 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sequential Adversarial Learning for Self-Supervised Deep Visual Odometry
Aug 23, 2019
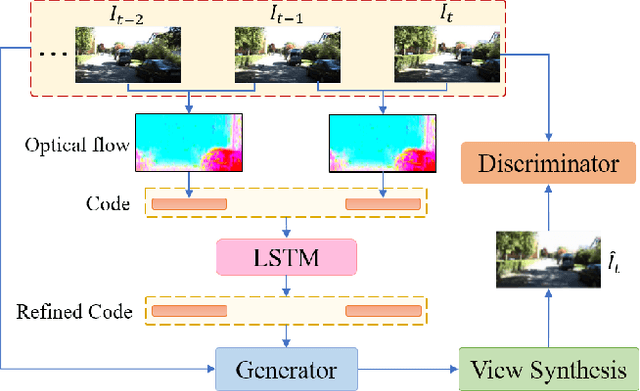
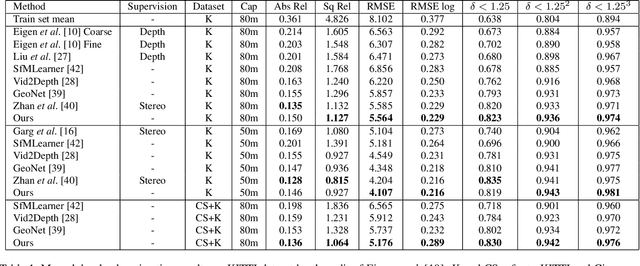
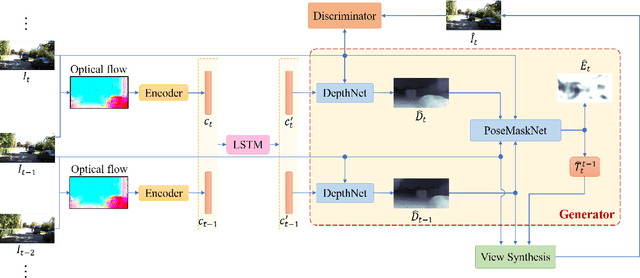
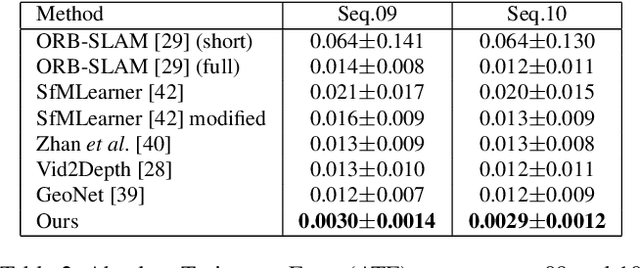
We propose a self-supervised learning framework for visual odometry (VO) that incorporates correlation of consecutive frames and takes advantage of adversarial learning. Previous methods tackle self-supervised VO as a local structure from motion (SfM) problem that recovers depth from single image and relative poses from image pairs by minimizing photometric loss between warped and captured images. As single-view depth estimation is an ill-posed problem, and photometric loss is incapable of discriminating distortion artifacts of warped images, the estimated depth is vague and pose is inaccurate. In contrast to previous methods, our framework learns a compact representation of frame-to-frame correlation, which is updated by incorporating sequential information. The updated representation is used for depth estimation. Besides, we tackle VO as a self-supervised image generation task and take advantage of Generative Adversarial Networks (GAN). The generator learns to estimate depth and pose to generate a warped target image. The discriminator evaluates the quality of generated image with high-level structural perception that overcomes the problem of pixel-wise loss in previous methods. Experiments on KITTI and Cityscapes datasets show that our method obtains more accurate depth with details preserved and predicted pose outperforms state-of-the-art self-supervised methods significantly.
Generalization by Recognizing Confusion
Jun 13, 2020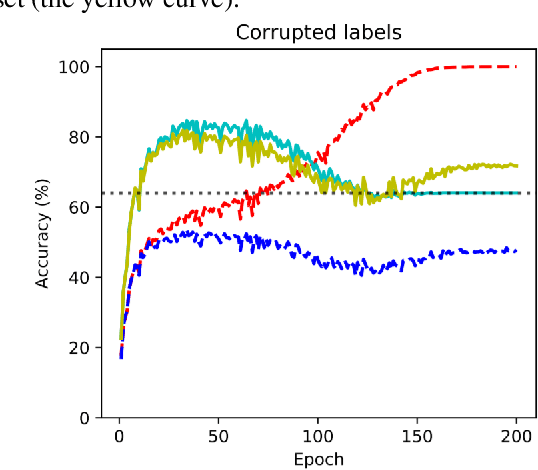
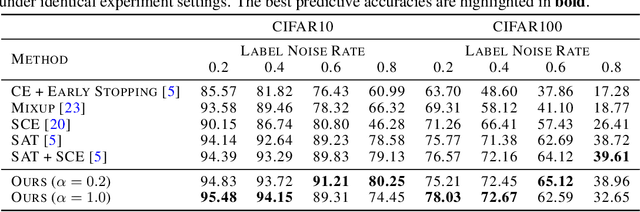
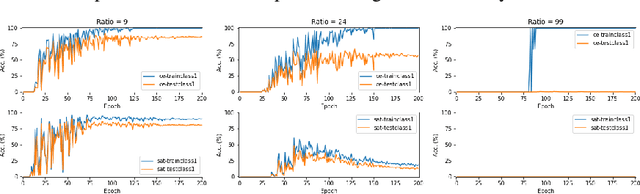

A recently-proposed technique called self-adaptive training augments modern neural networks by allowing them to adjust training labels on the fly, to avoid overfitting to samples that may be mislabeled or otherwise non-representative. By combining the self-adaptive objective with mixup, we further improve the accuracy of self-adaptive models for image recognition; the resulting classifier obtains state-of-the-art accuracies on datasets corrupted with label noise. Robustness to label noise implies a lower generalization gap; thus, our approach also leads to improved generalizability. We find evidence that the Rademacher complexity of these algorithms is low, suggesting a new path towards provable generalization for this type of deep learning model. Last, we highlight a novel connection between difficulties accounting for rare classes and robustness under noise, as rare classes are in a sense indistinguishable from label noise. Our code can be found at https://github.com/Tuxianeer/generalizationconfusion.
TENet: Triple Excitation Network for Video Salient Object Detection
Jul 20, 2020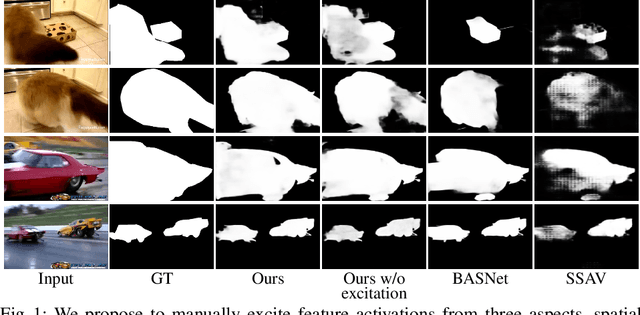
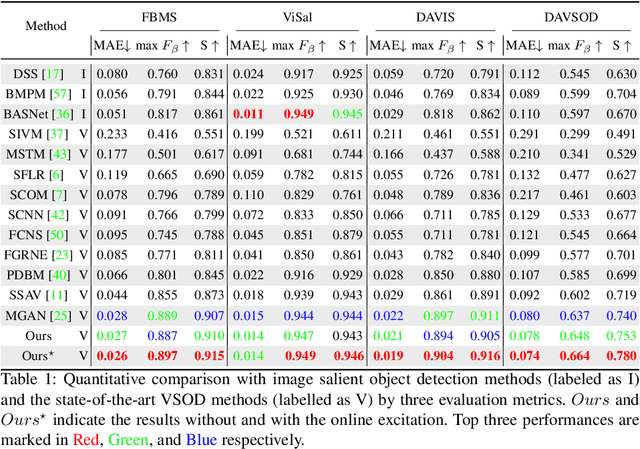
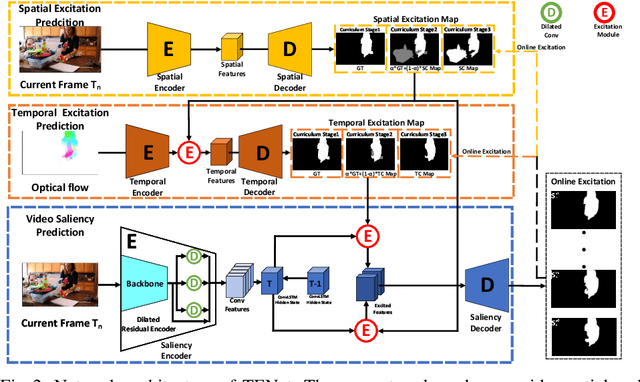
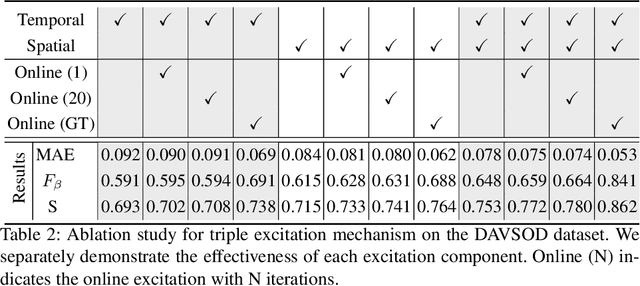
In this paper, we propose a simple yet effective approach, named Triple Excitation Network, to reinforce the training of video salient object detection (VSOD) from three aspects, spatial, temporal, and online excitations. These excitation mechanisms are designed following the spirit of curriculum learning and aim to reduce learning ambiguities at the beginning of training by selectively exciting feature activations using ground truth. Then we gradually reduce the weight of ground truth excitations by a curriculum rate and replace it by a curriculum complementary map for better and faster convergence. In particular, the spatial excitation strengthens feature activations for clear object boundaries, while the temporal excitation imposes motions to emphasize spatio-temporal salient regions. Spatial and temporal excitations can combat the saliency shifting problem and conflict between spatial and temporal features of VSOD. Furthermore, our semi-curriculum learning design enables the first online refinement strategy for VSOD, which allows exciting and boosting saliency responses during testing without re-training. The proposed triple excitations can easily plug in different VSOD methods. Extensive experiments show the effectiveness of all three excitation methods and the proposed method outperforms state-of-the-art image and video salient object detection methods.
Robust Technique for Representative Volume Element Identification in Noisy Microtomography Images of Porous Materials Based on Pores Morphology and Their Spatial Distribution
Jul 06, 2020
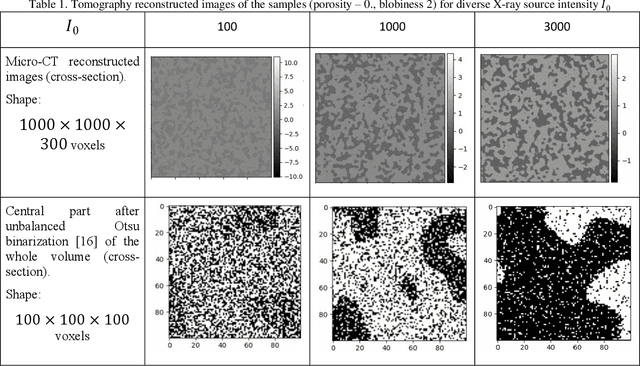
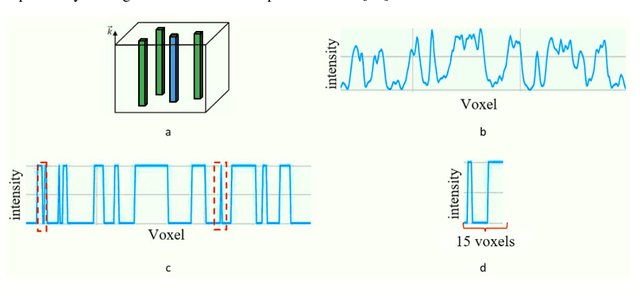
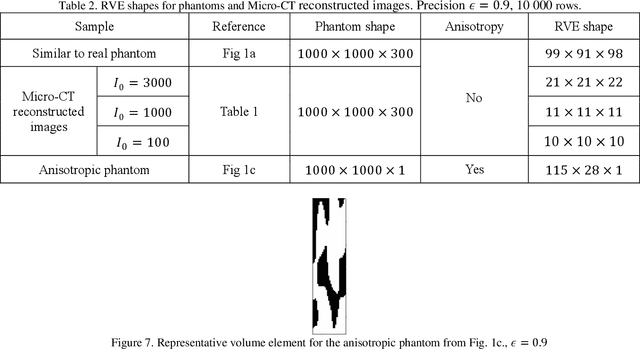
Microtomography is a powerful method of materials investigation. It enables to obtain physical properties of porous media non-destructively that is useful in studies. One of the application ways is a calculation of porosity, pore sizes, surface area, and other parameters of metal-ceramic (cermet) membranes which are widely spread in the filtration industry. The microtomography approach is efficient because all of those parameters are calculated simultaneously in contrast to the conventional techniques. Nevertheless, the calculations on Micro-CT reconstructed images appear to be time-consuming, consequently representative volume element should be chosen to speed them up. This research sheds light on representative elementary volume identification without consideration of any physical parameters such as porosity, etc. Thus, the volume element could be found even in noised and grayscale images. The proposed method is flexible and does not overestimate the volume size in the case of anisotropic samples. The obtained volume element could be used for computations of the domain's physical characteristics if the image is filtered and binarized, or for selections of optimal filtering parameters for denoising procedure.
Online Representation Learning with Single and Multi-layer Hebbian Networks for Image Classification
Jan 29, 2018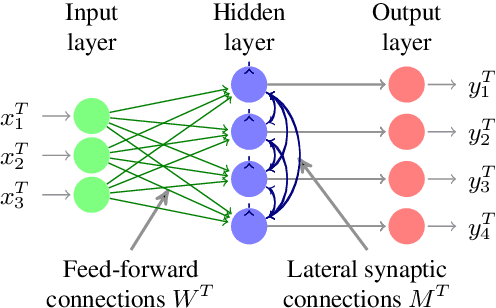

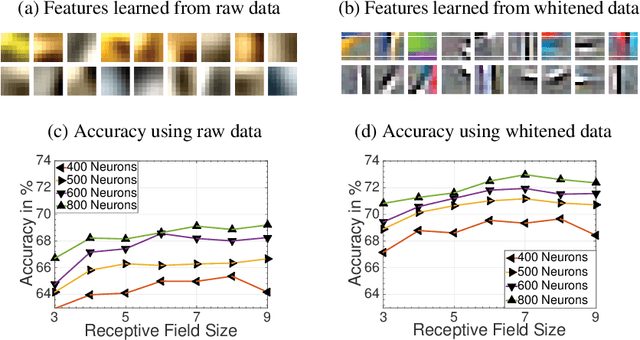
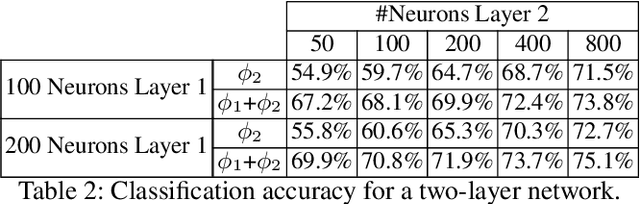
Unsupervised learning permits the development of algorithms that are able to adapt to a variety of different data sets using the same underlying rules thanks to the autonomous discovery of discriminating features during training. Recently, a new class of Hebbian-like and local unsupervised learning rules for neural networks have been developed that minimise a similarity matching cost-function. These have been shown to perform sparse representation learning. This study tests the effectiveness of one such learning rule for learning features from images. The rule implemented is derived from a nonnegative classical multidimensional scaling cost-function, and is applied to both single and multi-layer architectures. The features learned by the algorithm are then used as input to an SVM to test their effectiveness in classification on the established CIFAR-10 image dataset. The algorithm performs well in comparison to other unsupervised learning algorithms and multi-layer networks, thus suggesting its validity in the design of a new class of compact, online learning networks.
Accurate 3D Reconstruction of Dynamic Scenes from Monocular Image Sequences with Severe Occlusions
Dec 20, 2017
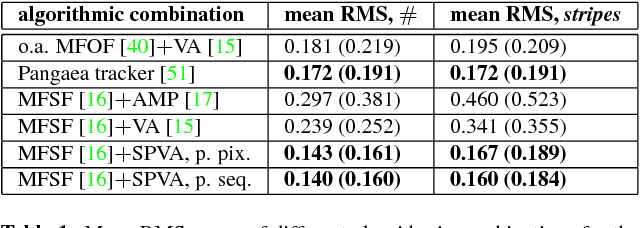
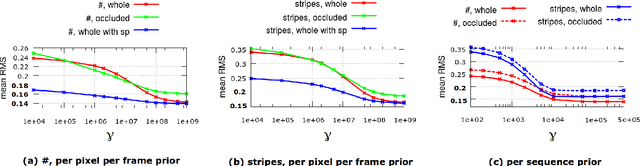

The paper introduces an accurate solution to dense orthographic Non-Rigid Structure from Motion (NRSfM) in scenarios with severe occlusions or, likewise, inaccurate correspondences. We integrate a shape prior term into variational optimisation framework. It allows to penalize irregularities of the time-varying structure on the per-pixel level if correspondence quality indicator such as an occlusion tensor is available. We make a realistic assumption that several non-occluded views of the scene are sufficient to estimate an initial shape prior, though the entire observed scene may exhibit non-rigid deformations. Experiments on synthetic and real image data show that the proposed framework significantly outperforms state of the art methods for correspondence establishment in combination with the state of the art NRSfM methods. Together with the profound insights into optimisation methods, implementation details for heterogeneous platforms are provided.
NormGrad: Finding the Pixels that Matter for Training
Oct 19, 2019

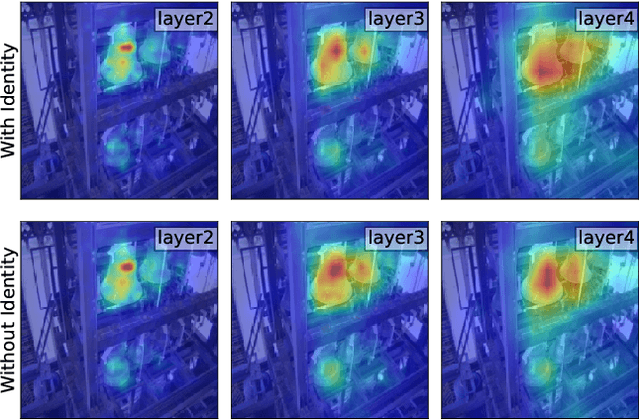
The different families of saliency methods, either based on contrastive signals, closed-form formulas mixing gradients with activations or on perturbation masks, all focus on which parts of an image are responsible for the model's inference. In this paper, we are rather interested by the locations of an image that contribute to the model's training. First, we propose a principled attribution method that we extract from the summation formula used to compute the gradient of the weights for a 1x1 convolutional layer. The resulting formula is fast to compute and can used throughout the network, allowing us to efficiently produce fined-grained importance maps. We will show how to extend it in order to compute saliency maps at any targeted point within the network. Secondly, to make the attribution really specific to the training of the model, we introduce a meta-learning approach for saliency methods by considering an inner optimisation step within the loss. This way, we do not aim at identifying the parts of an image that contribute to the model's output but rather the locations that are responsible for the good training of the model on this image. Conversely, we also show that a similar meta-learning approach can be used to extract the adversarial locations which can lead to the degradation of the model.
Monocular 3D Detection with Geometric Constraints Embedding and Semi-supervised Training
Sep 02, 2020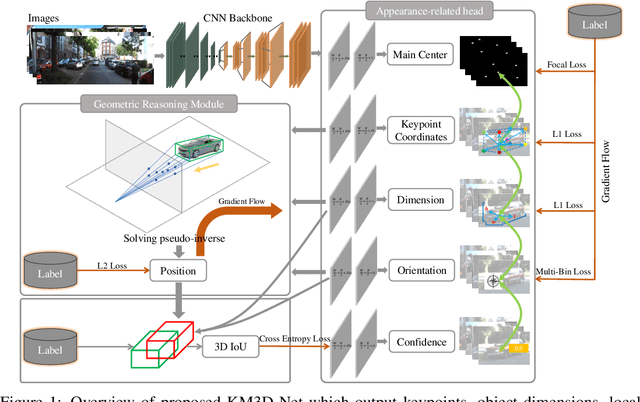
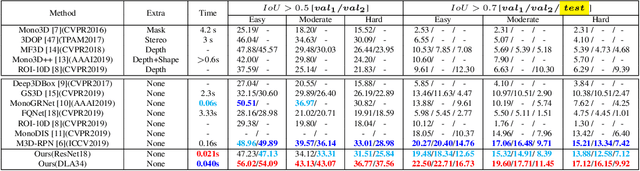
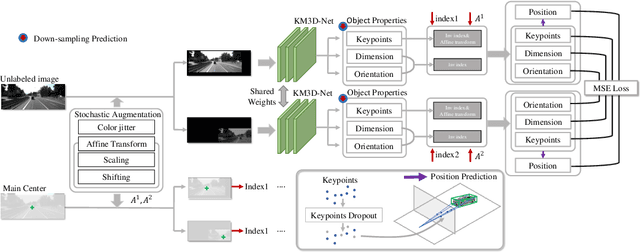
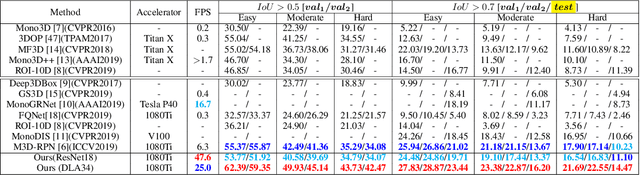
In this work, we propose a novel single-shot and keypoints-based framework for monocular 3D objects detection using only RGB images, called KM3D-Net. We design a fully convolutional model to predict object keypoints, dimension, and orientation, and then combine these estimations with perspective geometry constraints to compute position attribute. Further, we reformulate the geometric constraints as a differentiable version and embed it into the network to reduce running time while maintaining the consistency of model outputs in an end-to-end fashion. Benefiting from this simple structure, we then propose an effective semi-supervised training strategy for the setting where labeled training data is scarce. In this strategy, we enforce a consensus prediction of two shared-weights KM3D-Net for the same unlabeled image under different input augmentation conditions and network regularization. In particular, we unify the coordinate-dependent augmentations as the affine transformation for the differential recovering position of objects and propose a keypoints-dropout module for the network regularization. Our model only requires RGB images without synthetic data, instance segmentation, CAD model, or depth generator. Nevertheless, extensive experiments on the popular KITTI 3D detection dataset indicate that the KM3D-Net surpasses all previous state-of-the-art methods in both efficiency and accuracy by a large margin. And also, to the best of our knowledge, this is the first time that semi-supervised learning is applied in monocular 3D objects detection. We even surpass most of the previous fully supervised methods with only 13\% labeled data on KITTI.
AnalogNet: Convolutional Neural Network Inference on Analog Focal Plane Sensor Processors
Jun 21, 2020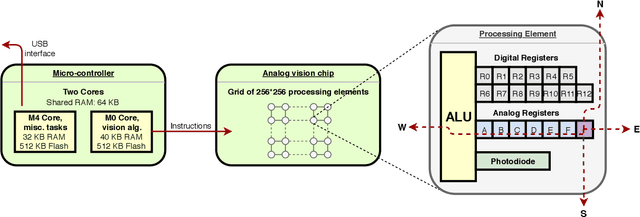
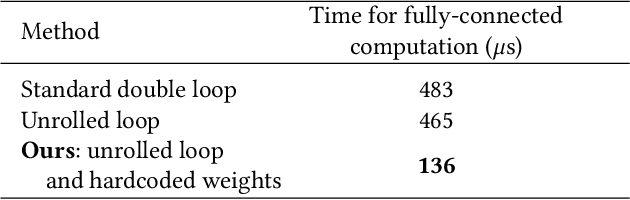


We present a high-speed, energy-efficient Convolutional Neural Network (CNN) architecture utilising the capabilities of a unique class of devices known as analog Focal Plane Sensor Processors (FPSP), in which the sensor and the processor are embedded together on the same silicon chip. Unlike traditional vision systems, where the sensor array sends collected data to a separate processor for processing, FPSPs allow data to be processed on the imaging device itself. This unique architecture enables ultra-fast image processing and high energy efficiency, at the expense of limited processing resources and approximate computations. In this work, we show how to convert standard CNNs to FPSP code, and demonstrate a method of training networks to increase their robustness to analog computation errors. Our proposed architecture, coined AnalogNet, reaches a testing accuracy of 96.9% on the MNIST handwritten digits recognition task, at a speed of 2260 FPS, for a cost of 0.7 mJ per frame.
Improving Generative Visual Dialog by Answering Diverse Questions
Sep 23, 2019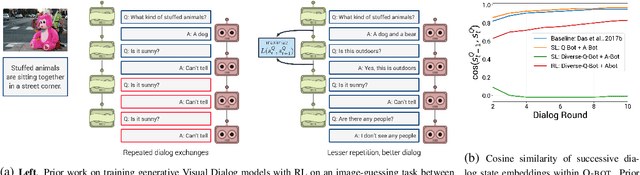

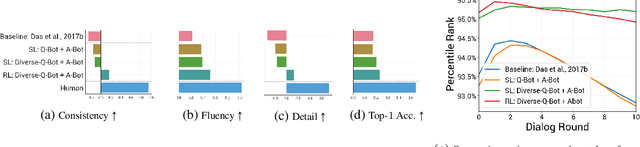

Prior work on training generative Visual Dialog models with reinforcement learning(Das et al.) has explored a Qbot-Abot image-guessing game and shown that this 'self-talk' approach can lead to improved performance at the downstream dialog-conditioned image-guessing task. However, this improvement saturates and starts degrading after a few rounds of interaction, and does not lead to a better Visual Dialog model. We find that this is due in part to repeated interactions between Qbot and Abot during self-talk, which are not informative with respect to the image. To improve this, we devise a simple auxiliary objective that incentivizes Qbot to ask diverse questions, thus reducing repetitions and in turn enabling Abot to explore a larger state space during RL ie. be exposed to more visual concepts to talk about, and varied questions to answer. We evaluate our approach via a host of automatic metrics and human studies, and demonstrate that it leads to better dialog, ie. dialog that is more diverse (ie. less repetitive), consistent (ie. has fewer conflicting exchanges), fluent (ie. more human-like),and detailed, while still being comparably image-relevant as prior work and ablations.