 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Brush Your Text: Synthesize Any Scene Text on Images via Diffusion Model
Dec 19, 2023
Recently, diffusion-based image generation methods are credited for their remarkable text-to-image generation capabilities, while still facing challenges in accurately generating multilingual scene text images. To tackle this problem, we propose Diff-Text, which is a training-free scene text generation framework for any language. Our model outputs a photo-realistic image given a text of any language along with a textual description of a scene. The model leverages rendered sketch images as priors, thus arousing the potential multilingual-generation ability of the pre-trained Stable Diffusion. Based on the observation from the influence of the cross-attention map on object placement in generated images, we propose a localized attention constraint into the cross-attention layer to address the unreasonable positioning problem of scene text. Additionally, we introduce contrastive image-level prompts to further refine the position of the textual region and achieve more accurate scene text generation. Experiments demonstrate that our method outperforms the existing method in both the accuracy of text recognition and the naturalness of foreground-background blending.
Unsupervised Segmentation of Colonoscopy Images
Dec 19, 2023Colonoscopy plays a crucial role in the diagnosis and prognosis of various gastrointestinal diseases. Due to the challenges of collecting large-scale high-quality ground truth annotations for colonoscopy images, and more generally medical images, we explore using self-supervised features from vision transformers in three challenging tasks for colonoscopy images. Our results indicate that image-level features learned from DINO models achieve image classification performance comparable to fully supervised models, and patch-level features contain rich semantic information for object detection. Furthermore, we demonstrate that self-supervised features combined with unsupervised segmentation can be used to discover multiple clinically relevant structures in a fully unsupervised manner, demonstrating the tremendous potential of applying these methods in medical image analysis.
SR-LIVO: LiDAR-Inertial-Visual Odometry and Mapping with Sweep Reconstruction
Dec 28, 2023Existing LiDAR-inertial-visual odometry and mapping (LIV-SLAM) systems mainly utilize the LiDAR-inertial odometry (LIO) module for structure reconstruction and the visual-inertial odometry (VIO) module for color rendering. However, the accuracy of VIO is often compromised by photometric changes, weak textures and motion blur, unlike the more robust LIO. This paper introduces SR-LIVO, an advanced and novel LIV-SLAM system employing sweep reconstruction to align reconstructed sweeps with image timestamps. This allows the LIO module to accurately determine states at all imaging moments, enhancing pose accuracy and processing efficiency. Experimental results on two public datasets demonstrate that: 1) our SRLIVO outperforms existing state-of-the-art LIV-SLAM systems in both pose accuracy and time efficiency; 2) our LIO-based pose estimation prove more accurate than VIO-based ones in several mainstream LIV-SLAM systems (including ours). We have released our source code to contribute to the community development in this field.
Research on the Laws of Multimodal Perception and Cognition from a Cross-cultural Perspective -- Taking Overseas Chinese Gardens as an Example
Dec 29, 2023This study aims to explore the complex relationship between perceptual and cognitive interactions in multimodal data analysis,with a specific emphasis on spatial experience design in overseas Chinese gardens. It is found that evaluation content and images on social media can reflect individuals' concerns and sentiment responses, providing a rich data base for cognitive research that contains both sentimental and image-based cognitive information. Leveraging deep learning techniques, we analyze textual and visual data from social media, thereby unveiling the relationship between people's perceptions and sentiment cognition within the context of overseas Chinese gardens. In addition, our study introduces a multi-agent system (MAS)alongside AI agents. Each agent explores the laws of aesthetic cognition through chat scene simulation combined with web search. This study goes beyond the traditional approach of translating perceptions into sentiment scores, allowing for an extension of the research methodology in terms of directly analyzing texts and digging deeper into opinion data. This study provides new perspectives for understanding aesthetic experience and its impact on architecture and landscape design across diverse cultural contexts, which is an essential contribution to the field of cultural communication and aesthetic understanding.
Toward Spatial Temporal Consistency of Joint Visual Tactile Perception in VR Applications
Dec 29, 2023With the development of VR technology, especially the emergence of the metaverse concept, the integration of visual and tactile perception has become an expected experience in human-machine interaction. Therefore, achieving spatial-temporal consistency of visual and tactile information in VR applications has become a necessary factor for realizing this experience. The state-of-the-art vibrotactile datasets generally contain temporal-level vibrotactile information collected by randomly sliding on the surface of an object, along with the corresponding image of the material/texture. However, they lack the position/spatial information that corresponds to the signal acquisition, making it difficult to achieve spatiotemporal alignment of visual-tactile data. Therefore, we develop a new data acquisition system in this paper which can collect visual and vibrotactile signals of different textures/materials with spatial and temporal consistency. In addition, we develop a VR-based application call "V-Touching" by leveraging the dataset generated by the new acquisition system, which can provide pixel-to-taxel joint visual-tactile perception when sliding over the surface of objects in the virtual environment with distinct vibrotactile feedback of different textures/materials.
KOALA: Self-Attention Matters in Knowledge Distillation of Latent Diffusion Models for Memory-Efficient and Fast Image Synthesis
Dec 07, 2023Stable diffusion is the mainstay of the text-to-image (T2I) synthesis in the community due to its generation performance and open-source nature. Recently, Stable Diffusion XL (SDXL), the successor of stable diffusion, has received a lot of attention due to its significant performance improvements with a higher resolution of 1024x1024 and a larger model. However, its increased computation cost and model size require higher-end hardware(e.g., bigger VRAM GPU) for end-users, incurring higher costs of operation. To address this problem, in this work, we propose an efficient latent diffusion model for text-to-image synthesis obtained by distilling the knowledge of SDXL. To this end, we first perform an in-depth analysis of the denoising U-Net in SDXL, which is the main bottleneck of the model, and then design a more efficient U-Net based on the analysis. Secondly, we explore how to effectively distill the generation capability of SDXL into an efficient U-Net and eventually identify four essential factors, the core of which is that self-attention is the most important part. With our efficient U-Net and self-attention-based knowledge distillation strategy, we build our efficient T2I models, called KOALA-1B & -700M, while reducing the model size up to 54% and 69% of the original SDXL model. In particular, the KOALA-700M is more than twice as fast as SDXL while still retaining a decent generation quality. We hope that due to its balanced speed-performance tradeoff, our KOALA models can serve as a cost-effective alternative to SDXL in resource-constrained environments.
A Two-stream Hybrid CNN-Transformer Network for Skeleton-based Human Interaction Recognition
Dec 31, 2023Human Interaction Recognition is the process of identifying interactive actions between multiple participants in a specific situation. The aim is to recognise the action interactions between multiple entities and their meaning. Many single Convolutional Neural Network has issues, such as the inability to capture global instance interaction features or difficulty in training, leading to ambiguity in action semantics. In addition, the computational complexity of the Transformer cannot be ignored, and its ability to capture local information and motion features in the image is poor. In this work, we propose a Two-stream Hybrid CNN-Transformer Network (THCT-Net), which exploits the local specificity of CNN and models global dependencies through the Transformer. CNN and Transformer simultaneously model the entity, time and space relationships between interactive entities respectively. Specifically, Transformer-based stream integrates 3D convolutions with multi-head self-attention to learn inter-token correlations; We propose a new multi-branch CNN framework for CNN-based streams that automatically learns joint spatio-temporal features from skeleton sequences. The convolutional layer independently learns the local features of each joint neighborhood and aggregates the features of all joints. And the raw skeleton coordinates as well as their temporal difference are integrated with a dual-branch paradigm to fuse the motion features of the skeleton. Besides, a residual structure is added to speed up training convergence. Finally, the recognition results of the two branches are fused using parallel splicing. Experimental results on diverse and challenging datasets, demonstrate that the proposed method can better comprehend and infer the meaning and context of various actions, outperforming state-of-the-art methods.
Fast Diffusion-Based Counterfactuals for Shortcut Removal and Generation
Dec 21, 2023Shortcut learning is when a model -- e.g. a cardiac disease classifier -- exploits correlations between the target label and a spurious shortcut feature, e.g. a pacemaker, to predict the target label based on the shortcut rather than real discriminative features. This is common in medical imaging, where treatment and clinical annotations correlate with disease labels, making them easy shortcuts to predict disease. We propose a novel detection and quantification of the impact of potential shortcut features via a fast diffusion-based counterfactual image generation that can synthetically remove or add shortcuts. Via a novel inpainting-based modification we spatially limit the changes made with no extra inference step, encouraging the removal of spatially constrained shortcut features while ensuring that the shortcut-free counterfactuals preserve their remaining image features to a high degree. Using these, we assess how shortcut features influence model predictions. This is enabled by our second contribution: An efficient diffusion-based counterfactual explanation method with significant inference speed-up at comparable image quality as state-of-the-art. We confirm this on two large chest X-ray datasets, a skin lesion dataset, and CelebA.
Towards General Purpose Vision Foundation Models for Medical Image Analysis: An Experimental Study of DINOv2 on Radiology Benchmarks
Dec 04, 2023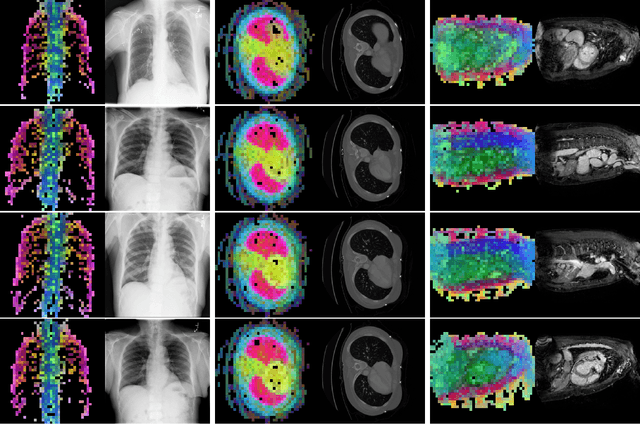
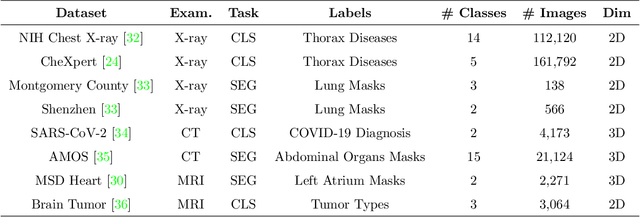
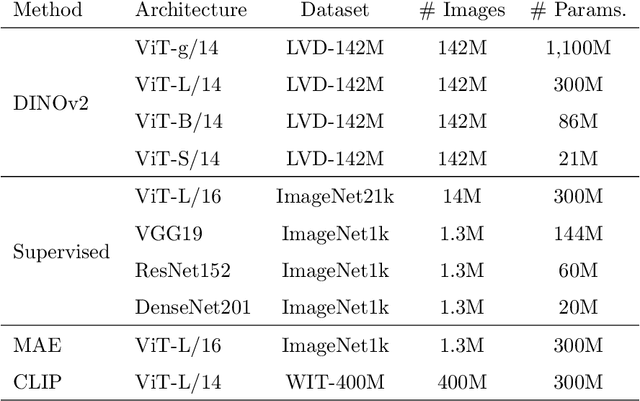
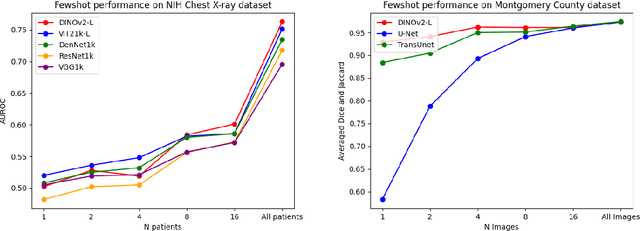
The integration of deep learning systems into the medical domain has been hindered by the resource-intensive process of data annotation and the inability of these systems to generalize to different data distributions. Foundation models, which are models pre-trained on large datasets, have emerged as a solution to reduce reliance on annotated data and enhance model generalizability and robustness. DINOv2, an open-source foundation model pre-trained with self-supervised learning on 142 million curated natural images, excels in extracting general-purpose visual representations, exhibiting promising capabilities across various vision tasks. Nevertheless, a critical question remains unanswered regarding DINOv2's adaptability to radiological imaging, and the clarity on whether its features are sufficiently general to benefit radiology image analysis is yet to be established. Therefore, this study comprehensively evaluates DINOv2 for radiology, conducting over 100 experiments across diverse modalities (X-ray, CT, and MRI). Tasks include disease classification and organ segmentation on both 2D and 3D images, evaluated under different settings like kNN, few-shot learning, linear-probing, end-to-end fine-tuning, and parameter-efficient fine-tuning, to measure the effectiveness and generalizability of the DINOv2 feature embeddings. Comparative analyses with established medical image analysis models, U-Net and TransUnet for segmentation, and CNN and ViT models pre-trained via supervised, weakly supervised, and self-supervised learning for classification, reveal DINOv2's superior performance in segmentation tasks and competitive results in disease classification. The findings contribute insights to potential avenues for optimizing pre-training strategies for medical imaging and enhancing the broader understanding of DINOv2's role in bridging the gap between natural and radiological image analysis.
SA$^2$VP: Spatially Aligned-and-Adapted Visual Prompt
Dec 16, 2023As a prominent parameter-efficient fine-tuning technique in NLP, prompt tuning is being explored its potential in computer vision. Typical methods for visual prompt tuning follow the sequential modeling paradigm stemming from NLP, which represents an input image as a flattened sequence of token embeddings and then learns a set of unordered parameterized tokens prefixed to the sequence representation as the visual prompts for task adaptation of large vision models. While such sequential modeling paradigm of visual prompt has shown great promise, there are two potential limitations. First, the learned visual prompts cannot model the underlying spatial relations in the input image, which is crucial for image encoding. Second, since all prompt tokens play the same role of prompting for all image tokens without distinction, it lacks the fine-grained prompting capability, i.e., individual prompting for different image tokens. In this work, we propose the \mymodel model (\emph{SA$^2$VP}), which learns a two-dimensional prompt token map with equal (or scaled) size to the image token map, thereby being able to spatially align with the image map. Each prompt token is designated to prompt knowledge only for the spatially corresponding image tokens. As a result, our model can conduct individual prompting for different image tokens in a fine-grained manner. Moreover, benefiting from the capability of preserving the spatial structure by the learned prompt token map, our \emph{SA$^2$VP} is able to model the spatial relations in the input image, leading to more effective prompting. Extensive experiments on three challenging benchmarks for image classification demonstrate the superiority of our model over other state-of-the-art methods for visual prompt tuning. Code is available at \emph{https://github.com/tommy-xq/SA2VP}.