 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fault-Diagnosing SLAM for Varying Scale Change Detection
Sep 16, 2019
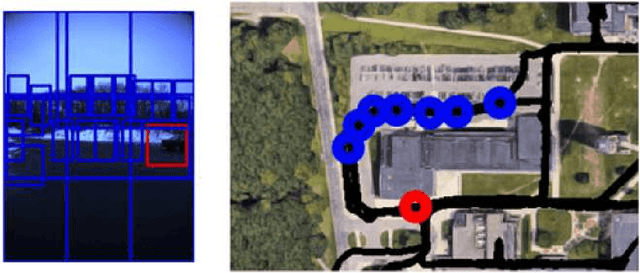
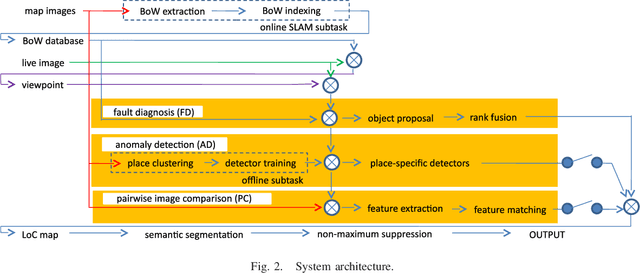

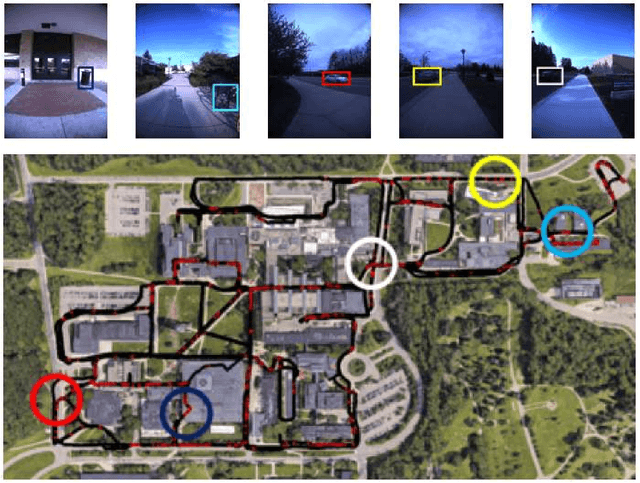
In this paper, we present a new fault diagnosis (FD) -based approach for detection of imagery changes that can detect significant changes as inconsistencies between different sub-modules (e.g., self-localizaiton) of visual SLAM. Unlike classical change detection approaches such as pairwise image comparison (PC) and anomaly detection (AD), neither the memorization of each map image nor the maintenance of up-to-date place-specific anomaly detectors are required in this FD approach. A significant challenge that is encountered when incorporating different SLAM sub-modules into FD involves dealing with the varying scales of objects that have changed (e.g., the appearance of small dangerous obstacles on the floor). To address this issue, we reconsider the bag-of-words (BoW) image representation, by exploiting its recent advances in terms of self-localization and change detection. As a key advantage, BoW image representation can be reorganized into any different scaling by simply cropping the original BoW image. Furthermore, we propose to combine different self-localization modules with strong and weak BoW features with different discriminativity, and to treat inconsistency between strong and weak self-localization as an indicator of change. The efficacy of the proposed approach for FD with/without AD and/or PC was experimentally validated.
On the training dynamics of deep networks with $L_2$ regularization
Jun 15, 2020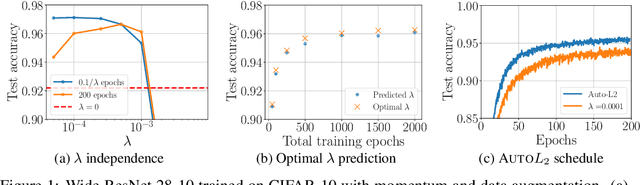
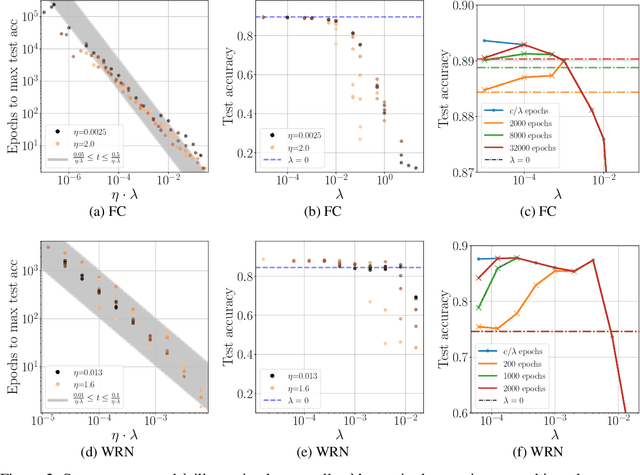
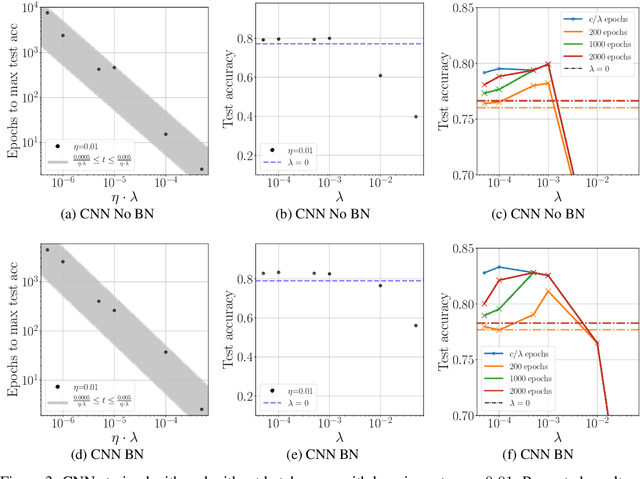
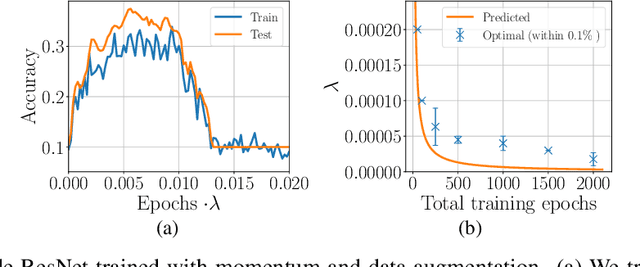
We study the role of $L_2$ regularization in deep learning, and uncover simple relations between the performance of the model, the $L_2$ coefficient, the learning rate, and the number of training steps. These empirical relations hold when the network is overparameterized. They can be used to predict the optimal regularization parameter of a given model. In addition, based on these observations we propose a dynamical schedule for the regularization parameter that improves performance and speeds up training. We test these proposals in modern image classification settings. Finally, we show that these empirical relations can be understood theoretically in the context of infinitely wide networks. We derive the gradient flow dynamics of such networks, and compare the role of $L_2$ regularization in this context with that of linear models.
RS-MetaNet: Deep meta metric learning for few-shot remote sensing scene classification
Sep 28, 2020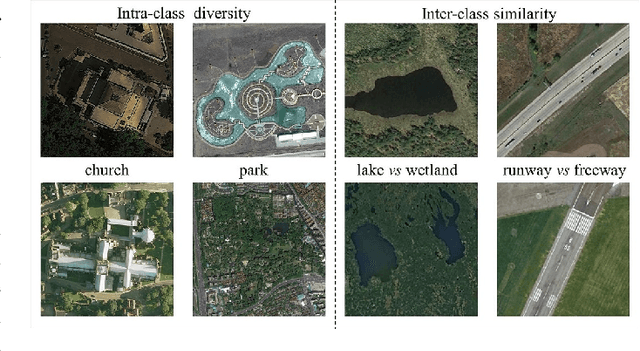
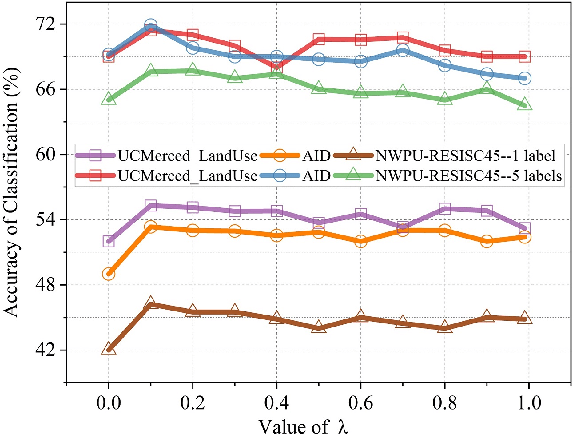
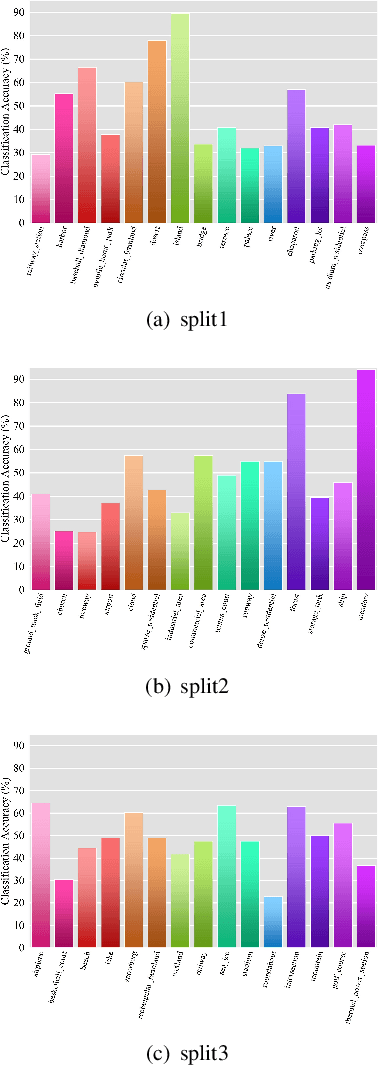
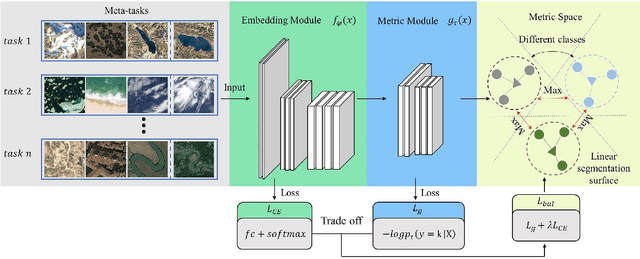
Training a modern deep neural network on massive labeled samples is the main paradigm in solving the scene classification problem for remote sensing, but learning from only a few data points remains a challenge. Existing methods for few-shot remote sensing scene classification are performed in a sample-level manner, resulting in easy overfitting of learned features to individual samples and inadequate generalization of learned category segmentation surfaces. To solve this problem, learning should be organized at the task level rather than the sample level. Learning on tasks sampled from a task family can help tune learning algorithms to perform well on new tasks sampled in that family. Therefore, we propose a simple but effective method, called RS-MetaNet, to resolve the issues related to few-shot remote sensing scene classification in the real world. On the one hand, RS-MetaNet raises the level of learning from the sample to the task by organizing training in a meta way, and it learns to learn a metric space that can well classify remote sensing scenes from a series of tasks. We also propose a new loss function, called Balance Loss, which maximizes the generalization ability of the model to new samples by maximizing the distance between different categories, providing the scenes in different categories with better linear segmentation planes while ensuring model fit. The experimental results on three open and challenging remote sensing datasets, UCMerced\_LandUse, NWPU-RESISC45, and Aerial Image Data, demonstrate that our proposed RS-MetaNet method achieves state-of-the-art results in cases where there are only 1-20 labeled samples.
* 13 pages, 11 figures
Joint Chromatic and Polarimetric Demosaicing via Sparse Coding
Dec 16, 2019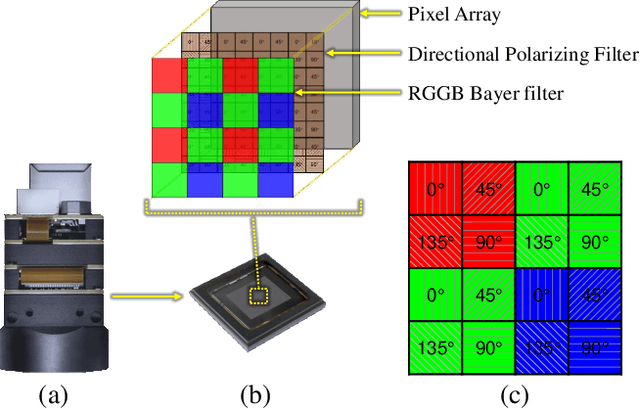
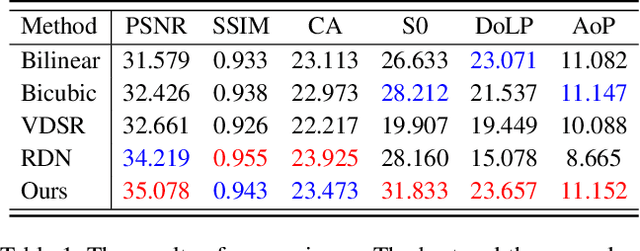
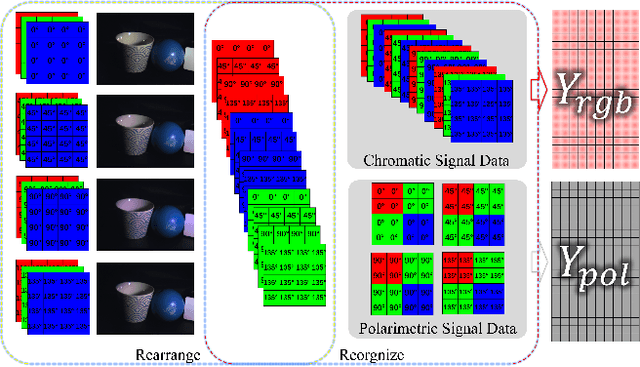

Thanks to the latest progress in image sensor manufacturing technology, the emergence of the single-chip polarized color sensor is likely to bring advantages to computer vision tasks. Despite the importance of the sensor, joint chromatic and polarimetric demosaicing is the key to obtaining the high-quality RGB-Polarization image for the sensor. Since the polarized color sensor is equipped with a new type of chip, the demosaicing problem cannot be currently well-addressed by former methods. In this paper, we propose a joint chromatic and polarimetric demosaicing model to address this challenging problem. To solve this non-convex problem, we further present a sparse representation-based optimization strategy that utilizes chromatic information and polarimetric information to jointly optimize the model. In addition, we build an optical data acquisition system to collect an RGB-Polarization dataset. Results of both qualitative and quantitative experiments have shown that our method is capable of faithfully recovering full 12-channel chromatic and polarimetric information for each pixel from a single mosaic input image. Moreover, we show that the proposed method can perform well not only on the synthetic data but the real captured data.
An Overview of Deep Learning Architectures in Few-Shot Learning Domain
Aug 19, 2020
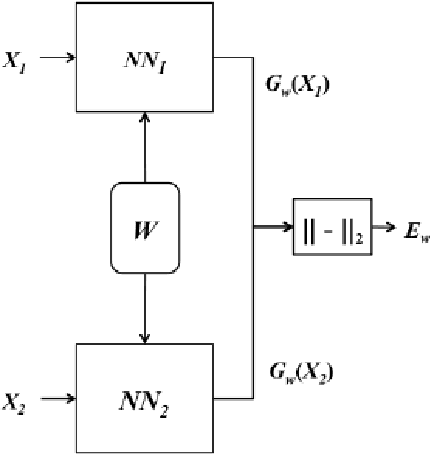
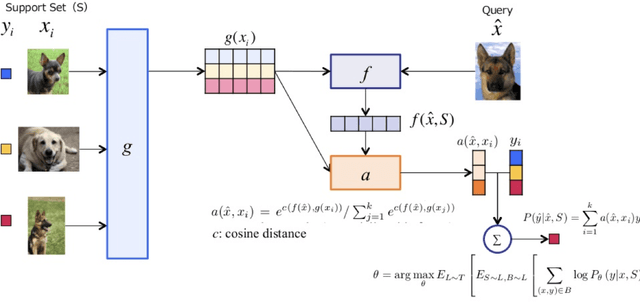
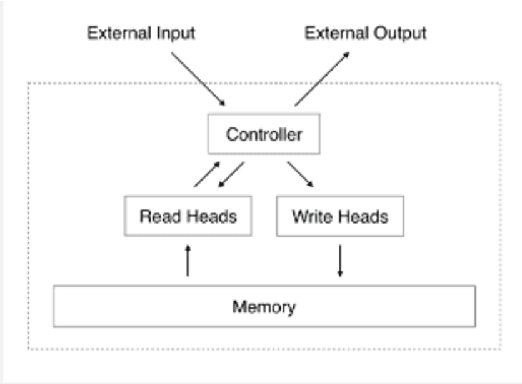
Since 2012, Deep learning has revolutionized Artificial Intelligence and has achieved state-of-the-art outcomes in different domains, ranging from Image Classification to Speech Generation. Though it has many potentials, our current architectures come with the pre-requisite of large amounts of data. Few-Shot Learning (also known as one-shot learning) is a sub-field of machine learning that aims to create such models that can learn the desired objective with less data, similar to how humans learn. In this paper, we have reviewed some of the well-known deep learning-based approaches towards few-shot learning. We have discussed the recent achievements, challenges, and possibilities of improvement of few-shot learning based deep learning architectures. Our aim for this paper is threefold: (i) Give a brief introduction to deep learning architectures for few-shot learning with pointers to core references. (ii) Indicate how deep learning has been applied to the low-data regime, from data preparation to model training. and, (iii) Provide a starting point for people interested in experimenting and perhaps contributing to the field of few-shot learning by pointing out some useful resources and open-source code. Our code is available at Github: https://github.com/shruti-jadon/Hands-on-One-Shot-Learning.
Deep Multi-Modal Image Correspondence Learning
Dec 05, 2016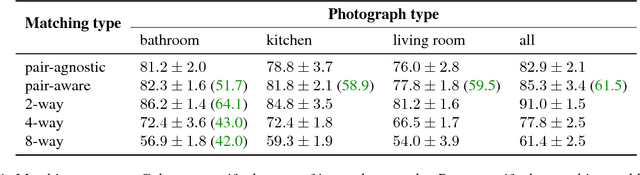
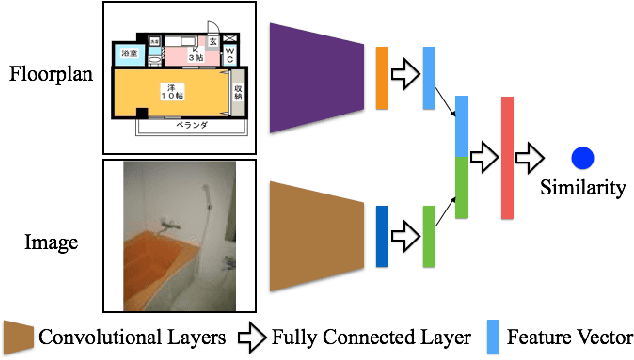
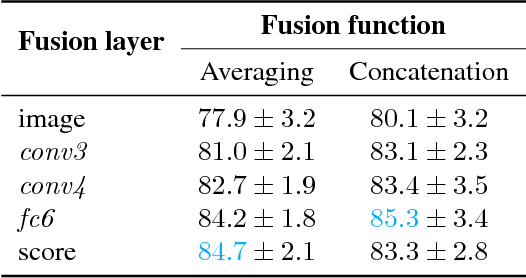
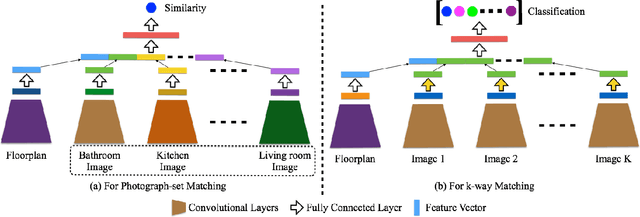
Inference of correspondences between images from different modalities is an extremely important perceptual ability that enables humans to understand and recognize cross-modal concepts. In this paper, we consider an instance of this problem that involves matching photographs of building interiors with their corresponding floorplan. This is a particularly challenging problem because a floorplan, as a stylized architectural drawing, is very different in appearance from a color photograph. Furthermore, individual photographs by themselves depict only a part of a floorplan (e.g., kitchen, bathroom, and living room). We propose the use of a number of different neural network architectures for this task, which are trained and evaluated on a novel large-scale dataset of 5 million floorplan images and 80 million associated photographs. Experimental evaluation reveals that our neural network architectures are able to identify visual cues that result in reliable matches across these two quite different modalities. In fact, the trained networks are able to even outperform human subjects in several challenging image matching problems. Our result implies that neural networks are effective at perceptual tasks that require long periods of reasoning even for humans to solve.
Automatic Segmentation of Non-Tumor Tissues in Glioma MR Brain Images Using Deformable Registration with Partial Convolutional Networks
Jul 10, 2020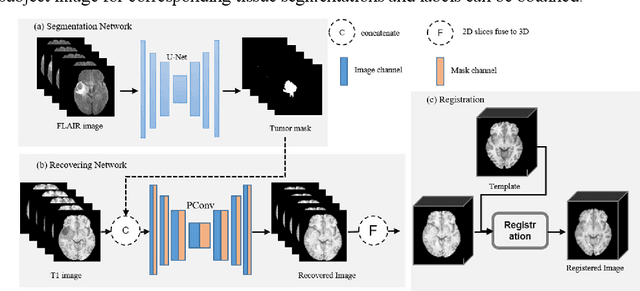

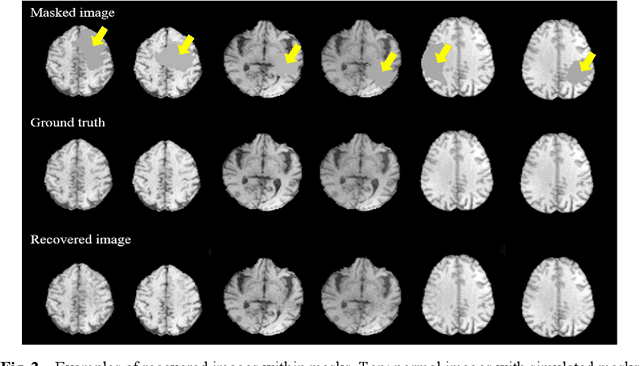
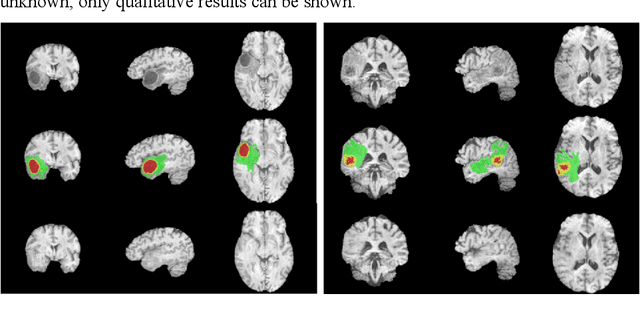
In brain tumor diagnosis and surgical planning, segmentation of tumor regions and accurate analysis of surrounding normal tissues are necessary for physicians. Pathological variability often renders difficulty to register a well-labeled normal atlas to such images and to automatic segment/label surrounding normal brain tissues. In this paper, we propose a new registration approach that first segments brain tumor using a U-Net and then simulates missed normal tissues within the tumor region using a partial convolutional network. Then, a standard normal brain atlas image is registered onto such tumor-removed images in order to segment/label the normal brain tissues. In this way, our new approach greatly reduces the effects of pathological variability in deformable registration and segments the normal tissues surrounding brain tumor well. In experiments, we used MICCAI BraTS2018 T1 tumor images to evaluate the proposed algorithm. By comparing direct registration with the proposed algorithm, the results showed that the Dice coefficient for gray matters was significantly improved for surrounding normal brain tissues.
Deep 3D-Zoom Net: Unsupervised Learning of Photo-Realistic 3D-Zoom
Oct 02, 2019
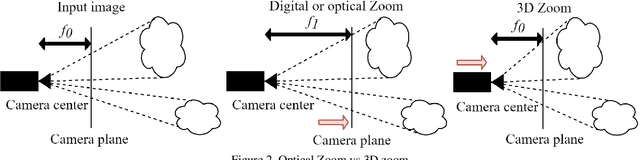
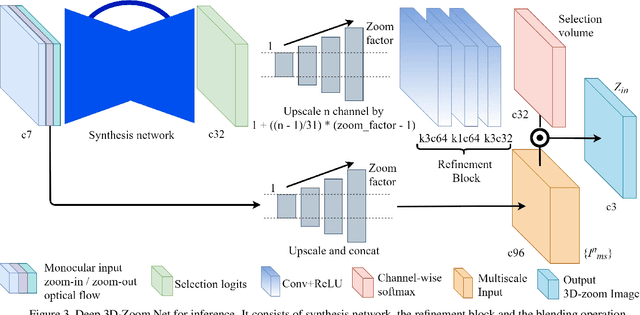
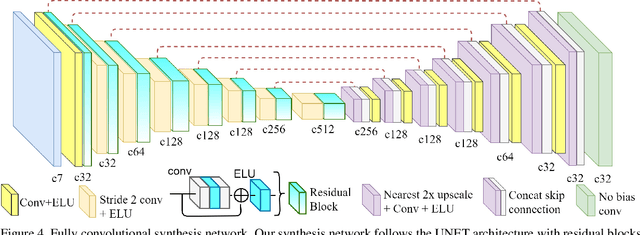
The 3D-zoom operation is the positive translation of the camera in the Z-axis, perpendicular to the image plane. In contrast, the optical zoom changes the focal length and the digital zoom is used to enlarge a certain region of an image to the original image size. In this paper, we are the first to formulate an unsupervised 3D-zoom learning problem where images with an arbitrary zoom factor can be generated from a given single image. An unsupervised framework is convenient, as it is a challenging task to obtain a 3D-zoom dataset of natural scenes due to the need for special equipment to ensure camera movement is restricted to the Z-axis. In addition, the objects in the scenes should not move when being captured, which hinders the construction of a large dataset of outdoor scenes. We present a novel unsupervised framework to learn how to generate arbitrarily 3D-zoomed versions of a single image, not requiring a 3D-zoom ground truth, called the Deep 3D-Zoom Net. The Deep 3D-Zoom Net incorporates the following features: (i) transfer learning from a pre-trained disparity estimation network via a back re-projection reconstruction loss; (ii) a fully convolutional network architecture that models depth-image-based rendering (DIBR), taking into account high-frequency details without the need for estimating the intermediate disparity; and (iii) incorporating a discriminator network that acts as a no-reference penalty for unnaturally rendered areas. Even though there is no baseline to fairly compare our results, our method outperforms previous novel view synthesis research in terms of realistic appearance on large camera baselines. We performed extensive experiments to verify the effectiveness of our method on the KITTI and Cityscapes datasets.
Scene Text Recognition via Transformer
Apr 10, 2020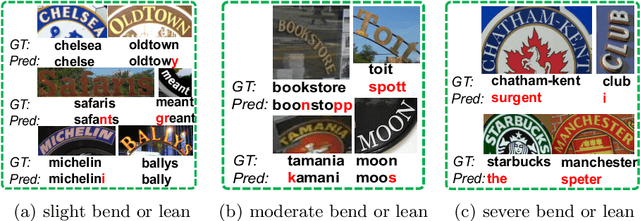
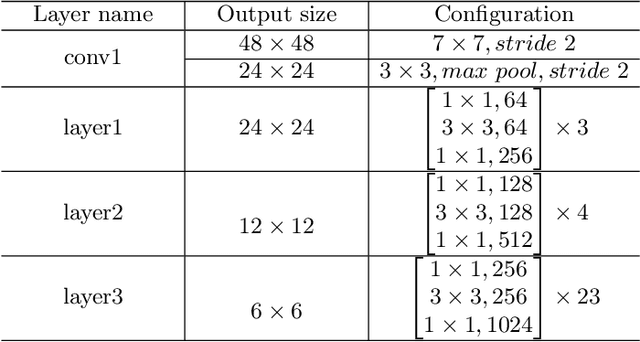
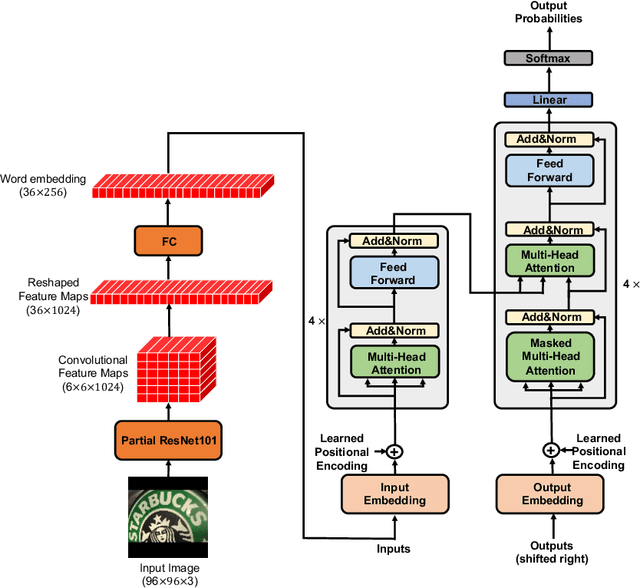
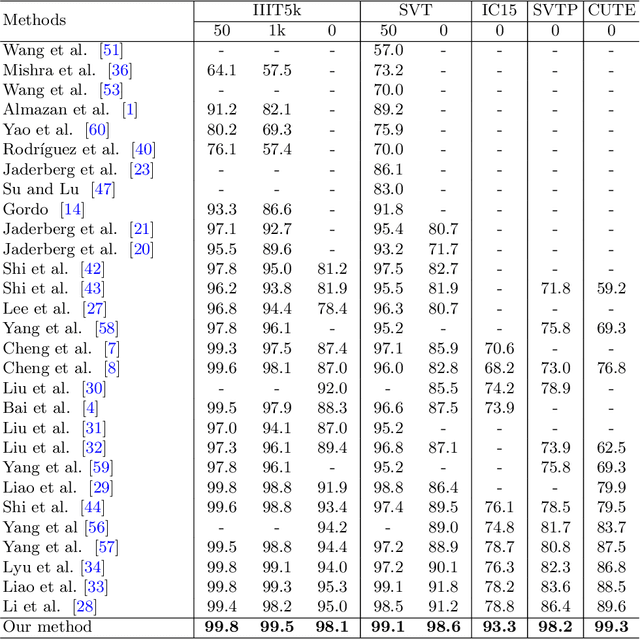
Scene text recognition with arbitrary shape is very challenging due to large variations in text shapes, fonts, colors, backgrounds, etc. Most state-of-the-art algorithms rectify the input image into the normalized image, then treat the recognition as a sequence prediction task. The bottleneck of such methods is the rectification, which will cause errors due to distortion perspective. In this paper, we find that the rectification is completely unnecessary. What all we need is the spatial attention. We therefore propose a simple but extremely effective scene text recognition method based on transformer [50]. Different from previous transformer based models [56,34], which just use the decoder of the transformer to decode the convolutional attention, the proposed method use a convolutional feature maps as word embedding input into transformer. In such a way, our method is able to make full use of the powerful attention mechanism of the transformer. Extensive experimental results show that the proposed method significantly outperforms state-of-the-art methods by a very large margin on both regular and irregular text datasets. On one of the most challenging CUTE dataset whose state-of-the-art prediction accuracy is 89.6%, our method achieves 99.3%, which is a pretty surprising result. We will release our source code and believe that our method will be a new benchmark of scene text recognition with arbitrary shapes.
Distorted Representation Space Characterization Through Backpropagated Gradients
Aug 27, 2019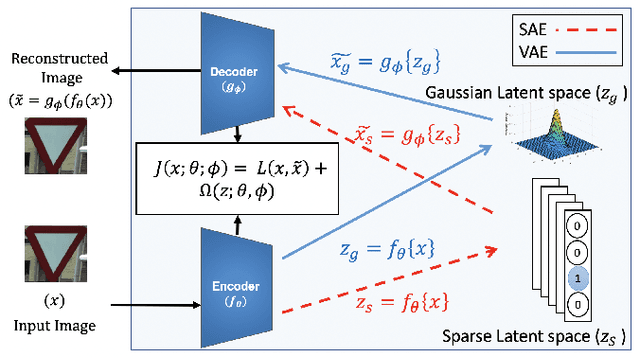
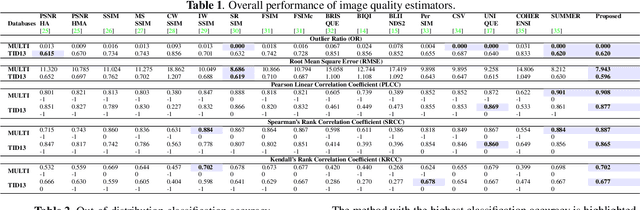
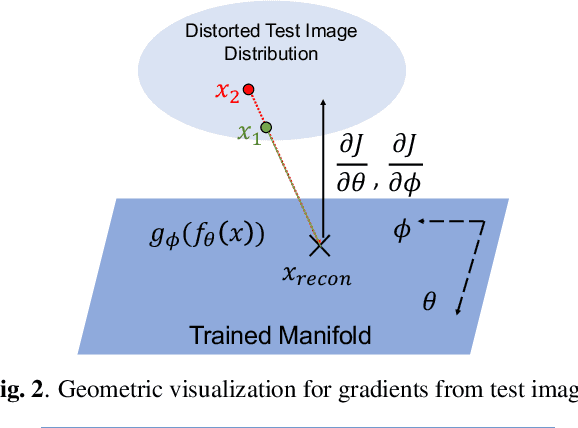
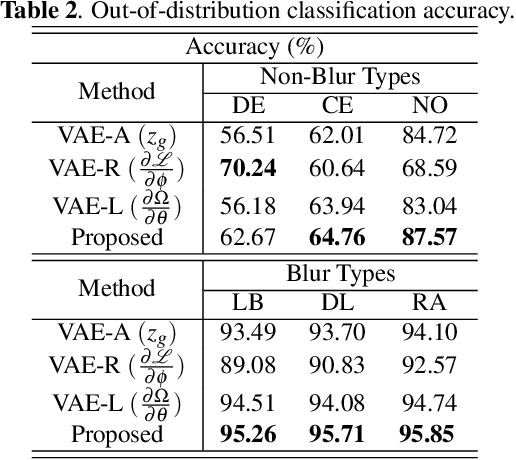
In this paper, we utilize weight gradients from backpropagation to characterize the representation space learned by deep learning algorithms. We demonstrate the utility of such gradients in applications including perceptual image quality assessment and out-of-distribution classification. The applications are chosen to validate the effectiveness of gradients as features when the test image distribution is distorted from the train image distribution. In both applications, the proposed gradient based features outperform activation features. In image quality assessment, the proposed approach is compared with other state of the art approaches and is generally the top performing method on TID 2013 and MULTI-LIVE databases in terms of accuracy, consistency, linearity, and monotonic behavior. Finally, we analyze the effect of regularization on gradients using CURE-TSR dataset for out-of-distribution classification.