 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-Paced Representation Learning with Partial Curricula for Sketch-based Image Retrieval
Mar 05, 2018
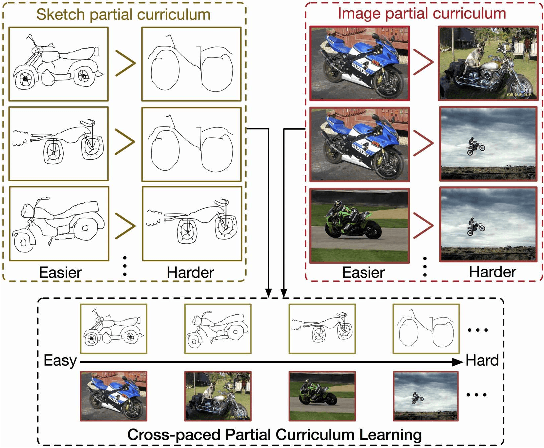
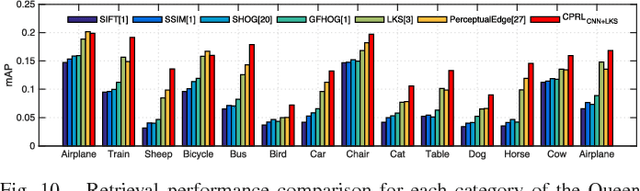
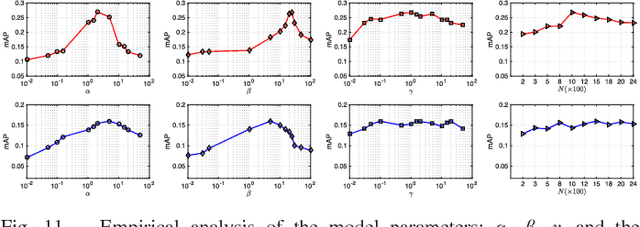
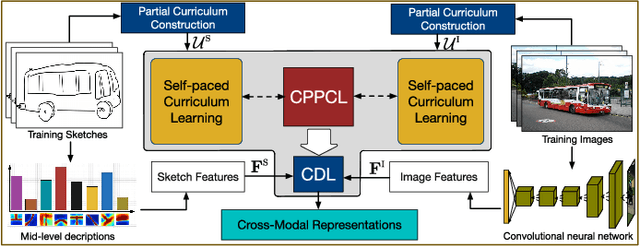
In this paper we address the problem of learning robust cross-domain representations for sketch-based image retrieval (SBIR). While most SBIR approaches focus on extracting low- and mid-level descriptors for direct feature matching, recent works have shown the benefit of learning coupled feature representations to describe data from two related sources. However, cross-domain representation learning methods are typically cast into non-convex minimization problems that are difficult to optimize, leading to unsatisfactory performance. Inspired by self-paced learning, a learning methodology designed to overcome convergence issues related to local optima by exploiting the samples in a meaningful order (i.e. easy to hard), we introduce the cross-paced partial curriculum learning (CPPCL) framework. Compared with existing self-paced learning methods which only consider a single modality and cannot deal with prior knowledge, CPPCL is specifically designed to assess the learning pace by jointly handling data from dual sources and modality-specific prior information provided in the form of partial curricula. Additionally, thanks to the learned dictionaries, we demonstrate that the proposed CPPCL embeds robust coupled representations for SBIR. Our approach is extensively evaluated on four publicly available datasets (i.e. CUFS, Flickr15K, QueenMary SBIR and TU-Berlin Extension datasets), showing superior performance over competing SBIR methods.
Aerial image geolocalization from recognition and matching of roads and intersections
May 26, 2016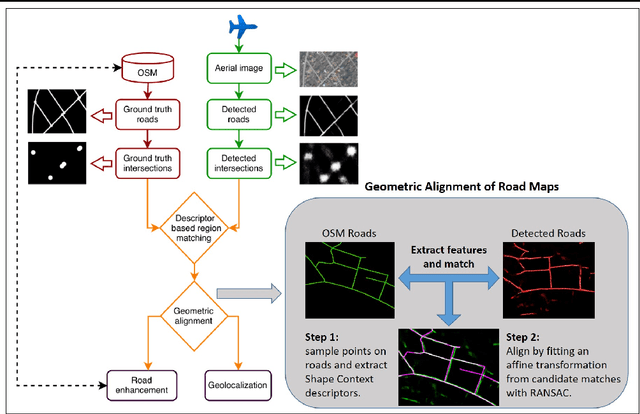
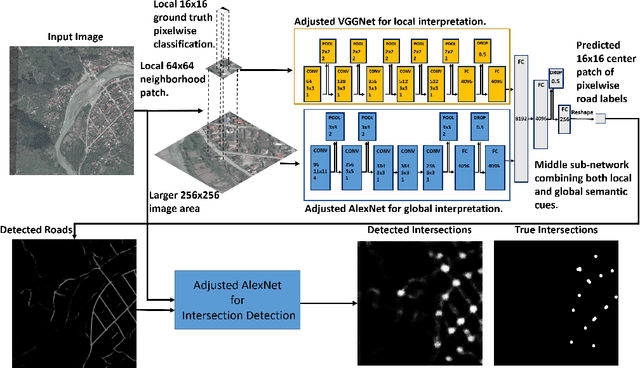
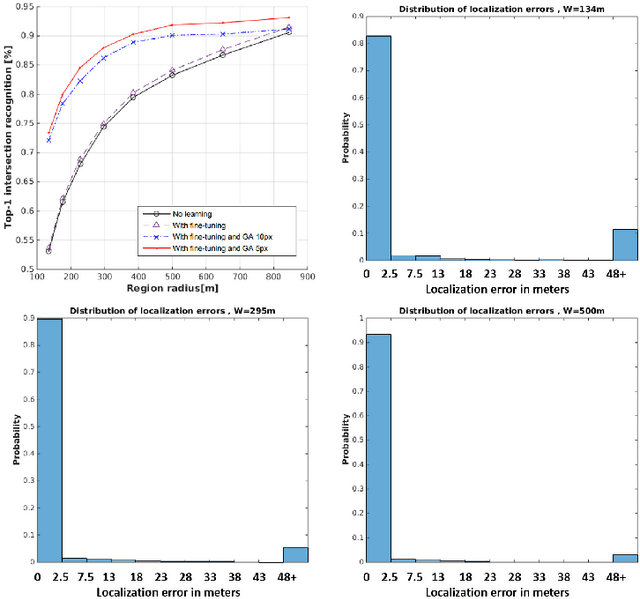

Aerial image analysis at a semantic level is important in many applications with strong potential impact in industry and consumer use, such as automated mapping, urban planning, real estate and environment monitoring, or disaster relief. The problem is enjoying a great interest in computer vision and remote sensing, due to increased computer power and improvement in automated image understanding algorithms. In this paper we address the task of automatic geolocalization of aerial images from recognition and matching of roads and intersections. Our proposed method is a novel contribution in the literature that could enable many applications of aerial image analysis when GPS data is not available. We offer a complete pipeline for geolocalization, from the detection of roads and intersections, to the identification of the enclosing geographic region by matching detected intersections to previously learned manually labeled ones, followed by accurate geometric alignment between the detected roads and the manually labeled maps. We test on a novel dataset with aerial images of two European cities and use the publicly available OpenStreetMap project for collecting ground truth roads annotations. We show in extensive experiments that our approach produces highly accurate localizations in the challenging case when we train on images from one city and test on the other and the quality of the aerial images is relatively poor. We also show that the the alignment between detected roads and pre-stored manual annotations can be effectively used for improving the quality of the road detection results.
AcED: Accurate and Edge-consistent Monocular Depth Estimation
Jun 16, 2020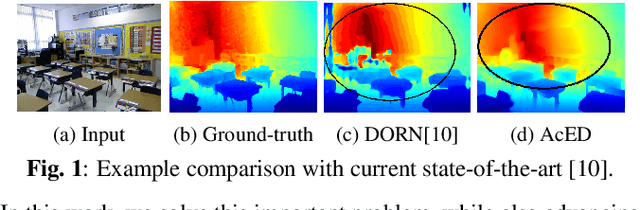
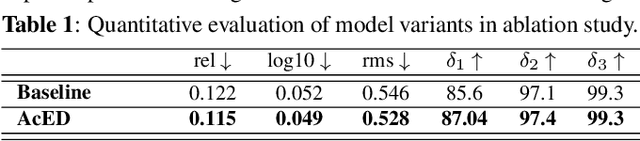
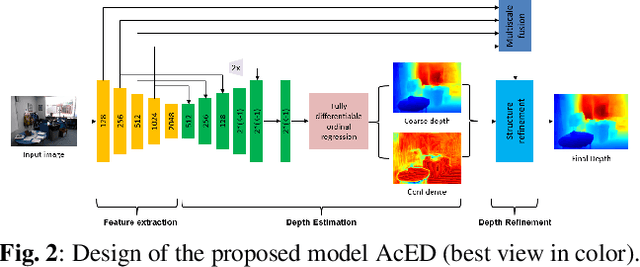
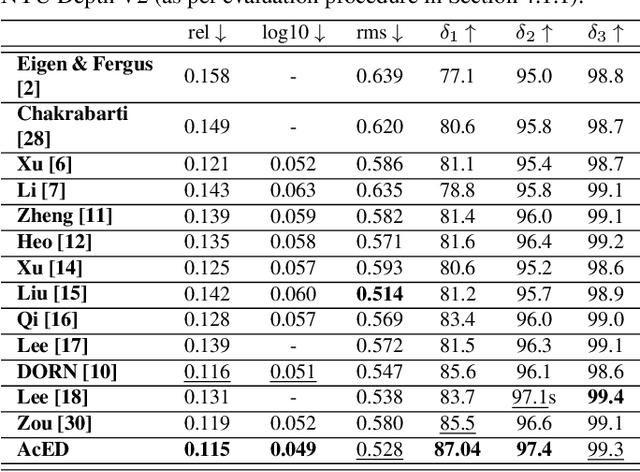
Single image depth estimation is a challenging problem. The current state-of-the-art method formulates the problem as that of ordinal regression. However, the formulation is not fully differentiable and depth maps are not generated in an end-to-end fashion. The method uses a na\"ive threshold strategy to determine per-pixel depth labels, which results in significant discretization errors. For the first time, we formulate a fully differentiable ordinal regression and train the network in end-to-end fashion. This enables us to include boundary and smoothness constraints in the optimization function, leading to smooth and edge-consistent depth maps. A novel per-pixel confidence map computation for depth refinement is also proposed. Extensive evaluation of the proposed model on challenging benchmarks reveals its superiority over recent state-of-the-art methods, both quantitatively and qualitatively. Additionally, we demonstrate practical utility of the proposed method for single camera bokeh solution using in-house dataset of challenging real-life images.
A Robust Iris Authentication System on GPU-Based Edge Devices using Multi-Modalities Learning Model
Dec 02, 2019
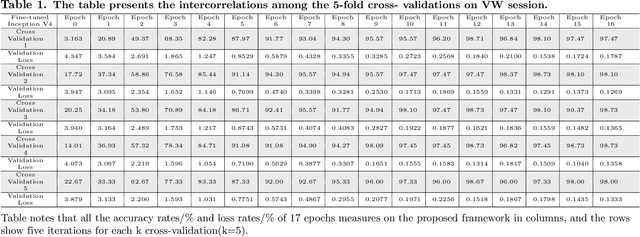
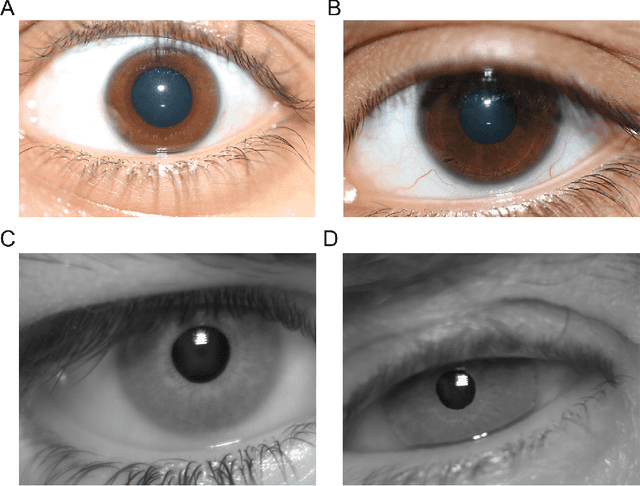
In recent years, mobile Internet has accelerated the proliferation of smart mobile development. The mobile payment, mobile security and privacy protection have become the focus of widespread attention. Iris recognition becomes a high-security authentication technology in these fields, it is widely used in distinct science fields in biometric authentication fields. The Convolutional Neural Network (CNN) is one of the mainstream deep learning approaches for image recognition, whereas its anti-noise ability is weak and needs a certain amount of memory to train in image classification tasks. Under these conditions we put forward a fine-tuning neural network model based on the Mask R-CNN and Inception V4 neural network model, which integrates every component in an overall system that combines the iris detection, extraction, and recognition function as an iris recognition system. The proposed framework has the characteristics of scalability and high availability; it not only can learn part-whole relationships of the iris image but also enhancing the robustness of the whole framework. Importantly, the proposed model can be trained using the different spectrum of samples, such as Visible Wavelength (VW) and Near Infrared (NIR) iris biometric databases. The recognition average accuracy of 99.10% is achieved while executing in the mobile edge calculation device of the Jetson Nano.
A Multi-Hypothesis Approach to Color Constancy
Mar 02, 2020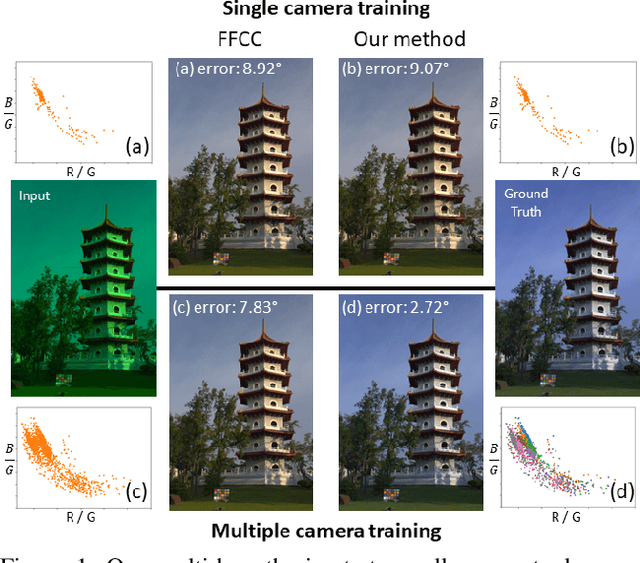
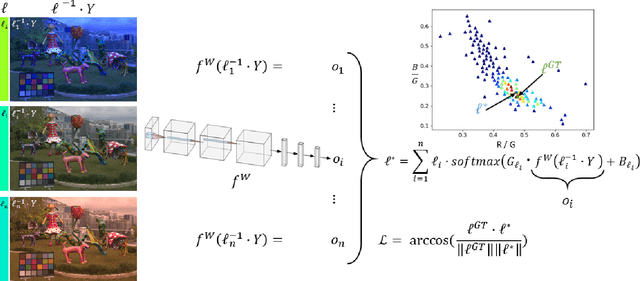
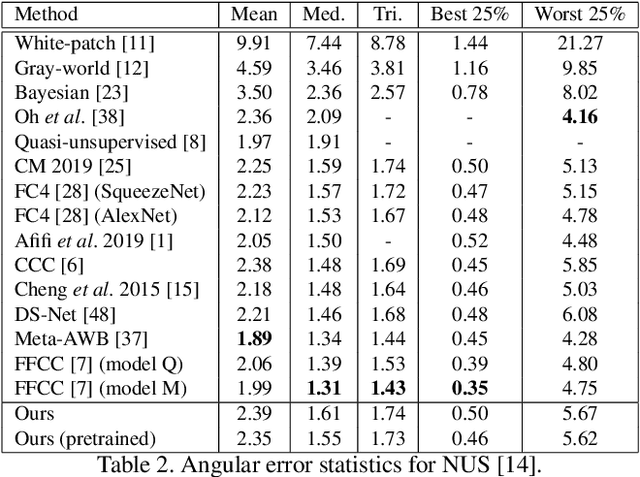
Contemporary approaches frame the color constancy problem as learning camera specific illuminant mappings. While high accuracy can be achieved on camera specific data, these models depend on camera spectral sensitivity and typically exhibit poor generalisation to new devices. Additionally, regression methods produce point estimates that do not explicitly account for potential ambiguities among plausible illuminant solutions, due to the ill-posed nature of the problem. We propose a Bayesian framework that naturally handles color constancy ambiguity via a multi-hypothesis strategy. Firstly, we select a set of candidate scene illuminants in a data-driven fashion and apply them to a target image to generate of set of corrected images. Secondly, we estimate, for each corrected image, the likelihood of the light source being achromatic using a camera-agnostic CNN. Finally, our method explicitly learns a final illumination estimate from the generated posterior probability distribution. Our likelihood estimator learns to answer a camera-agnostic question and thus enables effective multi-camera training by disentangling illuminant estimation from the supervised learning task. We extensively evaluate our proposed approach and additionally set a benchmark for novel sensor generalisation without re-training. Our method provides state-of-the-art accuracy on multiple public datasets (up to 11% median angular error improvement) while maintaining real-time execution.
Transfer Learning for Brain Tumor Segmentation
Dec 28, 2019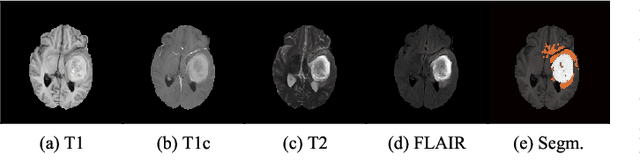
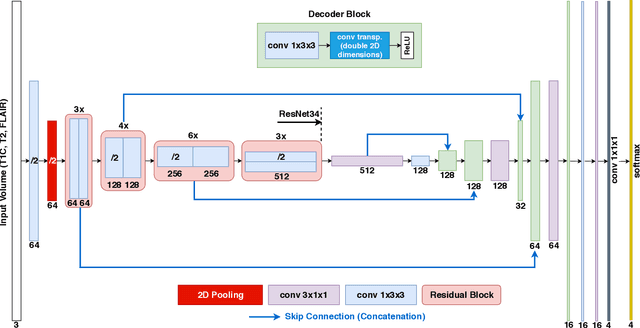
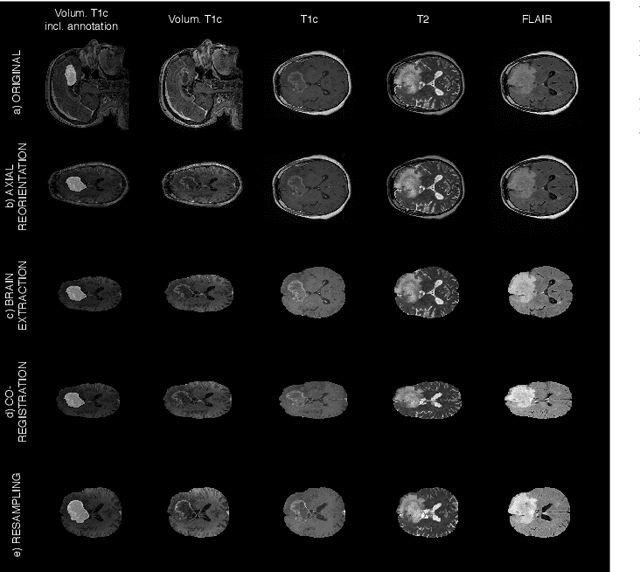
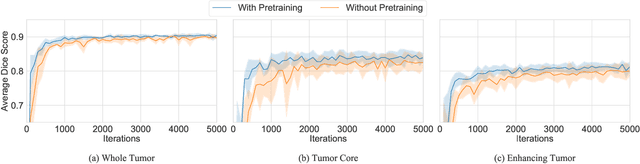
Gliomas are the most common malignant brain tumors that are treated with chemoradiotherapy and surgery. Magnetic Resonance Imaging (MRI) is used by radiotherapists to manually segment brain lesions and to observe their development throughout the therapy. The manual image segmentation process is time-consuming and results tend to vary among different human raters. Therefore, there is a substantial demand for automatic image segmentation algorithms that produce a reliable and accurate segmentation of various brain tissue types. Recent advances in deep learning have led to convolutional neural network architectures that excel at various visual recognition tasks. They have been successfully applied to the medical context including medical image segmentation. In particular, fully convolutional networks (FCNs) such as the U-Net produce state-of-the-art results in the automatic segmentation of brain tumors. MRI brain scans are volumetric and exist in various co-registered modalities that serve as input channels for these FCN architectures. Training algorithms for brain tumor segmentation on this complex input requires large amounts of computational resources and is prone to overfitting. In this work, we construct FCNs with pretrained convolutional encoders. We show that we can stabilize the training process this way and produce more robust predictions. We evaluate our methods on publicly available data as well as on a privately acquired clinical dataset. We also show that the impact of pretraining is even higher for predictions on the clinical data.
Super-Resolution-based Snake Model -- An Unsupervised Method for Large-Scale Building Extraction using Airborne LiDAR Data and Optical Image
Apr 18, 2020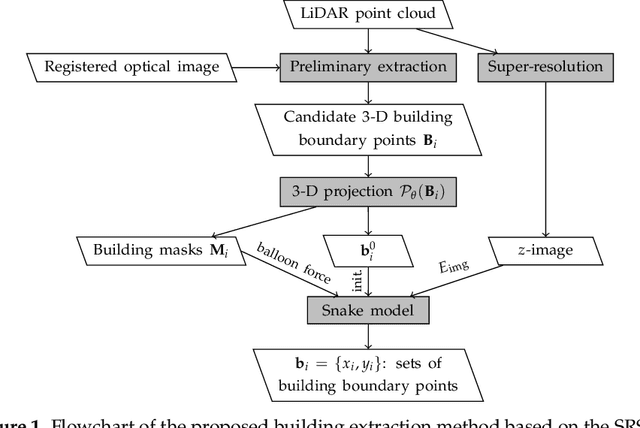



Automatic extraction of buildings in urban and residential scenes has become a subject of growing interest in the domain of photogrammetry and remote sensing, particularly since mid-1990s. Active contour model, colloquially known as snake model, has been studied to extract buildings from aerial and satellite imagery. However, this task is still very challenging due to the complexity of building size, shape, and its surrounding environment. This complexity leads to a major obstacle for carrying out a reliable large-scale building extraction, since the involved prior information and assumptions on building such as shape, size, and color cannot be generalized over large areas. This paper presents an efficient snake model to overcome such challenge, called Super-Resolution-based Snake Model (SRSM). The SRSM operates on high-resolution LiDAR-based elevation images -- called z-images -- generated by a super-resolution process applied to LiDAR data. The involved balloon force model is also improved to shrink or inflate adaptively, instead of inflating the snake continuously. This method is applicable for a large scale such as city scale and even larger, while having a high level of automation and not requiring any prior knowledge nor training data from the urban scenes (hence unsupervised). It achieves high overall accuracy when tested on various datasets. For instance, the proposed SRSM yields an average area-based Quality of 86.57% and object-based Quality of 81.60% on the ISPRS Vaihingen benchmark datasets. Compared to other methods using this benchmark dataset, this level of accuracy is highly desirable even for a supervised method. Similarly desirable outcomes are obtained when carrying out the proposed SRSM on the whole City of Quebec (total area of 656 km2), yielding an area-based Quality of 62.37% and an object-based Quality of 63.21%.
The Wilson Machine for Image Modeling
Nov 11, 2015


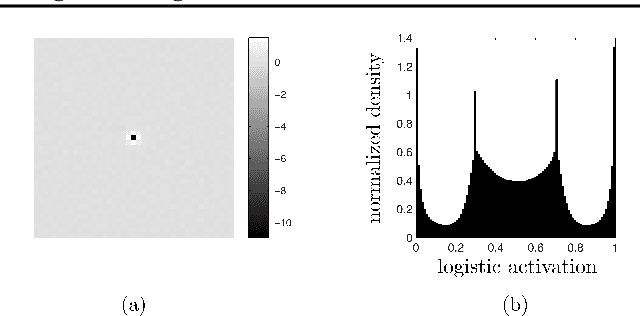
Learning the distribution of natural images is one of the hardest and most important problems in machine learning. The problem remains open, because the enormous complexity of the structures in natural images spans all length scales. We break down the complexity of the problem and show that the hierarchy of structures in natural images fuels a new class of learning algorithms based on the theory of critical phenomena and stochastic processes. We approach this problem from the perspective of the theory of critical phenomena, which was developed in condensed matter physics to address problems with infinite length-scale fluctuations, and build a framework to integrate the criticality of natural images into a learning algorithm. The problem is broken down by mapping images into a hierarchy of binary images, called bitplanes. In this representation, the top bitplane is critical, having fluctuations in structures over a vast range of scales. The bitplanes below go through a gradual stochastic heating process to disorder. We turn this representation into a directed probabilistic graphical model, transforming the learning problem into the unsupervised learning of the distribution of the critical bitplane and the supervised learning of the conditional distributions for the remaining bitplanes. We learnt the conditional distributions by logistic regression in a convolutional architecture. Conditioned on the critical binary image, this simple architecture can generate large, natural-looking images, with many shades of gray, without the use of hidden units, unprecedented in the studies of natural images. The framework presented here is a major step in bringing criticality and stochastic processes to machine learning and in studying natural image statistics.
Concept Learners for Generalizable Few-Shot Learning
Jul 14, 2020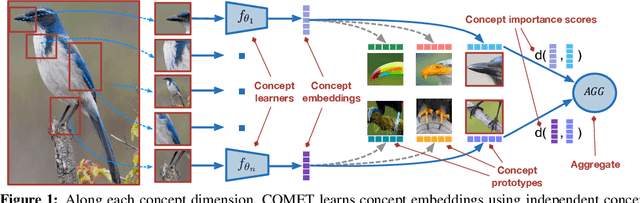
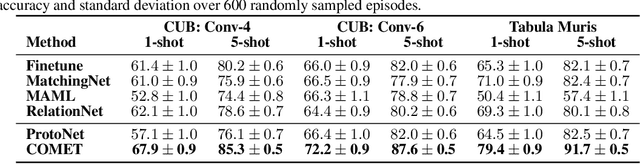

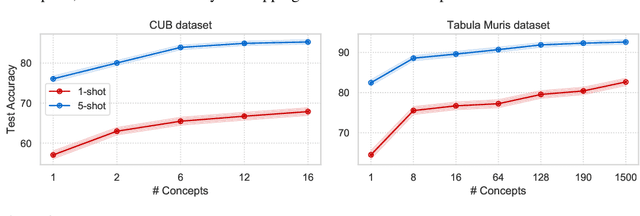
Developing algorithms that are able to generalize to a novel task given only a few labeled examples represents a fundamental challenge in closing the gap between machine- and human-level performance. The core of human cognition lies in the structured, reusable concepts that help us to rapidly adapt to new tasks and provide reasoning behind our decisions. However, existing meta-learning methods learn complex representations across prior labeled tasks without imposing any structure on the learned representations. Here we propose COMET, a meta-learning method that improves generalization ability by learning to learn along human-interpretable concept dimensions. Instead of learning a joint unstructured metric space, COMET learns mappings of high-level concepts into semi-structured metric spaces, and effectively combines the outputs of independent concept learners. We evaluate our model on few-shot tasks from diverse domains, including a benchmark image classification dataset and a novel single-cell dataset from a biological domain developed in our work. COMET significantly outperforms strong meta-learning baselines, achieving $9$-$12\%$ average improvement on the most challenging $1$-shot learning tasks, while unlike existing methods also providing interpretations behind the model's predictions.
Analyzing Worldwide Social Distancing through Large-Scale Computer Vision
Aug 27, 2020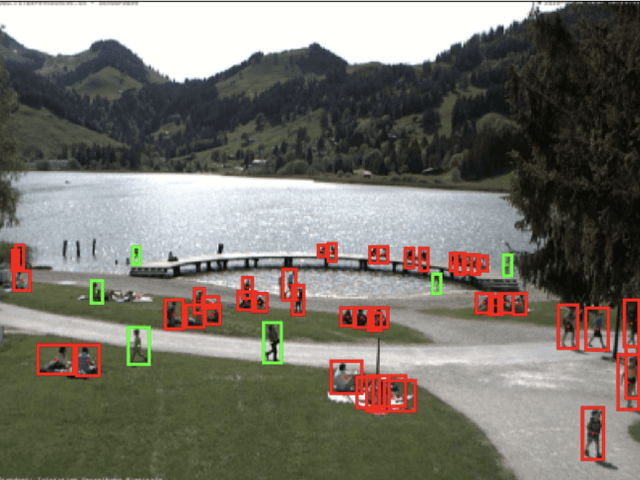
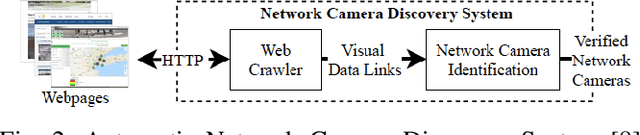
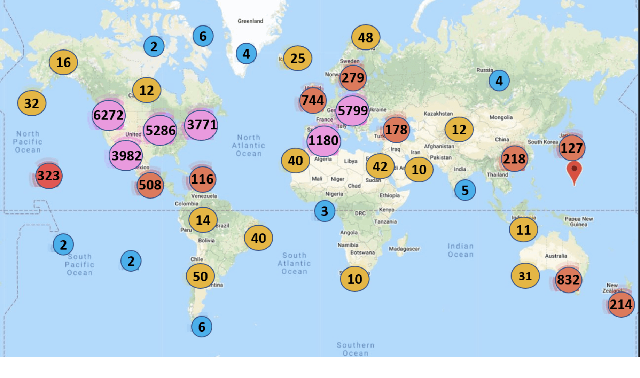
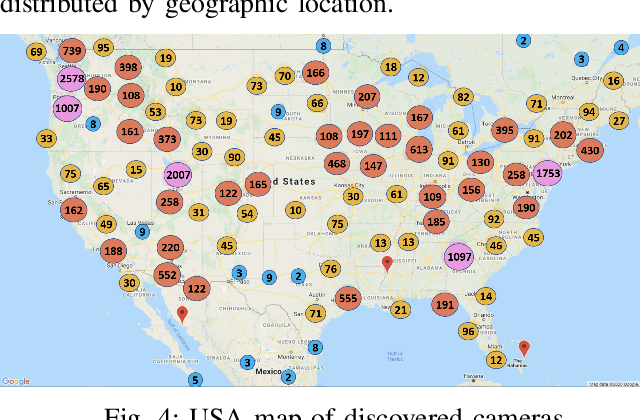
In order to contain the COVID-19 pandemic, countries around the world have introduced social distancing guidelines as public health interventions to reduce the spread of the disease. However, monitoring the efficacy of these guidelines at a large scale (nationwide or worldwide) is difficult. To make matters worse, traditional observational methods such as in-person reporting is dangerous because observers may risk infection. A better solution is to observe activities through network cameras; this approach is scalable and observers can stay in safe locations. This research team has created methods that can discover thousands of network cameras worldwide, retrieve data from the cameras, analyze the data, and report the sizes of crowds as different countries issued and lifted restrictions (also called ''lockdown''). We discover 11,140 network cameras that provide real-time data and we present the results across 15 countries. We collect data from these cameras beginning April 2020 at approximately 0.5TB per week. After analyzing 10,424,459 images from still image cameras and frames extracted periodically from video, the data reveals that the residents in some countries exhibited more activity (judged by numbers of people and vehicles) after the restrictions were lifted. In other countries, the amounts of activities showed no obvious changes during the restrictions and after the restrictions were lifted. The data further reveals whether people stay ''social distancing'', at least 6 feet apart. This study discerns whether social distancing is being followed in several types of locations and geographical locations worldwide and serve as an early indicator whether another wave of infections is likely to occur soon.