 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Part-Aware Data Augmentation for 3D Object Detection in Point Cloud
Jul 27, 2020
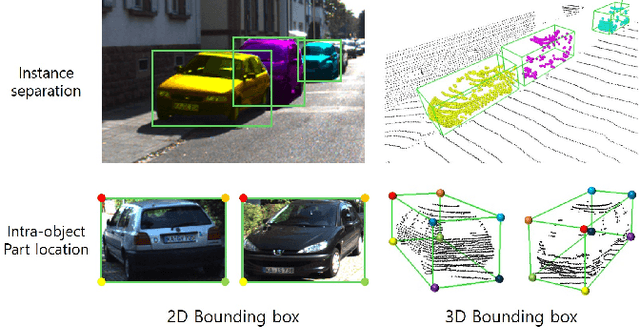
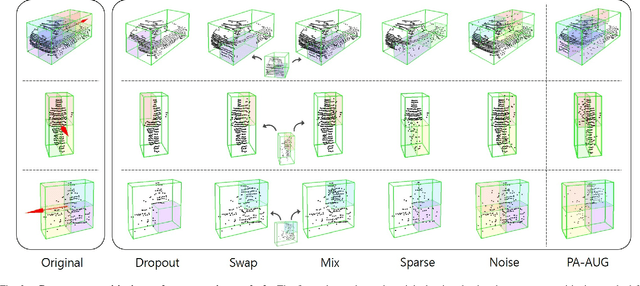
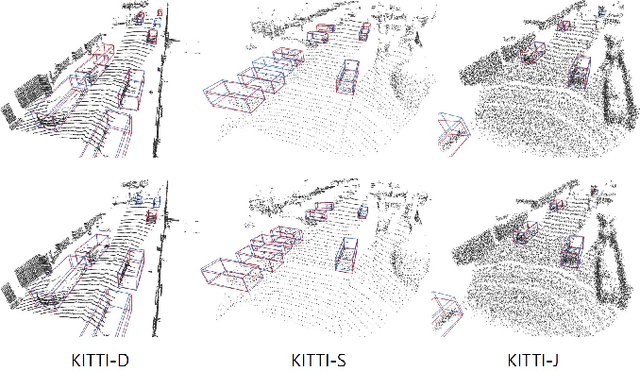
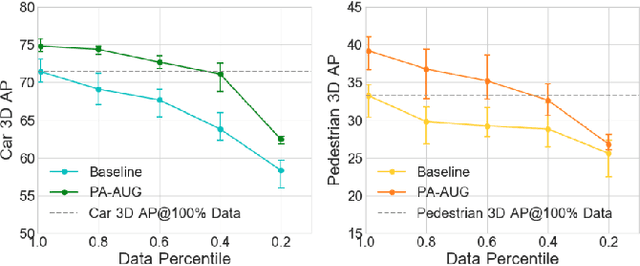
Data augmentation has greatly contributed to improving the performance in image recognition tasks, and a lot of related studies have been conducted. However, data augmentation on 3D point cloud data has not been much explored. 3D label has more sophisticated and rich structural information than the 2D label, so it enables more diverse and effective data augmentation. In this paper, we propose part-aware data augmentation (PA-AUG) that can better utilize rich information of 3D label to enhance the performance of 3D object detectors. PA-AUG divides objects into partitions and stochastically applies five novel augmentation methods to each local region. It is compatible with existing point cloud data augmentation methods and can be used universally regardless of the detector's architecture. PA-AUG has improved the performance of state-of-the-art 3D object detector for all classes of the KITTI dataset and has the equivalent effect of increasing the train data by about 2.5$\times$. We also show that PA-AUG not only increases performance for a given dataset but also is robust to corrupted data. CODE WILL BE AVAILABLE.
Unstructured Road Vanishing Point Detection Using the Convolutional Neural Network and Heatmap Regression
Jun 08, 2020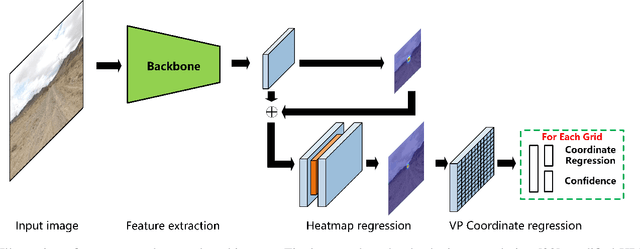
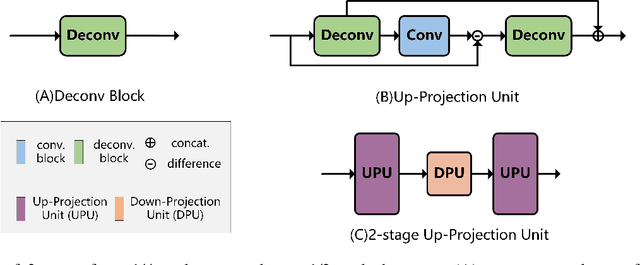


Unstructured road vanishing point (VP) detection is a challenging problem, especially in the field of autonomous driving. In this paper, we proposed a novel solution combining the convolutional neural network (CNN) and heatmap regression to detect unstructured road VP. The proposed algorithm firstly adopts a lightweight backbone, i.e., depthwise convolution modified HRNet, to extract hierarchical features of the unstructured road image. Then, three advanced strategies, i.e., multi-scale supervised learning, heatmap super-resolution, and coordinate regression techniques are utilized to achieve fast and high-precision unstructured road VP detection. The empirical results on Kong's dataset show that our proposed approach enjoys the highest detection accuracy compared with state-of-the-art methods under various conditions in real-time, achieving the highest speed of 33 fps.
UESegNet: Context Aware Unconstrained ROI Segmentation Networks for Ear Biometric
Oct 08, 2020
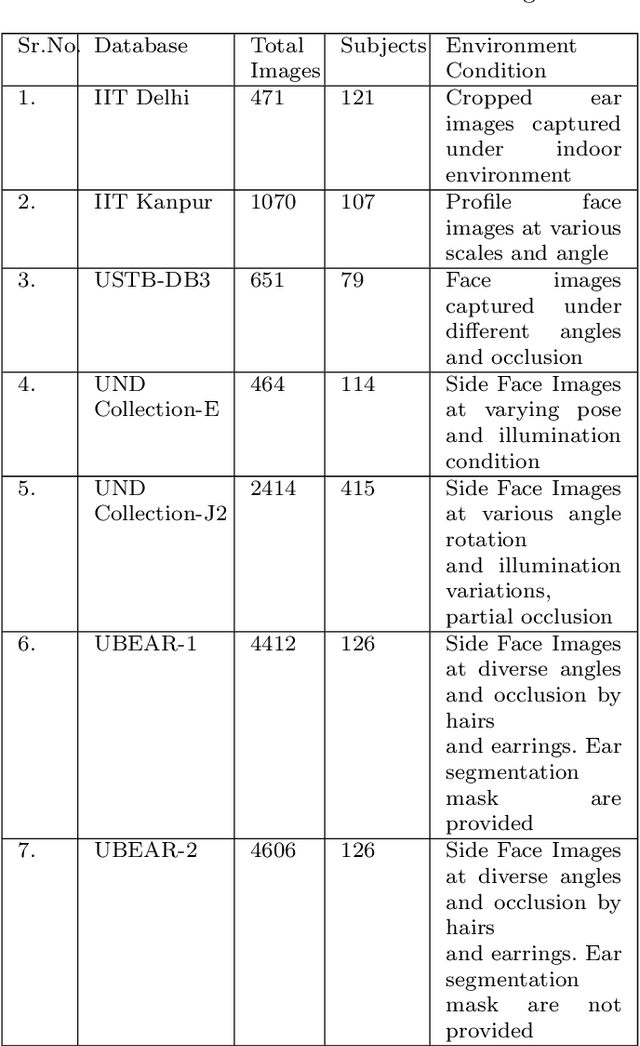
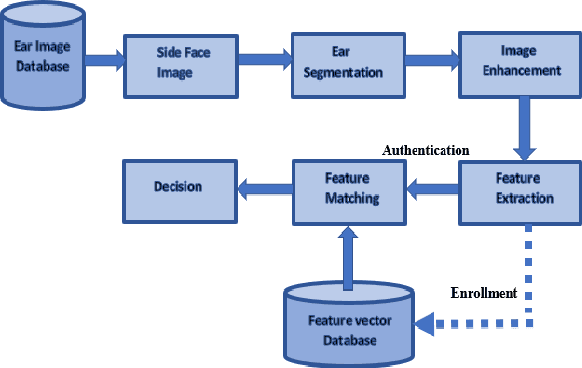
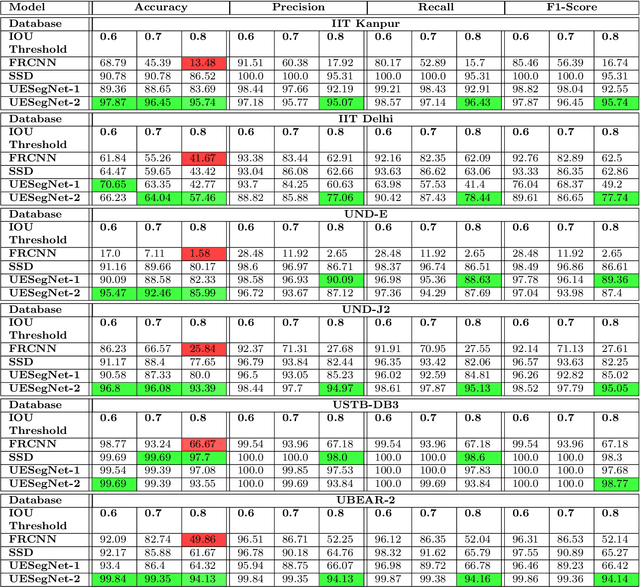
Biometric-based personal authentication systems have seen a strong demand mainly due to the increasing concern in various privacy and security applications. Although the use of each biometric trait is problem dependent, the human ear has been found to have enough discriminating characteristics to allow its use as a strong biometric measure. To locate an ear in a 2D side face image is a challenging task, numerous existing approaches have achieved significant performance, but the majority of studies are based on the constrained environment. However, ear biometrics possess a great level of difficulties in the unconstrained environment, where pose, scale, occlusion, illuminations, background clutter etc. varies to a great extent. To address the problem of ear localization in the wild, we have proposed two high-performance region of interest (ROI) segmentation models UESegNet-1 and UESegNet-2, which are fundamentally based on deep convolutional neural networks and primarily uses contextual information to localize ear in the unconstrained environment. Additionally, we have applied state-of-the-art deep learning models viz; FRCNN (Faster Region Proposal Network) and SSD (Single Shot MultiBox Detecor) for ear localization task. To test the model's generalization, they are evaluated on six different benchmark datasets viz; IITD, IITK, USTB-DB3, UND-E, UND-J2 and UBEAR, all of which contain challenging images. The performance of the models is compared on the basis of object detection performance measure parameters such as IOU (Intersection Over Union), Accuracy, Precision, Recall, and F1-Score. It has been observed that the proposed models UESegNet-1 and UESegNet-2 outperformed the FRCNN and SSD at higher values of IOUs i.e. an accuracy of 100\% is achieved at IOU 0.5 on majority of the databases.
A Method for Identifying Origin of Digital Images Using a Convolution Neural Network
Nov 02, 2019

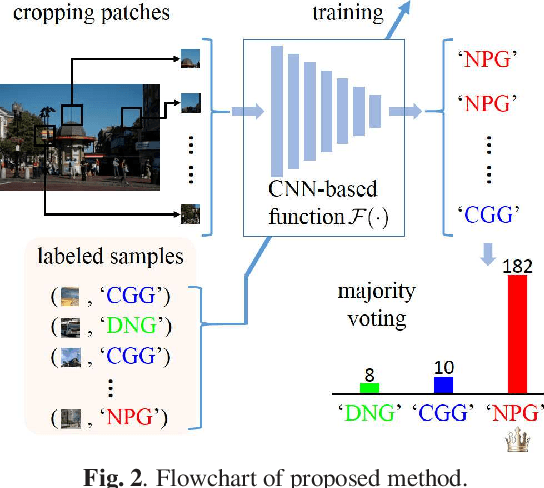
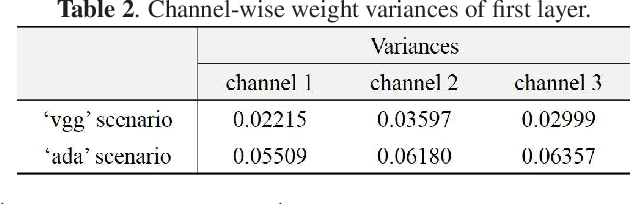
The rapid development of deep learning techniques has created new challenges in identifying the origin of digital images because generative adversarial networks and variational autoencoders can create plausible digital images whose contents are not present in natural scenes. In this paper, we consider the origin that can be broken down into three categories: natural photographic image (NPI), computer generated graphic (CGG), and deep network generated image (DGI). A method is presented for effectively identifying the origin of digital images that is based on a convolutional neural network (CNN) and uses a local-to-global framework to reduce training complexity. By feeding labeled data, the CNN is trained to predict the origin of local patches cropped from an image. The origin of the full-size image is then determined by majority voting. Unlike previous forensic methods, the CNN takes the raw pixels as input without the aid of "residual map". Experimental results revealed that not only the high-frequency components but also the middle-frequency ones contribute to origin identification. The proposed method achieved up to 95.21% identification accuracy and behaved robustly against several common post-processing operations including JPEG compression, scaling, geometric transformation, and contrast stretching. The quantitative results demonstrate that the proposed method is more effective than handcrafted feature-based methods.
Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection
May 28, 2020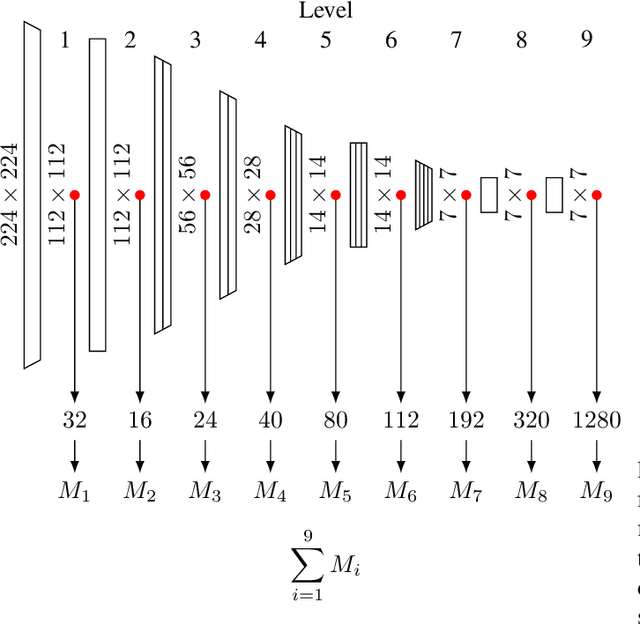
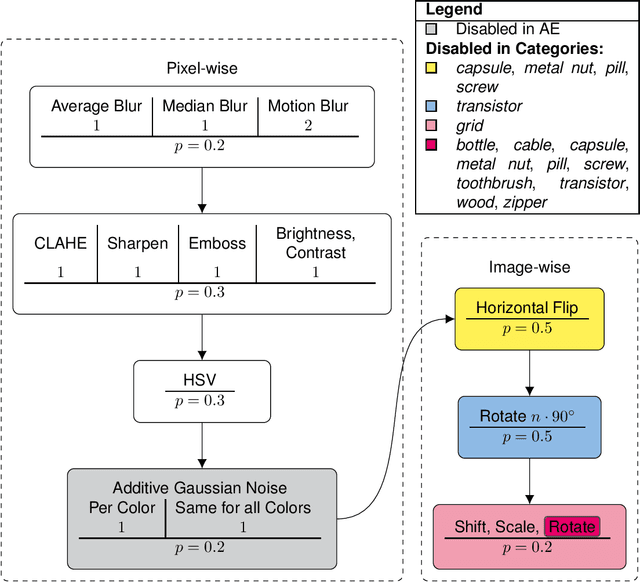
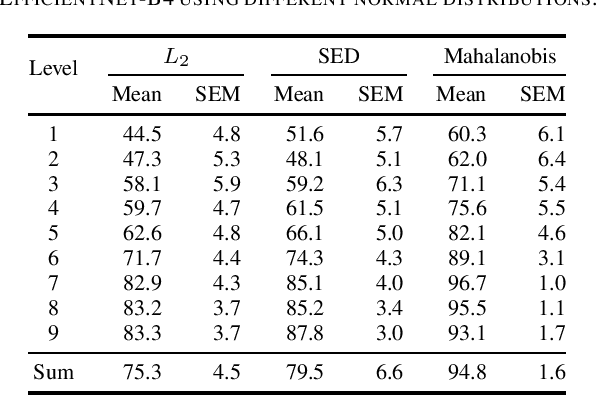
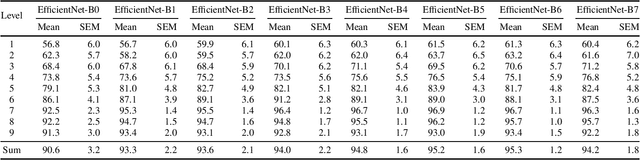
Anomaly Detection (AD) in images is a fundamental computer vision problem and refers to identifying images and/or image substructures that deviate significantly from the norm. Popular AD algorithms commonly try to learn a model of normality from scratch using task specific datasets, but are limited to semi-supervised approaches employing mostly normal data due to the inaccessibility of anomalies on a large scale combined with the ambiguous nature of anomaly appearance. We follow an alternative approach and demonstrate that deep feature representations learned by discriminative models on large natural image datasets are well suited to describe normality and detect even subtle anomalies. Our model of normality is established by fitting a multivariate Gaussian to deep feature representations of classification networks trained on ImageNet using normal data only in a transfer learning setting. By subsequently applying the Mahalanobis distance as the anomaly score we outperform the current state of the art on the public MVTec AD dataset, achieving an Area Under the Receiver Operating Characteristic curve of $95.8 \pm 1.2$ (mean $\pm$ SEM) over all 15 classes. We further investigate why the learned representations are discriminative to the AD task using Principal Component Analysis. We find that the principal components containing little variance in normal data are the ones crucial for discriminating between normal and anomalous instances. This gives a possible explanation to the often sub-par performance of AD approaches trained from scratch using normal data only. By selectively fitting a multivariate Gaussian to these most relevant components only we are able to further reduce model complexity while retaining AD performance. We also investigate setting the working point by selecting acceptable False Positive Rate thresholds based on the multivariate Gaussian assumption.
Convolutional Neural Network and decision support in medical imaging: case study of the recognition of blood cell subtypes
Nov 19, 2019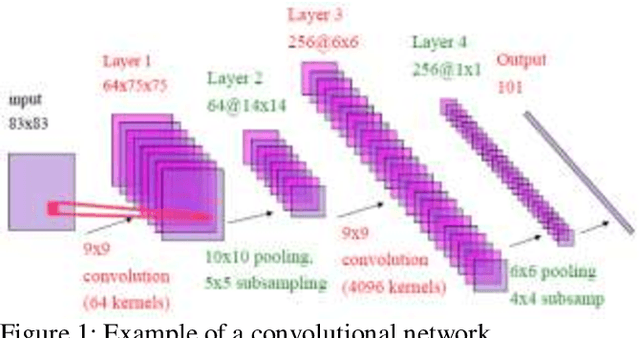
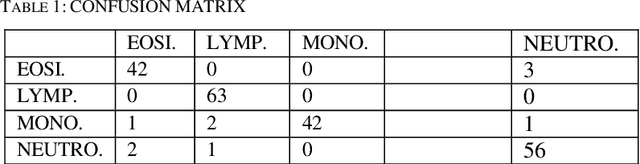
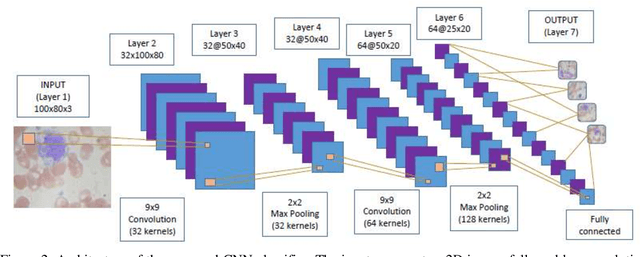
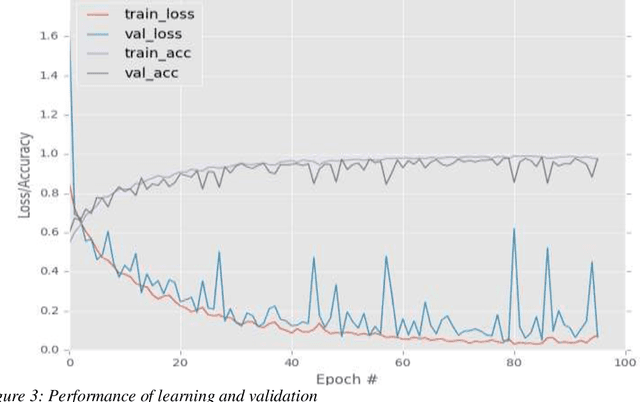
Identifying and characterizing the patient's blood samples is indispensable in diagnostics of malignance suspicious. A painstaking and sometimes subjective task is used in laboratories to manually classify white blood cells. Neural mathematical methods as deep learnings can be very useful in the automated recognition of blood cells. This study uses a particular type of deep learning i.e., convolutional neural networks (CNNs or ConvNets) for image recognition of the four (4) blood cell types (neutrophil, eosinophil, lymphocyte and monocyte) and to enable it to tag them employing a dataset of blood cells with labels for the corresponding cell types. The elements of the database are the input of our CNN and they allowed us to create learning models for the image recognition/classification of the blood cells. We evaluated the recognition performance and outputs learned by the networks in order to implement a neural image recognition model capable of distinguishing polynuclear cells (neutrophil and eosinophil) from those of mononuclear cells (lymphocyte and monocyte). The validation accuracy is 97.77%.
A Region Based Easy Path Wavelet Transform For Sparse Image Representation
Feb 15, 2017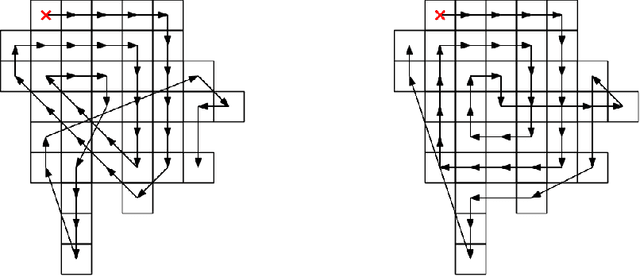
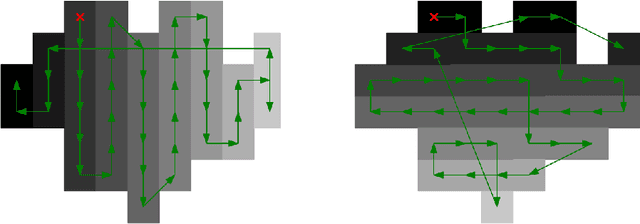
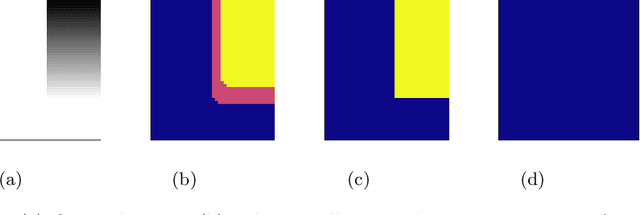

The Easy Path Wavelet Transform is an adaptive transform for bivariate functions (in particular natural images) which has been proposed in [1]. It provides a sparse representation by finding a path in the domain of the function leveraging the local correlations of the function values. It then applies a one dimensional wavelet transform to the obtained vector, decimates the points and iterates the procedure. The main drawback of such method is the need to store, for each level of the transform, the path which vectorizes the two dimensional data. Here we propose a variation on the method which consists of firstly applying a segmentation procedure to the function domain, partitioning it into regions where the variation in the function values is low; in a second step, inside each such region, a path is found in some deterministic way, i.e. not data-dependent. This circumvents the need to store the paths at each level, while still obtaining good quality lossy compression. This method is particularly well suited to encode a Region of Interest in the image with different quality than the rest of the image. [1] Gerlind Plonka. The easy path wavelet transform: A new adaptive wavelet transform for sparse representation of two-dimensional data. Multiscale Modeling & Simulation, 7(3):1474$-$1496, 2008.
Deep Learning feature selection to unhide demographic recommender systems factors
Jun 17, 2020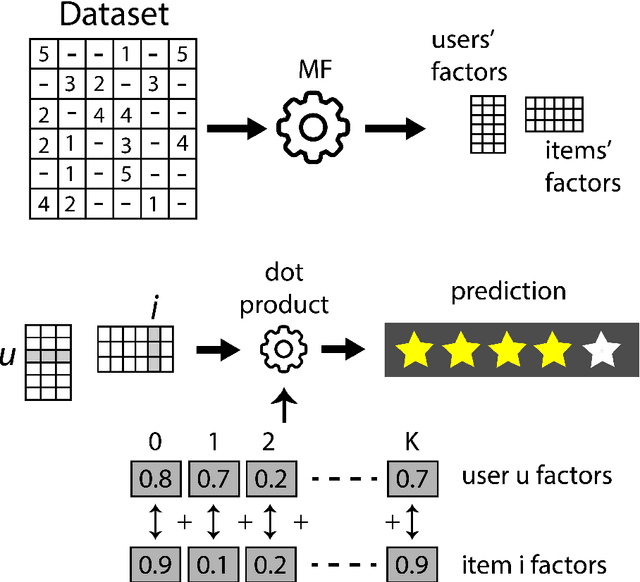

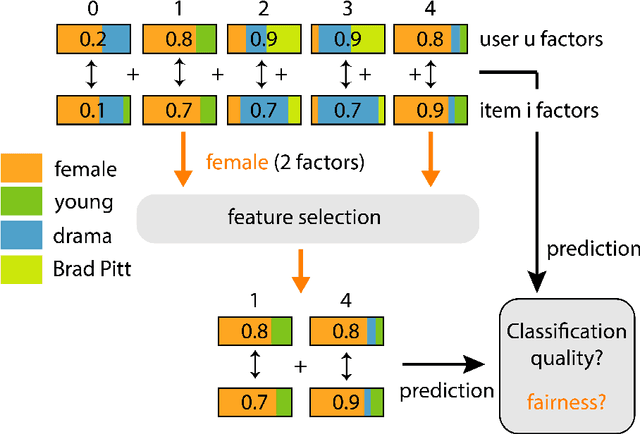
Extracting demographic features from hidden factors is an innovative concept that provides multiple and relevant applications. The matrix factorization model generates factors which do not incorporate semantic knowledge. This paper provides a deep learning-based method: DeepUnHide, able to extract demographic information from the users and items factors in collaborative filtering recommender systems. The core of the proposed method is the gradient-based localization used in the image processing literature to highlight the representative areas of each classification class. Validation experiments make use of two public datasets and current baselines. Results show the superiority of DeepUnHide to make feature selection and demographic classification, compared to the state of art of feature selection methods. Relevant and direct applications include recommendations explanation, fairness in collaborative filtering and recommendation to groups of users.
ASAP-NMS: Accelerating Non-Maximum Suppression Using Spatially Aware Priors
Aug 21, 2020

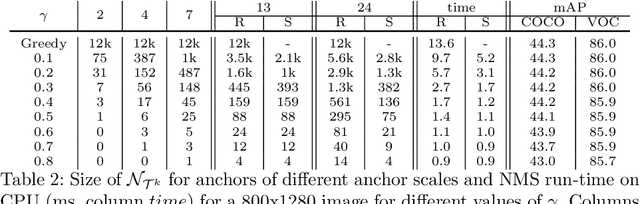

The widely adopted sequential variant of Non Maximum Suppression (or Greedy-NMS) is a crucial module for object-detection pipelines. Unfortunately, for the region proposal stage of two/multi-stage detectors, NMS is turning out to be a latency bottleneck due to its sequential nature. In this article, we carefully profile Greedy-NMS iterations to find that a major chunk of computation is wasted in comparing proposals that are already far-away and have a small chance of suppressing each other. We address this issue by comparing only those proposals that are generated from nearby anchors. The translation-invariant property of the anchor lattice affords generation of a lookup table, which provides an efficient access to nearby proposals, during NMS. This leads to an Accelerated NMS algorithm which leverages Spatially Aware Priors, or ASAP-NMS, and improves the latency of the NMS step from 13.6ms to 1.2 ms on a CPU without sacrificing the accuracy of a state-of-the-art two-stage detector on COCO and VOC datasets. Importantly, ASAP-NMS is agnostic to image resolution and can be used as a simple drop-in module during inference. Using ASAP-NMS at run-time only, we obtain an mAP of 44.2\%@25Hz on the COCO dataset with a V100 GPU.
Multi-modal Transfer Learning for Grasping Transparent and Specular Objects
May 29, 2020
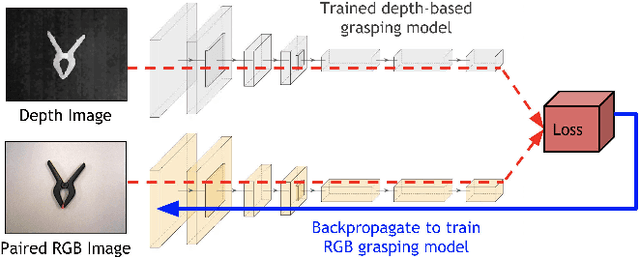
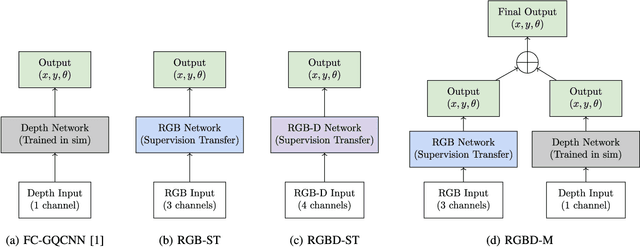

State-of-the-art object grasping methods rely on depth sensing to plan robust grasps, but commercially available depth sensors fail to detect transparent and specular objects. To improve grasping performance on such objects, we introduce a method for learning a multi-modal perception model by bootstrapping from an existing uni-modal model. This transfer learning approach requires only a pre-existing uni-modal grasping model and paired multi-modal image data for training, foregoing the need for ground-truth grasp success labels nor real grasp attempts. Our experiments demonstrate that our approach is able to reliably grasp transparent and reflective objects. Video and supplementary material are available at https://sites.google.com/view/transparent-specular-grasping.
* RA-L with presentation at ICRA 2020