 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving GAN Training with Probability Ratio Clipping and Sample Reweighting
Jun 12, 2020
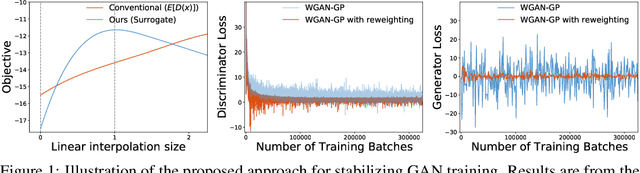


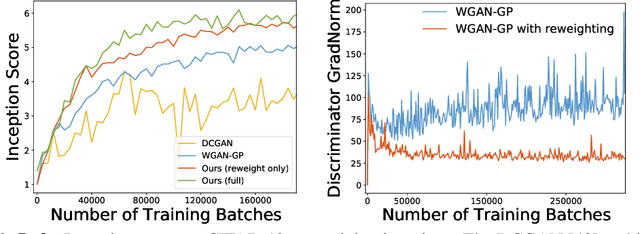
Despite success on a wide range of problems related to vision, generative adversarial networks (GANs) can suffer from inferior performance due to unstable training, especially for text generation. we propose a new variational GAN training framework which enjoys superior training stability. Our approach is inspired by a connection of GANs and reinforcement learning under a variational perspective. The connection leads to (1) probability ratio clipping that regularizes generator training to prevent excessively large updates, and (2) a sample re-weighting mechanism that stabilizes discriminator training by downplaying bad-quality fake samples. We provide theoretical analysis on the convergence of our approach. By plugging the training approach in diverse state-of-the-art GAN architectures, we obtain significantly improved performance over a range of tasks, including text generation, text style transfer, and image generation.
KutralNet: A Portable Deep Learning Model for Fire Recognition
Aug 16, 2020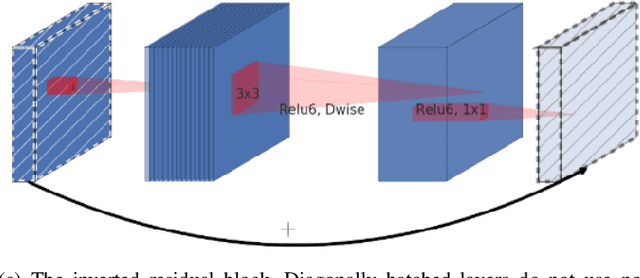
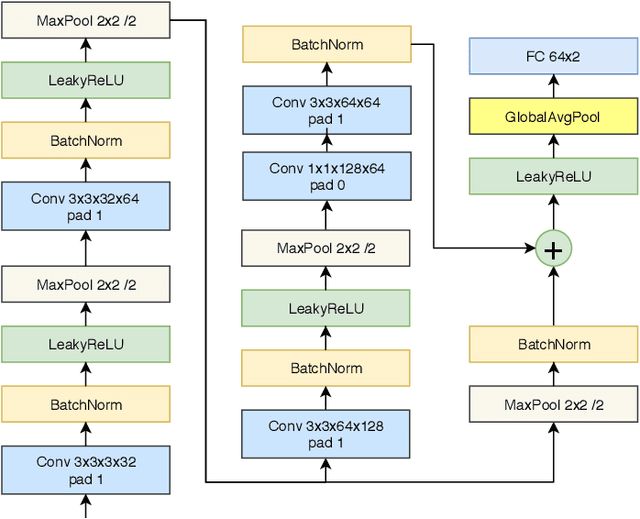
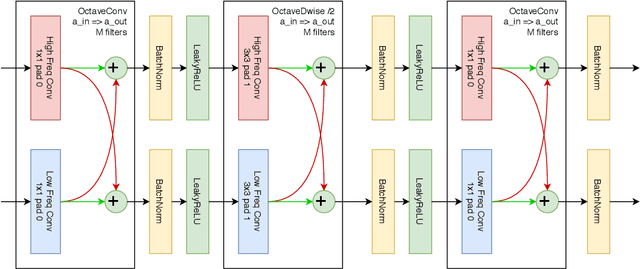
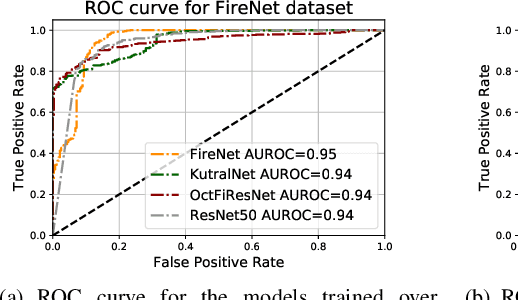
Most of the automatic fire alarm systems detect the fire presence through sensors like thermal, smoke, or flame. One of the new approaches to the problem is the use of images to perform the detection. The image approach is promising since it does not need specific sensors and can be easily embedded in different devices. However, besides the high performance, the computational cost of the used deep learning methods is a challenge to their deployment in portable devices. In this work, we propose a new deep learning architecture that requires fewer floating-point operations (flops) for fire recognition. Additionally, we propose a portable approach for fire recognition and the use of modern techniques such as inverted residual block, convolutions like depth-wise, and octave, to reduce the model's computational cost. The experiments show that our model keeps high accuracy while substantially reducing the number of parameters and flops. One of our models presents 71\% fewer parameters than FireNet, while still presenting competitive accuracy and AUROC performance. The proposed methods are evaluated on FireNet and FiSmo datasets. The obtained results are promising for the implementation of the model in a mobile device, considering the reduced number of flops and parameters acquired.
How Can We Make GAN Perform Better in Single Medical Image Super-Resolution? A Lesion Focused Multi-Scale Approach
Jan 10, 2019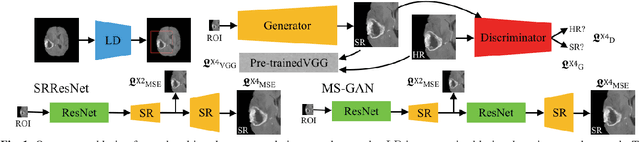
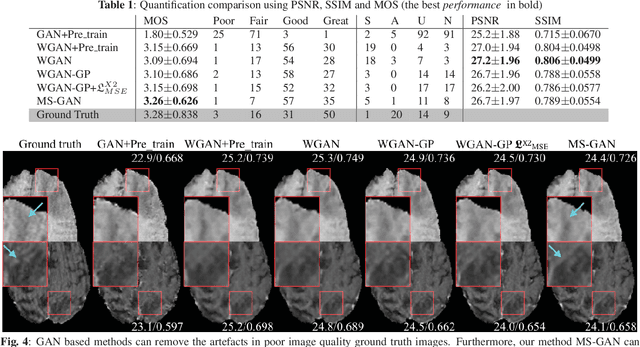
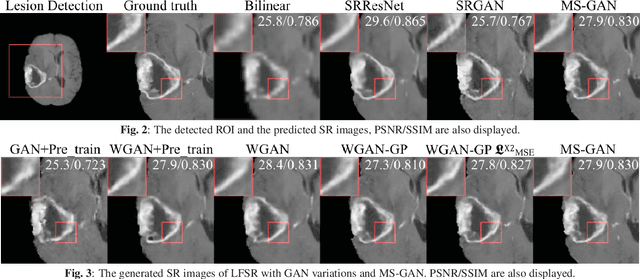
Single image super-resolution (SISR) is of great importance as a low-level computer vision task. The fast development of Generative Adversarial Network (GAN) based deep learning architectures realises an efficient and effective SISR to boost the spatial resolution of natural images captured by digital cameras. However, the SISR for medical images is still a very challenging problem. This is due to (1) compared to natural images, in general, medical images have lower signal to noise ratios, (2) GAN based models pre-trained on natural images may synthesise unrealistic patterns in medical images which could affect the clinical interpretation and diagnosis, and (3) the vanilla GAN architecture may suffer from unstable training and collapse mode that can also affect the SISR results. In this paper, we propose a novel lesion focused SR (LFSR) method, which incorporates GAN to achieve perceptually realistic SISR results for brain tumour MRI images. More importantly, we test and make comparison using recently developed GAN variations, e.g., Wasserstein GAN (WGAN) and WGAN with Gradient Penalty (WGAN-GP), and propose a novel multi-scale GAN (MS-GAN), to achieve a more stabilised and efficient training and improved perceptual quality of the super-resolved results. Based on both quantitative evaluations and our designed mean opinion score, the proposed LFSR coupled with MS-GAN has performed better in terms of both perceptual quality and efficiency.
PinView: Implicit Feedback in Content-Based Image Retrieval
Oct 02, 2014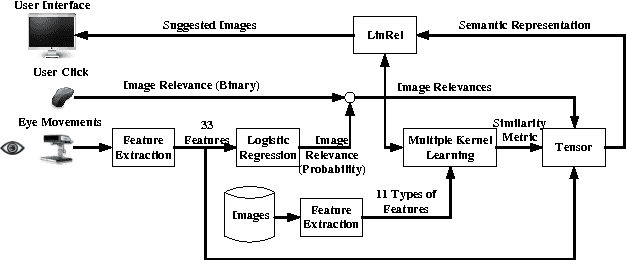
This paper describes PinView, a content-based image retrieval system that exploits implicit relevance feedback collected during a search session. PinView contains several novel methods to infer the intent of the user. From relevance feedback, such as eye movements or pointer clicks, and visual features of images, PinView learns a similarity metric between images which depends on the current interests of the user. It then retrieves images with a specialized online learning algorithm that balances the tradeoff between exploring new images and exploiting the already inferred interests of the user. We have integrated PinView to the content-based image retrieval system PicSOM, which enables applying PinView to real-world image databases. With the new algorithms PinView outperforms the original PicSOM, and in online experiments with real users the combination of implicit and explicit feedback gives the best results.
Mask2Lesion: Mask-Constrained Adversarial Skin Lesion Image Synthesis
Jul 15, 2019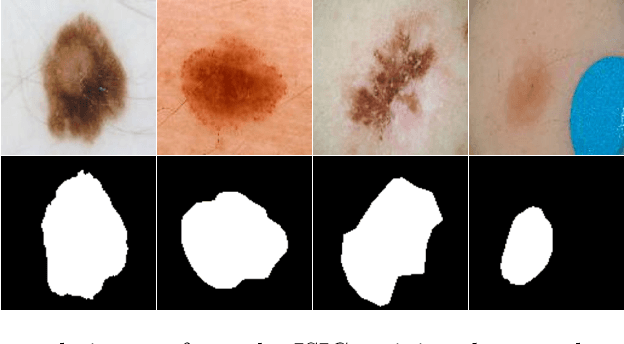
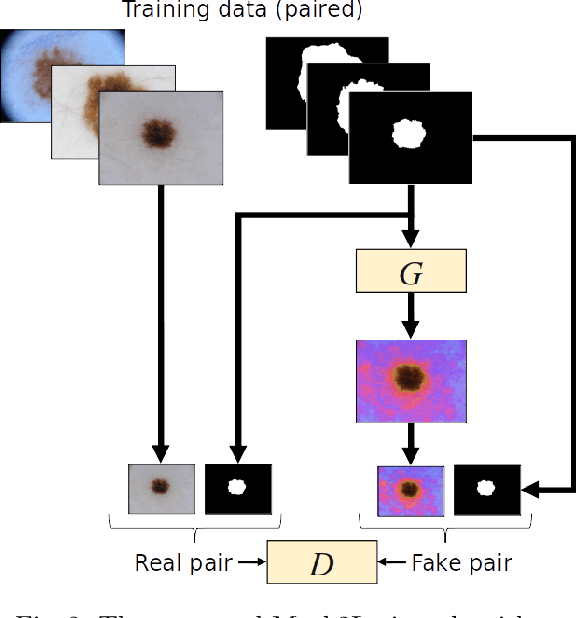

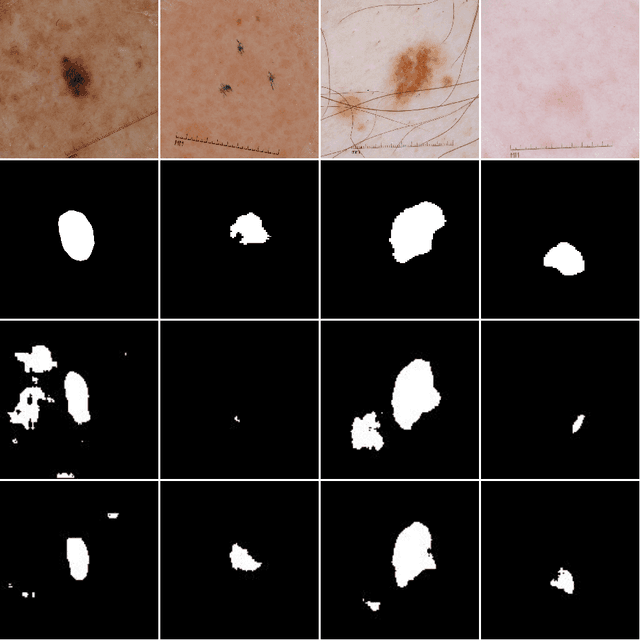
Skin lesion segmentation is a vital task in skin cancer diagnosis and further treatment. Although deep learning based approaches have significantly improved the segmentation accuracy, these algorithms are still reliant on having a large enough dataset in order to achieve adequate results. Inspired by the immense success of generative adversarial networks (GANs), we propose a GAN-based augmentation of the original dataset in order to improve the segmentation performance. In particular, we use the segmentation masks available in the training dataset to train the Mask2Lesion model, and use the model to generate new lesion images given any arbitrary mask, which are then used to augment the original training dataset. We test Mask2Lesion augmentation on the ISBI ISIC 2017 Skin Lesion Segmentation Challenge dataset and achieve an improvement of 5.17% in the mean Dice score as compared to a model trained with only classical data augmentation techniques.
Stable Segmentation of Digital Image
Aug 13, 2012In the paper the optimal image segmentation by means of piecewise constant approximations is considered. The optimality is defined by a minimum value of the total squared error or by equivalent value of standard deviation of the approximation from the image. The optimal approximations are defined independently on the method of their obtaining and might be generated in different algorithms. We investigate the computation of the optimal approximation on the grounds of stability with respect to a given set of modifications. To obtain the optimal approximation the Mumford-Shuh model is generalized and developed, which in the computational part is combined with the Otsu method in multi-thresholding version. The proposed solution is proved analytically and experimentally on the example of the standard image.
* 6 pages, 10 formulas, 2 figures, in russian
Multiview Chirality
Mar 19, 2020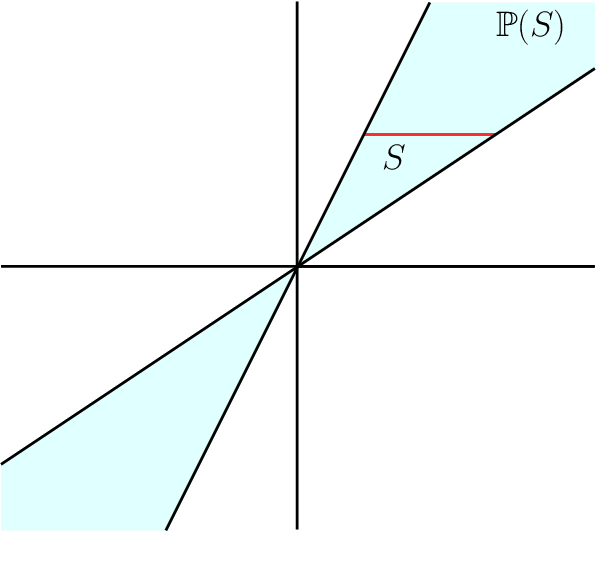
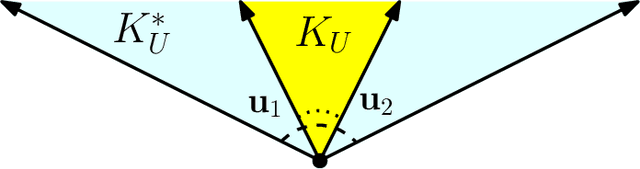
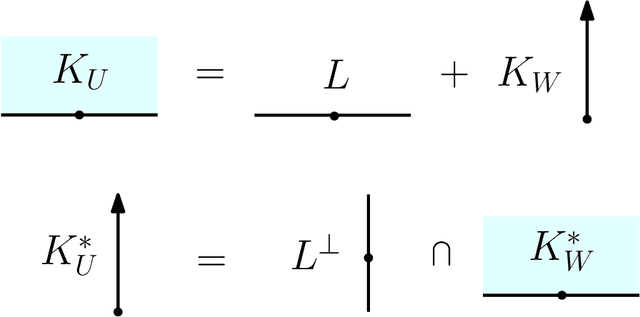
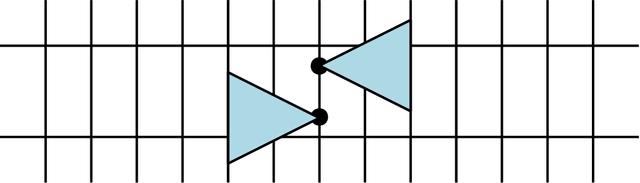
Given an arrangement of cameras $\mathcal{A} = \{A_1,\dots, A_m\}$, the chiral domain of $\mathcal{A}$ is the subset of $\mathbb{P}^3$ that lies in front it. It is a generalization of the classical definition of chirality. We give an algebraic description of this set and use it to generalize Hartley's theory of chiral reconstruction to $m \ge 2$ views and derive a chiral version of Triggs' Joint Image.
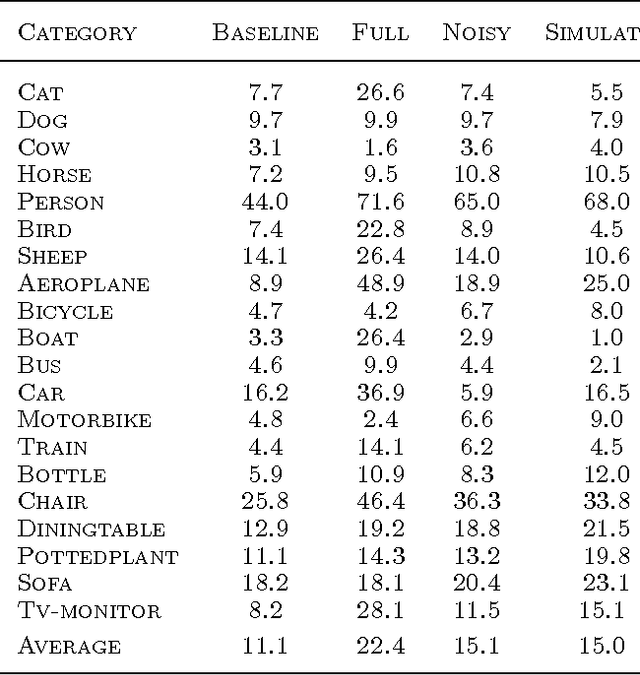
IITK at SemEval-2020 Task 8: Unimodal and Bimodal Sentiment Analysis of Internet Memes
Jul 21, 2020
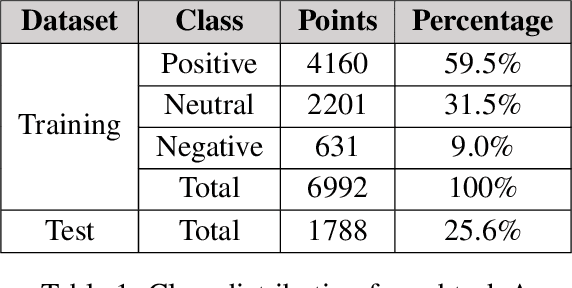
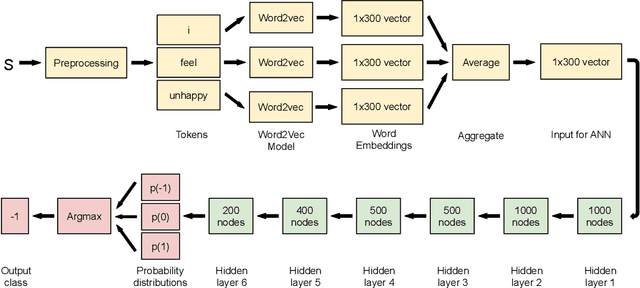
Social media is abundant in visual and textual information presented together or in isolation. Memes are the most popular form, belonging to the former class. In this paper, we present our approaches for the Memotion Analysis problem as posed in SemEval-2020 Task 8. The goal of this task is to classify memes based on their emotional content and sentiment. We leverage techniques from Natural Language Processing (NLP) and Computer Vision (CV) towards the sentiment classification of internet memes (Subtask A). We consider Bimodal (text and image) as well as Unimodal (text-only) techniques in our study ranging from the Na\"ive Bayes classifier to Transformer-based approaches. Our results show that a text-only approach, a simple Feed Forward Neural Network (FFNN) with Word2vec embeddings as input, performs superior to all the others. We stand first in the Sentiment analysis task with a relative improvement of 63% over the baseline macro-F1 score. Our work is relevant to any task concerned with the combination of different modalities.
Inner Eye Canthus Localization for Human Body Temperature Screening
Aug 27, 2020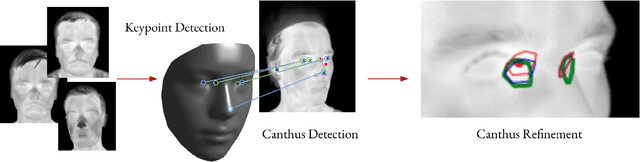
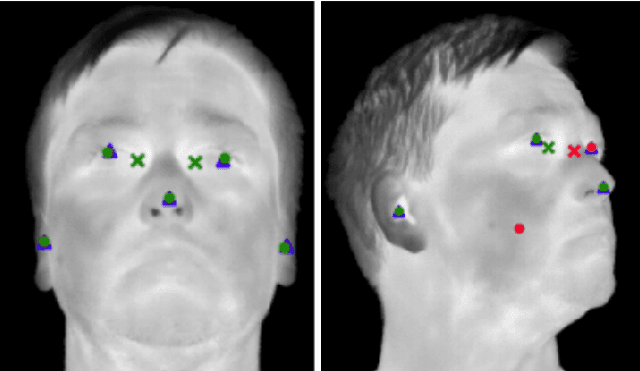
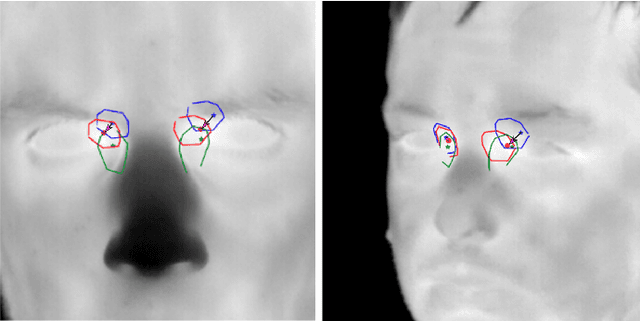
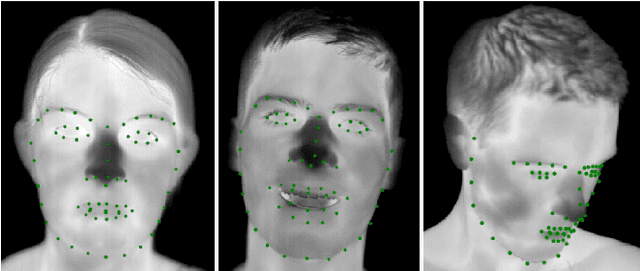
In this paper, we propose an automatic approach for localizing the inner eye canthus in thermal face images. We first coarsely detect 5 facial keypoints corresponding to the center of the eyes, the nosetip and the ears. Then we compute a sparse 2D-3D points correspondence using a 3D Morphable Face Model (3DMM). This correspondence is used to project the entire 3D face onto the image, and subsequently locate the inner eye canthus. Detecting this location allows to obtain the most precise body temperature measurement for a person using a thermal camera. We evaluated the approach on a thermal face dataset provided with manually annotated landmarks. However, such manual annotations are normally conceived to identify facial parts such as eyes, nose and mouth, and are not specifically tailored for localizing the eye canthus region. As additional contribution, we enrich the original dataset by using the annotated landmarks to deform and project the 3DMM onto the images. Then, by manually selecting a small region corresponding to the eye canthus, we enrich the dataset with additional annotations. By using the manual landmarks, we ensure the correctness of the 3DMM projection, which can be used as ground-truth for future evaluations. Moreover, we supply the dataset with the 3D head poses and per-point visibility masks for detecting self-occlusions. The data will be publicly released.
Metric-Guided Prototype Learning
Jul 06, 2020

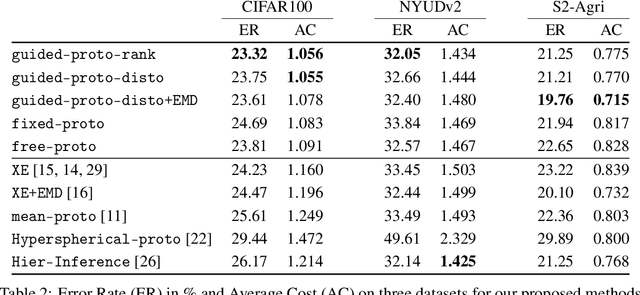

Not all errors are created equal. This is especially true for many key machine learning applications. In the case of classification tasks, the hierarchy of errors can be summarized under the form of a cost matrix, which assesses the gravity of confusing each pair of classes. When certain conditions are met, this matrix defines a metric, which we use in a new and versatile classification layer to model the disparity of errors. Our method relies on conjointly learning a feature-extracting network and a set of class representations, or prototypes, which incorporate the error metric into their relative arrangement. Our approach allows for consistent improvement of the network's prediction with regard to the cost matrix. Furthermore, when the induced metric contains insight on the data structure, our approach improves the overall precision. Experiments on three different tasks and public datasets -- from agricultural time series classification to depth image semantic segmentation -- validate our approach.