 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dense Multi-path U-Net for Ischemic Stroke Lesion Segmentation in Multiple Image Modalities
Oct 16, 2018
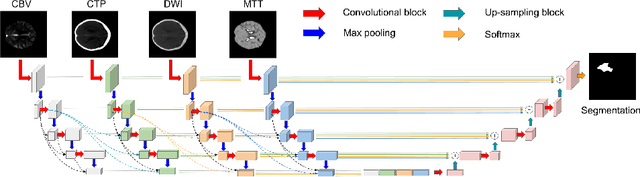
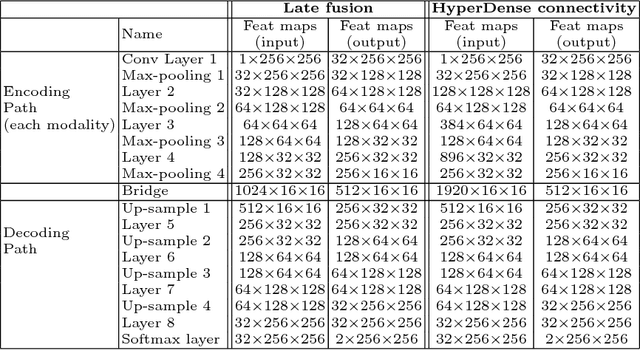
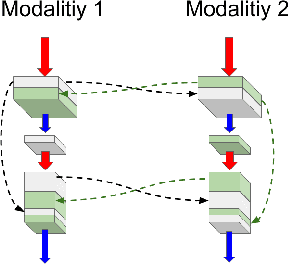
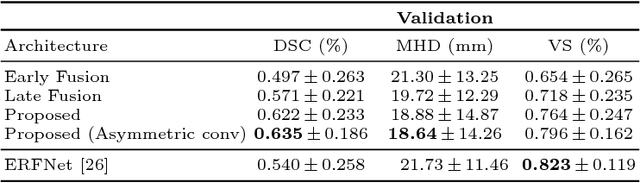
Delineating infarcted tissue in ischemic stroke lesions is crucial to determine the extend of damage and optimal treatment for this life-threatening condition. However, this problem remains challenging due to high variability of ischemic strokes' location and shape. Recently, fully-convolutional neural networks (CNN), in particular those based on U-Net, have led to improved performances for this task. In this work, we propose a novel architecture that improves standard U-Net based methods in three important ways. First, instead of combining the available image modalities at the input, each of them is processed in a different path to better exploit their unique information. Moreover, the network is densely-connected (i.e., each layer is connected to all following layers), both within each path and across different paths, similar to HyperDenseNet. This gives our model the freedom to learn the scale at which modalities should be processed and combined. Finally, inspired by the Inception architecture, we improve standard U-Net modules by extending inception modules with two convolutional blocks with dilated convolutions of different scale. This helps handling the variability in lesion sizes. We split the 93 stroke datasets into training and validation sets containing 83 and 9 examples respectively. Our network was trained on a NVidia TITAN XP GPU with 16 GBs RAM, using ADAM as optimizer and a learning rate of 1$\times$10$^{-5}$ during 200 epochs. Training took around 5 hours and segmentation of a whole volume took between 0.2 and 2 seconds, as average. The performance on the test set obtained by our method is compared to several baselines, to demonstrate the effectiveness of our architecture, and to a state-of-art architecture that employs factorized dilated convolutions, i.e., ERFNet.
Auxiliary Learning by Implicit Differentiation
Jun 22, 2020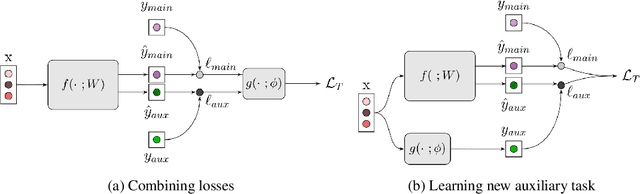
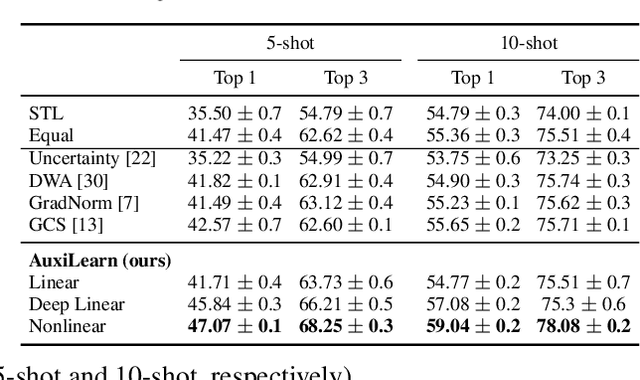

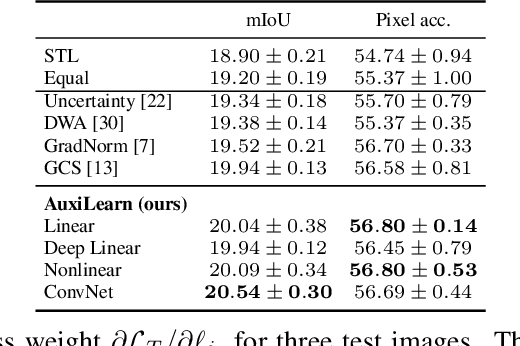
Training with multiple auxiliary tasks is a common practice used in deep learning for improving the performance on the main task of interest. Two main challenges arise in this multi-task learning setting: (i) Designing useful auxiliary tasks; and (ii) Combining auxiliary tasks into a single coherent loss. We propose a novel framework, \textit{AuxiLearn}, that targets both challenges, based on implicit differentiation. First, when useful auxiliaries are known, we propose learning a network that combines all losses into a single coherent objective function. This network can learn \textit{non-linear} interactions between auxiliary tasks. Second, when no useful auxiliary task is known, we describe how to learn a network that generates a meaningful, novel auxiliary task. We evaluate AuxiLearn in a series of tasks and domains, including image segmentation and learning with attributes. We find that AuxiLearn consistently improves accuracy compared with competing methods.
Fast acoustic scattering using convolutional neural networks
Nov 06, 2019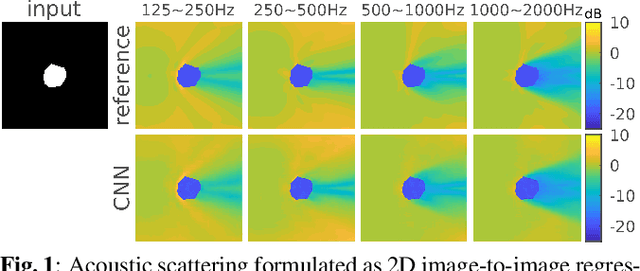
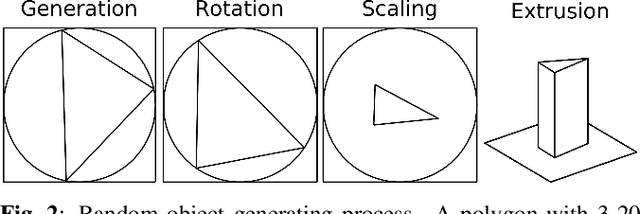
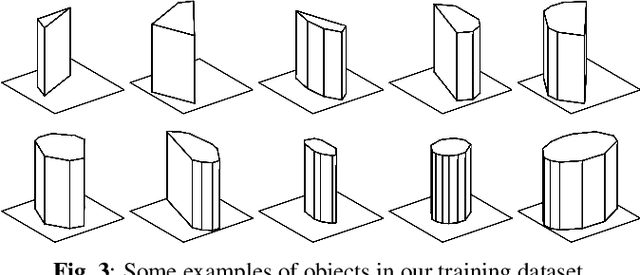
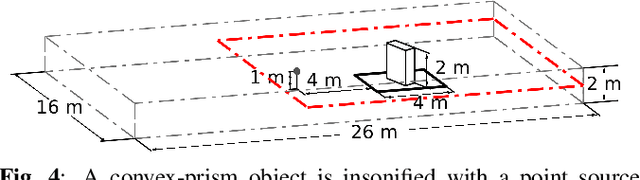
Diffracted scattering and occlusion are important acoustic effects in interactive auralization and noise control applications, typically requiring expensive numerical simulation. We propose training a convolutional neural network to map from a convex scatterer's cross-section to a 2D slice of the resulting spatial loudness distribution. We show that employing a full-resolution residual network for the resulting image-to-image regression problem yields spatially detailed loudness fields with a root-mean-squared error of less than 1 dB, at over 100* speedup compared to full wave simulation.
Incomplete Descriptor Mining with Elastic Loss for Person Re-Identification
Aug 10, 2020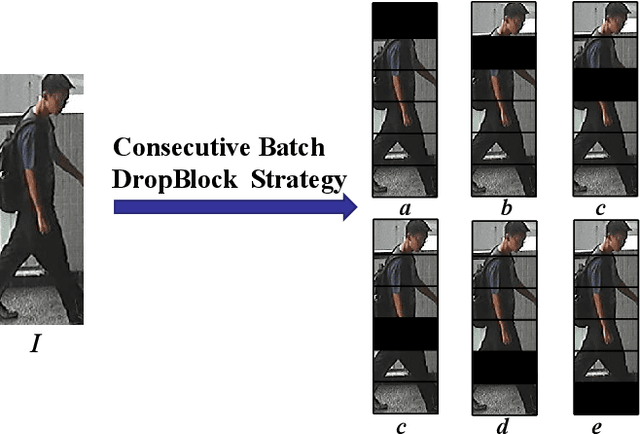
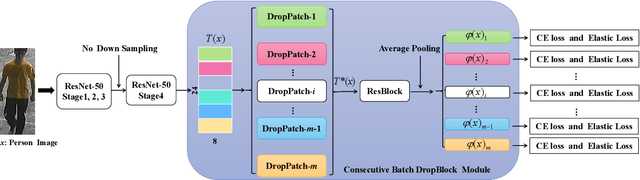
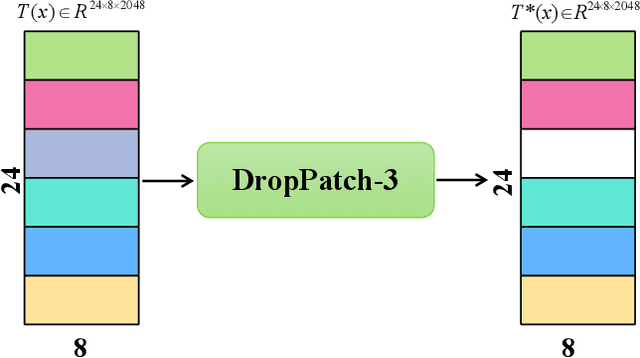
In this paper, we propose a novel person Re-ID model, Consecutive Batch DropBlock Network (CBDB-Net), to help the person Re-ID model to capture the attentive and robust person descriptor. The CBDB-Net contains two novel modules: the Consecutive Batch DropBlock Module (CBDBM) and the Elastic Loss. In the Consecutive Batch DropBlock Module (CBDBM), it firstly conducts uniform partition on the feature maps. And then, the CBDBM independently and continuously drops each patch from top to bottom on the feature maps, which outputs multiple incomplete features to push the model to capture the robust person descriptor. In the Elastic Loss, we design a novel weight control item to help the deep model adaptively balance hard sample pairs and easy sample pairs in the whole training process. Through an extensive set of ablation studies, we verify that the Consecutive Batch DropBlock Module (CBDBM) and the Elastic Loss each contribute to the performance boosts of CBDB-Net. We demonstrate that our CBDB-Net can achieve the competitive performance on the three generic person Re-ID datasets (the Market-1501, the DukeMTMC-Re-ID, and the CUHK03 dataset), three occlusion Person Re-ID datasets (the Occluded DukeMTMC, the Partial-REID, and the Partial iLIDS dataset), and the other image retrieval dataset (In-Shop Clothes Retrieval dataset).
Meta-LR-Schedule-Net: Learned LR Schedules that Scale and Generalize
Jul 29, 2020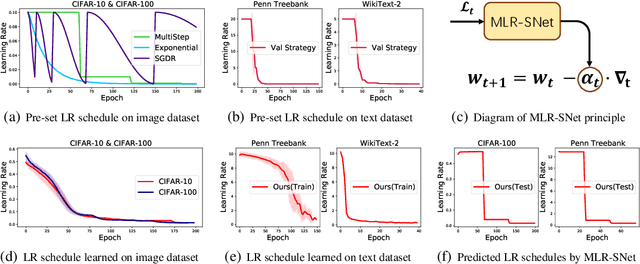

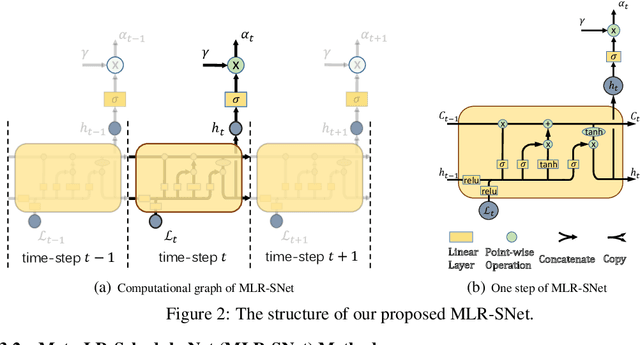
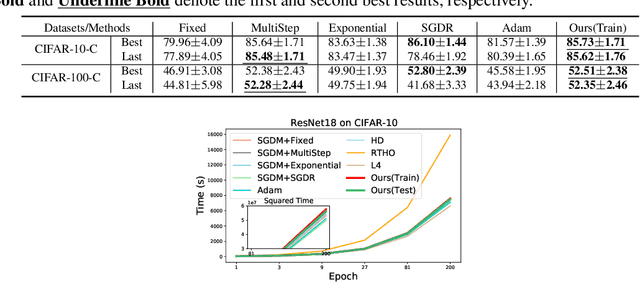
The learning rate (LR) is one of the most important hyper-parameters in stochastic gradient descent (SGD) for deep neural networks (DNNs) training and generalization. However, current hand-designed LR schedules need to manually pre-specify schedule as well as its extra hyper-parameters, which limits its ability to adapt non-convex optimization problems due to the significant variation of training dynamic. To address this issue, we propose a model capable of adaptively learning LR schedule from data. We specifically design a meta-learner with explicit mapping formulation to parameterize LR schedules, which can adjust LR adaptively to comply with current training dynamic by leveraging the information from past training histories. Image and text classification benchmark experiments substantiate the capability of our method for achieving proper LR schedules compared with baseline methods. Moreover, we transfer the learned LR schedule to other various tasks, like different training batch sizes, epochs, datasets, network architectures, especially large scale ImageNet dataset, showing its stronger generalization capability than related methods. Finally, guided by a small set of clean validation set, we show our method can achieve better generalization error when training data is biased with corrupted noise than baseline methods.
Multivariate mathematical morphology for DCE-MRI image analysis in angiogenesis studies
Oct 28, 2019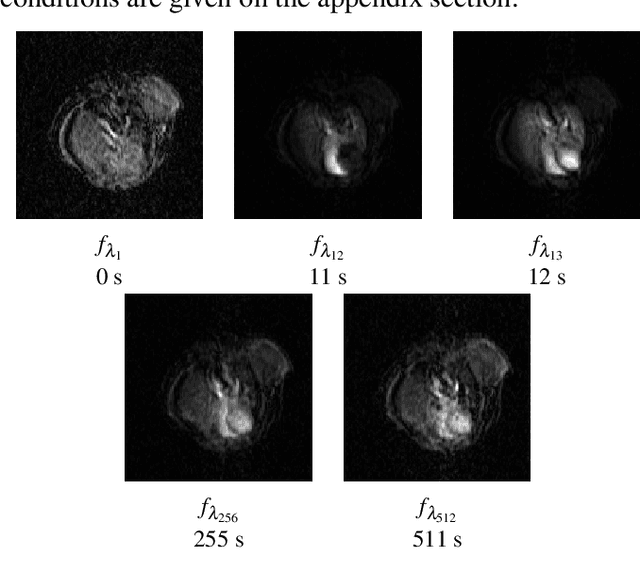
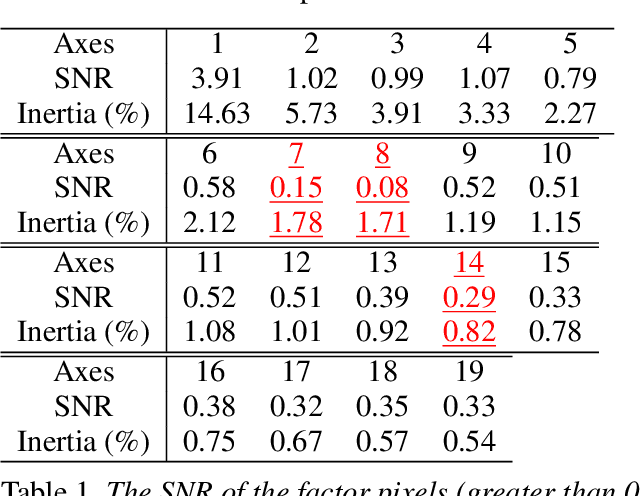
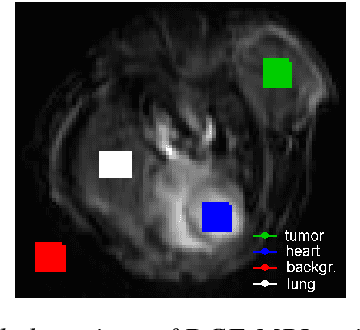
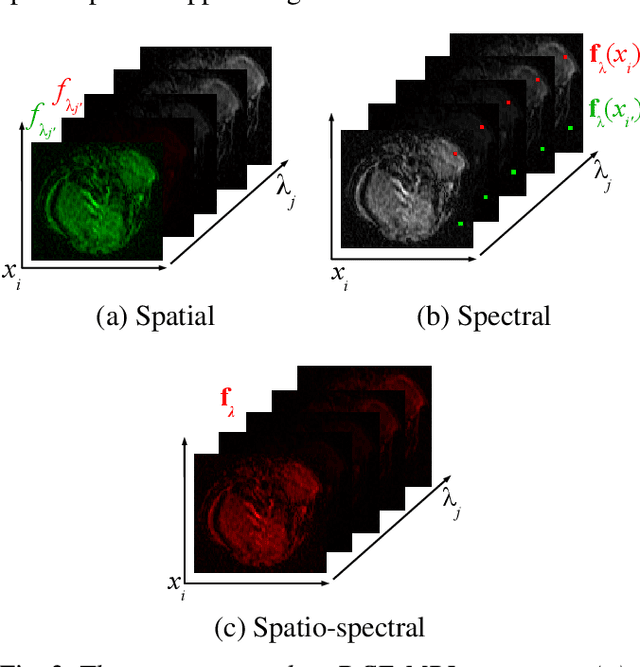
We propose a new computer aided detection framework for tumours acquired on DCE-MRI (Dynamic Contrast Enhanced Magnetic Resonance Imaging) series on small animals. In this approach we consider DCE-MRI series as multivariate images. A full multivariate segmentation method based on dimensionality reduction, noise filtering, supervised classification and stochastic watershed is explained and tested on several data sets. The two main key-points introduced in this paper are noise reduction preserving contours and spatio temporal segmentation by stochastic watershed. Noise reduction is performed in a special way that selects factorial axes of Factor Correspondence Analysis in order to preserves contours. Then a spatio-temporal approach based on stochastic watershed is used to segment tumours. The results obtained are in accordance with the diagnosis of the medical doctors.
Utilizing Satellite Imagery Datasets and Machine Learning Data Models to Evaluate Infrastructure Change in Undeveloped Regions
Sep 01, 2020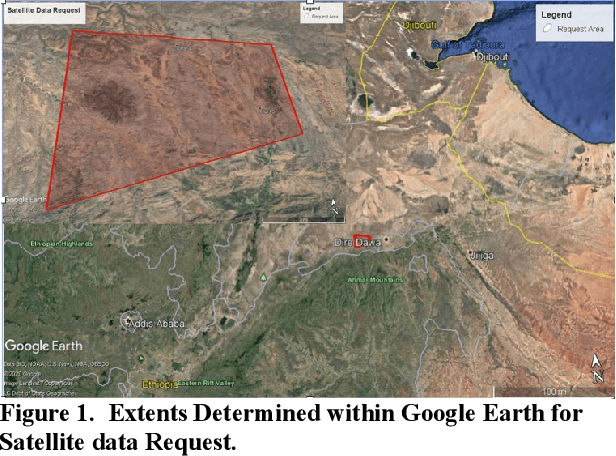

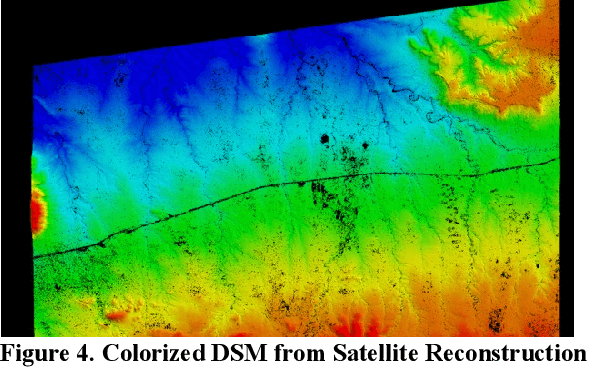
In the globalized economic world, it has become important to understand the purpose behind infrastructural and construction initiatives occurring within developing regions of the earth. This is critical when the financing for such projects must be coming from external sources, as is occurring throughout major portions of the African continent. When it comes to imagery analysis to research these regions, ground and aerial coverage is either non-existent or not commonly acquired. However, imagery from a large number of commercial, private, and government satellites have produced enormous datasets with global coverage, compiling geospatial resources that can be mined and processed using machine learning algorithms and neural networks. The downside is that a majority of these geospatial data resources are in a state of technical stasis, as it is difficult to quickly parse and determine a plan for request and processing when acquiring satellite image data. A goal of this research is to allow automated monitoring for largescale infrastructure projects, such as railways, to determine reliable metrics that define and predict the direction construction initiatives could take, allowing for a directed monitoring via narrowed and targeted satellite imagery requests. By utilizing photogrammetric techniques on available satellite data to create 3D Meshes and Digital Surface Models (DSM) we hope to effectively predict transport routes. In understanding the potential directions that largescale transport infrastructure will take through predictive modeling, it becomes much easier to track, understand, and monitor progress, especially in areas with limited imagery coverage.
A Method of Fluorescent Fibers Detection on Identity Documents under Ultraviolet Light
Dec 04, 2019


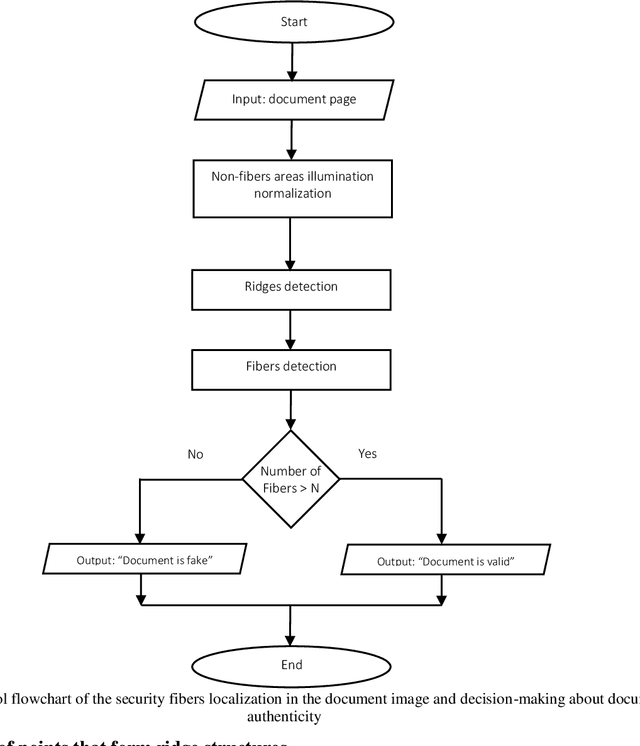
In this work we consider the problem of the fluorescent security fibers detection on the images of identity documents captured under ultraviolet light. As an example we use images of the second and third pages of the Russian passport and show features that render known methods and approaches based on image binarization non applicable. We propose a solution based on ridge detection in the gray-scale image of the document with preliminary normalized background. The algorithm was tested on a private dataset consisting of both authentic and model passports. Abandonment of binarization allowed to provide reliable and stable functioning of the proposed detector on a target dataset.
Projected-point-based Segmentation: A New Paradigm for LiDAR Point Cloud Segmentation
Aug 10, 2020
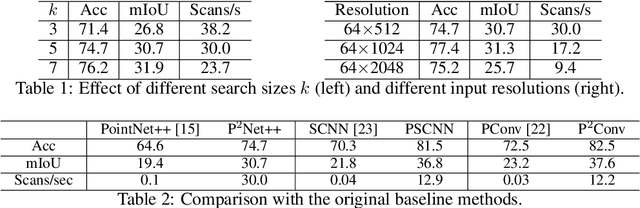
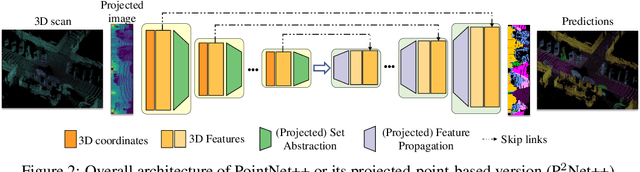

Most point-based semantic segmentation methods are designed for indoor scenarios, but many applications such as autonomous driving vehicles require accurate segmentation for outdoor scenarios. For this goal, light detection and ranging (LiDAR) sensors are often used to collect outdoor environmental data. The problem is that directly applying previous point-based segmentation methods to LiDAR point clouds usually leads to unsatisfactory results due to the domain gap between indoor and outdoor scenarios. To address such a domain gap, we propose a new paradigm, namely projected-point-based methods, to transform point-based methods to a suitable form for LiDAR point cloud segmentation by utilizing the characteristics of LiDAR point clouds. Specifically, we utilize the inherent ordered information of LiDAR points for point sampling and grouping, thus reducing unnecessary computation. All computations are carried out on the projected image, and there are only pointwise convolutions and matrix multiplication in projected-point-based methods. We compare projected-point-based methods with point-based methods on the challenging SemanticKITTI dataset, and experimental results demonstrate that projected-point-based methods achieve better accuracy than all baselines more efficiently. Even with a simple baseline architecture, projected-point-based methods perform favorably against previous state-of-the-art methods. The code will be released upon paper acceptance.
Geometry-Aware Instance Segmentation with Disparity Maps
Jun 14, 2020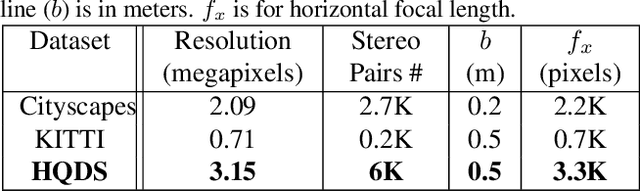
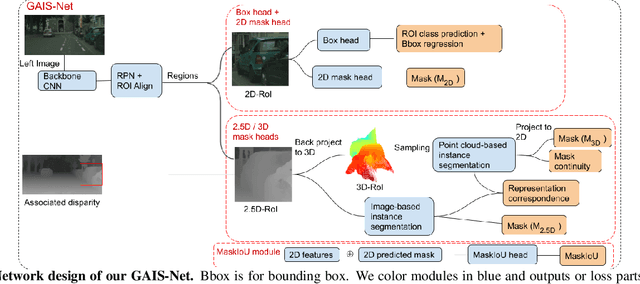
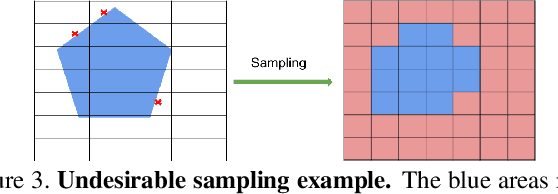
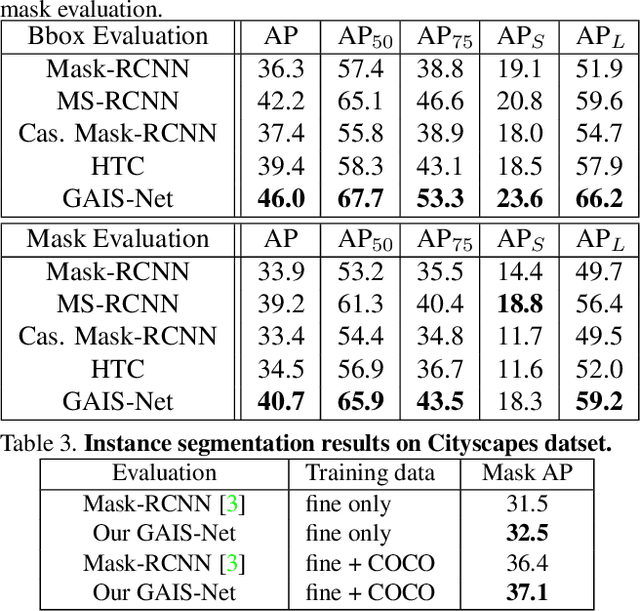
Most previous works of outdoor instance segmentation for images only use color information. We explore a novel direction of sensor fusion to exploit stereo cameras. Geometric information from disparities helps separate overlapping objects of the same or different classes. Moreover, geometric information penalizes region proposals with unlikely 3D shapes thus suppressing false positive detections. Mask regression is based on 2D, 2.5D, and 3D ROI using the pseudo-lidar and image-based representations. These mask predictions are fused by a mask scoring process. However, public datasets only adopt stereo systems with shorter baseline and focal legnth, which limit measuring ranges of stereo cameras. We collect and utilize High-Quality Driving Stereo (HQDS) dataset, using much longer baseline and focal length with higher resolution. Our performance attains state of the art. Please refer to our project page. The full paper is available here.