 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Establishing an Evaluation Metric to Quantify Climate Change Image Realism
Oct 22, 2019


With success on controlled tasks, generative models are being increasingly applied to humanitarian applications [1,2]. In this paper, we focus on the evaluation of a conditional generative model that illustrates the consequences of climate change-induced flooding to encourage public interest and awareness on the issue. Because metrics for comparing the realism of different modes in a conditional generative model do not exist, we propose several automated and human-based methods for evaluation. To do this, we adapt several existing metrics, and assess the automated metrics against gold standard human evaluation. We find that using Fr\'echet Inception Distance (FID) with embeddings from an intermediary Inception-V3 layer that precedes the auxiliary classifier produces results most correlated with human realism. While insufficient alone to establish a human-correlated automatic evaluation metric, we believe this work begins to bridge the gap between human and automated generative evaluation procedures.
SPEED: Secure, PrivatE, and Efficient Deep learning
Jun 16, 2020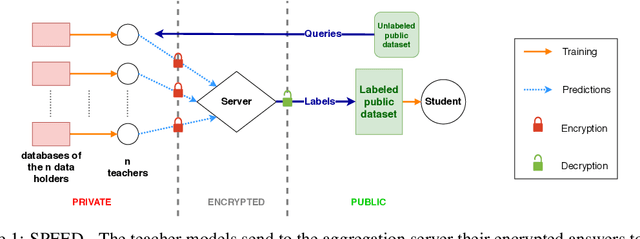
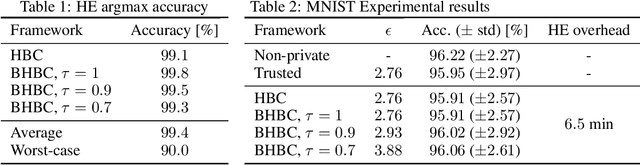
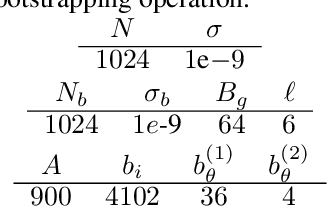
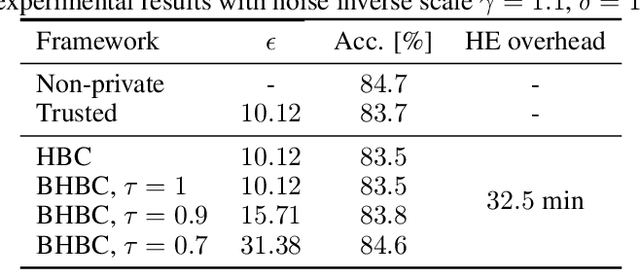
This paper addresses the issue of collaborative deep learning with privacy constraints. Building upon differentially private decentralized semi-supervised learning, we introduce homomorphically encrypted operations to extend the set of threats considered so far. While previous methods relied on the existence of an hypothetical 'trusted' third party, we designed specific aggregation operations in the encrypted domain that allow us to circumvent this assumption. This makes our method practical to real-life scenario where data holders do not trust any third party to process their datasets. Crucially the computational burden of the approach is maintained reasonable, making it suitable to deep learning applications. In order to illustrate the performances of our method, we carried out numerical experiments using image datasets in a classification context.
Self-Supervised GAN Compression
Jul 12, 2020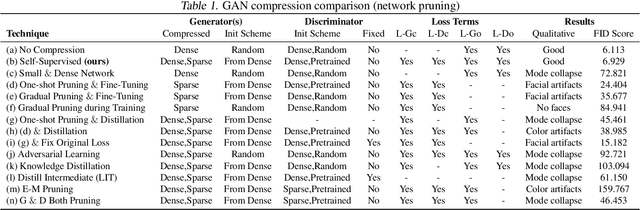

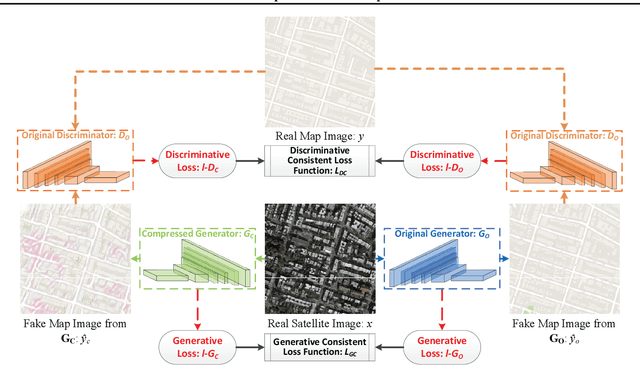
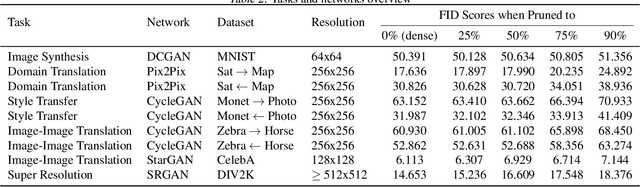
Deep learning's success has led to larger and larger models to handle more and more complex tasks; trained models can contain millions of parameters. These large models are compute- and memory-intensive, which makes it a challenge to deploy them with minimized latency, throughput, and storage requirements. Some model compression methods have been successfully applied to image classification and detection or language models, but there has been very little work compressing generative adversarial networks (GANs) performing complex tasks. In this paper, we show that a standard model compression technique, weight pruning, cannot be applied to GANs using existing methods. We then develop a self-supervised compression technique which uses the trained discriminator to supervise the training of a compressed generator. We show that this framework has a compelling performance to high degrees of sparsity, can be easily applied to new tasks and models, and enables meaningful comparisons between different pruning granularities.
Anomaly Detection with Tensor Networks
Jun 16, 2020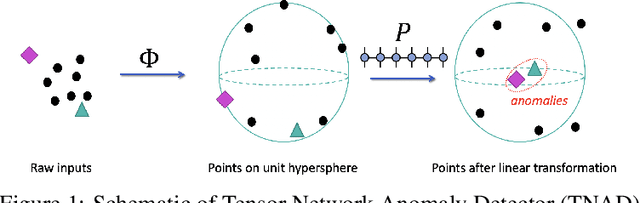
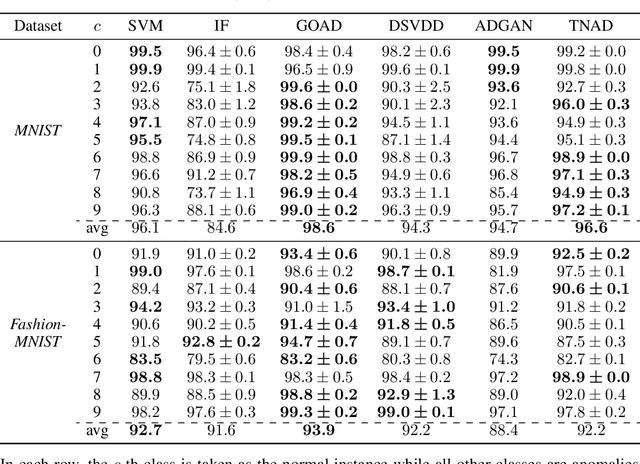
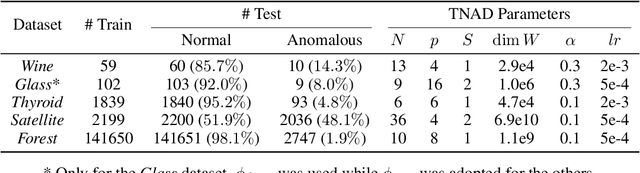
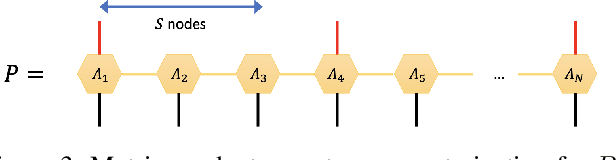
Originating from condensed matter physics, tensor networks are compact representations of high-dimensional tensors. In this paper, the prowess of tensor networks is demonstrated on the particular task of one-class anomaly detection. We exploit the memory and computational efficiency of tensor networks to learn a linear transformation over a space with dimension exponential in the number of original features. The linearity of our model enables us to ensure a tight fit around training instances by penalizing the model's global tendency to a predict normality via its Frobenius norm---a task that is infeasible for most deep learning models. Our method outperforms deep and classical algorithms on tabular datasets and produces competitive results on image datasets, despite not exploiting the locality of images.
RSL-Net: Localising in Satellite Images From a Radar on the Ground
Feb 06, 2020
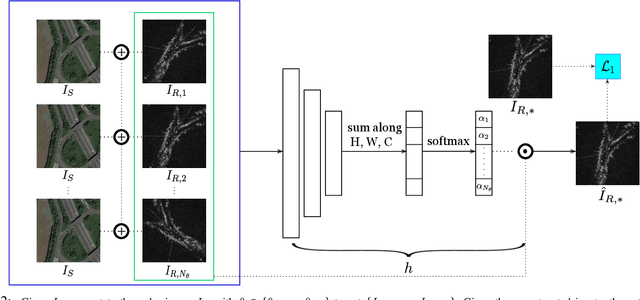

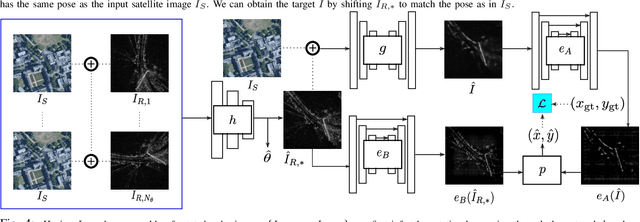
This paper is about localising a vehicle in an overhead image using FMCW radar mounted on a ground vehicle. FMCW radar offers extraordinary promise and efficacy for vehicle localisation. It is impervious to all weather types and lighting conditions. However the complexity of the interactions between millimetre radar wave and the physical environment makes it a challenging domain. Infrastructure-free large-scale radar-based localisation is in its infancy. Typically here a map is built and suitable techniques, compatible with the nature of sensor, are brought to bear. In this work we eschew the need for a radar-based map; instead we simply use an overhead image -- a resource readily available everywhere. This paper introduces a method that not only naturally deals with the complexity of the signal type but does so in the context of cross modal processing.
Including Images into Message Veracity Assessment in Social Media
Jul 20, 2020
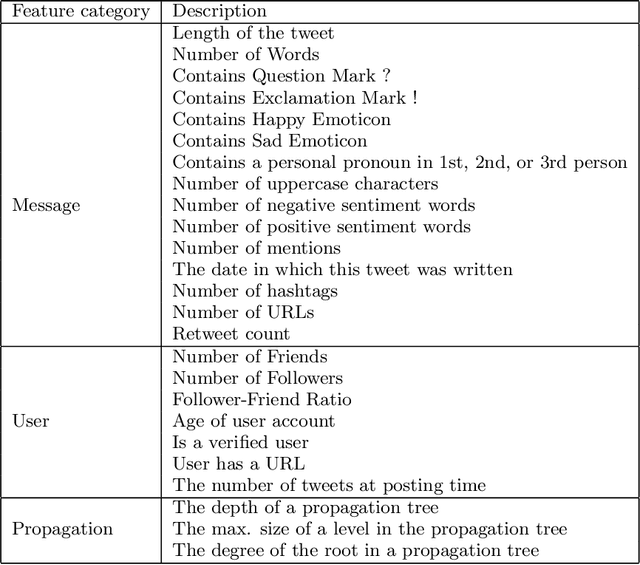
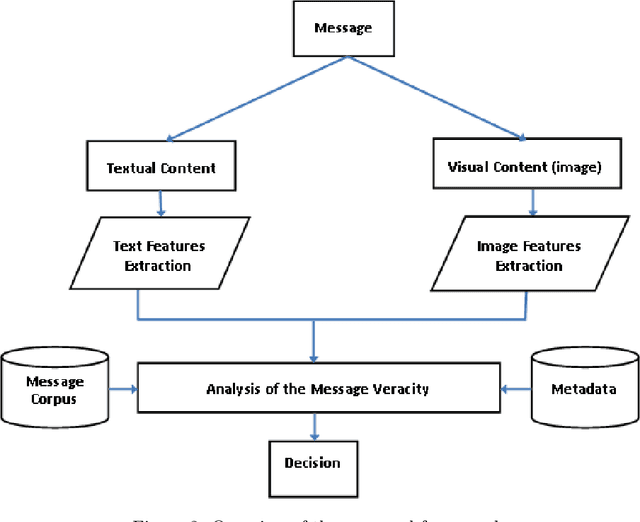

The extensive use of social media in the diffusion of information has also laid a fertile ground for the spread of rumors, which could significantly affect the credibility of social media. An ever-increasing number of users post news including, in addition to text, multimedia data such as images and videos. Yet, such multimedia content is easily editable due to the broad availability of simple and effective image and video processing tools. The problem of assessing the veracity of social network posts has attracted a lot of attention from researchers in recent years. However, almost all previous works have focused on analyzing textual contents to determine veracity, while visual contents, and more particularly images, remains ignored or little exploited in the literature. In this position paper, we propose a framework that explores two novel ways to assess the veracity of messages published on social networks by analyzing the credibility of both their textual and visual contents.
High-dimensional Convolutional Networks for Geometric Pattern Recognition
May 17, 2020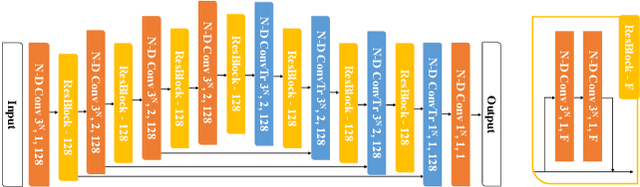

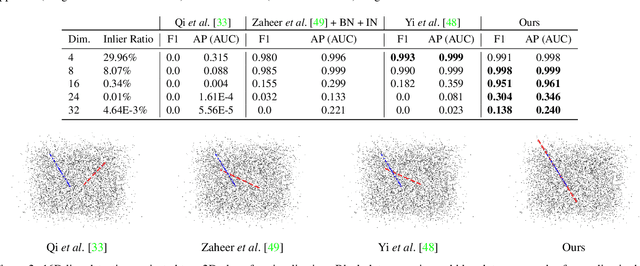
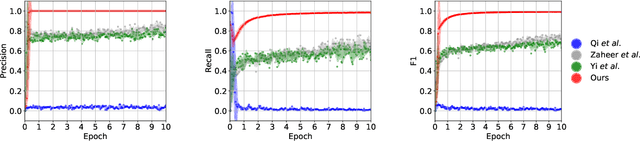
Many problems in science and engineering can be formulated in terms of geometric patterns in high-dimensional spaces. We present high-dimensional convolutional networks (ConvNets) for pattern recognition problems that arise in the context of geometric registration. We first study the effectiveness of convolutional networks in detecting linear subspaces in high-dimensional spaces with up to 32 dimensions: much higher dimensionality than prior applications of ConvNets. We then apply high-dimensional ConvNets to 3D registration under rigid motions and image correspondence estimation. Experiments indicate that our high-dimensional ConvNets outperform prior approaches that relied on deep networks based on global pooling operators.
Grounding Language in Play
May 15, 2020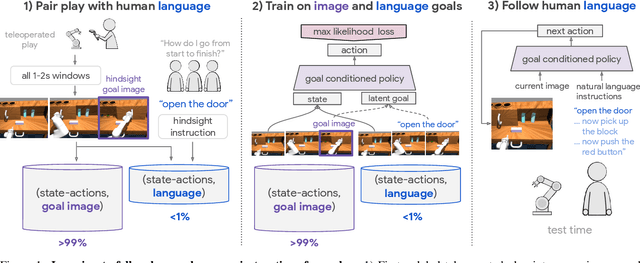
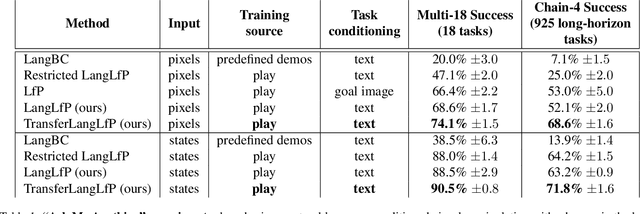
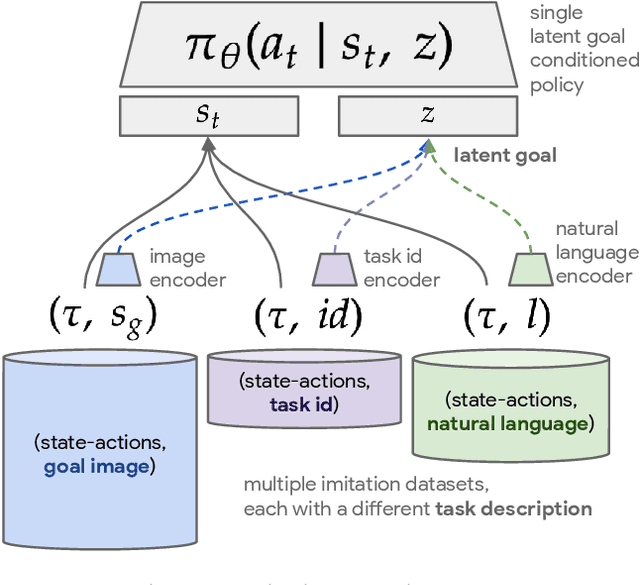

Natural language is perhaps the most versatile and intuitive way for humans to communicate tasks to a robot. Prior work on Learning from Play (LfP) [Lynch et al, 2019] provides a simple approach for learning a wide variety of robotic behaviors from general sensors. However, each task must be specified with a goal image---something that is not practical in open-world environments. In this work we present a simple and scalable way to condition policies on human language instead. We extend LfP by pairing short robot experiences from play with relevant human language after-the-fact. To make this efficient, we introduce multicontext imitation, which allows us to train a single agent to follow image or language goals, then use just language conditioning at test time. This reduces the cost of language pairing to less than 1% of collected robot experience, with the majority of control still learned via self-supervised imitation. At test time, a single agent trained in this manner can perform many different robotic manipulation skills in a row in a 3D environment, directly from images, and specified only with natural language (e.g. "open the drawer...now pick up the block...now press the green button..."). Finally, we introduce a simple technique that transfers knowledge from large unlabeled text corpora to robotic learning. We find that transfer significantly improves downstream robotic manipulation. It also allows our agent to follow thousands of novel instructions at test time in zero shot, in 16 different languages. See videos of our experiments at language-play.github.io
Instance-Based Counterfactual Explanations for Time Series Classification
Sep 28, 2020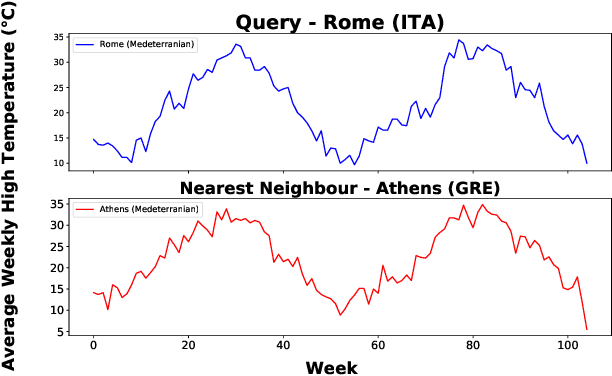

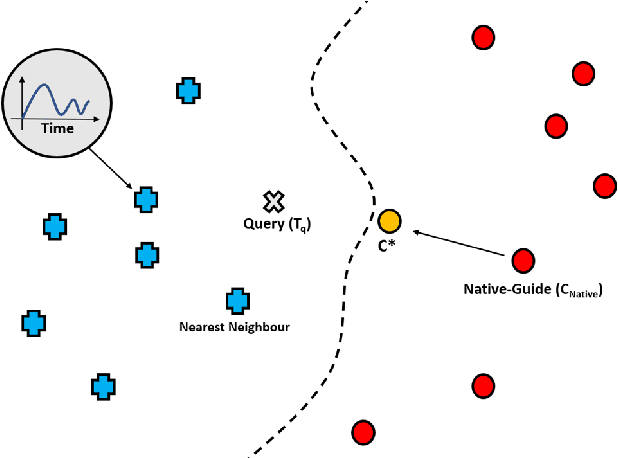
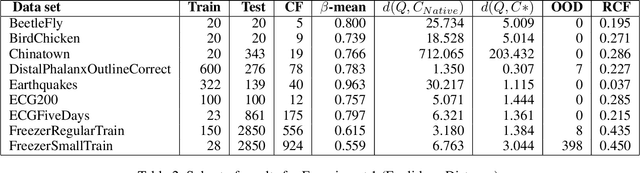
In recent years there has been a cascade of research in attempting to make AI systems more interpretable by providing explanations; so-called Explainable AI (XAI). Most of this research has dealt with the challenges that arise in explaining black-box deep learning systems in classification and regression tasks, with a focus on tabular and image data; for example, there is a rich seam of work on post-hoc counterfactual explanations for a variety of black-box classifiers (e.g., when a user is refused a loan, the counterfactual explanation tells the user about the conditions under which they would get the loan). However, less attention has been paid to the parallel interpretability challenges arising in AI systems dealing with time series data. This paper advances a novel technique, called Native-Guide, for the generation of proximal and plausible counterfactual explanations for instance-based time series classification tasks (e.g., where users are provided with alternative time series to explain how a classification might change). The Native-Guide method retrieves and uses native in-sample counterfactuals that already exist in the training data as "guides" for perturbation in time series counterfactual generation. This method can be coupled with both Euclidean and Dynamic Time Warping (DTW) distance measures. After illustrating the technique on a case study involving a climate classification task, we reported on a comprehensive series of experiments on both real-world and synthetic data sets from the UCR archive. These experiments provide computational evidence of the quality of the counterfactual explanations generated.
Using an ensemble color space model to tackle adversarial examples
Mar 10, 2020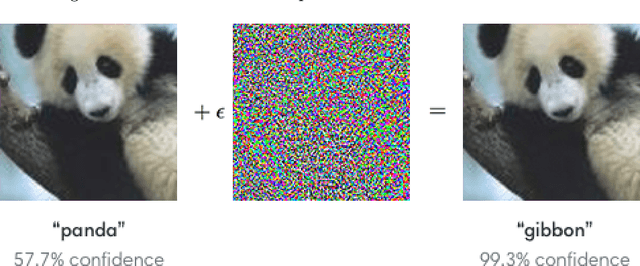
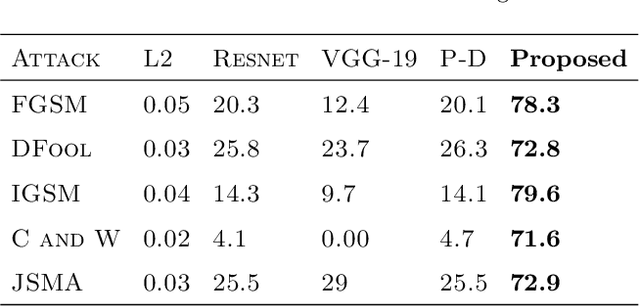
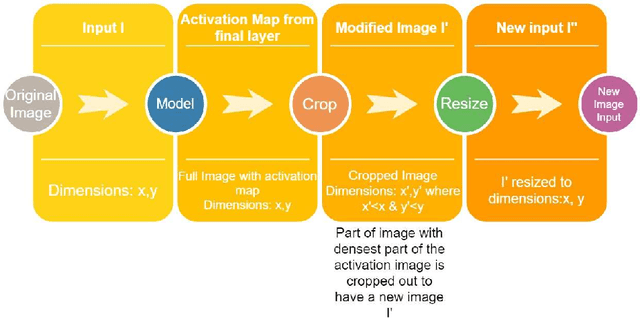
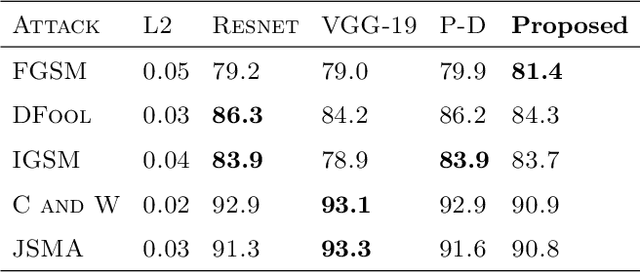
Minute pixel changes in an image drastically change the prediction that the deep learning model makes. One of the most significant problems that could arise due to this, for instance, is autonomous driving. Many methods have been proposed to combat this with varying amounts of success. We propose a 3 step method for defending such attacks. First, we denoise the image using statistical methods. Second, we show that adopting multiple color spaces in the same model can help us to fight these adversarial attacks further as each color space detects certain features explicit to itself. Finally, the feature maps generated are enlarged and sent back as an input to obtain even smaller features. We show that the proposed model does not need to be trained to defend an particular type of attack and is inherently more robust to black-box, white-box, and grey-box adversarial attack techniques. In particular, the model is 56.12 percent more robust than compared models in case of white box attacks when the models are not subject to adversarial example training.