 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Deeper Look into Hybrid Images
Feb 10, 2020
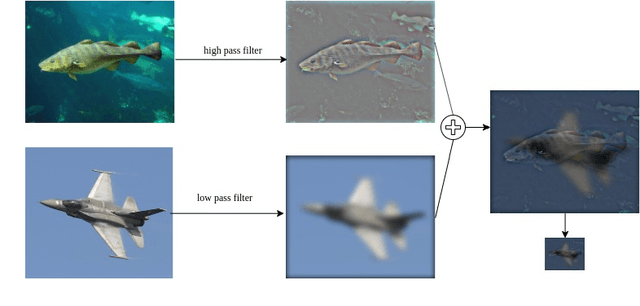

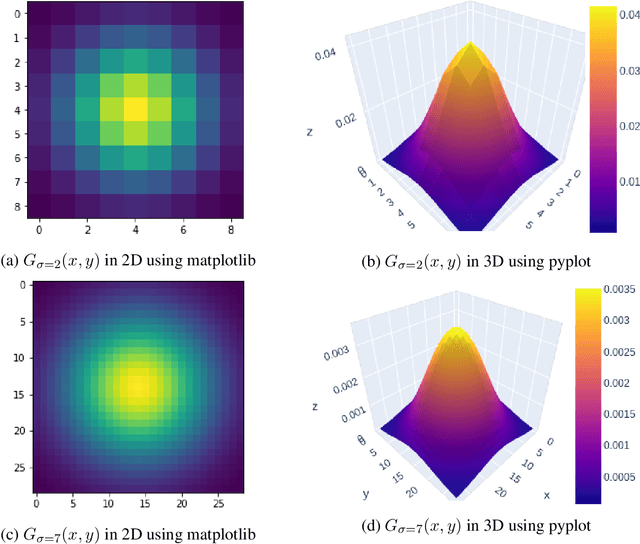

$Hybrid$ $images$ was first introduced by Olivia et al., that produced static images with two interpretations such that the images changes as a function of viewing distance. Hybrid images are built by studying human processing of multiscale images and are motivated by masking studies in visual perception. The first introduction of hybrid images showed that two images can be blend together with a high pass filter and a low pass filter in such a way that when the blended image is viewed from a distance, the high pass filter fades away and the low pass filter becomes prominent. Our main aim here is to study and review the original paper by changing and tweaking certain parameters to see how they affect the quality of the blended image produced. We have used exhaustively different set of images and filters to see how they function and whether this can be used in a real time system or not.
Alleviating the Burden of Labeling: Sentence Generation by Attention Branch Encoder-Decoder Network
Jul 09, 2020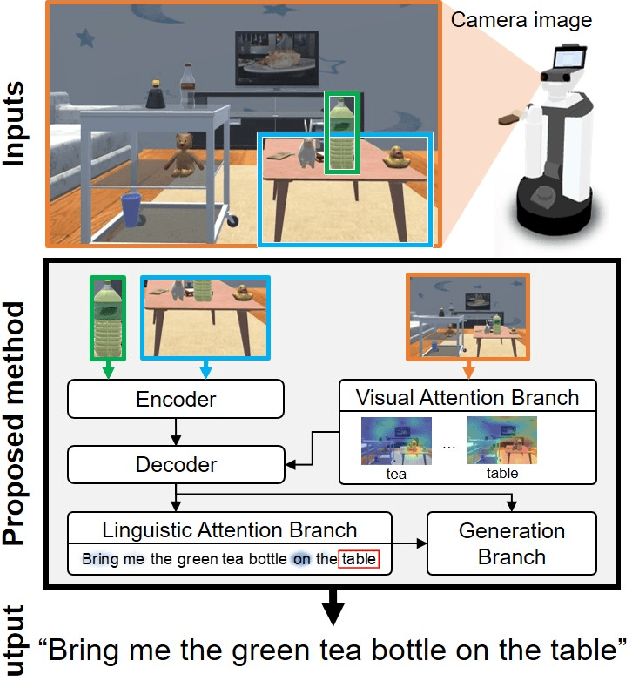

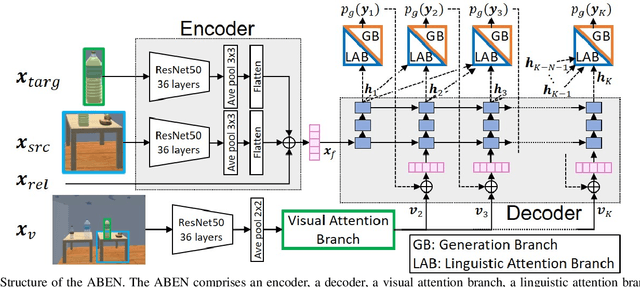
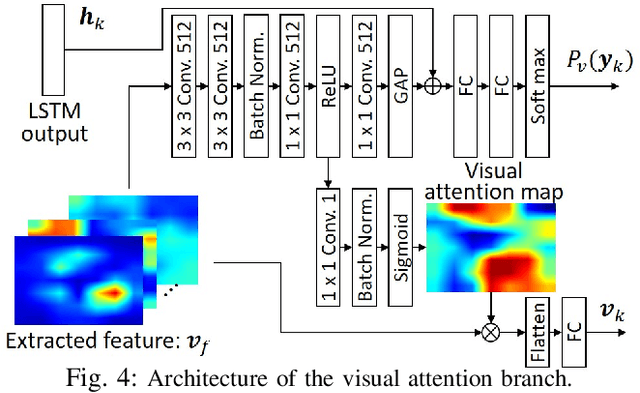
Domestic service robots (DSRs) are a promising solution to the shortage of home care workers. However, one of the main limitations of DSRs is their inability to interact naturally through language. Recently, data-driven approaches have been shown to be effective for tackling this limitation; however, they often require large-scale datasets, which is costly. Based on this background, we aim to perform automatic sentence generation of fetching instructions: for example, "Bring me a green tea bottle on the table." This is particularly challenging because appropriate expressions depend on the target object, as well as its surroundings. In this paper, we propose the attention branch encoder--decoder network (ABEN), to generate sentences from visual inputs. Unlike other approaches, the ABEN has multimodal attention branches that use subword-level attention and generate sentences based on subword embeddings. In experiments, we compared the ABEN with a baseline method using four standard metrics in image captioning. Results show that the ABEN outperformed the baseline in terms of these metrics.
Comparative analysis of evolutionary algorithms for image enhancement
Dec 18, 2013
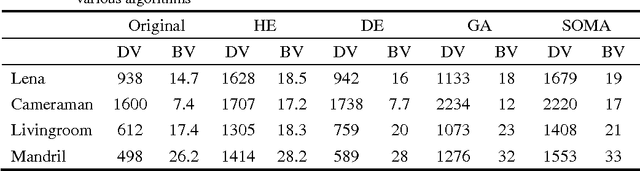
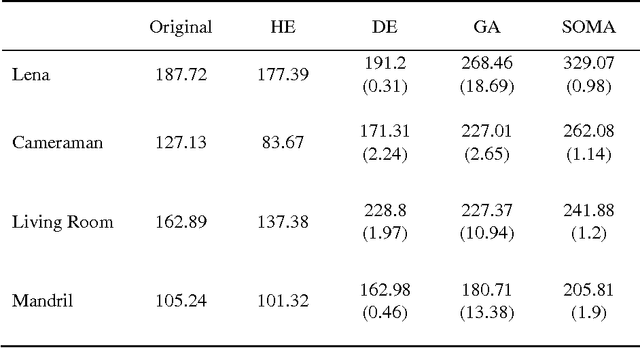
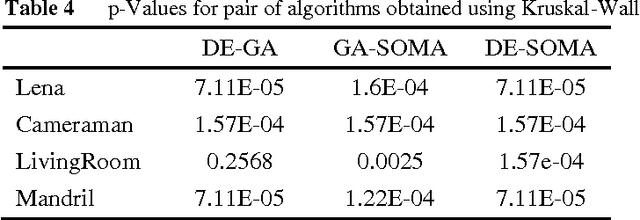
Evolutionary algorithms are metaheuristic techniques that derive inspiration from the natural process of evolution. They can efficiently solve (generate acceptable quality of solution in reasonable time) complex optimization (NP-Hard) problems. In this paper, automatic image enhancement is considered as an optimization problem and three evolutionary algorithms (Genetic Algorithm, Differential Evolution and Self Organizing Migration Algorithm) are employed to search for an optimum solution. They are used to find an optimum parameter set for an image enhancement transfer function. The aim is to maximize a fitness criterion which is a measure of image contrast and the visibility of details in the enhanced image. The enhancement results obtained using all three evolutionary algorithms are compared amongst themselves and also with the output of histogram equalization method.
Adversarial Attacks and Defense on Texts: A Survey
Jun 14, 2020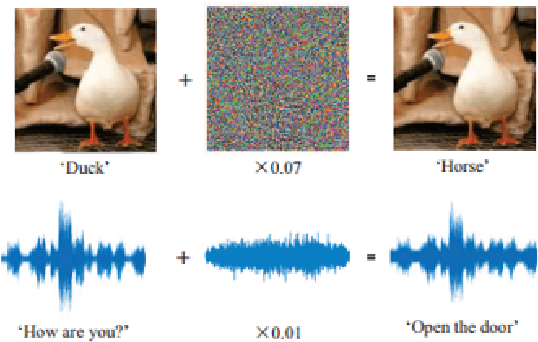
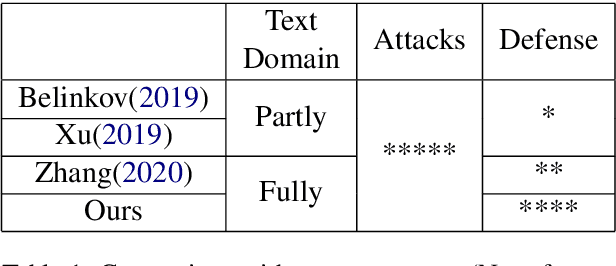
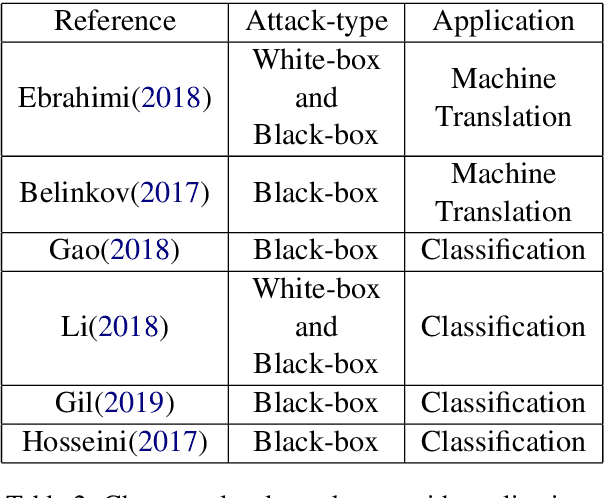
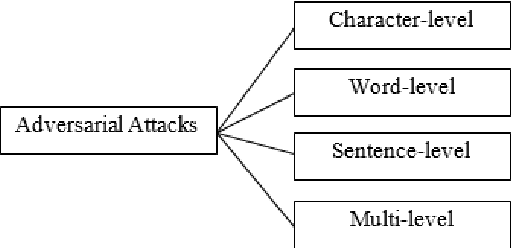
Deep learning models have been used widely for various purposes in recent years in object recognition, self-driving cars, face recognition, speech recognition, sentiment analysis, and many others. However, in recent years it has been shown that these models possess weakness to noises which force the model to misclassify. This issue has been studied profoundly in the image and audio domain. Very little has been studied on this issue concerning textual data. Even less survey on this topic has been performed to understand different types of attacks and defense techniques. In this manuscript, we accumulated and analyzed different attacking techniques and various defense models to provide a more comprehensive idea. Later we point out some of the interesting findings of all papers and challenges that need to be overcome to move forward in this field.
OptiBox: Breaking the Limits of Proposals for Visual Grounding
Nov 29, 2019
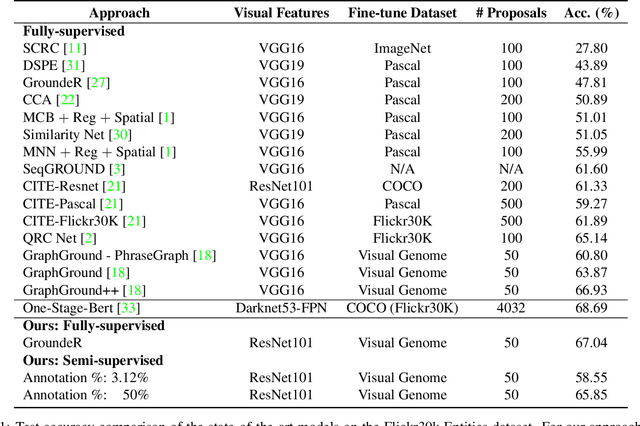
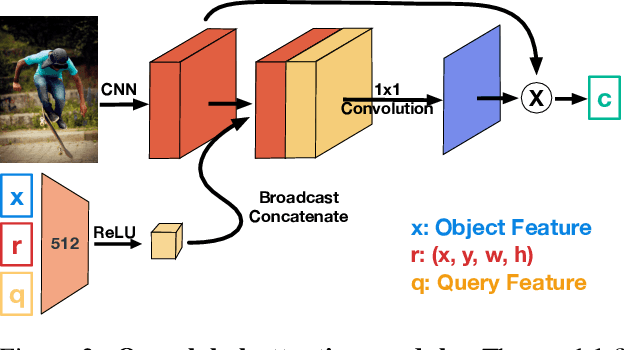

The problem of language grounding has attracted much attention in recent years due to its pivotal role in more general image-lingual high level reasoning tasks (e.g., image captioning, VQA). Despite the tremendous progress in visual grounding, the performance of most approaches has been hindered by the quality of bounding box proposals obtained in the early stages of all recent pipelines. To address this limitation, we propose a general progressive query-guided bounding box refinement architecture (OptiBox) that leverages global image encoding for added context. We apply this architecture in the context of the GroundeR model, first introduced in 2016, which has a number of unique and appealing properties, such as the ability to learn in the semi-supervised setting by leveraging cyclic language-reconstruction. Using GroundeR + OptiBox and a simple semantic language reconstruction loss that we propose, we achieve state-of-the-art grounding performance in the supervised setting on Flickr30k Entities dataset. More importantly, we are able to surpass many recent fully supervised models with only 50% of training data and perform competitively with as low as 3%.
Online Invariance Selection for Local Feature Descriptors
Jul 23, 2020
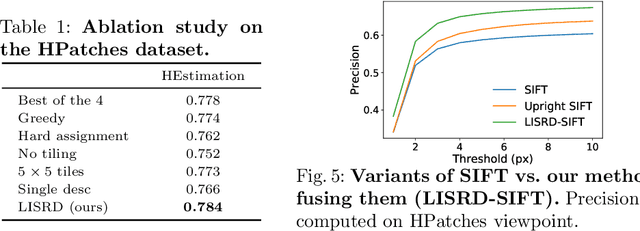
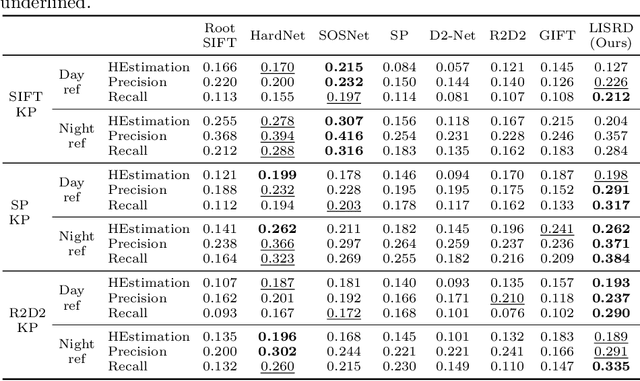
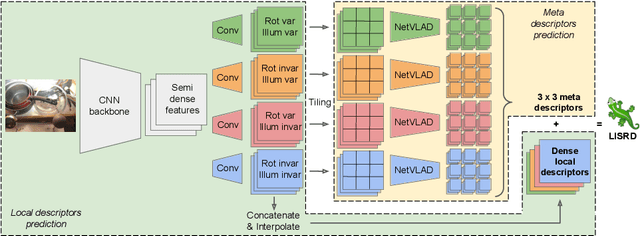
To be invariant, or not to be invariant: that is the question formulated in this work about local descriptors. A limitation of current feature descriptors is the trade-off between generalization and discriminative power: more invariance means less informative descriptors. We propose to overcome this limitation with a disentanglement of invariance in local descriptors and with an online selection of the most appropriate invariance given the context. Our framework consists in a joint learning of multiple local descriptors with different levels of invariance and of meta descriptors encoding the regional variations of an image. The similarity of these meta descriptors across images is used to select the right invariance when matching the local descriptors. Our approach, named Local Invariance Selection at Runtime for Descriptors (LISRD), enables descriptors to adapt to adverse changes in images, while remaining discriminative when invariance is not required. We demonstrate that our method can boost the performance of current descriptors and outperforms state-of-the-art descriptors in several matching tasks, when evaluated on challenging datasets with day-night illumination as well as viewpoint changes.
Blurred Image Classification based on Adaptive Dictionary
Oct 03, 2012
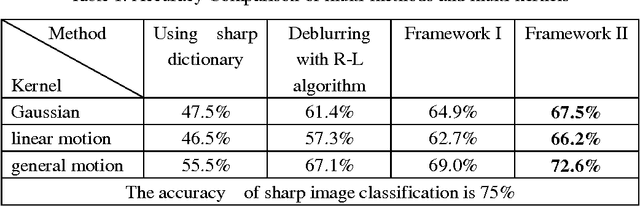

Two types of framework for blurred image classification based on adaptive dictionary are proposed. Given a blurred image, instead of image deblurring, the semantic category of the image is determined by blur insensitive sparse coefficients calculated depending on an adaptive dictionary. The dictionary is adaptive to the Point Spread Function (PSF) estimated from input blurred image. The PSF is assumed to be space invariant and inferred separately in one framework or updated combining with sparse coefficients calculation in an alternative and iterative algorithm in the other framework. The experiment has evaluated three types of blur, naming defocus blur, simple motion blur and camera shake blur. The experiment results confirm the effectiveness of the proposed frameworks.
* 10 pages,2 figures
Performance Evaluation of Deep Generative Models for Generating Hand-Written Character Images
Feb 26, 2020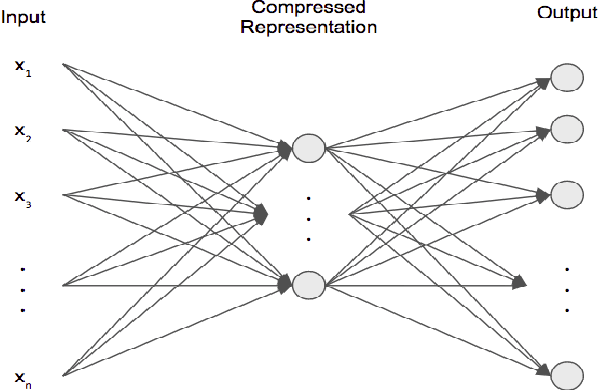
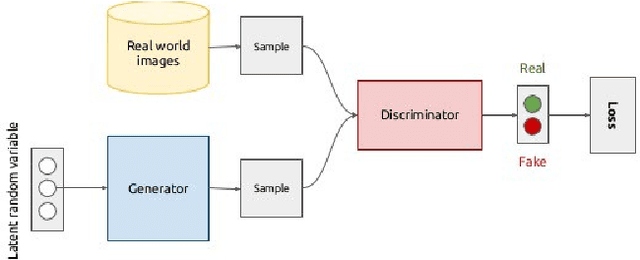
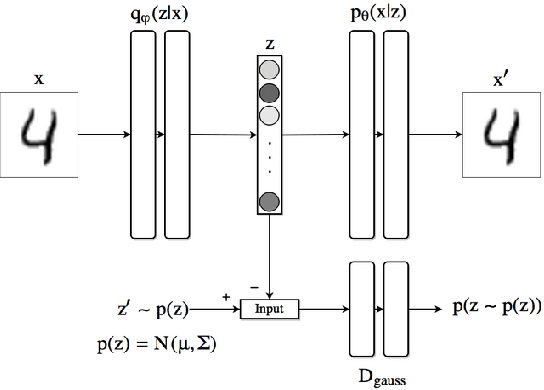
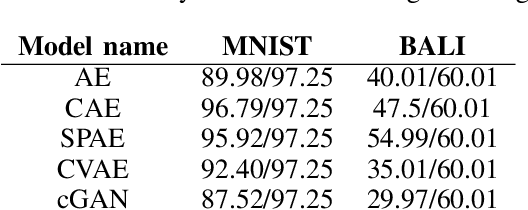
There have been many work in the literature on generation of various kinds of images such as Hand-Written characters (MNIST dataset), scene images (CIFAR-10 dataset), various objects images (ImageNet dataset), road signboard images (SVHN dataset) etc. Unfortunately, there have been very limited amount of work done in the domain of document image processing. Automatic image generation can lead to the enormous increase of labeled datasets with the help of only limited amount of labeled data. Various kinds of Deep generative models can be primarily divided into two categories. First category is auto-encoder (AE) and the second one is Generative Adversarial Networks (GANs). In this paper, we have evaluated various kinds of AE as well as GANs and have compared their performances on hand-written digits dataset (MNIST) and also on historical hand-written character dataset of Indonesian BALI language. Moreover, these generated characters are recognized by using character recognition tool for calculating the statistical performance of these generated characters with respect to original character images.
Exploiting Temporal Attention Features for Effective Denoising in Videos
Aug 05, 2020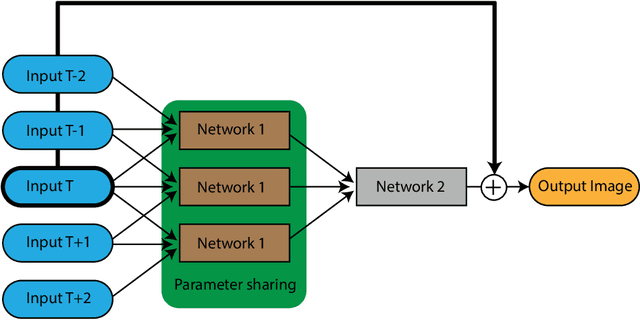

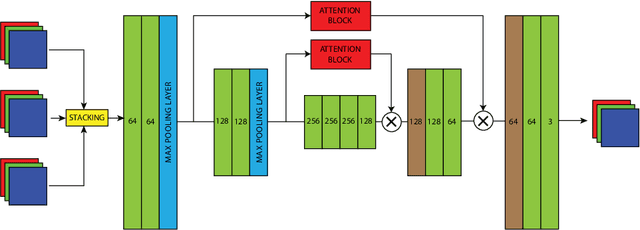
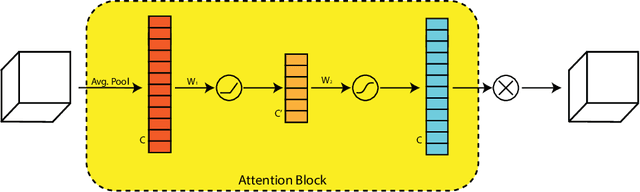
Video denoising has significant applications in diverse domains of computer vision, such as video-based object localization, text detection, and several others. An image denoising approach applied to video denoising results in flickering due to ignoring the temporal aspects of video frames. The proposed method makes use of the temporal as well as the spatial characteristics of video frames to form a two-stage denoising pipeline. Each stage uses a channel-wise attention mechanism to forward the encoder signal to the decoder side. The Attention Block used here is based on soft attention to rank the filters for effective learning. A key advantage of our approach is that it does not require prior information related to the amount of noise present in the video. Hence, it is quite suitable for application in real-life scenarios. We train the model on a large set of noisy videos along with their ground-truth. Experimental analysis shows that our approach performs denoising effectively and also surpasses existing methods in terms of efficiency and PSNR/SSIM metrics. In addition to this, we construct a new dataset for training video denoising models and also share the trained model online for further comparative studies.
Journey Towards Tiny Perceptual Super-Resolution
Jul 08, 2020

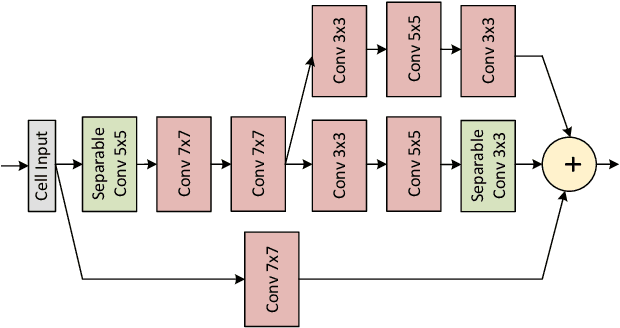
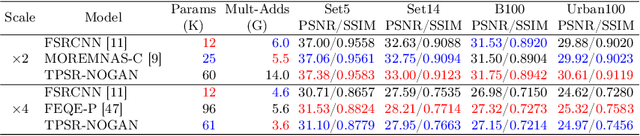
Recent works in single-image perceptual super-resolution (SR) have demonstrated unprecedented performance in generating realistic textures by means of deep convolutional networks. However, these convolutional models are excessively large and expensive, hindering their effective deployment to end devices. In this work, we propose a neural architecture search (NAS) approach that integrates NAS and generative adversarial networks (GANs) with recent advances in perceptual SR and pushes the efficiency of small perceptual SR models to facilitate on-device execution. Specifically, we search over the architectures of both the generator and the discriminator sequentially, highlighting the unique challenges and key observations of searching for an SR-optimized discriminator and comparing them with existing discriminator architectures in the literature. Our tiny perceptual SR (TPSR) models outperform SRGAN and EnhanceNet on both full-reference perceptual metric (LPIPS) and distortion metric (PSNR) while being up to 26.4$\times$ more memory efficient and 33.6$\times$ more compute efficient respectively.