 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Compose Hypercolumns for Visual Correspondence
Jul 21, 2020
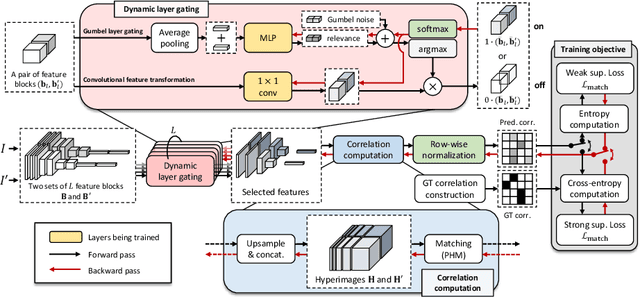
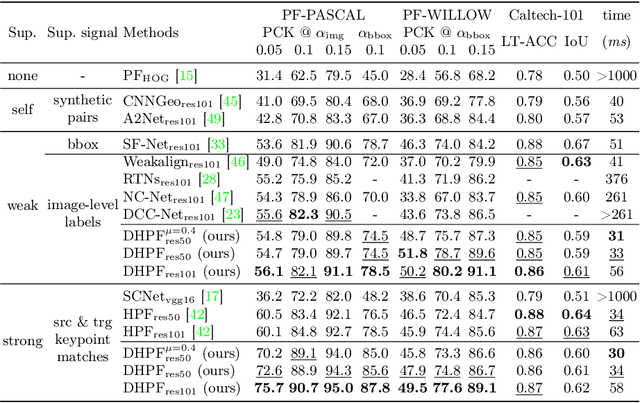
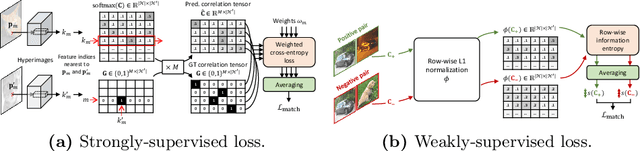
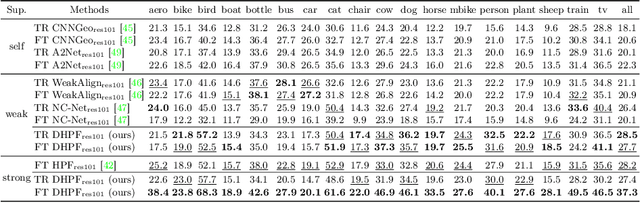
Feature representation plays a crucial role in visual correspondence, and recent methods for image matching resort to deeply stacked convolutional layers. These models, however, are both monolithic and static in the sense that they typically use a specific level of features, e.g., the output of the last layer, and adhere to it regardless of the images to match. In this work, we introduce a novel approach to visual correspondence that dynamically composes effective features by leveraging relevant layers conditioned on the images to match. Inspired by both multi-layer feature composition in object detection and adaptive inference architectures in classification, the proposed method, dubbed Dynamic Hyperpixel Flow, learns to compose hypercolumn features on the fly by selecting a small number of relevant layers from a deep convolutional neural network. We demonstrate the effectiveness on the task of semantic correspondence, i.e., establishing correspondences between images depicting different instances of the same object or scene category. Experiments on standard benchmarks show that the proposed method greatly improves matching performance over the state of the art in an adaptive and efficient manner.
NanoFlow: Scalable Normalizing Flows with Sublinear Parameter Complexity
Jun 11, 2020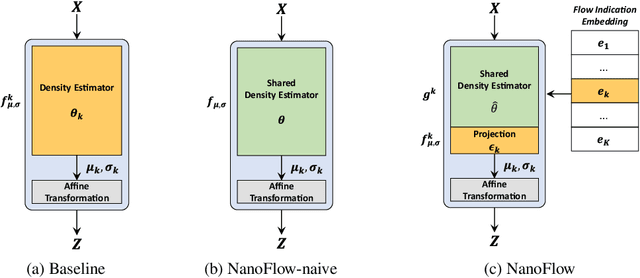
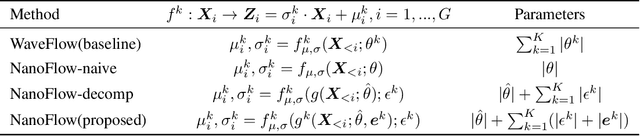
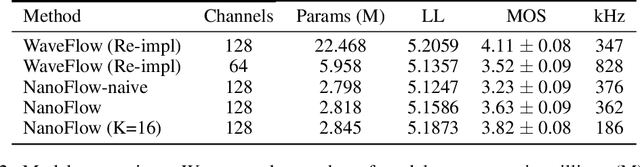
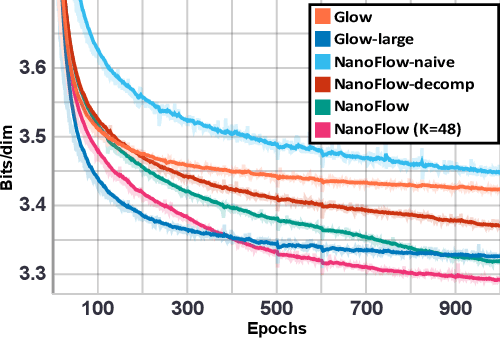
Normalizing flows (NFs) have become a prominent method for deep generative models that allow for an analytic probability density estimation and efficient synthesis. However, a flow-based network is considered to be inefficient in parameter complexity because of reduced expressiveness of bijective mapping, which renders the models prohibitively expensive in terms of parameters. We present an alternative of parameterization scheme, called NanoFlow, which uses a single neural density estimator to model multiple transformation stages. Hence, we propose an efficient parameter decomposition method and the concept of \textit{flow indication embedding}, which are key missing components that enable density estimation from a single neural network. Experiments performed on audio and image models confirm that our method provides a new parameter-efficient solution for scalable NFs with significantly sublinear parameter complexity.
Predicting Visual Memory Schemas with Variational Autoencoders
Jul 19, 2019
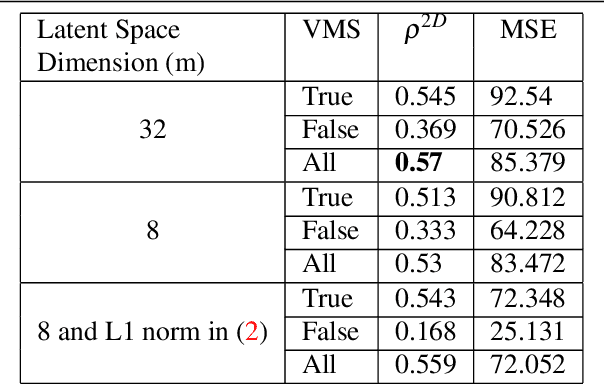
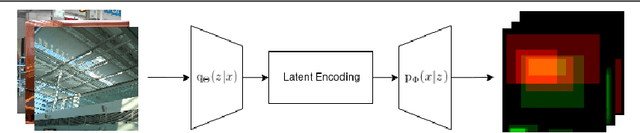

Visual memory schema (VMS) maps show which regions of an image cause that image to be remembered or falsely remembered. Previous work has succeeded in generating low resolution VMS maps using convolutional neural networks. We instead approach this problem as an image-to-image translation task making use of a variational autoencoder. This approach allows us to generate higher resolution dual channel images that represent visual memory schemas, allowing us to evaluate predicted true memorability and false memorability separately. We also evaluate the relationship between VMS maps, predicted VMS maps, ground truth memorability scores, and predicted memorability scores.
Gated Convolutional Networks with Hybrid Connectivity for Image Classification
Aug 26, 2019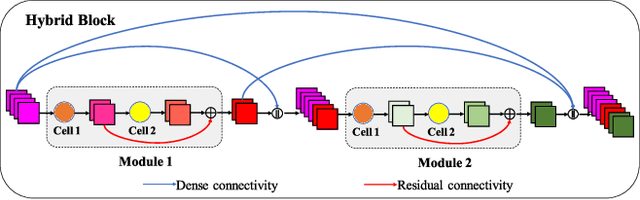
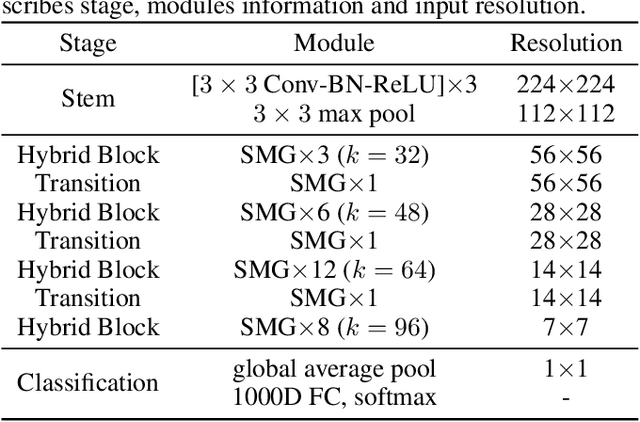
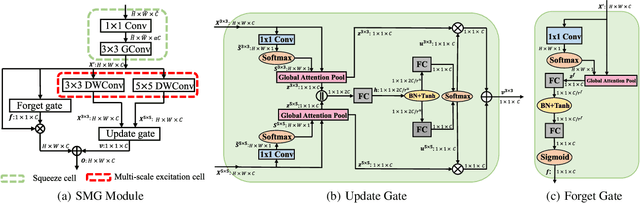
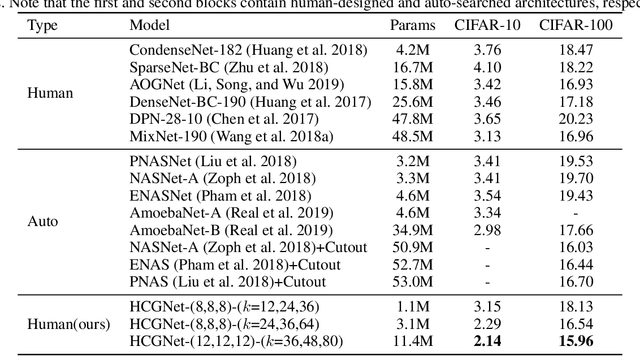
We design a highly efficient architecture called Gated Convolutional Network with Hybrid Connectivity (HCGNet), which is equipped with the combination of local residual and global dense connectivity to enjoy their individual superiorities as well as attention-based gate mechanism to assist feature recalibration. To adapt our hybrid connectivity, we further propose a novel module which includes a squeeze cell for obtaining the compact features from input and then a multi-scale excitation cell attached an update gate to model the global context features for capturing long-range dependency based on multi-scale information. We also locate a forget gate on residual connectivity to decay the reused features, which can be aggergated with newly global context features to form the output that can facilitate effective feature exploration as well as re-exploitation to some extent. Moreover, the number of our proposed modules under dense connectivity can quite fewer than classical DenseNet thus reducing considerable redundancy but with empirically better performance. On CIFAR-10/100 datasets, HCGNets significantly outperform state-of-the-art both human-designed and auto-searched networks with much fewer parameters. It can also consistently obtain better performance and interpretability than widely applied networks in practice on ImageNet dataset.
RoboCoDraw: Robotic Avatar Drawing with GAN-based Style Transfer and Time-efficient Path Optimization
Dec 11, 2019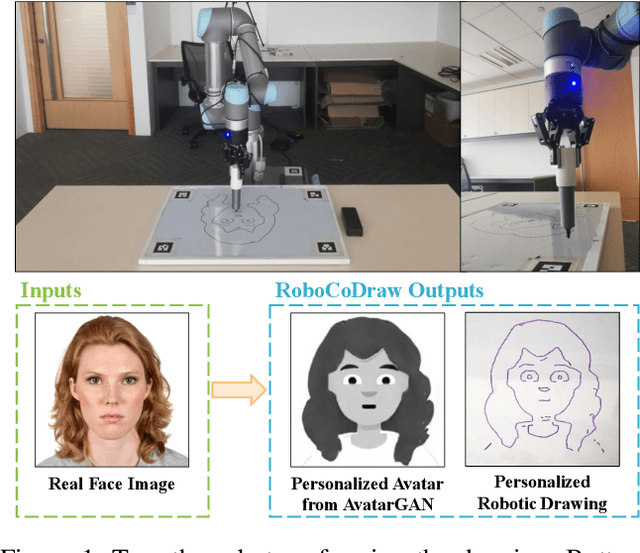
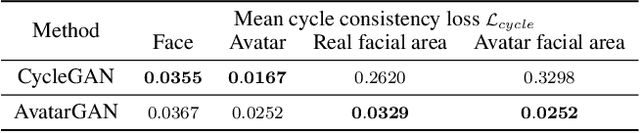

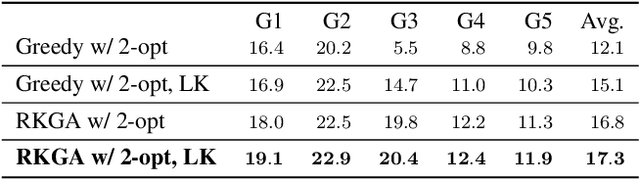
Robotic drawing has become increasingly popular as an entertainment and interactive tool. In this paper we present RoboCoDraw, a real-time collaborative robot-based drawing system that draws stylized human face sketches interactively in front of human users, by using the Generative Adversarial Network (GAN)-based style transfer and a Random-Key Genetic Algorithm (RKGA)-based path optimization. The proposed RoboCoDraw system takes a real human face image as input, converts it to a stylized avatar, then draws it with a robotic arm. A core component in this system is the Avatar-GAN proposed by us, which generates a cartoon avatar face image from a real human face. AvatarGAN is trained with unpaired face and avatar images only and can generate avatar images of much better likeness with human face images in comparison with the vanilla CycleGAN. After the avatar image is generated, it is fed to a line extraction algorithm and converted to sketches. An RKGA-based path optimization algorithm is applied to find a time-efficient robotic drawing path to be executed by the robotic arm. We demonstrate the capability of RoboCoDraw on various face images using a lightweight, safe collaborative robot UR5.
PinView: Implicit Feedback in Content-Based Image Retrieval
Oct 02, 2014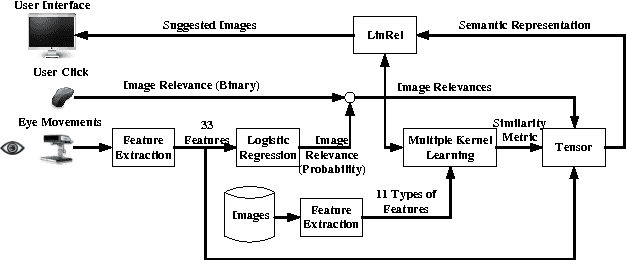
This paper describes PinView, a content-based image retrieval system that exploits implicit relevance feedback collected during a search session. PinView contains several novel methods to infer the intent of the user. From relevance feedback, such as eye movements or pointer clicks, and visual features of images, PinView learns a similarity metric between images which depends on the current interests of the user. It then retrieves images with a specialized online learning algorithm that balances the tradeoff between exploring new images and exploiting the already inferred interests of the user. We have integrated PinView to the content-based image retrieval system PicSOM, which enables applying PinView to real-world image databases. With the new algorithms PinView outperforms the original PicSOM, and in online experiments with real users the combination of implicit and explicit feedback gives the best results.
Machine Learning for Precipitation Nowcasting from Radar Images
Dec 11, 2019

High-resolution nowcasting is an essential tool needed for effective adaptation to climate change, particularly for extreme weather. As Deep Learning (DL) techniques have shown dramatic promise in many domains, including the geosciences, we present an application of DL to the problem of precipitation nowcasting, i.e., high-resolution (1 km x 1 km) short-term (1 hour) predictions of precipitation. We treat forecasting as an image-to-image translation problem and leverage the power of the ubiquitous UNET convolutional neural network. We find this performs favorably when compared to three commonly used models: optical flow, persistence and NOAA's numerical one-hour HRRR nowcasting prediction.
SOIC: Semantic Online Initialization and Calibration for LiDAR and Camera
Mar 09, 2020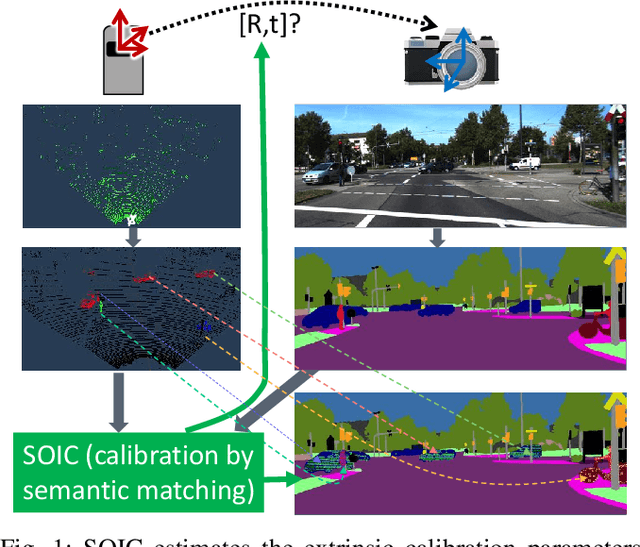
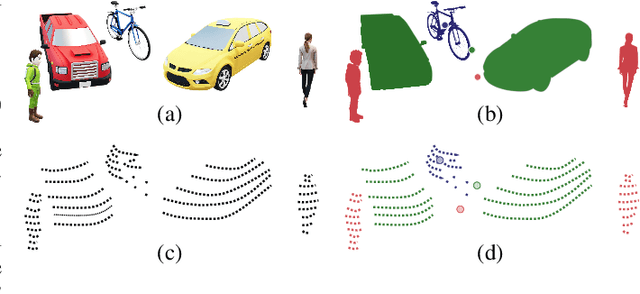
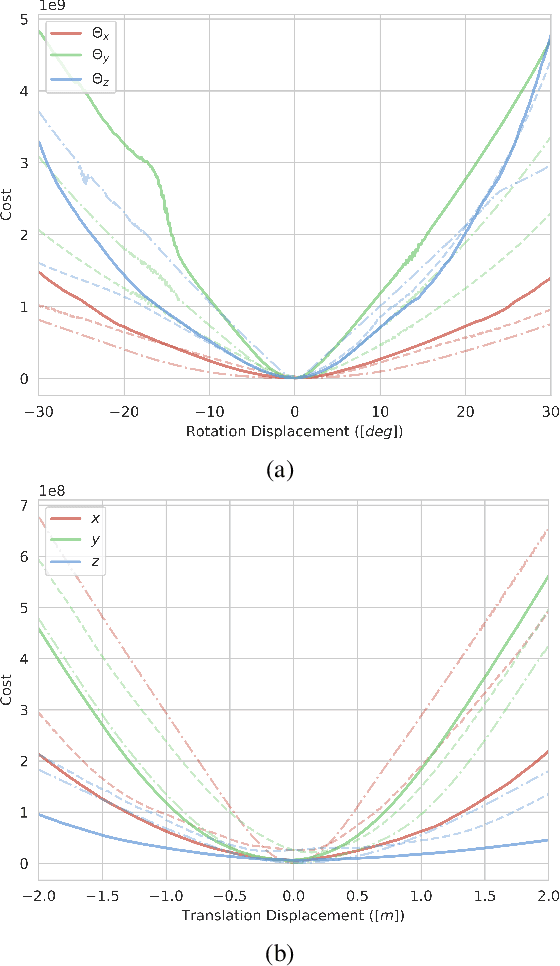
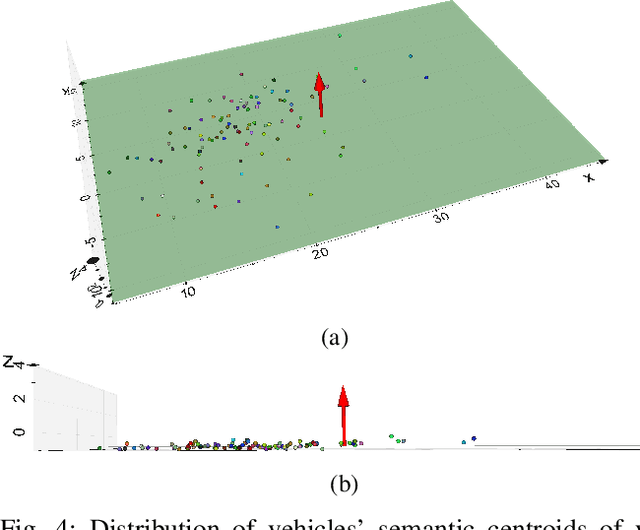
This paper presents a novel semantic-based online extrinsic calibration approach, SOIC (so, I see), for Light Detection and Ranging (LiDAR) and camera sensors. Previous online calibration methods usually need prior knowledge of rough initial values for optimization. The proposed approach removes this limitation by converting the initialization problem to a Perspective-n-Point (PnP) problem with the introduction of semantic centroids (SCs). The closed-form solution of this PnP problem has been well researched and can be found with existing PnP methods. Since the semantic centroid of the point cloud usually does not accurately match with that of the corresponding image, the accuracy of parameters are not improved even after a nonlinear refinement process. Thus, a cost function based on the constraint of the correspondence between semantic elements from both point cloud and image data is formulated. Subsequently, optimal extrinsic parameters are estimated by minimizing the cost function. We evaluate the proposed method either with GT or predicted semantics on KITTI dataset. Experimental results and comparisons with the baseline method verify the feasibility of the initialization strategy and the accuracy of the calibration approach. In addition, we release the source code at https://github.com/--/SOIC.
Hiding Data in Images Using Cryptography and Deep Neural Network
Dec 22, 2019

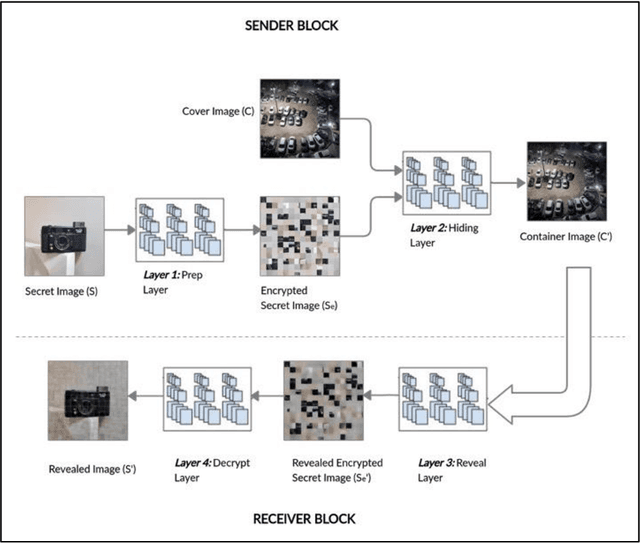
Steganography is an art of obscuring data inside another quotidian file of similar or varying types. Hiding data has always been of significant importance to digital forensics. Previously, steganography has been combined with cryptography and neural networks separately. Whereas, this research combines steganography, cryptography with the neural networks all together to hide an image inside another container image of the larger or same size. Although the cryptographic technique used is quite simple, but is effective when convoluted with deep neural nets. Other steganography techniques involve hiding data efficiently, but in a uniform pattern which makes it less secure. This method targets both the challenges and make data hiding secure and non-uniform.
Deep Complementary Joint Model for Complex Scene Registration and Few-shot Segmentation on Medical Images
Aug 03, 2020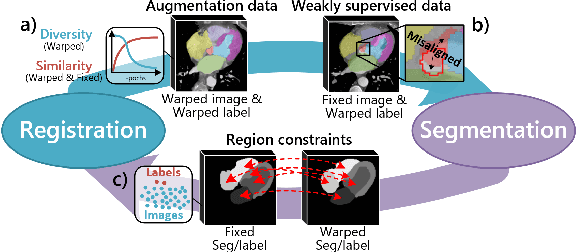

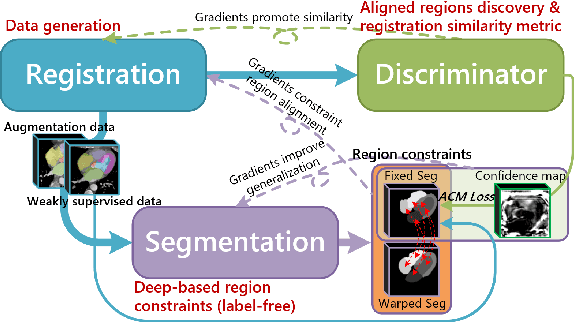
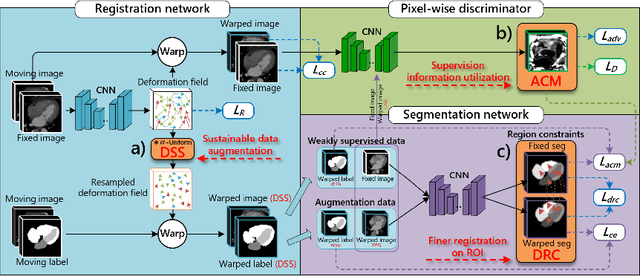
Deep learning-based medical image registration and segmentation joint models utilize the complementarity (augmentation data or weakly supervised data from registration, region constraints from segmentation) to bring mutual improvement in complex scene and few-shot situation. However, further adoption of the joint models are hindered: 1) the diversity of augmentation data is reduced limiting the further enhancement of segmentation, 2) misaligned regions in weakly supervised data disturb the training process, 3) lack of label-based region constraints in few-shot situation limits the registration performance. We propose a novel Deep Complementary Joint Model (DeepRS) for complex scene registration and few-shot segmentation. We embed a perturbation factor in the registration to increase the activity of deformation thus maintaining the augmentation data diversity. We take a pixel-wise discriminator to extract alignment confidence maps which highlight aligned regions in weakly supervised data so the misaligned regions' disturbance will be suppressed via weighting. The outputs from segmentation model are utilized to implement deep-based region constraints thus relieving the label requirements and bringing fine registration. Extensive experiments on the CT dataset of MM-WHS 2017 Challenge show great advantages of our DeepRS that outperforms the existing state-of-the-art models.