 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Generalization of Structured Low Rank Algorithms (Deep-SLR)
Dec 07, 2019
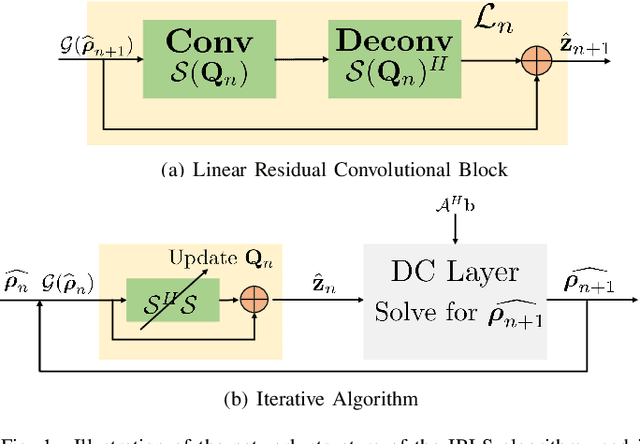
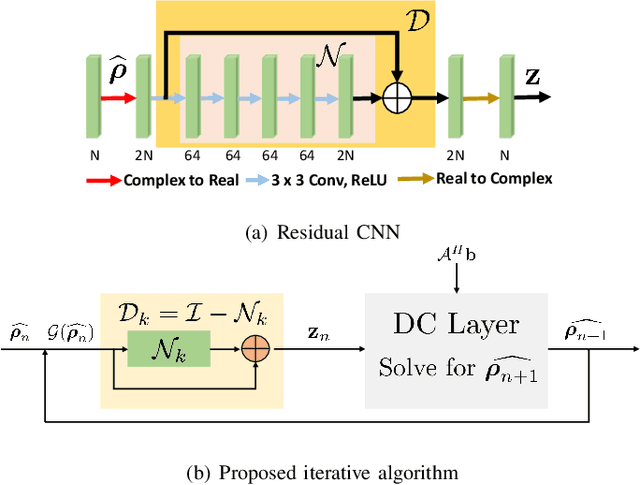
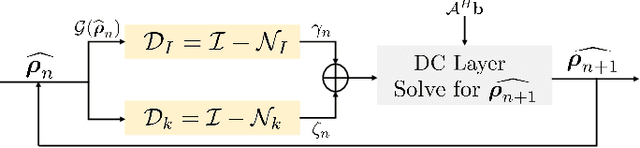
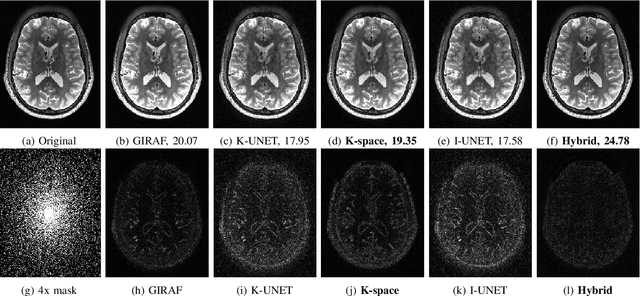
Structured low-rank (SLR) algorithms are emerging as powerful image reconstruction approaches because they can capitalize on several signal properties, which conventional image-based approaches have difficulty in exploiting. The main challenge with this scheme that self learns an annihilation convolutional filterbank from the undersampled data is its high computational complexity. We introduce a deep-learning approach to quite significantly reduce the computational complexity of SLR schemes. Specifically, we pre-learn a CNN-based annihilation filterbank from exemplar data, which is used as a prior in a model-based reconstruction scheme. The CNN parameters are learned in an end-to-end fashion by un-rolling the iterative algorithm. The main difference of the proposed scheme with current model-based deep learning strategies is the learning of non-linear annihilation relations in Fourier space using a modelbased framework. The experimental comparisons show that the proposed scheme can offer similar performance as SLR schemes in the calibrationless parallel MRI setting, while reducing the run-time by around three orders of magnitude. We also combine the proposed scheme with image domain priors, which are complementary, thus further improving the performance over SLR schemes.
Projected-point-based Segmentation: A New Paradigm for LiDAR Point Cloud Segmentation
Aug 10, 2020
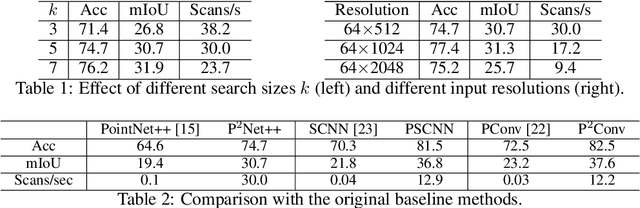
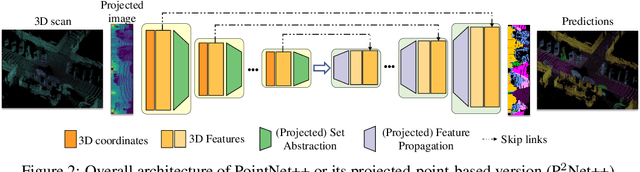

Most point-based semantic segmentation methods are designed for indoor scenarios, but many applications such as autonomous driving vehicles require accurate segmentation for outdoor scenarios. For this goal, light detection and ranging (LiDAR) sensors are often used to collect outdoor environmental data. The problem is that directly applying previous point-based segmentation methods to LiDAR point clouds usually leads to unsatisfactory results due to the domain gap between indoor and outdoor scenarios. To address such a domain gap, we propose a new paradigm, namely projected-point-based methods, to transform point-based methods to a suitable form for LiDAR point cloud segmentation by utilizing the characteristics of LiDAR point clouds. Specifically, we utilize the inherent ordered information of LiDAR points for point sampling and grouping, thus reducing unnecessary computation. All computations are carried out on the projected image, and there are only pointwise convolutions and matrix multiplication in projected-point-based methods. We compare projected-point-based methods with point-based methods on the challenging SemanticKITTI dataset, and experimental results demonstrate that projected-point-based methods achieve better accuracy than all baselines more efficiently. Even with a simple baseline architecture, projected-point-based methods perform favorably against previous state-of-the-art methods. The code will be released upon paper acceptance.
Meta-LR-Schedule-Net: Learned LR Schedules that Scale and Generalize
Jul 29, 2020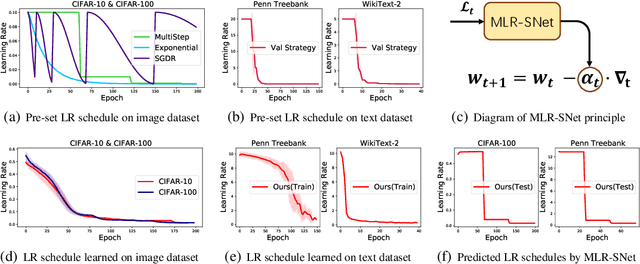

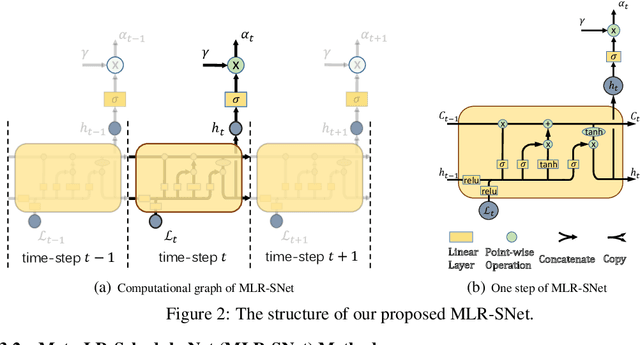
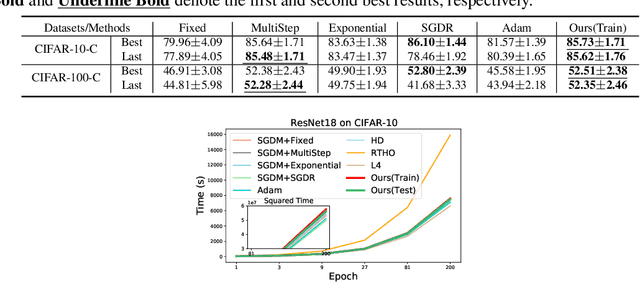
The learning rate (LR) is one of the most important hyper-parameters in stochastic gradient descent (SGD) for deep neural networks (DNNs) training and generalization. However, current hand-designed LR schedules need to manually pre-specify schedule as well as its extra hyper-parameters, which limits its ability to adapt non-convex optimization problems due to the significant variation of training dynamic. To address this issue, we propose a model capable of adaptively learning LR schedule from data. We specifically design a meta-learner with explicit mapping formulation to parameterize LR schedules, which can adjust LR adaptively to comply with current training dynamic by leveraging the information from past training histories. Image and text classification benchmark experiments substantiate the capability of our method for achieving proper LR schedules compared with baseline methods. Moreover, we transfer the learned LR schedule to other various tasks, like different training batch sizes, epochs, datasets, network architectures, especially large scale ImageNet dataset, showing its stronger generalization capability than related methods. Finally, guided by a small set of clean validation set, we show our method can achieve better generalization error when training data is biased with corrupted noise than baseline methods.
CDE-GAN: Cooperative Dual Evolution Based Generative Adversarial Network
Aug 21, 2020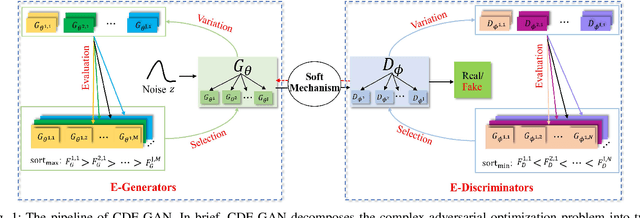
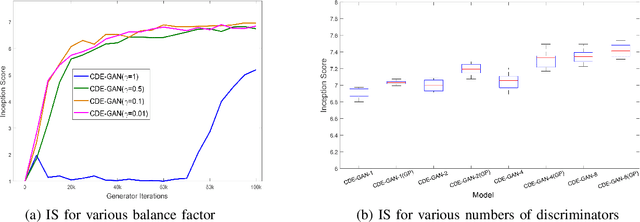
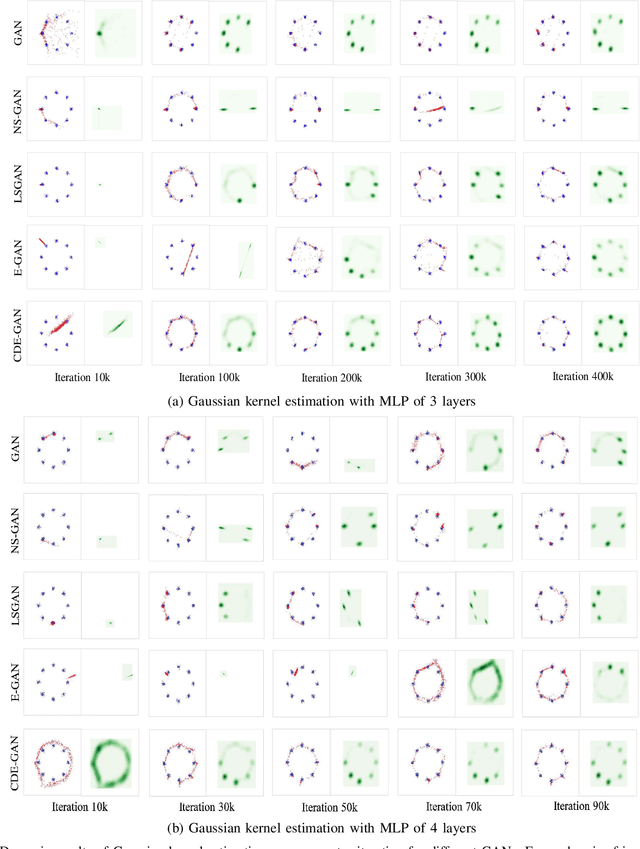

Generative adversarial networks (GANs) have been a popular deep generative model for real-word applications. Despite many recent efforts on GANs have been contributed, however, mode collapse and instability of GANs are still open problems caused by their adversarial optimization difficulties. In this paper, motivated by the cooperative co-evolutionary algorithm, we propose a Cooperative Dual Evolution based Generative Adversarial Network (CDE-GAN) to circumvent these drawbacks. In essence, CDE-GAN incorporates dual evolution with respect to generator(s) and discriminators into a unified evolutionary adversarial framework, thus it exploits the complementary properties and injects dual mutation diversity into training to steadily diversify the estimated density in capturing multi-modes, and to improve generative performance. Specifically, CDE-GAN decomposes the complex adversarial optimization problem into two subproblems (generation and discrimination), and each subproblem is solved with a separated subpopulation (E-Generators and EDiscriminators), evolved by an individual evolutionary algorithm. Additionally, to keep the balance between E-Generators and EDiscriminators, we proposed a Soft Mechanism to cooperate them to conduct effective adversarial training. Extensive experiments on one synthetic dataset and three real-world benchmark image datasets, demonstrate that the proposed CDE-GAN achieves the competitive and superior performance in generating good quality and diverse samples over baselines. The code and more generated results are available at our project homepage https://shiming-chen.github.io/CDE-GAN-website/CDE-GAN.html.
Fused Text Recogniser and Deep Embeddings Improve Word Recognition and Retrieval
Jul 01, 2020
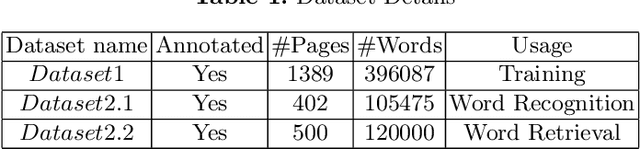
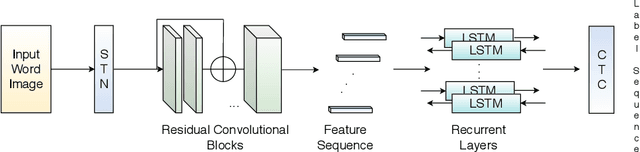

Recognition and retrieval of textual content from the large document collections have been a powerful use case for the document image analysis community. Often the word is the basic unit for recognition as well as retrieval. Systems that rely only on the text recogniser (OCR) output are not robust enough in many situations, especially when the word recognition rates are poor, as in the case of historic documents or digital libraries. An alternative has been word spotting based methods that retrieve/match words based on a holistic representation of the word. In this paper, we fuse the noisy output of text recogniser with a deep embeddings representation derived out of the entire word. We use average and max fusion for improving the ranked results in the case of retrieval. We validate our methods on a collection of Hindi documents. We improve word recognition rate by 1.4 and retrieval by 11.13 in the mAP.
Image reconstruction from dense binary pixels
Dec 06, 2015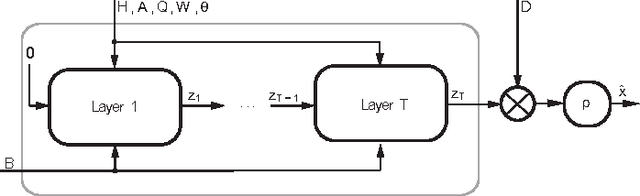


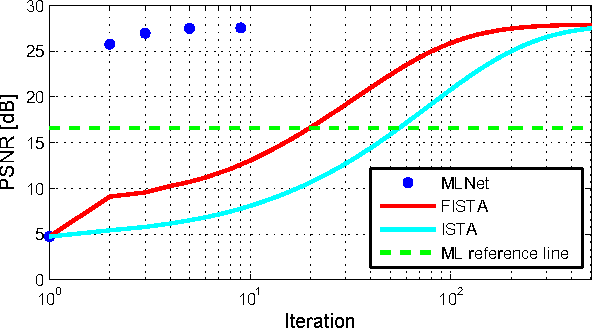
Recently, the dense binary pixel Gigavision camera had been introduced, emulating a digital version of the photographic film. While seems to be a promising solution for HDR imaging, its output is not directly usable and requires an image reconstruction process. In this work, we formulate this problem as the minimization of a convex objective combining a maximum-likelihood term with a sparse synthesis prior. We present MLNet - a novel feed-forward neural network, producing acceptable output quality at a fixed complexity and is two orders of magnitude faster than iterative algorithms. We present state of the art results in the abstract.
Long Range Stereo Matching by Learning Depth and Disparity
Sep 10, 2020
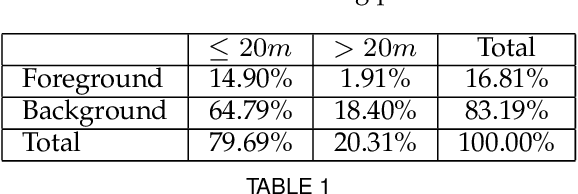
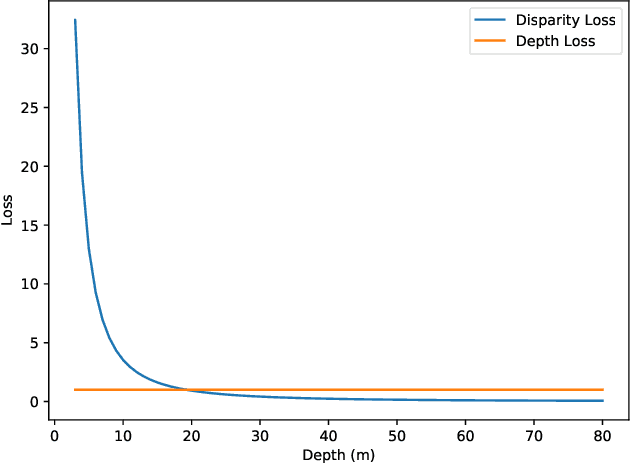
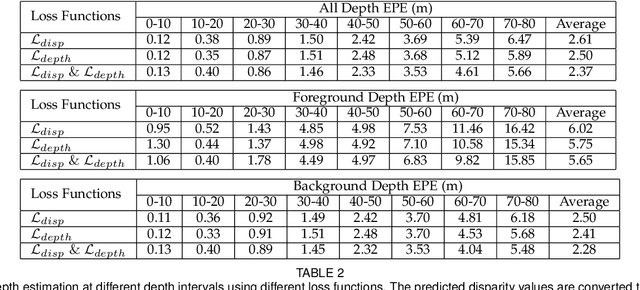
Stereo matching generally involves computation of pixel correspondences and estimation of disparities between rectified image pairs. In many applications including simultaneous localization and mapping (SLAM) and 3D object detection, disparity is particularly needed to calculate depth values. While many recent stereo matching solutions focus on delivering a neural network model that provides better matching and aggregation, little attention has been given to the problems of having bias in training data or selected loss function. As the performance of supervised learning networks largely depends on the properties of training data and its loss function, we will show that by simply allowing the neural network to be aware of a bias, its performance improves. We also demonstrate the existence of bias in both the popular KITTI 2015 stereo dataset and the commonly used smooth L1 loss function. Our solution has two components: The loss is depth-based and has two different parts for foreground and background pixels. The combination of those allows the stereo matching network to evenly focus on all pixels and mitigate the potential of over-fitting caused by the bias. The efficacy of our approach is demonstrated by an extensive set of experiments and benchmarking those against the state-of-the-art results. In particular, our results show that the proposed loss function is very effective for the estimation of depth and disparity for objects at distances beyond 50 meters, which represents the frontier for the emerging applications of the passive vision in building autonomous navigation systems.
D2D: Keypoint Extraction with Describe to Detect Approach
May 27, 2020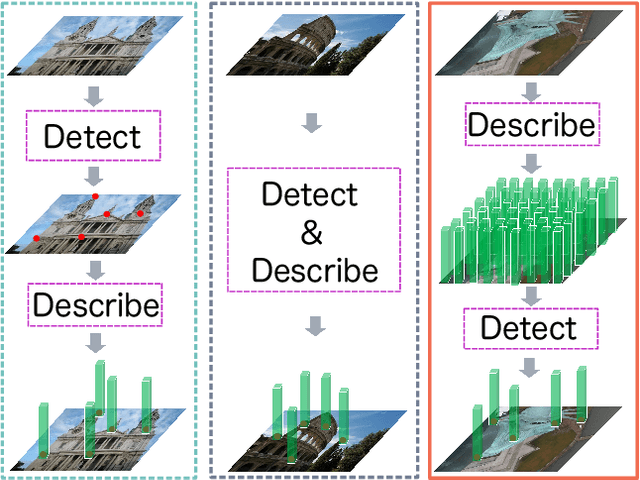
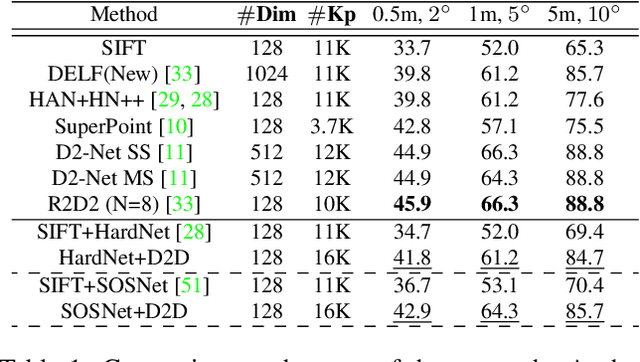
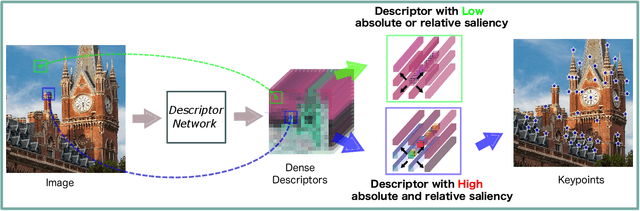
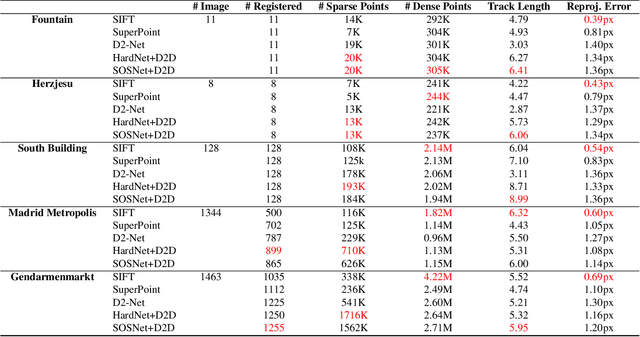
In this paper, we present a novel approach that exploits the information within the descriptor space to propose keypoint locations. Detect then describe, or detect and describe jointly are two typical strategies for extracting local descriptors. In contrast, we propose an approach that inverts this process by first describing and then detecting the keypoint locations. % Describe-to-Detect (D2D) leverages successful descriptor models without the need for any additional training. Our method selects keypoints as salient locations with high information content which is defined by the descriptors rather than some independent operators. We perform experiments on multiple benchmarks including image matching, camera localisation, and 3D reconstruction. The results indicate that our method improves the matching performance of various descriptors and that it generalises across methods and tasks.
Evaluating Salient Object Detection in Natural Images with Multiple Objects having Multi-level Saliency
Mar 19, 2020
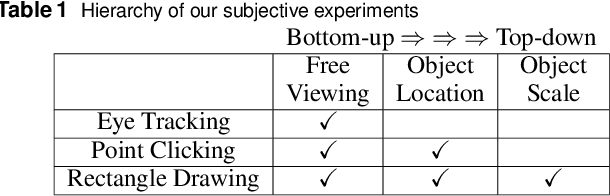

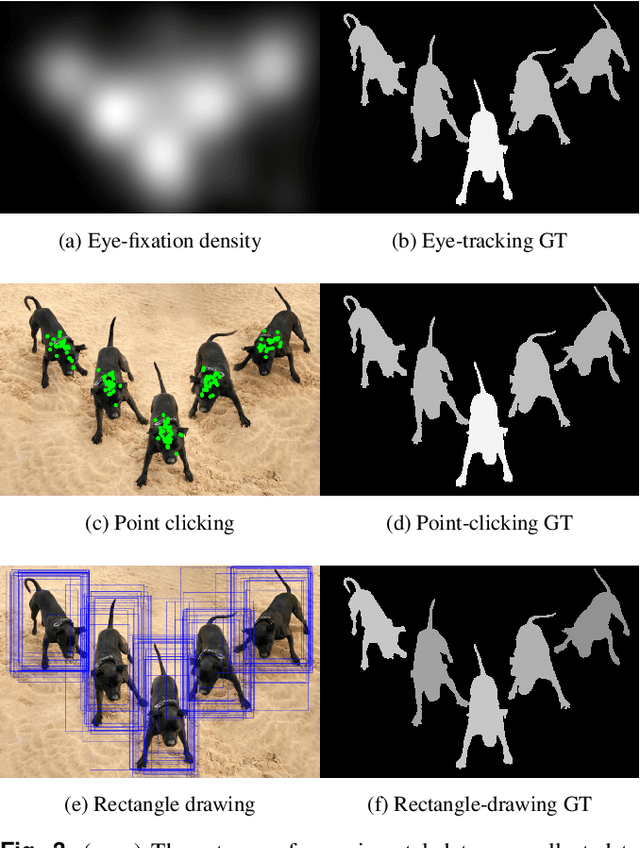
Salient object detection is evaluated using binary ground truth with the labels being salient object class and background. In this paper, we corroborate based on three subjective experiments on a novel image dataset that objects in natural images are inherently perceived to have varying levels of importance. Our dataset, named SalMoN (saliency in multi-object natural images), has 588 images containing multiple objects. The subjective experiments performed record spontaneous attention and perception through eye fixation duration, point clicking and rectangle drawing. As object saliency in a multi-object image is inherently multi-level, we propose that salient object detection must be evaluated for the capability to detect all multi-level salient objects apart from the salient object class detection capability. For this purpose, we generate multi-level maps as ground truth corresponding to all the dataset images using the results of the subjective experiments, with the labels being multi-level salient objects and background. We then propose the use of mean absolute error, Kendall's rank correlation and average area under precision-recall curve to evaluate existing salient object detection methods on our multi-level saliency ground truth dataset. Approaches that represent saliency detection on images as local-global hierarchical processing of a graph perform well in our dataset.
* Accepted Article
It's All About The Scale -- Efficient Text Detection Using Adaptive Scaling
Jul 28, 2019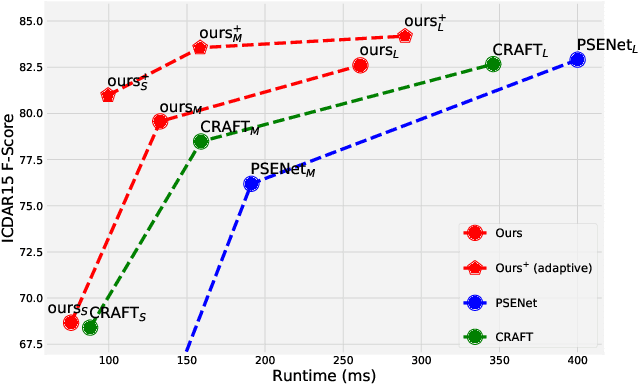
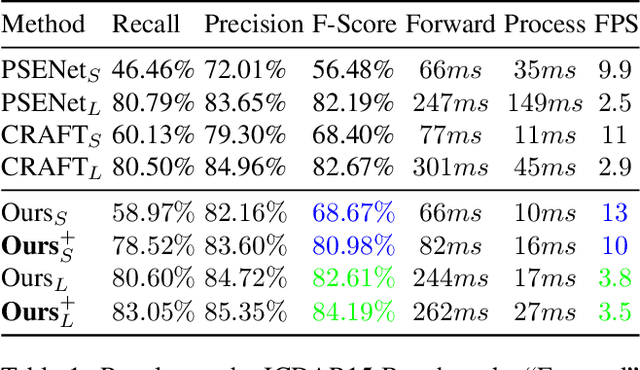

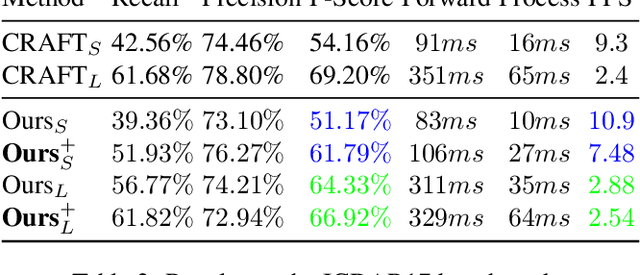
"Text can appear anywhere". This property requires us to carefully process all the pixels in an image in order to accurately localize all text instances. In particular, for the more difficult task of localizing small text regions, many methods use an enlarged image or even several rescaled ones as their input. This significantly increases the processing time of the entire image and needlessly enlarges background regions. If we were to have a prior telling us the coarse location of text instances in the image and their approximate scale, we could have adaptively chosen which regions to process and how to rescale them, thus significantly reducing the processing time. To estimate this prior we propose a segmentation-based network with an additional "scale predictor", an output channel that predicts the scale of each text segment. The network is applied on a scaled down image to efficiently approximate the desired prior, without processing all the pixels of the original image. The approximated prior is then used to create a compact image containing only text regions, resized to a canonical scale, which is fed again to the segmentation network for fine-grained detection. We show that our approach offers a powerful alternative to fixed scaling schemes, achieving an equivalent accuracy to larger input scales while processing far fewer pixels. Qualitative and quantitative results are presented on the ICDAR15 and ICDAR17 MLT benchmarks to validate our approach.