 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints
Jan 08, 2020

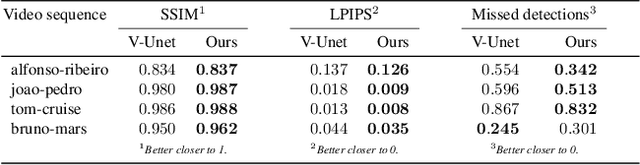

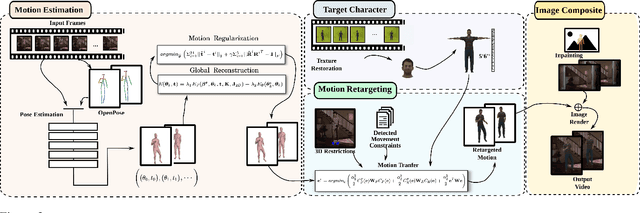
Creating plausible virtual actors from images of real actors remains one of the key challenges in computer vision and computer graphics. Marker-less human motion estimation and shape modeling from images in the wild bring this challenge to the fore. Although the recent advances on view synthesis and image-to-image translation, currently available formulations are limited to transfer solely style and do not take into account the character's motion and shape, which are by nature intermingled to produce plausible human forms. In this paper, we propose a unifying formulation for transferring appearance and retargeting human motion from monocular videos that regards all these aspects. Our method is composed of four main components and synthesizes new videos of people in a different context where they were initially recorded. Differently from recent appearance transferring methods, our approach takes into account body shape, appearance and motion constraints. The evaluation is performed with several experiments using publicly available real videos containing hard conditions. Our method is able to transfer both human motion and appearance outperforming state-of-the-art methods, while preserving specific features of the motion that must be maintained (e.g., feet touching the floor, hands touching a particular object) and holding the best visual quality and appearance metrics such as Structural Similarity (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS).
Removing Dynamic Objects for Static Scene Reconstruction using Light Fields
Mar 24, 2020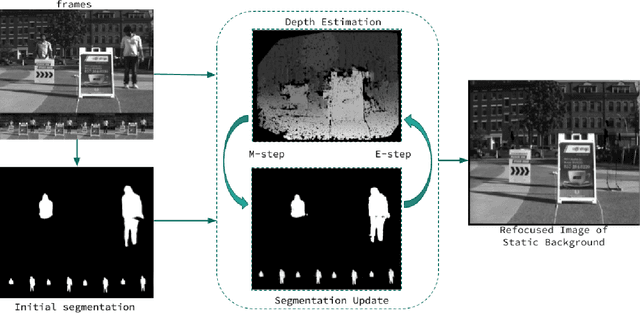
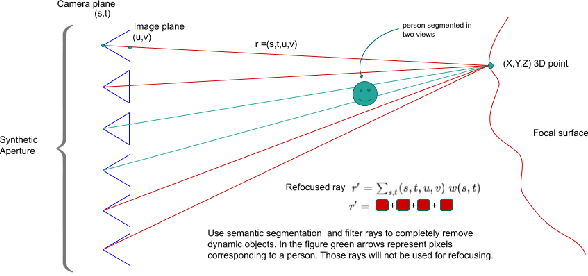
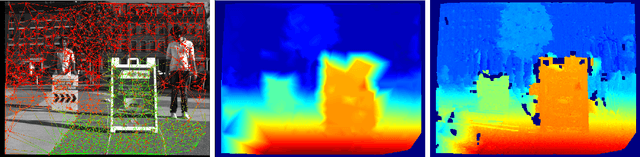
There is a general expectation that robots should operate in environments that consist of static and dynamic entities including people, furniture and automobiles. These dynamic environments pose challenges to visual simultaneous localization and mapping (SLAM) algorithms by introducing errors into the front-end. Light fields provide one possible method for addressing such problems by capturing a more complete visual information of a scene. In contrast to a single ray from a perspective camera, Light Fields capture a bundle of light rays emerging from a single point in space, allowing us to see through dynamic objects by refocusing past them. In this paper we present a method to synthesize a refocused image of the static background in the presence of dynamic objects that uses a light-field acquired with a linear camera array. We simultaneously estimate both the depth and the refocused image of the static scene using semantic segmentation for detecting dynamic objects in a single time step. This eliminates the need for initializing a static map . The algorithm is parallelizable and is implemented on GPU allowing us execute it at close to real time speeds. We demonstrate the effectiveness of our method on real-world data acquired using a small robot with a five camera array.
BWCFace: Open-set Face Recognition using Body-worn Camera
Sep 24, 2020
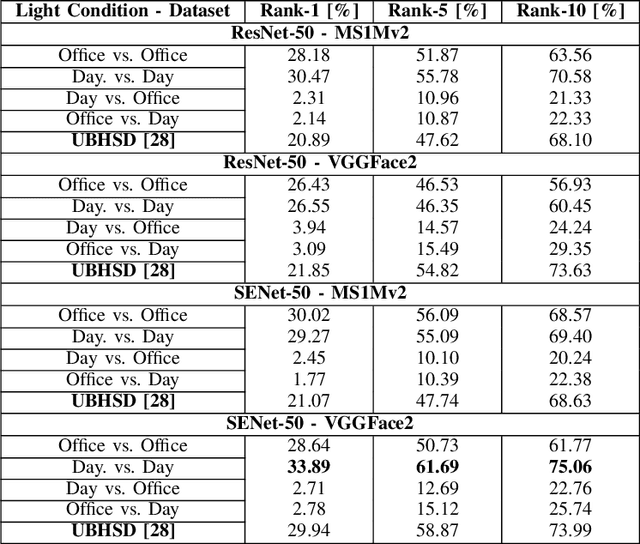
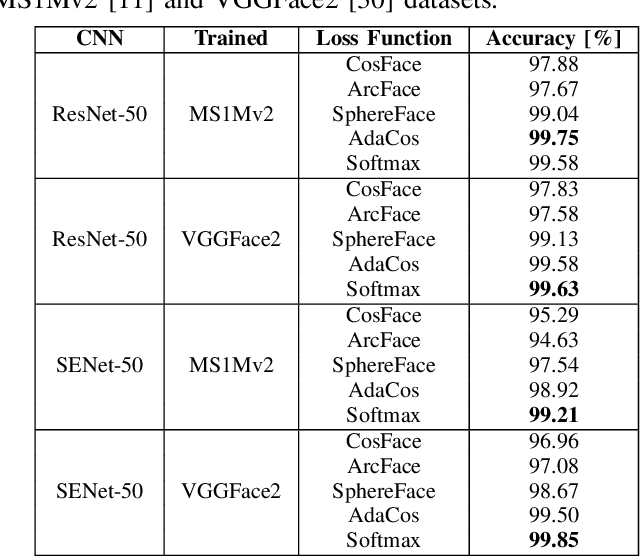
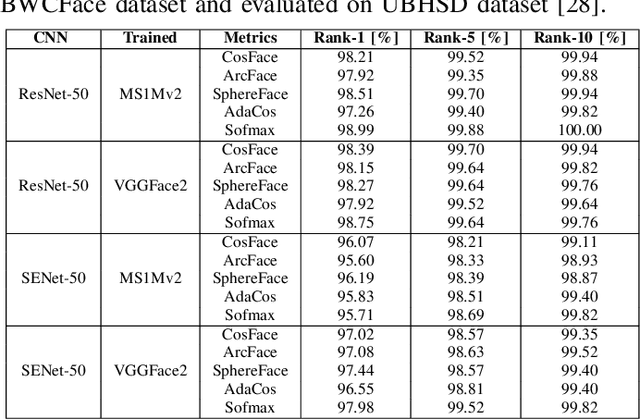
With computer vision reaching an inflection point in the past decade, face recognition technology has become pervasive in policing, intelligence gathering, and consumer applications. Recently, face recognition technology has been deployed on bodyworn cameras to keep officers safe, enabling situational awareness and providing evidence for trial. However, limited academic research has been conducted on this topic using traditional techniques on datasets with small sample size. This paper aims to bridge the gap in the state-of-the-art face recognition using bodyworn cameras (BWC). To this aim, the contribution of this work is two-fold: (1) collection of a dataset called BWCFace consisting of a total of 178K facial images of 132 subjects captured using the body-worn camera in in-door and daylight conditions, and (2) open-set evaluation of the latest deep-learning-based Convolutional Neural Network (CNN) architectures combined with five different loss functions for face identification, on the collected dataset. Experimental results on our BWCFace dataset suggest a maximum of 33.89% Rank-1 accuracy obtained when facial features are extracted using SENet-50 trained on a large scale VGGFace2 facial image dataset. However, performance improved up to a maximum of 99.00% Rank-1 accuracy when pretrained CNN models are fine-tuned on a subset of identities in our BWCFace dataset. Equivalent performances were obtained across body-worn camera sensor models used in existing face datasets. The collected BWCFace dataset and the pretrained/ fine-tuned algorithms are publicly available to promote further research and development in this area. A downloadable link of this dataset and the algorithms is available by contacting the authors.
Vulnerability of deep neural networks for detecting COVID-19 cases from chest X-ray images to universal adversarial attacks
May 22, 2020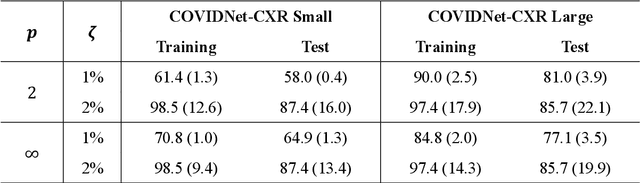
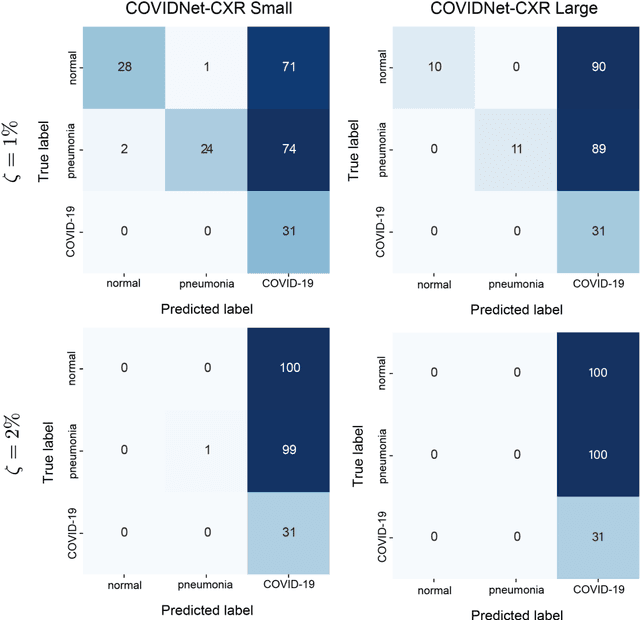
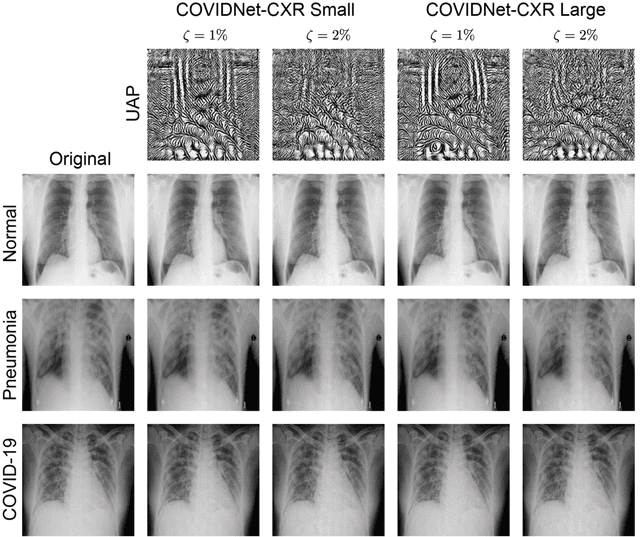
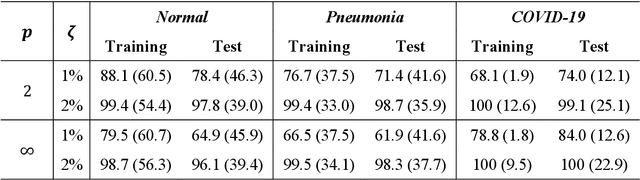
Under the epidemic of the novel coronavirus disease 2019 (COVID-19), chest X-ray computed tomography imaging is being used for effectively screening COVID-19 patients. The development of computer-aided systems based on deep neural networks (DNNs) has been advanced, to rapidly and accurately detect COVID-19 cases, because the need for expert radiologists, who are limited in number, forms a bottleneck for the screening. However, so far, the vulnerability of DNN-based systems has been poorly evaluated, although DNNs are vulnerable to a single perturbation, called universal adversarial perturbation (UAP), which can induce DNN failure in most classification tasks. Thus, we focus on representative DNN models for detecting COVID-19 cases from chest X-ray images and evaluate their vulnerability to UAPs generated using simple iterative algorithms. We consider nontargeted UAPs, which cause a task failure resulting in an input being assigned an incorrect label, and targeted UAPs, which cause the DNN to classify an input into a specific class. The results demonstrate that the models are vulnerable to nontargeted and targeted UAPs, even in case of small UAPs. In particular, 2% norm of the UPAs to the average norm of an image in the image dataset achieves >85% and >90% success rates for the nontargeted and targeted attacks, respectively. Due to the nontargeted UAPs, the DNN models judge most chest X-ray images as COVID-19 cases. The targeted UAPs make the DNN models classify most chest X-ray images into a given target class. The results indicate that careful consideration is required in practical applications of DNNs to COVID-19 diagnosis; in particular, they emphasize the need for strategies to address security concerns. As an example, we show that iterative fine-tuning of the DNN models using UAPs improves the robustness of the DNN models against UAPs.
Deep Multi-Modal Image Correspondence Learning
Dec 05, 2016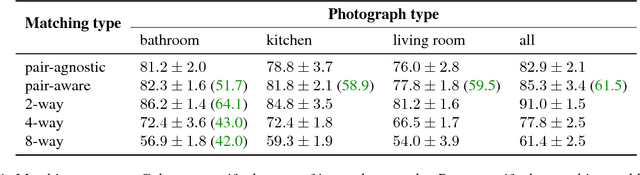
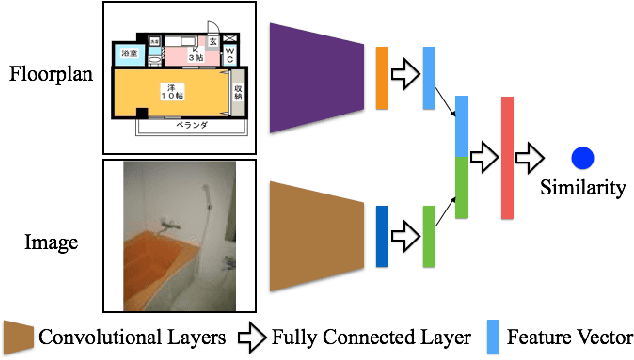
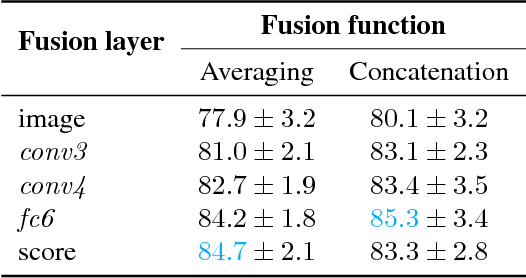
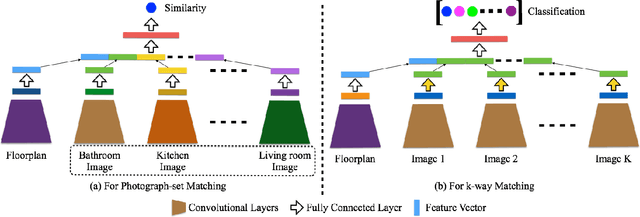
Inference of correspondences between images from different modalities is an extremely important perceptual ability that enables humans to understand and recognize cross-modal concepts. In this paper, we consider an instance of this problem that involves matching photographs of building interiors with their corresponding floorplan. This is a particularly challenging problem because a floorplan, as a stylized architectural drawing, is very different in appearance from a color photograph. Furthermore, individual photographs by themselves depict only a part of a floorplan (e.g., kitchen, bathroom, and living room). We propose the use of a number of different neural network architectures for this task, which are trained and evaluated on a novel large-scale dataset of 5 million floorplan images and 80 million associated photographs. Experimental evaluation reveals that our neural network architectures are able to identify visual cues that result in reliable matches across these two quite different modalities. In fact, the trained networks are able to even outperform human subjects in several challenging image matching problems. Our result implies that neural networks are effective at perceptual tasks that require long periods of reasoning even for humans to solve.
Wavelets to the Rescue: Improving Sample Quality of Latent Variable Deep Generative Models
Oct 26, 2019

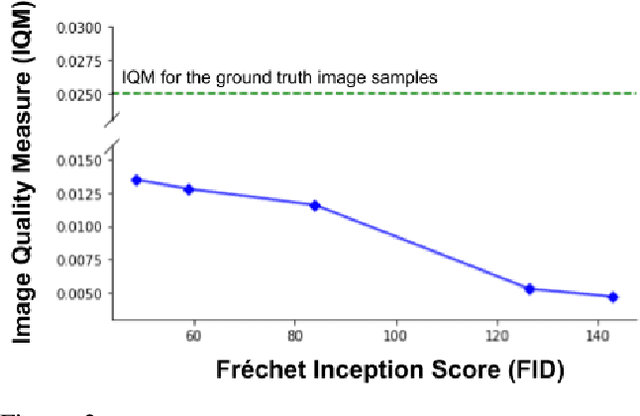
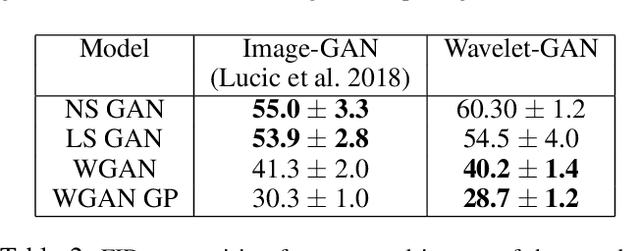
Variational Autoencoders (VAE) are probabilistic deep generative models underpinned by elegant theory, stable training processes, and meaningful manifold representations. However, they produce blurry images due to a lack of explicit emphasis over high-frequency textural details of the images, and the difficulty to directly model the complex joint probability distribution over the high-dimensional image space. In this work, we approach these two challenges with a novel wavelet space VAE that uses the decoder to model the images in the wavelet coefficient space. This enables the VAE to emphasize over high-frequency components within an image obtained via wavelet decomposition. Additionally, by decomposing the complex function of generating high-dimensional images into inverse wavelet transformation and generation of wavelet coefficients, the latter becomes simpler to model by the VAE. We empirically validate that deep generative models operating in the wavelet space can generate images of higher quality than the image (RGB) space counterparts. Quantitatively, on benchmark natural image datasets, we achieve consistently better FID scores than VAE based architectures and competitive FID scores with a variety of GAN models for the same architectural and experimental setup. Furthermore, the proposed wavelet-based generative model retains desirable attributes like disentangled and informative latent representation without losing the quality in the generated samples.
NanoFlow: Scalable Normalizing Flows with Sublinear Parameter Complexity
Jun 11, 2020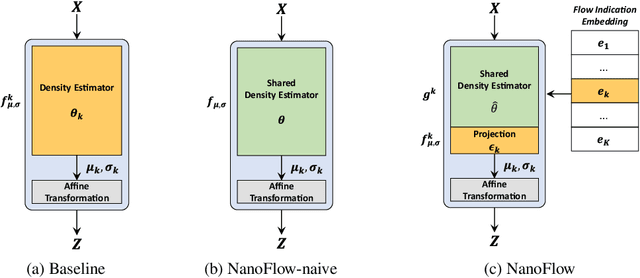
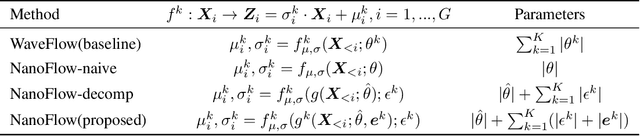
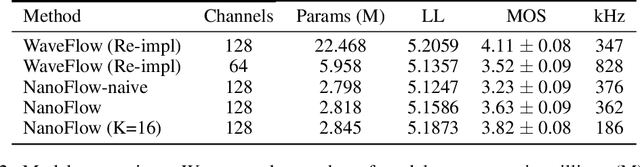
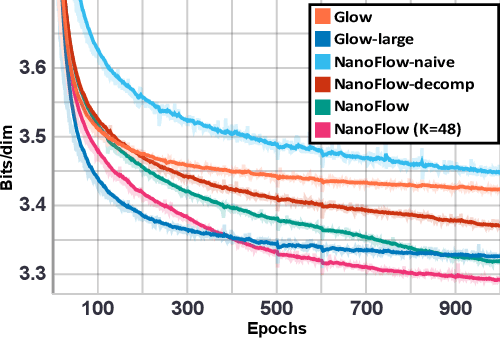
Normalizing flows (NFs) have become a prominent method for deep generative models that allow for an analytic probability density estimation and efficient synthesis. However, a flow-based network is considered to be inefficient in parameter complexity because of reduced expressiveness of bijective mapping, which renders the models prohibitively expensive in terms of parameters. We present an alternative of parameterization scheme, called NanoFlow, which uses a single neural density estimator to model multiple transformation stages. Hence, we propose an efficient parameter decomposition method and the concept of \textit{flow indication embedding}, which are key missing components that enable density estimation from a single neural network. Experiments performed on audio and image models confirm that our method provides a new parameter-efficient solution for scalable NFs with significantly sublinear parameter complexity.
Automatic identification of fossils and abiotic grains during carbonate microfacies analysis using deep convolutional neural networks
Sep 24, 2020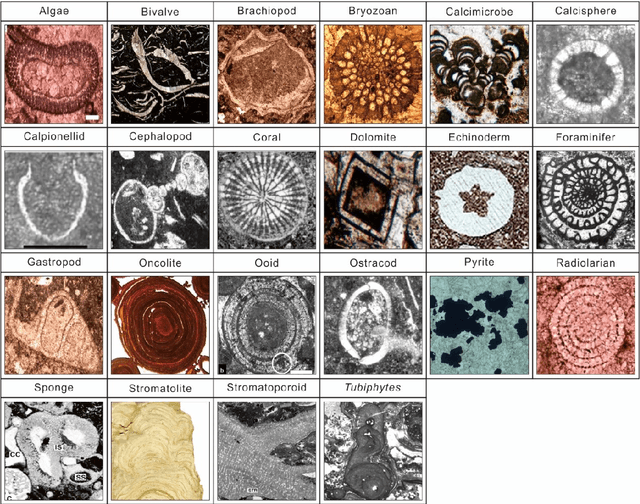
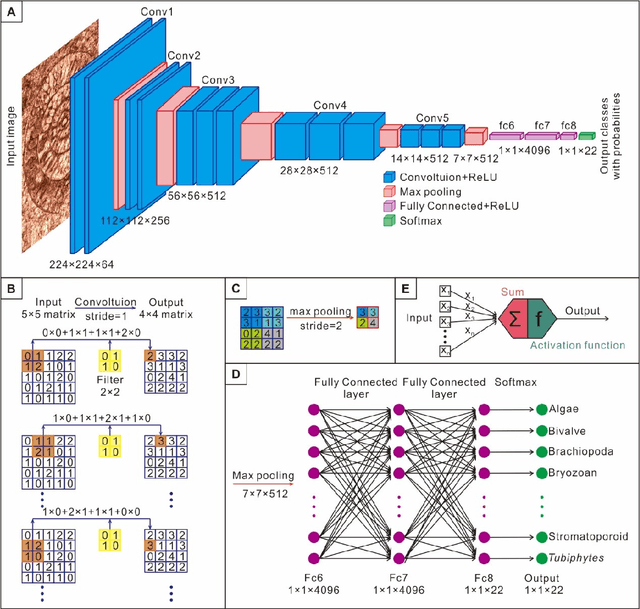
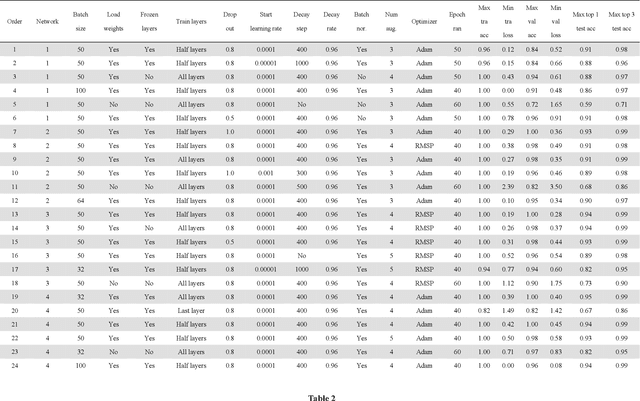
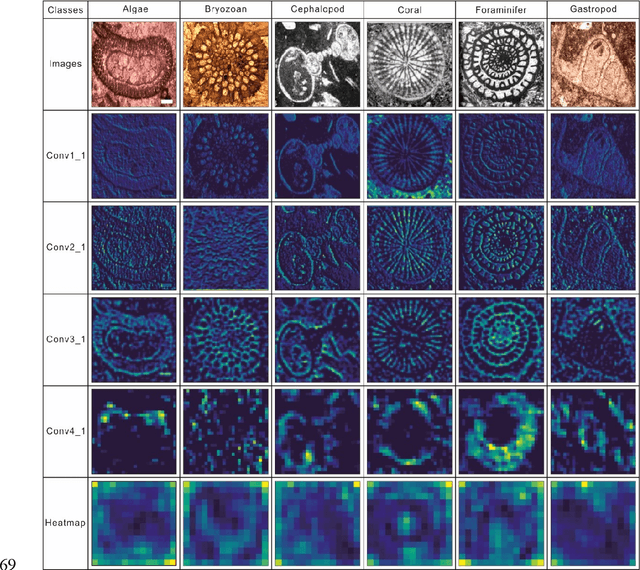
Petrographic analysis based on microfacies identification in thin sections is widely used in sedimentary environment interpretation and paleoecological reconstruction. Fossil recognition from microfacies is an essential procedure for petrographers to complete this task. Distinguishing the morphological and microstructural diversity of skeletal fragments requires extensive prior knowledge of fossil morphotypes in microfacies and long training sessions under the microscope. This requirement engenders certain challenges for sedimentologists and paleontologists, especially novices. However, a machine classifier can help address this challenge. We collected a microfacies image dataset comprising both public data from 1,149 references and our own materials (including a total of 30,815 images of 22 fossil and abiotic grain groups). We employed a high-performance workstation to implement four classic deep convolutional neural networks (DCNNs), which have proven to be highly efficient in computer vision over the last several years. Our framework uses a transfer learning technique, which reuses the pre-trained parameters that are trained on a larger ImageNet dataset as initialization for the network to achieve high accuracy with low computing costs. We obtained up to 95% of the top one and 99% of the top three test accuracies in the Inception ResNet v2 architecture. The machine classifier exhibited 0.99 precision on minerals, such as dolomite and pyrite. Although it had some difficulty on samples having similar morphologies, such as the bivalve, brachiopod, and ostracod, it nevertheless obtained 0.88 precision. Our machine learning framework demonstrated high accuracy with reproducibility and bias avoidance that was comparable to those of human classifiers. Its application can thus eliminate much of the tedious, manually intensive efforts by human experts conducting routine identification.
Using Genetic Algorithm To Evolve Cellular Automata In Performing Edge Detection
May 13, 2020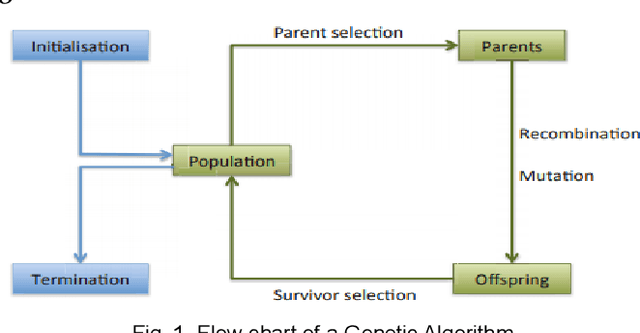

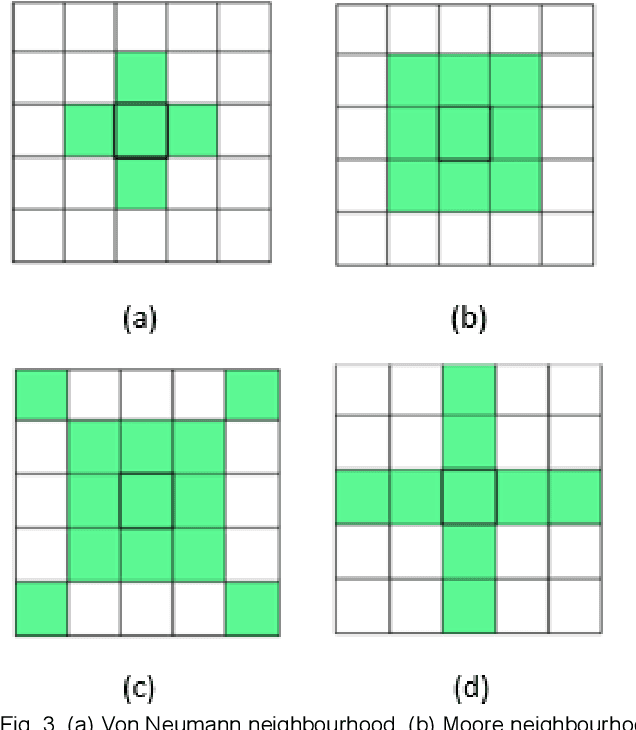

Cellular automata are discrete and computational models thatcan be shown as general models of complexity. They are used in varied applications to derive the generalized behavior of the presented model. In this paper we have took one such application. We have made an effort to perform edge detection on an image using genetic algorithm. The purpose and the intention here is to analyze the capability and performance of the suggested genetic algorithm. Genetic algorithms are used to depict or obtain a general solution of given problem. Using this feature of GA we have tried to evolve the cellular automata and shown that how with time it converges to the desired results.
PatchPerPix for Instance Segmentation
Jan 21, 2020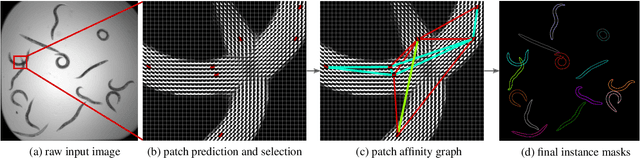
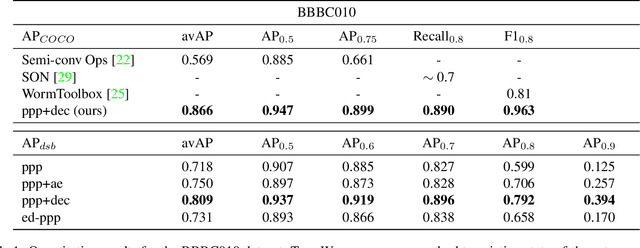
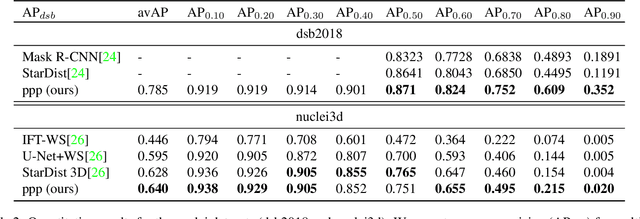
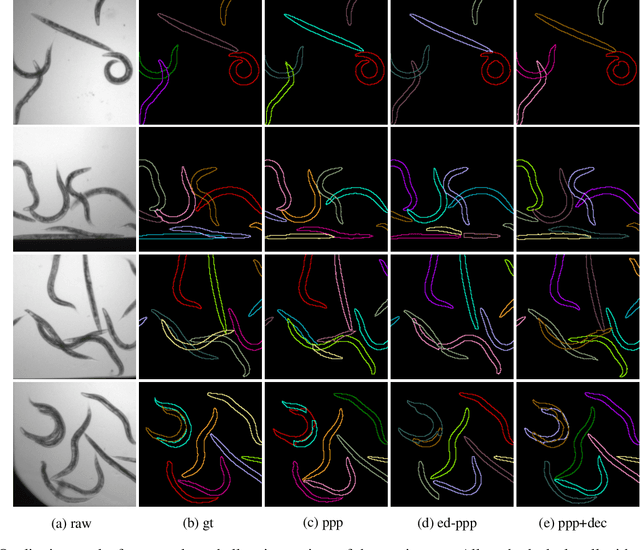
In this paper we present a novel method for proposal free instance segmentation that can handle sophisticated object shapes that span large parts of an image and form dense object clusters with crossovers. Our method is based on predicting dense local shape descriptors, which we assemble to form instances. All instances are assembled simultaneously in one go. To our knowledge, our method is the first non-iterative method that guarantees instances to be composed of learnt shape patches. We evaluate our method on a variety of data domains, where it defines the new state of the art on two challenging benchmarks, namely the ISBI 2012 EM segmentation benchmark, and the BBBC010 C. elegans dataset. We show furthermore that our method performs well also on 3d image data, and can handle even extreme cases of complex shape clusters.