 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Impute: A General Framework for Semi-supervised Learning
Dec 22, 2019
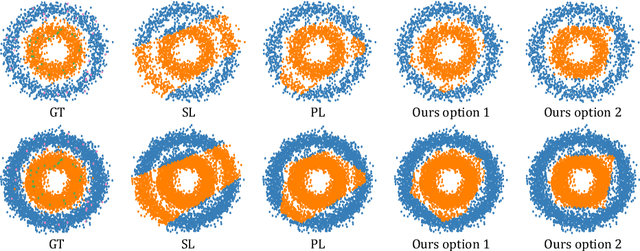
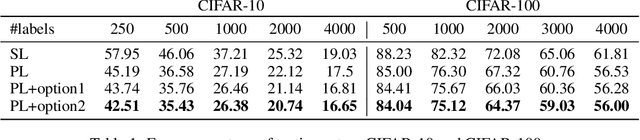
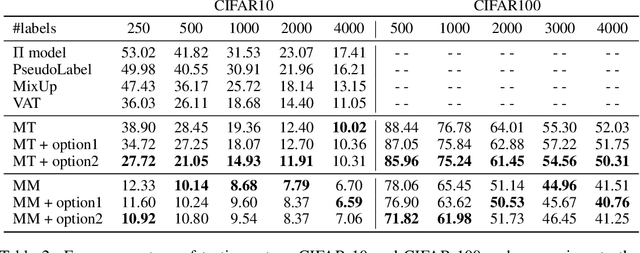
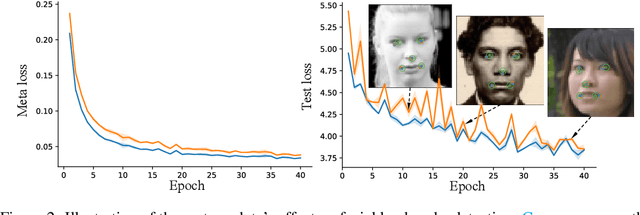
Recent semi-supervised learning methods have shown to achieve comparable results to their supervised counterparts while using only a small portion of labels in image classification tasks thanks to their regularization strategies. In this paper, we take a more direct approach for semi-supervised learning and propose learning to impute the labels of unlabeled samples such that a network achieves better generalization when it is trained on these labels. We pose the problem in a learning-to-learn formulation which can easily be incorporated to the state-of-the-art semi-supervised techniques and boost their performance especially when the labels are limited. We demonstrate that our method is applicable to both classification and regression problems including image classification and facial landmark detection tasks.
Enabling Highly Efficient Capsule Networks Processing Through A PIM-Based Architecture Design
Nov 07, 2019



In recent years, the CNNs have achieved great successes in the image processing tasks, e.g., image recognition and object detection. Unfortunately, traditional CNN's classification is found to be easily misled by increasingly complex image features due to the usage of pooling operations, hence unable to preserve accurate position and pose information of the objects. To address this challenge, a novel neural network structure called Capsule Network has been proposed, which introduces equivariance through capsules to significantly enhance the learning ability for image segmentation and object detection. Due to its requirement of performing a high volume of matrix operations, CapsNets have been generally accelerated on modern GPU platforms that provide highly optimized software library for common deep learning tasks. However, based on our performance characterization on modern GPUs, CapsNets exhibit low efficiency due to the special program and execution features of their routing procedure, including massive unshareable intermediate variables and intensive synchronizations, which are very difficult to optimize at software level. To address these challenges, we propose a hybrid computing architecture design named \textit{PIM-CapsNet}. It preserves GPU's on-chip computing capability for accelerating CNN types of layers in CapsNet, while pipelining with an off-chip in-memory acceleration solution that effectively tackles routing procedure's inefficiency by leveraging the processing-in-memory capability of today's 3D stacked memory. Using routing procedure's inherent parallellization feature, our design enables hierarchical improvements on CapsNet inference efficiency through minimizing data movement and maximizing parallel processing in memory.
Deep Robust Clustering by Contrastive Learning
Aug 07, 2020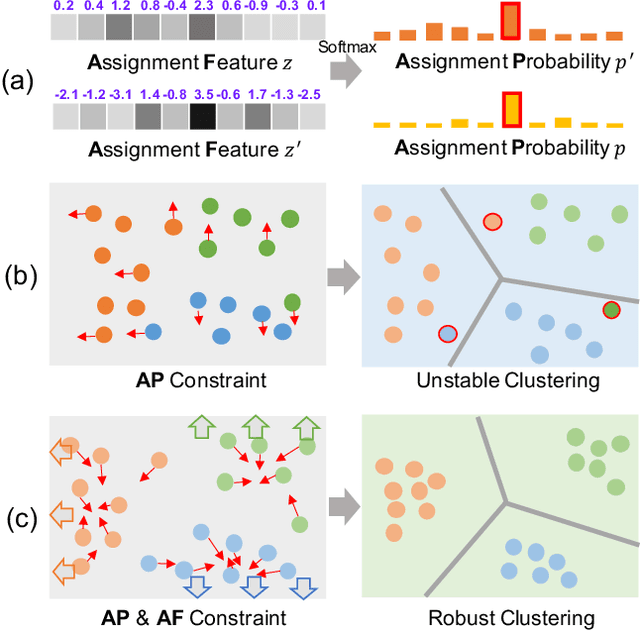
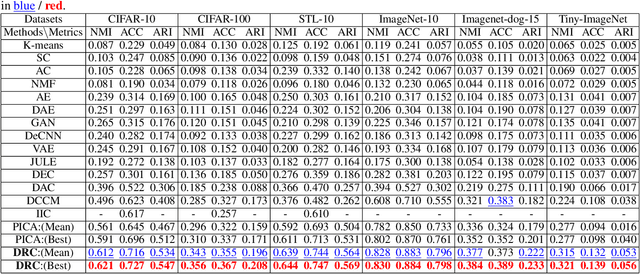
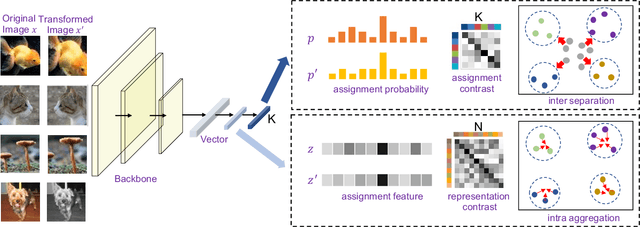

Recently, many unsupervised deep learning methods have been proposed to learn clustering with unlabelled data. By introducing data augmentation, most of the latest methods look into deep clustering from the perspective that the original image and its tansformation should share similar semantic clustering assignment. However, the representation features before softmax activation function could be quite different even the assignment probability is very similar since softmax is only sensitive to the maximum value. This may result in high intra-class diversities in the representation feature space, which will lead to unstable local optimal and thus harm the clustering performance. By investigating the internal relationship between mutual information and contrastive learning, we summarized a general framework that can turn any maximizing mutual information into minimizing contrastive loss. We apply it to both the semantic clustering assignment and representation feature and propose a novel method named Deep Robust Clustering by Contrastive Learning (DRC). Different to existing methods, DRC aims to increase inter-class diver-sities and decrease intra-class diversities simultaneously and achieve more robust clustering results. Extensive experiments on six widely-adopted deep clustering benchmarks demonstrate the superiority of DRC in both stability and accuracy. e.g., attaining 71.6% mean accuracy on CIFAR-10, which is 7.1% higher than state-of-the-art results.
Frequency Separation for Real-World Super-Resolution
Nov 18, 2019
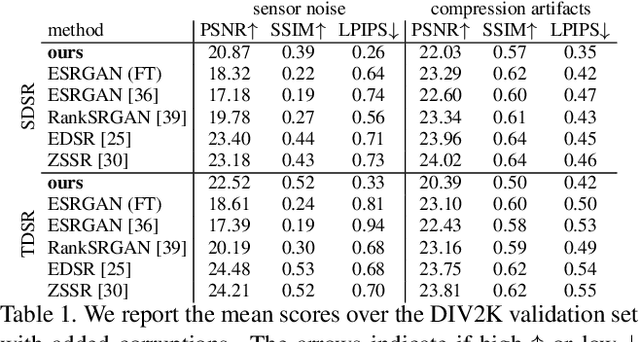

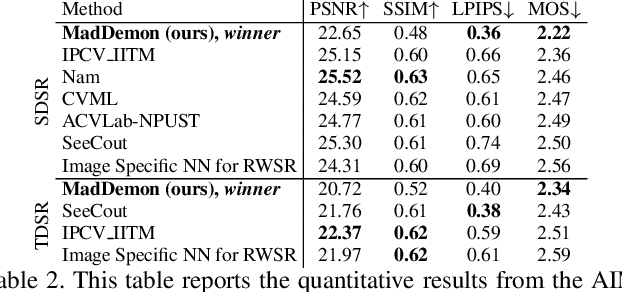
Most of the recent literature on image super-resolution (SR) assumes the availability of training data in the form of paired low resolution (LR) and high resolution (HR) images or the knowledge of the downgrading operator (usually bicubic downscaling). While the proposed methods perform well on standard benchmarks, they often fail to produce convincing results in real-world settings. This is because real-world images can be subject to corruptions such as sensor noise, which are severely altered by bicubic downscaling. Therefore, the models never see a real-world image during training, which limits their generalization capabilities. Moreover, it is cumbersome to collect paired LR and HR images in the same source domain. To address this problem, we propose DSGAN to introduce natural image characteristics in bicubically downscaled images. It can be trained in an unsupervised fashion on HR images, thereby generating LR images with the same characteristics as the original images. We then use the generated data to train a SR model, which greatly improves its performance on real-world images. Furthermore, we propose to separate the low and high image frequencies and treat them differently during training. Since the low frequencies are preserved by downsampling operations, we only require adversarial training to modify the high frequencies. This idea is applied to our DSGAN model as well as the SR model. We demonstrate the effectiveness of our method in several experiments through quantitative and qualitative analysis. Our solution is the winner of the AIM Challenge on Real World SR at ICCV 2019.
Pose-aware Adversarial Domain Adaptation for Personalized Facial Expression Recognition
Jul 12, 2020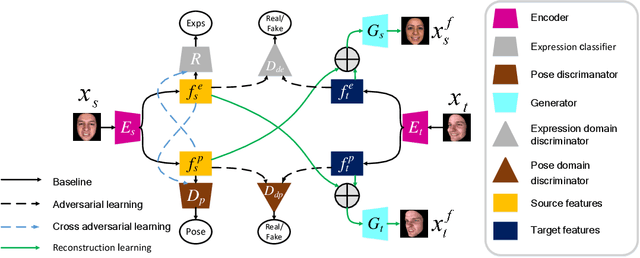
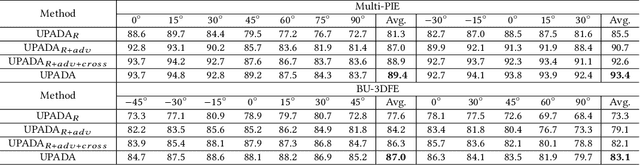
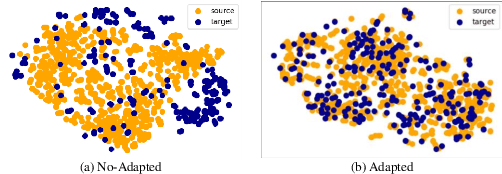
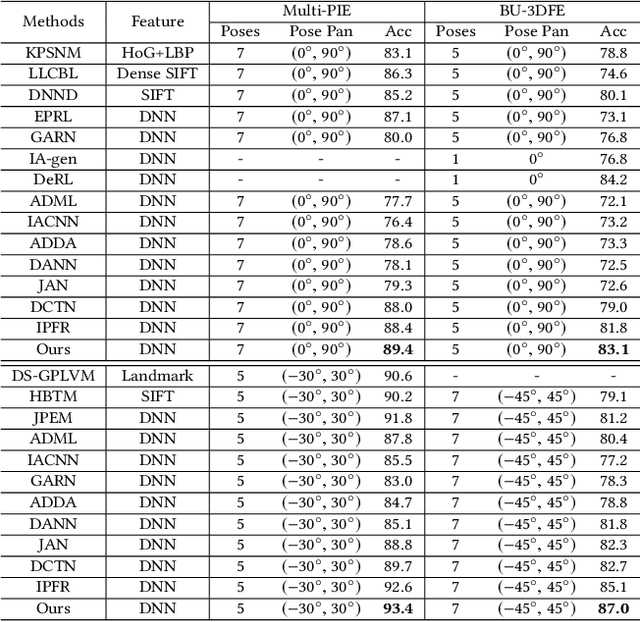
Current facial expression recognition methods fail to simultaneously cope with pose and subject variations. In this paper, we propose a novel unsupervised adversarial domain adaptation method which can alleviate both variations at the same time. Specially, our method consists of three learning strategies: adversarial domain adaptation learning, cross adversarial feature learning, and reconstruction learning. The first aims to learn pose- and expression-related feature representations in the source domain and adapt both feature distributions to that of the target domain by imposing adversarial learning. By using personalized adversarial domain adaptation, this learning strategy can alleviate subject variations and exploit information from the source domain to help learning in the target domain. The second serves to perform feature disentanglement between pose- and expression-related feature representations by impulsing pose-related feature representations expression-undistinguished and the expression-related feature representations pose-undistinguished. The last can further boost feature learning by applying face image reconstructions so that the learned expression-related feature representations are more pose- and identity-robust. Experimental results on four benchmark datasets demonstrate the effectiveness of the proposed method.
RSL-Net: Localising in Satellite Images From a Radar on the Ground
Jan 09, 2020
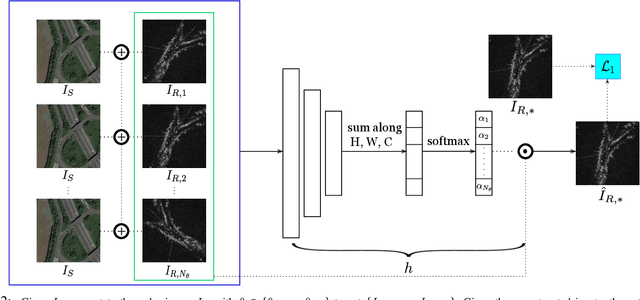

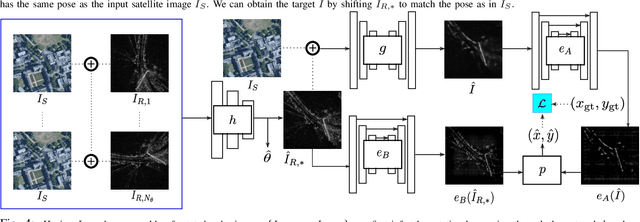
This paper is about localising a vehicle in an overhead image using FMCW radar mounted on a ground vehicle. FMCW radar offers extraordinary promise and efficacy for vehicle localisation. It is impervious to all weather types and lighting conditions. However the complexity of the interactions between millimetre radar wave and the physical environment makes it a challenging domain. Infrastructure-free large-scale radar-based localisation is in its infancy. Typically here a map is built and suitable techniques, compatible with the nature of sensor, are brought to bear. In this work we eschew the need for a radar-based map; instead we simply use an overhead image -- a resource readily available everywhere. This paper introduces a method that not only naturally deals with the complexity of the signal type but does so in the context of cross modal processing.
Discriminative Autoencoder for Feature Extraction: Application to Character Recognition
Dec 11, 2019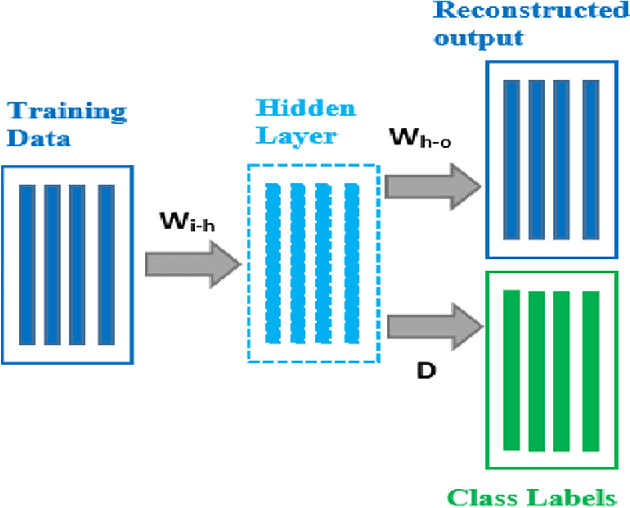
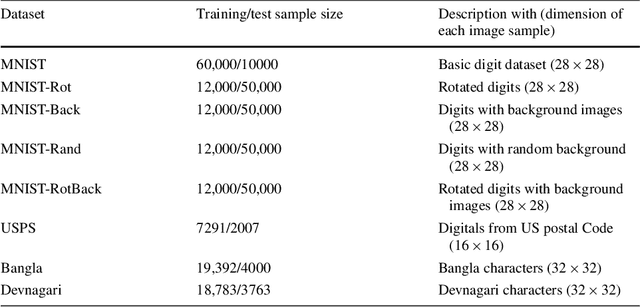

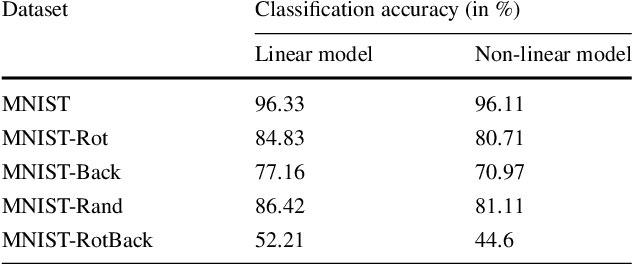
Conventionally, autoencoders are unsupervised representation learning tools. In this work, we propose a novel discriminative autoencoder. Use of supervised discriminative learning ensures that the learned representation is robust to variations commonly encountered in image datasets. Using the basic discriminating autoencoder as a unit, we build a stacked architecture aimed at extracting relevant representation from the training data. The efficiency of our feature extraction algorithm ensures a high classification accuracy with even simple classification schemes like KNN (K-nearest neighbor). We demonstrate the superiority of our model for representation learning by conducting experiments on standard datasets for character/image recognition and subsequent comparison with existing supervised deep architectures like class sparse stacked autoencoder and discriminative deep belief network.
Tackling the Unannotated: Scene Graph Generation with Bias-Reduced Models
Aug 18, 2020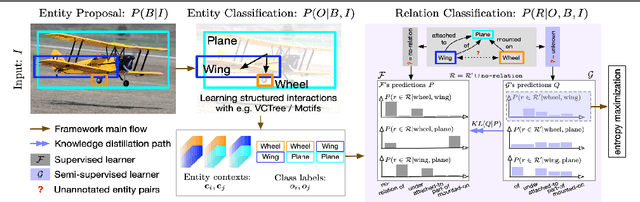
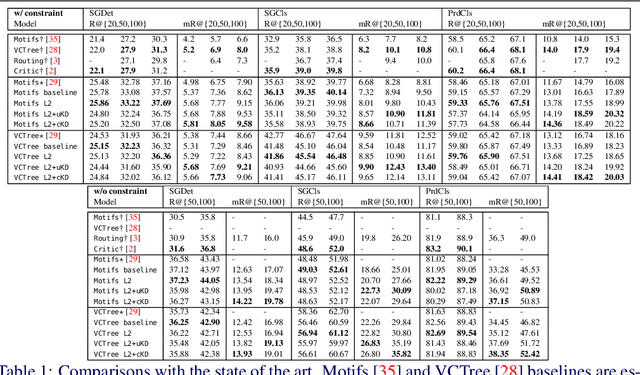
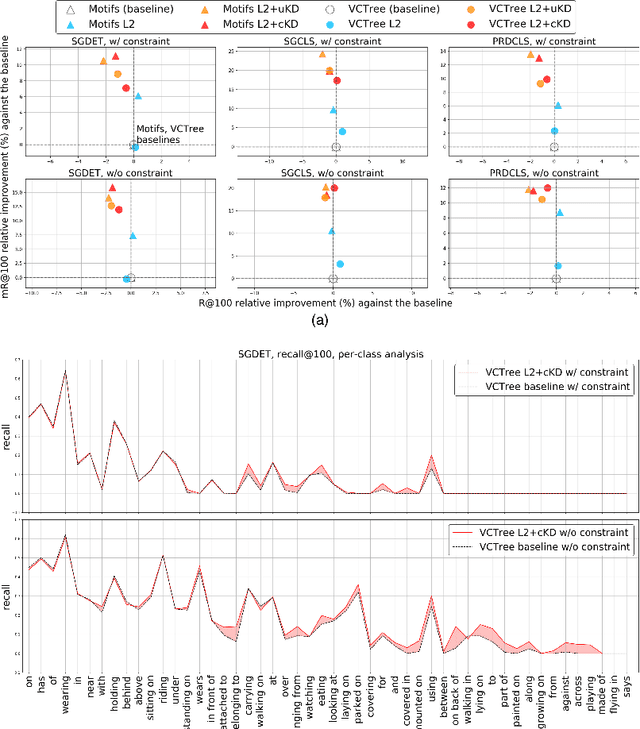
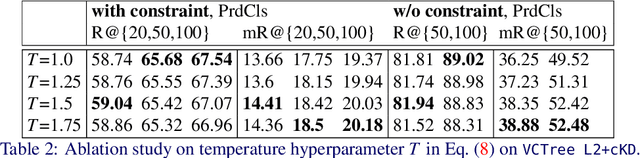
Predicting a scene graph that captures visual entities and their interactions in an image has been considered a crucial step towards full scene comprehension. Recent scene graph generation (SGG) models have shown their capability of capturing the most frequent relations among visual entities. However, the state-of-the-art results are still far from satisfactory, e.g. models can obtain 31% in overall recall R@100, whereas the likewise important mean class-wise recall mR@100 is only around 8% on Visual Genome (VG). The discrepancy between R and mR results urges to shift the focus from pursuing a high R to a high mR with a still competitive R. We suspect that the observed discrepancy stems from both the annotation bias and sparse annotations in VG, in which many visual entity pairs are either not annotated at all or only with a single relation when multiple ones could be valid. To address this particular issue, we propose a novel SGG training scheme that capitalizes on self-learned knowledge. It involves two relation classifiers, one offering a less biased setting for the other to base on. The proposed scheme can be applied to most of the existing SGG models and is straightforward to implement. We observe significant relative improvements in mR (between +6.6% and +20.4%) and competitive or better R (between -2.4% and 0.3%) across all standard SGG tasks.
Attribute Propagation Network for Graph Zero-shot Learning
Sep 24, 2020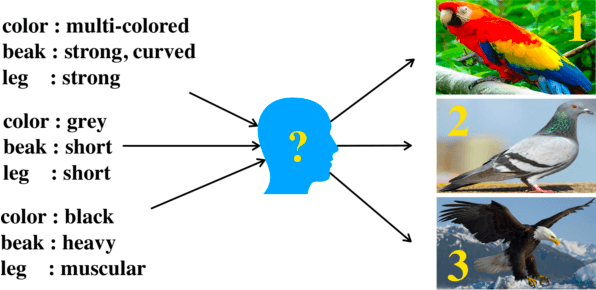

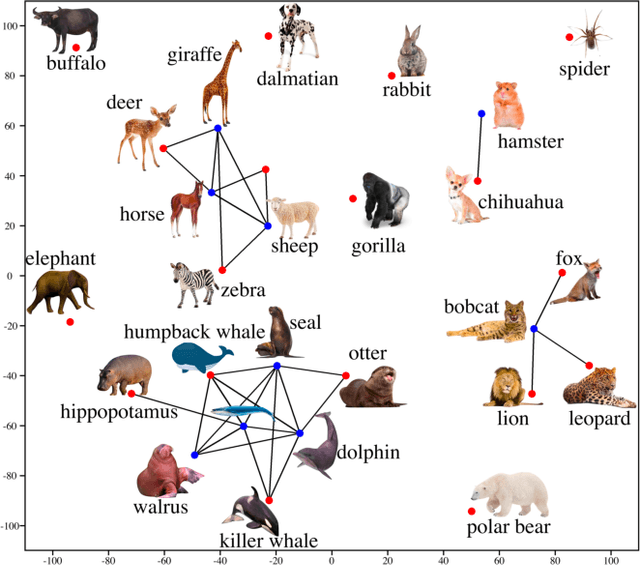
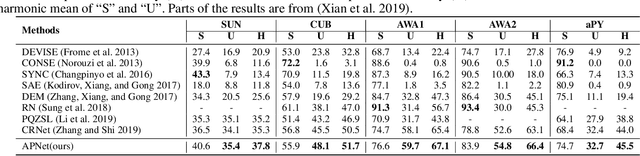
The goal of zero-shot learning (ZSL) is to train a model to classify samples of classes that were not seen during training. To address this challenging task, most ZSL methods relate unseen test classes to seen(training) classes via a pre-defined set of attributes that can describe all classes in the same semantic space, so the knowledge learned on the training classes can be adapted to unseen classes. In this paper, we aim to optimize the attribute space for ZSL by training a propagation mechanism to refine the semantic attributes of each class based on its neighbors and related classes on a graph of classes. We show that the propagated attributes can produce classifiers for zero-shot classes with significantly improved performance in different ZSL settings. The graph of classes is usually free or very cheap to acquire such as WordNet or ImageNet classes. When the graph is not provided, given pre-defined semantic embeddings of the classes, we can learn a mechanism to generate the graph in an end-to-end manner along with the propagation mechanism. However, this graph-aided technique has not been well-explored in the literature. In this paper, we introduce the attribute propagation network (APNet), which is composed of 1) a graph propagation model generating attribute vector for each class and 2) a parameterized nearest neighbor (NN) classifier categorizing an image to the class with the nearest attribute vector to the image's embedding. For better generalization over unseen classes, different from previous methods, we adopt a meta-learning strategy to train the propagation mechanism and the similarity metric for the NN classifier on multiple sub-graphs, each associated with a classification task over a subset of training classes. In experiments with two zero-shot learning settings and five benchmark datasets, APNet achieves either compelling performance or new state-of-the-art results.
Live Face De-Identification in Video
Nov 19, 2019

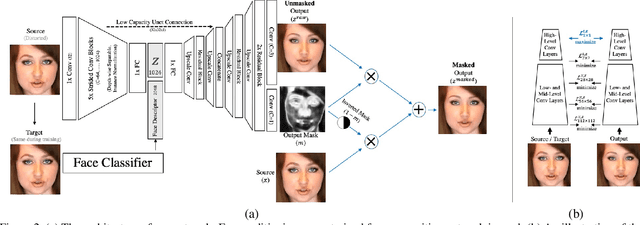
We propose a method for face de-identification that enables fully automatic video modification at high frame rates. The goal is to maximally decorrelate the identity, while having the perception (pose, illumination and expression) fixed. We achieve this by a novel feed-forward encoder-decoder network architecture that is conditioned on the high-level representation of a person's facial image. The network is global, in the sense that it does not need to be retrained for a given video or for a given identity, and it creates natural looking image sequences with little distortion in time.
* ICCV 2019