 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Natural Adversarial Patch Generation Method Based on Latent Diffusion Model
Dec 27, 2023
Recently, some research show that deep neural networks are vulnerable to the adversarial attacks, the well-trainned samples or patches could be used to trick the neural network detector or human visual perception. However, these adversarial patches, with their conspicuous and unusual patterns, lack camouflage and can easily raise suspicion in the real world. To solve this problem, this paper proposed a novel adversarial patch method called the Latent Diffusion Patch (LDP), in which, a pretrained encoder is first designed to compress the natural images into a feature space with key characteristics. Then trains the diffusion model using the above feature space. Finally, explore the latent space of the pretrained diffusion model using the image denoising technology. It polishes the patches and images through the powerful natural abilities of diffusion models, making them more acceptable to the human visual system. Experimental results, both digital and physical worlds, show that LDPs achieve a visual subjectivity score of 87.3%, while still maintaining effective attack capabilities.
AdvCloak: Customized Adversarial Cloak for Privacy Protection
Dec 22, 2023With extensive face images being shared on social media, there has been a notable escalation in privacy concerns. In this paper, we propose AdvCloak, an innovative framework for privacy protection using generative models. AdvCloak is designed to automatically customize class-wise adversarial masks that can maintain superior image-level naturalness while providing enhanced feature-level generalization ability. Specifically, AdvCloak sequentially optimizes the generative adversarial networks by employing a two-stage training strategy. This strategy initially focuses on adapting the masks to the unique individual faces via image-specific training and then enhances their feature-level generalization ability to diverse facial variations of individuals via person-specific training. To fully utilize the limited training data, we combine AdvCloak with several general geometric modeling methods, to better describe the feature subspace of source identities. Extensive quantitative and qualitative evaluations on both common and celebrity datasets demonstrate that AdvCloak outperforms existing state-of-the-art methods in terms of efficiency and effectiveness.
Amodal Ground Truth and Completion in the Wild
Dec 28, 2023The problem we study in this paper is amodal image segmentation: predicting entire object segmentation masks including both visible and invisible (occluded) parts. In previous work, the amodal segmentation ground truth on real images is usually predicted by manual annotaton and thus is subjective. In contrast, we use 3D data to establish an automatic pipeline to determine authentic ground truth amodal masks for partially occluded objects in real images. This pipeline is used to construct an amodal completion evaluation benchmark, MP3D-Amodal, consisting of a variety of object categories and labels. To better handle the amodal completion task in the wild, we explore two architecture variants: a two-stage model that first infers the occluder, followed by amodal mask completion; and a one-stage model that exploits the representation power of Stable Diffusion for amodal segmentation across many categories. Without bells and whistles, our method achieves a new state-of-the-art performance on Amodal segmentation datasets that cover a large variety of objects, including COCOA and our new MP3D-Amodal dataset. The dataset, model, and code are available at https://www.robots.ox.ac.uk/~vgg/research/amodal/.
Generalized Mask-aware IoU for Anchor Assignment for Real-time Instance Segmentation
Dec 28, 2023This paper introduces Generalized Mask-aware Intersection-over-Union (GmaIoU) as a new measure for positive-negative assignment of anchor boxes during training of instance segmentation methods. Unlike conventional IoU measure or its variants, which only consider the proximity of anchor and ground-truth boxes; GmaIoU additionally takes into account the segmentation mask. This enables GmaIoU to provide more accurate supervision during training. We demonstrate the effectiveness of GmaIoU by replacing IoU with our GmaIoU in ATSS, a state-of-the-art (SOTA) assigner. Then, we train YOLACT, a real-time instance segmentation method, using our GmaIoU-based ATSS assigner. The resulting YOLACT based on the GmaIoU assigner outperforms (i) ATSS with IoU by $\sim 1.0-1.5$ mask AP, (ii) YOLACT with a fixed IoU threshold assigner by $\sim 1.5-2$ mask AP over different image sizes and (iii) decreases the inference time by $25 \%$ owing to using less anchors. Taking advantage of this efficiency, we further devise GmaYOLACT, a faster and $+7$ mask AP points more accurate detector than YOLACT. Our best model achieves $38.7$ mask AP at $26$ fps on COCO test-dev establishing a new state-of-the-art for real-time instance segmentation.
PEA-Diffusion: Parameter-Efficient Adapter with Knowledge Distillation in non-English Text-to-Image Generation
Nov 28, 2023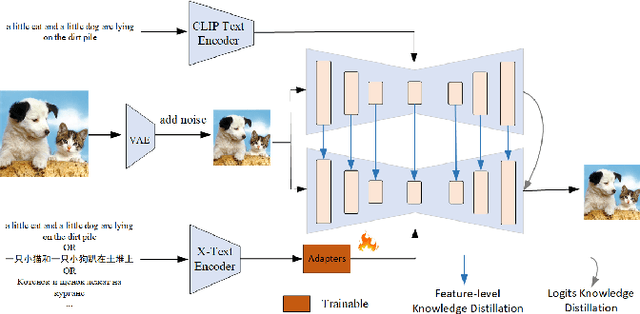
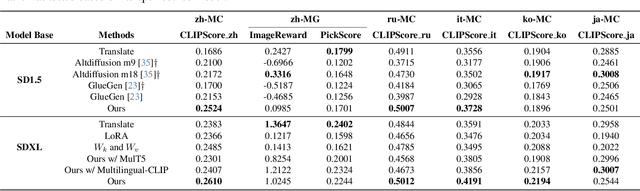

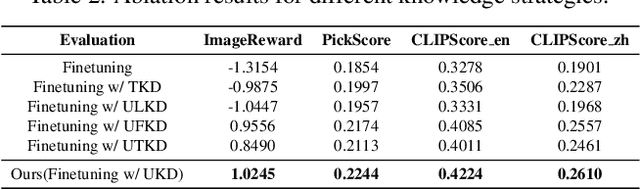
Text-to-image diffusion models are well-known for their ability to generate realistic images based on textual prompts. However, the existing works have predominantly focused on English, lacking support for non-English text-to-image models. The most commonly used translation methods cannot solve the generation problem related to language culture, while training from scratch on a specific language dataset is prohibitively expensive. In this paper, we are inspired to propose a simple plug-and-play language transfer method based on knowledge distillation. All we need to do is train a lightweight MLP-like parameter-efficient adapter (PEA) with only 6M parameters under teacher knowledge distillation along with a small parallel data corpus. We are surprised to find that freezing the parameters of UNet can still achieve remarkable performance on the language-specific prompt evaluation set, demonstrating that PEA can stimulate the potential generation ability of the original UNet. Additionally, it closely approaches the performance of the English text-to-image model on a general prompt evaluation set. Furthermore, our adapter can be used as a plugin to achieve significant results in downstream tasks in cross-lingual text-to-image generation. Code will be available at: https://github.com/OPPO-Mente-Lab/PEA-Diffusion
Unveiling Objects with SOLA: An Annotation-Free Image Search on the Object Level for Automotive Data Sets
Dec 04, 2023Huge image data sets are the fundament for the development of the perception of automated driving systems. A large number of images is necessary to train robust neural networks that can cope with diverse situations. A sufficiently large data set contains challenging situations and objects. For testing the resulting functions, it is necessary that these situations and objects can be found and extracted from the data set. While it is relatively easy to record a large amount of unlabeled data, it is far more difficult to find demanding situations and objects. However, during the development of perception systems, it must be possible to access challenging data without having to perform lengthy and time-consuming annotations. A developer must therefore be able to search dynamically for specific situations and objects in a data set. Thus, we designed a method which is based on state-of-the-art neural networks to search for objects with certain properties within an image. For the ease of use, the query of this search is described using natural language. To determine the time savings and performance gains, we evaluated our method qualitatively and quantitatively on automotive data sets.
InfoVisDial: An Informative Visual Dialogue Dataset by Bridging Large Multimodal and Language Models
Dec 21, 2023In this paper, we build a visual dialogue dataset, named InfoVisDial, which provides rich informative answers in each round even with external knowledge related to the visual content. Different from existing datasets where the answer is compact and short, InfoVisDial contains long free-form answers with rich information in each round of dialogue. For effective data collection, the key idea is to bridge the large-scale multimodal model (e.g., GIT) and the language models (e.g., GPT-3). GIT can describe the image content even with scene text, while GPT-3 can generate informative dialogue based on the image description and appropriate prompting techniques. With such automatic pipeline, we can readily generate informative visual dialogue data at scale. Then, we ask human annotators to rate the generated dialogues to filter the low-quality conversations.Human analyses show that InfoVisDial covers informative and diverse dialogue topics: $54.4\%$ of the dialogue rounds are related to image scene texts, and $36.7\%$ require external knowledge. Each round's answer is also long and open-ended: $87.3\%$ of answers are unique with an average length of $8.9$, compared with $27.37\%$ and $2.9$ in VisDial. Last, we propose a strong baseline by adapting the GIT model for the visual dialogue task and fine-tune the model on InfoVisDial. Hopefully, our work can motivate more effort on this direction.
Multi-scale Progressive Feature Embedding for Accurate NIR-to-RGB Spectral Domain Translation
Dec 26, 2023NIR-to-RGB spectral domain translation is a challenging task due to the mapping ambiguities, and existing methods show limited learning capacities. To address these challenges, we propose to colorize NIR images via a multi-scale progressive feature embedding network (MPFNet), with the guidance of grayscale image colorization. Specifically, we first introduce a domain translation module that translates NIR source images into the grayscale target domain. By incorporating a progressive training strategy, the statistical and semantic knowledge from both task domains are efficiently aligned with a series of pixel- and feature-level consistency constraints. Besides, a multi-scale progressive feature embedding network is designed to improve learning capabilities. Experiments show that our MPFNet outperforms state-of-the-art counterparts by 2.55 dB in the NIR-to-RGB spectral domain translation task in terms of PSNR.
When an Image is Worth 1,024 x 1,024 Words: A Case Study in Computational Pathology
Dec 06, 2023This technical report presents LongViT, a vision Transformer that can process gigapixel images in an end-to-end manner. Specifically, we split the gigapixel image into a sequence of millions of patches and project them linearly into embeddings. LongNet is then employed to model the extremely long sequence, generating representations that capture both short-range and long-range dependencies. The linear computation complexity of LongNet, along with its distributed algorithm, enables us to overcome the constraints of both computation and memory. We apply LongViT in the field of computational pathology, aiming for cancer diagnosis and prognosis within gigapixel whole-slide images. Experimental results demonstrate that LongViT effectively encodes gigapixel images and outperforms previous state-of-the-art methods on cancer subtyping and survival prediction. Code and models will be available at https://aka.ms/LongViT.
Compression of end-to-end non-autoregressive image-to-speech system for low-resourced devices
Nov 30, 2023People with visual impairments have difficulty accessing touchscreen-enabled personal computing devices like mobile phones and laptops. The image-to-speech (ITS) systems can assist them in mitigating this problem, but their huge model size makes it extremely hard to be deployed on low-resourced embedded devices. In this paper, we aim to overcome this challenge by developing an efficient endto-end neural architecture for generating audio from tiny segments of display content on low-resource devices. We introduced a vision transformers-based image encoder and utilized knowledge distillation to compress the model from 6.1 million to 2.46 million parameters. Human and automatic evaluation results show that our approach leads to a very minimal drop in performance and can speed up the inference time by 22%.