 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly Supervised Learning with Region and Box-level Annotations for Salient Instance Segmentation
Aug 19, 2020
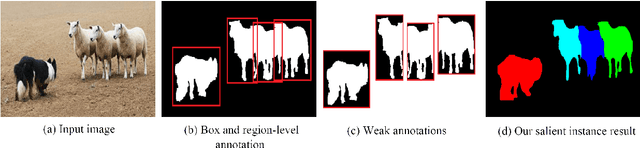
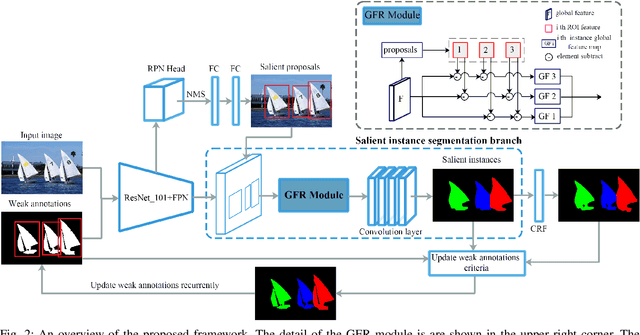
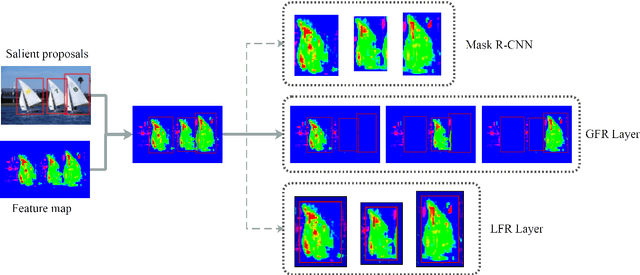

Salient instance segmentation is a new challenging task that received widespread attention in saliency detection area. Due to the limited scale of the existing dataset and the high mask annotations cost, it is difficult to train a salient instance neural network completely. In this paper, we appeal to train a salient instance segmentation framework by a weakly supervised source without resorting to laborious labeling. We present a cyclic global context salient instance segmentation network (CGCNet), which is supervised by the combination of the binary salient regions and bounding boxes from the existing saliency detection datasets. For a precise pixel-level location, a global feature refining layer is introduced that dilates the context features of each salient instance to the global context in the image. Meanwhile, a labeling updating scheme is embedded in the proposed framework to online update the weak annotations for next iteration. Experiment results demonstrate that the proposed end-to-end network trained by weakly supervised annotations can be competitive to the existing fully supervised salient instance segmentation methods. Without bells and whistles, our proposed method achieves a mask AP of 57.13%, which outperforms the best fully supervised methods and establishes new states of the art for weakly supervised salient instance segmentation.
Classification-Based Anomaly Detection for General Data
May 05, 2020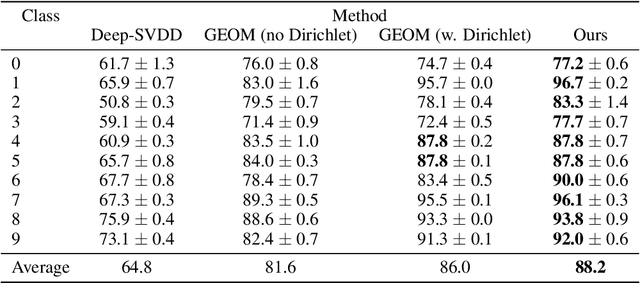
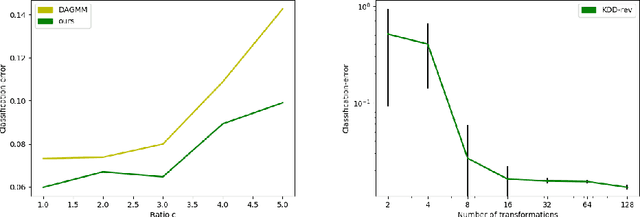
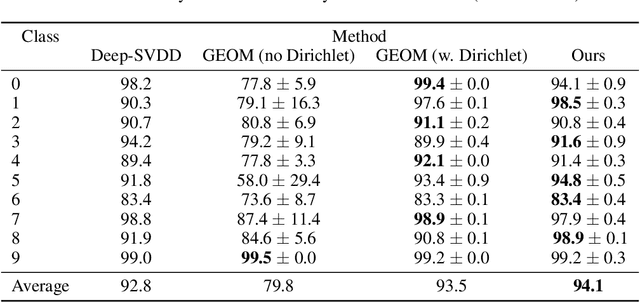
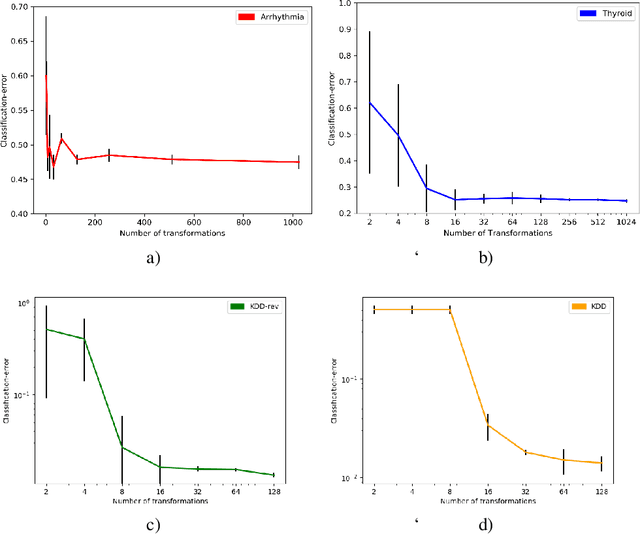
Anomaly detection, finding patterns that substantially deviate from those seen previously, is one of the fundamental problems of artificial intelligence. Recently, classification-based methods were shown to achieve superior results on this task. In this work, we present a unifying view and propose an open-set method, GOAD, to relax current generalization assumptions. Furthermore, we extend the applicability of transformation-based methods to non-image data using random affine transformations. Our method is shown to obtain state-of-the-art accuracy and is applicable to broad data types. The strong performance of our method is extensively validated on multiple datasets from different domains.
Pathological Visual Question Answering
Oct 06, 2020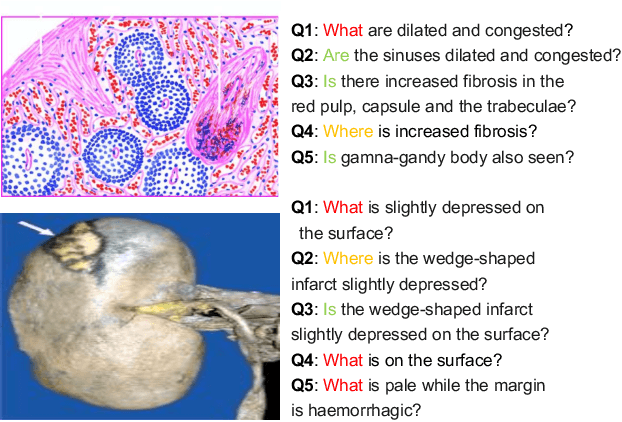
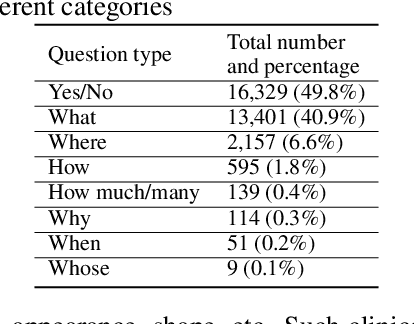
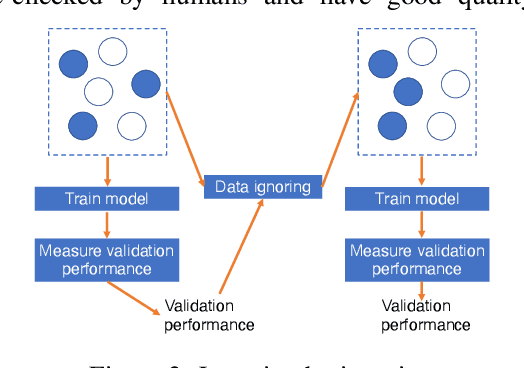
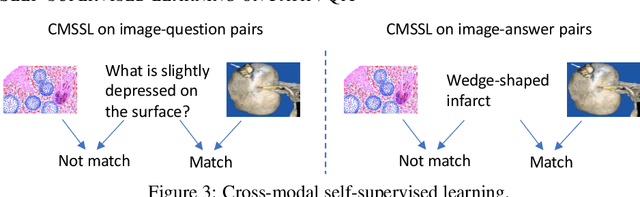
Is it possible to develop an "AI Pathologist" to pass the board-certified examination of the American Board of Pathology (ABP)? To build such a system, three challenges need to be addressed. First, we need to create a visual question answering (VQA) dataset where the AI agent is presented with a pathology image together with a question and is asked to give the correct answer. Due to privacy concerns, pathology images are usually not publicly available. Besides, only well-trained pathologists can understand pathology images, but they barely have time to help create datasets for AI research. The second challenge is: since it is difficult to hire highly experienced pathologists to create pathology visual questions and answers, the resulting pathology VQA dataset may contain errors. Training pathology VQA models using these noisy or even erroneous data will lead to problematic models that cannot generalize well on unseen images. The third challenge is: the medical concepts and knowledge covered in pathology question-answer (QA) pairs are very diverse while the number of QA pairs available for modeling training is limited. How to learn effective representations of diverse medical concepts based on limited data is technically demanding. In this paper, we aim to address these three challenges. To our best knowledge, our work represents the first one addressing the pathology VQA problem. To deal with the issue that a publicly available pathology VQA dataset is lacking, we create PathVQA dataset. To address the second challenge, we propose a learning-by-ignoring approach. To address the third challenge, we propose to use cross-modal self-supervised learning. We perform experiments on our created PathVQA dataset and the results demonstrate the effectiveness of our proposed learning-by-ignoring method and cross-modal self-supervised learning methods.
Hierarchical Patch VAE-GAN: Generating Diverse Videos from a Single Sample
Jun 23, 2020

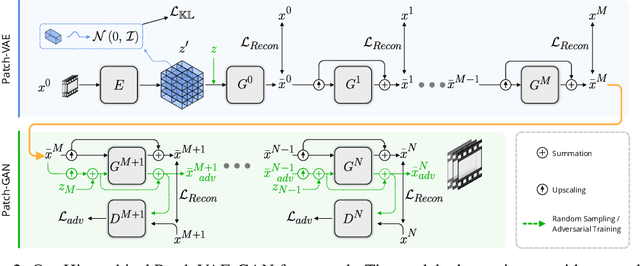

We consider the task of generating diverse and novel videos from a single video sample. Recently, new hierarchical patch-GAN based approaches were proposed for generating diverse images, given only a single sample at training time. Moving to videos, these approaches fail to generate diverse samples, and often collapse into generating samples similar to the training video. We introduce a novel patch-based variational autoencoder (VAE) which allows for a much greater diversity in generation. Using this tool, a new hierarchical video generation scheme is constructed: at coarse scales, our patch-VAE is employed, ensuring samples are of high diversity. Subsequently, at finer scales, a patch-GAN renders the fine details, resulting in high quality videos. Our experiments show that the proposed method produces diverse samples in both the image domain, and the more challenging video domain.
Bio-Inspired Foveated Technique for Augmented-Range Vehicle Detection Using Deep Neural Networks
Oct 02, 2019

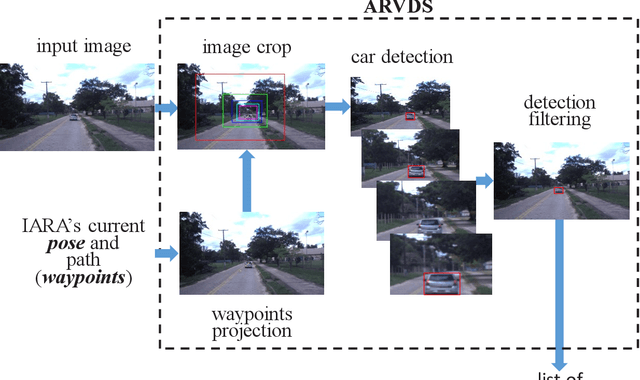
We propose a bio-inspired foveated technique to detect cars in a long range camera view using a deep convolutional neural network (DCNN) for the IARA self-driving car. The DCNN receives as input (i) an image, which is captured by a camera installed on IARA's roof; and (ii) crops of the image, which are centered in the waypoints computed by IARA's path planner and whose sizes increase with the distance from IARA. We employ an overlap filter to discard detections of the same car in different crops of the same image based on the percentage of overlap of detections' bounding boxes. We evaluated the performance of the proposed augmented-range vehicle detection system (ARVDS) using the hardware and software infrastructure available in the IARA self-driving car. Using IARA, we captured thousands of images of real traffic situations containing cars in a long range. Experimental results show that ARVDS increases the Average Precision (AP) of long range car detection from 29.51% (using a single whole image) to 63.15%.
Visual Compositional Learning for Human-Object Interaction Detection
Jul 24, 2020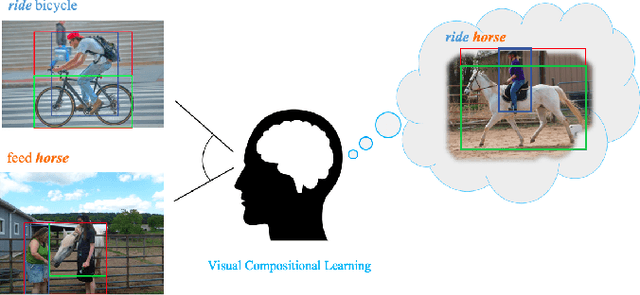
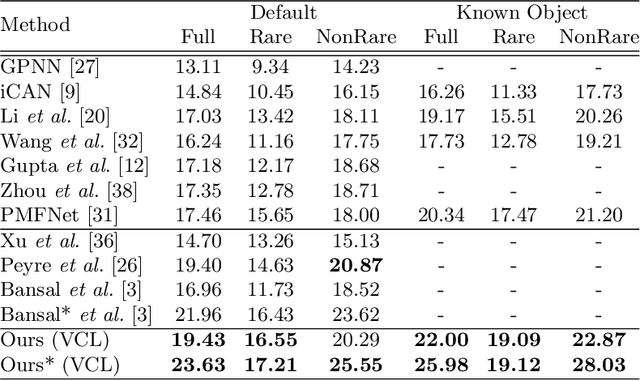
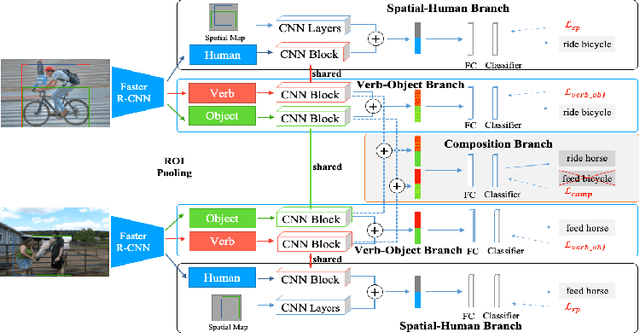
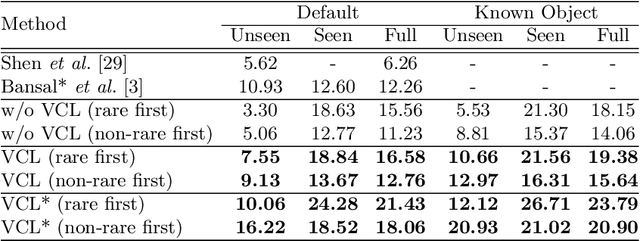
Human-Object interaction (HOI) detection aims to localize and infer relationships between human and objects in an image. It is challenging because an enormous number of possible combinations of objects and verbs types forms a long-tail distribution. We devise a deep Visual Compositional Learning (VCL) framework, which is a simple yet efficient framework to effectively address this problem. VCL first decomposes an HOI representation into object and verb specific features, and then composes new interaction samples in the feature space via stitching the decomposed features. The integration of decomposition and composition enables VCL to share object and verb features among different HOI samples and images, and to generate new interaction samples and new types of HOI, and thus largely alleviates the long-tail distribution problem and benefits low-shot or zero-shot HOI detection. Extensive experiments demonstrate that the proposed VCL can effectively improve the generalization of HOI detection on HICO-DET and V-COCO and outperforms the recent state-of-the-art methods on HICO-DET. Code is available at https://github.com/zhihou7/VCL.
Harmonizing Transferability and Discriminability for Adapting Object Detectors
Mar 13, 2020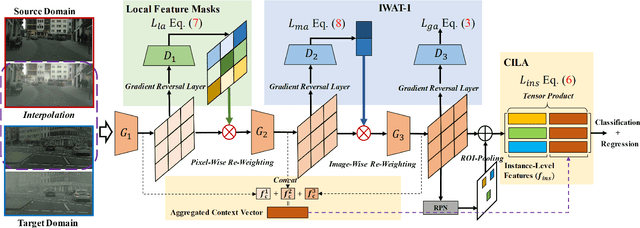
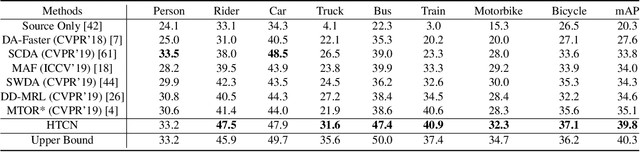
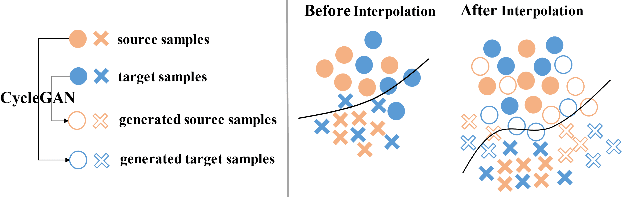

Recent advances in adaptive object detection have achieved compelling results in virtue of adversarial feature adaptation to mitigate the distributional shifts along the detection pipeline. Whilst adversarial adaptation significantly enhances the transferability of feature representations, the feature discriminability of object detectors remains less investigated. Moreover, transferability and discriminability may come at a contradiction in adversarial adaptation given the complex combinations of objects and the differentiated scene layouts between domains. In this paper, we propose a Hierarchical Transferability Calibration Network (HTCN) that hierarchically (local-region/image/instance) calibrates the transferability of feature representations for harmonizing transferability and discriminability. The proposed model consists of three components: (1) Importance Weighted Adversarial Training with input Interpolation (IWAT-I), which strengthens the global discriminability by re-weighting the interpolated image-level features; (2) Context-aware Instance-Level Alignment (CILA) module, which enhances the local discriminability by capturing the underlying complementary effect between the instance-level feature and the global context information for the instance-level feature alignment; (3) local feature masks that calibrate the local transferability to provide semantic guidance for the following discriminative pattern alignment. Experimental results show that HTCN significantly outperforms the state-of-the-art methods on benchmark datasets.
SegFix: Model-Agnostic Boundary Refinement for Segmentation
Jul 09, 2020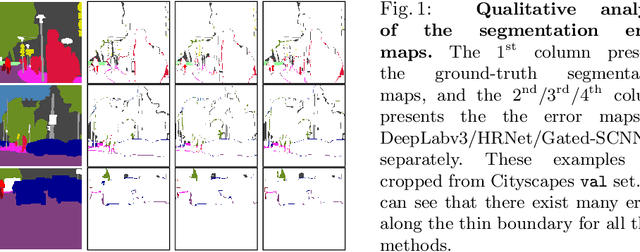
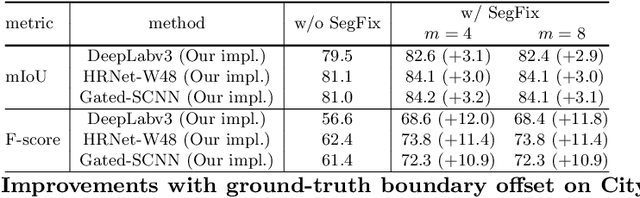
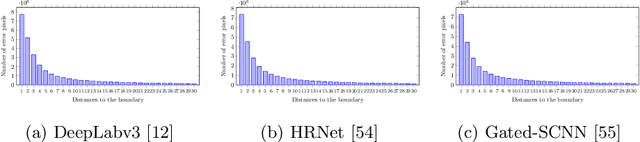
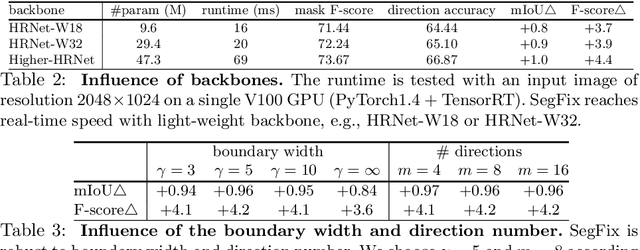
We present a model-agnostic post-processing scheme to improve the boundary quality for the segmentation result that is generated by any existing segmentation model. Motivated by the empirical observation that the label predictions of interior pixels are more reliable, we propose to replace the originally unreliable predictions of boundary pixels by the predictions of interior pixels. Our approach processes only the input image through two steps: (i) localize the boundary pixels and (ii) identify the corresponding interior pixel for each boundary pixel. We build the correspondence by learning a direction away from the boundary pixel to an interior pixel. Our method requires no prior information of the segmentation models and achieves nearly real-time speed. We empirically verify that our SegFix consistently reduces the boundary errors for segmentation results generated from various state-of-the-art models on Cityscapes, ADE20K and GTA5. Code is available at: https://github.com/openseg-group/openseg.pytorch.
Heteroscedastic Uncertainty for Robust Generative Latent Dynamics
Aug 18, 2020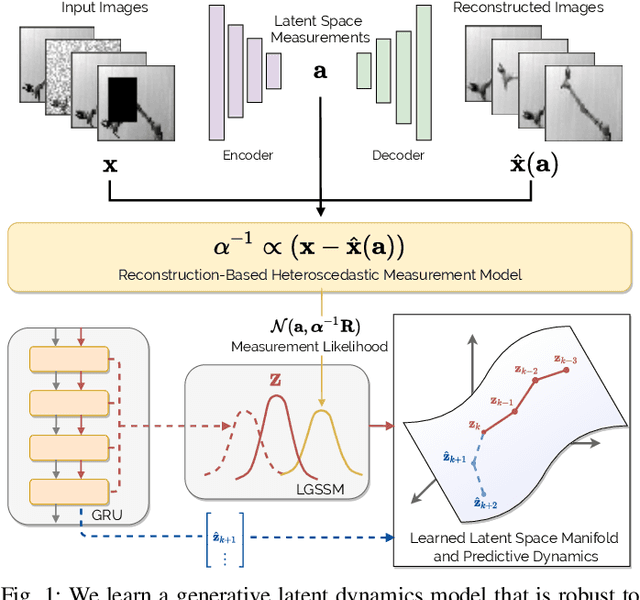

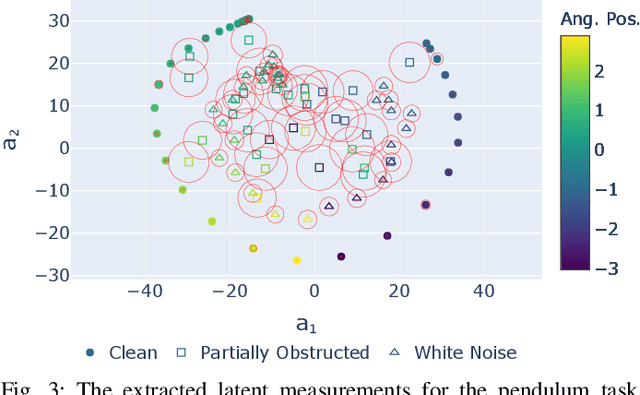

Learning or identifying dynamics from a sequence of high-dimensional observations is a difficult challenge in many domains, including reinforcement learning and control. The problem has recently been studied from a generative perspective through latent dynamics: high-dimensional observations are embedded into a lower-dimensional space in which the dynamics can be learned. Despite some successes, latent dynamics models have not yet been applied to real-world robotic systems where learned representations must be robust to a variety of perceptual confounds and noise sources not seen during training. In this paper, we present a method to jointly learn a latent state representation and the associated dynamics that is amenable for long-term planning and closed-loop control under perceptually difficult conditions. As our main contribution, we describe how our representation is able to capture a notion of heteroscedastic or input-specific uncertainty at test time by detecting novel or out-of-distribution (OOD) inputs. We present results from prediction and control experiments on two image-based tasks: a simulated pendulum balancing task and a real-world robotic manipulator reaching task. We demonstrate that our model produces significantly more accurate predictions and exhibits improved control performance, compared to a model that assumes homoscedastic uncertainty only, in the presence of varying degrees of input degradation.
DeepLiDARFlow: A Deep Learning Architecture For Scene Flow Estimation Using Monocular Camera and Sparse LiDAR
Aug 18, 2020
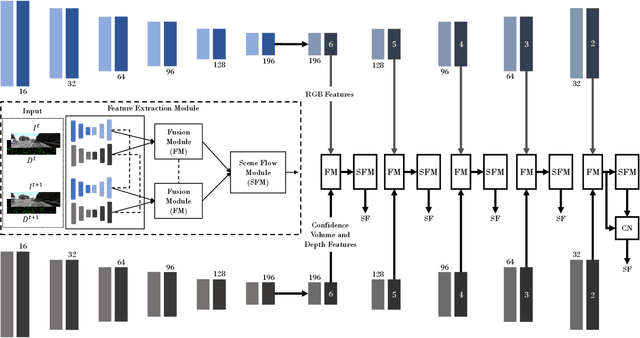
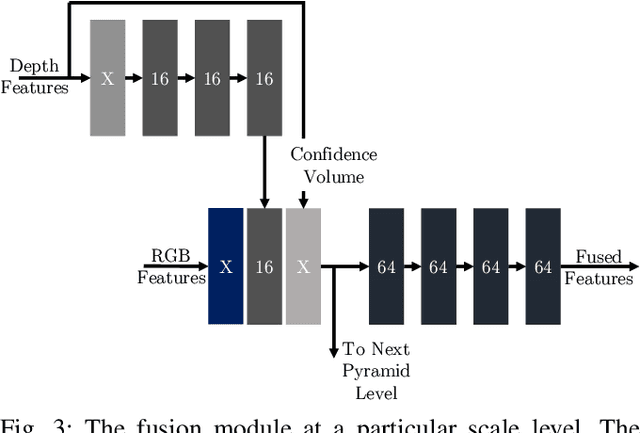
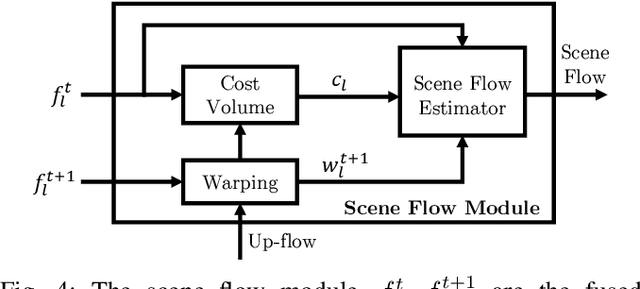
Scene flow is the dense 3D reconstruction of motion and geometry of a scene. Most state-of-the-art methods use a pair of stereo images as input for full scene reconstruction. These methods depend a lot on the quality of the RGB images and perform poorly in regions with reflective objects, shadows, ill-conditioned light environment and so on. LiDAR measurements are much less sensitive to the aforementioned conditions but LiDAR features are in general unsuitable for matching tasks due to their sparse nature. Hence, using both LiDAR and RGB can potentially overcome the individual disadvantages of each sensor by mutual improvement and yield robust features which can improve the matching process. In this paper, we present DeepLiDARFlow, a novel deep learning architecture which fuses high level RGB and LiDAR features at multiple scales in a monocular setup to predict dense scene flow. Its performance is much better in the critical regions where image-only and LiDAR-only methods are inaccurate. We verify our DeepLiDARFlow using the established data sets KITTI and FlyingThings3D and we show strong robustness compared to several state-of-the-art methods which used other input modalities. The code of our paper is available at https://github.com/dfki-av/DeepLiDARFlow.