 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Predicting Visual Memory Schemas with Variational Autoencoders
Jul 19, 2019

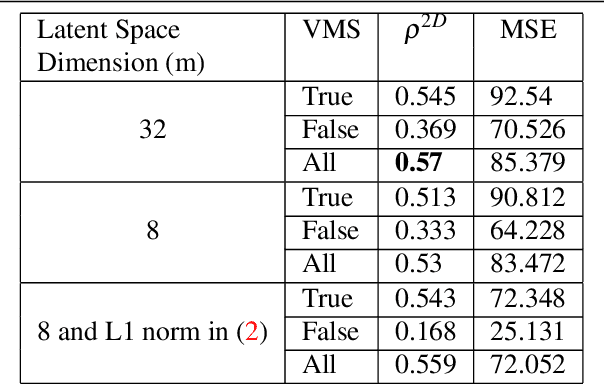
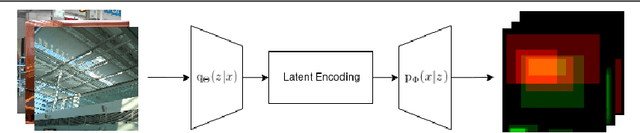

Visual memory schema (VMS) maps show which regions of an image cause that image to be remembered or falsely remembered. Previous work has succeeded in generating low resolution VMS maps using convolutional neural networks. We instead approach this problem as an image-to-image translation task making use of a variational autoencoder. This approach allows us to generate higher resolution dual channel images that represent visual memory schemas, allowing us to evaluate predicted true memorability and false memorability separately. We also evaluate the relationship between VMS maps, predicted VMS maps, ground truth memorability scores, and predicted memorability scores.
RoboCoDraw: Robotic Avatar Drawing with GAN-based Style Transfer and Time-efficient Path Optimization
Dec 11, 2019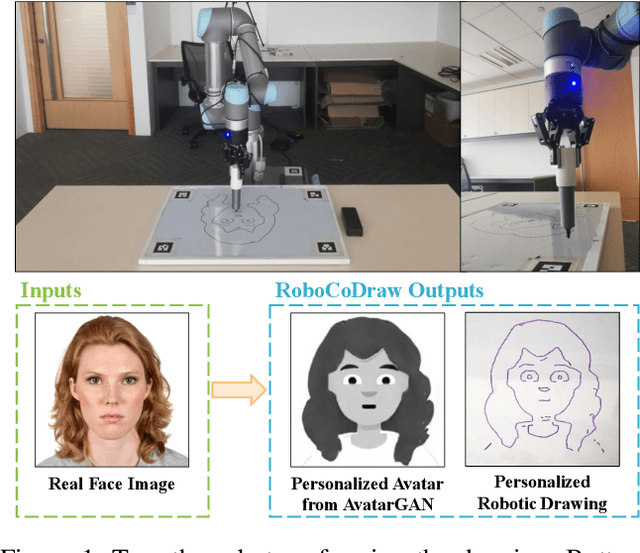
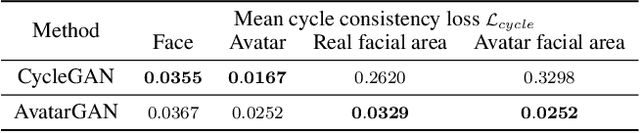

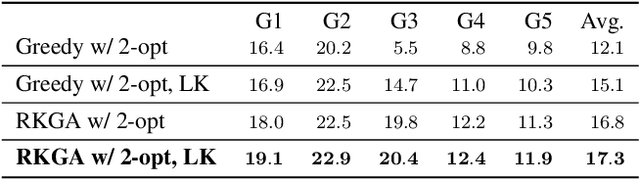
Robotic drawing has become increasingly popular as an entertainment and interactive tool. In this paper we present RoboCoDraw, a real-time collaborative robot-based drawing system that draws stylized human face sketches interactively in front of human users, by using the Generative Adversarial Network (GAN)-based style transfer and a Random-Key Genetic Algorithm (RKGA)-based path optimization. The proposed RoboCoDraw system takes a real human face image as input, converts it to a stylized avatar, then draws it with a robotic arm. A core component in this system is the Avatar-GAN proposed by us, which generates a cartoon avatar face image from a real human face. AvatarGAN is trained with unpaired face and avatar images only and can generate avatar images of much better likeness with human face images in comparison with the vanilla CycleGAN. After the avatar image is generated, it is fed to a line extraction algorithm and converted to sketches. An RKGA-based path optimization algorithm is applied to find a time-efficient robotic drawing path to be executed by the robotic arm. We demonstrate the capability of RoboCoDraw on various face images using a lightweight, safe collaborative robot UR5.
PDO-eConvs: Partial Differential Operator Based Equivariant Convolutions
Jul 20, 2020
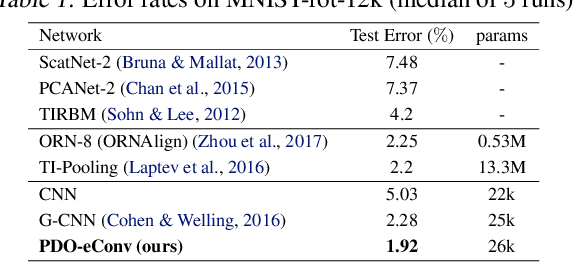

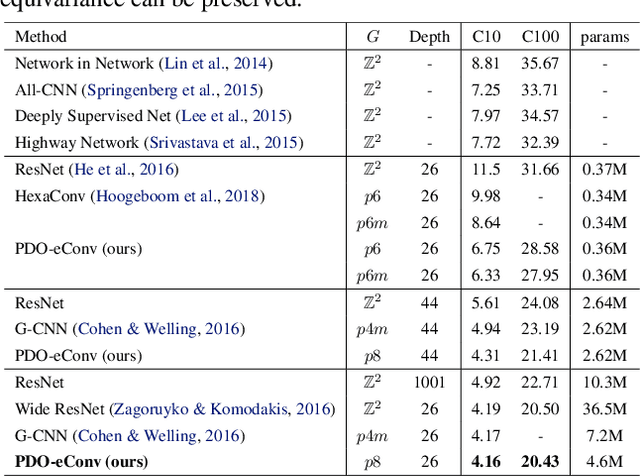
Recent research has shown that incorporating equivariance into neural network architectures is very helpful, and there have been some works investigating the equivariance of networks under group actions. However, as digital images and feature maps are on the discrete meshgrid, corresponding equivariance-preserving transformation groups are very limited. In this work, we deal with this issue from the connection between convolutions and partial differential operators (PDOs). In theory, assuming inputs to be smooth, we transform PDOs and propose a system which is equivariant to a much more general continuous group, the $n$-dimension Euclidean group. In implementation, we discretize the system using the numerical schemes of PDOs, deriving approximately equivariant convolutions (PDO-eConvs). Theoretically, the approximation error of PDO-eConvs is of the quadratic order. It is the first time that the error analysis is provided when the equivariance is approximate. Extensive experiments on rotated MNIST and natural image classification show that PDO-eConvs perform competitively yet use parameters much more efficiently. Particularly, compared with Wide ResNets, our methods result in better results using only 12.6% parameters.
Hiding Data in Images Using Cryptography and Deep Neural Network
Dec 22, 2019

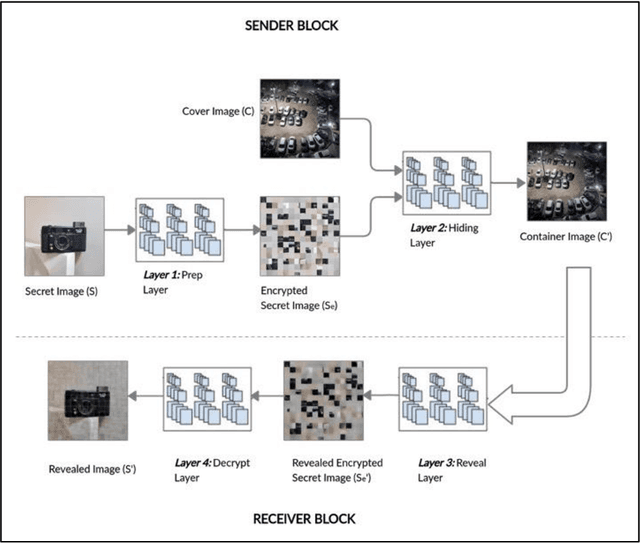
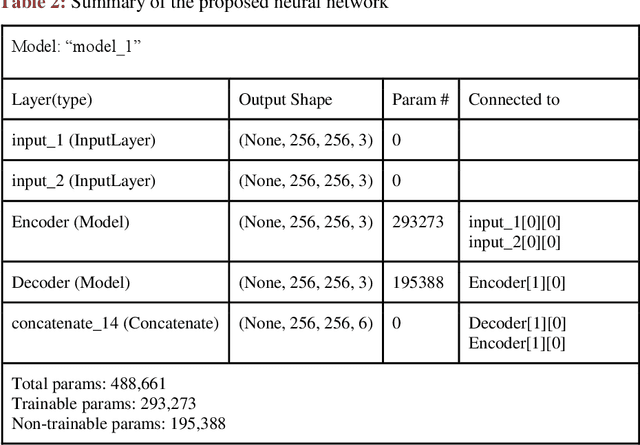
Steganography is an art of obscuring data inside another quotidian file of similar or varying types. Hiding data has always been of significant importance to digital forensics. Previously, steganography has been combined with cryptography and neural networks separately. Whereas, this research combines steganography, cryptography with the neural networks all together to hide an image inside another container image of the larger or same size. Although the cryptographic technique used is quite simple, but is effective when convoluted with deep neural nets. Other steganography techniques involve hiding data efficiently, but in a uniform pattern which makes it less secure. This method targets both the challenges and make data hiding secure and non-uniform.
Machine Learning for Precipitation Nowcasting from Radar Images
Dec 11, 2019

High-resolution nowcasting is an essential tool needed for effective adaptation to climate change, particularly for extreme weather. As Deep Learning (DL) techniques have shown dramatic promise in many domains, including the geosciences, we present an application of DL to the problem of precipitation nowcasting, i.e., high-resolution (1 km x 1 km) short-term (1 hour) predictions of precipitation. We treat forecasting as an image-to-image translation problem and leverage the power of the ubiquitous UNET convolutional neural network. We find this performs favorably when compared to three commonly used models: optical flow, persistence and NOAA's numerical one-hour HRRR nowcasting prediction.
Gated Convolutional Networks with Hybrid Connectivity for Image Classification
Aug 26, 2019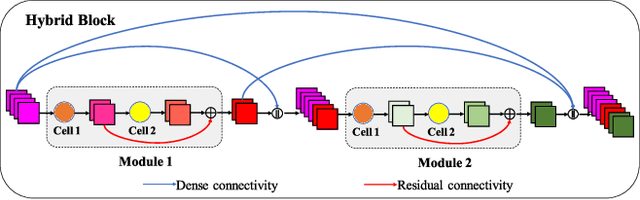
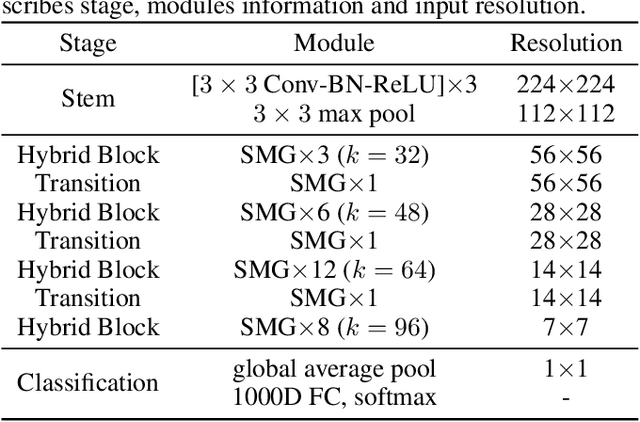
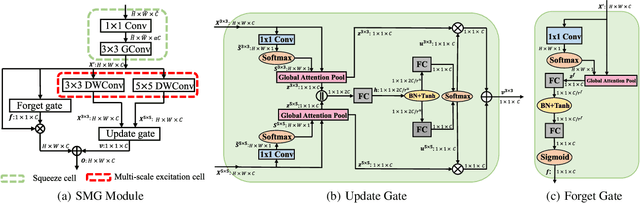
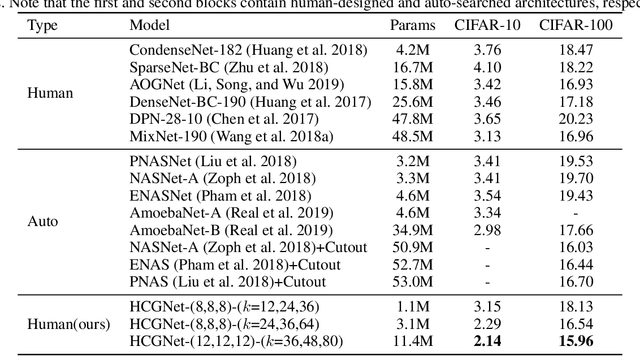
We design a highly efficient architecture called Gated Convolutional Network with Hybrid Connectivity (HCGNet), which is equipped with the combination of local residual and global dense connectivity to enjoy their individual superiorities as well as attention-based gate mechanism to assist feature recalibration. To adapt our hybrid connectivity, we further propose a novel module which includes a squeeze cell for obtaining the compact features from input and then a multi-scale excitation cell attached an update gate to model the global context features for capturing long-range dependency based on multi-scale information. We also locate a forget gate on residual connectivity to decay the reused features, which can be aggergated with newly global context features to form the output that can facilitate effective feature exploration as well as re-exploitation to some extent. Moreover, the number of our proposed modules under dense connectivity can quite fewer than classical DenseNet thus reducing considerable redundancy but with empirically better performance. On CIFAR-10/100 datasets, HCGNets significantly outperform state-of-the-art both human-designed and auto-searched networks with much fewer parameters. It can also consistently obtain better performance and interpretability than widely applied networks in practice on ImageNet dataset.
AQD: Towards Accurate Quantized Object Detection
Aug 03, 2020
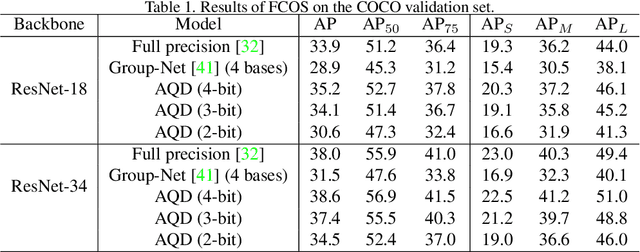
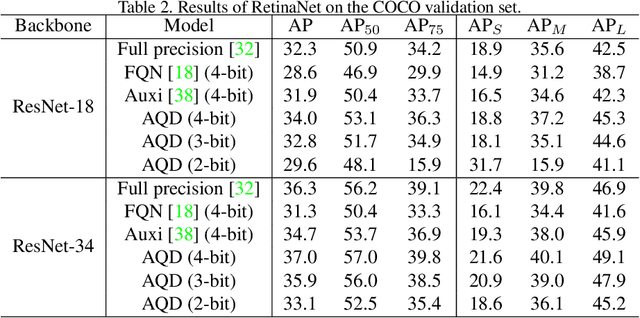

Network quantization aims to lower the bitwidth of weights and activations and hence reduce the model size and accelerate the inference of deep networks. Even though existing quantization methods have achieved promising performance on image classification, applying aggressively low bitwidth quantization on object detection while preserving the performance is still a challenge. In this paper, we demonstrate that the poor performance of the quantized network on object detection comes from the inaccurate batch statistics of batch normalization. To solve this, we propose an accurate quantized object detection (AQD) method. Specifically, we propose to employ multi-level batch normalization (multi-level BN) to estimate the batch statistics of each detection head separately. We further propose a learned interval quantization method to improve how the quantizer itself is configured. To evaluate the performance of the proposed methods, we apply AQD to two one-stage detectors (i.e., RetinaNet and FCOS). Experimental results on COCO show that our methods achieve near-lossless performance compared with the full-precision model by using extremely low bitwidth regimes such as 3-bit. In particular, we even outperform the full-precision counterpart by a large margin with a 4-bit detector, which is of great practical value.
Lesion Mask-based Simultaneous Synthesis of Anatomic and MolecularMR Images using a GAN
Jul 05, 2020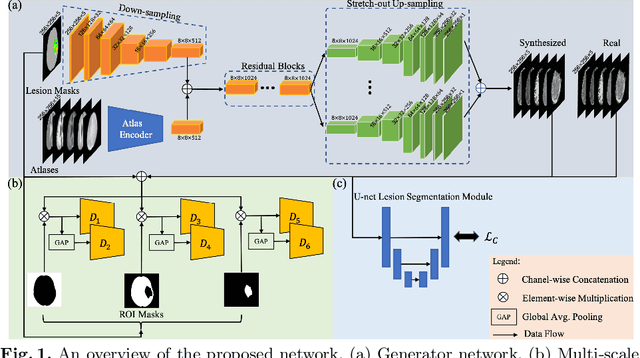

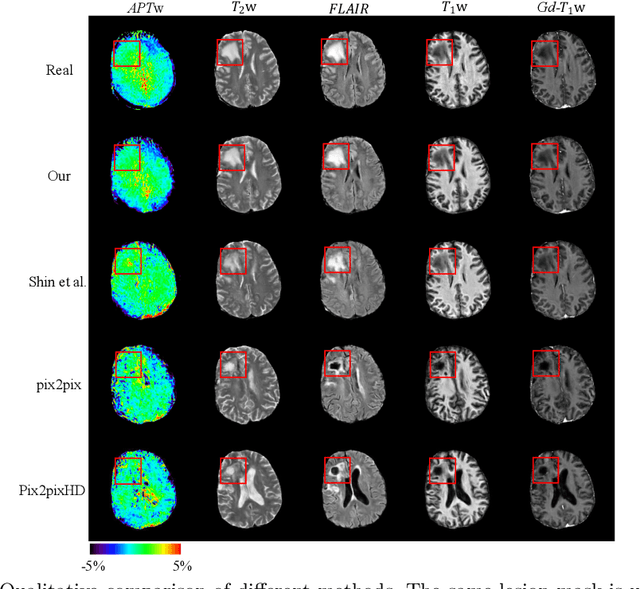
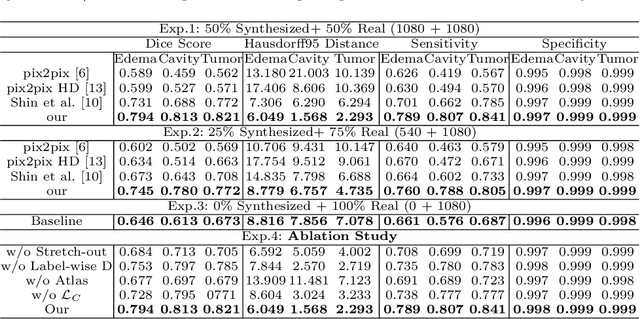
Data-driven automatic approaches have demonstrated their great potential in resolving various clinical diagnostic dilemmas for patients with malignant gliomas in neuro-oncology with the help of conventional and advanced molecular MR images. However, the lack of sufficient annotated MRI data has vastly impeded the development of such automatic methods. Conventional data augmentation approaches, including flipping, scaling, rotation, and distortion are not capable of generating data with diverse image content. In this paper, we propose a generative adversarial network (GAN), which can simultaneously synthesize data from arbitrary manipulated lesion information on multiple anatomic and molecular MRI sequences, including T1-weighted (T1w), gadolinium enhanced T1w (Gd-T1w), T2-weighted (T2w), fluid-attenuated inversion recovery (FLAIR), and amide proton transfer-weighted (APTw). The proposed framework consists of a stretch-out up-sampling module, a brain atlas encoder, a segmentation consistency module, and multi-scale labelwise discriminators. Extensive experiments on real clinical data demonstrate that the proposed model can perform significantly better than the state-of-the-art synthesis methods.
Novel min-max reformulations of Linear Inverse Problems
Jul 05, 2020

In this article, we dwell into the class of so-called ill-posed Linear Inverse Problems (LIP) which simply refers to the task of recovering the entire signal from its relatively few random linear measurements. Such problems arise in a variety of settings with applications ranging from medical image processing, recommender systems, etc. We propose a slightly generalized version of the error constrained linear inverse problem and obtain a novel and equivalent convex-concave min-max reformulation by providing an exposition to its convex geometry. Saddle points of the min-max problem are completely characterized in terms of a solution to the LIP, and vice versa. Applying simple saddle point seeking ascend-descent type algorithms to solve the min-max problems provides novel and simple algorithms to find a solution to the LIP. Moreover, the reformulation of an LIP as the min-max problem provided in this article is crucial in developing methods to solve the dictionary learning problem with almost sure recovery constraints.
Learning from Multiple Datasets with Heterogeneous and Partial Labels for Universal Lesion Detection in CT
Sep 05, 2020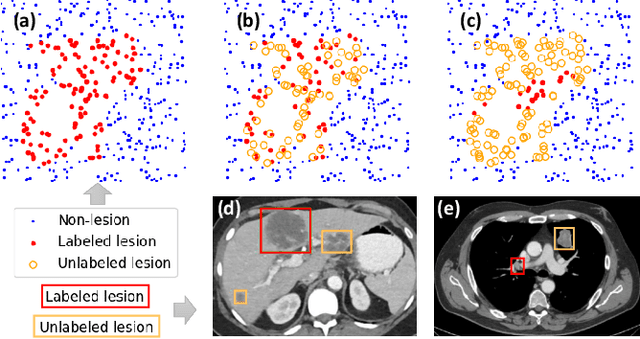
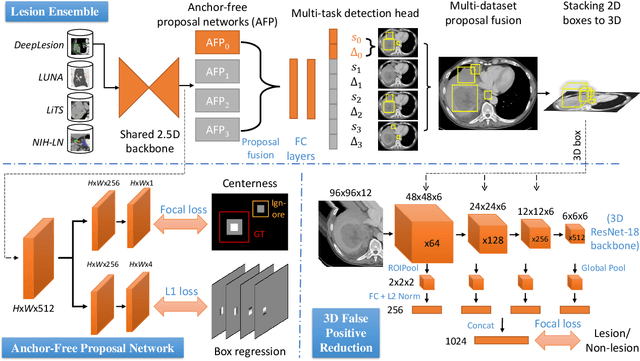
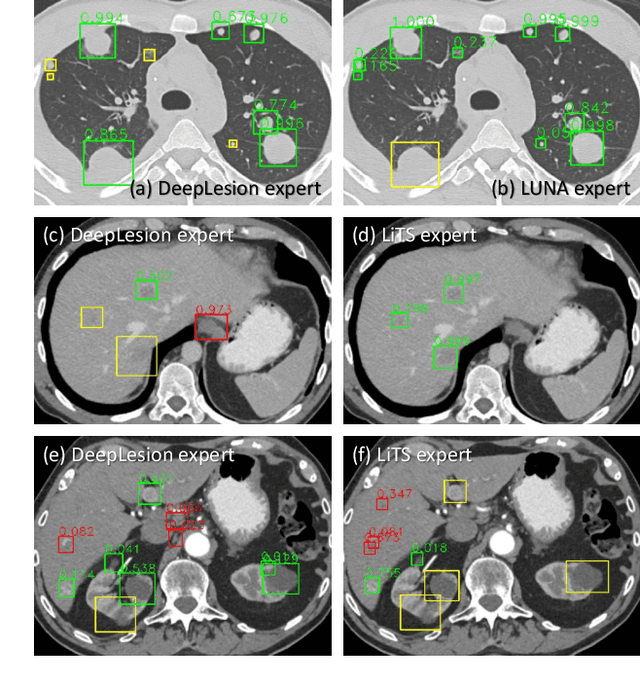
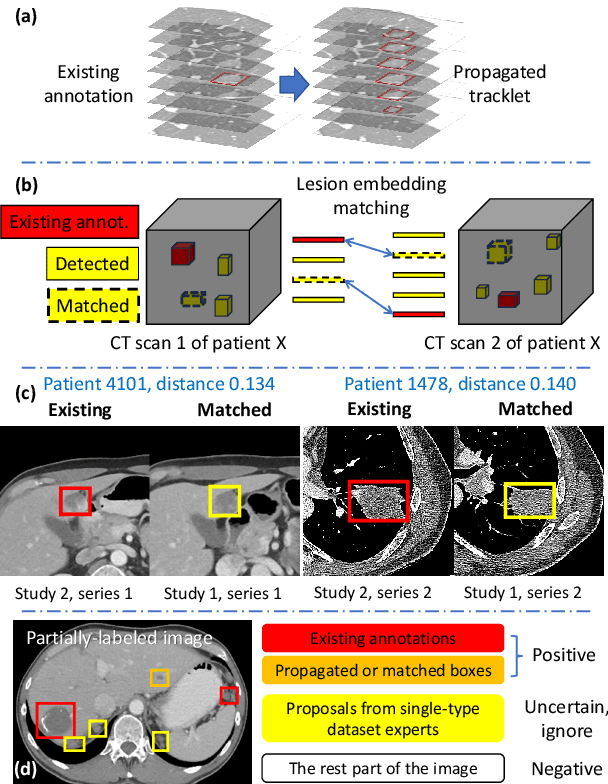
Large-scale datasets with high-quality labels are desired for training accurate deep learning models. However, due to annotation costs, medical imaging datasets are often either partially-labeled or small. For example, DeepLesion is a large-scale CT image dataset with lesions of various types, but it also has many unlabeled lesions (missing annotations). When training a lesion detector on a partially-labeled dataset, the missing annotations will generate incorrect negative signals and degrade performance. Besides DeepLesion, there are several small single-type datasets, such as LUNA for lung nodules and LiTS for liver tumors. Such datasets have heterogeneous label scopes, i.e., different lesion types are labeled in different datasets with other types ignored. In this work, we aim to tackle the problem of heterogeneous and partial labels, and develop a universal lesion detection algorithm to detect a comprehensive variety of lesions. First, we build a simple yet effective lesion detection framework named Lesion ENSemble (LENS). LENS can efficiently learn from multiple heterogeneous lesion datasets in a multi-task fashion and leverage their synergy by feature sharing and proposal fusion. Next, we propose strategies to mine missing annotations from partially-labeled datasets by exploiting clinical prior knowledge and cross-dataset knowledge transfer. Finally, we train our framework on four public lesion datasets and evaluate it on 800 manually-labeled sub-volumes in DeepLesion. On this challenging task, our method brings a relative improvement of 49% compared to the current state-of-the-art approach.