 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PDO-eConvs: Partial Differential Operator Based Equivariant Convolutions
Jul 20, 2020
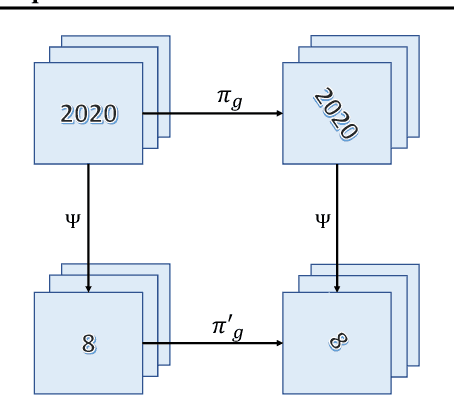
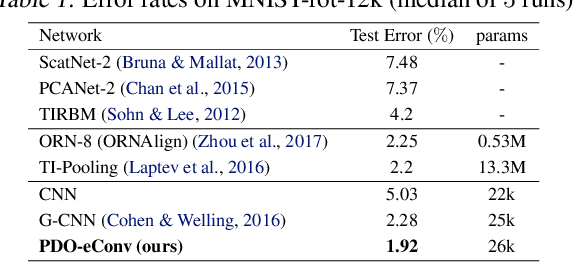

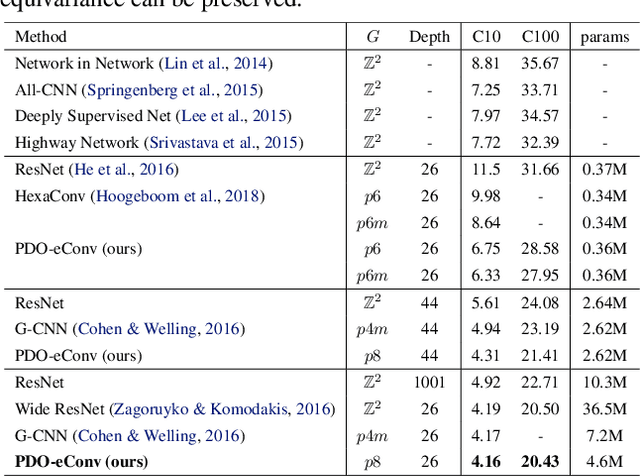
Recent research has shown that incorporating equivariance into neural network architectures is very helpful, and there have been some works investigating the equivariance of networks under group actions. However, as digital images and feature maps are on the discrete meshgrid, corresponding equivariance-preserving transformation groups are very limited. In this work, we deal with this issue from the connection between convolutions and partial differential operators (PDOs). In theory, assuming inputs to be smooth, we transform PDOs and propose a system which is equivariant to a much more general continuous group, the $n$-dimension Euclidean group. In implementation, we discretize the system using the numerical schemes of PDOs, deriving approximately equivariant convolutions (PDO-eConvs). Theoretically, the approximation error of PDO-eConvs is of the quadratic order. It is the first time that the error analysis is provided when the equivariance is approximate. Extensive experiments on rotated MNIST and natural image classification show that PDO-eConvs perform competitively yet use parameters much more efficiently. Particularly, compared with Wide ResNets, our methods result in better results using only 12.6% parameters.
The Relative Performance of Ensemble Methods with Deep Convolutional Neural Networks for Image Classification
Apr 05, 2017

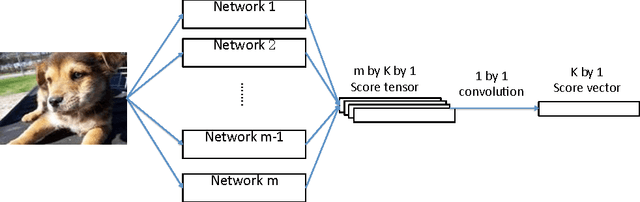
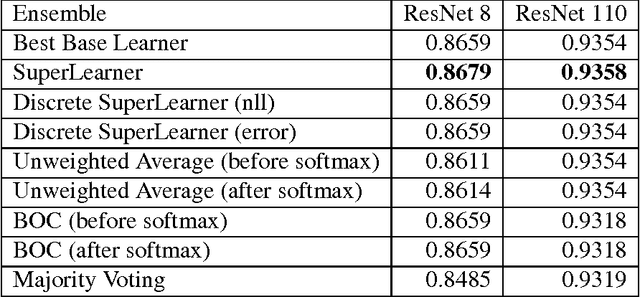
Artificial neural networks have been successfully applied to a variety of machine learning tasks, including image recognition, semantic segmentation, and machine translation. However, few studies fully investigated ensembles of artificial neural networks. In this work, we investigated multiple widely used ensemble methods, including unweighted averaging, majority voting, the Bayes Optimal Classifier, and the (discrete) Super Learner, for image recognition tasks, with deep neural networks as candidate algorithms. We designed several experiments, with the candidate algorithms being the same network structure with different model checkpoints within a single training process, networks with same structure but trained multiple times stochastically, and networks with different structure. In addition, we further studied the over-confidence phenomenon of the neural networks, as well as its impact on the ensemble methods. Across all of our experiments, the Super Learner achieved best performance among all the ensemble methods in this study.
YOLOff: You Only Learn Offsets for robust 6DoF object pose estimation
Feb 25, 2020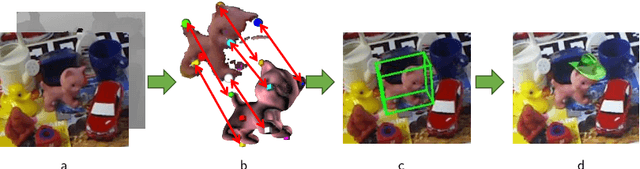

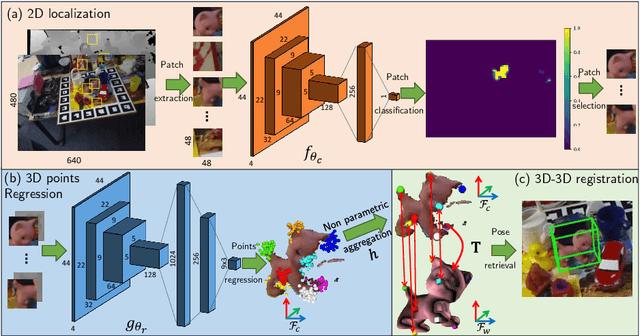

Estimating the 3D translation and orientation of an object is a challenging task that can be considered within augmented reality or robotic applications. In this paper, we propose a novel approach to perform 6 DoF object pose estimation from a single RGB-D image in cluttered scenes. We adopt an hybrid pipeline in two stages: data-driven and geometric respectively. The first data-driven step consists of a classification CNN to estimate the object 2D location in the image from local patches, followed by a regression CNN trained to predict the 3D location of a set of keypoints in the camera coordinate system. We robustly perform local voting to recover the location of each keypoint in the camera coordinate system. To extract the pose information, the geometric step consists in aligning the 3D points in the camera coordinate system with the corresponding 3D points in world coordinate system by minimizing a registration error, thus computing the pose. Our experiments on the standard dataset LineMod show that our approach more robust and accurate than state-of-the-art methods.
Vulnerability of deep neural networks for detecting COVID-19 cases from chest X-ray images to universal adversarial attacks
May 22, 2020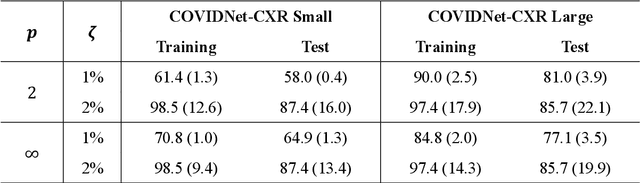
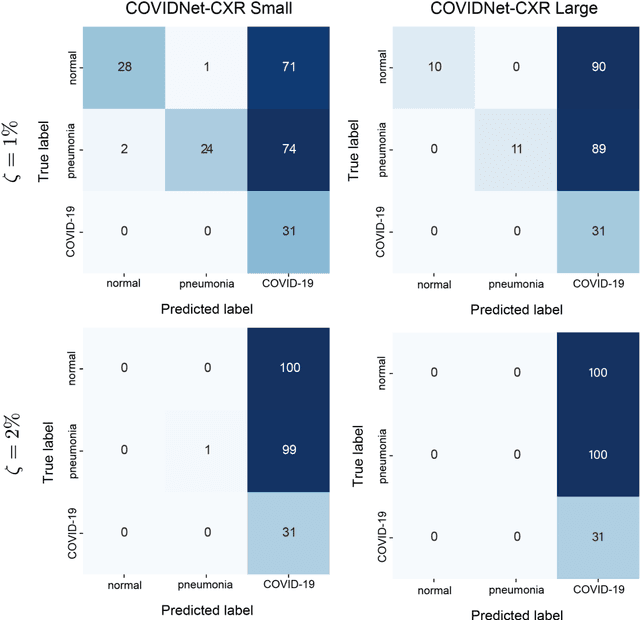
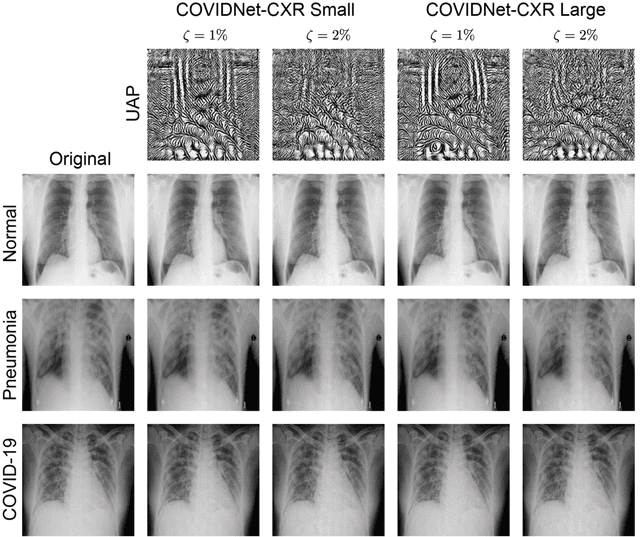
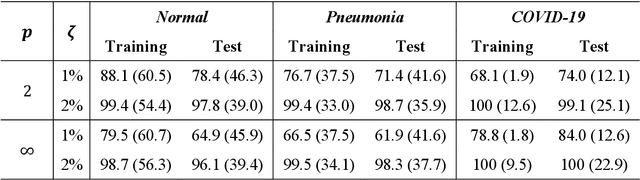
Under the epidemic of the novel coronavirus disease 2019 (COVID-19), chest X-ray computed tomography imaging is being used for effectively screening COVID-19 patients. The development of computer-aided systems based on deep neural networks (DNNs) has been advanced, to rapidly and accurately detect COVID-19 cases, because the need for expert radiologists, who are limited in number, forms a bottleneck for the screening. However, so far, the vulnerability of DNN-based systems has been poorly evaluated, although DNNs are vulnerable to a single perturbation, called universal adversarial perturbation (UAP), which can induce DNN failure in most classification tasks. Thus, we focus on representative DNN models for detecting COVID-19 cases from chest X-ray images and evaluate their vulnerability to UAPs generated using simple iterative algorithms. We consider nontargeted UAPs, which cause a task failure resulting in an input being assigned an incorrect label, and targeted UAPs, which cause the DNN to classify an input into a specific class. The results demonstrate that the models are vulnerable to nontargeted and targeted UAPs, even in case of small UAPs. In particular, 2% norm of the UPAs to the average norm of an image in the image dataset achieves >85% and >90% success rates for the nontargeted and targeted attacks, respectively. Due to the nontargeted UAPs, the DNN models judge most chest X-ray images as COVID-19 cases. The targeted UAPs make the DNN models classify most chest X-ray images into a given target class. The results indicate that careful consideration is required in practical applications of DNNs to COVID-19 diagnosis; in particular, they emphasize the need for strategies to address security concerns. As an example, we show that iterative fine-tuning of the DNN models using UAPs improves the robustness of the DNN models against UAPs.
Review of Artificial Intelligence Techniques in Imaging Data Acquisition, Segmentation and Diagnosis for COVID-19
Apr 07, 2020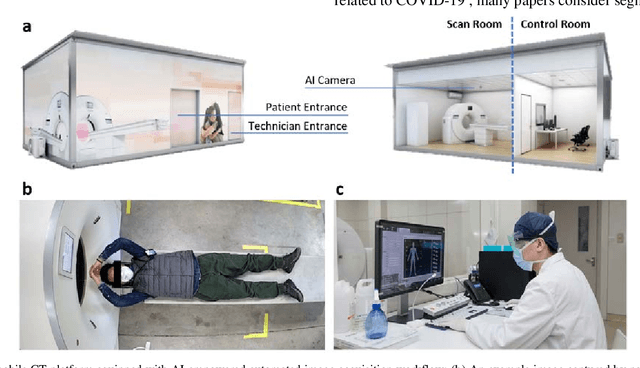
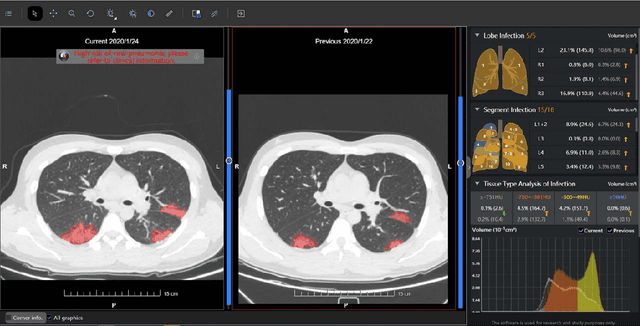
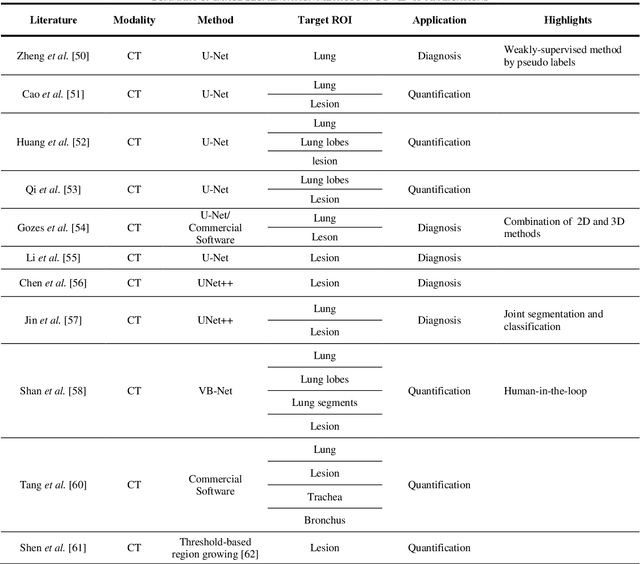
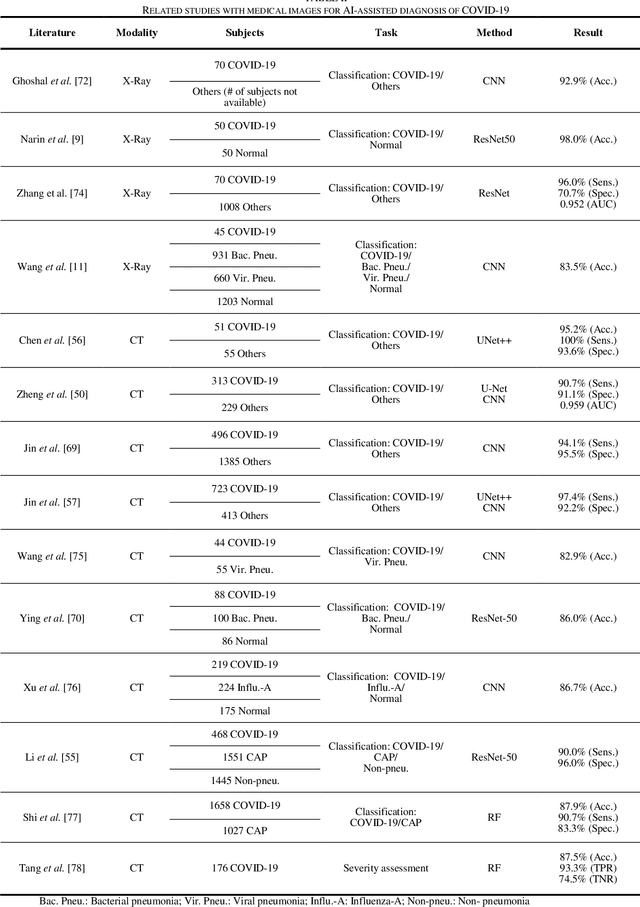
(This paper was submitted as an invited paper to IEEE Reviews in Biomedical Engineering on April 6, 2020.) The pandemic of coronavirus disease 2019 (COVID-19) is spreading all over the world. Medical imaging such as X-ray and computed tomography (CT) plays an essential role in the global fight against COVID-19, whereas the recently emerging artificial intelligence (AI) technologies further strengthen the power of the imaging tools and help medical specialists. We hereby review the rapid responses in the community of medical imaging (empowered by AI) toward COVID-19. For example, AI-empowered image acquisition can significantly help automate the scanning procedure and also reshape the workflow with minimal contact to patients, providing the best protection to the imaging technicians. Also, AI can improve work efficiency by accurate delination of infections in X-ray and CT images, facilitating subsequent quantification. Moreover, the computer-aided platforms help radiologists make clinical decisions, i.e., for disease diagnosis, tracking, and prognosis. In this review paper, we thus cover the entire pipeline of medical imaging and analysis techniques involved with COVID-19, including image acquisition, segmentation, diagnosis, and follow-up. We particularly focus on the integration of AI with X-ray and CT, both of which are widely used in the frontline hospitals, in order to depict the latest progress of medical imaging and radiology fighting against COVID-19.
Two-stage Discriminative Re-ranking for Large-scale Landmark Retrieval
Mar 25, 2020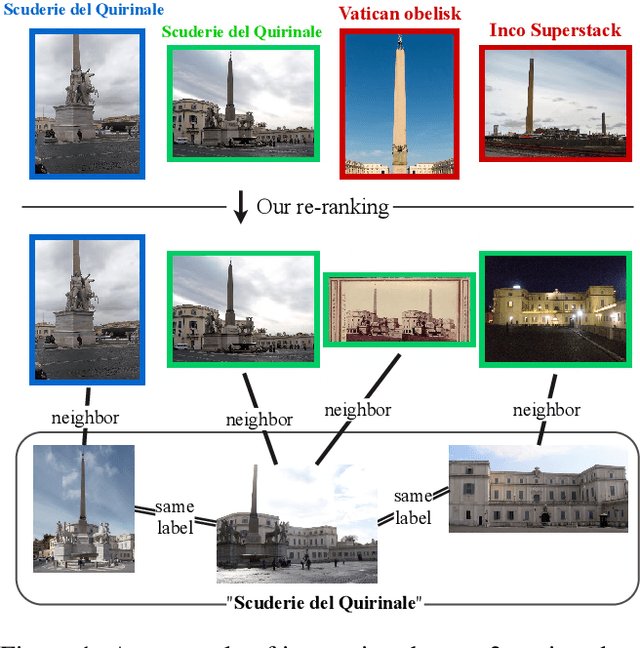
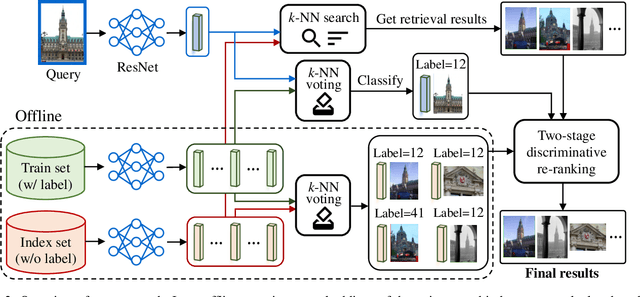
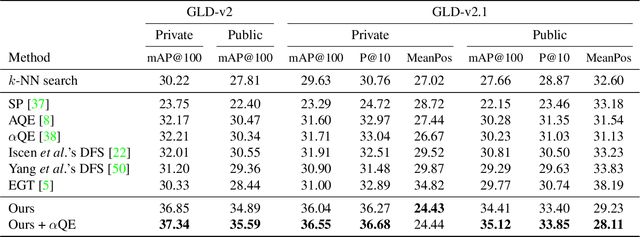
We propose an efficient pipeline for large-scale landmark image retrieval that addresses the diversity of the dataset through two-stage discriminative re-ranking. Our approach is based on embedding the images in a feature-space using a convolutional neural network trained with a cosine softmax loss. Due to the variance of the images, which include extreme viewpoint changes such as having to retrieve images of the exterior of a landmark from images of the interior, this is very challenging for approaches based exclusively on visual similarity. Our proposed re-ranking approach improves the results in two steps: in the sort-step, $k$-nearest neighbor search with soft-voting to sort the retrieved results based on their label similarity to the query images, and in the insert-step, we add additional samples from the dataset that were not retrieved by image-similarity. This approach allows overcoming the low visual diversity in retrieved images. In-depth experimental results show that the proposed approach significantly outperforms existing approaches on the challenging Google Landmarks Datasets. Using our methods, we achieved 1st place in the Google Landmark Retrieval 2019 challenge and 3rd place in the Google Landmark Recognition 2019 challenge on Kaggle. Our code is publicly available here: \url{https://github.com/lyakaap/Landmark2019-1st-and-3rd-Place-Solution}
NanoFlow: Scalable Normalizing Flows with Sublinear Parameter Complexity
Jun 11, 2020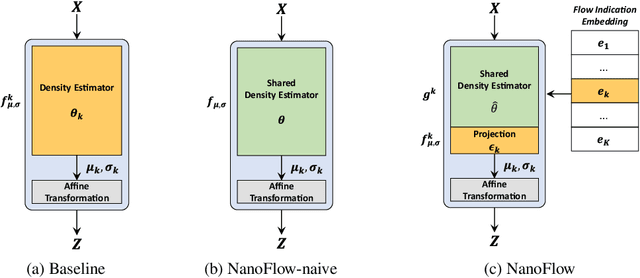
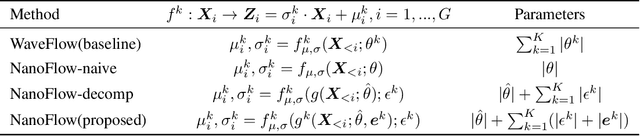
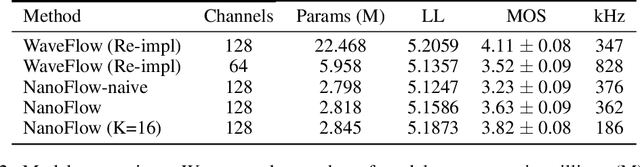
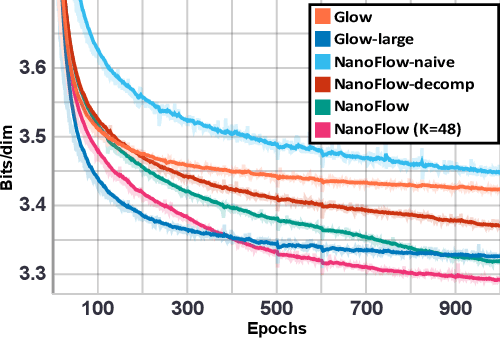
Normalizing flows (NFs) have become a prominent method for deep generative models that allow for an analytic probability density estimation and efficient synthesis. However, a flow-based network is considered to be inefficient in parameter complexity because of reduced expressiveness of bijective mapping, which renders the models prohibitively expensive in terms of parameters. We present an alternative of parameterization scheme, called NanoFlow, which uses a single neural density estimator to model multiple transformation stages. Hence, we propose an efficient parameter decomposition method and the concept of \textit{flow indication embedding}, which are key missing components that enable density estimation from a single neural network. Experiments performed on audio and image models confirm that our method provides a new parameter-efficient solution for scalable NFs with significantly sublinear parameter complexity.
Automatic Image De-fencing System
Oct 21, 2016
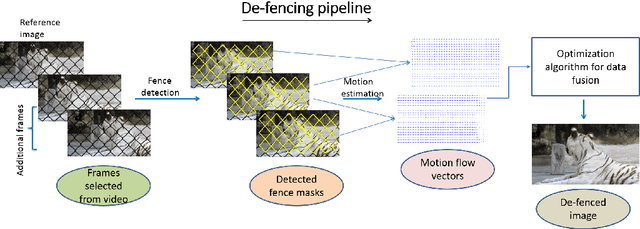


Tourists and Wild-life photographers are often hindered in capturing their cherished images or videos by a fence that limits accessibility to the scene of interest. The situation has been exacerbated by growing concerns of security at public places and a need exists to provide a tool that can be used for post-processing such fenced videos to produce a de-fenced image. There are several challenges in this problem, we identify them as Robust detection of fence/occlusions and Estimating pixel motion of background scenes and Filling in the fence/occlusions by utilizing information in multiple frames of the input video. In this work, we aim to build an automatic post-processing tool that can efficiently rid the input video of occlusion artifacts like fences. Our work is distinguished by two major contributions. The first is the introduction of learning based technique to detect the fences patterns with complicated backgrounds. The second is the formulation of objective function and further minimization through loopy belief propagation to fill-in the fence pixels. We observe that grids of Histogram of oriented gradients descriptor using Support vector machines based classifier significantly outperforms detection accuracy of texels in a lattice. We present results of experiments using several real-world videos to demonstrate the effectiveness of the proposed fence detection and de-fencing algorithm.
Online Invariance Selection for Local Feature Descriptors
Jul 20, 2020
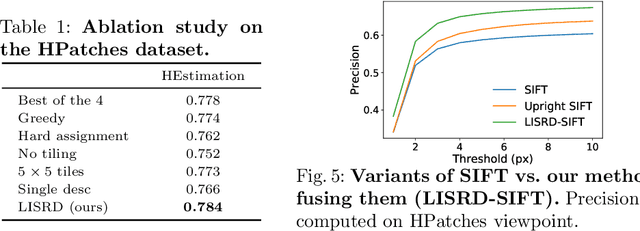
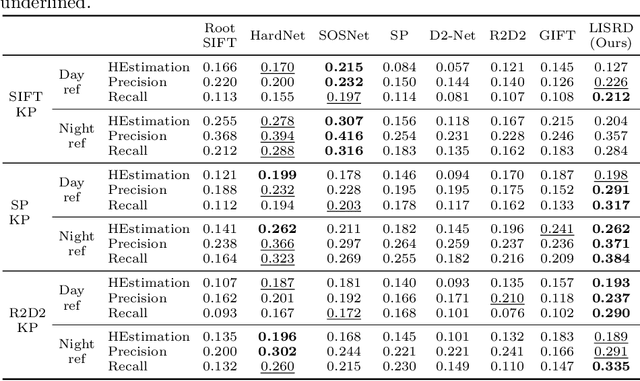
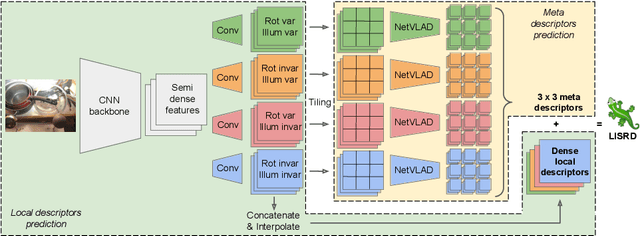
To be invariant, or not to be invariant: that is the question formulated in this work about local descriptors. A limitation of current feature descriptors is the trade-off between generalization and discriminative power: more invariance means less informative descriptors. We propose to overcome this limitation with a disentanglement of invariance in local descriptors and with an online selection of the most appropriate invariance given the context. Our framework consists in a joint learning of multiple local descriptors with different levels of invariance and of meta descriptors encoding the regional variations of an image. The similarity of these meta descriptors across images is used to select the right invariance when matching the local descriptors. Our approach, named Local Invariance Selection at Runtime for Descriptors (LISRD), enables descriptors to adapt to adverse changes in images, while remaining discriminative when invariance is not required. We demonstrate that our method can boost the performance of current descriptors and outperforms state-of-the-art descriptors in several matching tasks, when evaluated on challenging datasets with day-night illumination as well as viewpoint changes.
Lesion Mask-based Simultaneous Synthesis of Anatomic and MolecularMR Images using a GAN
Jul 05, 2020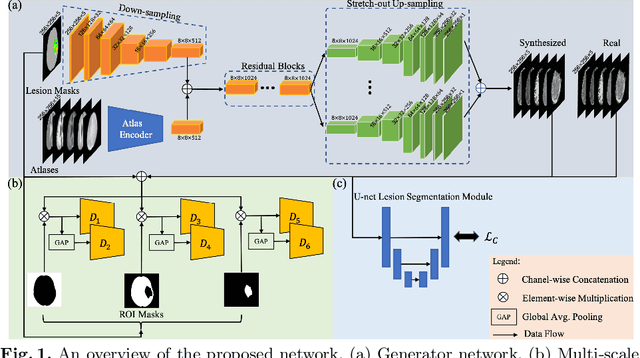

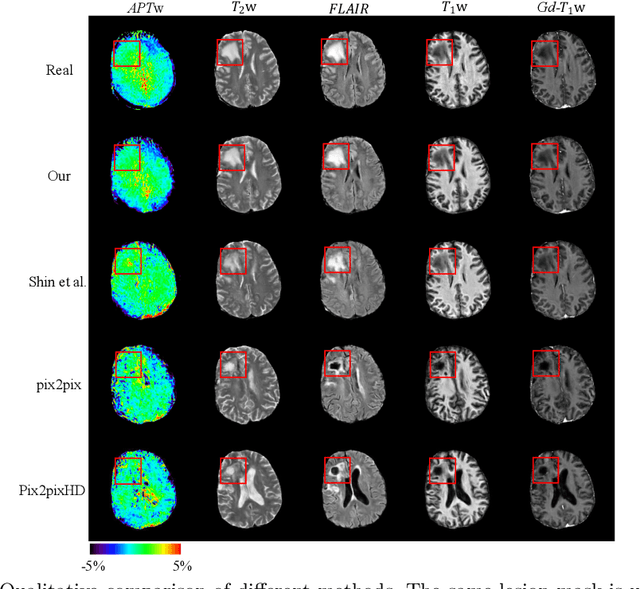
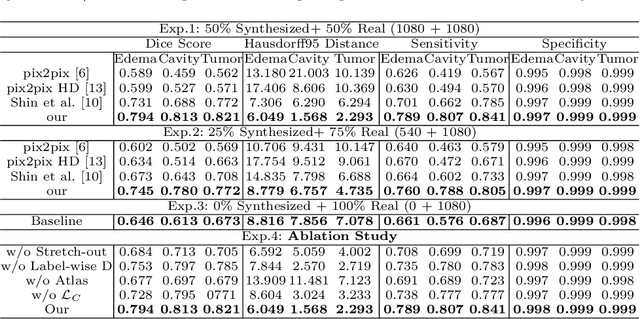
Data-driven automatic approaches have demonstrated their great potential in resolving various clinical diagnostic dilemmas for patients with malignant gliomas in neuro-oncology with the help of conventional and advanced molecular MR images. However, the lack of sufficient annotated MRI data has vastly impeded the development of such automatic methods. Conventional data augmentation approaches, including flipping, scaling, rotation, and distortion are not capable of generating data with diverse image content. In this paper, we propose a generative adversarial network (GAN), which can simultaneously synthesize data from arbitrary manipulated lesion information on multiple anatomic and molecular MRI sequences, including T1-weighted (T1w), gadolinium enhanced T1w (Gd-T1w), T2-weighted (T2w), fluid-attenuated inversion recovery (FLAIR), and amide proton transfer-weighted (APTw). The proposed framework consists of a stretch-out up-sampling module, a brain atlas encoder, a segmentation consistency module, and multi-scale labelwise discriminators. Extensive experiments on real clinical data demonstrate that the proposed model can perform significantly better than the state-of-the-art synthesis methods.