 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Taming Adversarial Domain Transfer with Structural Constraints for Image Enhancement
Dec 18, 2017
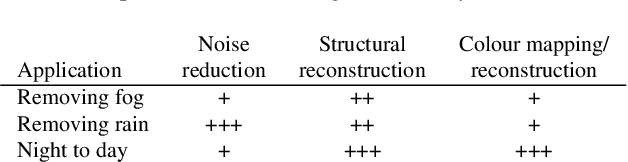

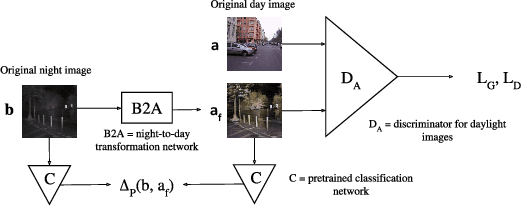
The goal of this work is to improve images of traffic scenes that are degraded by natural causes such as fog, rain and limited visibility during the night. For these applications, it is next to impossible to get pixel perfect pairs of the same scene, with and without the degrading conditions. This makes it unsuitable for conventional supervised learning approaches, however, it is easy to collect a dataset of unpaired images of the scenes in a perfect and in a degraded condition. To enhance the images taken in a poor visibility condition, domain transfer models can be trained to transform an image from the degraded to the clear domain. A well-known concept for unsupervised domain transfer are cycle-consistent generative adversarial models. Unfortunately, the resulting generators often change the structure of the scene. This causes an undesirable change in the semantics of the traffic situation. We propose three ways to cope with this problem depending on the type of degradation: forcing the same perception in both domains, forcing the same edges in both domains or guiding the generator to produce semantically sound transformations.
SaADB: A Self-attention Guided ADB Network for Person Re-identification
Jul 10, 2020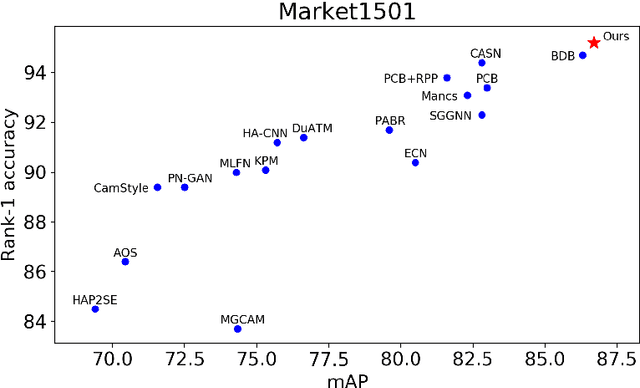
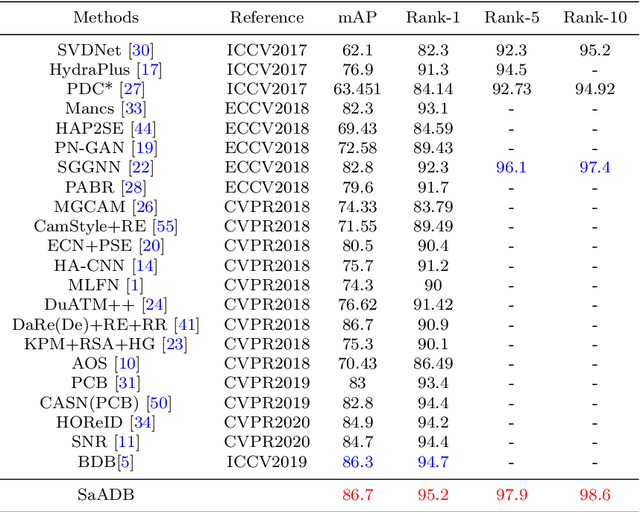
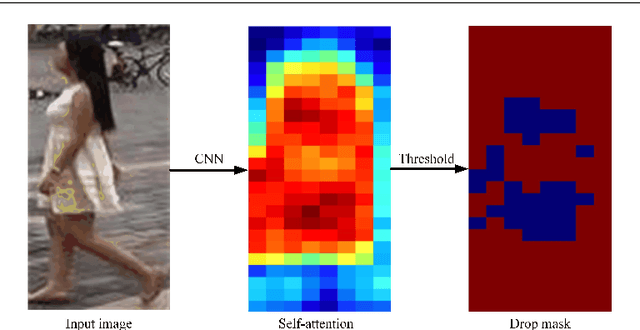
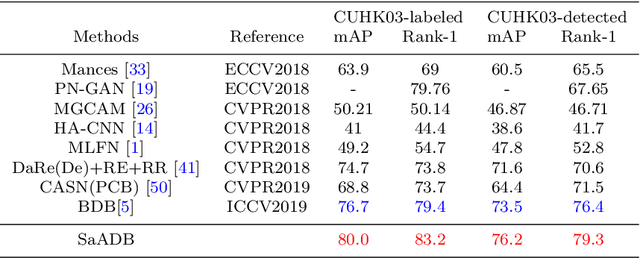
Recently, Batch DropBlock network (BDB) has demonstrated its effectiveness on person image representation and re-ID task via feature erasing. However, BDB drops the features randomly which may lead to sub-optimal results. In this paper, we propose a novel Self-attention guided Adaptive DropBlock network (SaADB) for person re-ID which can adaptively erase the most discriminative regions. Specifically, SaADB first obtains a self-attention map by channel-wise pooling and returns a drop mask by thresholding the self-attention map. Then, the input features and self-attention guided drop mask are multiplied to generate the dropped feature maps. Meanwhile, we utilize the spatial and channel attention to learn a better feature map and iteratively train with the feature dropping module for person re-ID. Experiments on several benchmark datasets demonstrate that the proposed SaADB significantly beats the prevalent competitors in person re-ID.
The Shape of an Image: A Study of Mapper on Images
Dec 07, 2017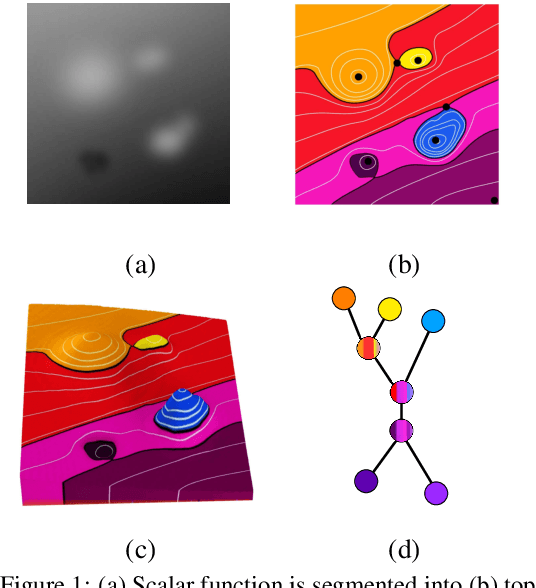
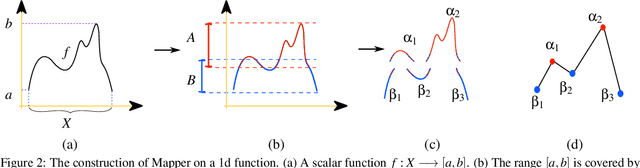
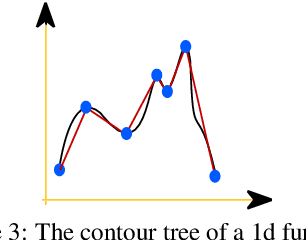
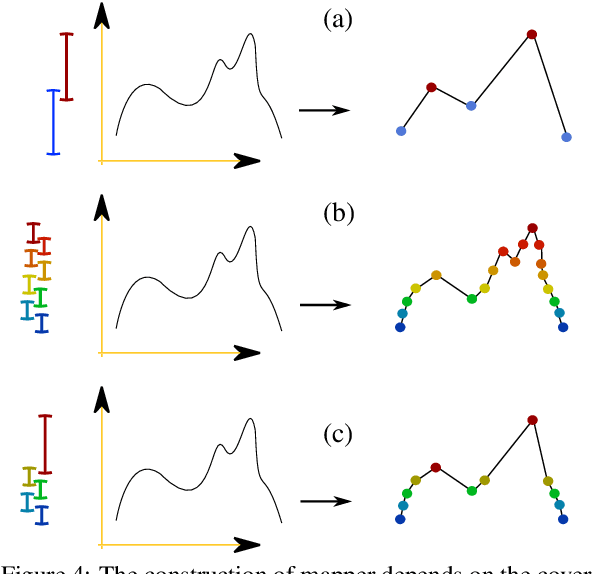
We study the topological construction called Mapper in the context of simply connected domains, in particular on images. The Mapper construction can be considered as a generalization for contour, split, and joint trees on simply connected domains. A contour tree on an image domain assumes the height function to be a piecewise linear Morse function. This is a rather restrictive class of functions and does not allow us to explore the topology for most real world images. The Mapper construction avoids this limitation by assuming only continuity on the height function allowing this construction to robustly deal with a significant larger set of images. We provide a customized construction for Mapper on images, give a fast algorithm to compute it, and show how to simplify the Mapper structure in this case. Finally, we provide a simple procedure that guarantees the equivalence of Mapper to contour, join, and split trees on a simply connected domain.
Relaxed Linearized Algorithms for Faster X-Ray CT Image Reconstruction
Dec 14, 2015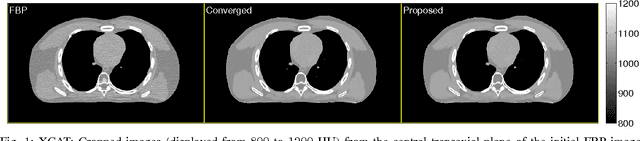
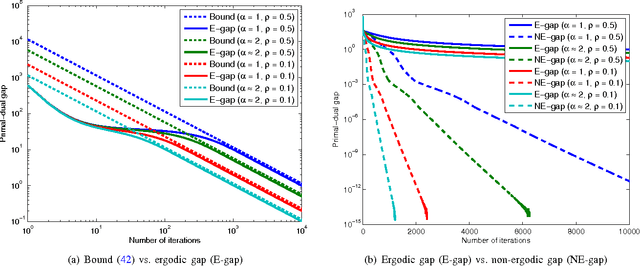
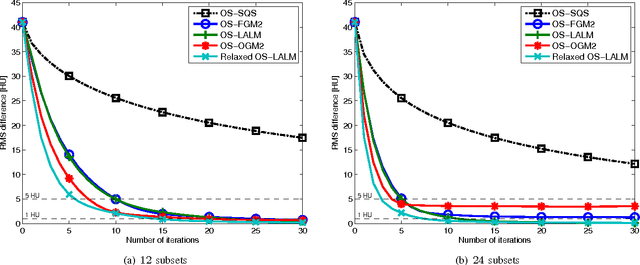
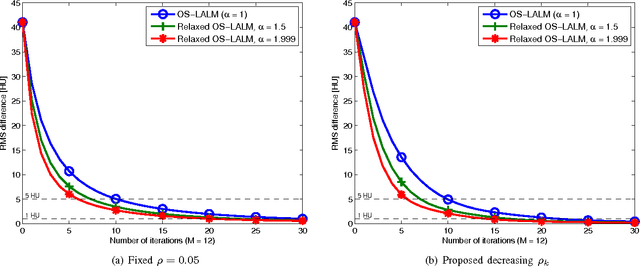
Statistical image reconstruction (SIR) methods are studied extensively for X-ray computed tomography (CT) due to the potential of acquiring CT scans with reduced X-ray dose while maintaining image quality. However, the longer reconstruction time of SIR methods hinders their use in X-ray CT in practice. To accelerate statistical methods, many optimization techniques have been investigated. Over-relaxation is a common technique to speed up convergence of iterative algorithms. For instance, using a relaxation parameter that is close to two in alternating direction method of multipliers (ADMM) has been shown to speed up convergence significantly. This paper proposes a relaxed linearized augmented Lagrangian (AL) method that shows theoretical faster convergence rate with over-relaxation and applies the proposed relaxed linearized AL method to X-ray CT image reconstruction problems. Experimental results with both simulated and real CT scan data show that the proposed relaxed algorithm (with ordered-subsets [OS] acceleration) is about twice as fast as the existing unrelaxed fast algorithms, with negligible computation and memory overhead.
Forced Spatial Attention for Driver Foot Activity Classification
Aug 20, 2019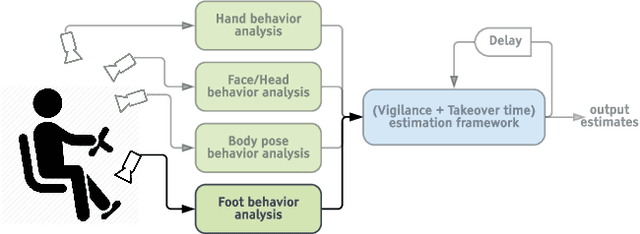
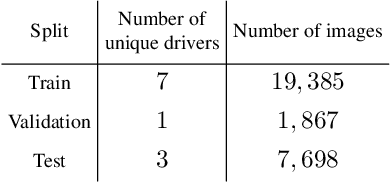

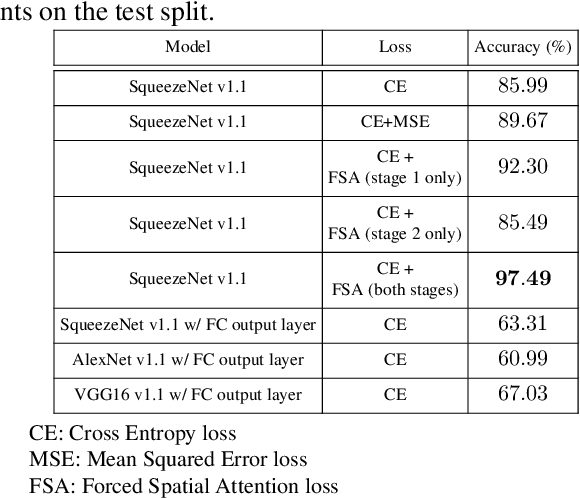
This paper provides a simple solution for reliably solving image classification tasks tied to spatial locations of salient objects in the scene. Unlike conventional image classification approaches that are designed to be invariant to translations of objects in the scene, we focus on tasks where the output classes vary with respect to where an object of interest is situated within an image. To handle this variant of the image classification task, we propose augmenting the standard cross-entropy (classification) loss with a domain dependent Forced Spatial Attention (FSA) loss, which in essence compels the network to attend to specific regions in the image associated with the desired output class. To demonstrate the utility of this loss function, we consider the task of driver foot activity classification - where each activity is strongly correlated with where the driver's foot is in the scene. Training with our proposed loss function results in significantly improved accuracies, better generalization, and robustness against noise, while obviating the need for very large datasets.
STEER: Simple Temporal Regularization For Neural ODEs
Jul 01, 2020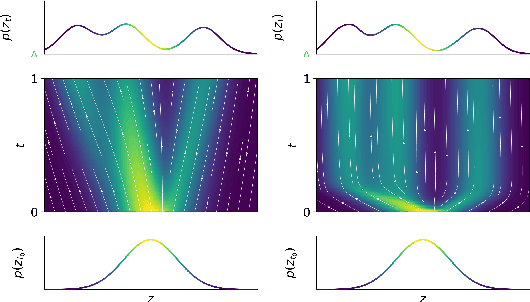
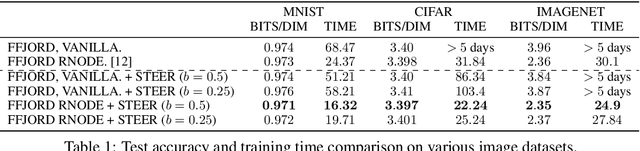
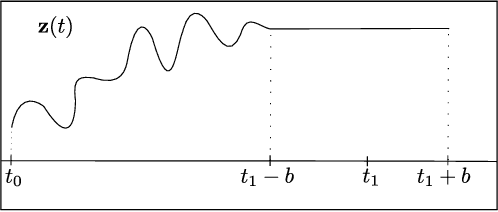
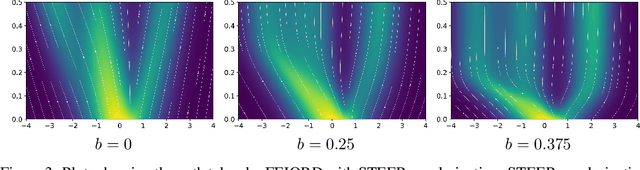
Training Neural Ordinary Differential Equations (ODEs) is often computationally expensive. Indeed, computing the forward pass of such models involves solving an ODE which can become arbitrarily complex during training. Recent works have shown that regularizing the dynamics of the ODE can partially alleviate this. In this paper we propose a new regularization technique: randomly sampling the end time of the ODE during training. The proposed regularization is simple to implement, has negligible overhead and is effective across a wide variety of tasks. Further, the technique is orthogonal to several other methods proposed to regularize the dynamics of ODEs and as such can be used in conjunction with them. We show through experiments on normalizing flows, time series models and image recognition that the proposed regularization can significantly decrease training time and even improve performance over baseline models.
Photorealistic Lip Sync with Adversarial Temporal Convolutional Networks
Feb 20, 2020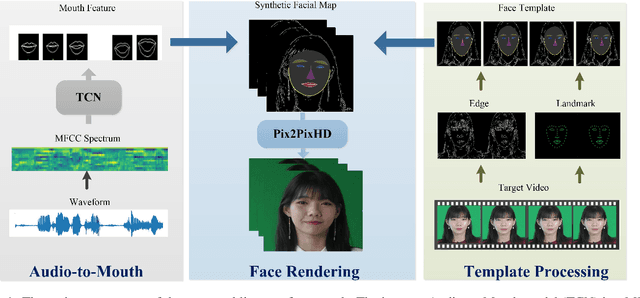

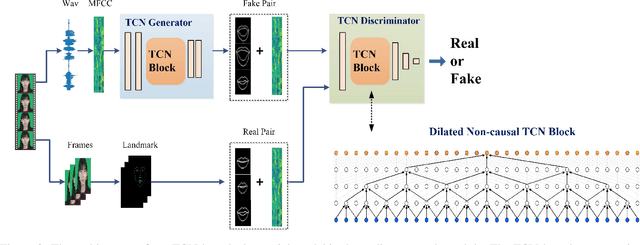

Lip sync has emerged as a promising technique to generate mouth movements on a talking head. However, synthesizing a clear, accurate and human-like performance is still challenging. In this paper, we present a novel lip-sync solution for producing a high-quality and photorealistic talking head from speech. We focus on capturing the specific lip movement and talking style of the target person. We model the seq-to-seq mapping from audio signals to mouth features by two adversarial temporal convolutional networks. Experiments show our model outperforms traditional RNN-based baselines in both accuracy and speed. We also propose an image-to-image translation-based approach for generating high-resolution photoreal face appearance from synthetic facial maps. This fully-trainable framework not only avoids the cumbersome steps like candidate-frame selection in graphics-based rendering methods but also solves some existing issues in recent neural network-based solutions. Our work will benefit related applications such as conversational agent, virtual anchor, tele-presence and gaming.
Image Segmentation and Restoration Using Parametric Contours With Free Endpoints
Apr 27, 2015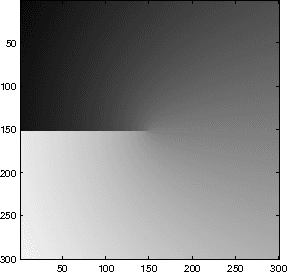
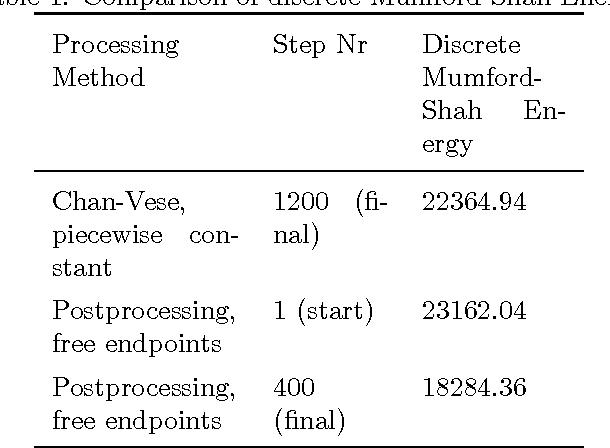
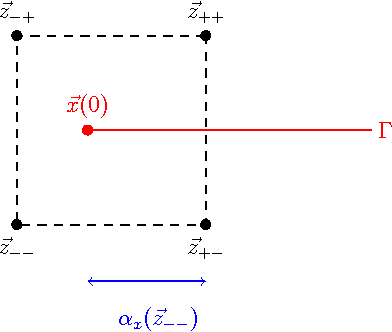
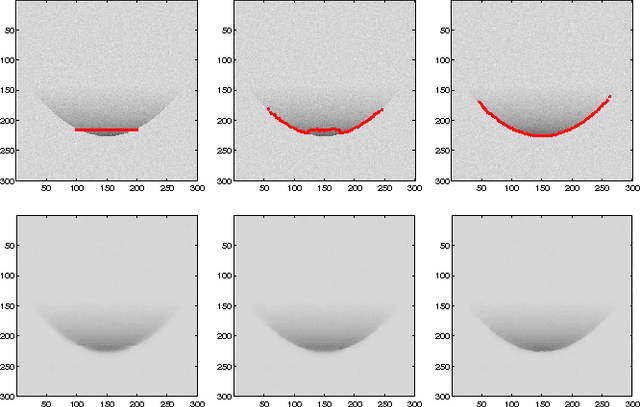
In this paper, we introduce a novel approach for active contours with free endpoints. A scheme is presented for image segmentation and restoration based on a discrete version of the Mumford-Shah functional where the contours can be both closed and open curves. Additional to a flow of the curves in normal direction, evolution laws for the tangential flow of the endpoints are derived. Using a parametric approach to describe the evolving contours together with an edge-preserving denoising, we obtain a fast method for image segmentation and restoration. The analytical and numerical schemes are presented followed by numerical experiments with artificial test images and with a real medical image.
Improved Consistency Regularization for GANs
Feb 11, 2020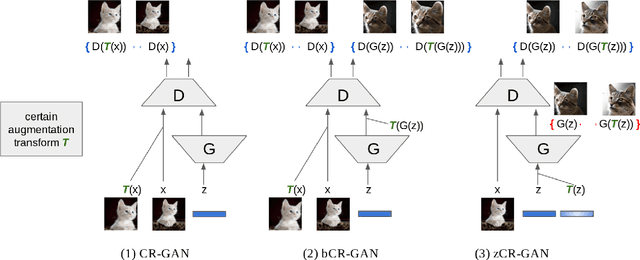
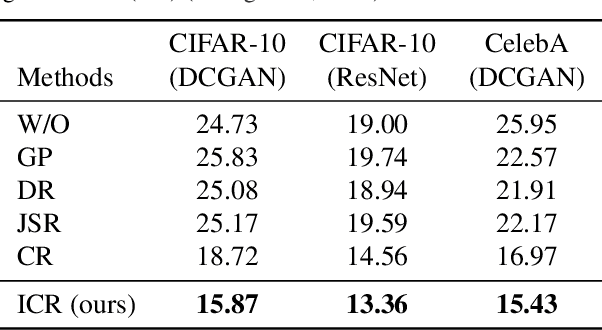


Recent work has increased the performance of Generative Adversarial Networks (GANs) by enforcing a consistency cost on the discriminator. We improve on this technique in several ways. We first show that consistency regularization can introduce artifacts into the GAN samples and explain how to fix this issue. We then propose several modifications to the consistency regularization procedure designed to improve its performance. We carry out extensive experiments quantifying the benefit of our improvements. For unconditional image synthesis on CIFAR-10 and CelebA, our modifications yield the best known FID scores on various GAN architectures. For conditional image synthesis on CIFAR-10, we improve the state-of-the-art FID score from 11.48 to 9.21. Finally, on ImageNet-2012, we apply our technique to the original BigGAN model and improve the FID from 6.66 to 5.38, which is the best score at that model size.
SCREENet: A Multi-view Deep Convolutional Neural Network for Classification of High-resolution Synthetic Mammographic Screening Scans
Sep 25, 2020
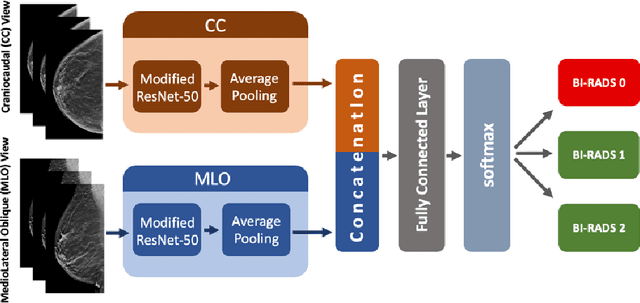
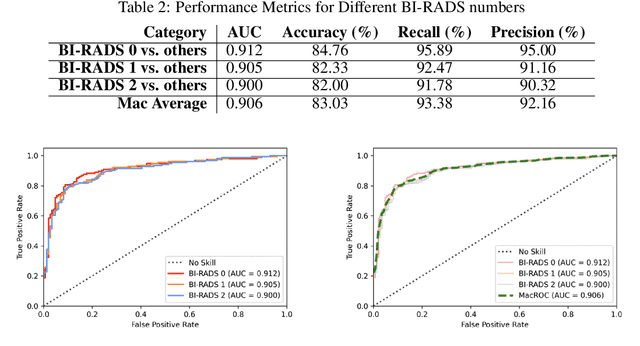
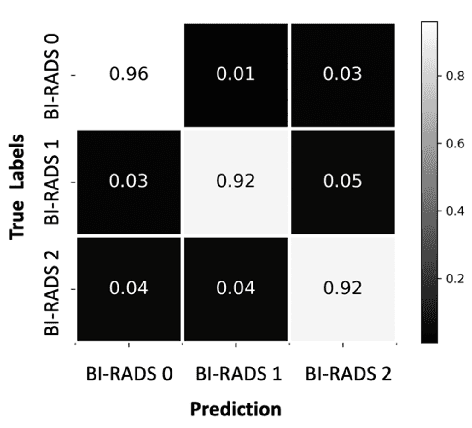
Purpose: To develop and evaluate the accuracy of a multi-view deep learning approach to the analysis of high-resolution synthetic mammograms from digital breast tomosynthesis screening cases, and to assess the effect on accuracy of image resolution and training set size. Materials and Methods: In a retrospective study, 21,264 screening digital breast tomosynthesis (DBT) exams obtained at our institution were collected along with associated radiology reports. The 2D synthetic mammographic images from these exams, with varying resolutions and data set sizes, were used to train a multi-view deep convolutional neural network (MV-CNN) to classify screening images into BI-RADS classes (BI-RADS 0, 1 and 2) before evaluation on a held-out set of exams. Results: Area under the receiver operating characteristic curve (AUC) for BI-RADS 0 vs non-BI-RADS 0 class was 0.912 for the MV-CNN trained on the full dataset. The model obtained accuracy of 84.8%, recall of 95.9% and precision of 95.0%. This AUC value decreased when the same model was trained with 50% and 25% of images (AUC = 0.877, P=0.010 and 0.834, P=0.009 respectively). Also, the performance dropped when the same model was trained using images that were under-sampled by 1/2 and 1/4 (AUC = 0.870, P=0.011 and 0.813, P=0.009 respectively). Conclusion: This deep learning model classified high-resolution synthetic mammography scans into normal vs needing further workup using tens of thousands of high-resolution images. Smaller training data sets and lower resolution images both caused significant decrease in performance.