 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A DNN Framework For Text Image Rectification From Planar Transformations
Nov 14, 2016

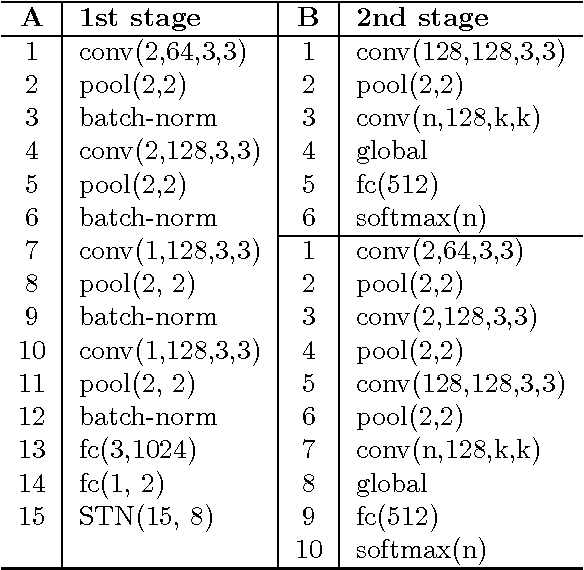
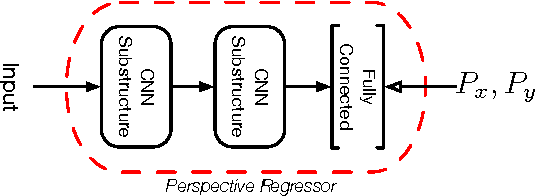
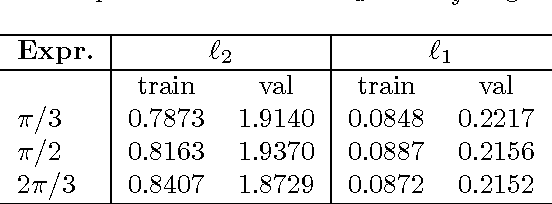
In this paper, a novel neural network architecture is proposed attempting to rectify text images with mild assumptions. A new dataset of text images is collected to verify our model and open to public. We explored the capability of deep neural network in learning geometric transformation and found the model could segment the text image without explicit supervised segmentation information. Experiments show the architecture proposed can restore planar transformations with wonderful robustness and effectiveness.
MLOD: A multi-view 3D object detection based on robust feature fusion method
Sep 09, 2019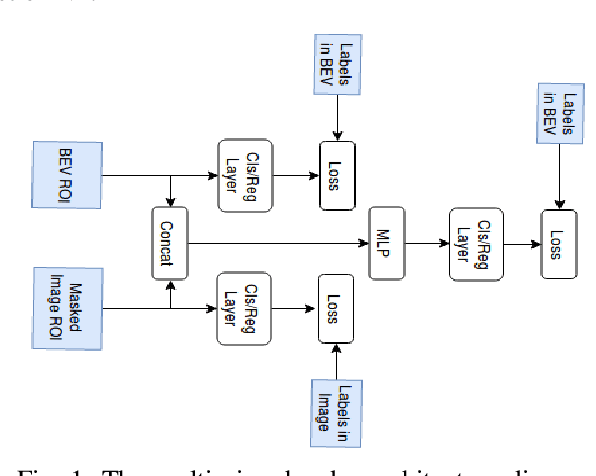
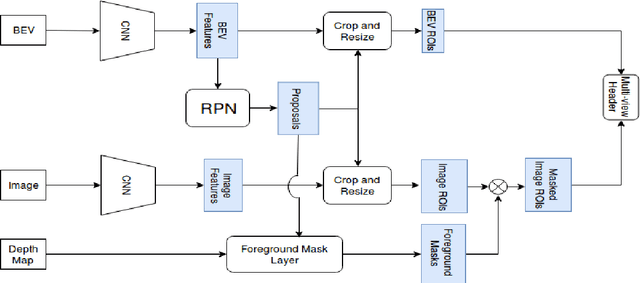
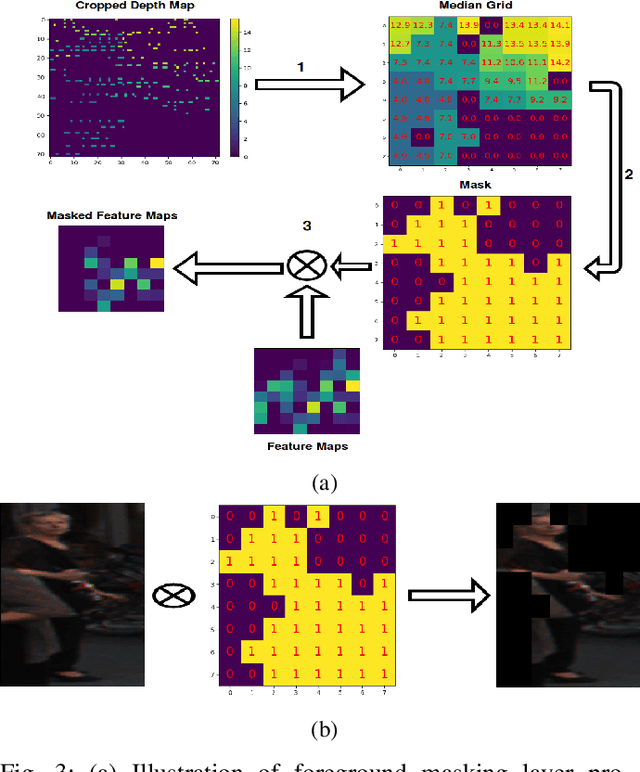
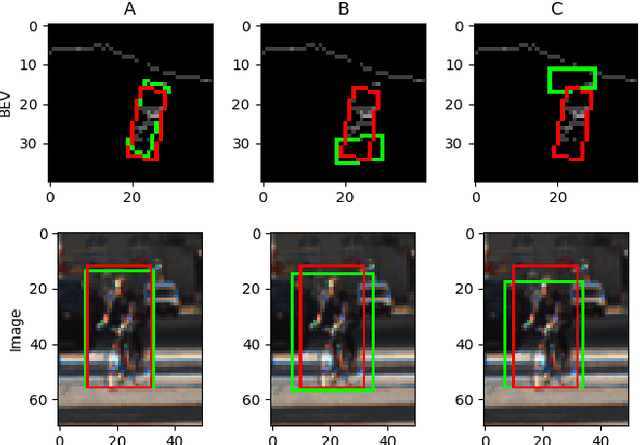
This paper presents Multi-view Labelling Object Detector (MLOD). The detector takes an RGB image and a LIDAR point cloud as input and follows the two-stage object detection framework. A Region Proposal Network (RPN) generates 3D proposals in a Bird's Eye View (BEV) projection of the point cloud. The second stage projects the 3D proposal bounding boxes to the image and BEV feature maps and sends the corresponding map crops to a detection header for classification and bounding-box regression. Unlike other multi-view based methods, the cropped image features are not directly fed to the detection header, but masked by the depth information to filter out parts outside 3D bounding boxes. The fusion of image and BEV features is challenging, as they are derived from different perspectives. We introduce a novel detection header, which provides detection results not just from fusion layer, but also from each sensor channel. Hence the object detector can be trained on data labelled in different views to avoid the degeneration of feature extractors. MLOD achieves state-of-the-art performance on the KITTI 3D object detection benchmark. Most importantly, the evaluation shows that the new header architecture is effective in preventing image feature extractor degeneration.
IAUnet: Global Context-Aware Feature Learning for Person Re-Identification
Sep 02, 2020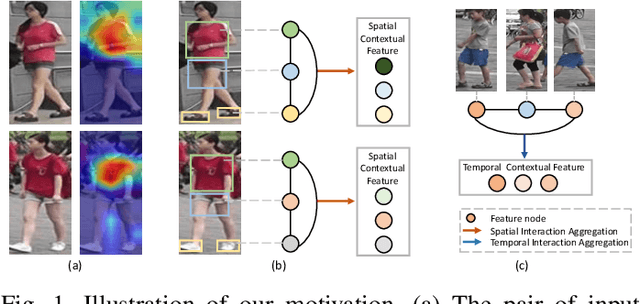
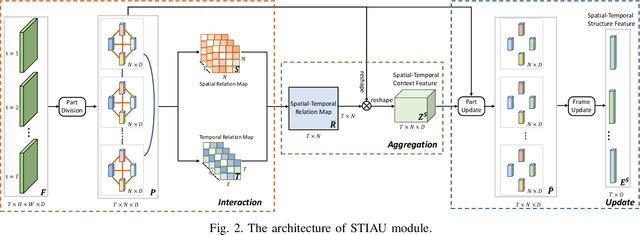
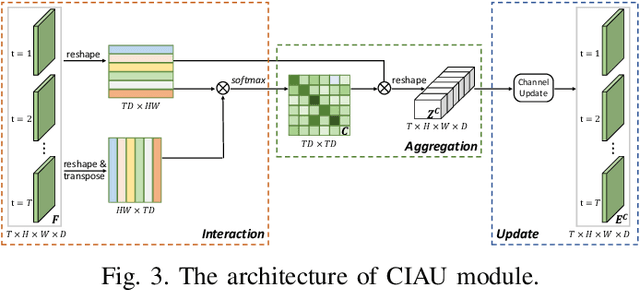

Person re-identification (reID) by CNNs based networks has achieved favorable performance in recent years. However, most of existing CNNs based methods do not take full advantage of spatial-temporal context modeling. In fact, the global spatial-temporal context can greatly clarify local distractions to enhance the target feature representation. To comprehensively leverage the spatial-temporal context information, in this work, we present a novel block, Interaction-Aggregation-Update (IAU), for high-performance person reID. Firstly, Spatial-Temporal IAU (STIAU) module is introduced. STIAU jointly incorporates two types of contextual interactions into a CNN framework for target feature learning. Here the spatial interactions learn to compute the contextual dependencies between different body parts of a single frame. While the temporal interactions are used to capture the contextual dependencies between the same body parts across all frames. Furthermore, a Channel IAU (CIAU) module is designed to model the semantic contextual interactions between channel features to enhance the feature representation, especially for small-scale visual cues and body parts. Therefore, the IAU block enables the feature to incorporate the globally spatial, temporal, and channel context. It is lightweight, end-to-end trainable, and can be easily plugged into existing CNNs to form IAUnet. The experiments show that IAUnet performs favorably against state-of-the-art on both image and video reID tasks and achieves compelling results on a general object categorization task. The source code is available at https://github.com/blue-blue272/ImgReID-IAnet.
Fast Glare Detection in Document Images
Oct 24, 2019
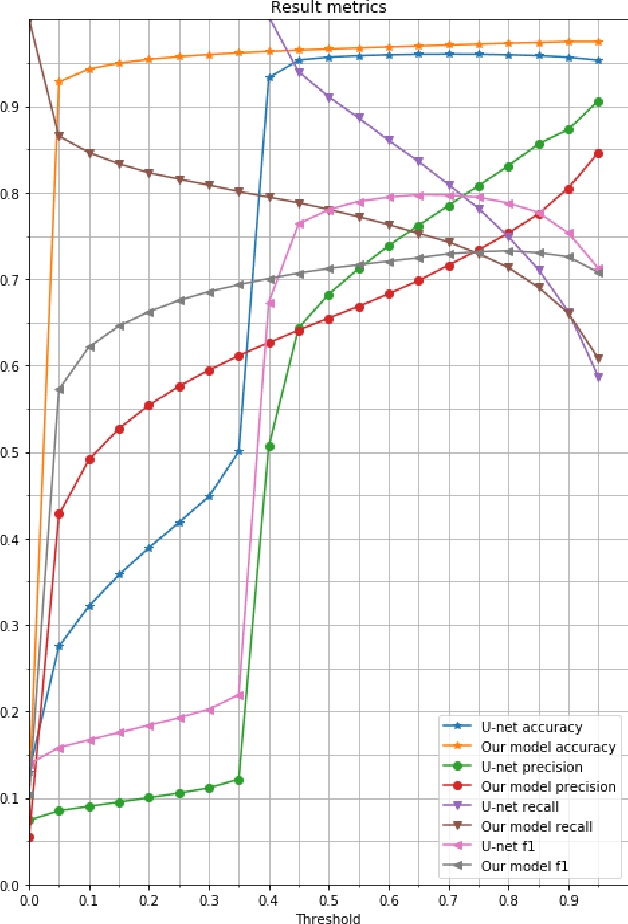
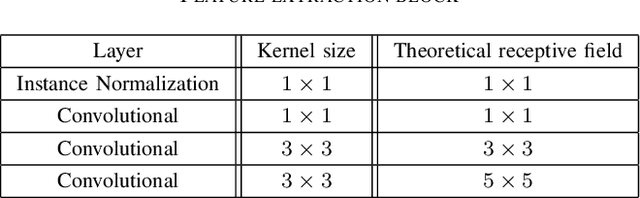
Glare is a phenomenon that occurs when the scene has a reflection of a light source or has one in it. This luminescence can hide useful information from the image, making text recognition virtually impossible. In this paper, we propose an approach to detect glare in images taken by users via mobile devices. Our method divides the document into blocks and collects luminance features from the original image and black-white strokes histograms of the binarized image. Finally, glare is detected using a convolutional neural network on the aforementioned histograms and luminance features. The network consists of several feature extraction blocks, one for each type of input, and the detection block, which calculates the resulting glare heatmap based on the output of the extraction part. The proposed solution detects glare with high recall and f-score.
Semantics-Driven Unsupervised Learning for Monocular Depth and Ego-Motion Estimation
Jun 08, 2020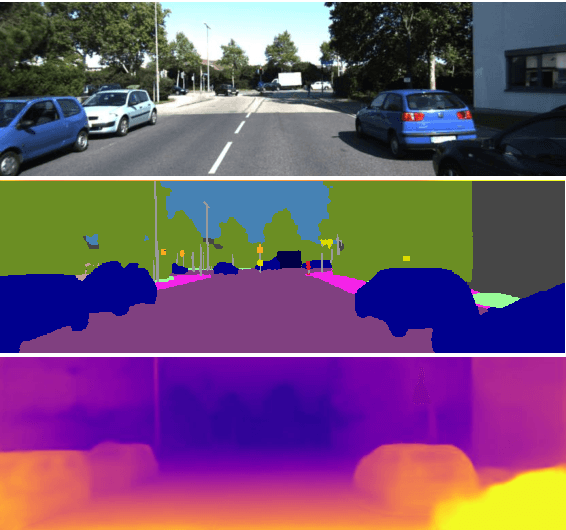
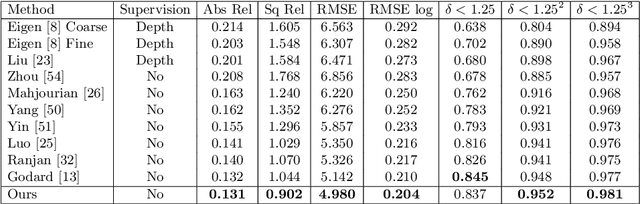
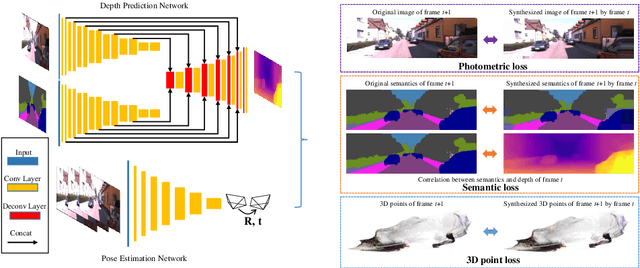
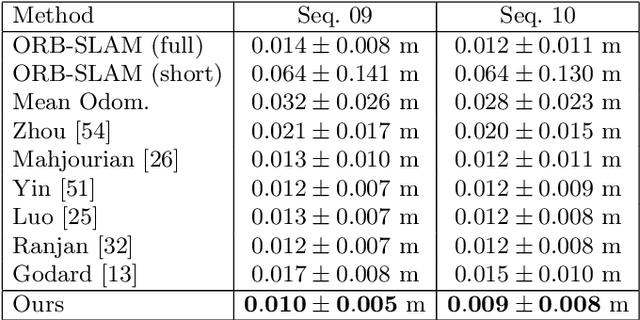
We propose a semantics-driven unsupervised learning approach for monocular depth and ego-motion estimation from videos in this paper. Recent unsupervised learning methods employ photometric errors between synthetic view and actual image as a supervision signal for training. In our method, we exploit semantic segmentation information to mitigate the effects of dynamic objects and occlusions in the scene, and to improve depth prediction performance by considering the correlation between depth and semantics. To avoid costly labeling process, we use noisy semantic segmentation results obtained by a pre-trained semantic segmentation network. In addition, we minimize the position error between the corresponding points of adjacent frames to utilize 3D spatial information. Experimental results on the KITTI dataset show that our method achieves good performance in both depth and ego-motion estimation tasks.
Online Invariance Selection for Local Feature Descriptors
Jul 17, 2020
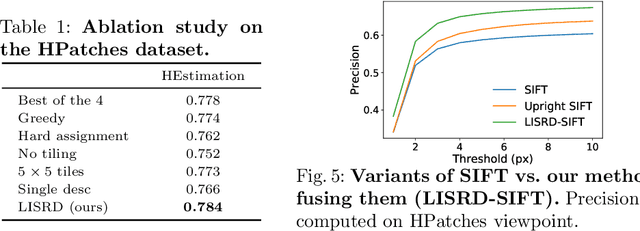
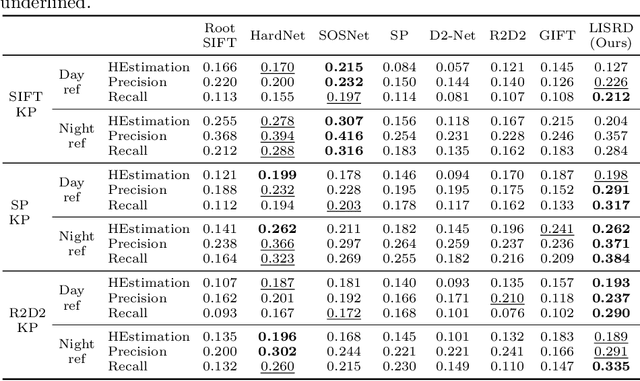
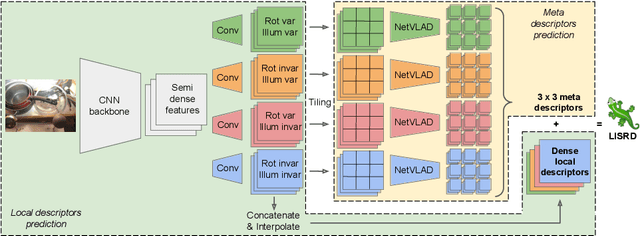
To be invariant, or not to be invariant: that is the question formulated in this work about local descriptors. A limitation of current feature descriptors is the trade-off between generalization and discriminative power: more invariance means less informative descriptors. We propose to overcome this limitation with a disentanglement of invariance in local descriptors and with an online selection of the most appropriate invariance given the context. Our framework consists in a joint learning of multiple local descriptors with different levels of invariance and of meta descriptors encoding the regional variations of an image. The similarity of these meta descriptors across images is used to select the right invariance when matching the local descriptors. Our approach, named Local Invariance Selection at Runtime for Descriptors (LISRD), enables descriptors to adapt to adverse changes in images, while remaining discriminative when invariance is not required. We demonstrate that our method can boost the performance of current descriptors and outperforms state-of-the-art descriptors in several matching tasks, when evaluated on challenging datasets with day-night illumination as well as viewpoint changes.
Predicting Visual Memory Schemas with Variational Autoencoders
Jul 19, 2019
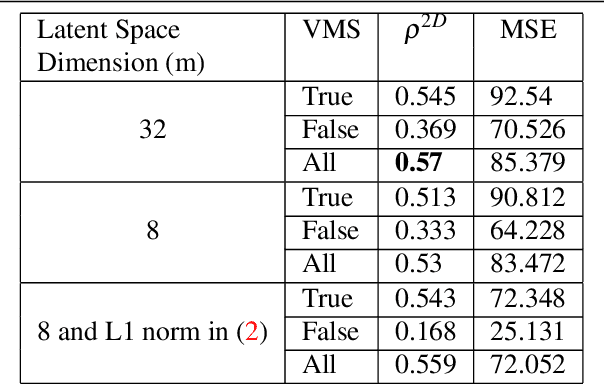
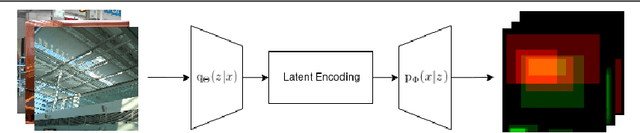

Visual memory schema (VMS) maps show which regions of an image cause that image to be remembered or falsely remembered. Previous work has succeeded in generating low resolution VMS maps using convolutional neural networks. We instead approach this problem as an image-to-image translation task making use of a variational autoencoder. This approach allows us to generate higher resolution dual channel images that represent visual memory schemas, allowing us to evaluate predicted true memorability and false memorability separately. We also evaluate the relationship between VMS maps, predicted VMS maps, ground truth memorability scores, and predicted memorability scores.
Vulnerability of Face Recognition Systems Against Composite Face Reconstruction Attack
Aug 23, 2020



Rounding confidence score is considered trivial but a simple and effective countermeasure to stop gradient descent based image reconstruction attacks. However, its capability in the face of more sophisticated reconstruction attacks is an uninvestigated research area. In this paper, we prove that, the face reconstruction attacks based on composite faces can reveal the inefficiency of rounding policy as countermeasure. We assume that, the attacker takes advantage of face composite parts which helps the attacker to get access to the most important features of the face or decompose it to the independent segments. Afterwards, decomposed segments are exploited as search parameters to create a search path to reconstruct optimal face. Face composition parts enable the attacker to violate the privacy of face recognition models even with a blind search. However, we assume that, the attacker may take advantage of random search to reconstruct the target face faster. The algorithm is started with random composition of face parts as initial face and confidence score is considered as fitness value. Our experiments show that, since the rounding policy as countermeasure can't stop the random search process, current face recognition systems are extremely vulnerable against such sophisticated attacks. To address this problem, we successfully test Face Detection Score Filtering (FDSF) as a countermeasure to protect the privacy of training data against proposed attack.
A Comprehensive Overview and Survey of Recent Advances in Meta-Learning
Apr 29, 2020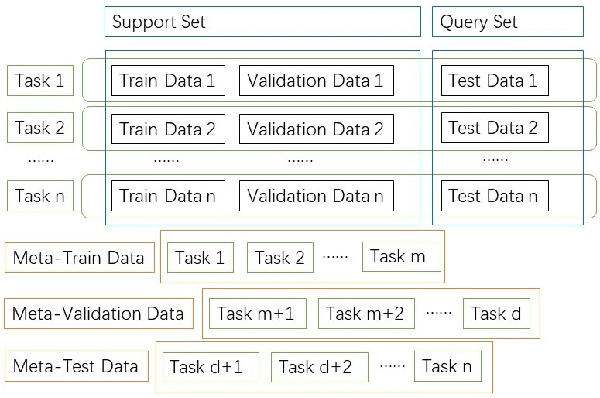

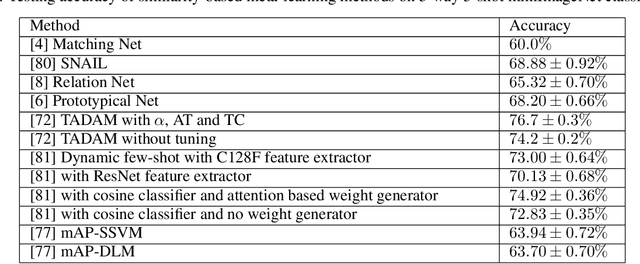
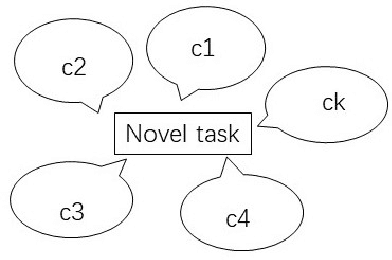
This article reviews meta-learning which seeks rapid and accurate model adaptation to unseen tasks with applications in image classification, natural language processing and robotics. Unlike deep learning, meta-learning uses few-shot datasets and concerns further improving model generalization to obtain higher prediction accuracy. We summarize meta-learning models in three categories: black-box adaptation, similarity based method and meta-learner procedure. Recent applications concentrate upon combination of meta-learning with Bayesian deep learning and reinforcement learning to provide feasible integrated problem solutions. We present performance comparison of recent meta-learning methods and discuss future research direction.
Automatic classification between COVID-19 pneumonia, non-COVID-19 pneumonia, and the healthy on chest X-ray image: combination of data augmentation methods
Jun 12, 2020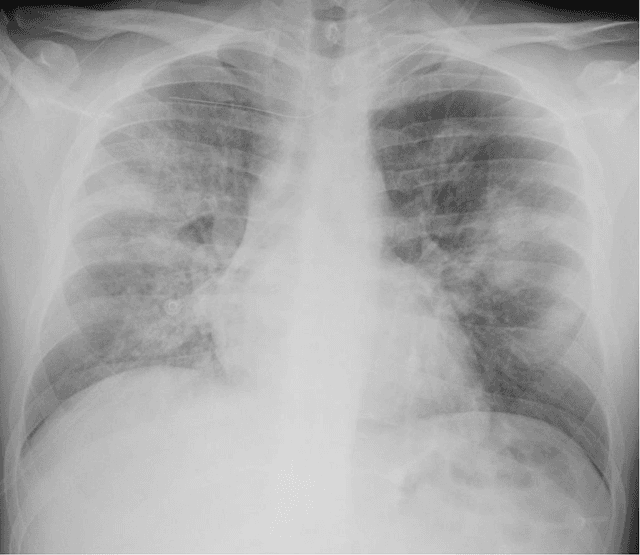
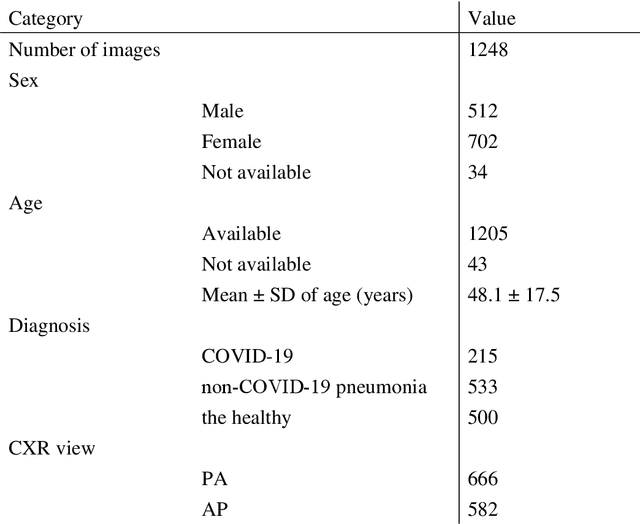
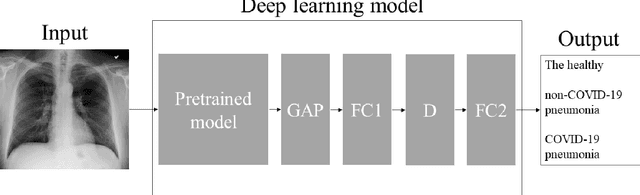
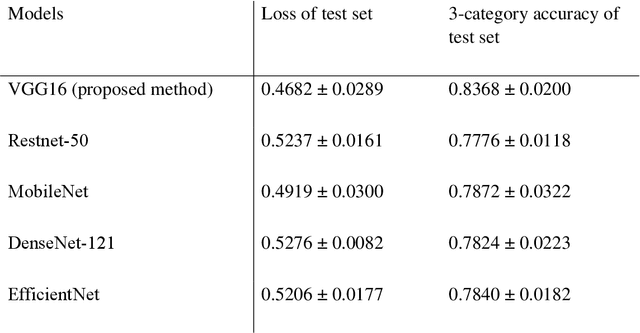
Purpose: This study aimed to develop and validate computer-aided diagnosis (CXDx) system for classification between COVID-19 pneumonia, non-COVID-19 pneumonia, and the healthy on chest X-ray (CXR) images. Materials and Methods: From two public datasets, 1248 CXR images were obtained, which included 215, 533, and 500 CXR images of COVID-19 pneumonia patients, non-COVID-19 pneumonia patients, and the healthy samples. The proposed CADx system utilized VGG16 as a pre-trained model and combination of conventional method and mixup as data augmentation methods. Other types of pre-trained models were compared with the VGG16-based model. Single type or no data augmentation methods were also evaluated. Splitting of training/validation/test sets was used when building and evaluating the CADx system. Three-category accuracy was evaluated for test set with 125 CXR images. Results: The three-category accuracy of the CAD system was 83.6% between COVID-19 pneumonia, non-COVID-19 pneumonia, and the healthy. Sensitivity for COVID-19 pneumonia was more than 90%. The combination of conventional method and mixup was more useful than single type or no data augmentation method. Conclusion: This study was able to create an accurate CADx system for the 3-category classification. Source code of our CADx system is available as open source for COVID-19 research.