 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Invertible Neural BRDF for Object Inverse Rendering
Aug 11, 2020

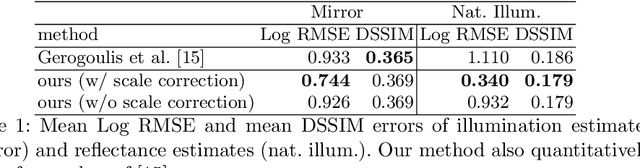

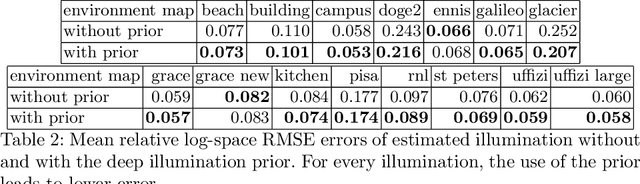
We introduce a novel neural network-based BRDF model and a Bayesian framework for object inverse rendering, i.e., joint estimation of reflectance and natural illumination from a single image of an object of known geometry. The BRDF is expressed with an invertible neural network, namely, normalizing flow, which provides the expressive power of a high-dimensional representation, computational simplicity of a compact analytical model, and physical plausibility of a real-world BRDF. We extract the latent space of real-world reflectance by conditioning this model, which directly results in a strong reflectance prior. We refer to this model as the invertible neural BRDF model (iBRDF). We also devise a deep illumination prior by leveraging the structural bias of deep neural networks. By integrating this novel BRDF model and reflectance and illumination priors in a MAP estimation formulation, we show that this joint estimation can be computed efficiently with stochastic gradient descent. We experimentally validate the accuracy of the invertible neural BRDF model on a large number of measured data and demonstrate its use in object inverse rendering on a number of synthetic and real images. The results show new ways in which deep neural networks can help solve challenging radiometric inverse problems.
A Review Paper: Noise Models in Digital Image Processing
May 13, 2015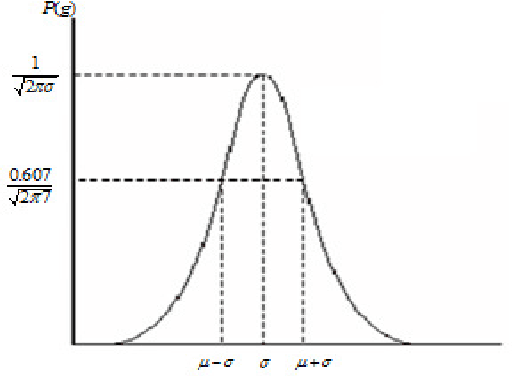
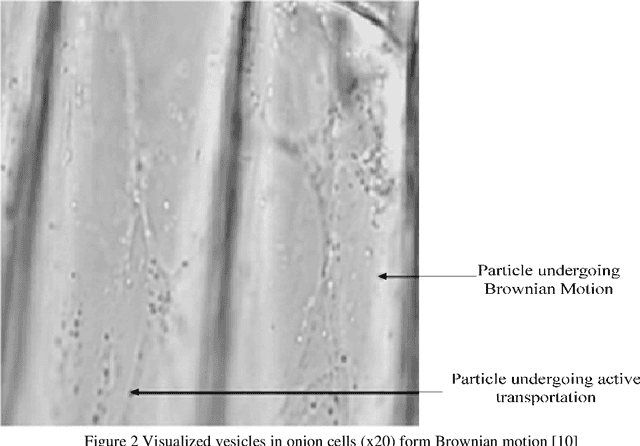

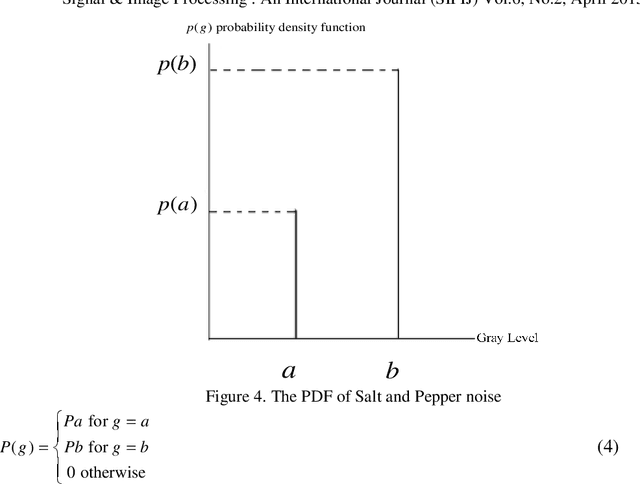
Noise is always presents in digital images during image acquisition, coding, transmission, and processing steps. Noise is very difficult to remove it from the digital images without the prior knowledge of noise model. That is why, review of noise models are essential in the study of image denoising techniques. In this paper, we express a brief overview of various noise models. These noise models can be selected by analysis of their origin. In this way, we present a complete and quantitative analysis of noise models available in digital images.
Depth Image Inpainting: Improving Low Rank Matrix Completion with Low Gradient Regularization
Apr 20, 2016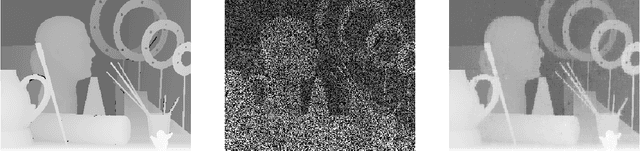


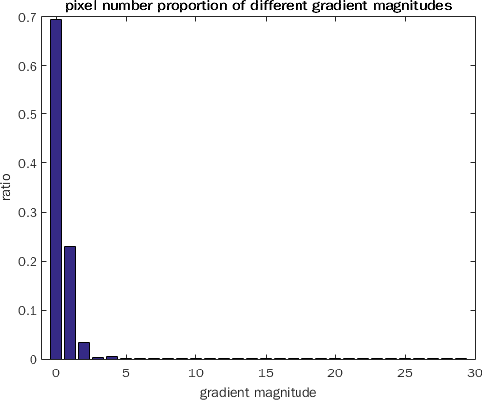
We consider the case of inpainting single depth images. Without corresponding color images, previous or next frames, depth image inpainting is quite challenging. One natural solution is to regard the image as a matrix and adopt the low rank regularization just as inpainting color images. However, the low rank assumption does not make full use of the properties of depth images. A shallow observation may inspire us to penalize the non-zero gradients by sparse gradient regularization. However, statistics show that though most pixels have zero gradients, there is still a non-ignorable part of pixels whose gradients are equal to 1. Based on this specific property of depth images , we propose a low gradient regularization method in which we reduce the penalty for gradient 1 while penalizing the non-zero gradients to allow for gradual depth changes. The proposed low gradient regularization is integrated with the low rank regularization into the low rank low gradient approach for depth image inpainting. We compare our proposed low gradient regularization with sparse gradient regularization. The experimental results show the effectiveness of our proposed approach.
Representation Learning with Deep Extreme Learning Machines for Efficient Image Set Classification
Apr 01, 2015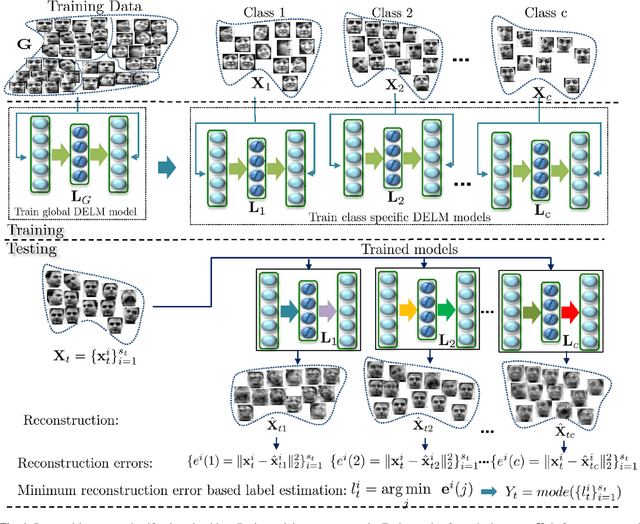
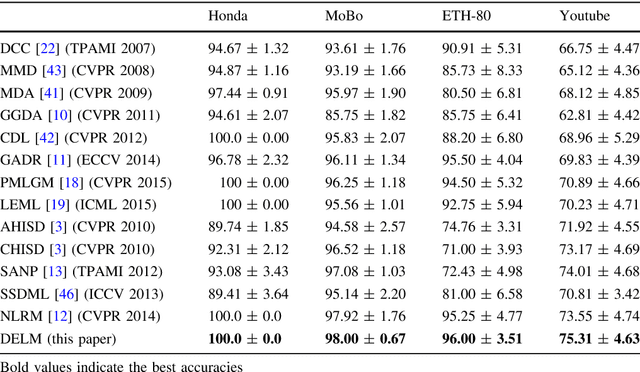
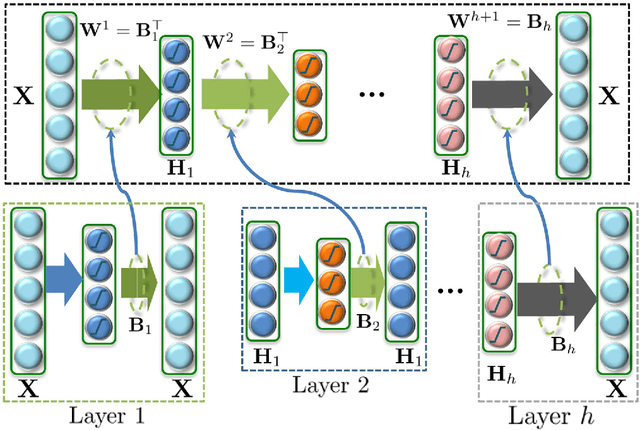
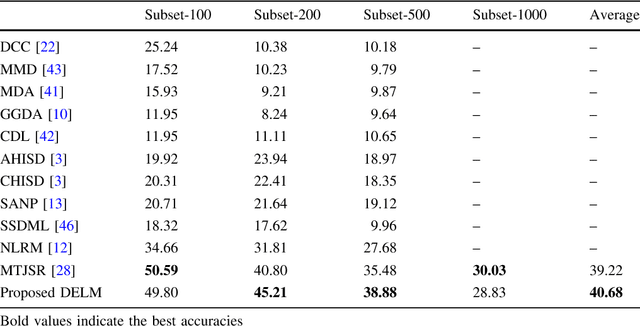
Efficient and accurate joint representation of a collection of images, that belong to the same class, is a major research challenge for practical image set classification. Existing methods either make prior assumptions about the data structure, or perform heavy computations to learn structure from the data itself. In this paper, we propose an efficient image set representation that does not make any prior assumptions about the structure of the underlying data. We learn the non-linear structure of image sets with Deep Extreme Learning Machines (DELM) that are very efficient and generalize well even on a limited number of training samples. Extensive experiments on a broad range of public datasets for image set classification (Honda/UCSD, CMU Mobo, YouTube Celebrities, Celebrity-1000, ETH-80) show that the proposed algorithm consistently outperforms state-of-the-art image set classification methods both in terms of speed and accuracy.
Spatio-temporal Attention Model for Tactile Texture Recognition
Aug 10, 2020
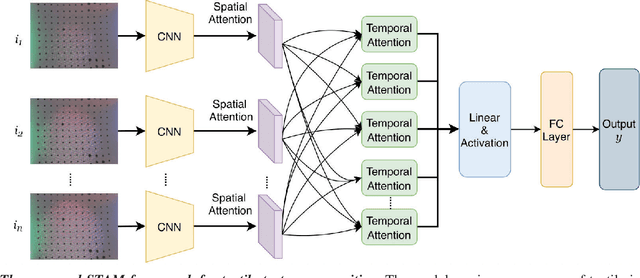
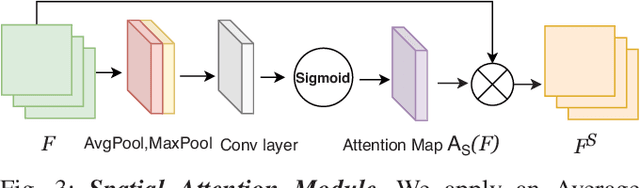
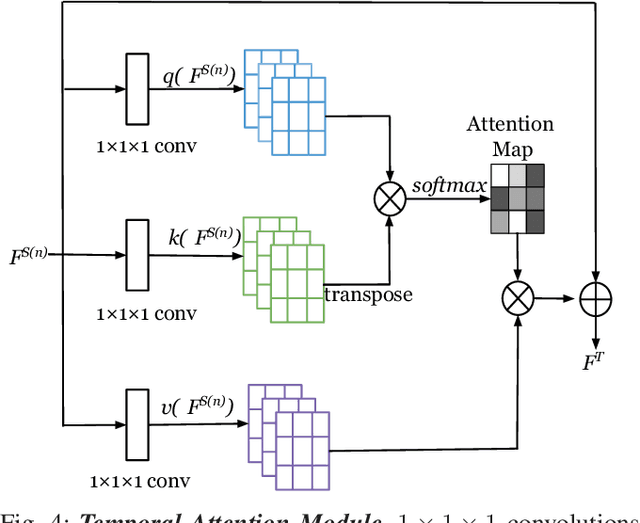
Recently, tactile sensing has attracted great interest in robotics, especially for facilitating exploration of unstructured environments and effective manipulation. A detailed understanding of the surface textures via tactile sensing is essential for many of these tasks. Previous works on texture recognition using camera based tactile sensors have been limited to treating all regions in one tactile image or all samples in one tactile sequence equally, which includes much irrelevant or redundant information. In this paper, we propose a novel Spatio-Temporal Attention Model (STAM) for tactile texture recognition, which is the very first of its kind to our best knowledge. The proposed STAM pays attention to both spatial focus of each single tactile texture and the temporal correlation of a tactile sequence. In the experiments to discriminate 100 different fabric textures, the spatially and temporally selective attention has resulted in a significant improvement of the recognition accuracy, by up to 18.8%, compared to the non-attention based models. Specifically, after introducing noisy data that is collected before the contact happens, our proposed STAM can learn the salient features efficiently and the accuracy can increase by 15.23% on average compared with the CNN based baseline approach. The improved tactile texture perception can be applied to facilitate robot tasks like grasping and manipulation.
D2D: Keypoint Extraction with Describe to Detect Approach
May 27, 2020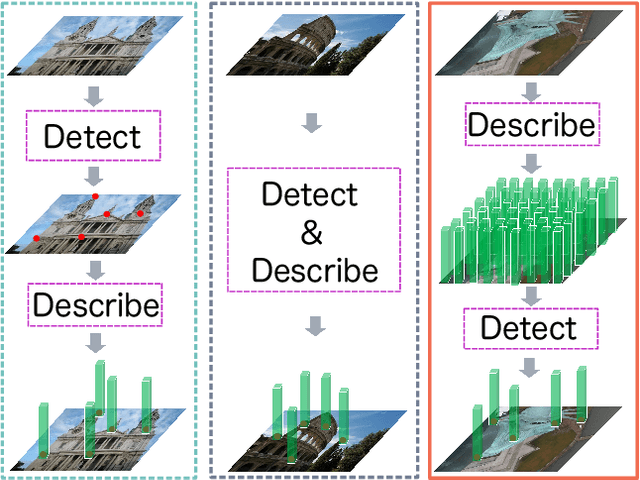
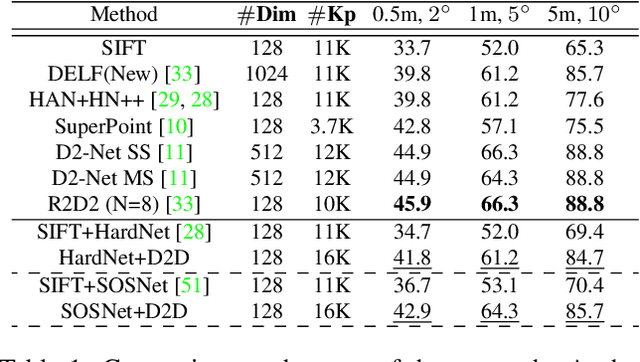
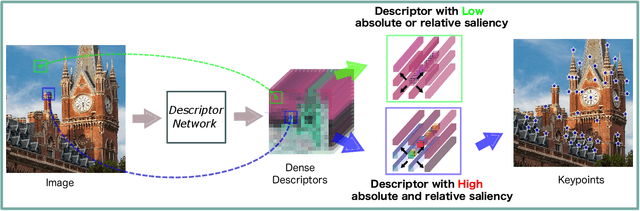
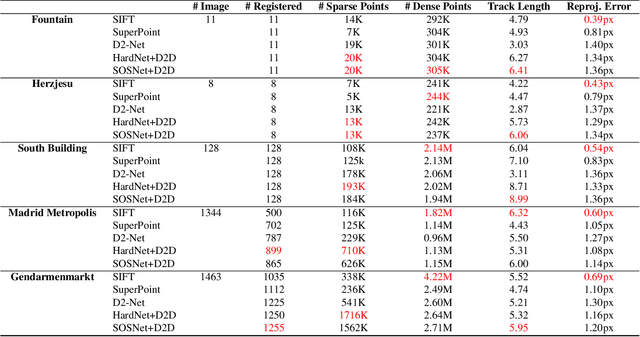
In this paper, we present a novel approach that exploits the information within the descriptor space to propose keypoint locations. Detect then describe, or detect and describe jointly are two typical strategies for extracting local descriptors. In contrast, we propose an approach that inverts this process by first describing and then detecting the keypoint locations. % Describe-to-Detect (D2D) leverages successful descriptor models without the need for any additional training. Our method selects keypoints as salient locations with high information content which is defined by the descriptors rather than some independent operators. We perform experiments on multiple benchmarks including image matching, camera localisation, and 3D reconstruction. The results indicate that our method improves the matching performance of various descriptors and that it generalises across methods and tasks.
Conditional Coupled Generative Adversarial Networks for Zero-Shot Domain Adaptation
Sep 11, 2020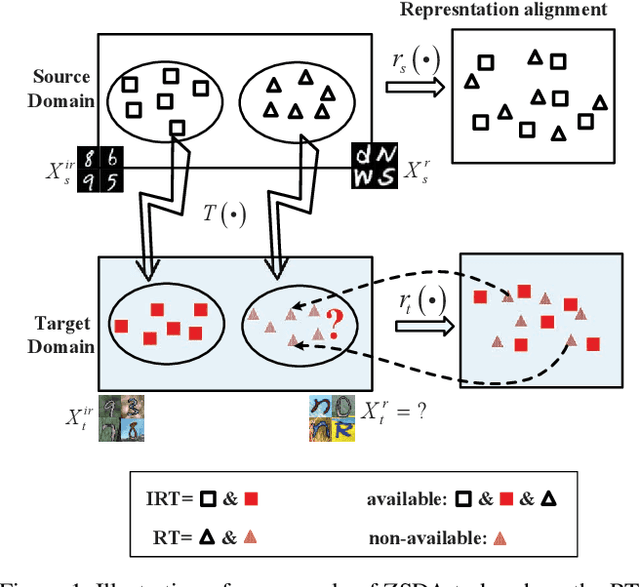
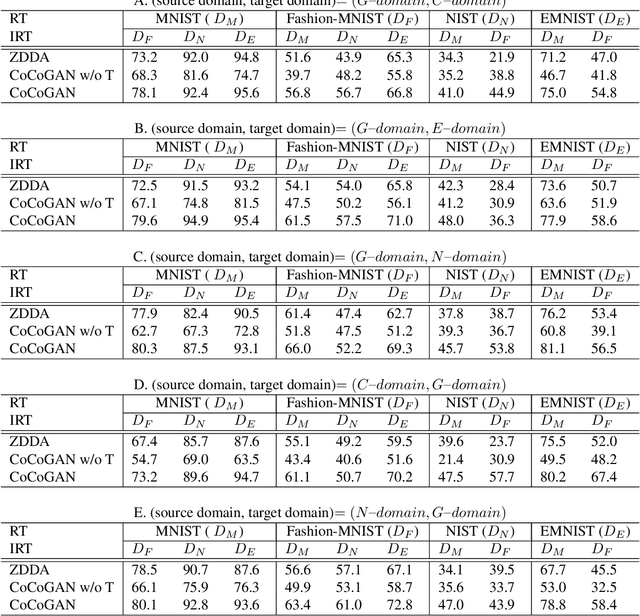
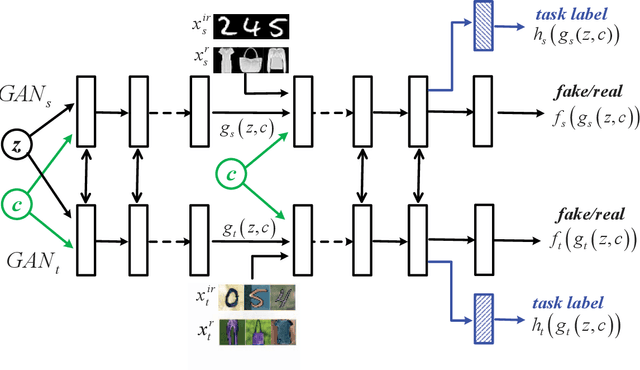

Machine learning models trained in one domain perform poorly in the other domains due to the existence of domain shift. Domain adaptation techniques solve this problem by training transferable models from the label-rich source domain to the label-scarce target domain. Unfortunately, a majority of the existing domain adaptation techniques rely on the availability of target-domain data, and thus limit their applications to a small community across few computer vision problems. In this paper, we tackle the challenging zero-shot domain adaptation (ZSDA) problem, where target-domain data is non-available in the training stage. For this purpose, we propose conditional coupled generative adversarial networks (CoCoGAN) by extending the coupled generative adversarial networks (CoGAN) into a conditioning model. Compared with the existing state of the arts, our proposed CoCoGAN is able to capture the joint distribution of dual-domain samples in two different tasks, i.e. the relevant task (RT) and an irrelevant task (IRT). We train CoCoGAN with both source-domain samples in RT and dual-domain samples in IRT to complete the domain adaptation. While the former provide high-level concepts of the non-available target-domain data, the latter carry the sharing correlation between the two domains in RT and IRT. To train CoCoGAN in the absence of target-domain data for RT, we propose a new supervisory signal, i.e. the alignment between representations across tasks. Extensive experiments carried out demonstrate that our proposed CoCoGAN outperforms existing state of the arts in image classifications.
Distributed Reinforcement Learning of Targeted Grasping with Active Vision for Mobile Manipulators
Jul 16, 2020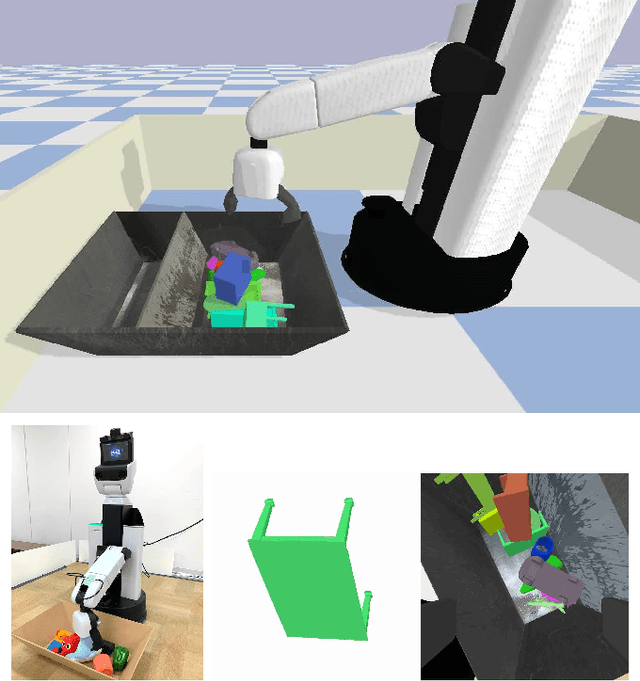
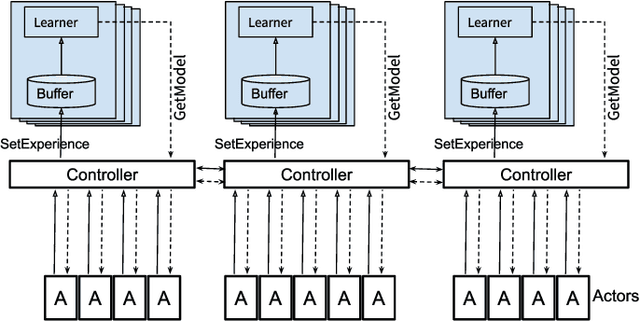
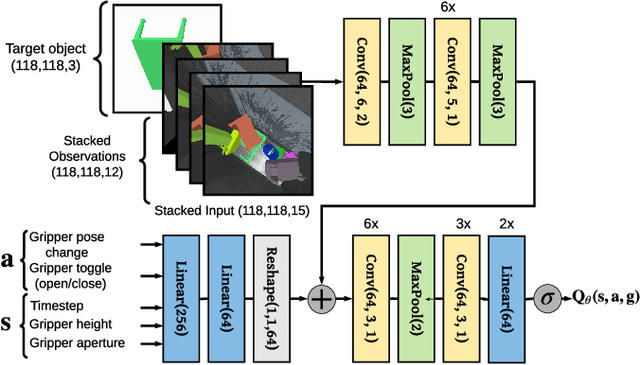
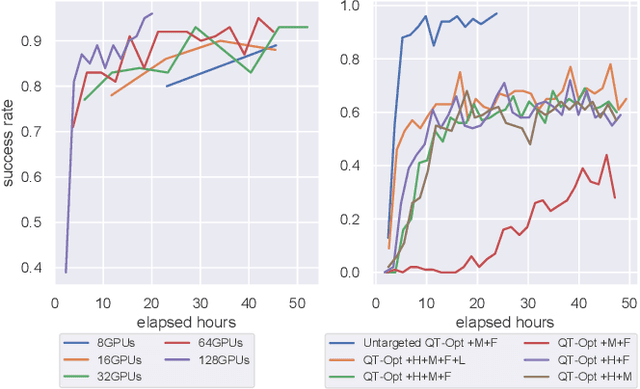
Developing personal robots that can perform a diverse range of manipulation tasks in unstructured environments necessitates solving several challenges for robotic grasping systems. We take a step towards this broader goal by presenting the first RL-based system, to our knowledge, for a mobile manipulator that can (a) achieve targeted grasping generalizing to unseen target objects, (b) learn complex grasping strategies for cluttered scenes with occluded objects, and (c) perform active vision through its movable wrist camera to better locate objects. The system is informed of the desired target object in the form of a single, arbitrary-pose RGB image of that object, enabling the system to generalize to unseen objects without retraining. To achieve such a system, we combine several advances in deep reinforcement learning and present a large-scale distributed training system using synchronous SGD that seamlessly scales to multi-node, multi-GPU infrastructure to make rapid prototyping easier. We train and evaluate our system in a simulated environment, identify key components for improving performance, analyze its behaviors, and transfer to a real-world setup.
An Architecture Combining Convolutional Neural Network (CNN) and Support Vector Machine (SVM) for Image Classification
Dec 10, 2017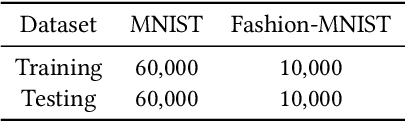
Convolutional neural networks (CNNs) are similar to "ordinary" neural networks in the sense that they are made up of hidden layers consisting of neurons with "learnable" parameters. These neurons receive inputs, performs a dot product, and then follows it with a non-linearity. The whole network expresses the mapping between raw image pixels and their class scores. Conventionally, the Softmax function is the classifier used at the last layer of this network. However, there have been studies (Alalshekmubarak and Smith, 2013; Agarap, 2017; Tang, 2013) conducted to challenge this norm. The cited studies introduce the usage of linear support vector machine (SVM) in an artificial neural network architecture. This project is yet another take on the subject, and is inspired by (Tang, 2013). Empirical data has shown that the CNN-SVM model was able to achieve a test accuracy of ~99.04% using the MNIST dataset (LeCun, Cortes, and Burges, 2010). On the other hand, the CNN-Softmax was able to achieve a test accuracy of ~99.23% using the same dataset. Both models were also tested on the recently-published Fashion-MNIST dataset (Xiao, Rasul, and Vollgraf, 2017), which is suppose to be a more difficult image classification dataset than MNIST (Zalandoresearch, 2017). This proved to be the case as CNN-SVM reached a test accuracy of ~90.72%, while the CNN-Softmax reached a test accuracy of ~91.86%. The said results may be improved if data preprocessing techniques were employed on the datasets, and if the base CNN model was a relatively more sophisticated than the one used in this study.
HyperTune: Dynamic Hyperparameter Tuning For Efficient Distribution of DNN Training Over Heterogeneous Systems
Jul 16, 2020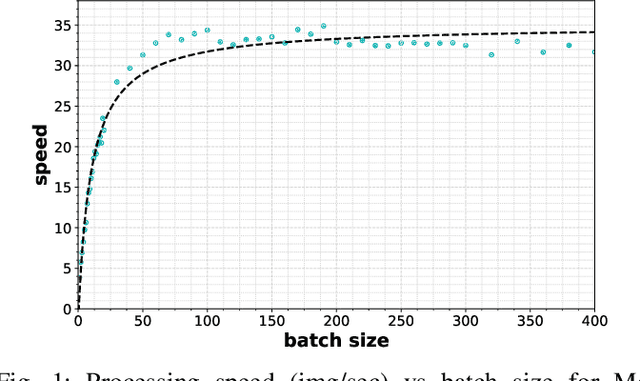
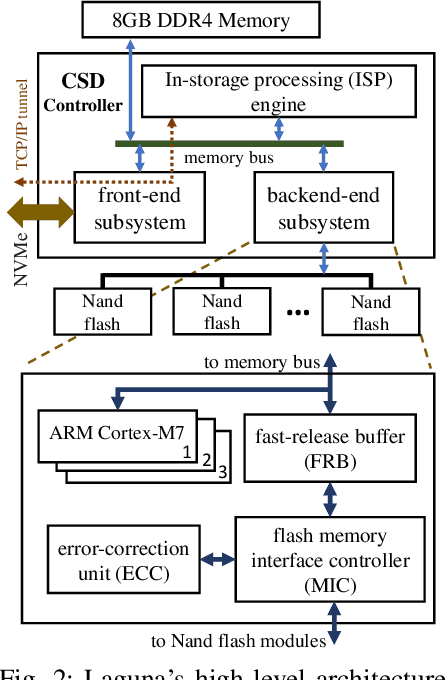
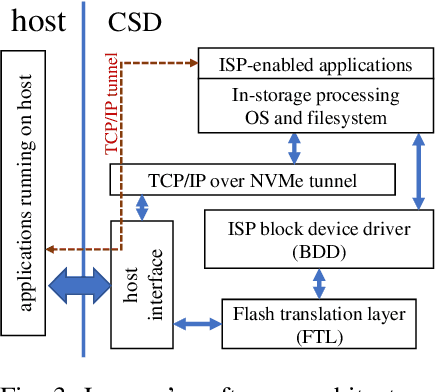

Distributed training is a novel approach to accelerate Deep Neural Networks (DNN) training, but common training libraries fall short of addressing the distributed cases with heterogeneous processors or the cases where the processing nodes get interrupted by other workloads. This paper describes distributed training of DNN on computational storage devices (CSD), which are NAND flash-based, high capacity data storage with internal processing engines. A CSD-based distributed architecture incorporates the advantages of federated learning in terms of performance scalability, resiliency, and data privacy by eliminating the unnecessary data movement between the storage device and the host processor. The paper also describes Stannis, a DNN training framework that improves on the shortcomings of existing distributed training frameworks by dynamically tuning the training hyperparameters in heterogeneous systems to maintain the maximum overall processing speed in term of processed images per second and energy efficiency. Experimental results on image classification training benchmarks show up to 3.1x improvement in performance and 2.45x reduction in energy consumption when using Stannis plus CSD compare to the generic systems.