 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sequence Modeling with Unconstrained Generation Order
Nov 01, 2019



The dominant approach to sequence generation is to produce a sequence in some predefined order, e.g. left to right. In contrast, we propose a more general model that can generate the output sequence by inserting tokens in any arbitrary order. Our model learns decoding order as a result of its training procedure. Our experiments show that this model is superior to fixed order models on a number of sequence generation tasks, such as Machine Translation, Image-to-LaTeX and Image Captioning.
Distributed Reinforcement Learning of Targeted Grasping with Active Vision for Mobile Manipulators
Jul 16, 2020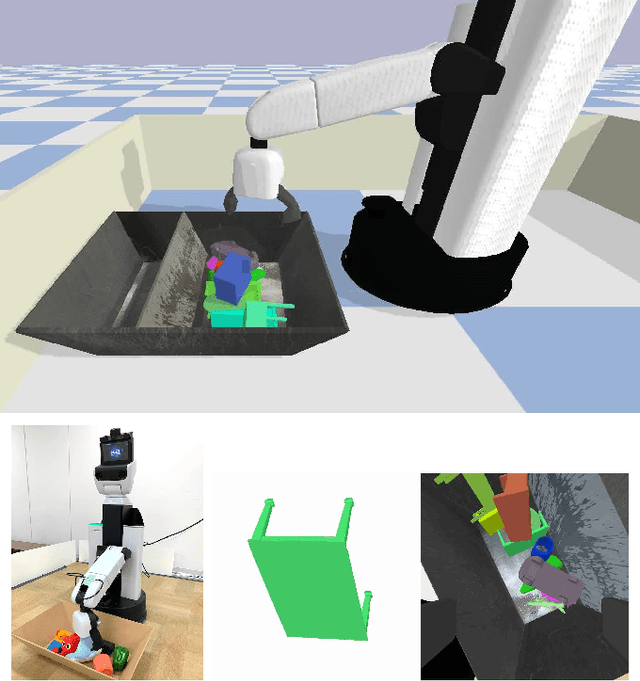
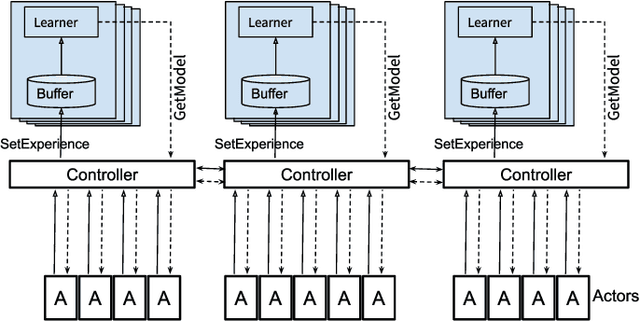
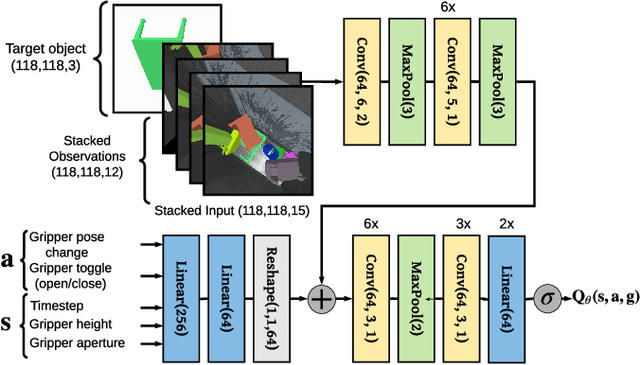
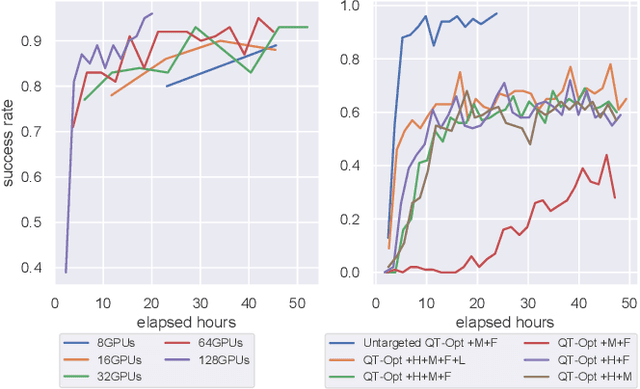
Developing personal robots that can perform a diverse range of manipulation tasks in unstructured environments necessitates solving several challenges for robotic grasping systems. We take a step towards this broader goal by presenting the first RL-based system, to our knowledge, for a mobile manipulator that can (a) achieve targeted grasping generalizing to unseen target objects, (b) learn complex grasping strategies for cluttered scenes with occluded objects, and (c) perform active vision through its movable wrist camera to better locate objects. The system is informed of the desired target object in the form of a single, arbitrary-pose RGB image of that object, enabling the system to generalize to unseen objects without retraining. To achieve such a system, we combine several advances in deep reinforcement learning and present a large-scale distributed training system using synchronous SGD that seamlessly scales to multi-node, multi-GPU infrastructure to make rapid prototyping easier. We train and evaluate our system in a simulated environment, identify key components for improving performance, analyze its behaviors, and transfer to a real-world setup.
Illumination-invariant image mosaic calculation based on logarithmic search
Mar 21, 2016
This technical report describes an improved image mosaicking algorithm. It is based on Jain's logarithmic search algorithm [Jain 1981] which is coupled to the method of Kourogi (1999} for matching images in a video sequence. Logarithmic search has a better invariance against illumination changes than the original optical-flow-based method of Kourogi.
HyperTune: Dynamic Hyperparameter Tuning For Efficient Distribution of DNN Training Over Heterogeneous Systems
Jul 16, 2020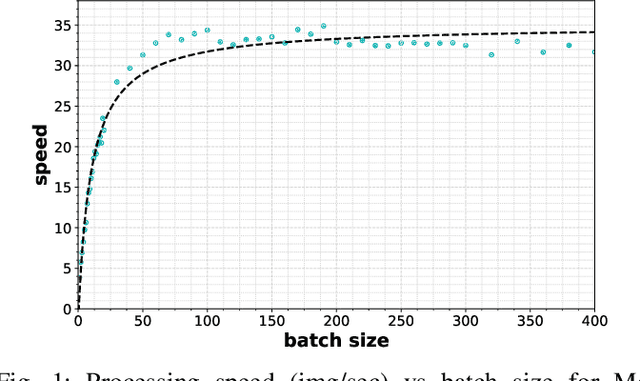
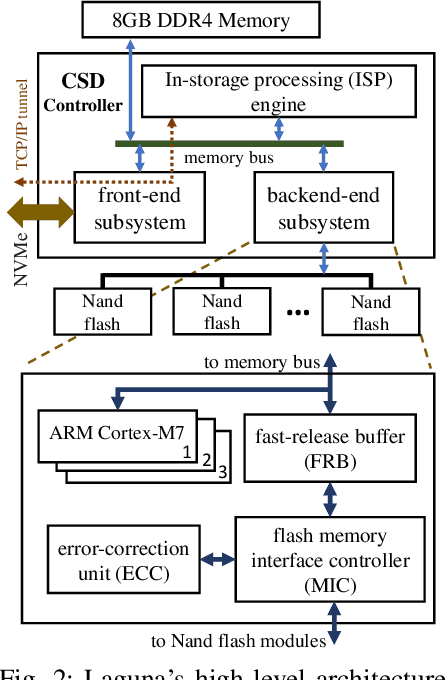
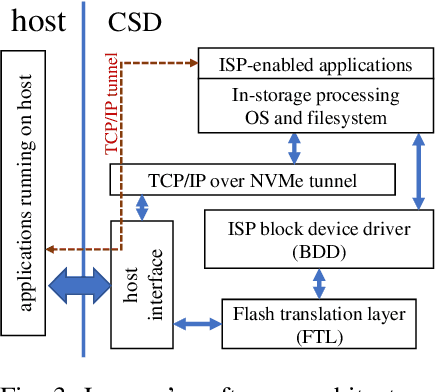

Distributed training is a novel approach to accelerate Deep Neural Networks (DNN) training, but common training libraries fall short of addressing the distributed cases with heterogeneous processors or the cases where the processing nodes get interrupted by other workloads. This paper describes distributed training of DNN on computational storage devices (CSD), which are NAND flash-based, high capacity data storage with internal processing engines. A CSD-based distributed architecture incorporates the advantages of federated learning in terms of performance scalability, resiliency, and data privacy by eliminating the unnecessary data movement between the storage device and the host processor. The paper also describes Stannis, a DNN training framework that improves on the shortcomings of existing distributed training frameworks by dynamically tuning the training hyperparameters in heterogeneous systems to maintain the maximum overall processing speed in term of processed images per second and energy efficiency. Experimental results on image classification training benchmarks show up to 3.1x improvement in performance and 2.45x reduction in energy consumption when using Stannis plus CSD compare to the generic systems.
Conditional Coupled Generative Adversarial Networks for Zero-Shot Domain Adaptation
Sep 11, 2020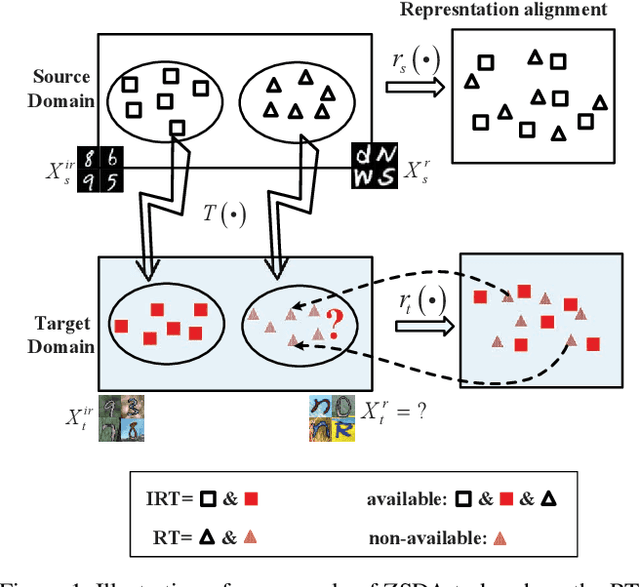
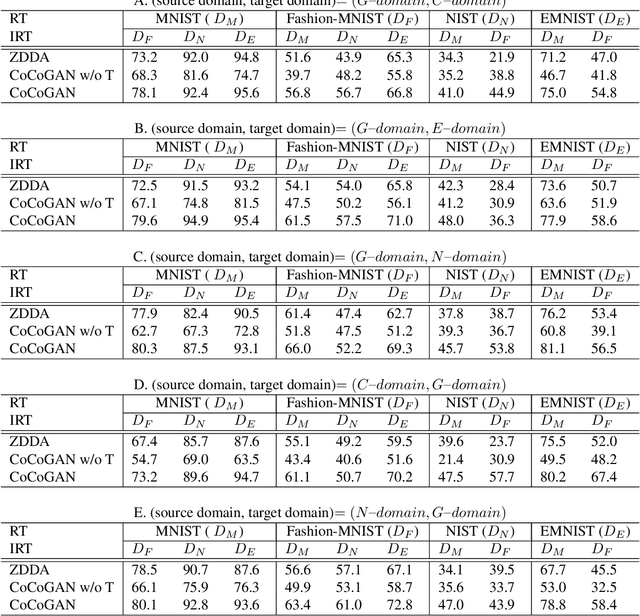
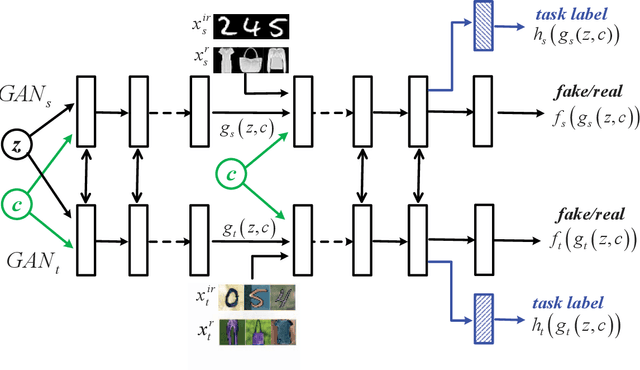

Machine learning models trained in one domain perform poorly in the other domains due to the existence of domain shift. Domain adaptation techniques solve this problem by training transferable models from the label-rich source domain to the label-scarce target domain. Unfortunately, a majority of the existing domain adaptation techniques rely on the availability of target-domain data, and thus limit their applications to a small community across few computer vision problems. In this paper, we tackle the challenging zero-shot domain adaptation (ZSDA) problem, where target-domain data is non-available in the training stage. For this purpose, we propose conditional coupled generative adversarial networks (CoCoGAN) by extending the coupled generative adversarial networks (CoGAN) into a conditioning model. Compared with the existing state of the arts, our proposed CoCoGAN is able to capture the joint distribution of dual-domain samples in two different tasks, i.e. the relevant task (RT) and an irrelevant task (IRT). We train CoCoGAN with both source-domain samples in RT and dual-domain samples in IRT to complete the domain adaptation. While the former provide high-level concepts of the non-available target-domain data, the latter carry the sharing correlation between the two domains in RT and IRT. To train CoCoGAN in the absence of target-domain data for RT, we propose a new supervisory signal, i.e. the alignment between representations across tasks. Extensive experiments carried out demonstrate that our proposed CoCoGAN outperforms existing state of the arts in image classifications.
Multi-Head Attention with Diversity for Learning Grounded Multilingual Multimodal Representations
Sep 30, 2019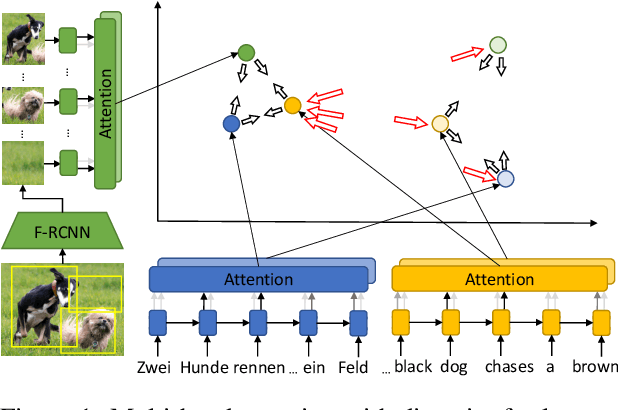
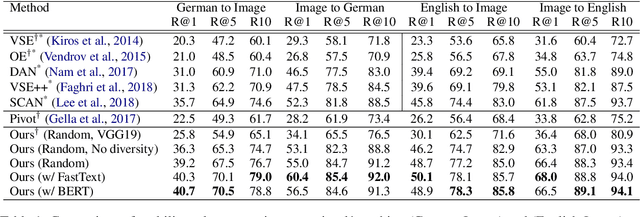
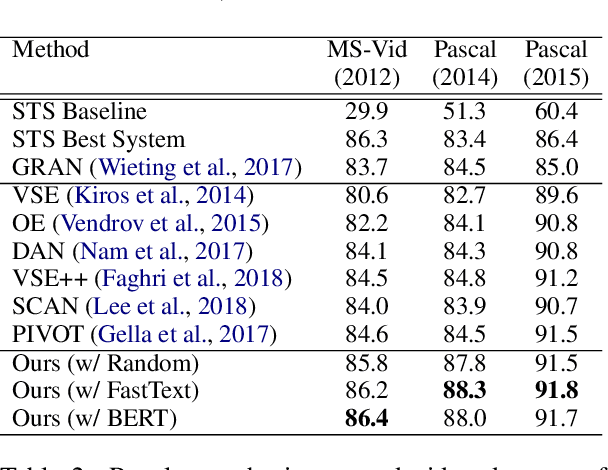

With the aim of promoting and understanding the multilingual version of image search, we leverage visual object detection and propose a model with diverse multi-head attention to learn grounded multilingual multimodal representations. Specifically, our model attends to different types of textual semantics in two languages and visual objects for fine-grained alignments between sentences and images. We introduce a new objective function which explicitly encourages attention diversity to learn an improved visual-semantic embedding space. We evaluate our model in the German-Image and English-Image matching tasks on the Multi30K dataset, and in the Semantic Textual Similarity task with the English descriptions of visual content. Results show that our model yields a significant performance gain over other methods in all of the three tasks.
Hierarchical Modeling of Multidimensional Data in Regularly Decomposed Spaces: Synthesis and Perspective
Jan 13, 2020



This fourth and last tome is focusing on describing the envisioned works for a project that has been presented in the preceding tome. It is about a new approach dedicated to the coding of still and moving pictures, trying to bridge the MPEG-4 and MPEG-7 standard bodies. The aim of this project is to define the principles of self-descriptive video coding. In order to establish them, the document is composed in five chapters that describe the various envisioned techniques for developing such a new approach in visual coding: - image segmentation, - computation of visual descriptors, - computation of perceptual groupings, - building of visual dictionaries, - picture and video coding. Based on the techniques of multiresolution computing, it is proposed to develop an image segmentation made from piecewise regular components, to compute attributes on the frame and the rendering of so produced shapes, independently to the geometric transforms that can occur in the image plane, and to gather them into perceptual groupings so as to be able in performing recognition of partially hidden patterns. Due to vector quantization of shapes frame and rendering, it will appear that simple shapes may be compared to a visual alphabet and that complex shapes then become words written using this alphabet and be recorded into a dictionary. With the help of a nearest neighbour scanning applied on the picture shapes, the self-descriptive coding will then generate a sentence made from words written using the simple shape alphabet.
Semantic Image Segmentation via Deep Parsing Network
Sep 24, 2015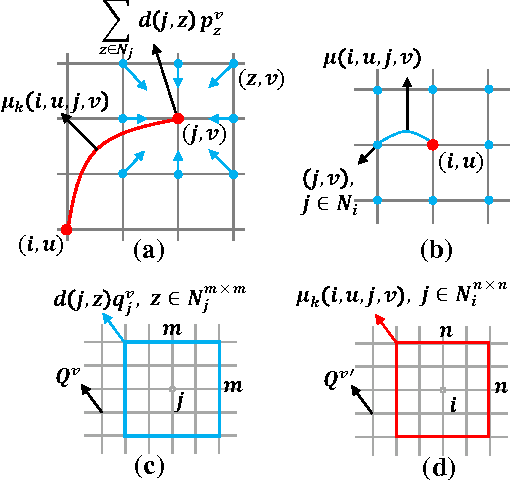
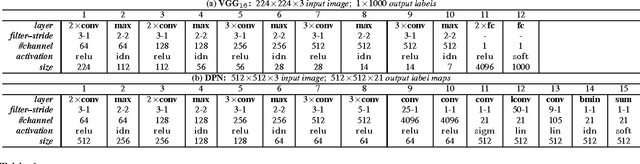
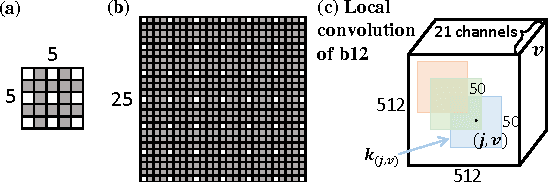

This paper addresses semantic image segmentation by incorporating rich information into Markov Random Field (MRF), including high-order relations and mixture of label contexts. Unlike previous works that optimized MRFs using iterative algorithm, we solve MRF by proposing a Convolutional Neural Network (CNN), namely Deep Parsing Network (DPN), which enables deterministic end-to-end computation in a single forward pass. Specifically, DPN extends a contemporary CNN architecture to model unary terms and additional layers are carefully devised to approximate the mean field algorithm (MF) for pairwise terms. It has several appealing properties. First, different from the recent works that combined CNN and MRF, where many iterations of MF were required for each training image during back-propagation, DPN is able to achieve high performance by approximating one iteration of MF. Second, DPN represents various types of pairwise terms, making many existing works as its special cases. Third, DPN makes MF easier to be parallelized and speeded up in Graphical Processing Unit (GPU). DPN is thoroughly evaluated on the PASCAL VOC 2012 dataset, where a single DPN model yields a new state-of-the-art segmentation accuracy.
Deep 3D-Zoom Net: Unsupervised Learning of Photo-Realistic 3D-Zoom
Sep 20, 2019
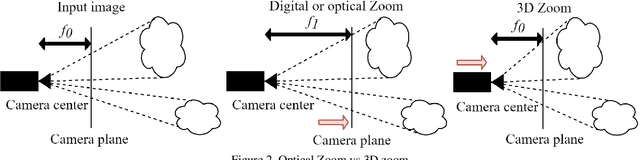
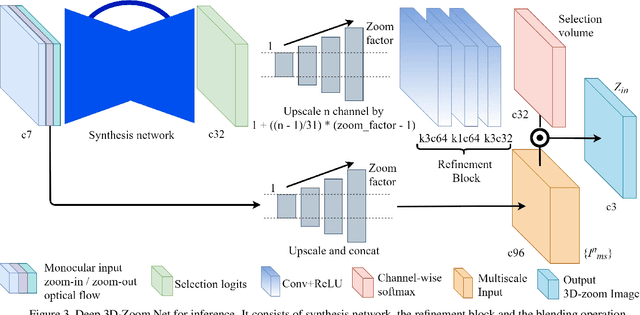
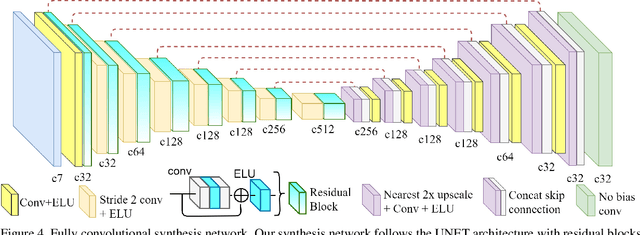
The 3D-zoom operation is the positive translation of the camera in the Z-axis, perpendicular to the image plane. In contrast, the optical zoom changes the focal length and the digital zoom is used to enlarge a certain region of an image to the original image size. In this paper, we are the first to formulate an unsupervised 3D-zoom learning problem where images with an arbitrary zoom factor can be generated from a given single image. An unsupervised framework is convenient, as it is a challenging task to obtain a 3D-zoom dataset of natural scenes due to the need for special equipment to ensure camera movement is restricted to the Z-axis. In addition, the objects in the scenes should not move when being captured, which hinders the construction of a large dataset of outdoor scenes. We present a novel unsupervised framework to learn how to generate arbitrarily 3D-zoomed versions of a single image, not requiring a 3D-zoom ground truth, called the Deep 3D-Zoom Net. The Deep 3D-Zoom Net incorporates the following features: (i) transfer learning from a pre-trained disparity estimation network via a back re-projection reconstruction loss; (ii) a fully convolutional network architecture that models depth-image-based rendering (DIBR), taking into account high-frequency details without the need for estimating the intermediate disparity; and (iii) incorporating a discriminator network that acts as a no-reference penalty for unnaturally rendered areas. Even though there is no baseline to fairly compare our results, our method outperforms previous novel view synthesis research in terms of realistic appearance on large camera baselines. We performed extensive experiments to verify the effectiveness of our method on the KITTI and Cityscapes datasets.
A Streaming Accelerator for Deep Convolutional Neural Networks with Image and Feature Decomposition for Resource-limited System Applications
Sep 15, 2017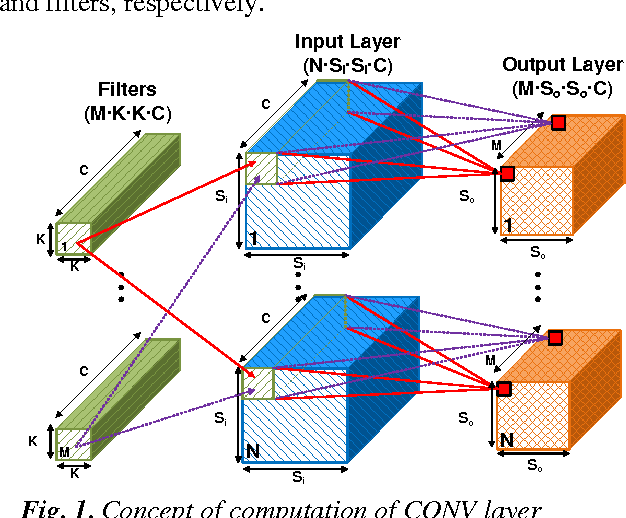
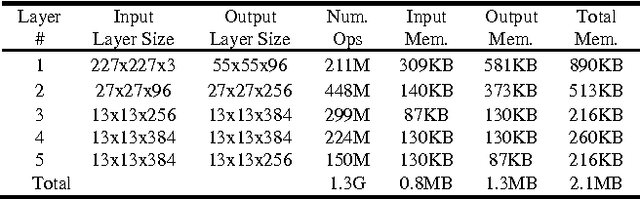
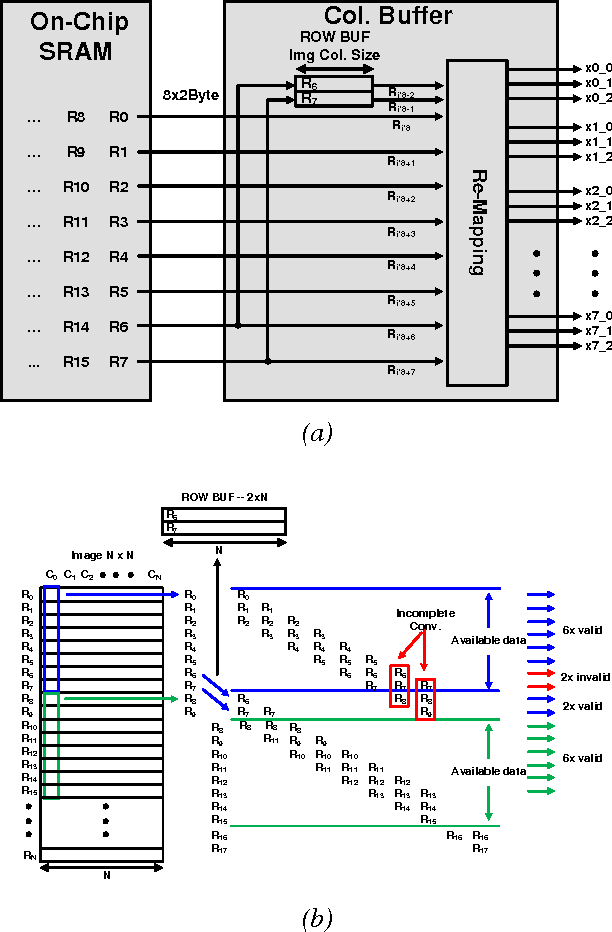
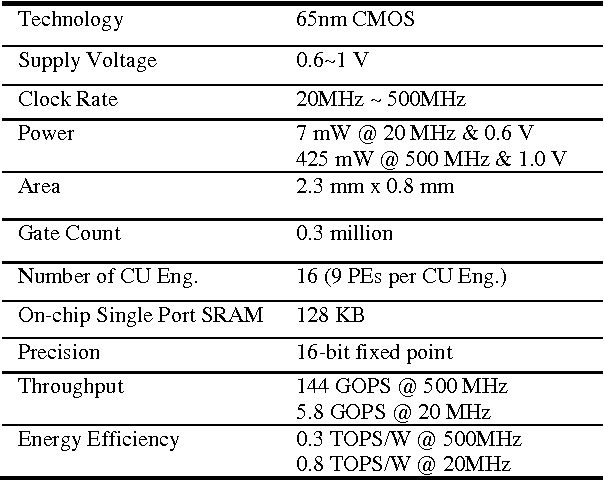
Deep convolutional neural networks (CNN) are widely used in modern artificial intelligence (AI) and smart vision systems but also limited by computation latency, throughput, and energy efficiency on a resource-limited scenario, such as mobile devices, internet of things (IoT), unmanned aerial vehicles (UAV), and so on. A hardware streaming architecture is proposed to accelerate convolution and pooling computations for state-of-the-art deep CNNs. It is optimized for energy efficiency by maximizing local data reuse to reduce off-chip DRAM data access. In addition, image and feature decomposition techniques are introduced to optimize memory access pattern for an arbitrary size of image and number of features within limited on-chip SRAM capacity. A prototype accelerator was implemented in TSMC 65 nm CMOS technology with 2.3 mm x 0.8 mm core area, which achieves 144 GOPS peak throughput and 0.8 TOPS/W peak energy efficiency.