 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
IDOL: A Framework for IMU-DVS Odometry using Lines
Aug 13, 2020
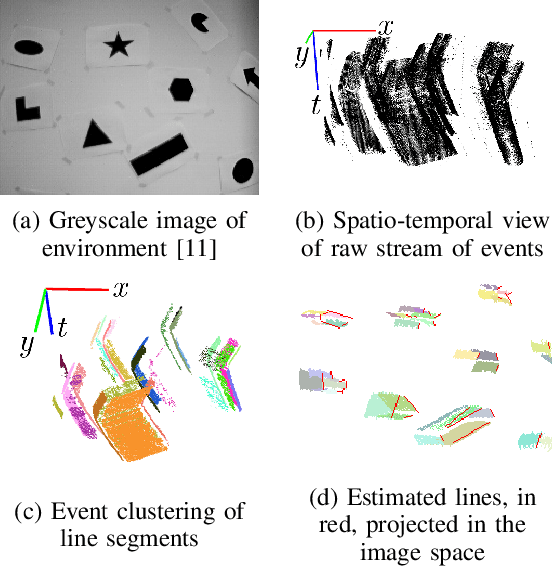
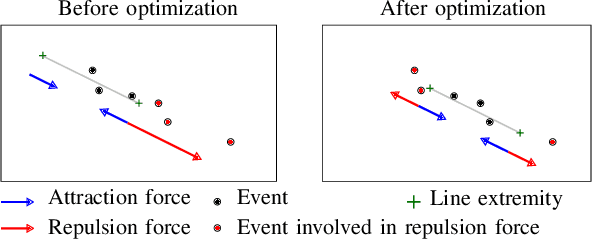

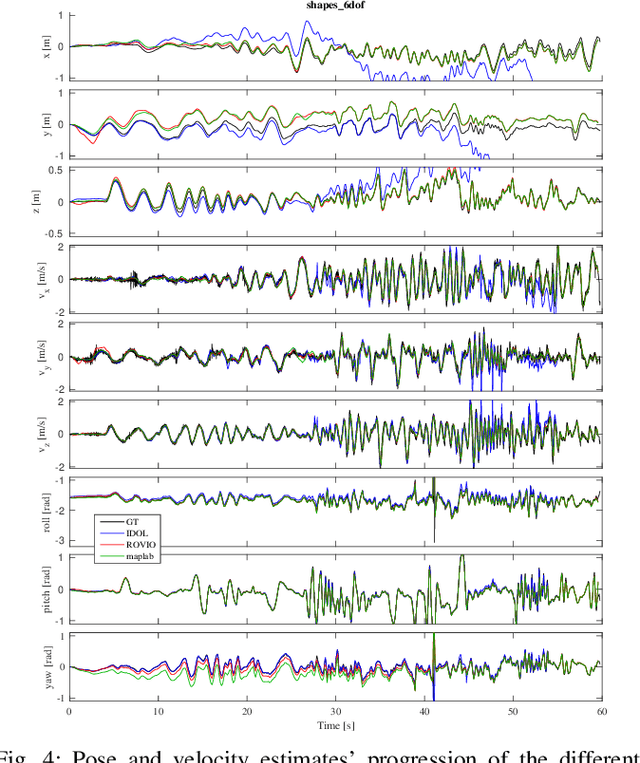
In this paper, we introduce IDOL, an optimization-based framework for IMU-DVS Odometry using Lines. Event cameras, also called Dynamic Vision Sensors (DVSs), generate highly asynchronous streams of events triggered upon illumination changes for each individual pixel. This novel paradigm presents advantages in low illumination conditions and high-speed motions. Nonetheless, this unconventional sensing modality brings new challenges to perform scene reconstruction or motion estimation. The proposed method offers to leverage a continuous-time representation of the inertial readings to associate each event with timely accurate inertial data. The method's front-end extracts event clusters that belong to line segments in the environment whereas the back-end estimates the system's trajectory alongside the lines' 3D position by minimizing point-to-line distances between individual events and the lines' projection in the image space. A novel attraction/repulsion mechanism is presented to accurately estimate the lines' extremities, avoiding their explicit detection in the event data. The proposed method is benchmarked against a state-of-the-art frame-based visual-inertial odometry framework using public datasets. The results show that IDOL performs at the same order of magnitude on most datasets and even shows better orientation estimates. These findings can have a great impact on new algorithms for DVS.
Image Set based Collaborative Representation for Face Recognition
Aug 30, 2013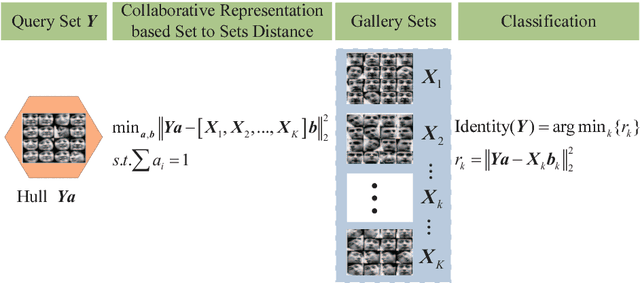

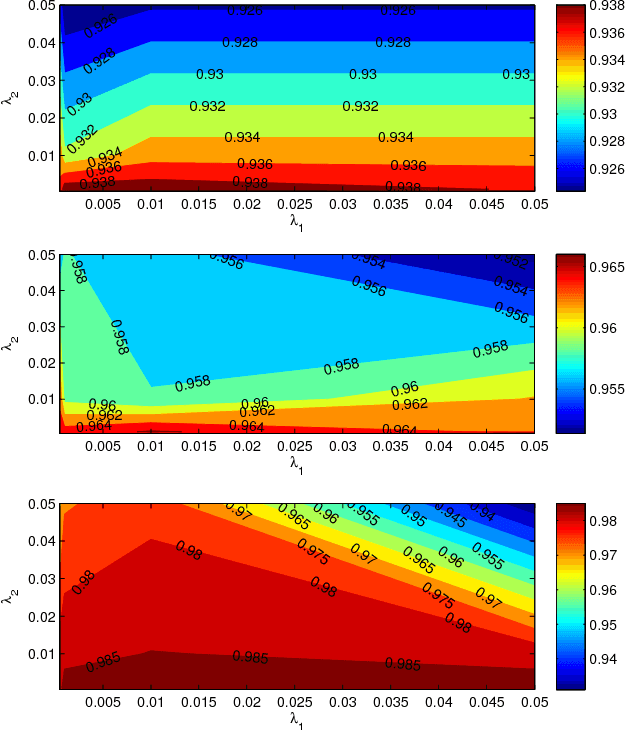
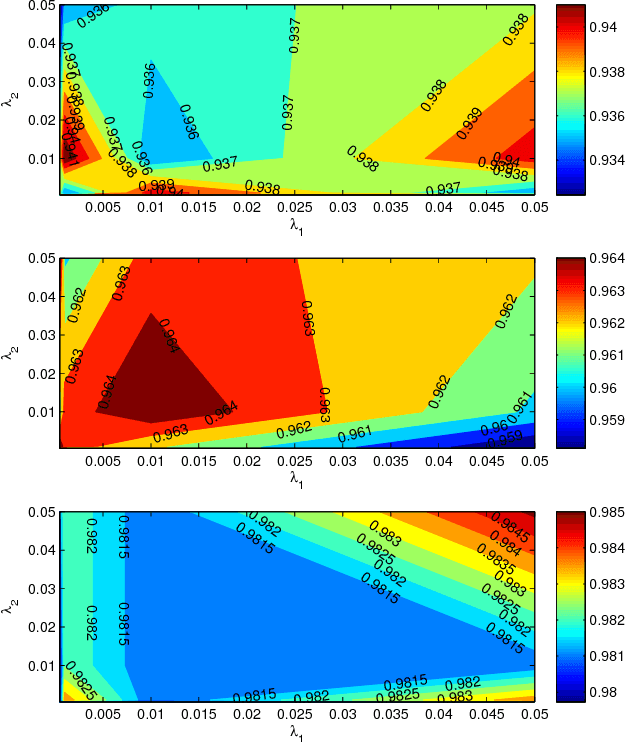
With the rapid development of digital imaging and communication technologies, image set based face recognition (ISFR) is becoming increasingly important. One key issue of ISFR is how to effectively and efficiently represent the query face image set by using the gallery face image sets. The set-to-set distance based methods ignore the relationship between gallery sets, while representing the query set images individually over the gallery sets ignores the correlation between query set images. In this paper, we propose a novel image set based collaborative representation and classification method for ISFR. By modeling the query set as a convex or regularized hull, we represent this hull collaboratively over all the gallery sets. With the resolved representation coefficients, the distance between the query set and each gallery set can then be calculated for classification. The proposed model naturally and effectively extends the image based collaborative representation to an image set based one, and our extensive experiments on benchmark ISFR databases show the superiority of the proposed method to state-of-the-art ISFR methods under different set sizes in terms of both recognition rate and efficiency.
Where Does Trust Break Down? A Quantitative Trust Analysis of Deep Neural Networks via Trust Matrix and Conditional Trust Densities
Sep 30, 2020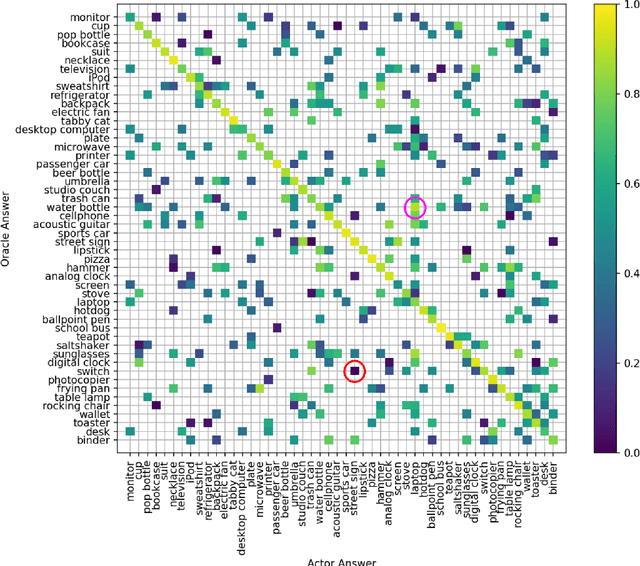
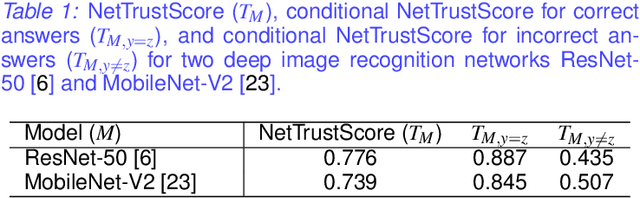
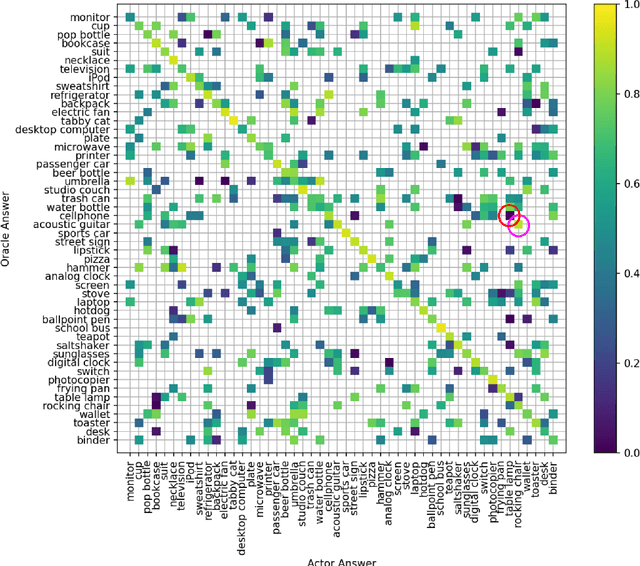
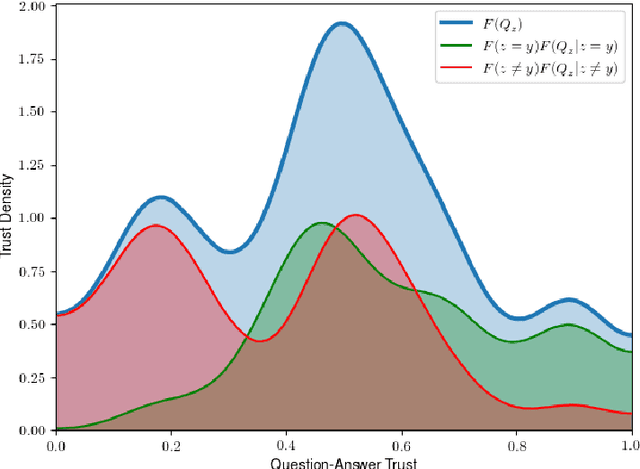
The advances and successes in deep learning in recent years have led to considerable efforts and investments into its widespread ubiquitous adoption for a wide variety of applications, ranging from personal assistants and intelligent navigation to search and product recommendation in e-commerce. With this tremendous rise in deep learning adoption comes questions about the trustworthiness of the deep neural networks that power these applications. Motivated to answer such questions, there has been a very recent interest in trust quantification. In this work, we introduce the concept of trust matrix, a novel trust quantification strategy that leverages the recently introduced question-answer trust metric by Wong et al. to provide deeper, more detailed insights into where trust breaks down for a given deep neural network given a set of questions. More specifically, a trust matrix defines the expected question-answer trust for a given actor-oracle answer scenario, allowing one to quickly spot areas of low trust that needs to be addressed to improve the trustworthiness of a deep neural network. The proposed trust matrix is simple to calculate, humanly interpretable, and to the best of the authors' knowledge is the first to study trust at the actor-oracle answer level. We further extend the concept of trust densities with the notion of conditional trust densities. We experimentally leverage trust matrices to study several well-known deep neural network architectures for image recognition, and further study the trust density and conditional trust densities for an interesting actor-oracle answer scenario. The results illustrate that trust matrices, along with conditional trust densities, can be useful tools in addition to the existing suite of trust quantification metrics for guiding practitioners and regulators in creating and certifying deep learning solutions for trusted operation.
Self-Supervised Siamese Learning on Stereo Image Pairs for Depth Estimation in Robotic Surgery
May 17, 2017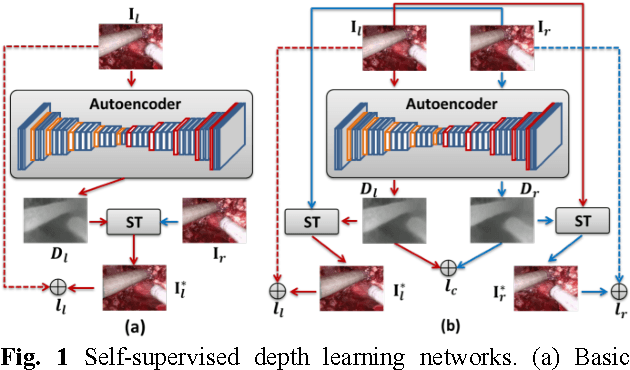
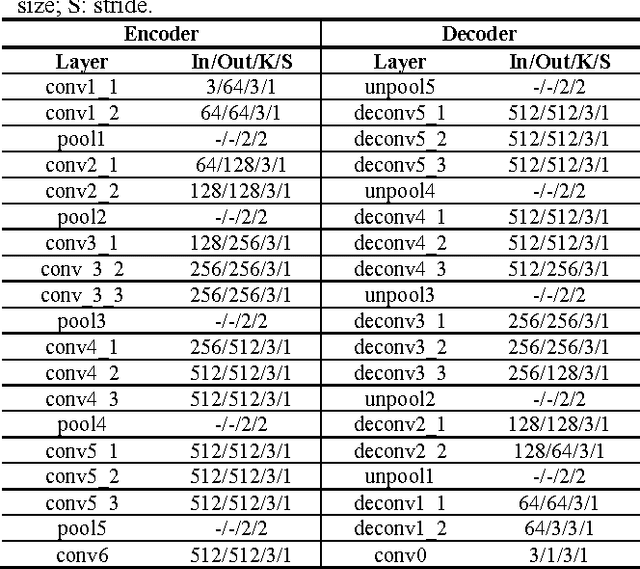
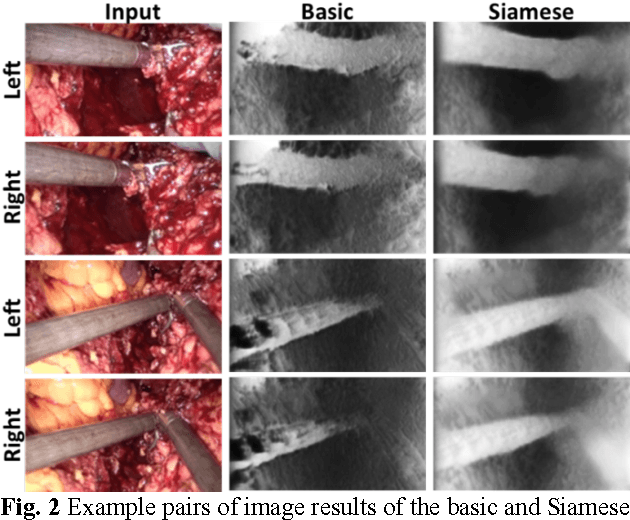

Robotic surgery has become a powerful tool for performing minimally invasive procedures, providing advantages in dexterity, precision, and 3D vision, over traditional surgery. One popular robotic system is the da Vinci surgical platform, which allows preoperative information to be incorporated into live procedures using Augmented Reality (AR). Scene depth estimation is a prerequisite for AR, as accurate registration requires 3D correspondences between preoperative and intraoperative organ models. In the past decade, there has been much progress on depth estimation for surgical scenes, such as using monocular or binocular laparoscopes [1,2]. More recently, advances in deep learning have enabled depth estimation via Convolutional Neural Networks (CNNs) [3], but training requires a large image dataset with ground truth depths. Inspired by [4], we propose a deep learning framework for surgical scene depth estimation using self-supervision for scalable data acquisition. Our framework consists of an autoencoder for depth prediction, and a differentiable spatial transformer for training the autoencoder on stereo image pairs without ground truth depths. Validation was conducted on stereo videos collected in robotic partial nephrectomy.
A Comprehensive Overview and Survey of Recent Advances in Meta-Learning
Apr 29, 2020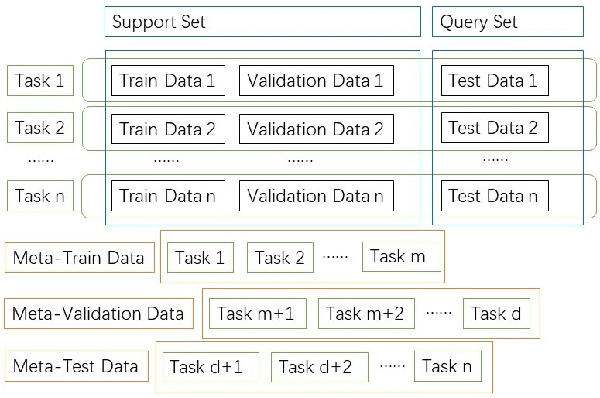

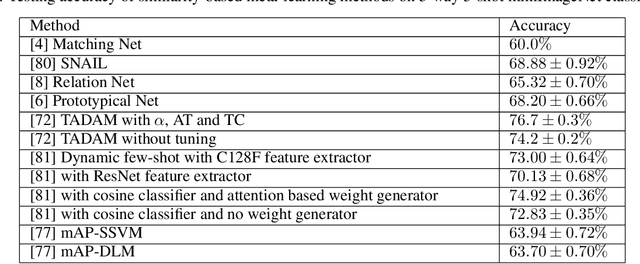
This article reviews meta-learning which seeks rapid and accurate model adaptation to unseen tasks with applications in image classification, natural language processing and robotics. Unlike deep learning, meta-learning uses few-shot datasets and concerns further improving model generalization to obtain higher prediction accuracy. We summarize meta-learning models in three categories: black-box adaptation, similarity based method and meta-learner procedure. Recent applications concentrate upon combination of meta-learning with Bayesian deep learning and reinforcement learning to provide feasible integrated problem solutions. We present performance comparison of recent meta-learning methods and discuss future research direction.
Gradient Centralization: A New Optimization Technique for Deep Neural Networks
Apr 03, 2020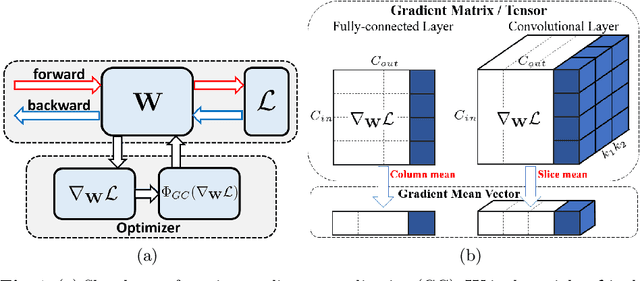
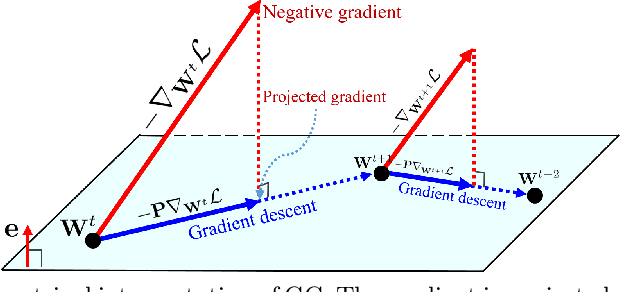

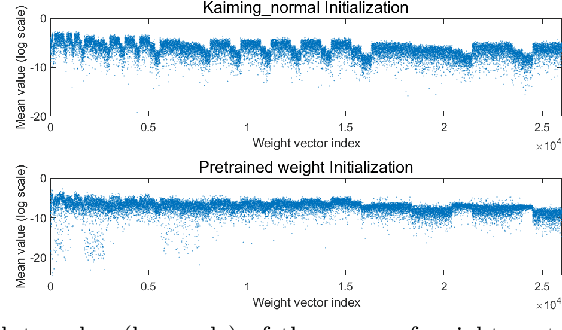
Optimization techniques are of great importance to effectively and efficiently train a deep neural network (DNN). It has been shown that using the first and second order statistics (e.g., mean and variance) to perform Z-score standardization on network activations or weight vectors, such as batch normalization (BN) and weight standardization (WS), can improve the training performance. Different from these existing methods that mostly operate on activations or weights, we present a new optimization technique, namely gradient centralization (GC), which operates directly on gradients by centralizing the gradient vectors to have zero mean. GC can be viewed as a projected gradient descent method with a constrained loss function. We show that GC can regularize both the weight space and output feature space so that it can boost the generalization performance of DNNs. Moreover, GC improves the Lipschitzness of the loss function and its gradient so that the training process becomes more efficient and stable. GC is very simple to implement and can be easily embedded into existing gradient based DNN optimizers with only one line of code. It can also be directly used to fine-tune the pre-trained DNNs. Our experiments on various applications, including general image classification, fine-grained image classification, detection and segmentation, demonstrate that GC can consistently improve the performance of DNN learning. The code of GC can be found at https://github.com/Yonghongwei/Gradient-Centralization.
CacheNet: A Model Caching Framework for Deep Learning Inference on the Edge
Jul 03, 2020
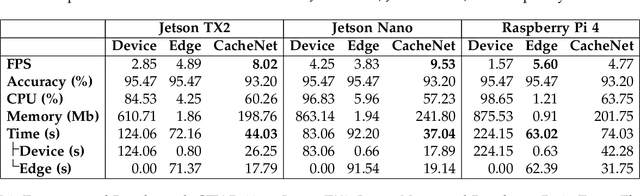
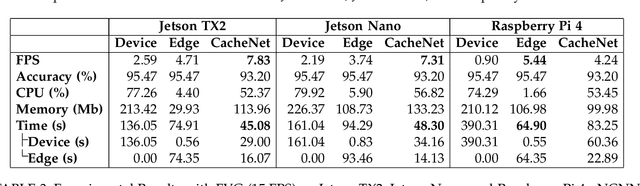
The success of deep neural networks (DNN) in machine perception applications such as image classification and speech recognition comes at the cost of high computation and storage complexity. Inference of uncompressed large scale DNN models can only run in the cloud with extra communication latency back and forth between cloud and end devices, while compressed DNN models achieve real-time inference on end devices at the price of lower predictive accuracy. In order to have the best of both worlds (latency and accuracy), we propose CacheNet, a model caching framework. CacheNet caches low-complexity models on end devices and high-complexity (or full) models on edge or cloud servers. By exploiting temporal locality in streaming data, high cache hit and consequently shorter latency can be achieved with no or only marginal decrease in prediction accuracy. Experiments on CIFAR-10 and FVG have shown CacheNet is 58-217% faster than baseline approaches that run inference tasks on end devices or edge servers alone.
Bayesian ensemble learning for image denoising
Aug 06, 2013


Natural images are often affected by random noise and image denoising has long been a central topic in Computer Vision. Many algorithms have been introduced to remove the noise from the natural images, such as Gaussian, Wiener filtering and wavelet thresholding. However, many of these algorithms remove the fine edges and make them blur. Recently, many promising denoising algorithms have been introduced such as Non-local Means, Fields of Experts, and BM3D. In this paper, we explore Bayesian method of ensemble learning for image denoising. Ensemble methods seek to combine multiple different algorithms to retain the strengths of all methods and the weaknesses of none. Bayesian ensemble models are Non-local Means and Fields of Experts, the very successful recent algorithms. The Non-local Means presumes that the image contains an extensive amount of self-similarity. The approach of the Fields of Experts model extends traditional Markov Random Field model by learning potential functions over extended pixel neighborhoods. The two models are implemented and image denoising is performed on natural images. The experimental results obtained are used to compare with the single algorithm and discuss the ensemble learning and their approaches. Comparing to the results of Non-local Means and Fields of Experts, Ensemble learning showed improvement nearly 1dB.
Explainable Disease Classification via weakly-supervised segmentation
Aug 24, 2020
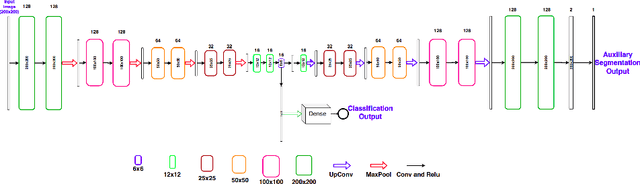
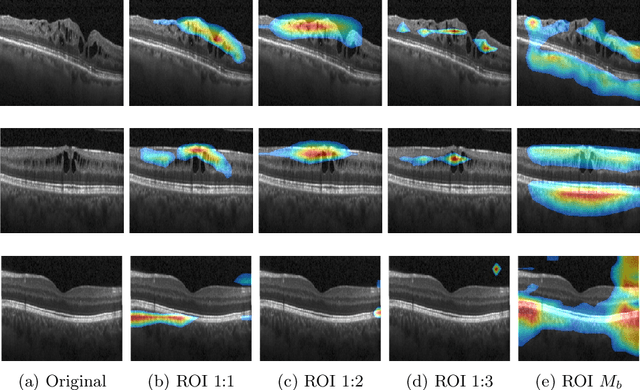
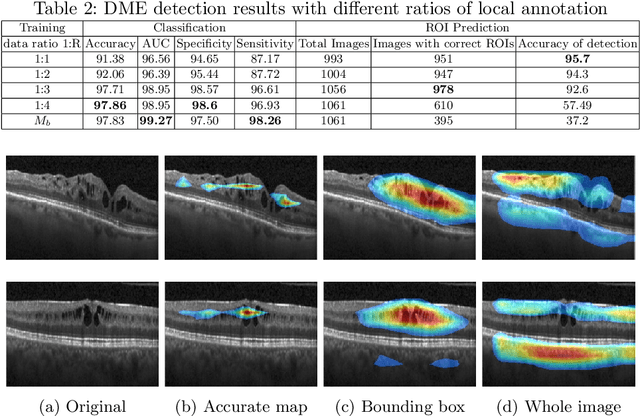
Deep learning based approaches to Computer Aided Diagnosis (CAD) typically pose the problem as an image classification (Normal or Abnormal) problem. These systems achieve high to very high accuracy in specific disease detection for which they are trained but lack in terms of an explanation for the provided decision/classification result. The activation maps which correspond to decisions do not correlate well with regions of interest for specific diseases. This paper examines this problem and proposes an approach which mimics the clinical practice of looking for an evidence prior to diagnosis. A CAD model is learnt using a mixed set of information: class labels for the entire training set of images plus a rough localisation of suspect regions as an extra input for a smaller subset of training images for guiding the learning. The proposed approach is illustrated with detection of diabetic macular edema (DME) from OCT slices. Results of testing on on a large public dataset show that with just a third of images with roughly segmented fluid filled regions, the classification accuracy is on par with state of the art methods while providing a good explanation in the form of anatomically accurate heatmap /region of interest. The proposed solution is then adapted to Breast Cancer detection from mammographic images. Good evaluation results on public datasets underscores the generalisability of the proposed solution.
BASN -- Learning Steganography with Binary Attention Mechanism
Jul 09, 2019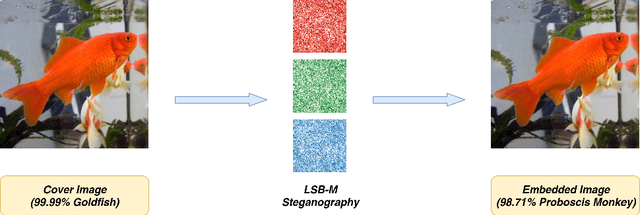
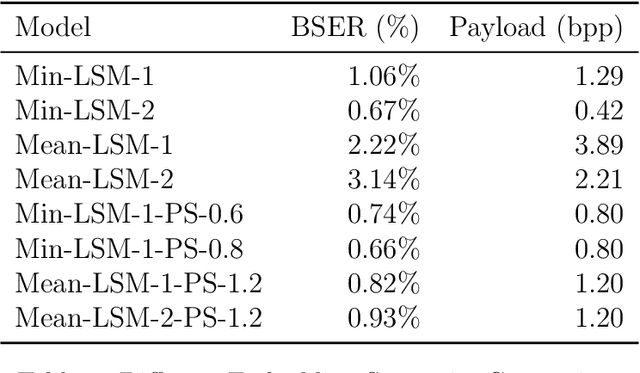
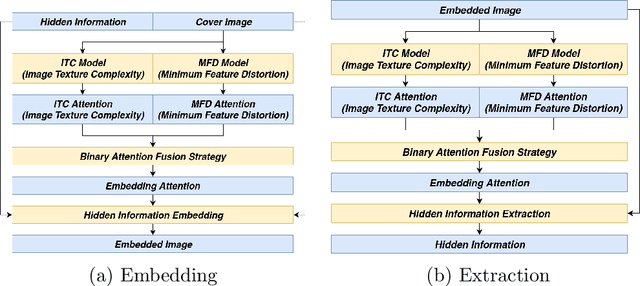

Secret information sharing through image carrier has aroused much research attention in recent years with images' growing domination on the Internet and mobile applications. However, with the booming trend of convolutional neural networks, image steganography is facing a more significant challenge from neural-network-automated tasks. To improve the security of image steganography and minimize task result distortion, models must maintain the feature maps generated by task-specific networks being irrelative to any hidden information embedded in the carrier. This paper introduces a binary attention mechanism into image steganography to help alleviate the security issue, and in the meanwhile, increase embedding payload capacity. The experimental results show that our method has the advantage of high payload capacity with little feature map distortion and still resist detection by state-of-the-art image steganalysis algorithms.