 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Joint Representations of Videos and Sentences with Web Image Search
Aug 08, 2016
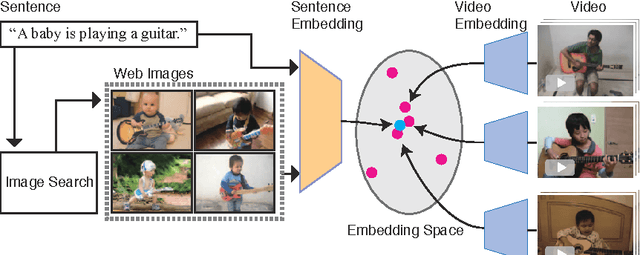
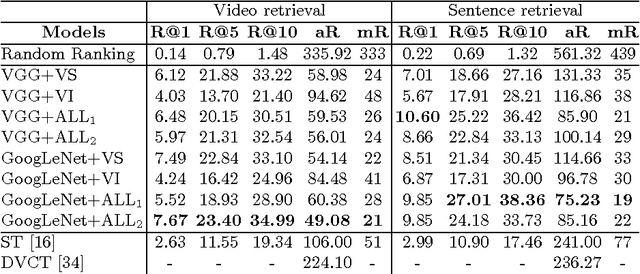
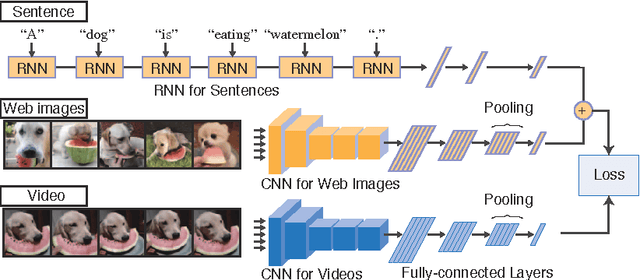
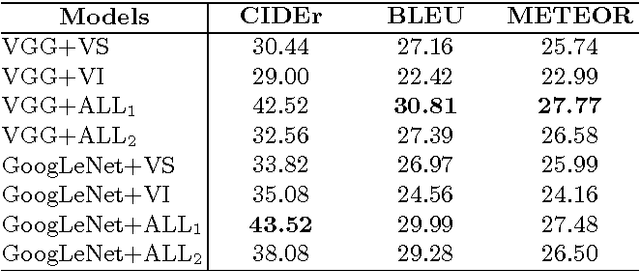
Our objective is video retrieval based on natural language queries. In addition, we consider the analogous problem of retrieving sentences or generating descriptions given an input video. Recent work has addressed the problem by embedding visual and textual inputs into a common space where semantic similarities correlate to distances. We also adopt the embedding approach, and make the following contributions: First, we utilize web image search in sentence embedding process to disambiguate fine-grained visual concepts. Second, we propose embedding models for sentence, image, and video inputs whose parameters are learned simultaneously. Finally, we show how the proposed model can be applied to description generation. Overall, we observe a clear improvement over the state-of-the-art methods in the video and sentence retrieval tasks. In description generation, the performance level is comparable to the current state-of-the-art, although our embeddings were trained for the retrieval tasks.
Vulnerability of Face Recognition Systems Against Composite Face Reconstruction Attack
Aug 23, 2020



Rounding confidence score is considered trivial but a simple and effective countermeasure to stop gradient descent based image reconstruction attacks. However, its capability in the face of more sophisticated reconstruction attacks is an uninvestigated research area. In this paper, we prove that, the face reconstruction attacks based on composite faces can reveal the inefficiency of rounding policy as countermeasure. We assume that, the attacker takes advantage of face composite parts which helps the attacker to get access to the most important features of the face or decompose it to the independent segments. Afterwards, decomposed segments are exploited as search parameters to create a search path to reconstruct optimal face. Face composition parts enable the attacker to violate the privacy of face recognition models even with a blind search. However, we assume that, the attacker may take advantage of random search to reconstruct the target face faster. The algorithm is started with random composition of face parts as initial face and confidence score is considered as fitness value. Our experiments show that, since the rounding policy as countermeasure can't stop the random search process, current face recognition systems are extremely vulnerable against such sophisticated attacks. To address this problem, we successfully test Face Detection Score Filtering (FDSF) as a countermeasure to protect the privacy of training data against proposed attack.
Micro-Facial Expression Recognition in Video Based on Optimal Convolutional Neural Network (MFEOCNN) Algorithm
Sep 29, 2020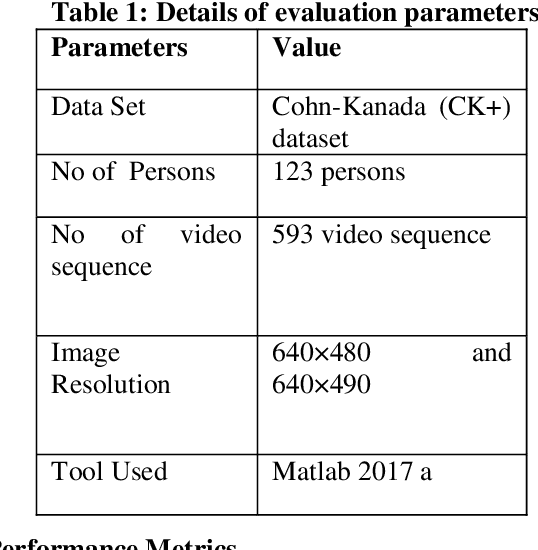
Facial expression is a standout amongst the most imperative features of human emotion recognition. For demonstrating the emotional states facial expressions are utilized by the people. In any case, recognition of facial expressions has persisted a testing and intriguing issue with regards to PC vision. Recognizing the Micro-Facial expression in video sequence is the main objective of the proposed approach. For efficient recognition, the proposed method utilizes the optimal convolution neural network. Here the proposed method considering the input dataset is the CK+ dataset. At first, by means of Adaptive median filtering preprocessing is performed in the input image. From the preprocessed output, the extracted features are Geometric features, Histogram of Oriented Gradients features and Local binary pattern features. The novelty of the proposed method is, with the help of Modified Lion Optimization (MLO) algorithm, the optimal features are selected from the extracted features. In a shorter computational time, it has the benefits of rapidly focalizing and effectively acknowledging with the aim of getting an overall arrangement or idea. Finally, the recognition is done by Convolution Neural network (CNN). Then the performance of the proposed MFEOCNN method is analysed in terms of false measures and recognition accuracy. This kind of emotion recognition is mainly used in medicine, marketing, E-learning, entertainment, law and monitoring. From the simulation, we know that the proposed approach achieves maximum recognition accuracy of 99.2% with minimum Mean Absolute Error (MAE) value. These results are compared with the existing for MicroFacial Expression Based Deep-Rooted Learning (MFEDRL), Convolutional Neural Network with Lion Optimization (CNN+LO) and Convolutional Neural Network (CNN) without optimization. The simulation of the proposed method is done in the working platform of MATLAB.
Learning to Have an Ear for Face Super-Resolution
Sep 27, 2019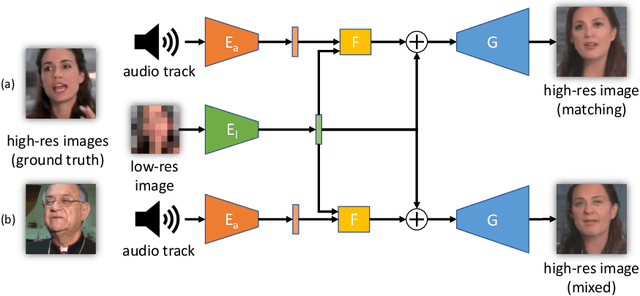
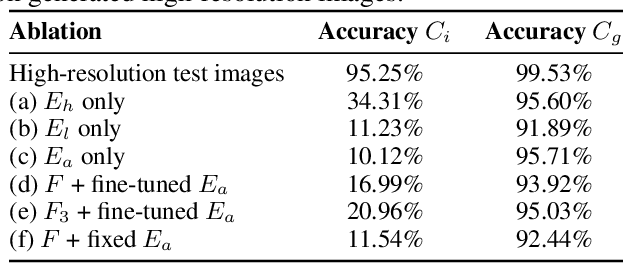
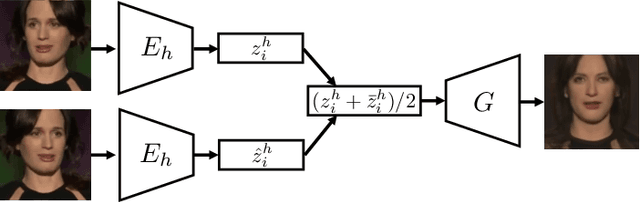
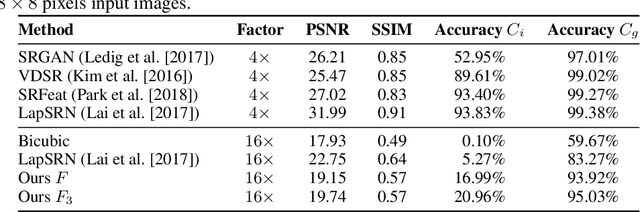
We propose a novel method to perform extreme (16x) face super-resolution by exploiting audio. Super-resolution is the task of recovering a high-resolution image from a low-resolution one. When the resolution of the input image is too low (e.g., 8x8 pixels), the loss of information is so dire that the details of the original identity have been lost. However, when the low-resolution image is extracted from a video, the audio track is also available. Because the audio carries information about the face identity, we propose to exploit it in the face reconstruction process. Towards this goal, we propose a model and a training procedure to extract information about the identity of a person from her audio track and to combine it with the information extracted from the low-resolution input image, which relates more to pose and colors of the face. We demonstrate that the combination of these two inputs yields high-resolution images that better capture the correct identity of the face. In particular, we show that audio can assist in recovering attributes such as the gender and the identity, and thus improve the correctness of the image reconstruction process. Our procedure does not make use of human annotation and thus can be easily trained with existing video datasets. Moreover, we show that our model allows one to mix low-resolution images and audio from different videos and to generate realistic faces with semantically meaningful combinations.
Exposing Deep-faked Videos by Anomalous Co-motion Pattern Detection
Aug 11, 2020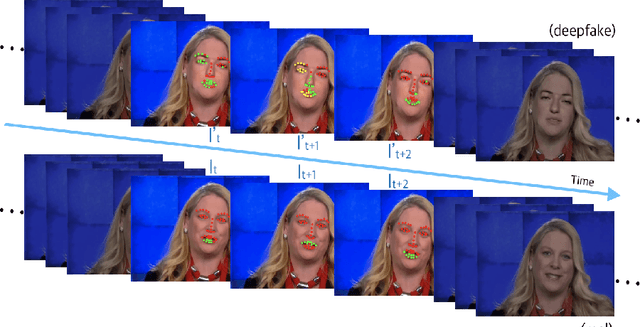
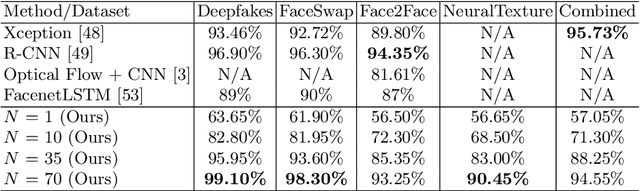
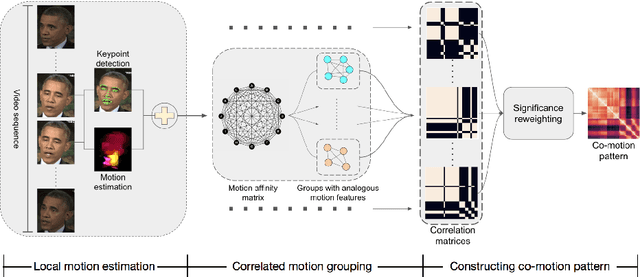

Recent deep learning based video synthesis approaches, in particular with applications that can forge identities such as "DeepFake", have raised great security concerns. Therefore, corresponding deep forensic methods are proposed to tackle this problem. However, existing methods are either based on unexplainable deep networks which greatly degrades the principal interpretability factor to media forensic, or rely on fragile image statistics such as noise pattern, which in real-world scenarios can be easily deteriorated by data compression. In this paper, we propose an fully-interpretable video forensic method that is designed specifically to expose deep-faked videos. To enhance generalizability on videos with various content, we model the temporal motion of multiple specific spatial locations in the videos to extract a robust and reliable representation, called Co-Motion Pattern. Such kind of conjoint pattern is mined across local motion features which is independent of the video contents so that the instance-wise variation can also be largely alleviated. More importantly, our proposed co-motion pattern possesses both superior interpretability and sufficient robustness against data compression for deep-faked videos. We conduct extensive experiments to empirically demonstrate the superiority and effectiveness of our approach under both classification and anomaly detection evaluation settings against the state-of-the-art deep forensic methods.
Transfer Learning for Protein Structure Classification and Function Inference at Low Resolution
Aug 11, 2020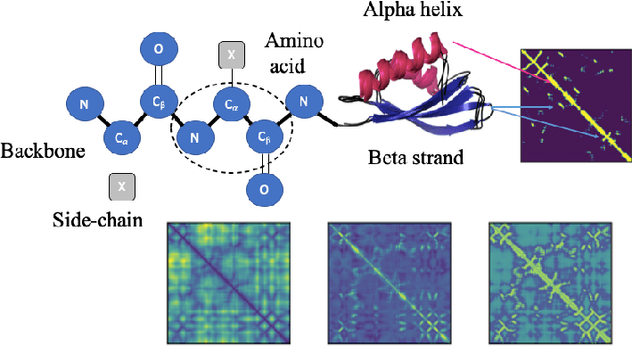
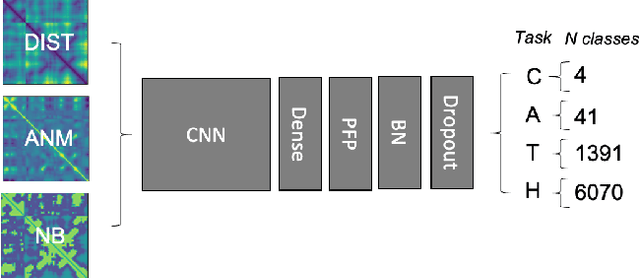
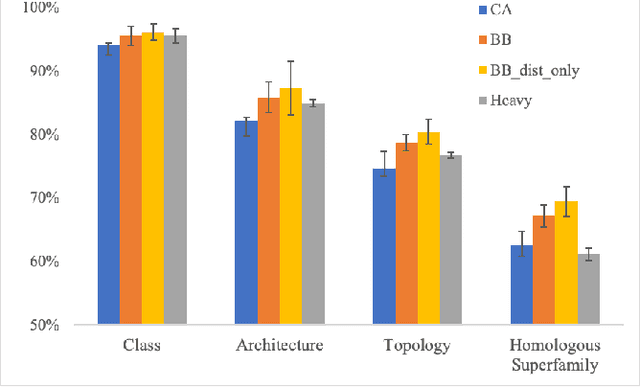

Structure determination is key to understanding protein function at a molecular level. Whilst significant advances have been made in predicting structure and function from amino acid sequence, researchers must still rely on expensive, time-consuming analytical methods to visualise detailed protein conformation. In this study, we demonstrate that it is possible to make accurate predictions of protein fold taxonomy from structures determined at low ($>$3 Angstroms) resolution, using a deep convolutional neural network trained on high-resolution structures ($\leq$3 Angstroms). Thus, we provide proof of concept for high-speed, low-cost protein structure classification at low resolution. We explore the relationship between the information content of the input image and the predictive power of the model, achieving state of the art performance on homologous superfamily prediction with maps of interatomic distance. Our findings contribute further evidence that inclusion of both amino acid alpha and beta carbon geometry in these maps improves classification performance over purely alpha carbon representations, and show that side-chain information may not be necessary for fine-grained structure predictions. Finally, we confirm that high-resolution, low-resolution and NMR-determined structures inhabit a common feature space, and thus provide a theoretical basis for mapping between domains to boost resolution.
An efficient iterative thresholding method for image segmentation
Aug 12, 2016
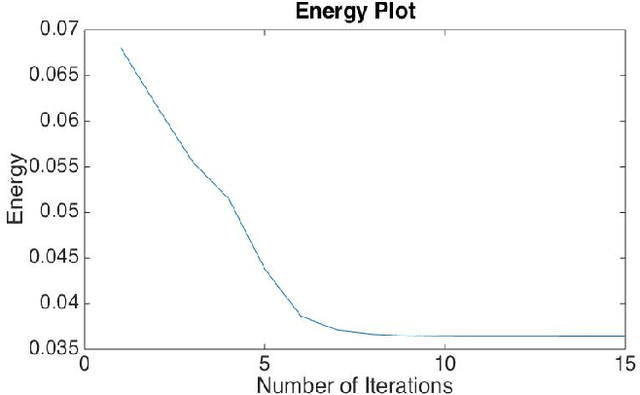
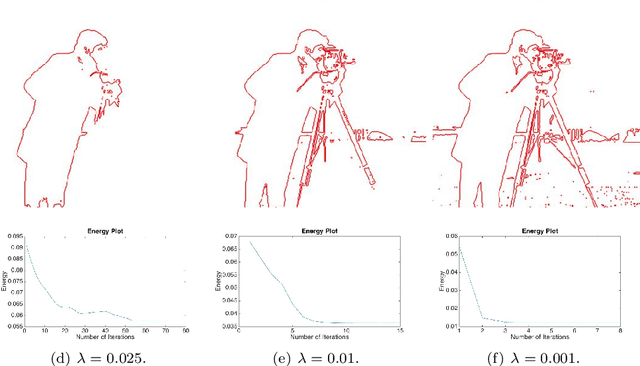
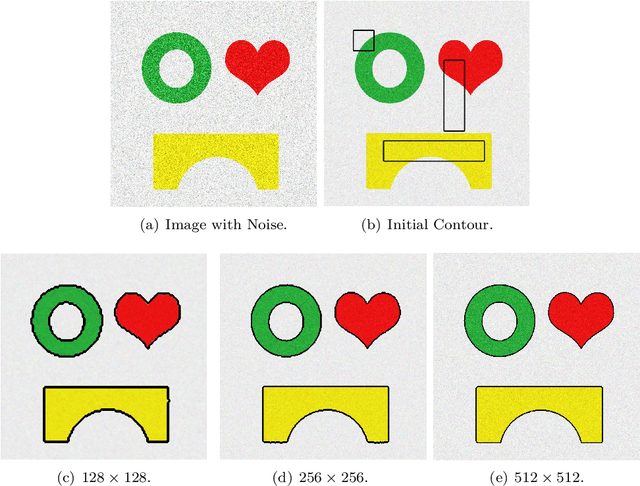
We proposed an efficient iterative thresholding method for multi-phase image segmentation. The algorithm is based on minimizing piecewise constant Mumford-Shah functional in which the contour length (or perimeter) is approximated by a non-local multi-phase energy. The minimization problem is solved by an iterative method. Each iteration consists of computing simple convolutions followed by a thresholding step. The algorithm is easy to implement and has the optimal complexity $O(N \log N)$ per iteration. We also show that the iterative algorithm has the total energy decaying property. We present some numerical results to show the efficiency of our method.
Bidirectional Graph Reasoning Network for Panoptic Segmentation
Apr 14, 2020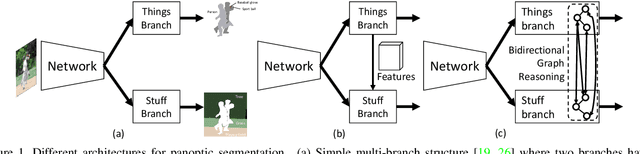
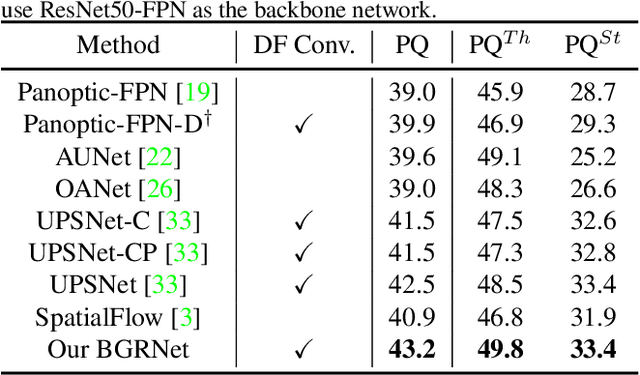
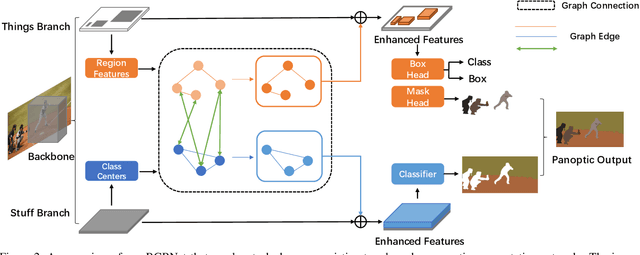

Recent researches on panoptic segmentation resort to a single end-to-end network to combine the tasks of instance segmentation and semantic segmentation. However, prior models only unified the two related tasks at the architectural level via a multi-branch scheme or revealed the underlying correlation between them by unidirectional feature fusion, which disregards the explicit semantic and co-occurrence relations among objects and background. Inspired by the fact that context information is critical to recognize and localize the objects, and inclusive object details are significant to parse the background scene, we thus investigate on explicitly modeling the correlations between object and background to achieve a holistic understanding of an image in the panoptic segmentation task. We introduce a Bidirectional Graph Reasoning Network (BGRNet), which incorporates graph structure into the conventional panoptic segmentation network to mine the intra-modular and intermodular relations within and between foreground things and background stuff classes. In particular, BGRNet first constructs image-specific graphs in both instance and semantic segmentation branches that enable flexible reasoning at the proposal level and class level, respectively. To establish the correlations between separate branches and fully leverage the complementary relations between things and stuff, we propose a Bidirectional Graph Connection Module to diffuse information across branches in a learnable fashion. Experimental results demonstrate the superiority of our BGRNet that achieves the new state-of-the-art performance on challenging COCO and ADE20K panoptic segmentation benchmarks.
The Analysis of Local Motion and Deformation in Image Sequences Inspired by Physical Electromagnetic Interaction
Oct 12, 2016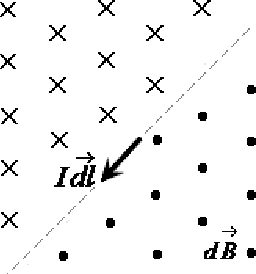
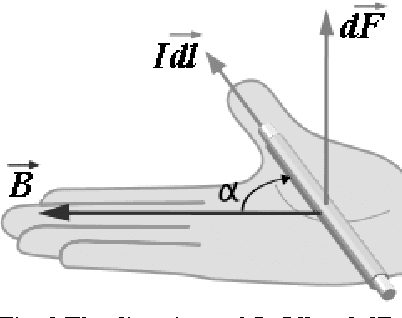

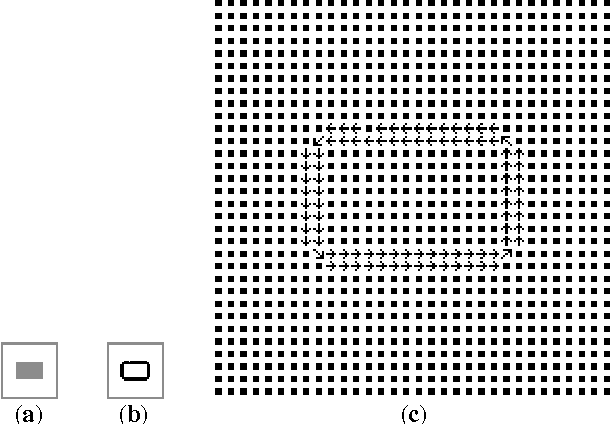
In order to analyze the moving and deforming of the objects in image sequence, a novel way is presented to analyze the local changes of object edges between two related images (such as two adjacent frames in a video sequence), which is inspired by the physical electromagnetic interaction. The changes of edge between adjacent frames in sequences are analyzed by simulation of virtual current interaction, which can reflect the change of the object's position or shape. The virtual current along the main edge line is proposed based on the significant edge extraction. Then the virtual interaction between the current elements in the two related images is studied by imitating the interaction between physical current-carrying wires. The experimental results prove that the distribution of magnetic forces on the current elements in one image applied by the other can reflect the local change of edge lines from one image to the other, which is important in further analysis.
* 15 pages, 23 figures. arXiv admin note: substantial text overlap with arXiv:1610.03615, arXiv:1610.02762
Invert to Learn to Invert
Nov 25, 2019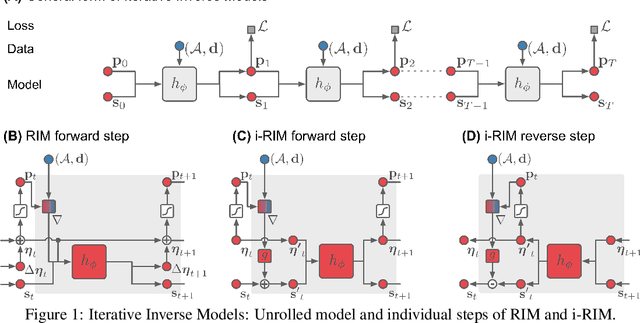
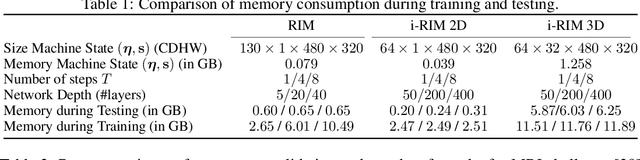
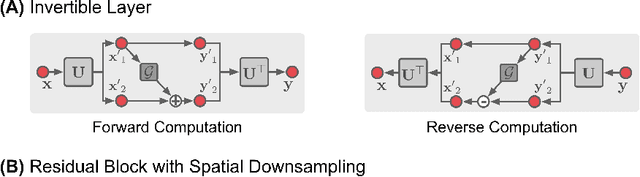
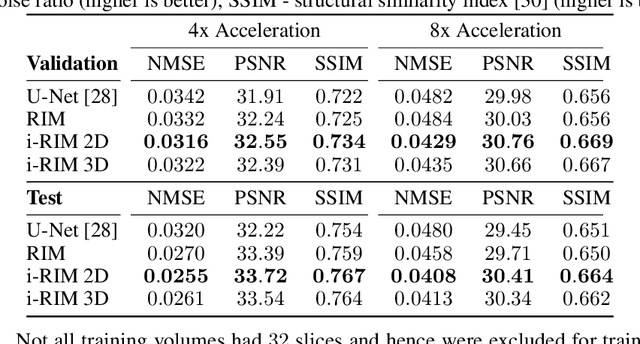
Iterative learning to infer approaches have become popular solvers for inverse problems. However, their memory requirements during training grow linearly with model depth, limiting in practice model expressiveness. In this work, we propose an iterative inverse model with constant memory that relies on invertible networks to avoid storing intermediate activations. As a result, the proposed approach allows us to train models with 400 layers on 3D volumes in an MRI image reconstruction task. In experiments on a public data set, we demonstrate that these deeper, and thus more expressive, networks perform state-of-the-art image reconstruction.