 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LT-Net: Label Transfer by Learning Reversible Voxel-wise Correspondence for One-shot Medical Image Segmentation
Mar 16, 2020
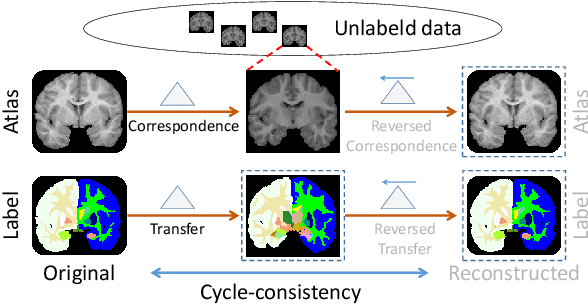
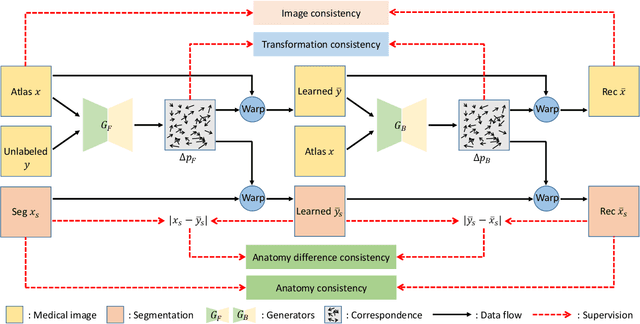
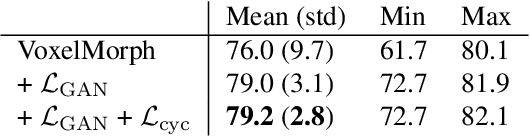
We introduce a one-shot segmentation method to alleviate the burden of manual annotation for medical images. The main idea is to treat one-shot segmentation as a classical atlas-based segmentation problem, where voxel-wise correspondence from the atlas to the unlabelled data is learned. Subsequently, segmentation label of the atlas can be transferred to the unlabelled data with the learned correspondence. However, since ground truth correspondence between images is usually unavailable, the learning system must be well-supervised to avoid mode collapse and convergence failure. To overcome this difficulty, we resort to the forward-backward consistency, which is widely used in correspondence problems, and additionally learn the backward correspondences from the warped atlases back to the original atlas. This cycle-correspondence learning design enables a variety of extra, cycle-consistency-based supervision signals to make the training process stable, while also boost the performance. We demonstrate the superiority of our method over both deep learning-based one-shot segmentation methods and a classical multi-atlas segmentation method via thorough experiments.
Double Backpropagation for Training Autoencoders against Adversarial Attack
Mar 04, 2020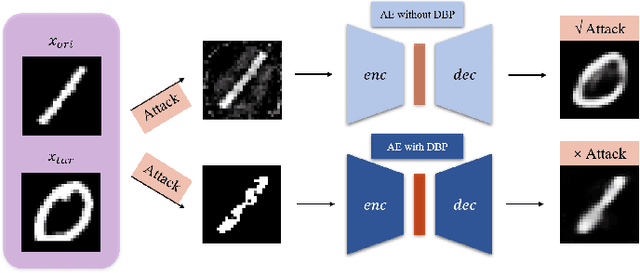

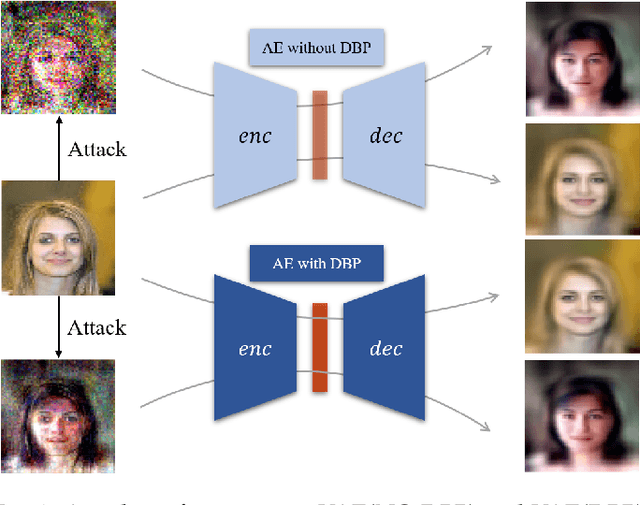

Deep learning, as widely known, is vulnerable to adversarial samples. This paper focuses on the adversarial attack on autoencoders. Safety of the autoencoders (AEs) is important because they are widely used as a compression scheme for data storage and transmission, however, the current autoencoders are easily attacked, i.e., one can slightly modify an input but has totally different codes. The vulnerability is rooted the sensitivity of the autoencoders and to enhance the robustness, we propose to adopt double backpropagation (DBP) to secure autoencoder such as VAE and DRAW. We restrict the gradient from the reconstruction image to the original one so that the autoencoder is not sensitive to trivial perturbation produced by the adversarial attack. After smoothing the gradient by DBP, we further smooth the label by Gaussian Mixture Model (GMM), aiming for accurate and robust classification. We demonstrate in MNIST, CelebA, SVHN that our method leads to a robust autoencoder resistant to attack and a robust classifier able for image transition and immune to adversarial attack if combined with GMM.
MIPGAN -- Generating Robust and High QualityMorph Attacks Using Identity Prior Driven GAN
Sep 03, 2020
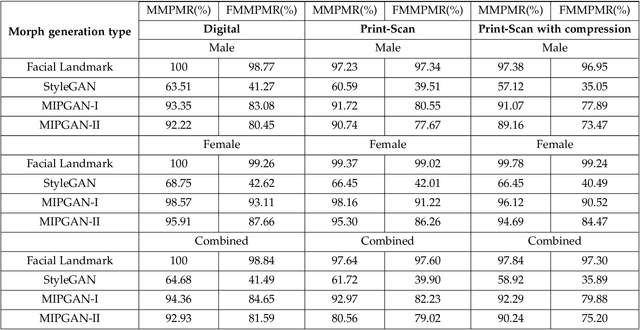
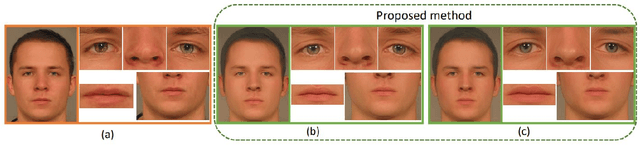
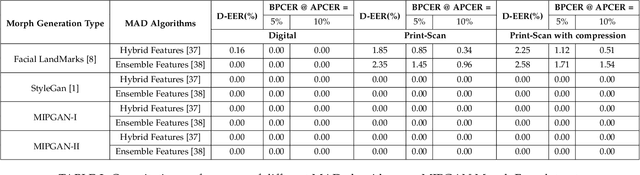
Face morphing attacks target to circumvent Face Recognition Systems (FRS) by employing face images derived from multiple data subjects (e.g., accomplices and malicious actors). Morphed images can verify against contributing data subjects with a reasonable success rate, given they have a high degree of identity resemblance. The success of the morphing attacks is directly dependent on the quality of the generated morph images. We present a new approach for generating robust attacks extending our earlier framework for generating face morphs. We present a new approach using an Identity Prior Driven Generative Adversarial Network, which we refer to as \textit{MIPGAN (Morphing through Identity Prior driven GAN)}. The proposed MIPGAN is derived from the StyleGAN with a newly formulated loss function exploiting perceptual quality and identity factor to generate a high quality morphed face image with minimal artifacts and with higher resolution. We demonstrate the proposed approach's applicability to generate robust morph attacks by evaluating it against a commercial Face Recognition System (FRS) and demonstrate the success rate of attacks. Extensive experiments are carried out to assess the FRS's vulnerability against the proposed morphed face generation technique on three types of data such as digital images, re-digitized (printed and scanned) images, and compressed images after re-digitization from newly generated \textit{MIPGAN Face Morph Dataset}. The obtained results demonstrate that the proposed approach of morph generation profoundly threatens the FRS.
Black-Box Saliency Map Generation Using Bayesian Optimisation
Jan 30, 2020
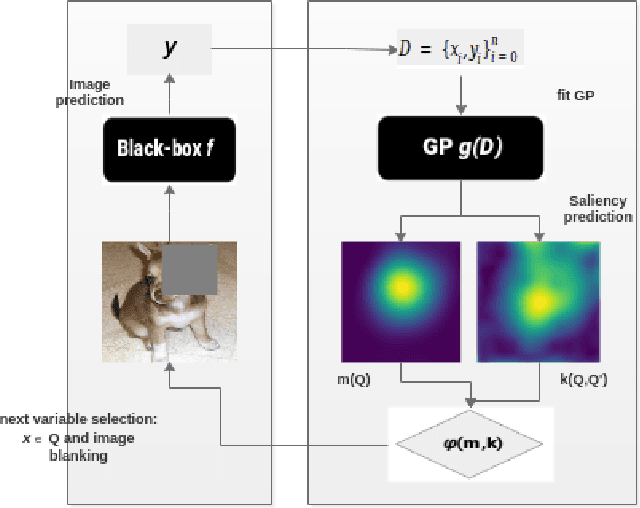
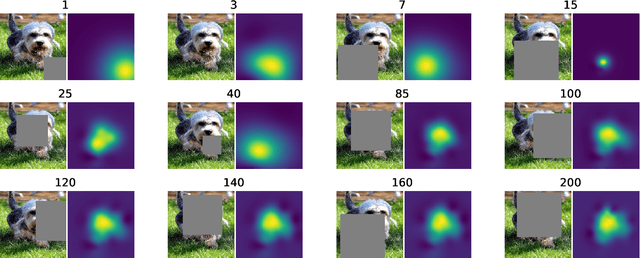
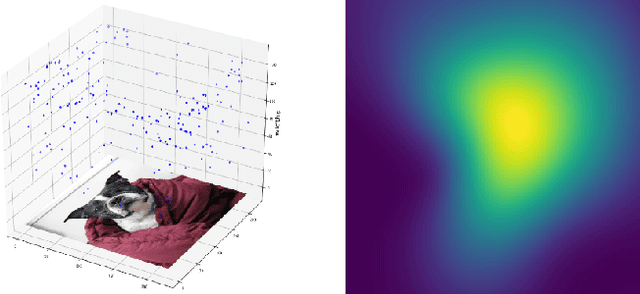
Saliency maps are often used in computer vision to provide intuitive interpretations of what input regions a model has used to produce a specific prediction. A number of approaches to saliency map generation are available, but most require access to model parameters. This work proposes an approach for saliency map generation for black-box models, where no access to model parameters is available, using a Bayesian optimisation sampling method. The approach aims to find the global salient image region responsible for a particular (black-box) model's prediction. This is achieved by a sampling-based approach to model perturbations that seeks to localise salient regions of an image to the black-box model. Results show that the proposed approach to saliency map generation outperforms grid-based perturbation approaches, and performs similarly to gradient-based approaches which require access to model parameters.
They are wearing a mask! Identification of Subjects Wearing a Surgical Mask from their Speech by means of x-vectors and Fisher Vectors
Aug 23, 2020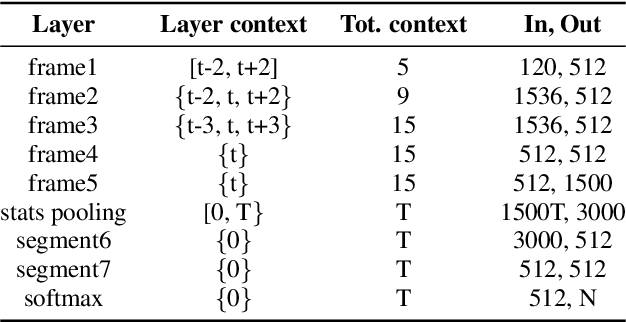
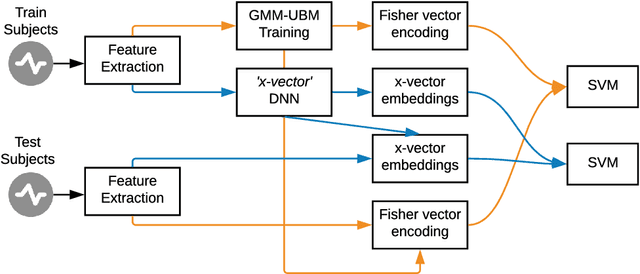
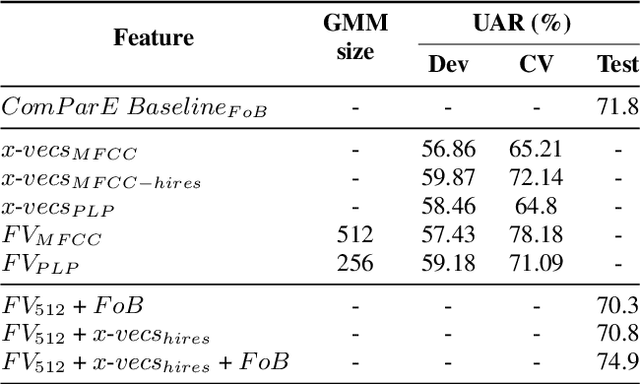
Challenges based on Computational Paralinguistics in the INTERSPEECH Conference have always had a good reception among the attendees owing to its competitive academic and research demands. This year, the INTERSPEECH 2020 Computational Paralinguistics Challenge offers three different problems; here, the Mask Sub-Challenge is of specific interest. This challenge involves the classification of speech recorded from subjects while wearing a surgical mask. In this study, to address the above-mentioned problem we employ two different types of feature extraction methods. The x-vectors embeddings, which is the current state-of-the-art approach for Speaker Recognition; and the Fisher Vector (FV), that is a method originally intended for Image Recognition, but here we utilize it to discriminate utterances. These approaches employ distinct frame-level representations: MFCC and PLP. Using Support Vector Machines (SVM) as the classifier, we perform a technical comparison between the performances of the FV encodings and the x-vector embeddings for this particular classification task. We find that the Fisher vector encodings provide better representations of the utterances than the x-vectors do for this specific dataset. Moreover, we show that a fusion of our best configurations outperforms all the baseline scores of the Mask Sub-Challenge.
Principal Component Properties of Adversarial Samples
Dec 07, 2019
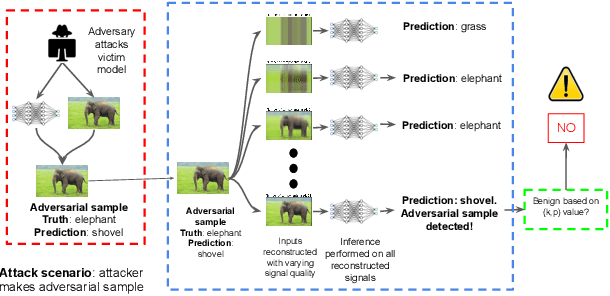
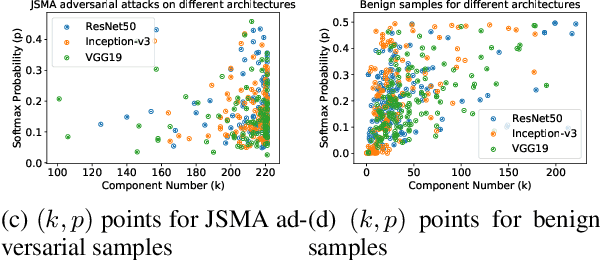
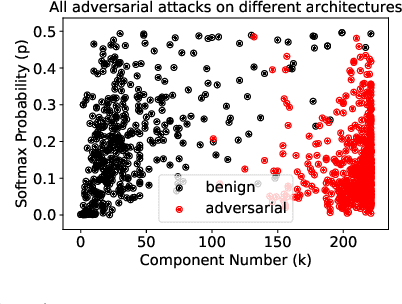
Deep Neural Networks for image classification have been found to be vulnerable to adversarial samples, which consist of sub-perceptual noise added to a benign image that can easily fool trained neural networks, posing a significant risk to their commercial deployment. In this work, we analyze adversarial samples through the lens of their contributions to the principal components of each image, which is different than prior works in which authors performed PCA on the entire dataset. We investigate a number of state-of-the-art deep neural networks trained on ImageNet as well as several attacks for each of the networks. Our results demonstrate empirically that adversarial samples across several attacks have similar properties in their contributions to the principal components of neural network inputs. We propose a new metric for neural networks to measure their robustness to adversarial samples, termed the (k,p) point. We utilize this metric to achieve 93.36% accuracy in detecting adversarial samples independent of architecture and attack type for models trained on ImageNet.
Type I Attack for Generative Models
Mar 04, 2020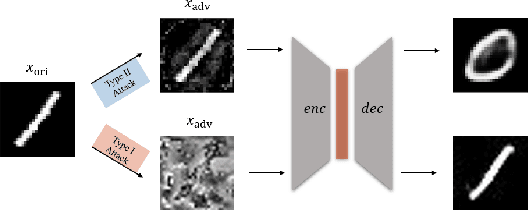
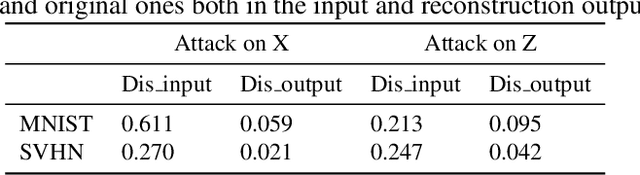

Generative models are popular tools with a wide range of applications. Nevertheless, it is as vulnerable to adversarial samples as classifiers. The existing attack methods mainly focus on generating adversarial examples by adding imperceptible perturbations to input, which leads to wrong result. However, we focus on another aspect of attack, i.e., cheating models by significant changes. The former induces Type II error and the latter causes Type I error. In this paper, we propose Type I attack to generative models such as VAE and GAN. One example given in VAE is that we can change an original image significantly to a meaningless one but their reconstruction results are similar. To implement the Type I attack, we destroy the original one by increasing the distance in input space while keeping the output similar because different inputs may correspond to similar features for the property of deep neural network. Experimental results show that our attack method is effective to generate Type I adversarial examples for generative models on large-scale image datasets.
A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
Aug 23, 2020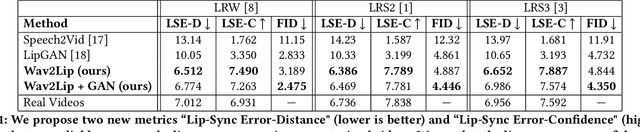
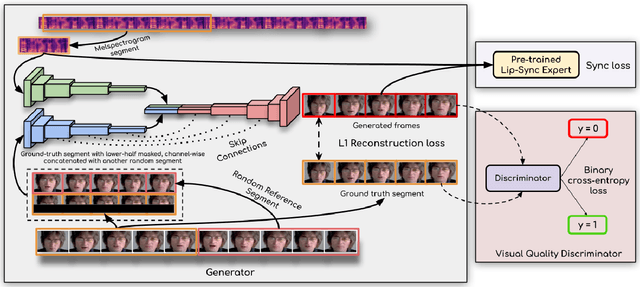
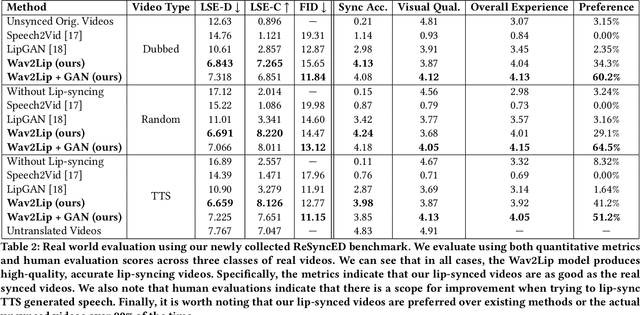
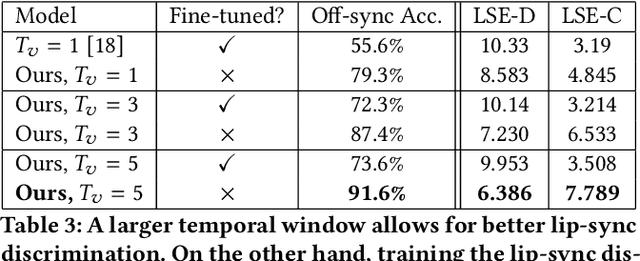
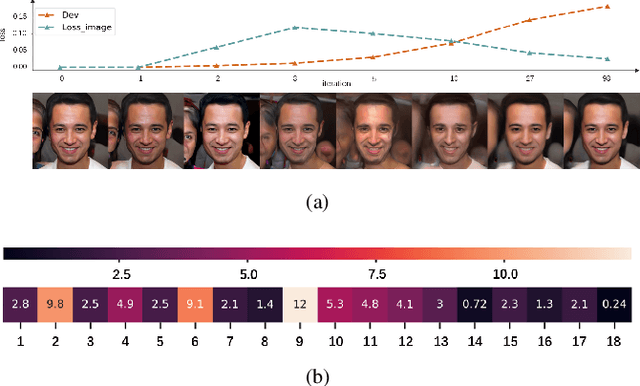
In this work, we investigate the problem of lip-syncing a talking face video of an arbitrary identity to match a target speech segment. Current works excel at producing accurate lip movements on a static image or videos of specific people seen during the training phase. However, they fail to accurately morph the lip movements of arbitrary identities in dynamic, unconstrained talking face videos, resulting in significant parts of the video being out-of-sync with the new audio. We identify key reasons pertaining to this and hence resolve them by learning from a powerful lip-sync discriminator. Next, we propose new, rigorous evaluation benchmarks and metrics to accurately measure lip synchronization in unconstrained videos. Extensive quantitative evaluations on our challenging benchmarks show that the lip-sync accuracy of the videos generated by our Wav2Lip model is almost as good as real synced videos. We provide a demo video clearly showing the substantial impact of our Wav2Lip model and evaluation benchmarks on our website: \url{cvit.iiit.ac.in/research/projects/cvit-projects/a-lip-sync-expert-is-all-you-need-for-speech-to-lip-generation-in-the-wild}. The code and models are released at this GitHub repository: \url{github.com/Rudrabha/Wav2Lip}. You can also try out the interactive demo at this link: \url{bhaasha.iiit.ac.in/lipsync}.
An Empirical Analysis of Backward Compatibility in Machine Learning Systems
Aug 11, 2020

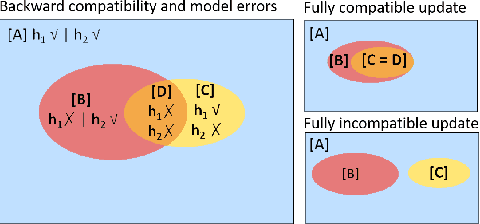

In many applications of machine learning (ML), updates are performed with the goal of enhancing model performance. However, current practices for updating models rely solely on isolated, aggregate performance analyses, overlooking important dependencies, expectations, and needs in real-world deployments. We consider how updates, intended to improve ML models, can introduce new errors that can significantly affect downstream systems and users. For example, updates in models used in cloud-based classification services, such as image recognition, can cause unexpected erroneous behavior in systems that make calls to the services. Prior work has shown the importance of "backward compatibility" for maintaining human trust. We study challenges with backward compatibility across different ML architectures and datasets, focusing on common settings including data shifts with structured noise and ML employed in inferential pipelines. Our results show that (i) compatibility issues arise even without data shift due to optimization stochasticity, (ii) training on large-scale noisy datasets often results in significant decreases in backward compatibility even when model accuracy increases, and (iii) distributions of incompatible points align with noise bias, motivating the need for compatibility aware de-noising and robustness methods.
Self-Supervised Monocular Depth Estimation: Solving the Dynamic Object Problem by Semantic Guidance
Jul 14, 2020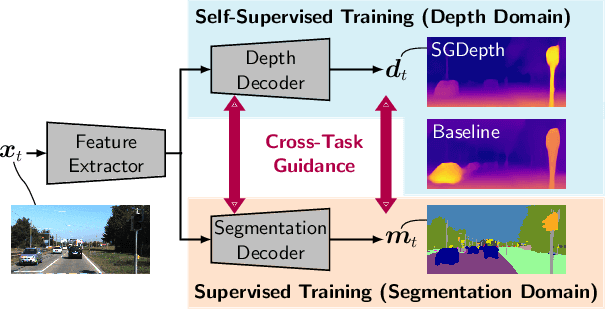
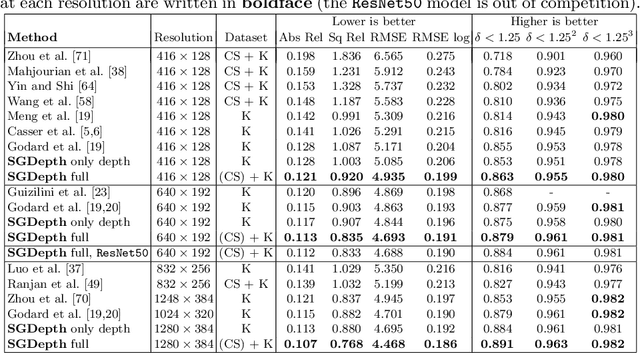
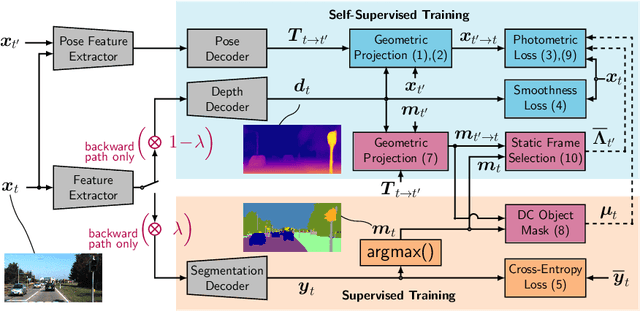
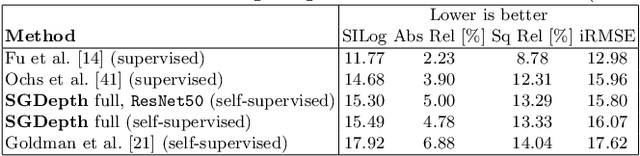
Self-supervised monocular depth estimation presents a powerful method to obtain 3D scene information from single camera images, which is trainable on arbitrary image sequences without requiring depth labels, e.g., from a LiDAR sensor. In this work we present a new self-supervised semantically-guided depth estimation (SGDepth) method to deal with moving dynamic-class (DC) objects, such as moving cars and pedestrians, which violate the static-world assumptions typically made during training of such models. Specifically, we propose (i) mutually beneficial cross-domain training of (supervised) semantic segmentation and self-supervised depth estimation with task-specific network heads, (ii) a semantic masking scheme providing guidance to prevent moving DC objects from contaminating the photometric loss, and (iii) a detection method for frames with non-moving DC objects, from which the depth of DC objects can be learned. We demonstrate the performance of our method on several benchmarks, in particular on the Eigen split, where we exceed all baselines without test-time refinement in all measures.