 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Set based Collaborative Representation for Face Recognition
Aug 30, 2013
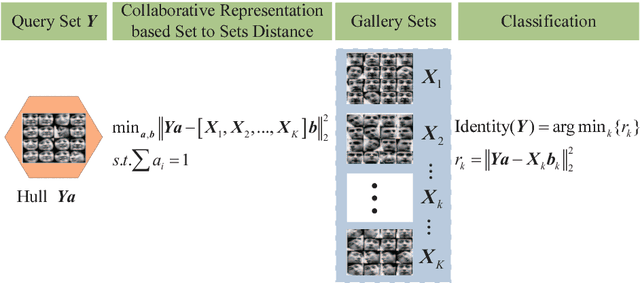

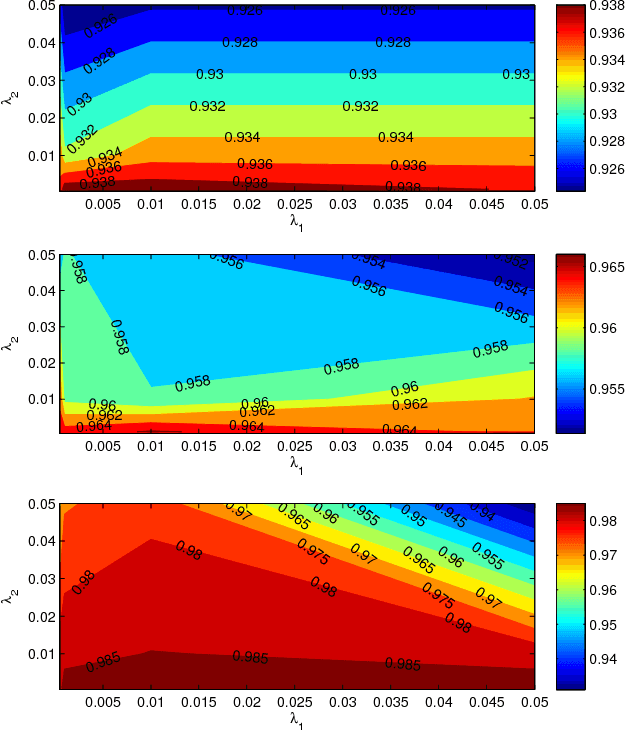
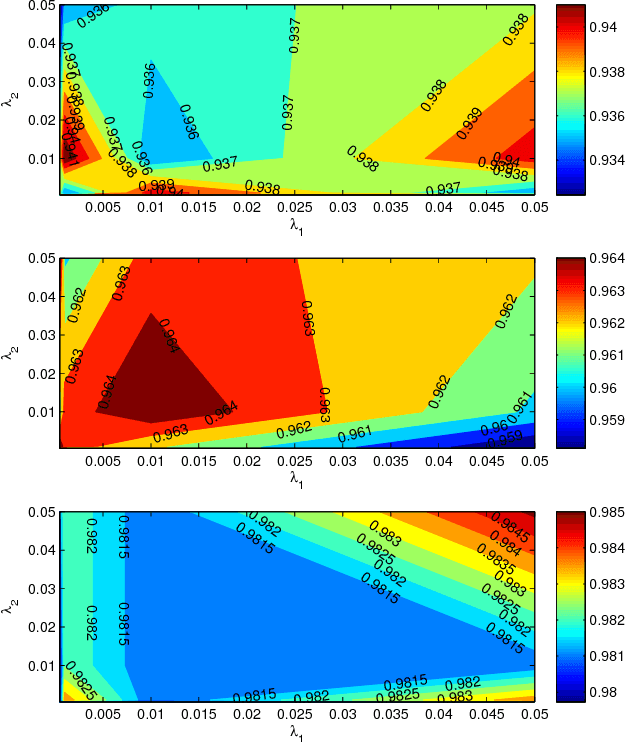
With the rapid development of digital imaging and communication technologies, image set based face recognition (ISFR) is becoming increasingly important. One key issue of ISFR is how to effectively and efficiently represent the query face image set by using the gallery face image sets. The set-to-set distance based methods ignore the relationship between gallery sets, while representing the query set images individually over the gallery sets ignores the correlation between query set images. In this paper, we propose a novel image set based collaborative representation and classification method for ISFR. By modeling the query set as a convex or regularized hull, we represent this hull collaboratively over all the gallery sets. With the resolved representation coefficients, the distance between the query set and each gallery set can then be calculated for classification. The proposed model naturally and effectively extends the image based collaborative representation to an image set based one, and our extensive experiments on benchmark ISFR databases show the superiority of the proposed method to state-of-the-art ISFR methods under different set sizes in terms of both recognition rate and efficiency.
Deep 3D-Zoom Net: Unsupervised Learning of Photo-Realistic 3D-Zoom
Sep 20, 2019
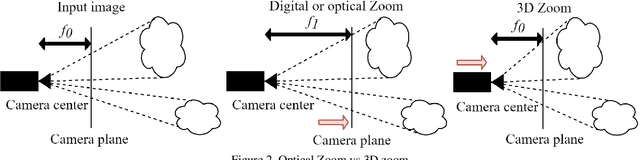
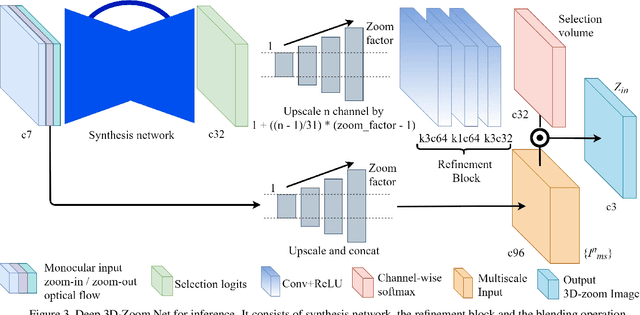
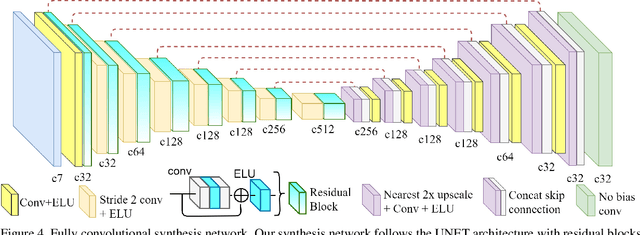
The 3D-zoom operation is the positive translation of the camera in the Z-axis, perpendicular to the image plane. In contrast, the optical zoom changes the focal length and the digital zoom is used to enlarge a certain region of an image to the original image size. In this paper, we are the first to formulate an unsupervised 3D-zoom learning problem where images with an arbitrary zoom factor can be generated from a given single image. An unsupervised framework is convenient, as it is a challenging task to obtain a 3D-zoom dataset of natural scenes due to the need for special equipment to ensure camera movement is restricted to the Z-axis. In addition, the objects in the scenes should not move when being captured, which hinders the construction of a large dataset of outdoor scenes. We present a novel unsupervised framework to learn how to generate arbitrarily 3D-zoomed versions of a single image, not requiring a 3D-zoom ground truth, called the Deep 3D-Zoom Net. The Deep 3D-Zoom Net incorporates the following features: (i) transfer learning from a pre-trained disparity estimation network via a back re-projection reconstruction loss; (ii) a fully convolutional network architecture that models depth-image-based rendering (DIBR), taking into account high-frequency details without the need for estimating the intermediate disparity; and (iii) incorporating a discriminator network that acts as a no-reference penalty for unnaturally rendered areas. Even though there is no baseline to fairly compare our results, our method outperforms previous novel view synthesis research in terms of realistic appearance on large camera baselines. We performed extensive experiments to verify the effectiveness of our method on the KITTI and Cityscapes datasets.
Forced Spatial Attention for Driver Foot Activity Classification
Jul 27, 2019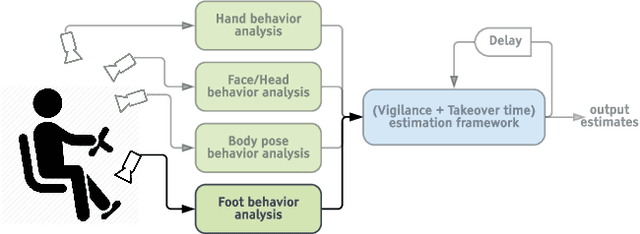
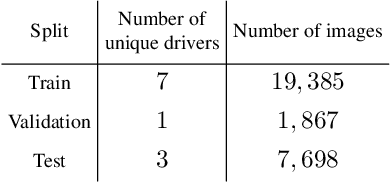

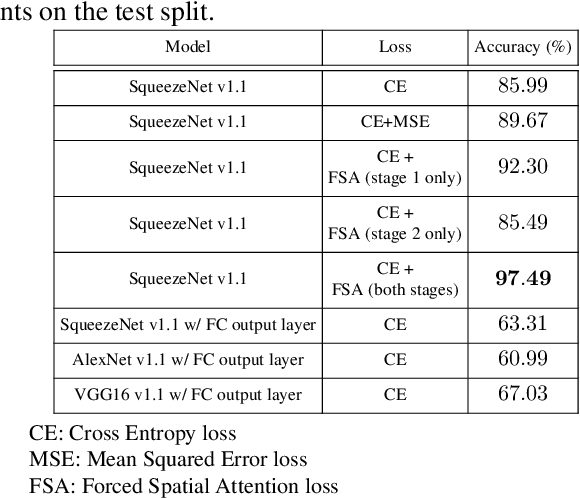
This paper provides a simple solution for reliably solving image classification tasks tied to spatial locations of salient objects in the scene. Unlike conventional image classification approaches that are designed to be invariant to translations of objects in the scene, we focus on tasks where the output classes vary with respect to where an object of interest is situated within an image. To handle this variant of the image classification task, we propose augmenting the standard cross-entropy (classification) loss with a domain dependent Forced Spatial Attention (FSA) loss, which in essence compels the network to attend to specific regions in the image associated with the desired output class. To demonstrate the utility of this loss function, we consider the task of driver foot activity classification - where each activity is strongly correlated with where the driver's foot is in the scene. Training with our proposed loss function results in significantly improved accuracies, better generalization, and robustness against noise, while obviating the need for very large datasets.
Deep Multi-Magnification Networks for Multi-Class Breast Cancer Image Segmentation
Oct 29, 2019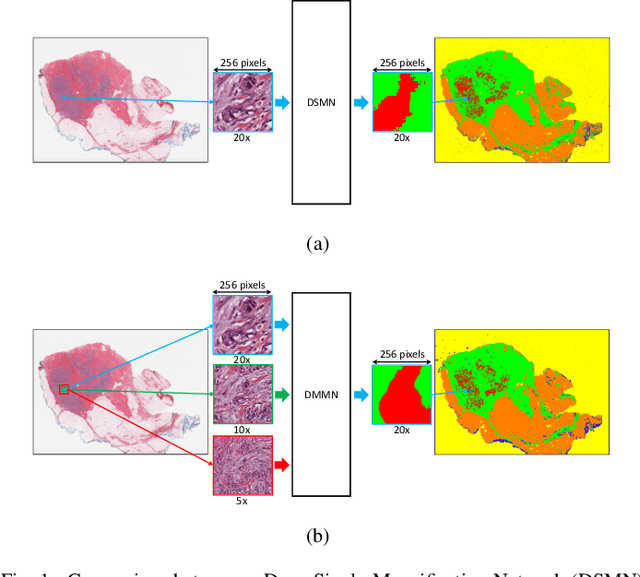
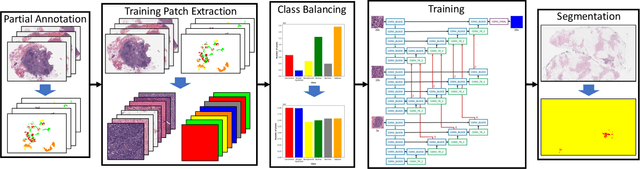
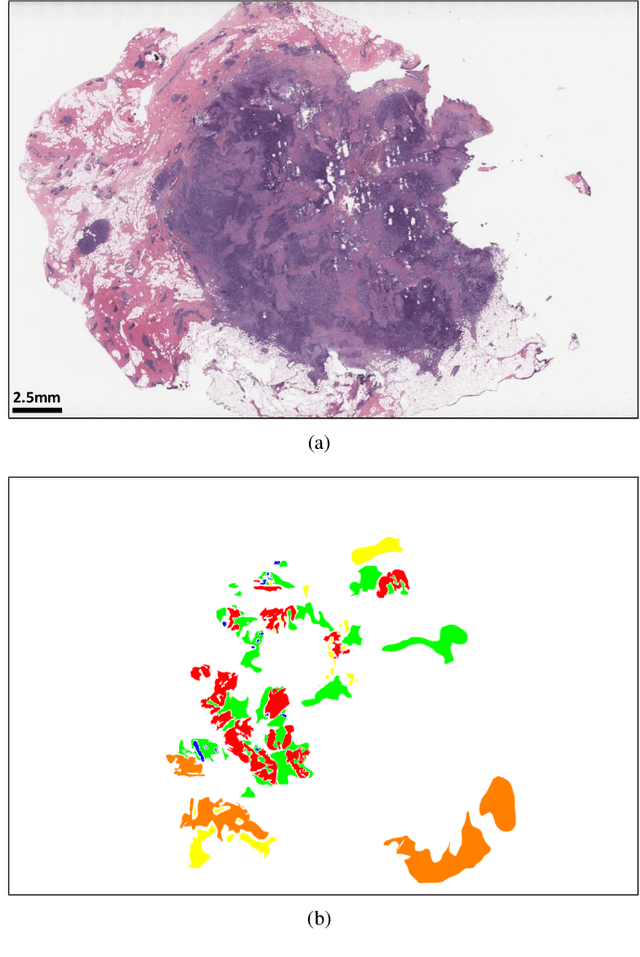
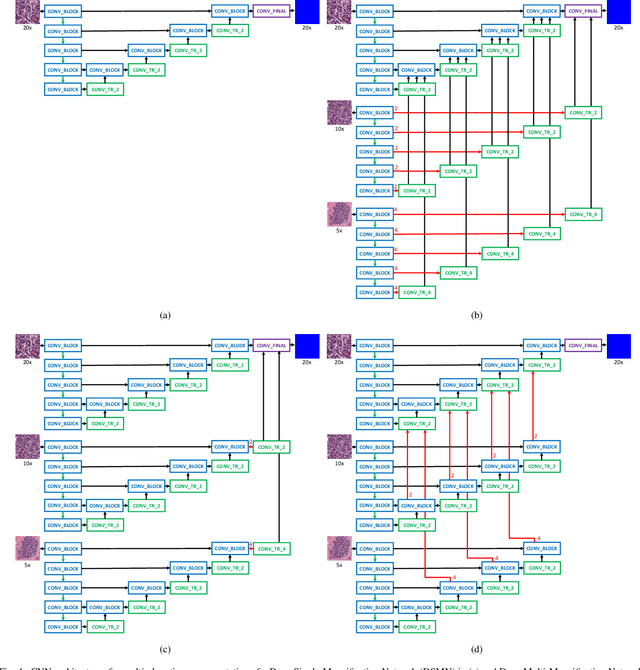
Breast carcinoma is one of the most common cancers for women in the United States. Pathologic analysis of surgical excision specimens for breast carcinoma is important to evaluate the completeness of surgical excision and has implications for future treatment. This analysis is performed manually by pathologists reviewing histologic slides prepared from formalin-fixed tissue. Digital pathology has provided means to digitize the glass slides and generate whole slide images. Computational pathology enables whole slide images to be automatically analyzed to assist pathologists, especially with the advancement of deep learning. The whole slide images generally contain giga-pixels of data, so it is impractical to process the images at the whole-slide-level. Most of the current deep learning techniques process the images at the patch-level, but they may produce poor results by looking at individual patches with a narrow field-of-view at a single magnification. In this paper, we present Deep Multi-Magnification Networks (DMMNs) to resemble how pathologists analyze histologic slides using microscopes. Our multi-class tissue segmentation architecture processes a set of patches from multiple magnifications to make more accurate predictions. For our supervised training, we use partial annotations to reduce the burden of annotators. Our segmentation architecture with multi-encoder, multi-decoder, and multi-concatenation outperforms other segmentation architectures on breast datasets and can be used to facilitate pathologists' assessments of breast cancer.
Bayesian ensemble learning for image denoising
Aug 06, 2013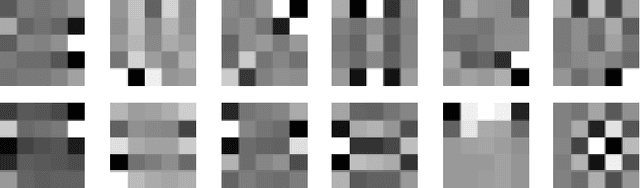

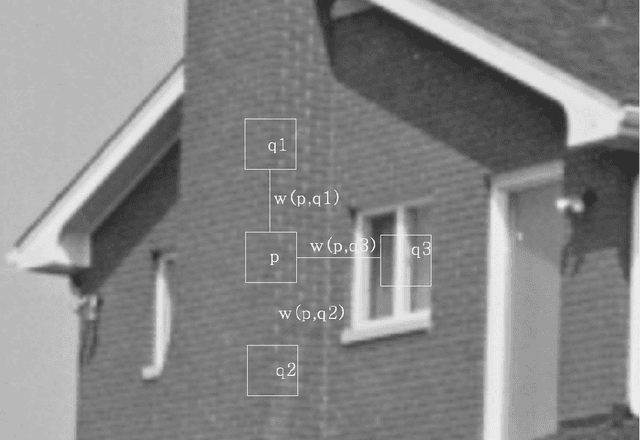

Natural images are often affected by random noise and image denoising has long been a central topic in Computer Vision. Many algorithms have been introduced to remove the noise from the natural images, such as Gaussian, Wiener filtering and wavelet thresholding. However, many of these algorithms remove the fine edges and make them blur. Recently, many promising denoising algorithms have been introduced such as Non-local Means, Fields of Experts, and BM3D. In this paper, we explore Bayesian method of ensemble learning for image denoising. Ensemble methods seek to combine multiple different algorithms to retain the strengths of all methods and the weaknesses of none. Bayesian ensemble models are Non-local Means and Fields of Experts, the very successful recent algorithms. The Non-local Means presumes that the image contains an extensive amount of self-similarity. The approach of the Fields of Experts model extends traditional Markov Random Field model by learning potential functions over extended pixel neighborhoods. The two models are implemented and image denoising is performed on natural images. The experimental results obtained are used to compare with the single algorithm and discuss the ensemble learning and their approaches. Comparing to the results of Non-local Means and Fields of Experts, Ensemble learning showed improvement nearly 1dB.
Few-Shot Abstract Visual Reasoning With Spectral Features
Oct 04, 2019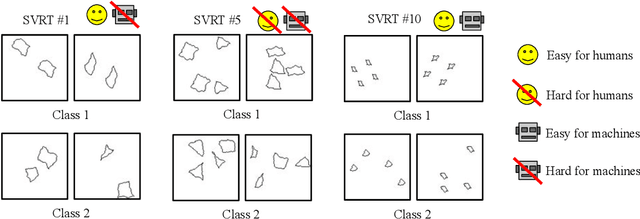
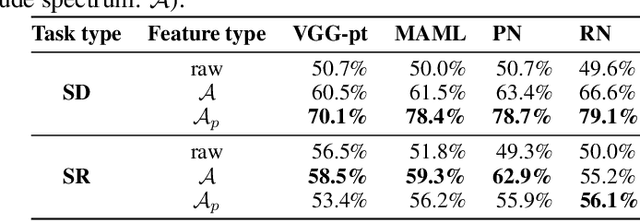
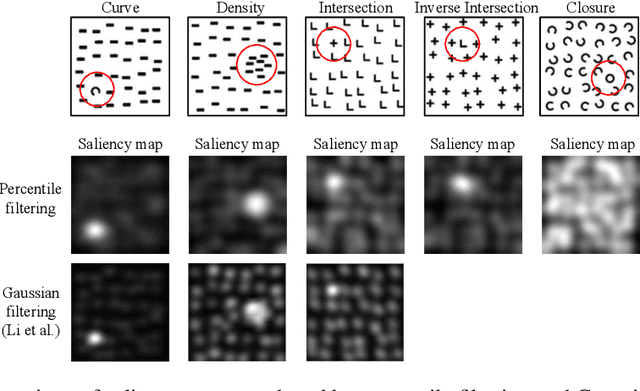
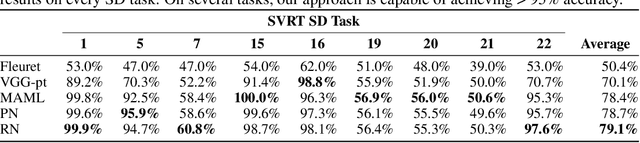
We present an image preprocessing technique capable of improving the performance of few-shot classifiers on abstract visual reasoning tasks. Many visual reasoning tasks with abstract features are easy for humans to learn with few examples but very difficult for computer vision approaches with the same number of samples, despite the ability for deep learning models to learn abstract features. Same-different (SD) problems represent a type of visual reasoning task requiring knowledge of pattern repetition within individual images, and modern computer vision approaches have largely faltered on these classification problems, even when provided with vast amounts of training data. We propose a simple method for solving these problems based on the insight that removing peaks from the amplitude spectrum of an image is capable of emphasizing the unique parts of the image. When combined with several classifiers, our method performs well on the SD SVRT tasks with few-shot learning, improving upon the best comparable results on all tasks, with average absolute accuracy increases nearly 40% for some classifiers. In particular, we find that combining Relational Networks with this image preprocessing approach improves their performance from chance-level to over 90% accuracy on several SD tasks.
Image classification by visual bag-of-words refinement and reduction
Jan 18, 2015

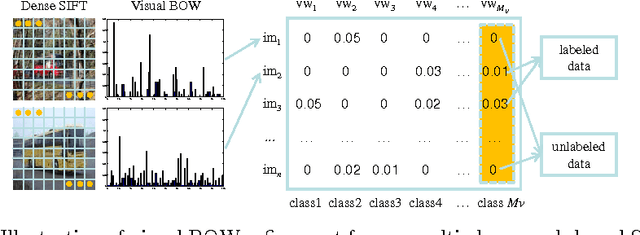

This paper presents a new framework for visual bag-of-words (BOW) refinement and reduction to overcome the drawbacks associated with the visual BOW model which has been widely used for image classification. Although very influential in the literature, the traditional visual BOW model has two distinct drawbacks. Firstly, for efficiency purposes, the visual vocabulary is commonly constructed by directly clustering the low-level visual feature vectors extracted from local keypoints, without considering the high-level semantics of images. That is, the visual BOW model still suffers from the semantic gap, and thus may lead to significant performance degradation in more challenging tasks (e.g. social image classification). Secondly, typically thousands of visual words are generated to obtain better performance on a relatively large image dataset. Due to such large vocabulary size, the subsequent image classification may take sheer amount of time. To overcome the first drawback, we develop a graph-based method for visual BOW refinement by exploiting the tags (easy to access although noisy) of social images. More notably, for efficient image classification, we further reduce the refined visual BOW model to a much smaller size through semantic spectral clustering. Extensive experimental results show the promising performance of the proposed framework for visual BOW refinement and reduction.
NIT-Agartala-NLP-Team at SemEval-2020 Task 8: Building Multimodal Classifiers to tackle Internet Humor
May 16, 2020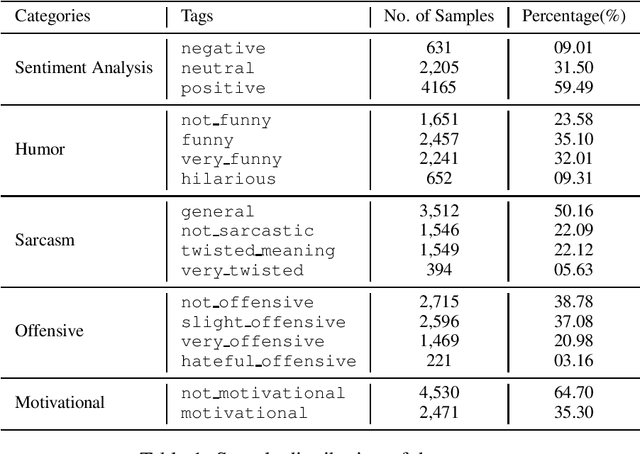
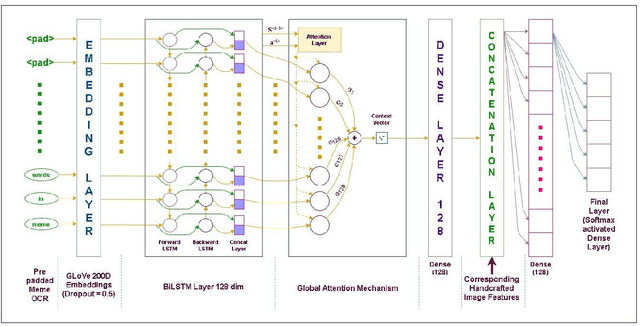


The paper describes the systems submitted to SemEval-2020 Task 8: Memotion by the `NIT-Agartala-NLP-Team'. A dataset of 8879 memes was made available by the task organizers to train and test our models. Our systems include a Logistic Regression baseline, a BiLSTM + Attention-based learner and a transfer learning approach with BERT. For the three sub-tasks A, B and C, we attained ranks 24/33, 11/29 and 15/26, respectively. We highlight our difficulties in harnessing image information as well as some techniques and handcrafted features we employ to overcome these issues. We also discuss various modelling issues and theorize possible solutions and reasons as to why these problems persist.
Switchblade -- a Neural Network for Hard 2D Tasks
Jun 29, 2020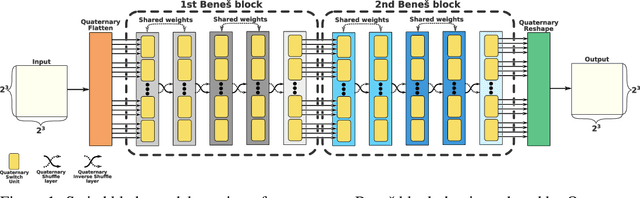

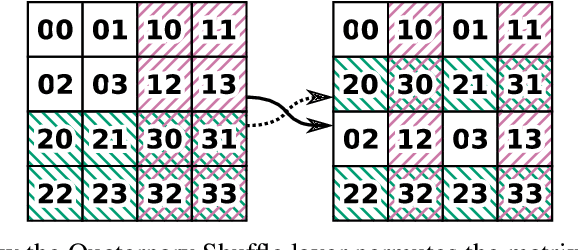
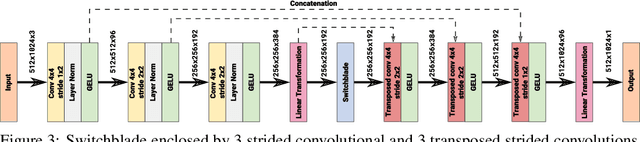
Convolutional neural networks have become the main tools for processing two-dimensional data. They work well for images, yet convolutions have a limited receptive field that prevents its applications to more complex 2D tasks. We propose a new neural network model, named Switchblade, that can efficiently exploit long-range dependencies in 2D data and solve much more challenging tasks. It has close-to-optimal $\mathcal{O}(n^2 \log{n})$ complexity for processing $n \times n$ data matrix. Besides the common image classification and segmentation, we consider a diverse set of algorithmic tasks on matrices and graphs. Switchblade can infer highly complex matrix squaring and graph triangle finding algorithms purely from input-output examples. We show that our model is likewise suitable for logical reasoning tasks -- it attains perfect accuracy on Sudoku puzzle solving. Additionally, we introduce a new dataset for predicting the checkmating move in chess on which our model achieves 72.5% accuracy.
Detecting Transaction-based Tax Evasion Activities on Social Media Platforms Using Multi-modal Deep Neural Networks
Jul 27, 2020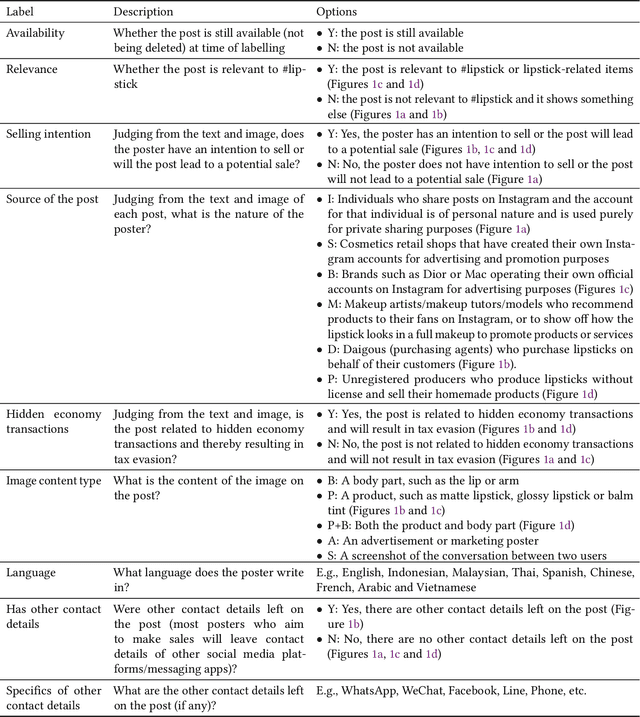

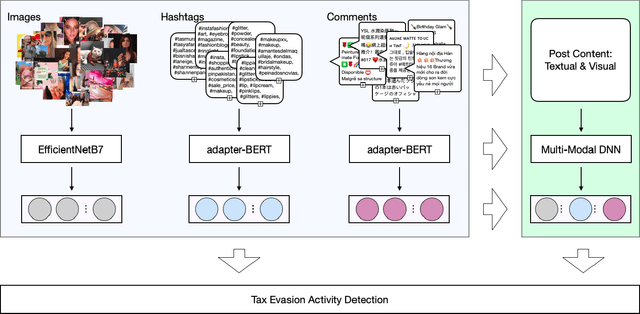
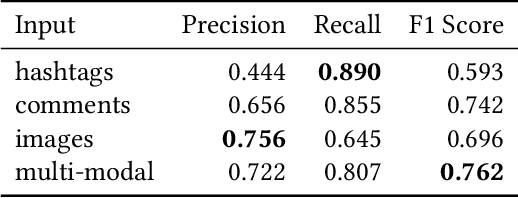
Social media platforms now serve billions of users by providing convenient means of communication, content sharing and even payment between different users. Due to such convenient and anarchic nature, they have also been used rampantly to promote and conduct business activities between unregistered market participants without paying taxes. Tax authorities worldwide face difficulties in regulating these hidden economy activities by traditional regulatory means. This paper presents a machine learning based Regtech tool for international tax authorities to detect transaction-based tax evasion activities on social media platforms. To build such a tool, we collected a dataset of 58,660 Instagram posts and manually labelled 2,081 sampled posts with multiple properties related to transaction-based tax evasion activities. Based on the dataset, we developed a multi-modal deep neural network to automatically detect suspicious posts. The proposed model combines comments, hashtags and image modalities to produce the final output. As shown by our experiments, the combined model achieved an AUC of 0.808 and F1 score of 0.762, outperforming any single modality models. This tool could help tax authorities to identify audit targets in an efficient and effective manner, and combat social e-commerce tax evasion in scale.