 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Pixel-Distribution Prior with Wider Convolution for Image Denoising
Jul 28, 2017
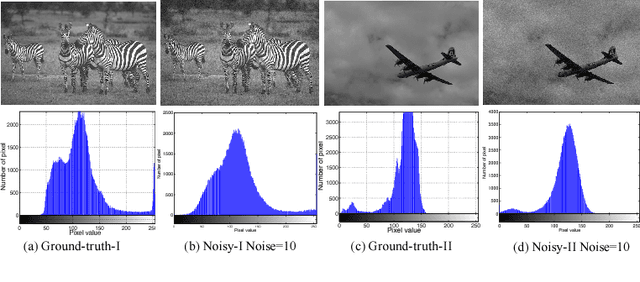
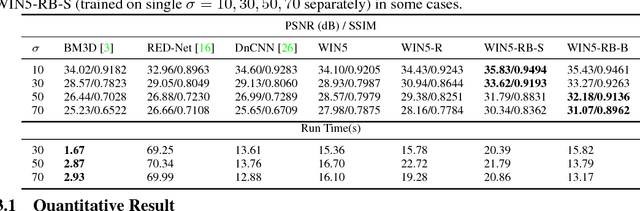
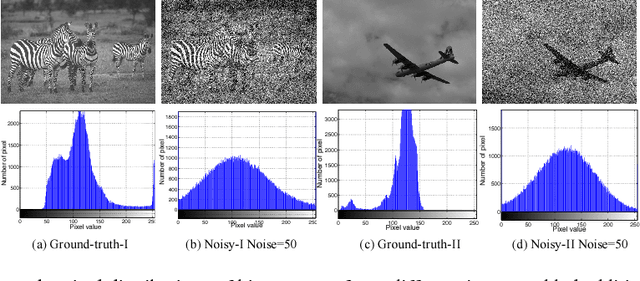
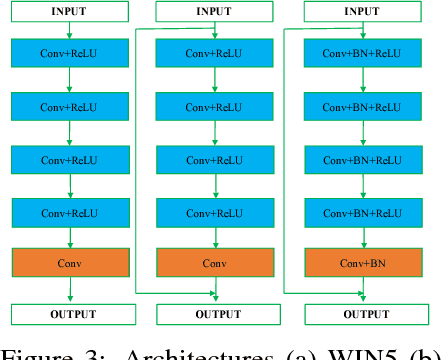
In this work, we explore an innovative strategy for image denoising by using convolutional neural networks (CNN) to learn pixel-distribution from noisy data. By increasing CNN's width with large reception fields and more channels in each layer, CNNs can reveal the ability to learn pixel-distribution, which is a prior existing in many different types of noise. The key to our approach is a discovery that wider CNNs tends to learn the pixel-distribution features, which provides the probability of that inference-mapping primarily relies on the priors instead of deeper CNNs with more stacked nonlinear layers. We evaluate our work: Wide inference Networks (WIN) on additive white Gaussian noise (AWGN) and demonstrate that by learning the pixel-distribution in images, WIN-based network consistently achieves significantly better performance than current state-of-the-art deep CNN-based methods in both quantitative and visual evaluations. \textit{Code and models are available at \url{https://github.com/cswin/WIN}}.
Towards an Intelligent Microscope: adaptively learned illumination for optimal sample classification
Oct 22, 2019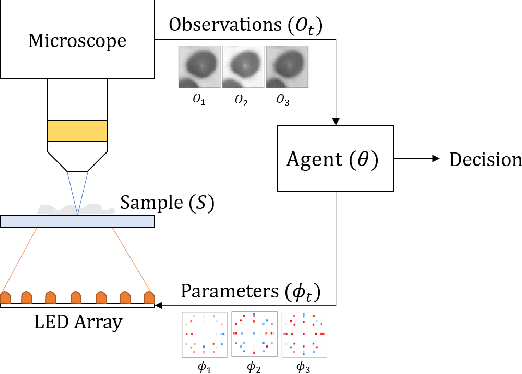
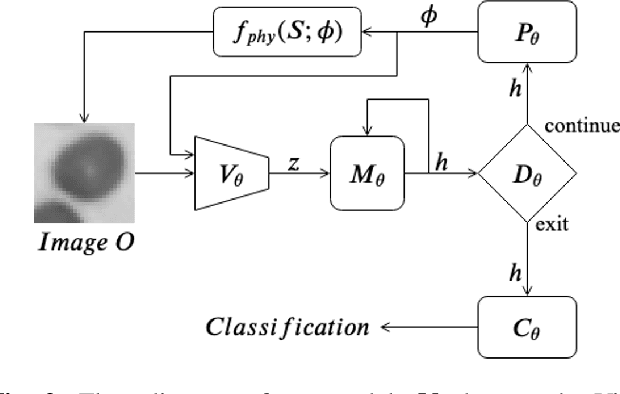
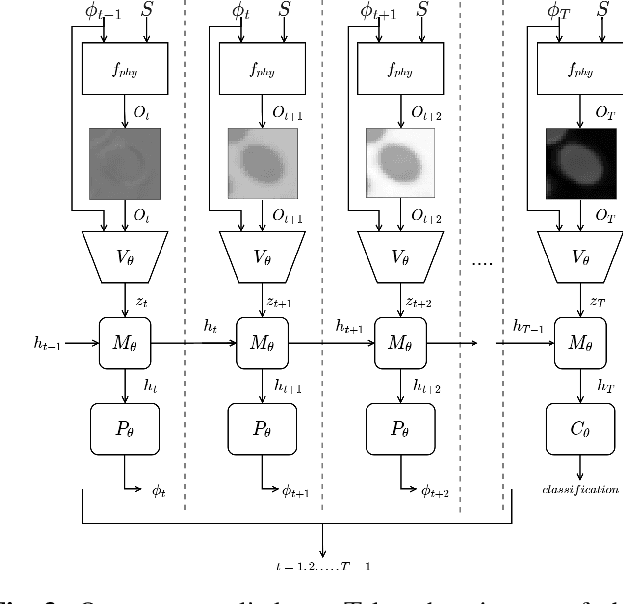
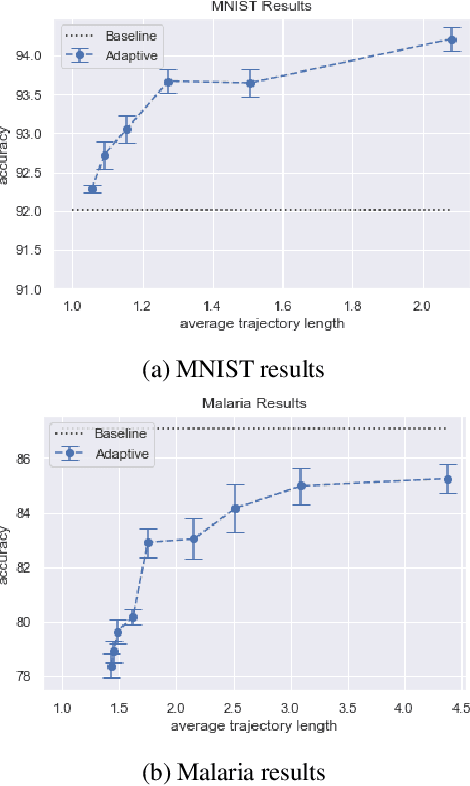
Recent machine learning techniques have dramatically changed how we process digital images. However, the way in which we capture images is still largely driven by human intuition and experience. This restriction is in part due to the many available degrees of freedom that alter the image acquisition process (lens focus, exposure, filtering, etc). Here we focus on one such degree of freedom - illumination within a microscope - which can drastically alter information captured by the image sensor. We present a reinforcement learning system that adaptively explores optimal patterns to illuminate specimens for immediate classification. The agent uses a recurrent latent space to encode a large set of variably-illuminated samples and illumination patterns. We train our agent using a reward that balances classification confidence with image acquisition cost. By synthesizing knowledge over multiple snapshots, the agent can classify on the basis of all previous images with higher accuracy than from naively illuminated images, thus demonstrating a smarter way to physically capture task-specific information.
Correcting Data Imbalance for Semi-Supervised Covid-19 Detection Using X-ray Chest Images
Aug 20, 2020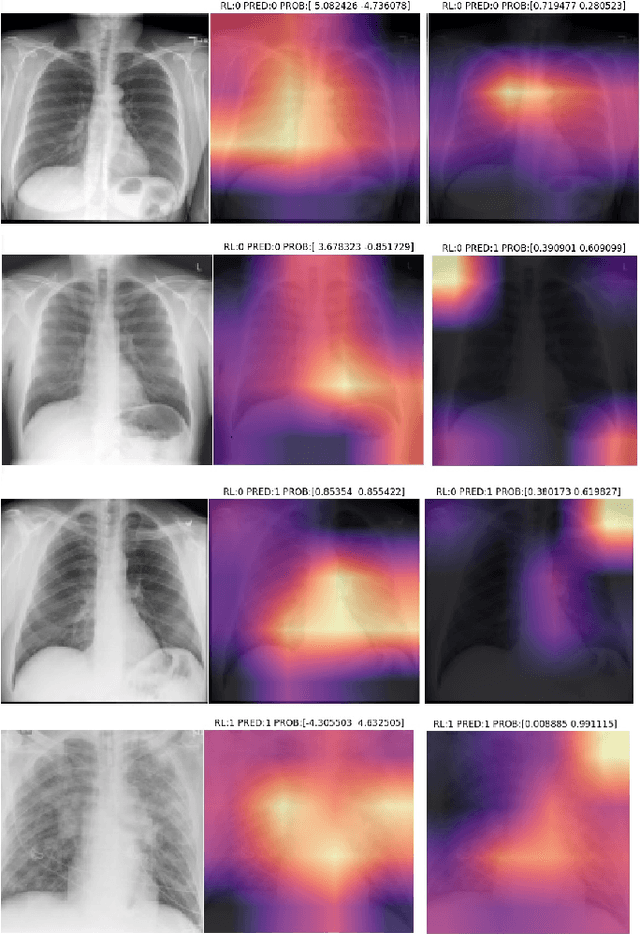
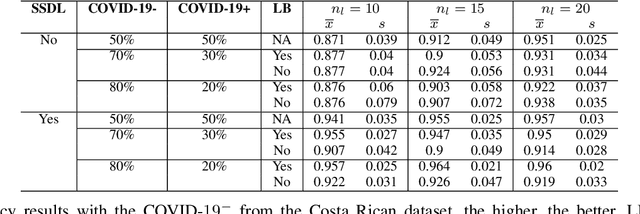
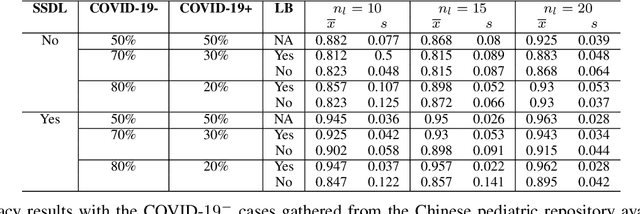
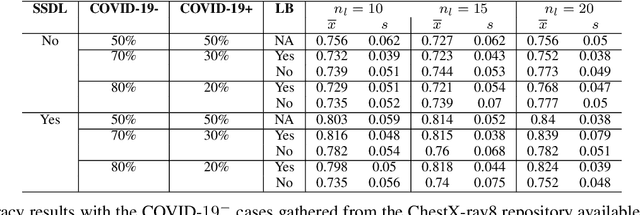
The Corona Virus (COVID-19) is an internationalpandemic that has quickly propagated throughout the world. The application of deep learning for image classification of chest X-ray images of Covid-19 patients, could become a novel pre-diagnostic detection methodology. However, deep learning architectures require large labelled datasets. This is often a limitation when the subject of research is relatively new as in the case of the virus outbreak, where dealing with small labelled datasets is a challenge. Moreover, in the context of a new highly infectious disease, the datasets are also highly imbalanced,with few observations from positive cases of the new disease. In this work we evaluate the performance of the semi-supervised deep learning architecture known as MixMatch using a very limited number of labelled observations and highly imbalanced labelled dataset. We propose a simple approach for correcting data imbalance, re-weight each observationin the loss function, giving a higher weight to the observationscorresponding to the under-represented class. For unlabelled observations, we propose the usage of the pseudo and augmentedlabels calculated by MixMatch to choose the appropriate weight. The MixMatch method combined with the proposed pseudo-label based balance correction improved classification accuracy by up to 10%, with respect to the non balanced MixMatch algorithm, with statistical significance. We tested our proposed approach with several available datasets using 10, 15 and 20 labelledobservations. Additionally, a new dataset is included among thetested datasets, composed of chest X-ray images of Costa Rican adult patients
TopoAL: An Adversarial Learning Approach for Topology-Aware Road Segmentation
Jul 17, 2020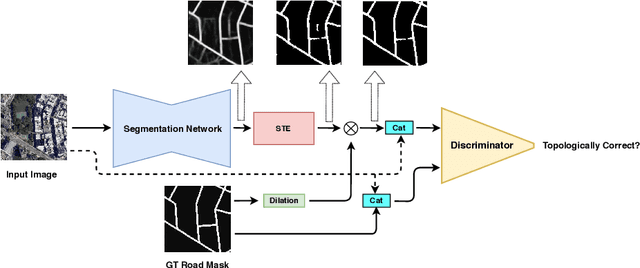
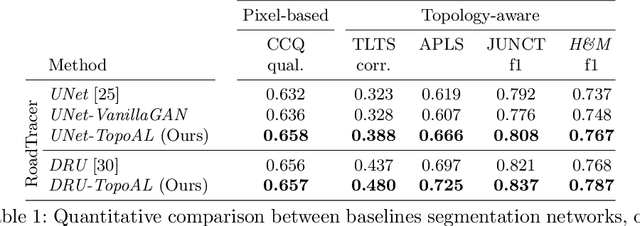

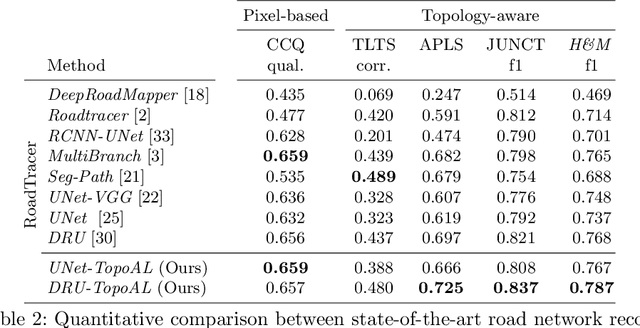
Most state-of-the-art approaches to road extraction from aerial images rely on a CNN trained to label road pixels as foreground and remainder of the image as background. The CNN is usually trained by minimizing pixel-wise losses, which is less than ideal to produce binary masks that preserve the road network's global connectivity. To address this issue, we introduce an Adversarial Learning (AL) strategy tailored for our purposes. A naive one would treat the segmentation network as a generator and would feed its output along with ground-truth segmentations to a discriminator. It would then train the generator and discriminator jointly. We will show that this is not enough because it does not capture the fact that most errors are local and need to be treated as such. Instead, we use a more sophisticated discriminator that returns a label pyramid describing what portions of the road network are correct at several different scales. This discriminator and the structured labels it returns are what gives our approach its edge and we will show that it outperforms state-of-the-art ones on the challenging RoadTracer dataset.
A Neuro-AI Interface for Evaluating Generative Adversarial Networks
Mar 05, 2020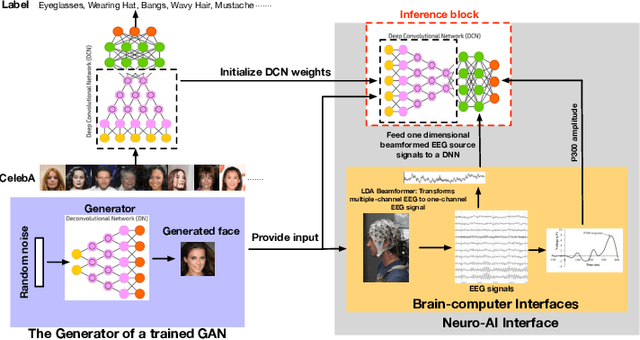
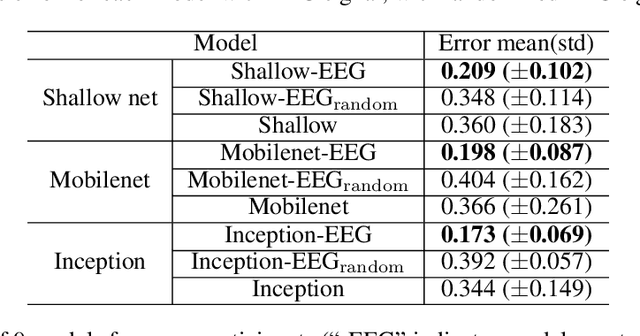
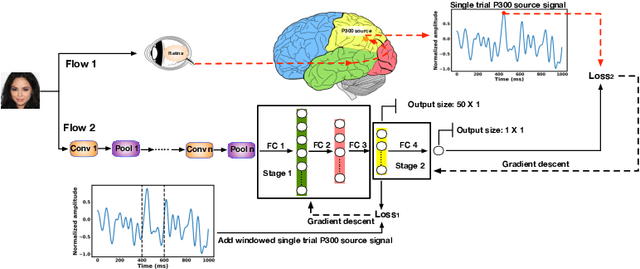
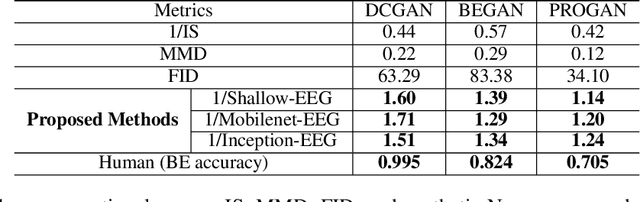
Generative adversarial networks (GANs) are increasingly attracting attention in the computer vision, natural language processing, speech synthesis and similar domains. However, evaluating the performance of GANs is still an open and challenging problem. Existing evaluation metrics primarily measure the dissimilarity between real and generated images using automated statistical methods. They often require large sample sizes for evaluation and do not directly reflect human perception of image quality. In this work, we introduce an evaluation metric called Neuroscore, for evaluating the performance of GANs, that more directly reflects psychoperceptual image quality through the utilization of brain signals. Our results show that Neuroscore has superior performance to the current evaluation metrics in that: (1) It is more consistent with human judgment; (2) The evaluation process needs much smaller numbers of samples; and (3) It is able to rank the quality of images on a per GAN basis. A convolutional neural network (CNN) based neuro-AI interface is proposed to predict Neuroscore from GAN-generated images directly without the need for neural responses. Importantly, we show that including neural responses during the training phase of the network can significantly improve the prediction capability of the proposed model. Codes and data can be referred at this link: https://github.com/villawang/Neuro-AI-Interface.
Pose Augmentation: Class-agnostic Object Pose Transformation for Object Recognition
Mar 19, 2020


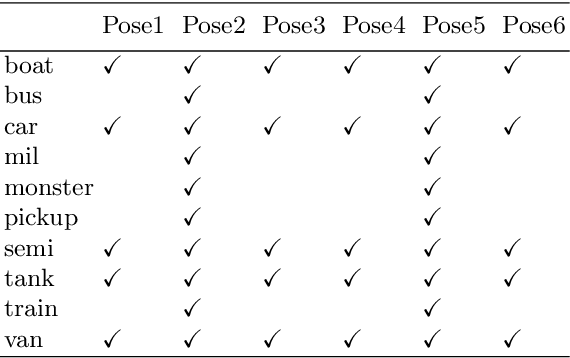
Object pose increases interclass object variance which makes object recognition from 2D images harder. To render a classifier robust to pose variations, most deep neural networks try to eliminate the influence of pose by using large datasets with many poses for each class. Here, we propose a different approach: a class-agnostic object pose transformation network (OPT-Net) can transform an image along 3D yaw and pitch axes to synthesize additional poses continuously. Synthesized images lead to better training of an object classifier. We design a novel eliminate-add structure to explicitly disentangle pose from object identity: first eliminate pose information of the input image and then add target pose information (regularized as continuous variables) to synthesize any target pose. We trained OPT-Net on images of toy vehicles shot on a turntable from the iLab-20M dataset. After training on unbalanced discrete poses (5 classes with 6 poses per object instance, plus 5 classes with only 2 poses), we show that OPT-Net can synthesize balanced continuous new poses along yaw and pitch axes with high quality. Training a ResNet-18 classifier with original plus synthesized poses improves mAP accuracy by 9% overtraining on original poses only. Further, the pre-trained OPT-Net can generalize to new object classes, which we demonstrate on both iLab-20M and RGB-D. We also show that the learned features can generalize to ImageNet.
Cross-Identity Motion Transfer for Arbitrary Objects through Pose-Attentive Video Reassembling
Jul 17, 2020
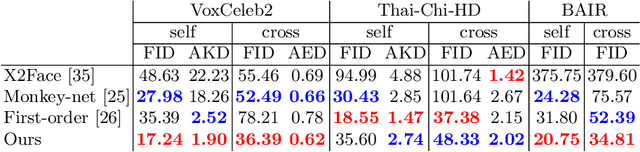
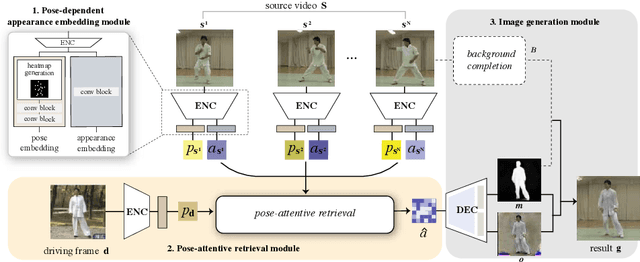
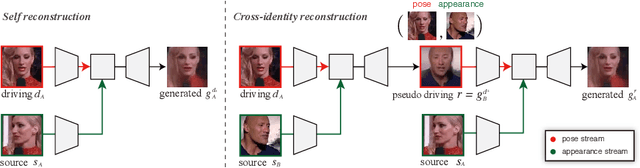
We propose an attention-based networks for transferring motions between arbitrary objects. Given a source image(s) and a driving video, our networks animate the subject in the source images according to the motion in the driving video. In our attention mechanism, dense similarities between the learned keypoints in the source and the driving images are computed in order to retrieve the appearance information from the source images. Taking a different approach from the well-studied warping based models, our attention-based model has several advantages. By reassembling non-locally searched pieces from the source contents, our approach can produce more realistic outputs. Furthermore, our system can make use of multiple observations of the source appearance (e.g. front and sides of faces) to make the results more accurate. To reduce the training-testing discrepancy of the self-supervised learning, a novel cross-identity training scheme is additionally introduced. With the training scheme, our networks is trained to transfer motions between different subjects, as in the real testing scenario. Experimental results validate that our method produces visually pleasing results in various object domains, showing better performances compared to previous works.
Embedding Expansion: Augmentation in Embedding Space for Deep Metric Learning
Mar 05, 2020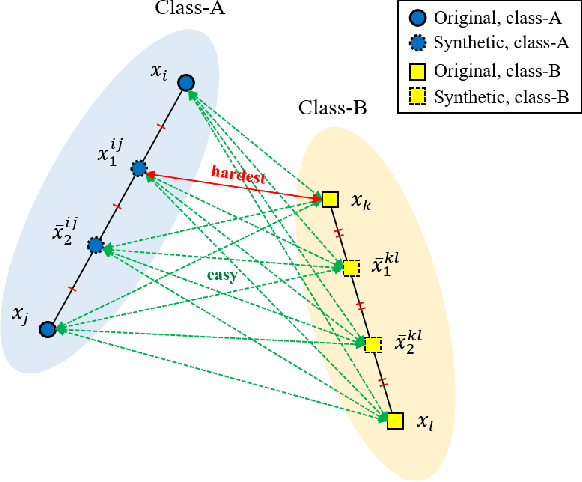

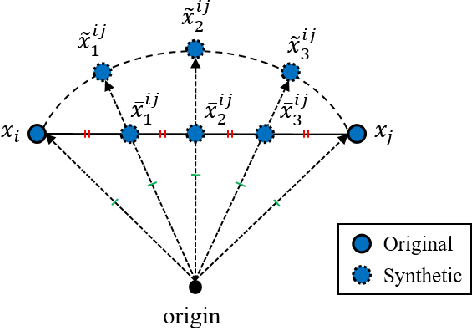
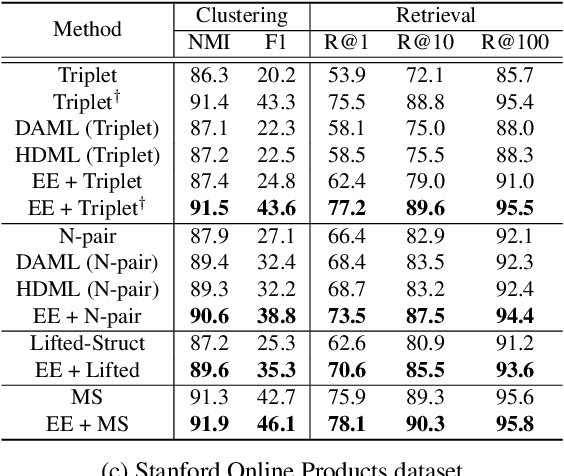
Learning the distance metric between pairs of samples has been studied for image retrieval and clustering. With the remarkable success of pair-based metric learning losses, recent works have proposed the use of generated synthetic points on metric learning losses for augmentation and generalization. However, these methods require additional generative networks along with the main network, which can lead to a larger model size, slower training speed, and harder optimization. Meanwhile, post-processing techniques, such as query expansion and database augmentation, have proposed the combination of feature points to obtain additional semantic information. In this paper, inspired by query expansion and database augmentation, we propose an augmentation method in an embedding space for pair-based metric learning losses, called embedding expansion. The proposed method generates synthetic points containing augmented information by a combination of feature points and performs hard negative pair mining to learn with the most informative feature representations. Because of its simplicity and flexibility, it can be used for existing metric learning losses without affecting model size, training speed, or optimization difficulty. Finally, the combination of embedding expansion and representative metric learning losses outperforms the state-of-the-art losses and previous sample generation methods in both image retrieval and clustering tasks. The implementation will be publicly available.
System to Integrate Fairness Transparently: An Industry Approach
Jun 10, 2020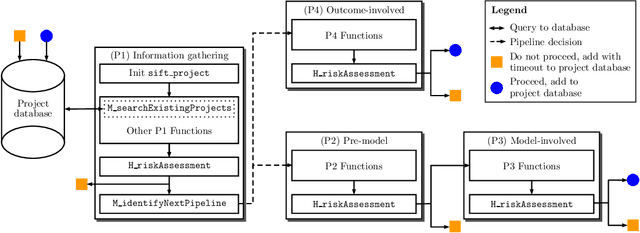
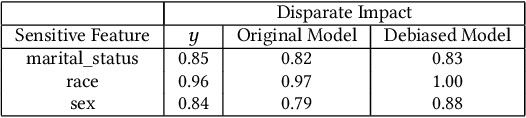
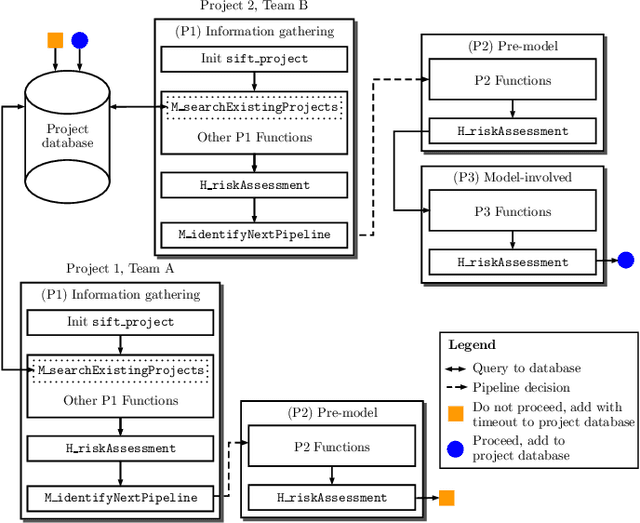
There have been significant research efforts to address the issue of unintentional bias in Machine Learning (ML). Many well-known companies have dealt with the fallout after the deployment of their products due to this issue. In an industrial context, enterprises have large-scale ML solutions for a broad class of use cases deployed for different swaths of customers. Trading off the cost of detecting and mitigating bias across this landscape over the lifetime of each use case against the risk of impact to the brand image is a key consideration. We propose a framework for industrial uses that addresses their methodological and mechanization needs. Our approach benefits from prior experience handling security and privacy concerns as well as past internal ML projects. Through significant reuse of bias handling ability at every stage in the ML development lifecycle to guide users we can lower overall costs of reducing bias.
Shop The Look: Building a Large Scale Visual Shopping System at Pinterest
Jun 18, 2020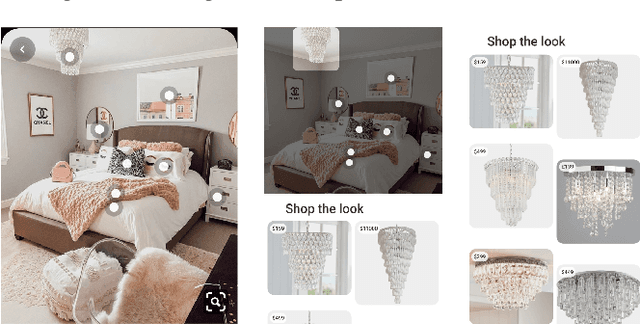

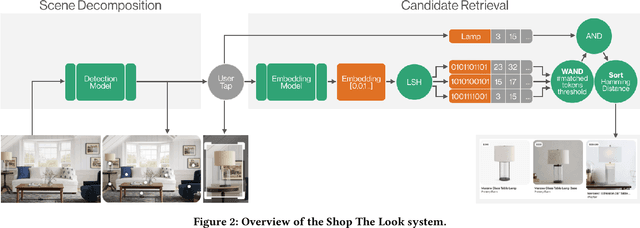
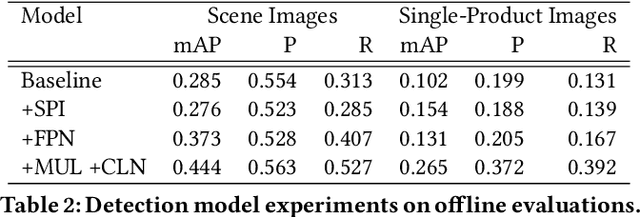
As online content becomes ever more visual, the demand for searching by visual queries grows correspondingly stronger. Shop The Look is an online shopping discovery service at Pinterest, leveraging visual search to enable users to find and buy products within an image. In this work, we provide a holistic view of how we built Shop The Look, a shopping oriented visual search system, along with lessons learned from addressing shopping needs. We discuss topics including core technology across object detection and visual embeddings, serving infrastructure for realtime inference, and data labeling methodology for training/evaluation data collection and human evaluation. The user-facing impacts of our system design choices are measured through offline evaluations, human relevance judgements, and online A/B experiments. The collective improvements amount to cumulative relative gains of over 160% in end-to-end human relevance judgements and over 80% in engagement. Shop The Look is deployed in production at Pinterest.