 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint Training of Variational Auto-Encoder and Latent Energy-Based Model
Jun 10, 2020


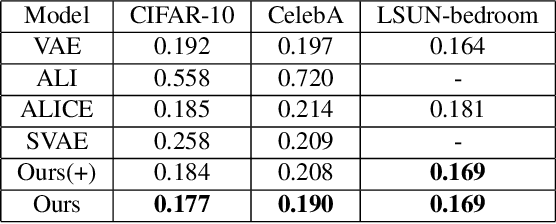

This paper proposes a joint training method to learn both the variational auto-encoder (VAE) and the latent energy-based model (EBM). The joint training of VAE and latent EBM are based on an objective function that consists of three Kullback-Leibler divergences between three joint distributions on the latent vector and the image, and the objective function is of an elegant symmetric and anti-symmetric form of divergence triangle that seamlessly integrates variational and adversarial learning. In this joint training scheme, the latent EBM serves as a critic of the generator model, while the generator model and the inference model in VAE serve as the approximate synthesis sampler and inference sampler of the latent EBM. Our experiments show that the joint training greatly improves the synthesis quality of the VAE. It also enables learning of an energy function that is capable of detecting out of sample examples for anomaly detection.
One-Shot Weakly Supervised Video Object Segmentation
Dec 18, 2019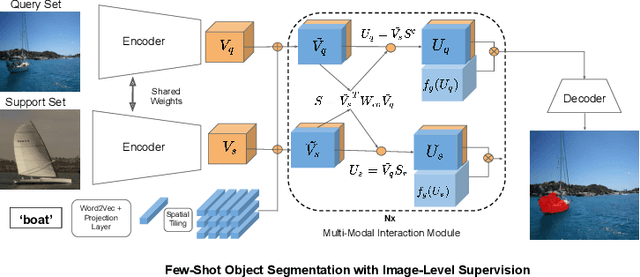
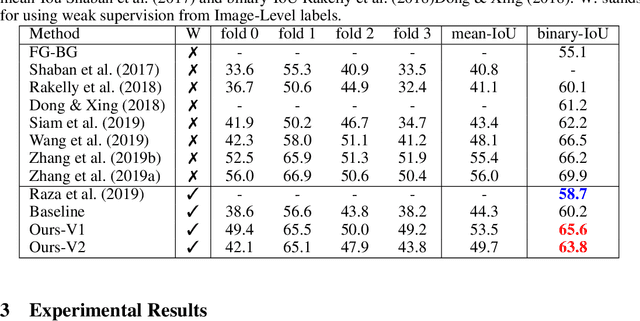


Conventional few-shot object segmentation methods learn object segmentation from a few labelled support images with strongly labelled segmentation masks. Recent work has shown to perform on par with weaker levels of supervision in terms of scribbles and bounding boxes. However, there has been limited attention given to the problem of few-shot object segmentation with image-level supervision. We propose a novel multi-modal interaction module for few-shot object segmentation that utilizes a co-attention mechanism using both visual and word embeddings. It enables our model to achieve 5.1% improvement over previously proposed image-level few-shot object segmentation. Our method compares relatively close to the state of the art methods that use strong supervision, while ours use the least possible supervision. We further propose a novel setup for few-shot weakly supervised video object segmentation(VOS) that relies on image-level labels for the first frame. The proposed setup uses weak annotation unlike semi-supervised VOS setting that utilizes strongly labelled segmentation masks. The setup evaluates the effectiveness of generalizing to novel classes in the VOS setting. The setup splits the VOS data into multiple folds with different categories per fold. It provides a potential setup to evaluate how few-shot object segmentation methods can benefit from additional object poses, or object interactions that is not available in static frames as in PASCAL-5i benchmark.
Segmenting Medical MRI via Recurrent Decoding Cell
Nov 21, 2019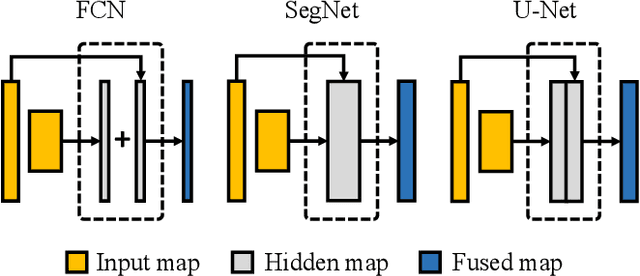
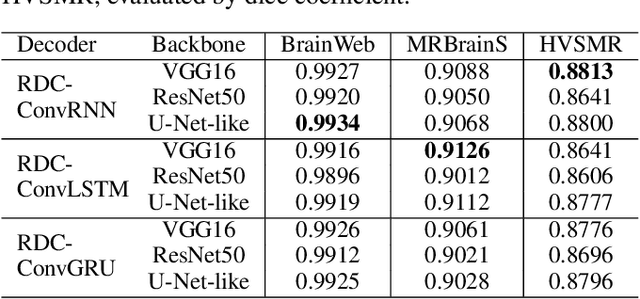
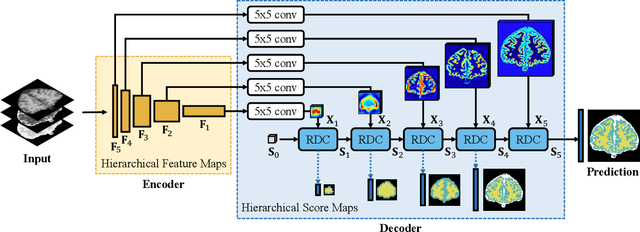
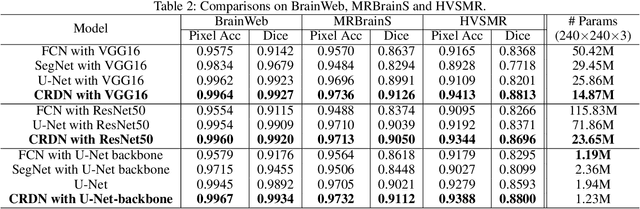
The encoder-decoder networks are commonly used in medical image segmentation due to their remarkable performance in hierarchical feature fusion. However, the expanding path for feature decoding and spatial recovery does not consider the long-term dependency when fusing feature maps from different layers, and the universal encoder-decoder network does not make full use of the multi-modality information to improve the network robustness especially for segmenting medical MRI. In this paper, we propose a novel feature fusion unit called Recurrent Decoding Cell (RDC) which leverages convolutional RNNs to memorize the long-term context information from the previous layers in the decoding phase. An encoder-decoder network, named Convolutional Recurrent Decoding Network (CRDN), is also proposed based on RDC for segmenting multi-modality medical MRI. CRDN adopts CNN backbone to encode image features and decode them hierarchically through a chain of RDCs to obtain the final high-resolution score map. The evaluation experiments on BrainWeb, MRBrainS and HVSMR datasets demonstrate that the introduction of RDC effectively improves the segmentation accuracy as well as reduces the model size, and the proposed CRDN owns its robustness to image noise and intensity non-uniformity in medical MRI.
Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image
Feb 26, 2018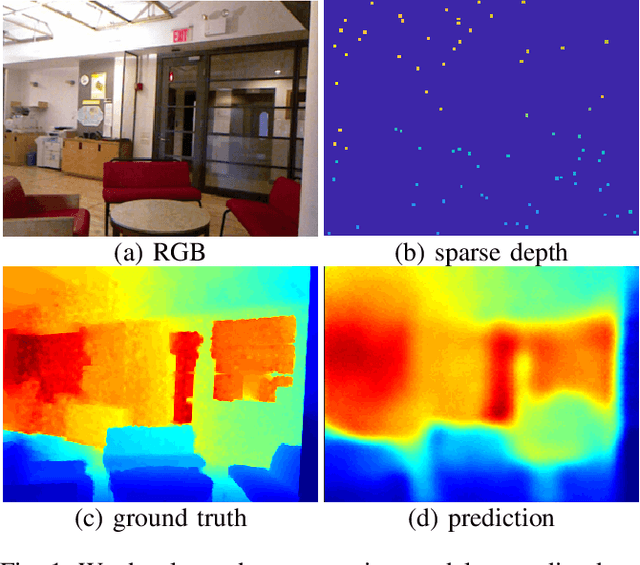
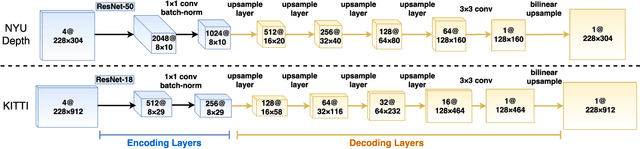
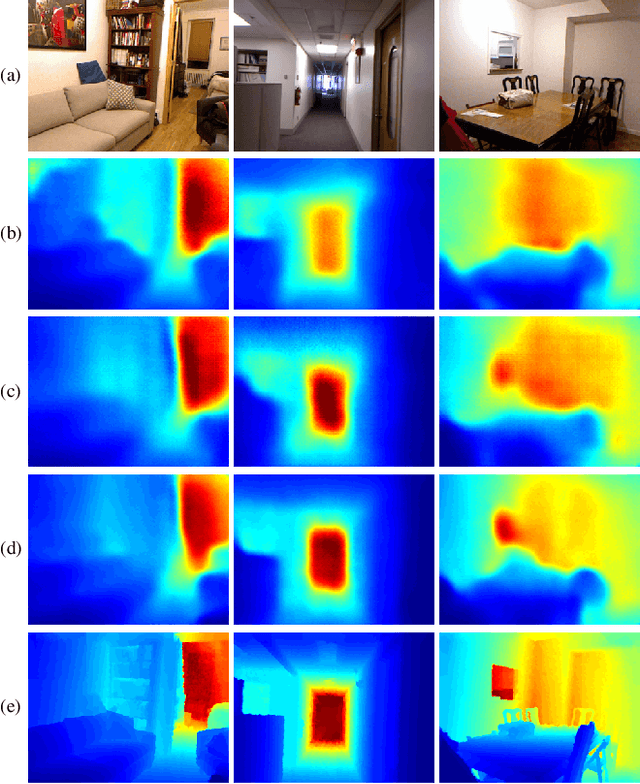
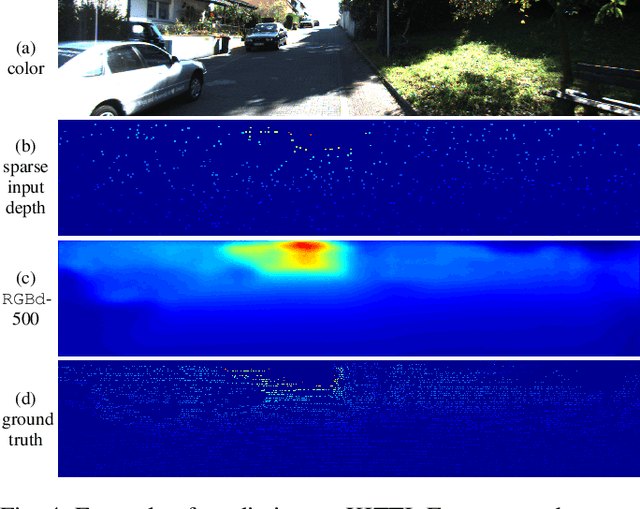
We consider the problem of dense depth prediction from a sparse set of depth measurements and a single RGB image. Since depth estimation from monocular images alone is inherently ambiguous and unreliable, to attain a higher level of robustness and accuracy, we introduce additional sparse depth samples, which are either acquired with a low-resolution depth sensor or computed via visual Simultaneous Localization and Mapping (SLAM) algorithms. We propose the use of a single deep regression network to learn directly from the RGB-D raw data, and explore the impact of number of depth samples on prediction accuracy. Our experiments show that, compared to using only RGB images, the addition of 100 spatially random depth samples reduces the prediction root-mean-square error by 50% on the NYU-Depth-v2 indoor dataset. It also boosts the percentage of reliable prediction from 59% to 92% on the KITTI dataset. We demonstrate two applications of the proposed algorithm: a plug-in module in SLAM to convert sparse maps to dense maps, and super-resolution for LiDARs. Software and video demonstration are publicly available.
Vispi: Automatic Visual Perception and Interpretation of Chest X-rays
Jun 12, 2019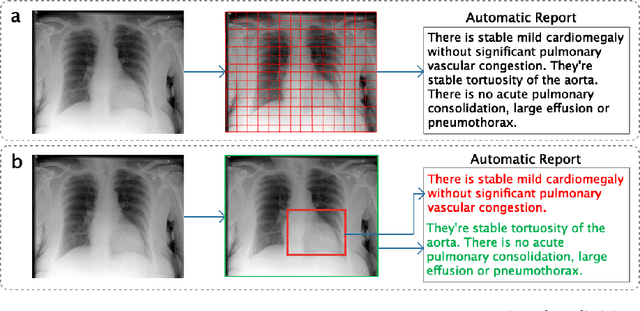
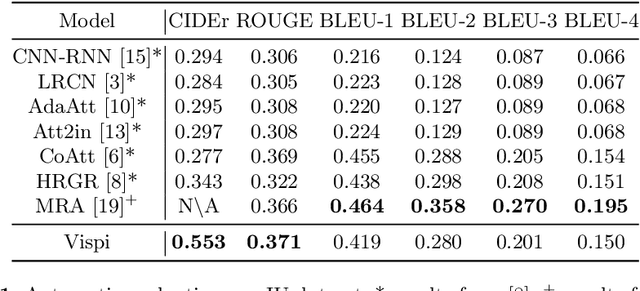
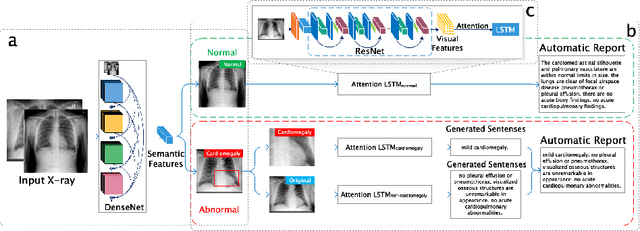
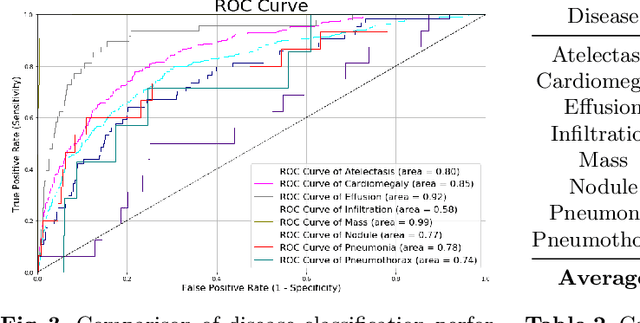
Medical imaging contains the essential information for rendering diagnostic and treatment decisions. Inspecting (visual perception) and interpreting image to generate a report are tedious clinical routines for a radiologist where automation is expected to greatly reduce the workload. Despite rapid development of natural image captioning, computer-aided medical image visual perception and interpretation remain a challenging task, largely due to the lack of high-quality annotated image-report pairs and tailor-made generative models for sufficient extraction and exploitation of localized semantic features, particularly those associated with abnormalities. To tackle these challenges, we present Vispi, an automatic medical image interpretation system, which first annotates an image via classifying and localizing common thoracic diseases with visual support and then followed by report generation from an attentive LSTM model. Analyzing an open IU X-ray dataset, we demonstrate a superior performance of Vispi in disease classification, localization and report generation using automatic performance evaluation metrics ROUGE and CIDEr.
Blind Inpainting of Large-scale Masks of Thin Structures with Adversarial and Reinforcement Learning
Dec 05, 2019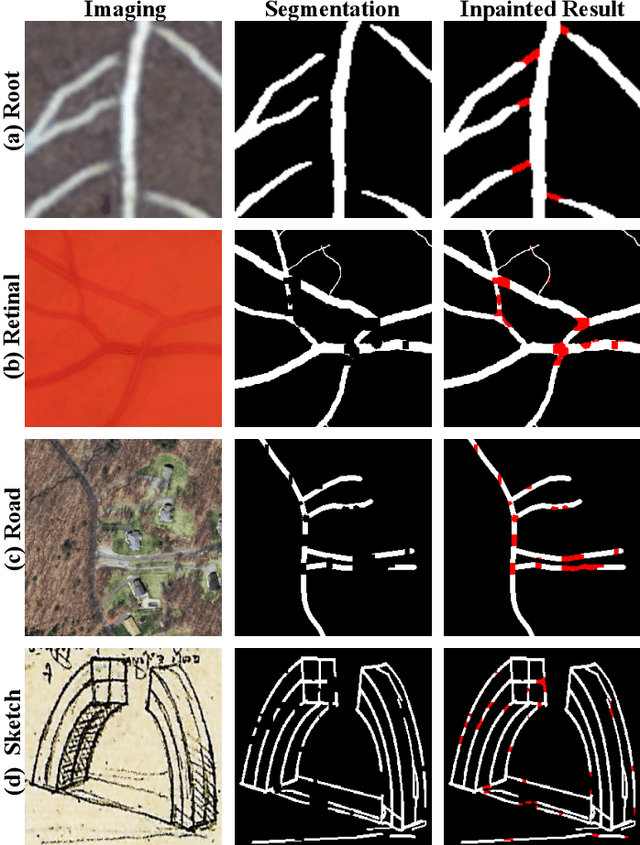
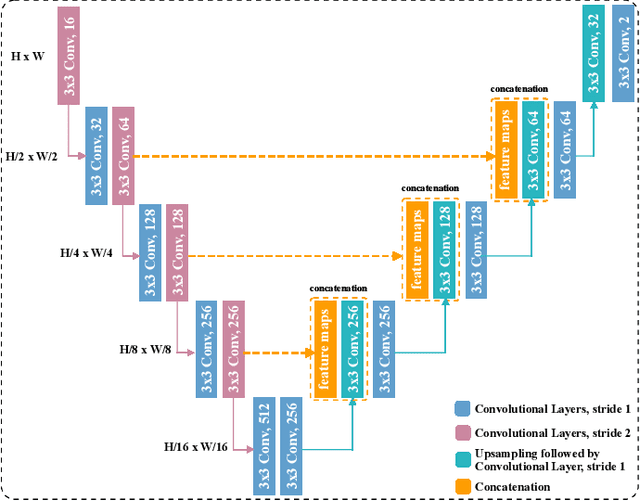
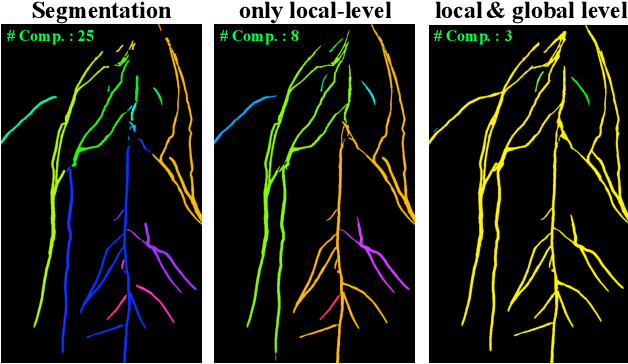
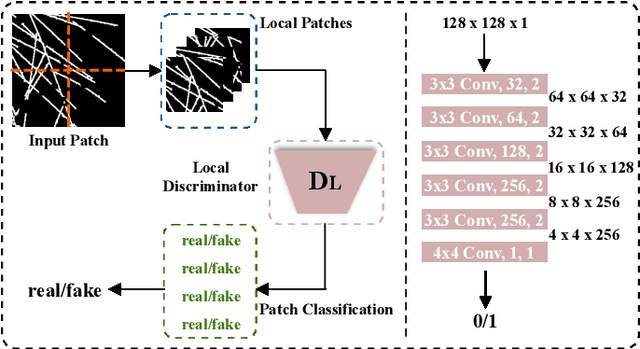
Several imaging applications (vessels, retina, plant roots, road networks from satellites) require the accurate segmentation of thin structures for subsequent analysis. Discontinuities (gaps) in the extracted foreground may hinder down-stream image-based analysis of biomarkers, organ structure and topology. In this paper, we propose a general post-processing technique to recover such gaps in large-scale segmentation masks. We cast this problem as a blind inpainting task, where the regions of missing lines in the segmentation masks are not known to the algorithm, which we solve with an adversarially trained neural network. One challenge of using large images is the memory capacity of current GPUs. The typical approach of dividing a large image into smaller patches to train the network does not guarantee global coherence of the reconstructed image that preserves structure and topology. We use adversarial training and reinforcement learning (Policy Gradient) to endow the model with both global context and local details. We evaluate our method in several datasets in medical imaging, plant science, and remote sensing. Our experiments demonstrate that our model produces the most realistic and complete inpainted results, outperforming other approaches. In a dedicated study on plant roots we find that our approach is also comparable to human performance. Implementation available at \url{https://github.com/Hhhhhhhhhhao/Thin-Structure-Inpainting}.
Relation Network for Person Re-identification
Nov 21, 2019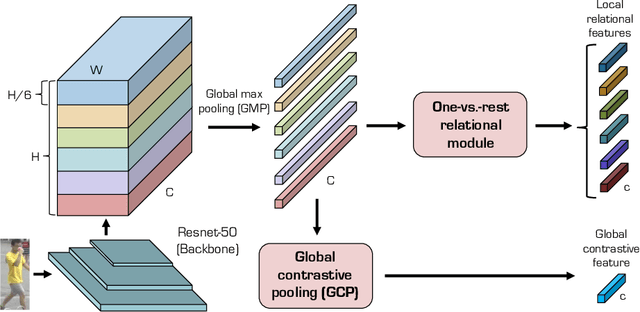
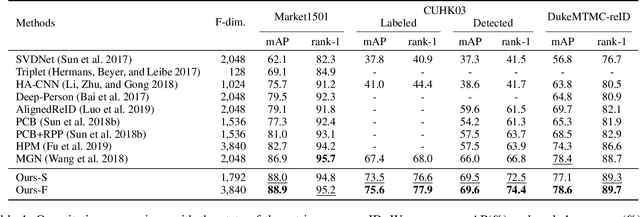
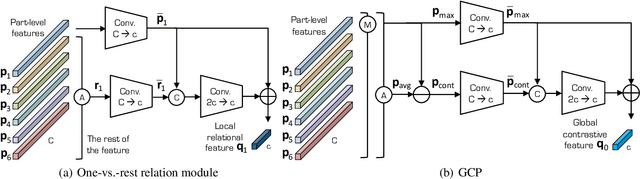
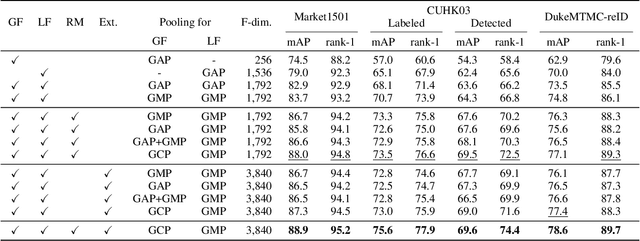
Person re-identification (reID) aims at retrieving an image of the person of interest from a set of images typically captured by multiple cameras. Recent reID methods have shown that exploiting local features describing body parts, together with a global feature of a person image itself, gives robust feature representations, even in the case of missing body parts. However, using the individual part-level features directly, without considering relations between body parts, confuses differentiating identities of different persons having similar attributes in corresponding parts. To address this issue, we propose a new relation network for person reID that considers relations between individual body parts and the rest of them. Our model makes a single part-level feature incorporate partial information of other body parts as well, supporting it to be more discriminative. We also introduce a global contrastive pooling (GCP) method to obtain a global feature of a person image. We propose to use contrastive features for GCP to complement conventional max and averaging pooling techniques. We show that our model outperforms the state of the art on the Market1501, DukeMTMC-reID and CUHK03 datasets, demonstrating the effectiveness of our approach on discriminative person representations.
Networks with pixels embedding: a method to improve noise resistance in images classification
May 24, 2020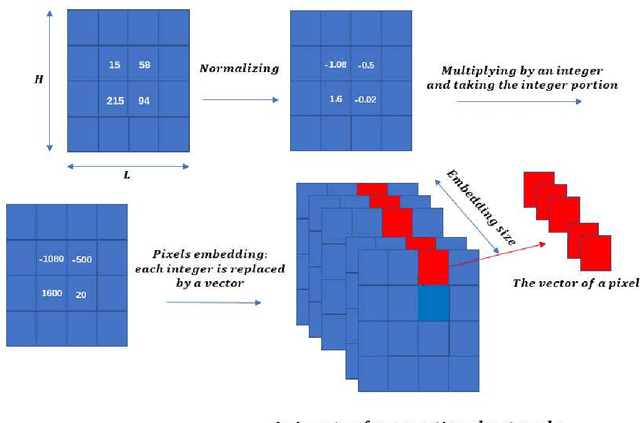
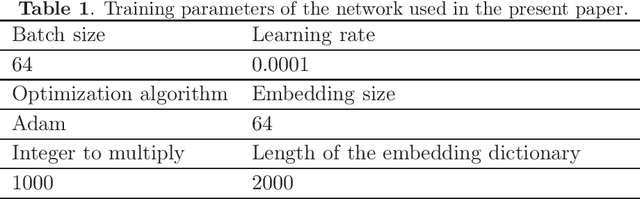
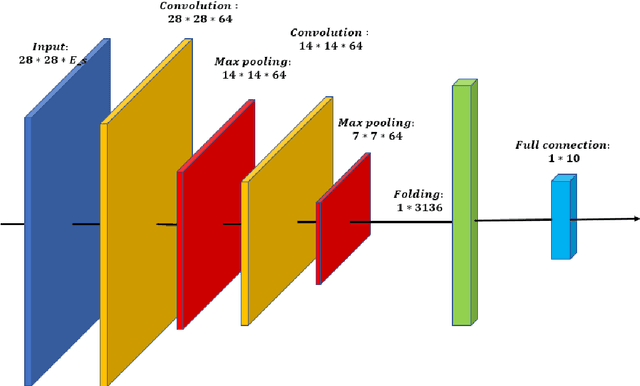
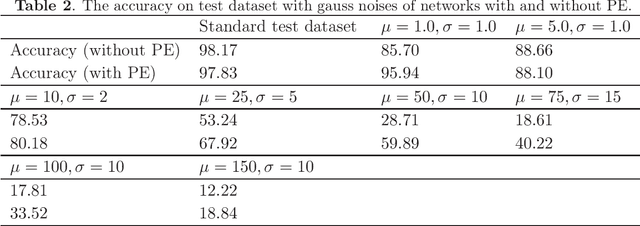
In the task of images classification, usually, the network is sensitive to noises. For example, an image of cat with noises might be misclassified as an ostrich. Conventionally, to overcome the problem of noises, one uses the technique of data enhancement, that is, to teach the network to distinguish noises by adding more images with noises in the training dataset. In this work, we provide a noise-resistance network in images classification by introducing a technique of pixels embedding. We test the network with pixels embedding, which is abbreviated as the network with PE, on the mnist database of handwritten digits. It shows that the network with PE outperforms the conventional network on images with noises. The technique of pixels embedding can be used in many tasks of images classification to improve noise resistance.
Texture Classification using Block Intensity and Gradient Difference (BIGD) Descriptor
Feb 04, 2020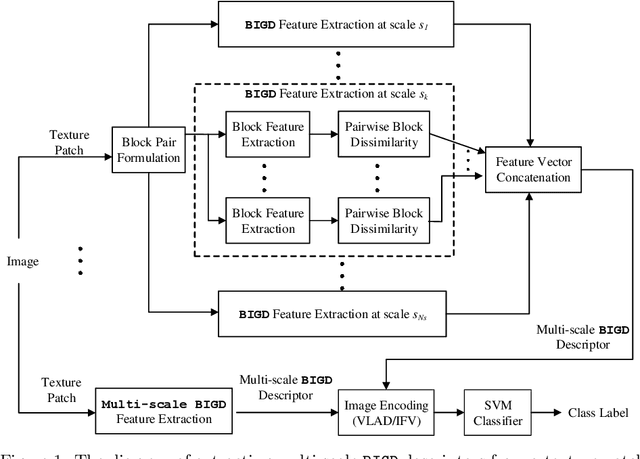
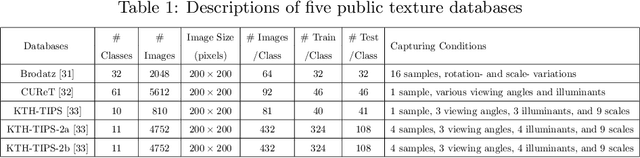
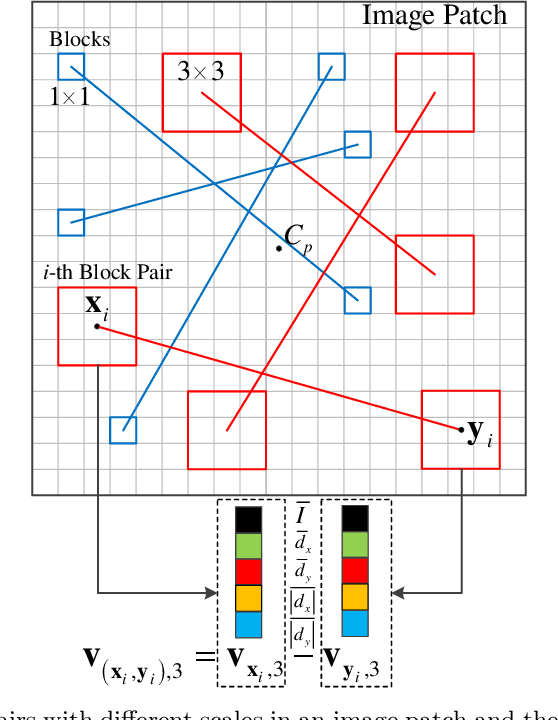
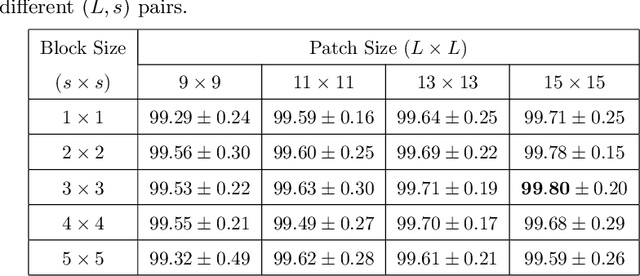
In this paper, we present an efficient and distinctive local descriptor, namely block intensity and gradient difference (BIGD). In an image patch, we randomly sample multi-scale block pairs and utilize the intensity and gradient differences of pairwise blocks to construct the local BIGD descriptor. The random sampling strategy and the multi-scale framework help BIGD descriptors capture the distinctive patterns of patches at different orientations and spatial granularity levels. We use vectors of locally aggregated descriptors (VLAD) or improved Fisher vector (IFV) to encode local BIGD descriptors into a full image descriptor, which is then fed into a linear support vector machine (SVM) classifier for texture classification. We compare the proposed descriptor with typical and state-of-the-art ones by evaluating their classification performance on five public texture data sets including Brodatz, CUReT, KTH-TIPS, and KTH-TIPS-2a and -2b. Experimental results show that the proposed BIGD descriptor with stronger discriminative power yields 0.12% ~ 6.43% higher classification accuracy than the state-of-the-art texture descriptor, dense microblock difference (DMD).
Interpretable Neuroevolutionary Models for Learning Non-Differentiable Functions and Programs
Jul 16, 2020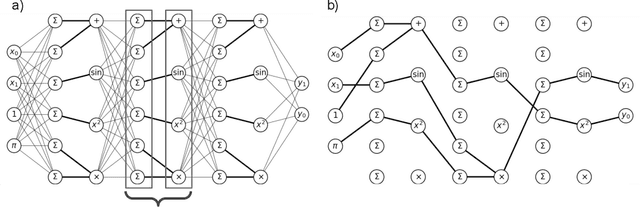
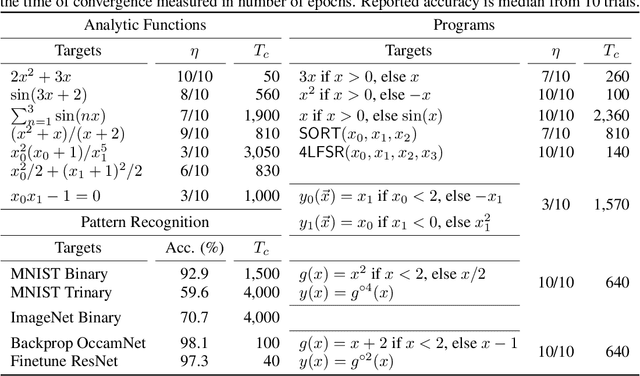
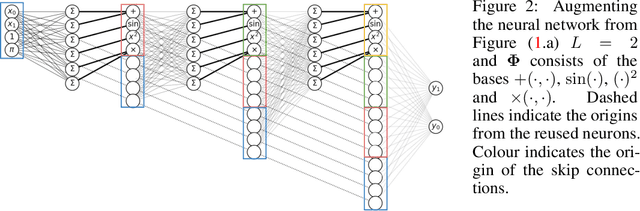
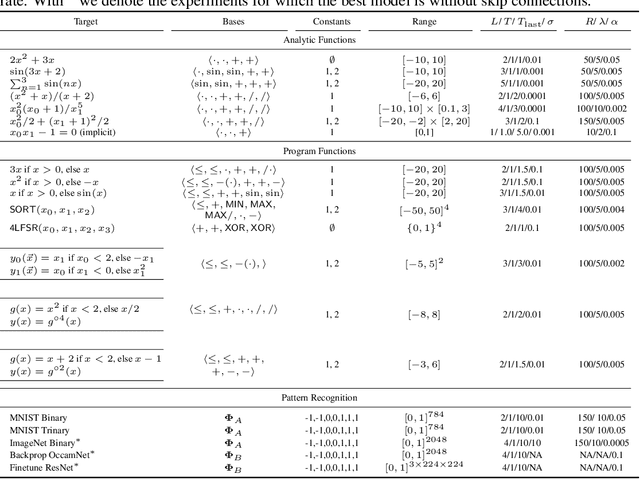
A key factor in the modern success of deep learning is the astonishing expressive power of neural networks. However, this comes at the cost of complex, black-boxed models that are unable to extrapolate beyond the domain of the training dataset, conflicting with goals of expressing physical laws or building human-readable programs. In this paper, we introduce OccamNet, a neural network model that can find interpretable, compact and sparse solutions for fitting data, \`{a} la Occam's razor. Our model defines a probability distribution over a non-differentiable function space, and we introduce an optimization method that samples functions and updates the weights based on cross-entropy matching in an evolutionary strategy: we train by biasing the probability mass towards better fitting solutions. We demonstrate that we can fit a variety of algorithms, ranging from simple analytic functions through recursive programs to even simple image classification. Our method takes minimal memory footprint, does not require AI accelerators for efficient training, fits complicated functions in minutes of training on a single CPU, and demonstrates significant performance gains when scaled on GPU. Our implementation, demonstrations and instructions for reproducing the experiments are available at https://github.com/AllanSCosta/occam-net.