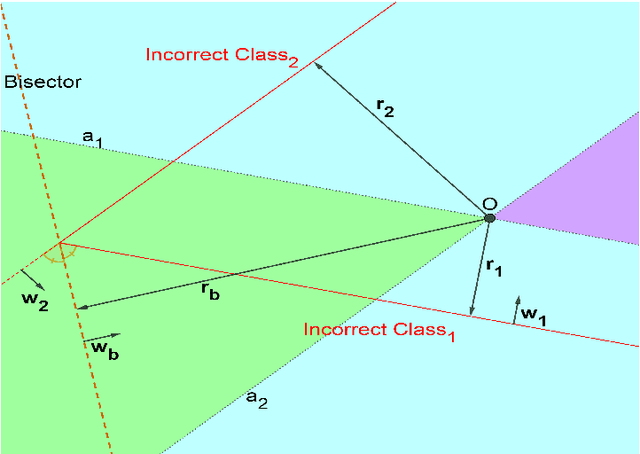

State-of-the-art deep learning models are untrustworthy due to their vulnerability to adversarial examples. Intriguingly, besides simple adversarial perturbations, there exist Universal Adversarial Perturbations (UAPs), which are input-agnostic perturbations that lead to misclassification of majority inputs. The main target of existing adversarial examples (including UAPs) is to change primarily the correct Top-1 predicted class by the incorrect one, which does not guarantee changing the Top-k prediction. However, in many real-world scenarios, dealing with digital data, Top-k predictions are more important. We propose an effective geometry-inspired method of computing Top-k adversarial examples for any k. We evaluate its effectiveness and efficiency by comparing it with other adversarial example crafting techniques. Based on this method, we propose Top-k Universal Adversarial Perturbations, image-agnostic tiny perturbations that cause true class to be absent among the Top-k pre-diction. We experimentally show that our approach outperforms baseline methods and even improves existing techniques of generating UAPs.
Lung Cancer Detection and Classification based on Image Processing and Statistical Learning
Nov 25, 2019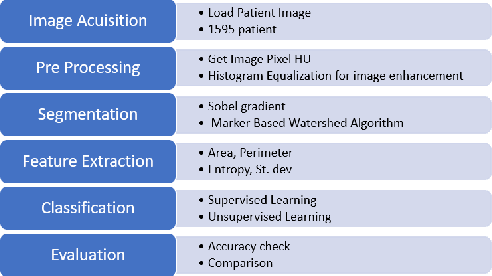
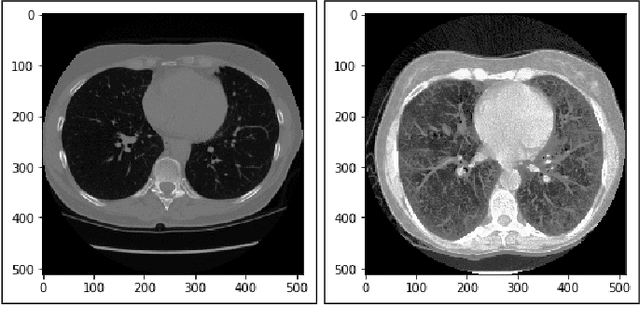
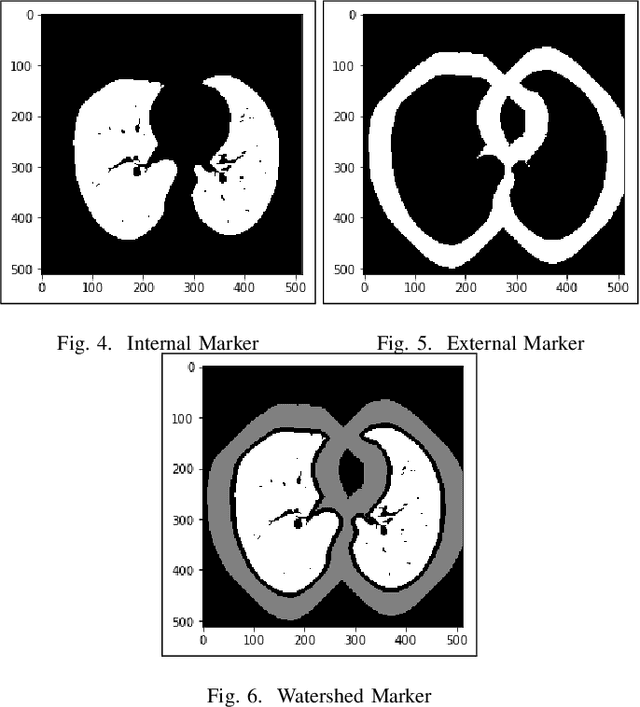
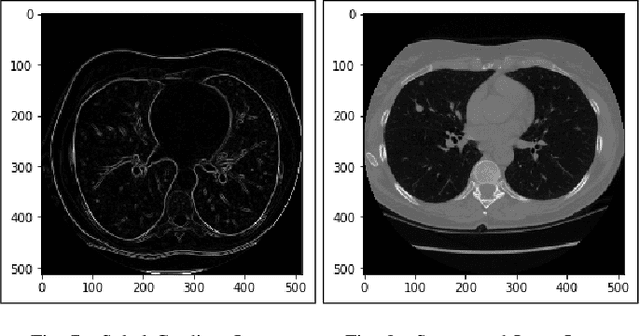
Lung cancer is one of the death threatening diseases among human beings. Early and accurate detection of lung cancer can increase the survival rate from lung cancer. Computed Tomography (CT) images are commonly used for detecting the lung cancer.Using a data set of thousands of high-resolution lung scans collected from Kaggle competition [1], we will develop algorithms that accurately determine in the lungs are cancerous or not. The proposed system promises better result than the existing systems, which would be beneficial for the radiologist for the accurate and early detection of cancer. The method has been tested on 198 slices of CT images of various stages of cancer obtained from Kaggle dataset[1] and is found satisfactory results. The accuracy of the proposed method in this dataset is 72.2%
Learning 2D-3D Correspondences To Solve The Blind Perspective-n-Point Problem
Mar 15, 2020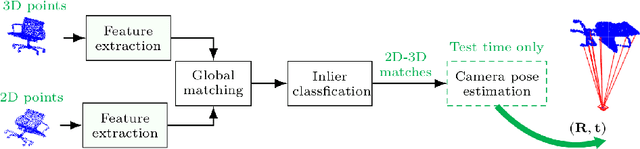

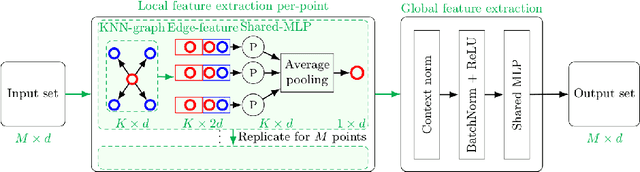

Conventional absolute camera pose via a Perspective-n-Point (PnP) solver often assumes that the correspondences between 2D image pixels and 3D points are given. When the correspondences between 2D and 3D points are not known a priori, the task becomes the much more challenging blind PnP problem. This paper proposes a deep CNN model which simultaneously solves for both the 6-DoF absolute camera pose and 2D--3D correspondences. Our model comprises three neural modules connected in sequence. First, a two-stream PointNet-inspired network is applied directly to both the 2D image keypoints and the 3D scene points in order to extract discriminative point-wise features harnessing both local and contextual information. Second, a global feature matching module is employed to estimate a matchability matrix among all 2D--3D pairs. Third, the obtained matchability matrix is fed into a classification module to disambiguate inlier matches. The entire network is trained end-to-end, followed by a robust model fitting (P3P-RANSAC) at test time only to recover the 6-DoF camera pose. Extensive tests on both real and simulated data have shown that our method substantially outperforms existing approaches, and is capable of processing thousands of points a second with the state-of-the-art accuracy.