 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Little W-Net That Could: State-of-the-Art Retinal Vessel Segmentation with Minimalistic Models
Sep 03, 2020
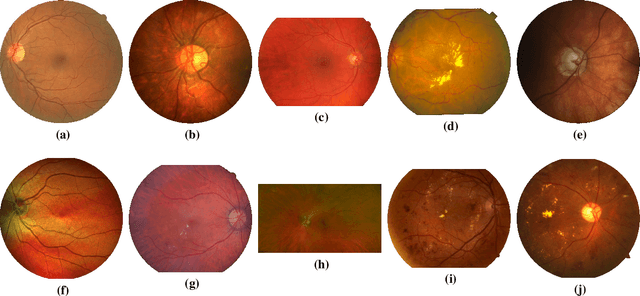
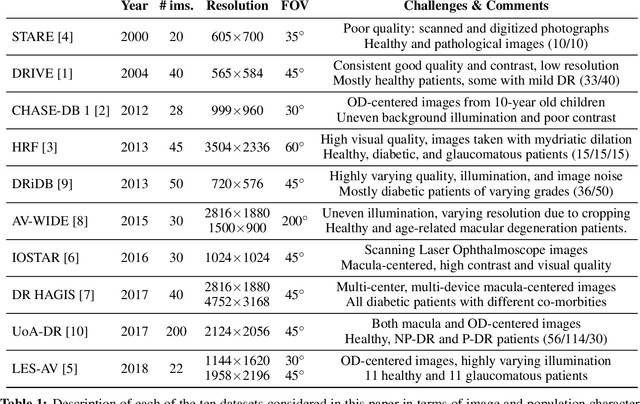
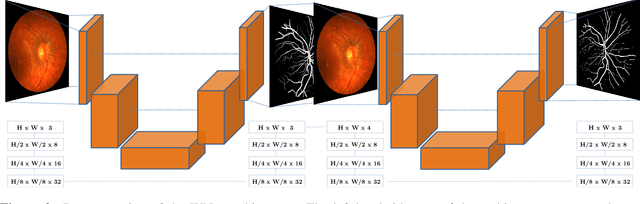
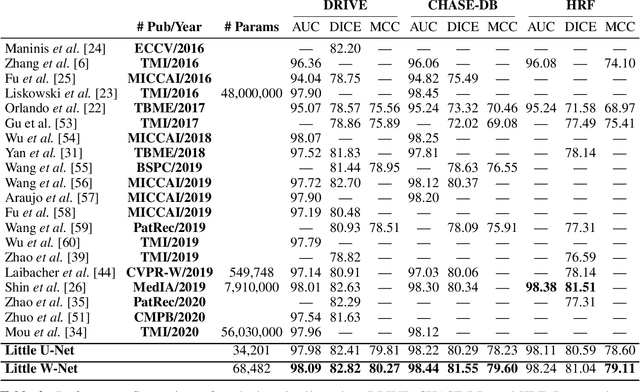
The segmentation of the retinal vasculature from eye fundus images represents one of the most fundamental tasks in retinal image analysis. Over recent years, increasingly complex approaches based on sophisticated Convolutional Neural Network architectures have been slowly pushing performance on well-established benchmark datasets. In this paper, we take a step back and analyze the real need of such complexity. Specifically, we demonstrate that a minimalistic version of a standard U-Net with several orders of magnitude less parameters, carefully trained and rigorously evaluated, closely approximates the performance of current best techniques. In addition, we propose a simple extension, dubbed W-Net, which reaches outstanding performance on several popular datasets, still using orders of magnitude less learnable weights than any previously published approach. Furthermore, we provide the most comprehensive cross-dataset performance analysis to date, involving up to 10 different databases. Our analysis demonstrates that the retinal vessel segmentation problem is far from solved when considering test images that differ substantially from the training data, and that this task represents an ideal scenario for the exploration of domain adaptation techniques. In this context, we experiment with a simple self-labeling strategy that allows us to moderately enhance cross-dataset performance, indicating that there is still much room for improvement in this area. Finally, we also test our approach on the Artery/Vein segmentation problem, where we again achieve results well-aligned with the state-of-the-art, at a fraction of the model complexity in recent literature. All the code to reproduce the results in this paper is released.
Adaptive Context-Aware Multi-Modal Network for Depth Completion
Aug 25, 2020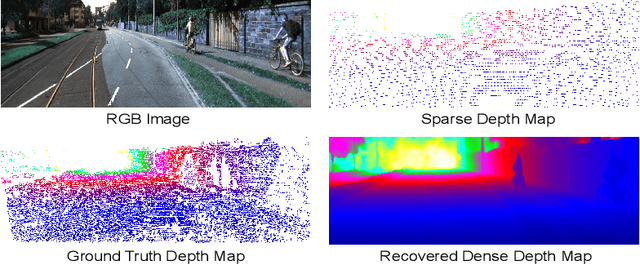
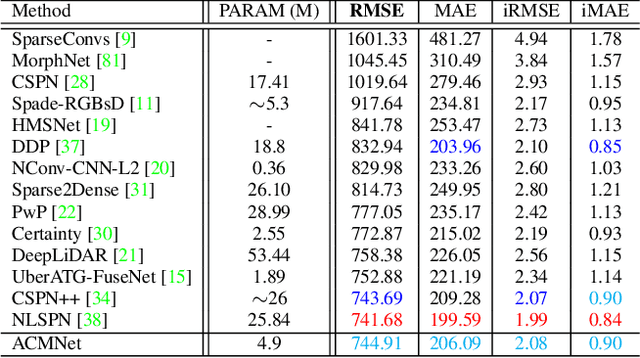
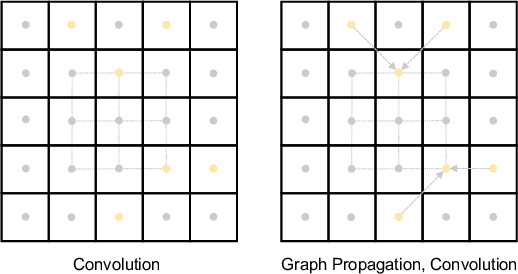
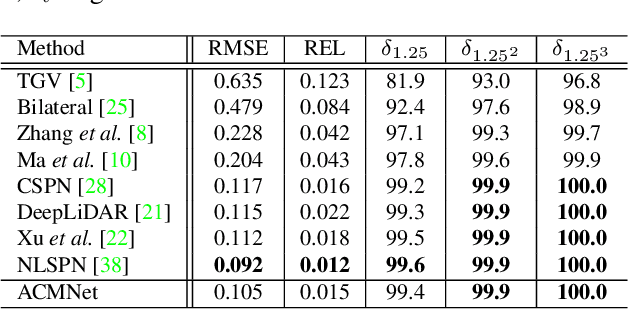
Depth completion aims to recover a dense depth map from the sparse depth data and the corresponding single RGB image. The observed pixels provide the significant guidance for the recovery of the unobserved pixels' depth. However, due to the sparsity of the depth data, the standard convolution operation, exploited by most of existing methods, is not effective to model the observed contexts with depth values. To address this issue, we propose to adopt the graph propagation to capture the observed spatial contexts. Specifically, we first construct multiple graphs at different scales from observed pixels. Since the graph structure varies from sample to sample, we then apply the attention mechanism on the propagation, which encourages the network to model the contextual information adaptively. Furthermore, considering the mutli-modality of input data, we exploit the graph propagation on the two modalities respectively to extract multi-modal representations. Finally, we introduce the symmetric gated fusion strategy to exploit the extracted multi-modal features effectively. The proposed strategy preserves the original information for one modality and also absorbs complementary information from the other through learning the adaptive gating weights. Our model, named Adaptive Context-Aware Multi-Modal Network (ACMNet), achieves the state-of-the-art performance on two benchmarks, {\it i.e.}, KITTI and NYU-v2, and at the same time has fewer parameters than latest models. Our code is available at: \url{https://github.com/sshan-zhao/ACMNet}.
Automated Segmentation of Brain Gray Matter Nuclei on Quantitative Susceptibility Mapping Using Deep Convolutional Neural Network
Aug 03, 2020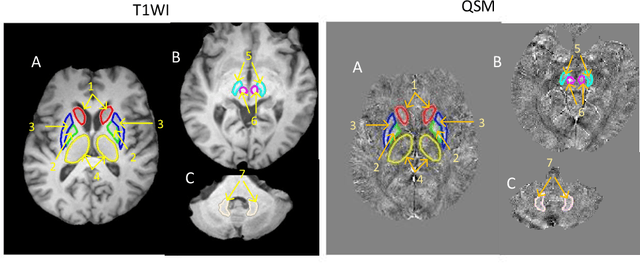
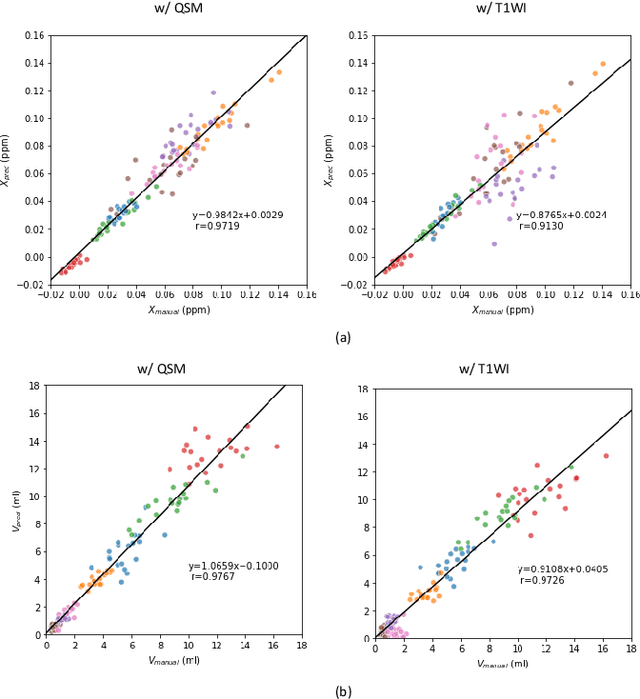
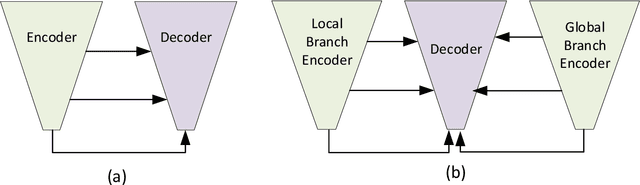
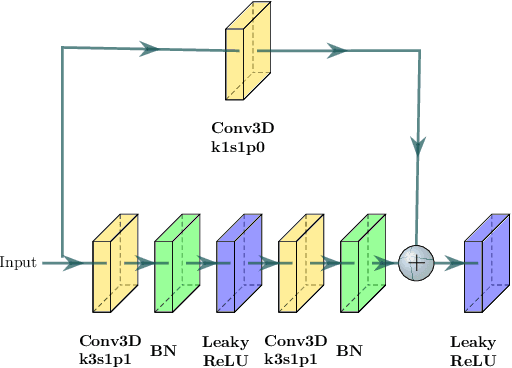
Abnormal iron accumulation in the brain subcortical nuclei has been reported to be correlated to various neurodegenerative diseases, which can be measured through the magnetic susceptibility from the quantitative susceptibility mapping (QSM). To quantitively measure the magnetic susceptibility, the nuclei should be accurately segmented, which is a tedious task for clinicians. In this paper, we proposed a double-branch residual-structured U-Net (DB-ResUNet) based on 3D convolutional neural network (CNN) to automatically segment such brain gray matter nuclei. To better tradeoff between segmentation accuracy and the memory efficiency, the proposed DB-ResUNet fed image patches with high resolution and the patches with low resolution but larger field of view into the local and global branches, respectively. Experimental results revealed that by jointly using QSM and T$_\text{1}$ weighted imaging (T$_\text{1}$WI) as inputs, the proposed method was able to achieve better segmentation accuracy over its single-branch counterpart, as well as the conventional atlas-based method and the classical 3D-UNet structure. The susceptibility values and the volumes were also measured, which indicated that the measurements from the proposed DB-ResUNet are able to present high correlation with values from the manually annotated regions of interest.
A Deep Convolutional Neural Network for COVID-19 Detection Using Chest X-Rays
Apr 30, 2020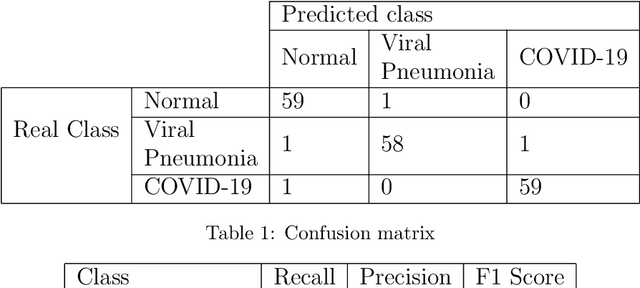
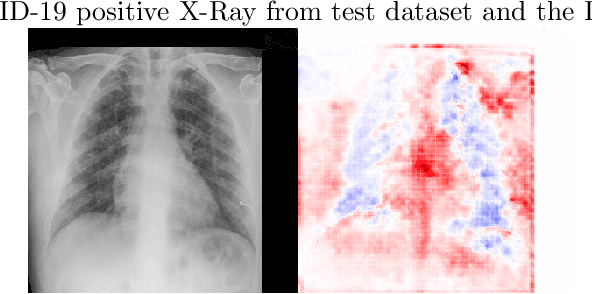
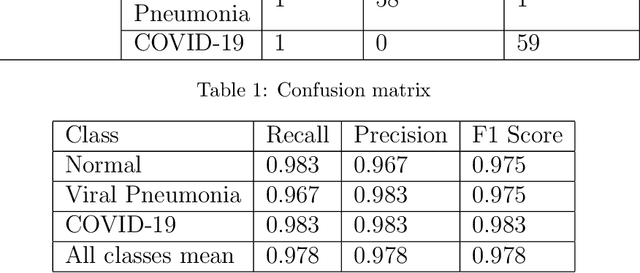
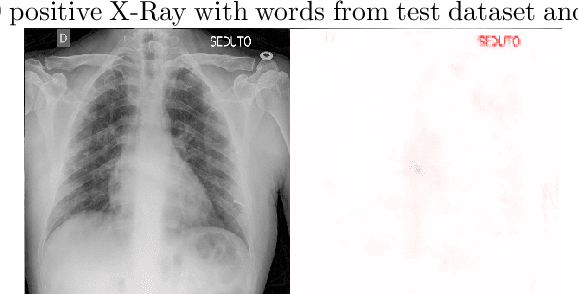
We present an image classifier based on the CheXNet and a transfer learning stage to classify chest X-Ray images according to three labels: COVID-19, viral pneumonia and normal. CheXNet is a DenseNet121 that has been trained twice, firstly on ImageNet and then, for classification of pneumonia and other 13 chest diseases, over a large chest X-Ray database (ChestX- ray14). The proposed network reached a test accuracy of 97.8% and, for the COVID-19 class, of 98.3%. In order to clarify the modus operandi of the network, we used Layer Wise Relevance Propagation (LRP) to generate heat maps, indicating an analytical path for future research on diagnosis.
Regularized Adaptation for Stable and Efficient Continuous-Level Learning
Mar 11, 2020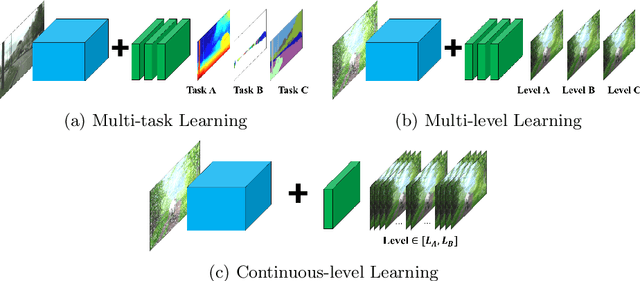

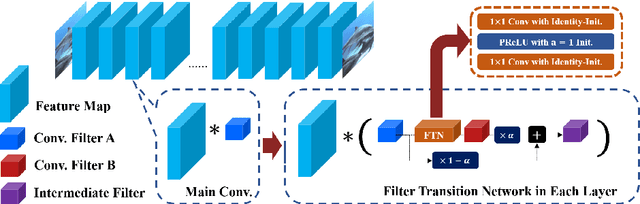

In Convolutional Neural Network (CNN) based image processing, most of the studies propose networks that are optimized for a single-level (or a single-objective); thus, they underperform on other levels and must be retrained for delivery of optimal performance. Using multiple models to cover multiple levels involves very high computational costs. To solve these problems, recent approaches train the networks on two different levels and propose their own interpolation methods to enable the arbitrary intermediate levels. However, many of them fail to adapt hard tasks or interpolate smoothly, or the others still require large memory and computational cost. In this paper, we propose a novel continuous-level learning framework using a Filter Transition Network (FTN) which is a non-linear module that easily adapt to new levels, and is regularized to prevent undesirable side-effects. Additionally, for stable learning of FTN, we newly propose a method to initialize non-linear CNNs with identity mappings. Furthermore, FTN is extremely lightweight module since it is a data-independent module, which means it is not affected by the spatial resolution of the inputs. Extensive results for various image processing tasks indicate that the performance of FTN is stable in terms of adaptation and interpolation, and comparable to that of the other heavy frameworks.
Continual General Chunking Problem and SyncMap
Jun 16, 2020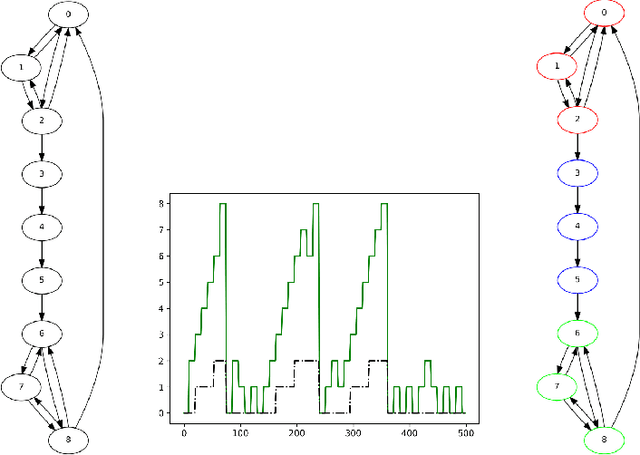
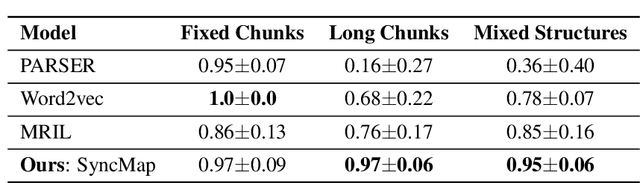
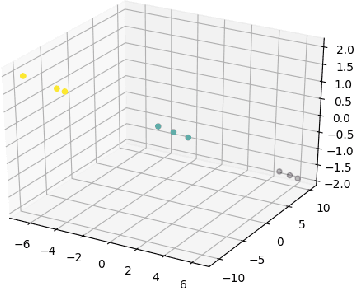
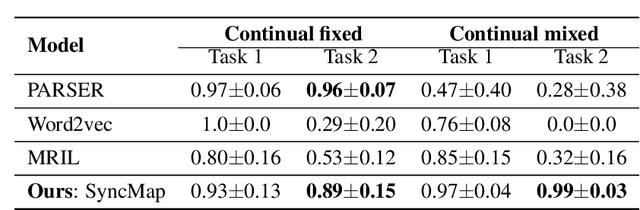
Humans possess an inherent ability to chunk sequences into their constituent parts. In fact, this ability is thought to bootstrap language skills to the learning of image patterns which might be a key to a more animal-like type of intelligence. Here, we propose a continual generalization of the chunking problem (an unsupervised problem), encompassing fixed and probabilistic chunks, discovery of temporal and causal structures and their continual variations. Additionally, we propose an algorithm called SyncMap that can learn and adapt to changes in the problem by creating a dynamic map which preserves the correlation between variables. Results of SyncMap suggest that the proposed algorithm learn near optimal solutions, despite the presence of many types of structures and their continual variation. When compared to Word2vec, PARSER and MRIL, SyncMap surpasses or ties with the best algorithm on $77\%$ of the scenarios while being the second best in the remaing $23\%$.
Learning-Based Human Segmentation and Velocity Estimation Using Automatic Labeled LiDAR Sequence for Training
Mar 11, 2020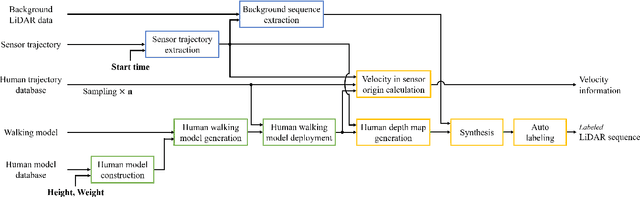

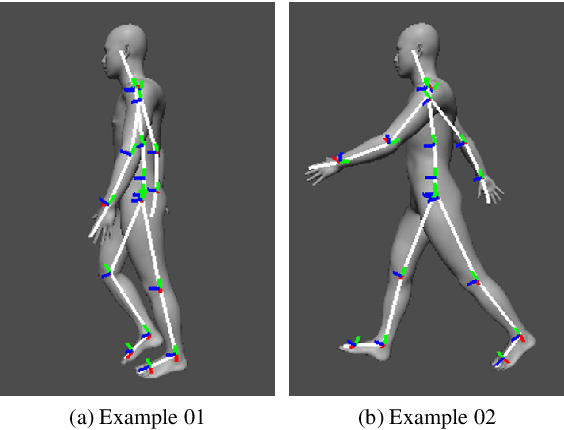

In this paper, we propose an automatic labeled sequential data generation pipeline for human segmentation and velocity estimation with point clouds. Considering the impact of deep neural networks, state-of-the-art network architectures have been proposed for human recognition using point clouds captured by Light Detection and Ranging (LiDAR). However, one disadvantage is that legacy datasets may only cover the image domain without providing important label information and this limitation has disturbed the progress of research to date. Therefore, we develop an automatic labeled sequential data generation pipeline, in which we can control any parameter or data generation environment with pixel-wise and per-frame ground truth segmentation and pixel-wise velocity information for human recognition. Our approach uses a precise human model and reproduces a precise motion to generate realistic artificial data. We present more than 7K video sequences which consist of 32 frames generated by the proposed pipeline. With the proposed sequence generator, we confirm that human segmentation performance is improved when using the video domain compared to when using the image domain. We also evaluate our data by comparing with data generated under different conditions. In addition, we estimate pedestrian velocity with LiDAR by only utilizing data generated by the proposed pipeline.
Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion
Sep 12, 2020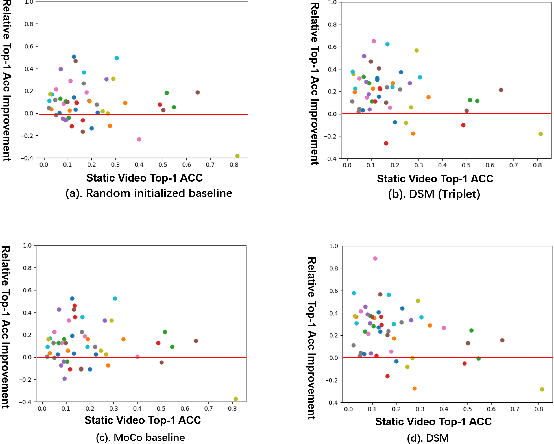

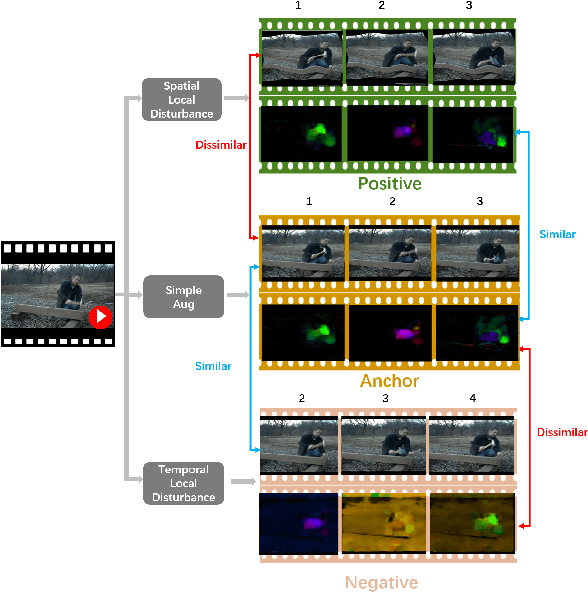
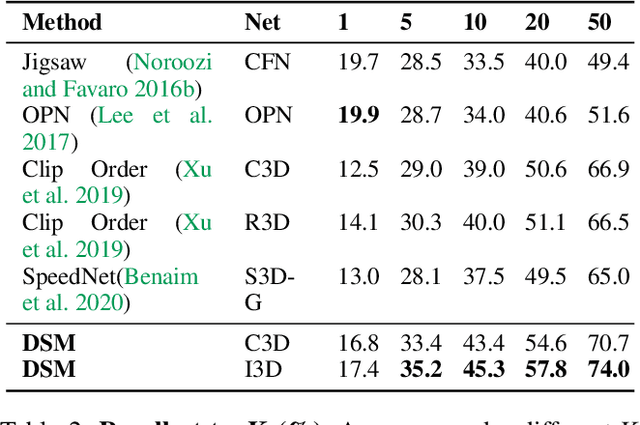
One significant factor we expect the video representation learning to capture, especially in contrast with the image representation learning, is the object motion. However, we found that in the current mainstream video datasets, some action categories are highly related with the scene where the action happens, making the model tend to degrade to a solution where only the scene information is encoded. For example, a trained model may predict a video as playing football simply because it sees the field, neglecting that the subject is dancing as a cheerleader on the field. This is against our original intention towards the video representation learning and may bring scene bias on different dataset that can not be ignored. In order to tackle this problem, we propose to decouple the scene and the motion (DSM) with two simple operations, so that the model attention towards the motion information is better paid. Specifically, we construct a positive clip and a negative clip for each video. Compared to the original video, the positive/negative is motion-untouched/broken but scene-broken/untouched by Spatial Local Disturbance and Temporal Local Disturbance. Our objective is to pull the positive closer while pushing the negative farther to the original clip in the latent space. In this way, the impact of the scene is weakened while the temporal sensitivity of the network is further enhanced. We conduct experiments on two tasks with various backbones and different pre-training datasets, and find that our method surpass the SOTA methods with a remarkable 8.1% and 8.8% improvement towards action recognition task on the UCF101 and HMDB51 datasets respectively using the same backbone.
Exploit Camera Raw Data for Video Super-Resolution via Hidden Markov Model Inference
Aug 24, 2020
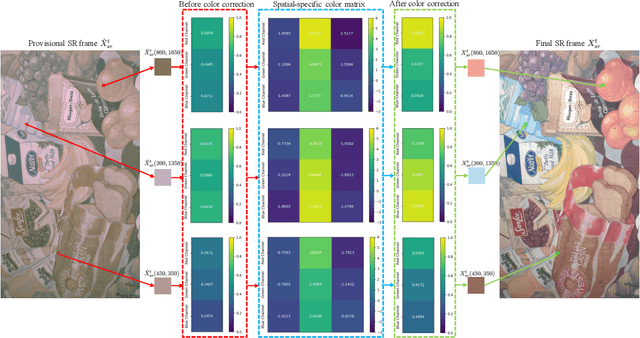

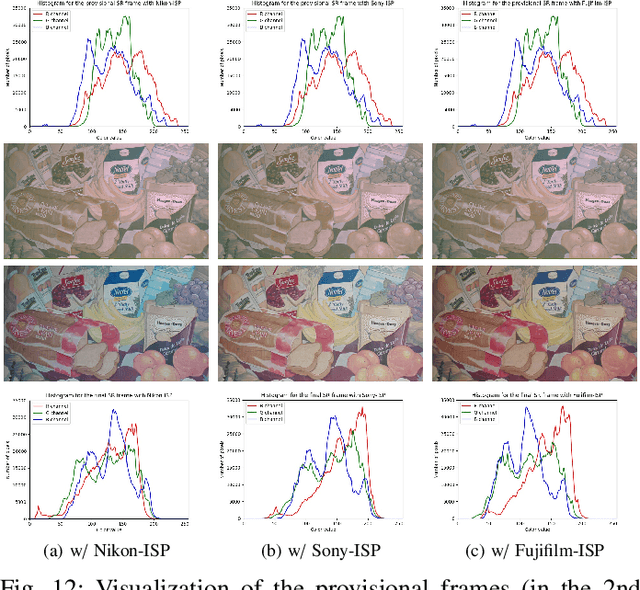
To the best of our knowledge, the existing deep-learning-based Video Super-Resolution (VSR) methods exclusively make use of videos produced by the Image Signal Processor (ISP) of the camera system as inputs. Such methods are 1) inherently suboptimal due to information loss incurred by non-invertible operations in ISP, and 2) inconsistent with the real imaging pipeline where VSR in fact serves as a pre-processing unit of ISP. To address this issue, we propose a new VSR method that can directly exploit camera sensor data, accompanied by a carefully built Raw Video Dataset (RawVD) for training, validation, and testing. This method consists of a Successive Deep Inference (SDI) module and a reconstruction module, among others. The SDI module is designed according to the architectural principle suggested by a canonical decomposition result for Hidden Markov Model (HMM) inference; it estimates the target high-resolution frame by repeatedly performing pairwise feature fusion using deformable convolutions. The reconstruction module, built with elaborately designed Attention-based Residual Dense Blocks (ARDBs), serves the purpose of 1) refining the fused feature and 2) learning the color information needed to generate a spatial-specific transformation for accurate color correction. Extensive experiments demonstrate that owing to the informativeness of the camera raw data, the effectiveness of the network architecture, and the separation of super-resolution and color correction processes, the proposed method achieves superior VSR results compared to the state-of-the-art and can be adapted to any specific camera-ISP.
Look Locally Infer Globally: A Generalizable Face Anti-Spoofing Approach
Jun 15, 2020
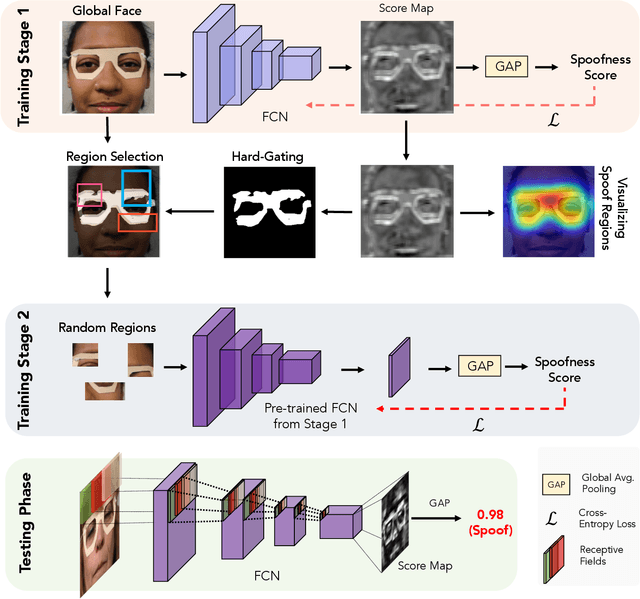
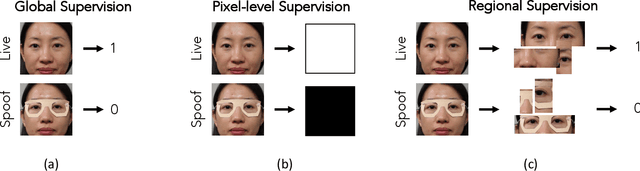

State-of-the-art spoof detection methods tend to overfit to the spoof types seen during training and fail to generalize to unknown spoof types. Given that face anti-spoofing is inherently a local task, we propose a face anti-spoofing framework, namely Self-Supervised Regional Fully Convolutional Network (SSR-FCN), that is trained to learn local discriminative cues from a face image in a self-supervised manner. The proposed framework improves generalizability while maintaining the computational efficiency of holistic face anti-spoofing approaches (< 4 ms on a Nvidia GTX 1080Ti GPU). The proposed method is interpretable since it localizes which parts of the face are labeled as spoofs. Experimental results show that SSR-FCN can achieve TDR = 65% @ 2.0% FDR when evaluated on a dataset comprising of 13 different spoof types under unknown attacks while achieving competitive performances under standard benchmark datasets (Oulu-NPU, CASIA-MFSD, and Replay-Attack).