 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gated Convolutional Networks with Hybrid Connectivity for Image Classification
Aug 26, 2019
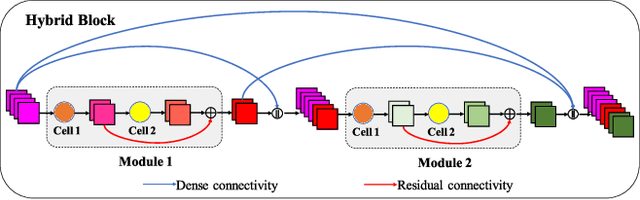
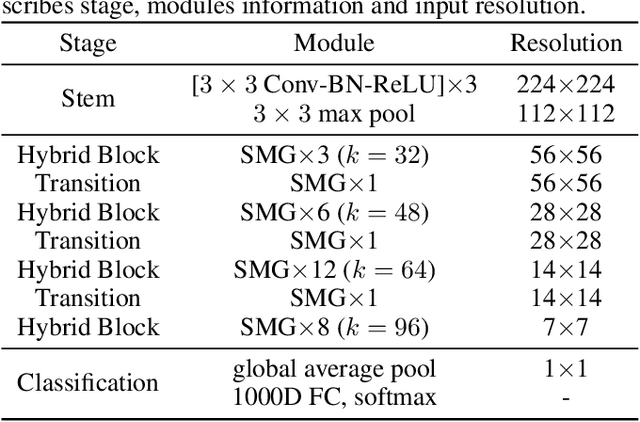
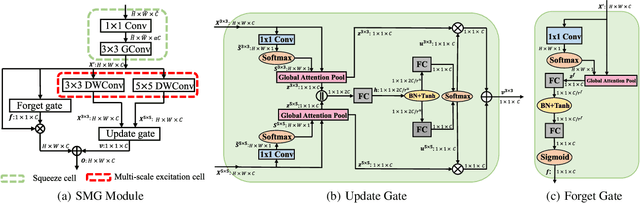
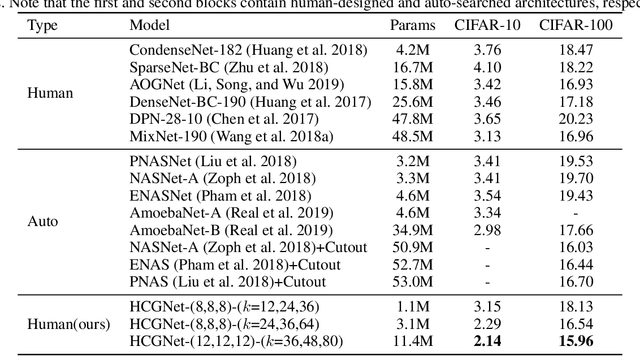
We design a highly efficient architecture called Gated Convolutional Network with Hybrid Connectivity (HCGNet), which is equipped with the combination of local residual and global dense connectivity to enjoy their individual superiorities as well as attention-based gate mechanism to assist feature recalibration. To adapt our hybrid connectivity, we further propose a novel module which includes a squeeze cell for obtaining the compact features from input and then a multi-scale excitation cell attached an update gate to model the global context features for capturing long-range dependency based on multi-scale information. We also locate a forget gate on residual connectivity to decay the reused features, which can be aggergated with newly global context features to form the output that can facilitate effective feature exploration as well as re-exploitation to some extent. Moreover, the number of our proposed modules under dense connectivity can quite fewer than classical DenseNet thus reducing considerable redundancy but with empirically better performance. On CIFAR-10/100 datasets, HCGNets significantly outperform state-of-the-art both human-designed and auto-searched networks with much fewer parameters. It can also consistently obtain better performance and interpretability than widely applied networks in practice on ImageNet dataset.
Multi view stereo with semantic priors
Jul 05, 2020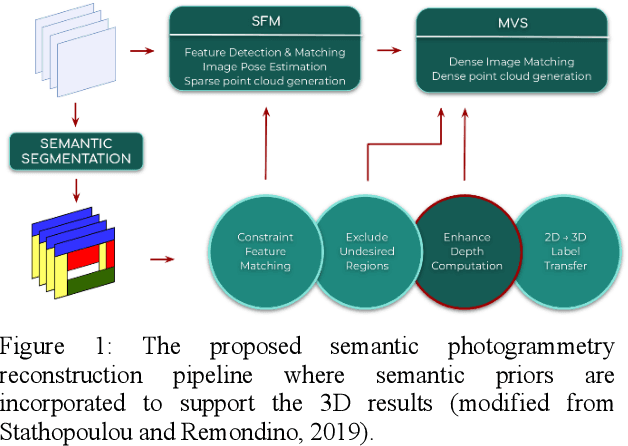
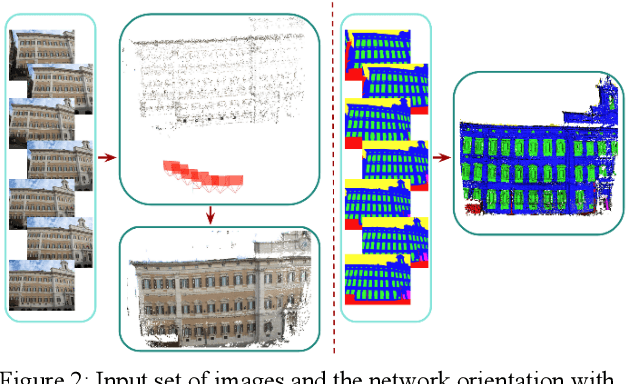
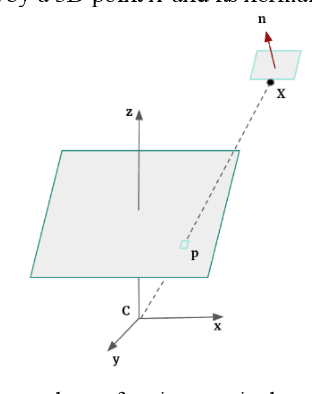

Patch-based stereo is nowadays a commonly used image-based technique for dense 3D reconstruction in large scale multi-view applications. The typical steps of such a pipeline can be summarized in stereo pair selection, depth map computation, depth map refinement and, finally, fusion in order to generate a complete and accurate representation of the scene in 3D. In this study, we aim to support the standard dense 3D reconstruction of scenes as implemented in the open source library OpenMVS by using semantic priors. To this end, during the depth map fusion step, along with the depth consistency check between depth maps of neighbouring views referring to the same part of the 3D scene, we impose extra semantic constraints in order to remove possible errors and selectively obtain segmented point clouds per label, boosting automation towards this direction. I n order to reassure semantic coherence between neighbouring views, additional semantic criterions can be considered, aiming to elim inate mismatches of pixels belonging in different classes.
Dynamic Spectral Residual Superpixels
Oct 10, 2019
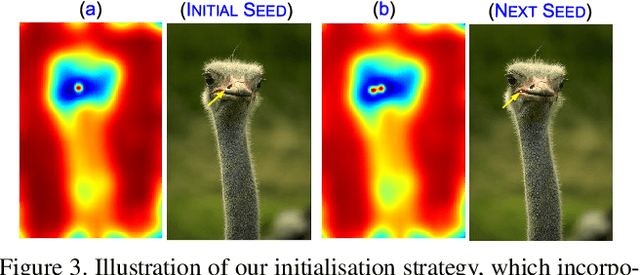
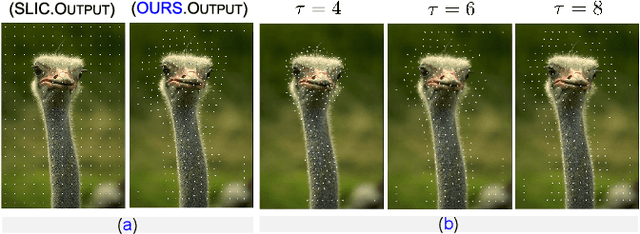

We consider the problem of segmenting an image into superpixels in the context of $k$-means clustering, in which we wish to decompose an image into local, homogeneous regions corresponding to the underlying objects. Our novel approach builds upon the widely used Simple Linear Iterative Clustering (SLIC), and incorporate a measure of objects' structure based on the spectral residual of an image. Based on this combination, we propose a modified initialisation scheme and search metric, which helps keeps fine-details. This combination leads to better adherence to object boundaries, while preventing unnecessary segmentation of large, uniform areas, while remaining computationally tractable in comparison to other methods. We demonstrate through numerical and visual experiments that our approach outperforms the state-of-the-art techniques.
Generative Guiding Block: Synthesizing Realistic Looking Variants Capable of Even Large Change Demands
Jul 02, 2019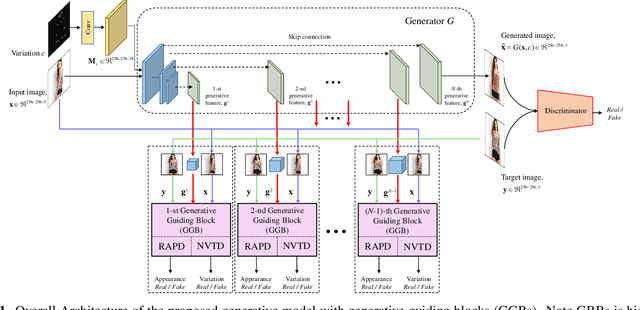
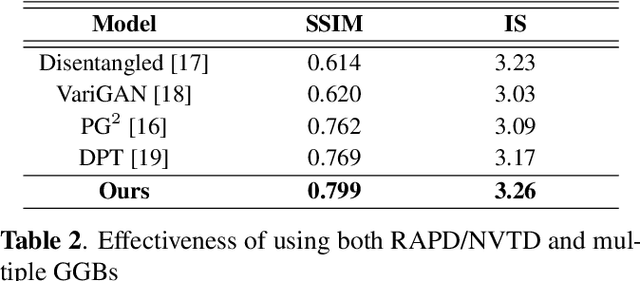
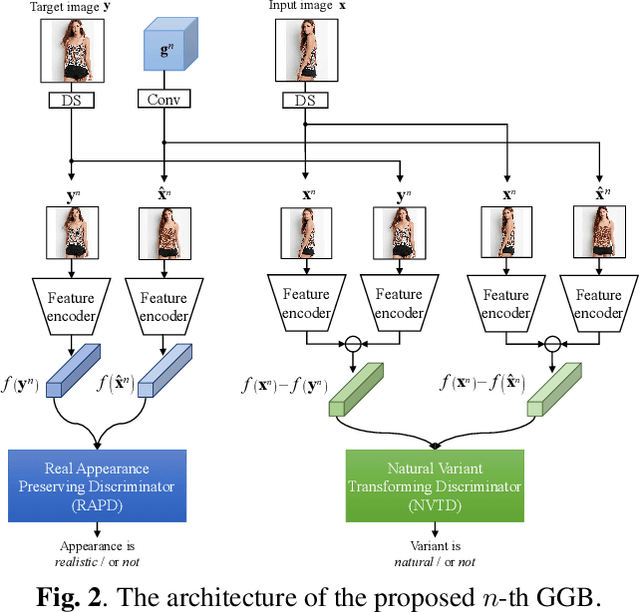
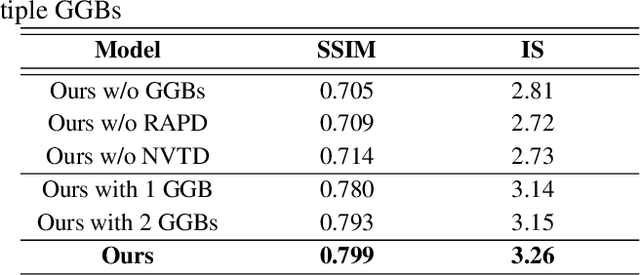
Realistic image synthesis is to generate an image that is perceptually indistinguishable from an actual image. Generating realistic looking images with large variations (e.g., large spatial deformations and large pose change), however, is very challenging. Handing large variations as well as preserving appearance needs to be taken into account in the realistic looking image generation. In this paper, we propose a novel realistic looking image synthesis method, especially in large change demands. To do that, we devise generative guiding blocks. The proposed generative guiding block includes realistic appearance preserving discriminator and naturalistic variation transforming discriminator. By taking the proposed generative guiding blocks into generative model, the latent features at the layer of generative model are enhanced to synthesize both realistic looking- and target variation- image. With qualitative and quantitative evaluation in experiments, we demonstrated the effectiveness of the proposed generative guiding blocks, compared to the state-of-the-arts.
Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints
Jan 08, 2020
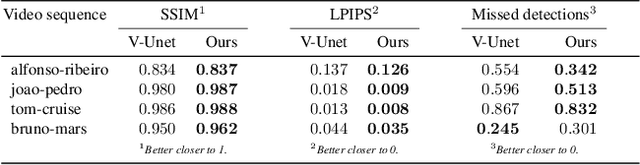

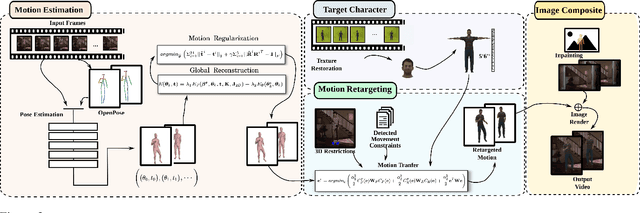
Creating plausible virtual actors from images of real actors remains one of the key challenges in computer vision and computer graphics. Marker-less human motion estimation and shape modeling from images in the wild bring this challenge to the fore. Although the recent advances on view synthesis and image-to-image translation, currently available formulations are limited to transfer solely style and do not take into account the character's motion and shape, which are by nature intermingled to produce plausible human forms. In this paper, we propose a unifying formulation for transferring appearance and retargeting human motion from monocular videos that regards all these aspects. Our method is composed of four main components and synthesizes new videos of people in a different context where they were initially recorded. Differently from recent appearance transferring methods, our approach takes into account body shape, appearance and motion constraints. The evaluation is performed with several experiments using publicly available real videos containing hard conditions. Our method is able to transfer both human motion and appearance outperforming state-of-the-art methods, while preserving specific features of the motion that must be maintained (e.g., feet touching the floor, hands touching a particular object) and holding the best visual quality and appearance metrics such as Structural Similarity (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS).
Multiview Chirality
Mar 19, 2020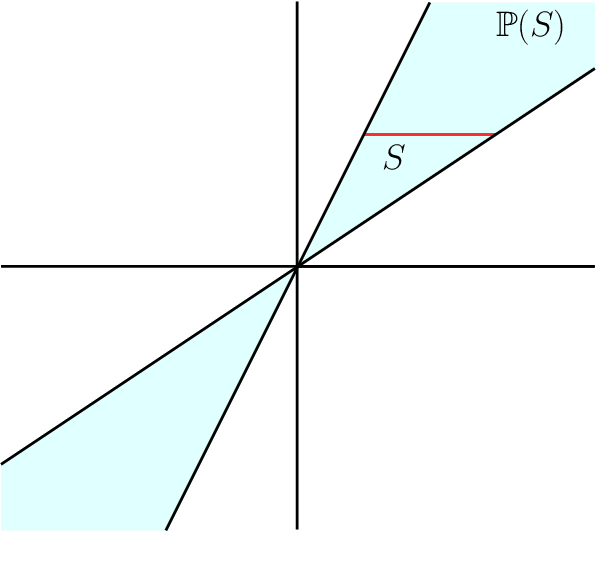
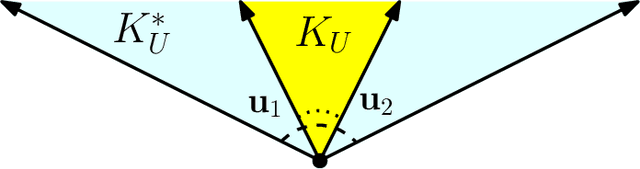
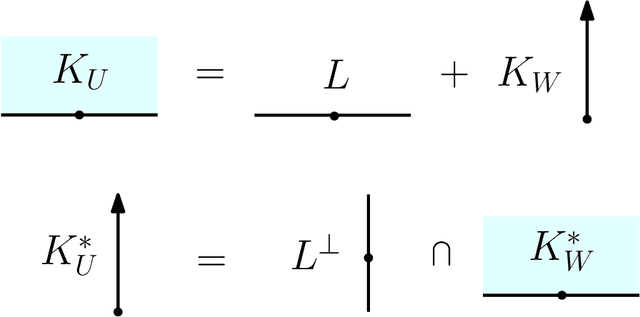
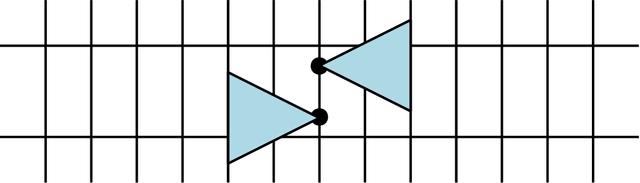
Given an arrangement of cameras $\mathcal{A} = \{A_1,\dots, A_m\}$, the chiral domain of $\mathcal{A}$ is the subset of $\mathbb{P}^3$ that lies in front it. It is a generalization of the classical definition of chirality. We give an algebraic description of this set and use it to generalize Hartley's theory of chiral reconstruction to $m \ge 2$ views and derive a chiral version of Triggs' Joint Image.
PatchPerPix for Instance Segmentation
Jan 21, 2020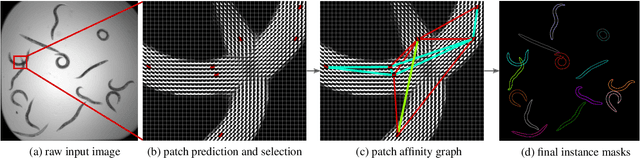
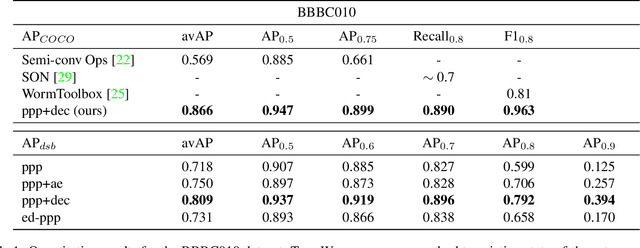
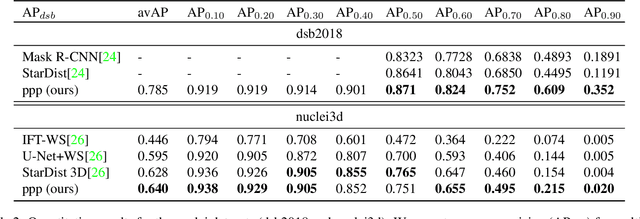
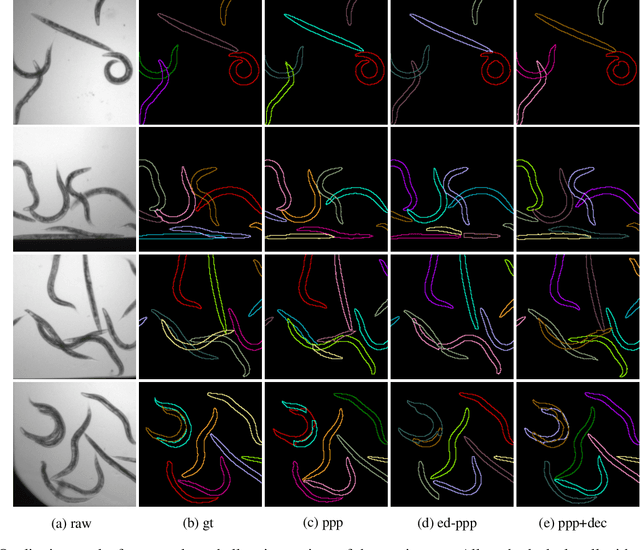
In this paper we present a novel method for proposal free instance segmentation that can handle sophisticated object shapes that span large parts of an image and form dense object clusters with crossovers. Our method is based on predicting dense local shape descriptors, which we assemble to form instances. All instances are assembled simultaneously in one go. To our knowledge, our method is the first non-iterative method that guarantees instances to be composed of learnt shape patches. We evaluate our method on a variety of data domains, where it defines the new state of the art on two challenging benchmarks, namely the ISBI 2012 EM segmentation benchmark, and the BBBC010 C. elegans dataset. We show furthermore that our method performs well also on 3d image data, and can handle even extreme cases of complex shape clusters.
Instance Segmentation of Visible and Occluded Regions for Finding and Picking Target from a Pile of Objects
Jan 21, 2020



We present a robotic system for picking a target from a pile of objects that is capable of finding and grasping the target object by removing obstacles in the appropriate order. The fundamental idea is to segment instances with both visible and occluded masks, which we call `instance occlusion segmentation'. To achieve this, we extend an existing instance segmentation model with a novel `relook' architecture, in which the model explicitly learns the inter-instance relationship. Also, by using image synthesis, we make the system capable of handling new objects without human annotations. The experimental results show the effectiveness of the relook architecture when compared with a conventional model and of the image synthesis when compared to a human-annotated dataset. We also demonstrate the capability of our system to achieve picking a target in a cluttered environment with a real robot.
Face Image Classification by Pooling Raw Features
Sep 17, 2014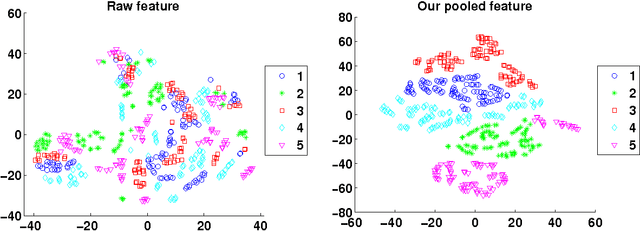
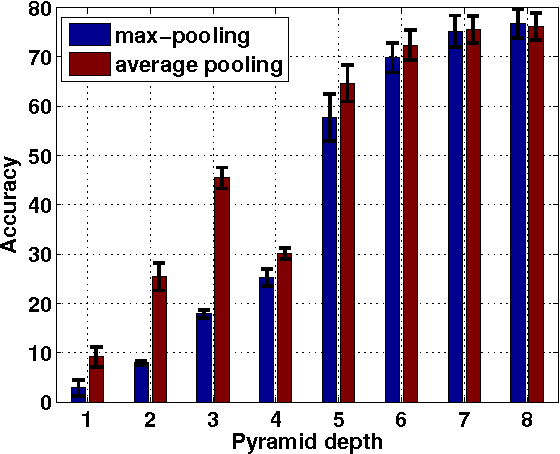
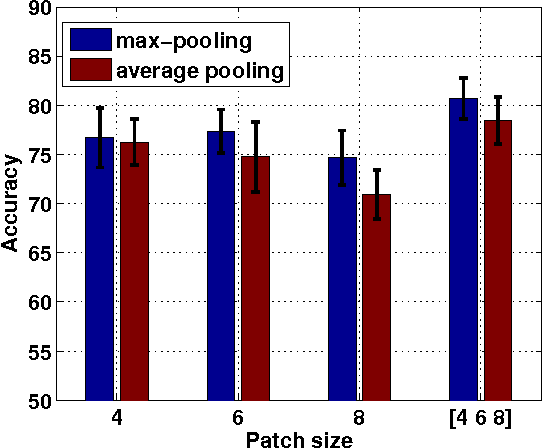
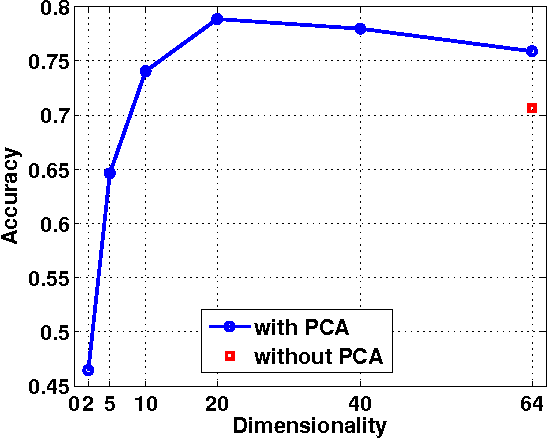
We propose a very simple, efficient yet surprisingly effective feature extraction method for face recognition (about 20 lines of Matlab code), which is mainly inspired by spatial pyramid pooling in generic image classification. We show that features formed by simply pooling local patches over a multi-level pyramid, coupled with a linear classifier, can significantly outperform most recent face recognition methods. The simplicity of our feature extraction procedure is demonstrated by the fact that no learning is involved (except PCA whitening). We show that, multi-level spatial pooling and dense extraction of multi-scale patches play critical roles in face image classification. The extracted facial features can capture strong structural information of individual faces with no label information being used. We also find that, pre-processing on local image patches such as contrast normalization can have an important impact on the classification accuracy. In particular, on the challenging face recognition datasets of FERET and LFW-a, our method improves previous best results by more than 10% and 20%, respectively.
Smart Hypothesis Generation for Efficient and Robust Room Layout Estimation
Oct 27, 2019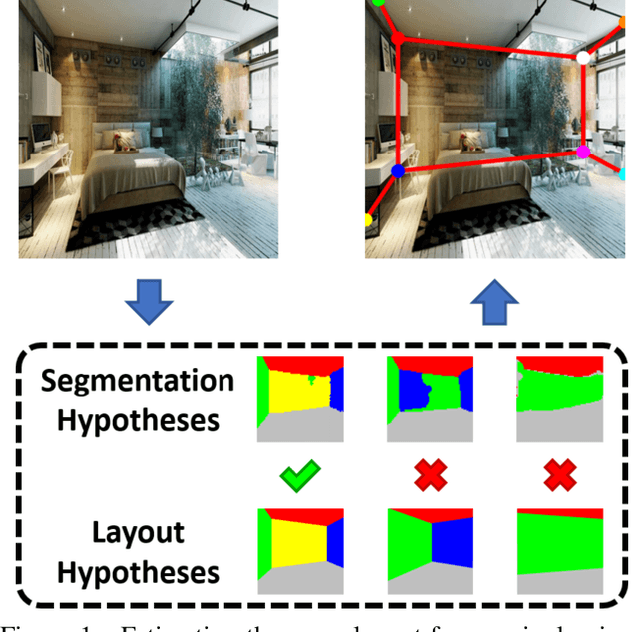
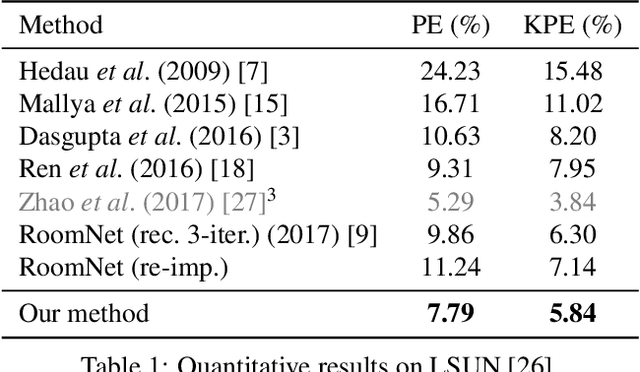

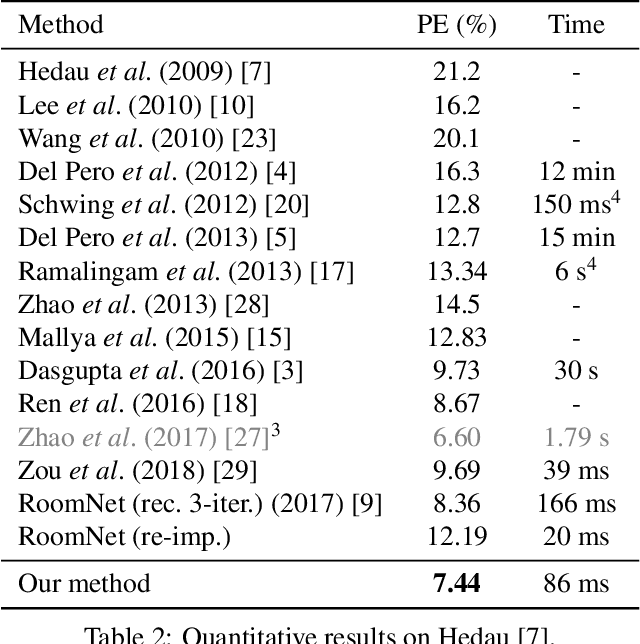
We propose a novel method to efficiently estimate the spatial layout of a room from a single monocular RGB image. As existing approaches based on low-level feature extraction, followed by a vanishing point estimation are very slow and often unreliable in realistic scenarios, we build on semantic segmentation of the input image. To obtain better segmentations, we introduce a robust, accurate and very efficient hypothesize-and-test scheme. The key idea is to use three segmentation hypotheses, each based on a different number of visible walls. For each hypothesis, we predict the image locations of the room corners and select the hypothesis for which the layout estimated from the room corners is consistent with the segmentation. We demonstrate the efficiency and robustness of our method on three challenging benchmark datasets, where we significantly outperform the state-of-the-art.