 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint Training of Variational Auto-Encoder and Latent Energy-Based Model
Jun 10, 2020


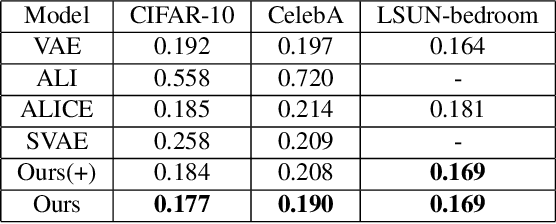

This paper proposes a joint training method to learn both the variational auto-encoder (VAE) and the latent energy-based model (EBM). The joint training of VAE and latent EBM are based on an objective function that consists of three Kullback-Leibler divergences between three joint distributions on the latent vector and the image, and the objective function is of an elegant symmetric and anti-symmetric form of divergence triangle that seamlessly integrates variational and adversarial learning. In this joint training scheme, the latent EBM serves as a critic of the generator model, while the generator model and the inference model in VAE serve as the approximate synthesis sampler and inference sampler of the latent EBM. Our experiments show that the joint training greatly improves the synthesis quality of the VAE. It also enables learning of an energy function that is capable of detecting out of sample examples for anomaly detection.
T-GD: Transferable GAN-generated Images Detection Framework
Aug 10, 2020
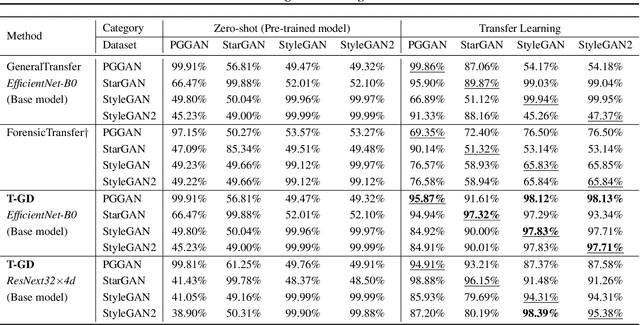
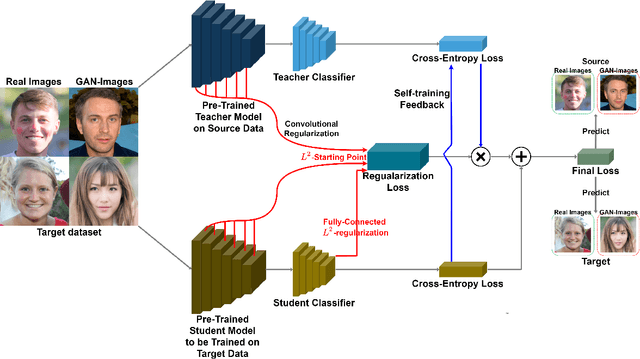
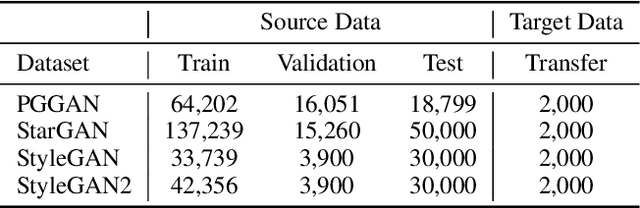
Recent advancements in Generative Adversarial Networks (GANs) enable the generation of highly realistic images, raising concerns about their misuse for malicious purposes. Detecting these GAN-generated images (GAN-images) becomes increasingly challenging due to the significant reduction of underlying artifacts and specific patterns. The absence of such traces can hinder detection algorithms from identifying GAN-images and transferring knowledge to identify other types of GAN-images as well. In this work, we present the Transferable GAN-images Detection framework T-GD, a robust transferable framework for an effective detection of GAN-images. T-GD is composed of a teacher and a student model that can iteratively teach and evaluate each other to improve the detection performance. First, we train the teacher model on the source dataset and use it as a starting point for learning the target dataset. To train the student model, we inject noise by mixing up the source and target datasets, while constraining the weight variation to preserve the starting point. Our approach is a self-training method, but distinguishes itself from prior approaches by focusing on improving the transferability of GAN-image detection. T-GD achieves high performance on the source dataset by overcoming catastrophic forgetting and effectively detecting state-of-the-art GAN-images with only a small volume of data without any metadata information.
Improving Emergency Response during Hurricane Season using Computer Vision
Sep 08, 2020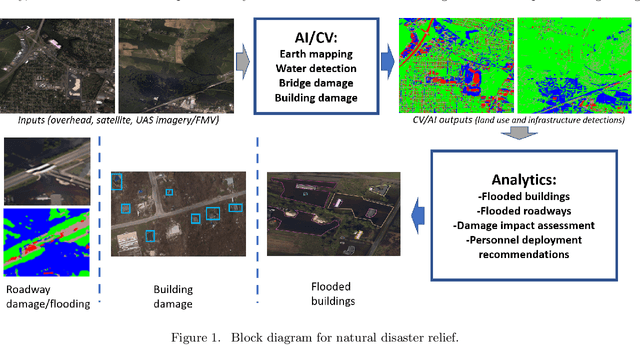
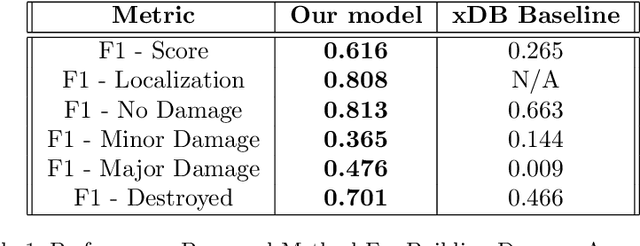
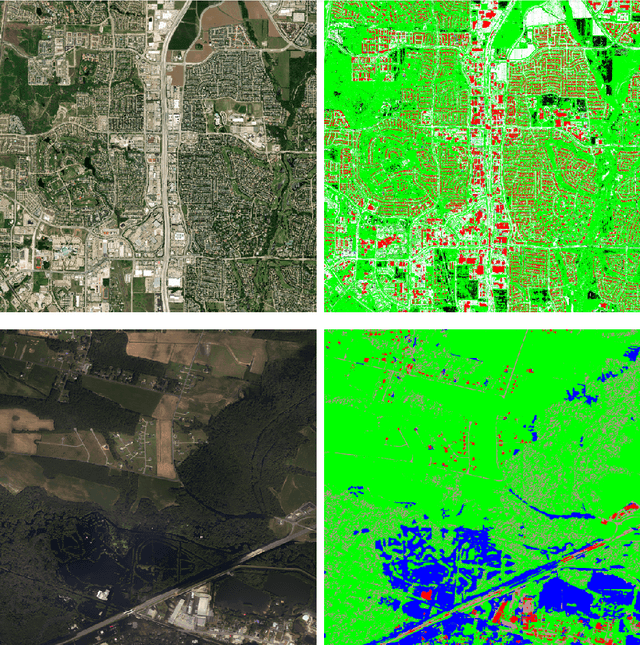

We have developed a framework for crisis response and management that incorporates the latest technologies in computer vision (CV), inland flood prediction, damage assessment and data visualization. The framework uses data collected before, during, and after the crisis to enable rapid and informed decision making during all phases of disaster response. Our computer-vision model analyzes spaceborne and airborne imagery to detect relevant features during and after a natural disaster and creates metadata that is transformed into actionable information through web-accessible mapping tools. In particular, we have designed an ensemble of models to identify features including water, roads, buildings, and vegetation from the imagery. We have investigated techniques to bootstrap and reduce dependency on large data annotation efforts by adding use of open source labels including OpenStreetMaps and adding complementary data sources including Height Above Nearest Drainage (HAND) as a side channel to the network's input to encourage it to learn other features orthogonal to visual characteristics. Modeling efforts include modification of connected U-Nets for (1) semantic segmentation, (2) flood line detection, and (3) for damage assessment. In particular for the case of damage assessment, we added a second encoder to U-Net so that it could learn pre-event and post-event image features simultaneously. Through this method, the network is able to learn the difference between the pre- and post-disaster images, and therefore more effectively classify the level of damage. We have validated our approaches using publicly available data from the National Oceanic and Atmospheric Administration (NOAA)'s Remote Sensing Division, which displays the city and street-level details as mosaic tile images as well as data released as part of the Xview2 challenge.
Shop The Look: Building a Large Scale Visual Shopping System at Pinterest
Jun 18, 2020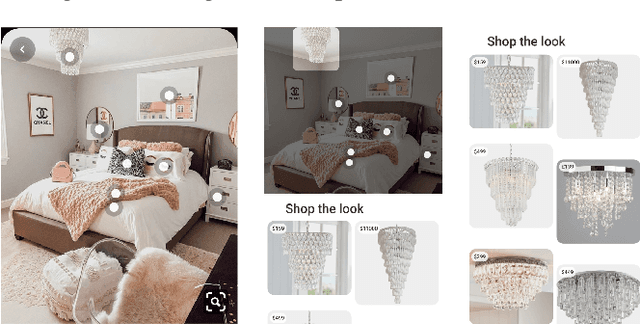

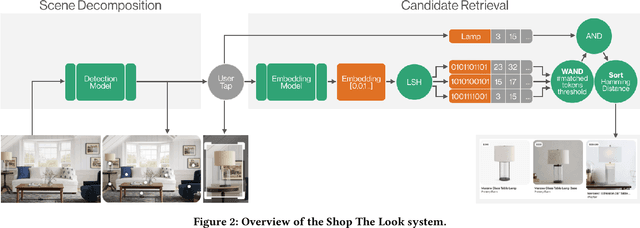
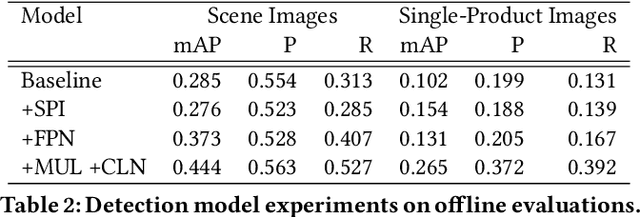
As online content becomes ever more visual, the demand for searching by visual queries grows correspondingly stronger. Shop The Look is an online shopping discovery service at Pinterest, leveraging visual search to enable users to find and buy products within an image. In this work, we provide a holistic view of how we built Shop The Look, a shopping oriented visual search system, along with lessons learned from addressing shopping needs. We discuss topics including core technology across object detection and visual embeddings, serving infrastructure for realtime inference, and data labeling methodology for training/evaluation data collection and human evaluation. The user-facing impacts of our system design choices are measured through offline evaluations, human relevance judgements, and online A/B experiments. The collective improvements amount to cumulative relative gains of over 160% in end-to-end human relevance judgements and over 80% in engagement. Shop The Look is deployed in production at Pinterest.
Networks with pixels embedding: a method to improve noise resistance in images classification
May 24, 2020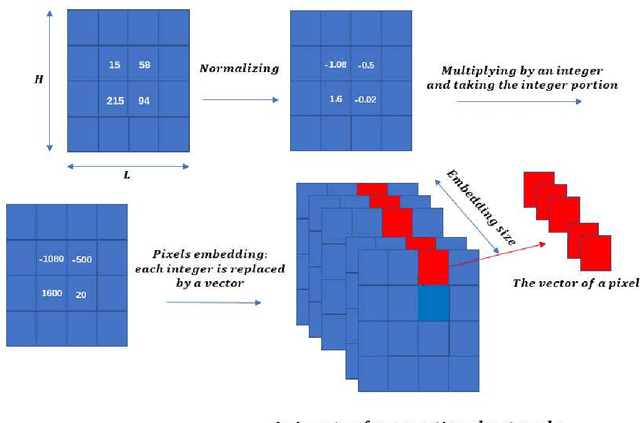
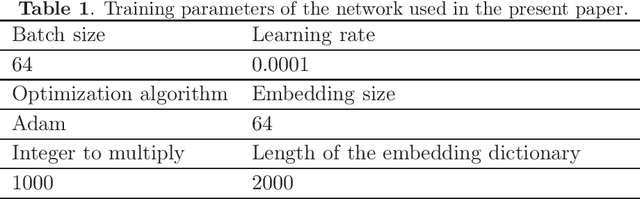
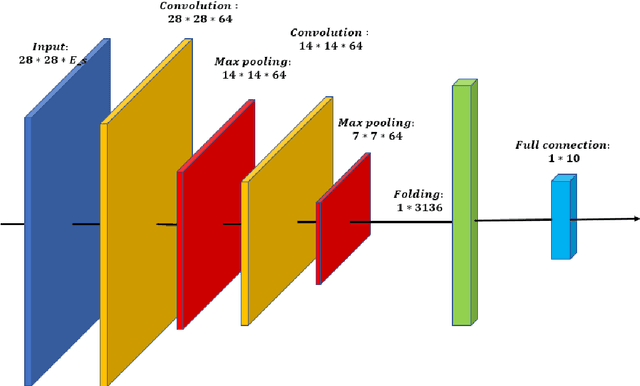
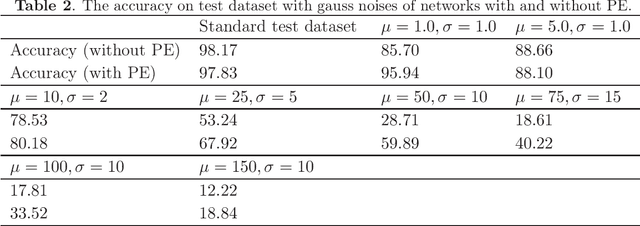
In the task of images classification, usually, the network is sensitive to noises. For example, an image of cat with noises might be misclassified as an ostrich. Conventionally, to overcome the problem of noises, one uses the technique of data enhancement, that is, to teach the network to distinguish noises by adding more images with noises in the training dataset. In this work, we provide a noise-resistance network in images classification by introducing a technique of pixels embedding. We test the network with pixels embedding, which is abbreviated as the network with PE, on the mnist database of handwritten digits. It shows that the network with PE outperforms the conventional network on images with noises. The technique of pixels embedding can be used in many tasks of images classification to improve noise resistance.
Attributed Relational SIFT-based Regions Graph (ARSRG): concepts and applications
Dec 20, 2019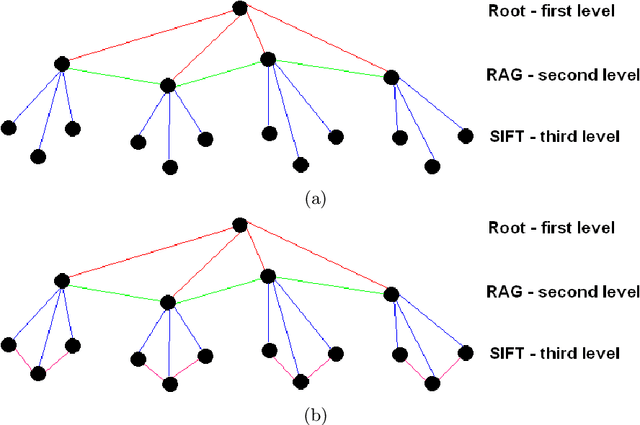
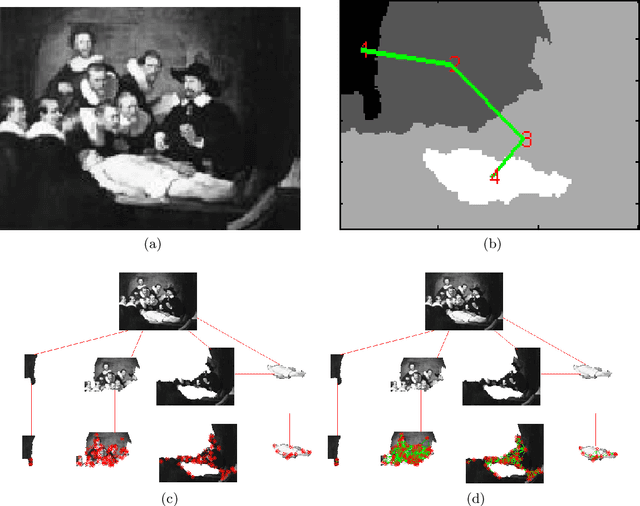


Graphs are widely adopted tools for encoding information. Generally, they are applied to disparate research fields where data needs to be represented in terms of local and spatial connections. In this context, a structure for ditigal image representation, called Attributed Relational SIFT-based Regions Graph (ARSRG), previously introduced, is presented. ARSRG has not been explored in detail in previous works and for this reason the goal is to investigate unknown aspects. The study is divided into two parts. A first, theoretical, introducing formal definitions, not yet specified previously, with purpose to clarify its structural configuration. A second, experimental, which provides fundamental elements about its adaptability and flexibility regarding different applications. The theoretical vision combined with the experimental one shows how the structure is adaptable to image representation including contents of different nature.
Correcting Data Imbalance for Semi-Supervised Covid-19 Detection Using X-ray Chest Images
Aug 20, 2020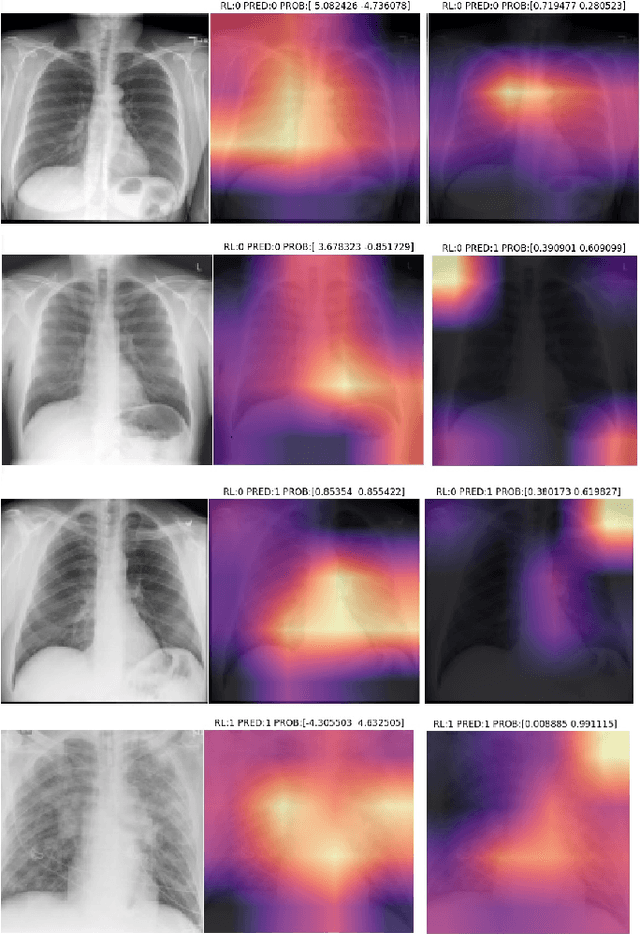
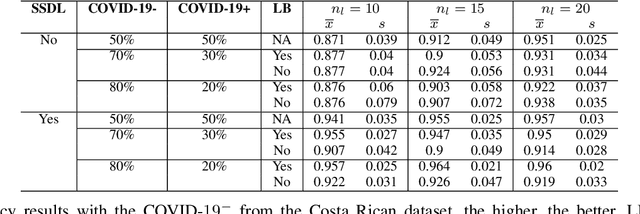
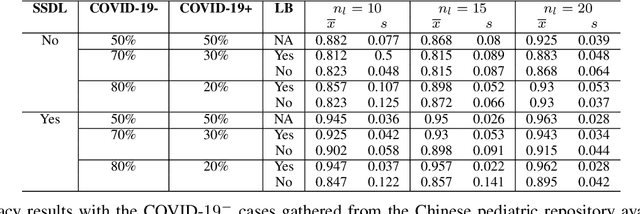
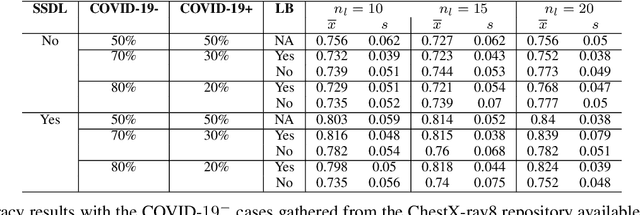
The Corona Virus (COVID-19) is an internationalpandemic that has quickly propagated throughout the world. The application of deep learning for image classification of chest X-ray images of Covid-19 patients, could become a novel pre-diagnostic detection methodology. However, deep learning architectures require large labelled datasets. This is often a limitation when the subject of research is relatively new as in the case of the virus outbreak, where dealing with small labelled datasets is a challenge. Moreover, in the context of a new highly infectious disease, the datasets are also highly imbalanced,with few observations from positive cases of the new disease. In this work we evaluate the performance of the semi-supervised deep learning architecture known as MixMatch using a very limited number of labelled observations and highly imbalanced labelled dataset. We propose a simple approach for correcting data imbalance, re-weight each observationin the loss function, giving a higher weight to the observationscorresponding to the under-represented class. For unlabelled observations, we propose the usage of the pseudo and augmentedlabels calculated by MixMatch to choose the appropriate weight. The MixMatch method combined with the proposed pseudo-label based balance correction improved classification accuracy by up to 10%, with respect to the non balanced MixMatch algorithm, with statistical significance. We tested our proposed approach with several available datasets using 10, 15 and 20 labelledobservations. Additionally, a new dataset is included among thetested datasets, composed of chest X-ray images of Costa Rican adult patients
Cross-Identity Motion Transfer for Arbitrary Objects through Pose-Attentive Video Reassembling
Jul 17, 2020
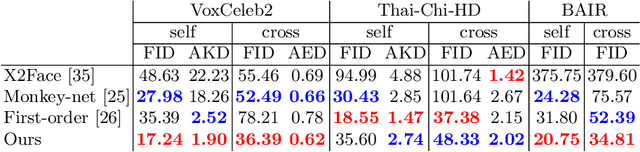
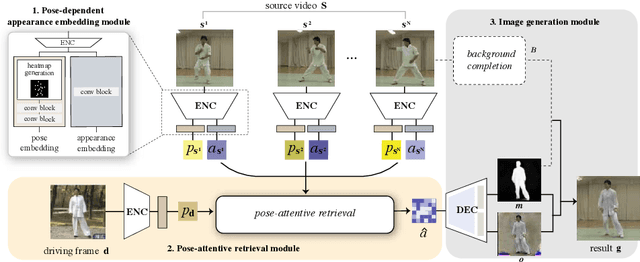
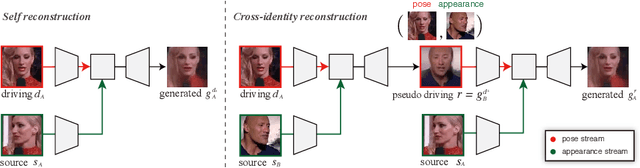
We propose an attention-based networks for transferring motions between arbitrary objects. Given a source image(s) and a driving video, our networks animate the subject in the source images according to the motion in the driving video. In our attention mechanism, dense similarities between the learned keypoints in the source and the driving images are computed in order to retrieve the appearance information from the source images. Taking a different approach from the well-studied warping based models, our attention-based model has several advantages. By reassembling non-locally searched pieces from the source contents, our approach can produce more realistic outputs. Furthermore, our system can make use of multiple observations of the source appearance (e.g. front and sides of faces) to make the results more accurate. To reduce the training-testing discrepancy of the self-supervised learning, a novel cross-identity training scheme is additionally introduced. With the training scheme, our networks is trained to transfer motions between different subjects, as in the real testing scenario. Experimental results validate that our method produces visually pleasing results in various object domains, showing better performances compared to previous works.
Roof material classification from aerial imagery
Apr 23, 2020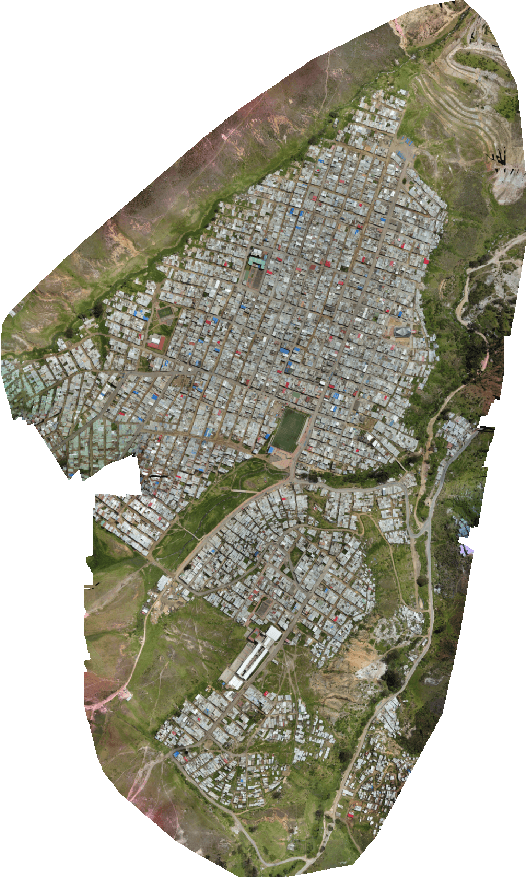
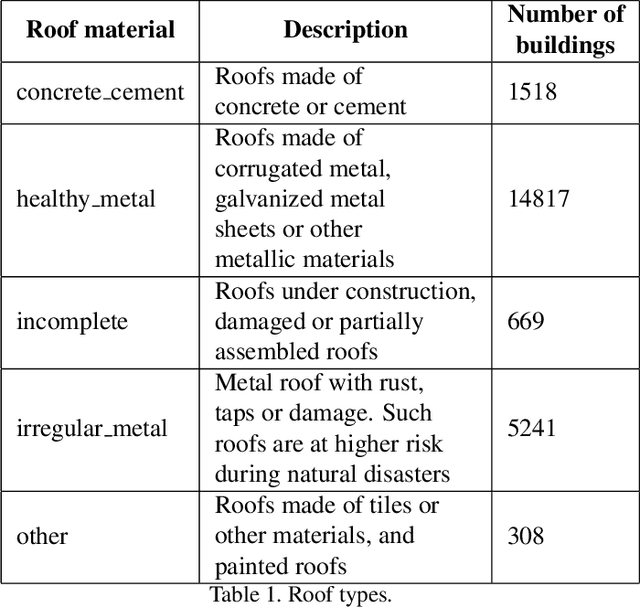
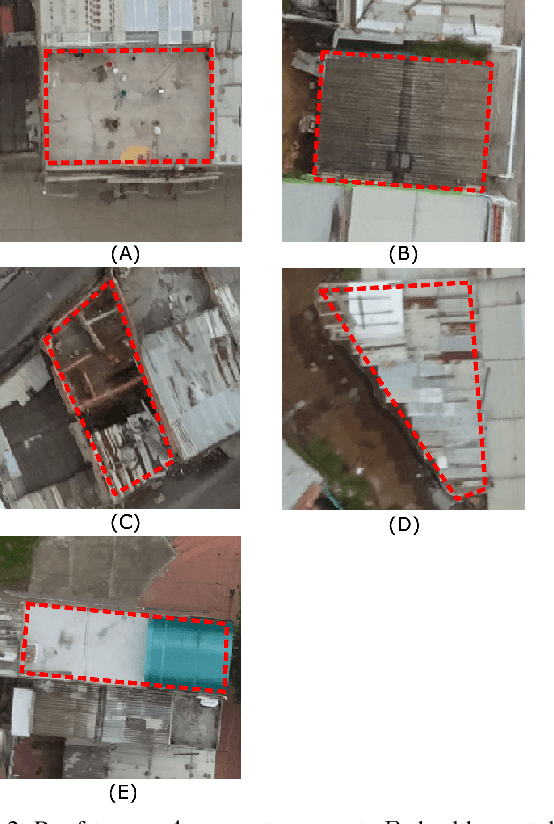
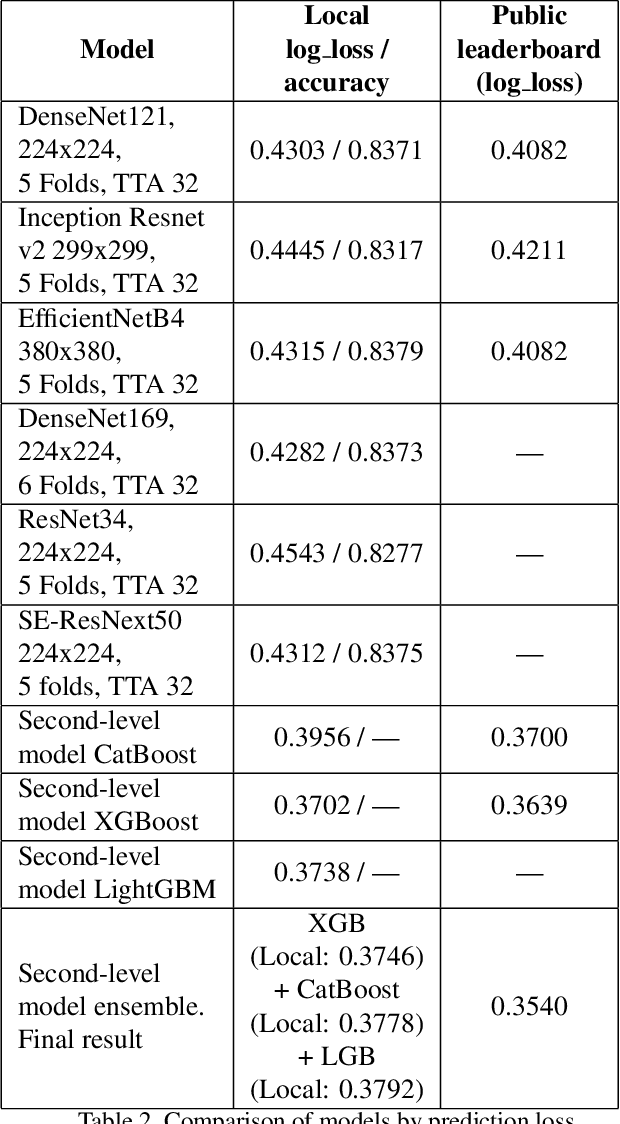
This paper describes an algorithm for classification of roof materials using aerial photographs. Main advantages of the algorithm are proposed methods to improve prediction accuracy. Proposed methods includes: method of converting ImageNet weights of neural networks for using multi-channel images; special set of features of second level models that are used in addition to specific predictions of neural networks; special set of image augmentations that improve training accuracy. In addition, complete flow for solving this problem is proposed. The following content is available in open access: solution code, weight sets and architecture of the used neural networks. The proposed solution achieved second place in the competition "Open AI Caribbean Challenge".
Interpolation between Residual and Non-Residual Networks
Jun 10, 2020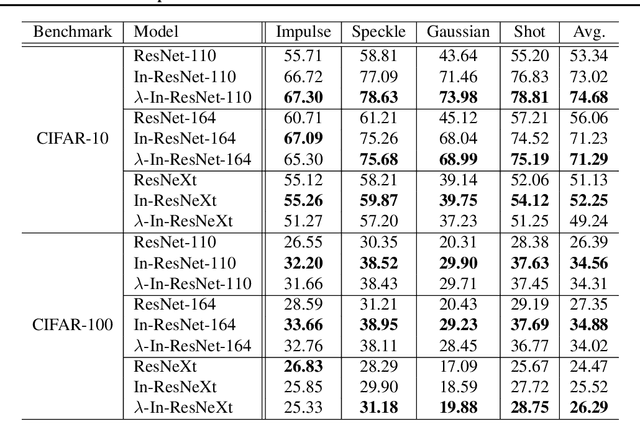
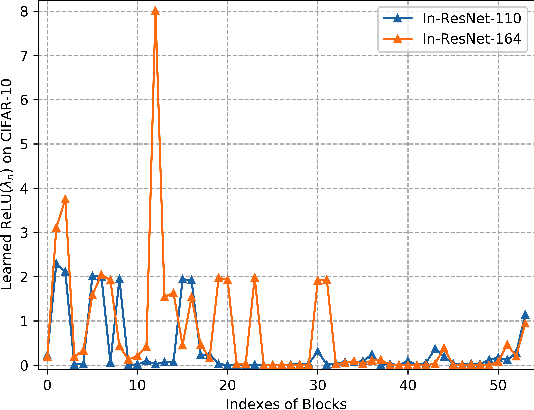
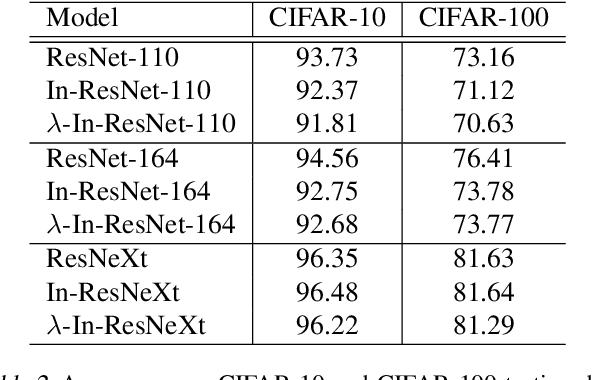
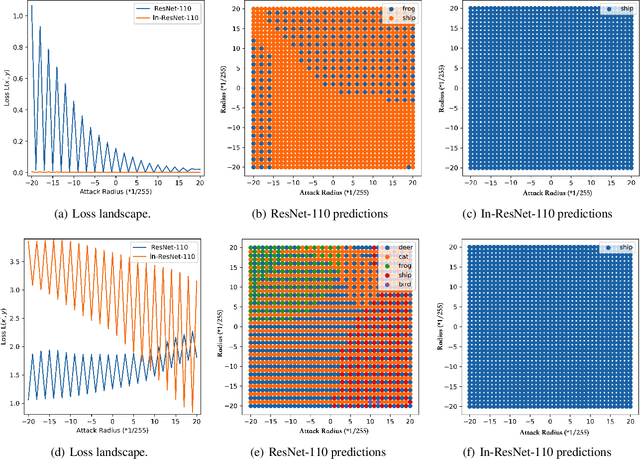
Although ordinary differential equations (ODEs) provide insights for designing network architectures, its relationship with the non-residual convolutional neural networks (CNNs) is still unclear. In this paper, we present a novel ODE model by adding a damping term. It can be shown that the proposed model can recover both a ResNet and a CNN by adjusting an interpolation coefficient. Therefore, the damped ODE model provides a unified framework for the interpretation of residual and non-residual networks. The Lyapunov analysis reveals better stability of the proposed model, and thus yields robustness improvement of the learned networks. Experiments on a number of image classification benchmarks show that the proposed model substantially improves the accuracy of ResNet and ResNeXt over the perturbed inputs from both stochastic noise and adversarial attack methods. Moreover, the loss landscape analysis demonstrates the improved robustness of our method along the attack direction.