 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bayesian Tensor Network with Polynomial Complexity for Probabilistic Machine Learning
Jan 07, 2020
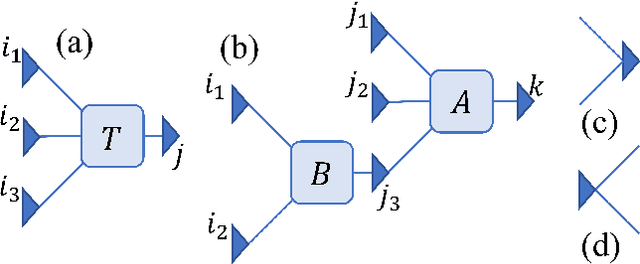
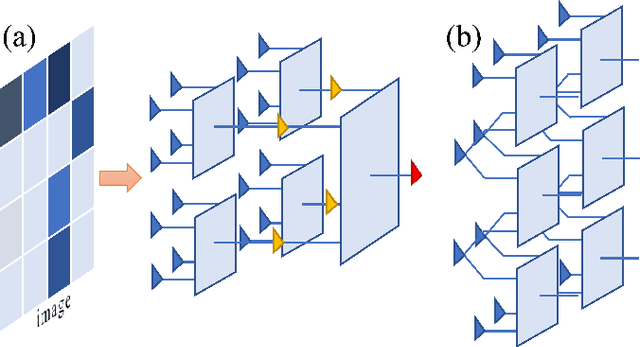
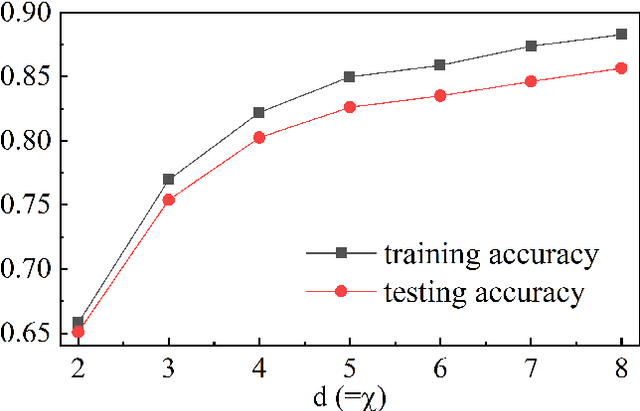
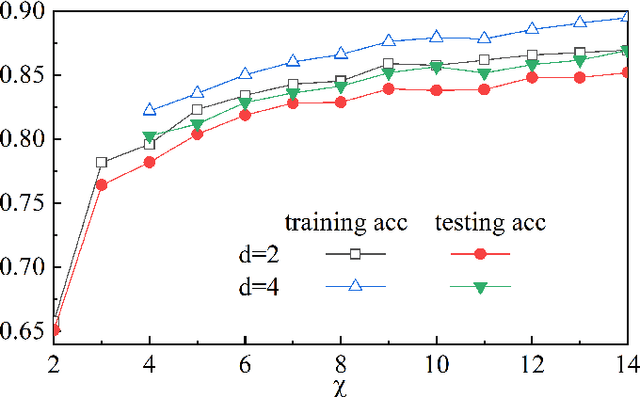
It is known that describing or calculating the conditional probabilities of multiple events is exponentially expensive. In this work, Bayesian tensor network (BTN) is proposed to efficiently capture the conditional probabilities of multiple sets of events with polynomial complexity. BTN is a directed acyclic graphical model that forms a subset of TN. To testify its validity for exponentially many events, BTN is implemented to the image recognition, where the classification is mapped to capturing the conditional probabilities in an exponentially large sample space. Competitive performance is achieved by the BTN with simple tree network structures. Analogous to the tensor network simulations of quantum systems, the validity of the simple-tree BTN implies an ``area law'' of fluctuations in image recognition problems.
Real-world Person Re-Identification via Degradation Invariance Learning
Apr 10, 2020


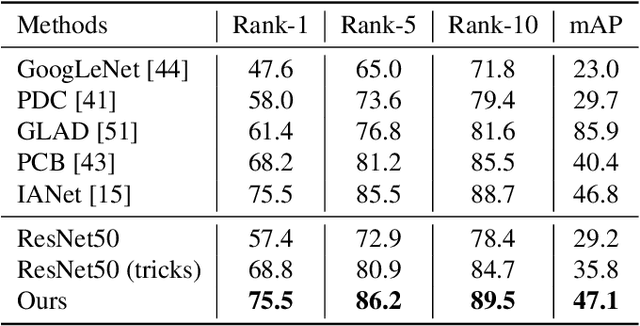
Person re-identification (Re-ID) in real-world scenarios usually suffers from various degradation factors, e.g., low-resolution, weak illumination, blurring and adverse weather. On the one hand, these degradations lead to severe discriminative information loss, which significantly obstructs identity representation learning; on the other hand, the feature mismatch problem caused by low-level visual variations greatly reduces retrieval performance. An intuitive solution to this problem is to utilize low-level image restoration methods to improve the image quality. However, existing restoration methods cannot directly serve to real-world Re-ID due to various limitations, e.g., the requirements of reference samples, domain gap between synthesis and reality, and incompatibility between low-level and high-level methods. In this paper, to solve the above problem, we propose a degradation invariance learning framework for real-world person Re-ID. By introducing a self-supervised disentangled representation learning strategy, our method is able to simultaneously extract identity-related robust features and remove real-world degradations without extra supervision. We use low-resolution images as the main demonstration, and experiments show that our approach is able to achieve state-of-the-art performance on several Re-ID benchmarks. In addition, our framework can be easily extended to other real-world degradation factors, such as weak illumination, with only a few modifications.
Assessing Automated Machine Learning service to detect COVID-19 from X-Ray and CT images: A Real-time Smartphone Application case study
Oct 03, 2020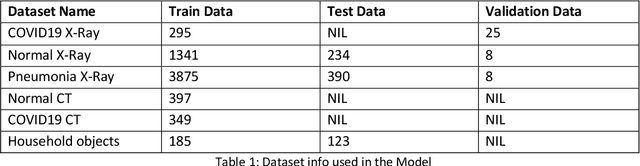
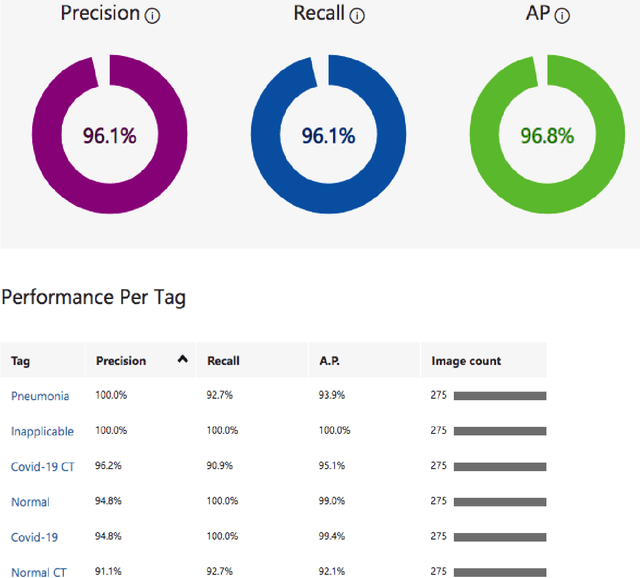
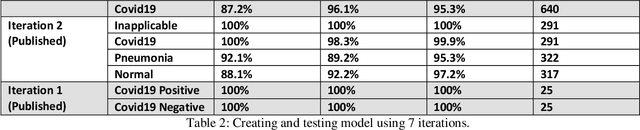
The recent outbreak of SARS COV-2 gave us a unique opportunity to study for a non interventional and sustainable AI solution. Lung disease remains a major healthcare challenge with high morbidity and mortality worldwide. The predominant lung disease was lung cancer. Until recently, the world has witnessed the global pandemic of COVID19, the Novel coronavirus outbreak. We have experienced how viral infection of lung and heart claimed thousands of lives worldwide. With the unprecedented advancement of Artificial Intelligence in recent years, Machine learning can be used to easily detect and classify medical imagery. It is much faster and most of the time more accurate than human radiologists. Once implemented, it is more cost-effective and time-saving. In our study, we evaluated the efficacy of Microsoft Cognitive Service to detect and classify COVID19 induced pneumonia from other Viral/Bacterial pneumonia based on X-Ray and CT images. We wanted to assess the implication and accuracy of the Automated ML-based Rapid Application Development (RAD) environment in the field of Medical Image diagnosis. This study will better equip us to respond with an ML-based diagnostic Decision Support System(DSS) for a Pandemic situation like COVID19. After optimization, the trained network achieved 96.8% Average Precision which was implemented as a Web Application for consumption. However, the same trained network did not perform the same like Web Application when ported to Smartphone for Real-time inference. Which was our main interest of study. The authors believe, there is scope for further study on this issue. One of the main goal of this study was to develop and evaluate the performance of AI-powered Smartphone-based Real-time Application. Facilitating primary diagnostic services in less equipped and understaffed rural healthcare centers of the world with unreliable internet service.
* 21 Pages, 6 Tables
A Deep Learning based Fast Signed Distance Map Generation
May 26, 2020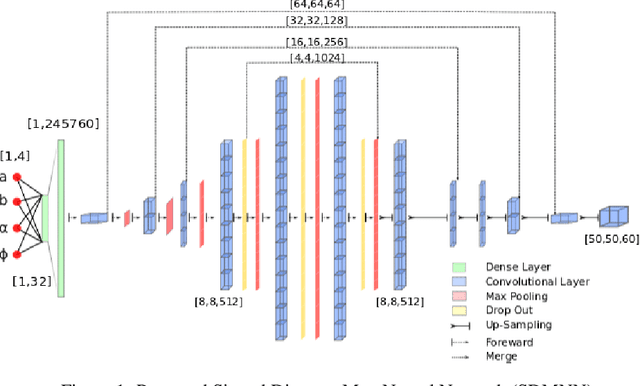

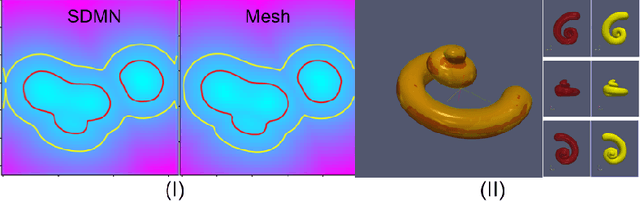

Signed distance map (SDM) is a common representation of surfaces in medical image analysis and machine learning. The computational complexity of SDM for 3D parametric shapes is often a bottleneck in many applications, thus limiting their interest. In this paper, we propose a learning based SDM generation neural network which is demonstrated on a tridimensional cochlea shape model parameterized by 4 shape parameters. The proposed SDM Neural Network generates a cochlea signed distance map depending on four input parameters and we show that the deep learning approach leads to a 60 fold improvement in the time of computation compared to more classical SDM generation methods. Therefore, the proposed approach achieves a good trade-off between accuracy and efficiency.
The Evolutionary Process of Image Transition in Conjunction with Box and Strip Mutation
Aug 05, 2016



Evolutionary algorithms have been used in many ways to generate digital art. We study how evolutionary processes are used for evolutionary art and present a new approach to the transition of images. Our main idea is to define evolutionary processes for digital image transition, combining different variants of mutation and evolutionary mechanisms. We introduce box and strip mutation operators which are specifically designed for image transition. Our experimental results show that the process of an evolutionary algorithm in combination with these mutation operators can be used as a valuable way to produce unique generative art.
Adversarial Attacks and Defense on Texts: A Survey
Jun 14, 2020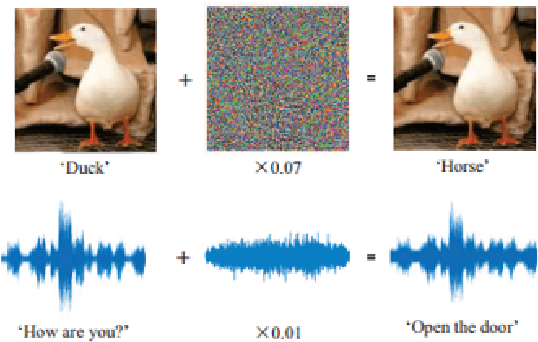
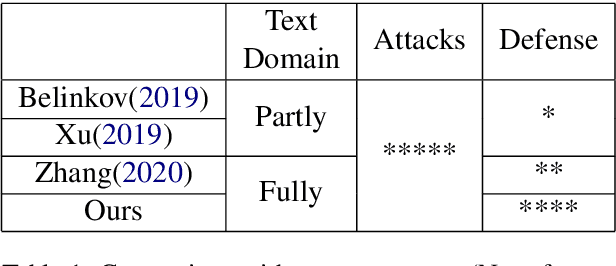
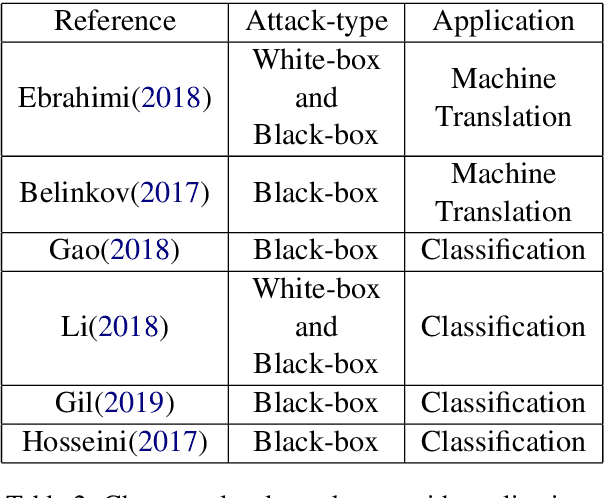
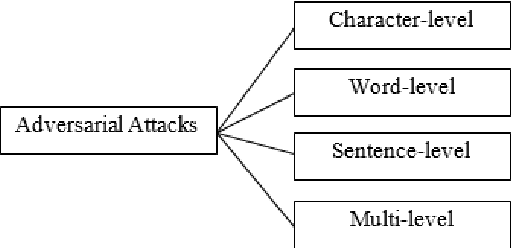
Deep learning models have been used widely for various purposes in recent years in object recognition, self-driving cars, face recognition, speech recognition, sentiment analysis, and many others. However, in recent years it has been shown that these models possess weakness to noises which force the model to misclassify. This issue has been studied profoundly in the image and audio domain. Very little has been studied on this issue concerning textual data. Even less survey on this topic has been performed to understand different types of attacks and defense techniques. In this manuscript, we accumulated and analyzed different attacking techniques and various defense models to provide a more comprehensive idea. Later we point out some of the interesting findings of all papers and challenges that need to be overcome to move forward in this field.
Journey Towards Tiny Perceptual Super-Resolution
Jul 08, 2020

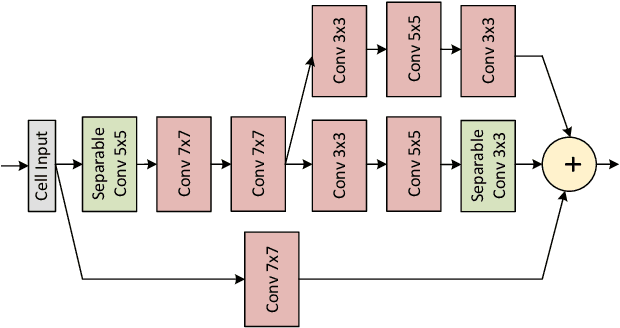
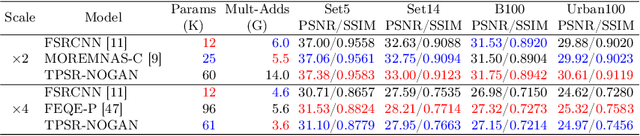
Recent works in single-image perceptual super-resolution (SR) have demonstrated unprecedented performance in generating realistic textures by means of deep convolutional networks. However, these convolutional models are excessively large and expensive, hindering their effective deployment to end devices. In this work, we propose a neural architecture search (NAS) approach that integrates NAS and generative adversarial networks (GANs) with recent advances in perceptual SR and pushes the efficiency of small perceptual SR models to facilitate on-device execution. Specifically, we search over the architectures of both the generator and the discriminator sequentially, highlighting the unique challenges and key observations of searching for an SR-optimized discriminator and comparing them with existing discriminator architectures in the literature. Our tiny perceptual SR (TPSR) models outperform SRGAN and EnhanceNet on both full-reference perceptual metric (LPIPS) and distortion metric (PSNR) while being up to 26.4$\times$ more memory efficient and 33.6$\times$ more compute efficient respectively.
Deep Collective Learning: Learning Optimal Inputs and Weights Jointly in Deep Neural Networks
Sep 17, 2020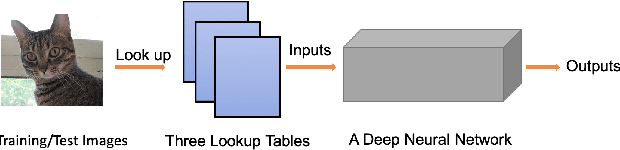
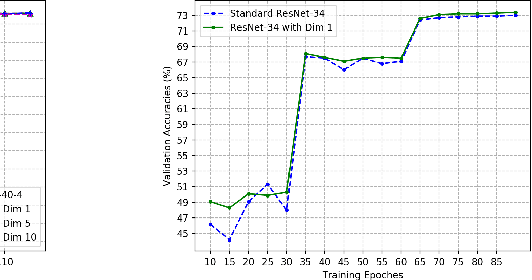
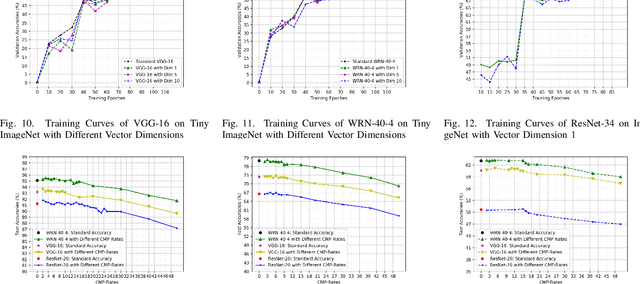

It is well observed that in deep learning and computer vision literature, visual data are always represented in a manually designed coding scheme (eg., RGB images are represented as integers ranging from 0 to 255 for each channel) when they are input to an end-to-end deep neural network (DNN) for any learning task. We boldly question whether the manually designed inputs are good for DNN training for different tasks and study whether the input to a DNN can be optimally learned end-to-end together with learning the weights of the DNN. In this paper, we propose the paradigm of {\em deep collective learning} which aims to learn the weights of DNNs and the inputs to DNNs simultaneously for given tasks. We note that collective learning has been implicitly but widely used in natural language processing while it has almost never been studied in computer vision. Consequently, we propose the lookup vision networks (Lookup-VNets) as a solution to deep collective learning in computer vision. This is achieved by associating each color in each channel with a vector in lookup tables. As learning inputs in computer vision has almost never been studied in the existing literature, we explore several aspects of this question through varieties of experiments on image classification tasks. Experimental results on four benchmark datasets, i.e., CIFAR-10, CIFAR-100, Tiny ImageNet, and ImageNet (ILSVRC2012) have shown several surprising characteristics of Lookup-VNets and have demonstrated the advantages and promise of Lookup-VNets and deep collective learning.
Boundary Guidance Hierarchical Network for Real-Time Tongue Segmentation
Mar 14, 2020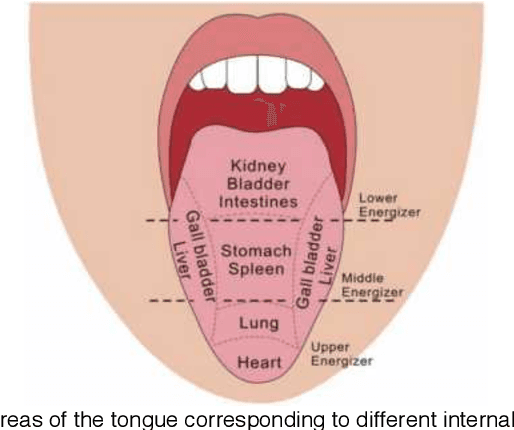
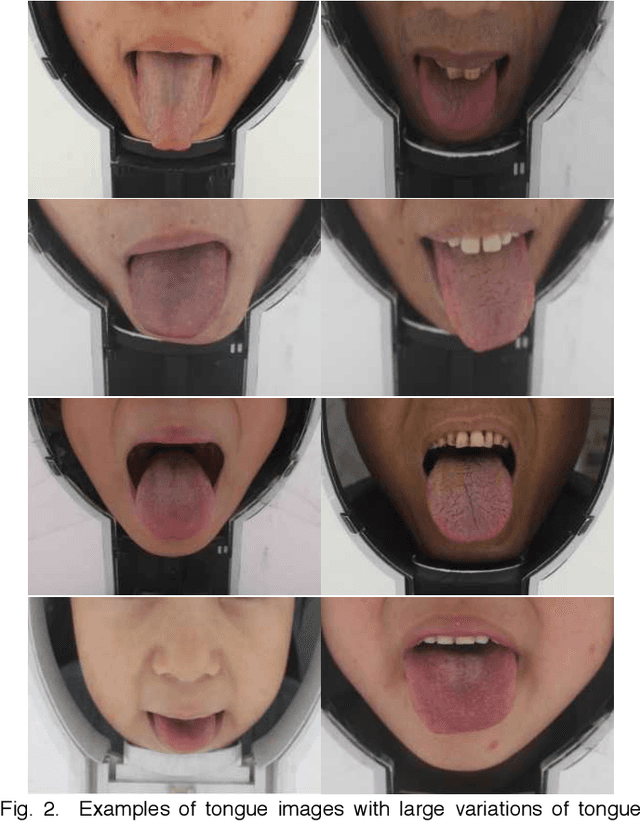
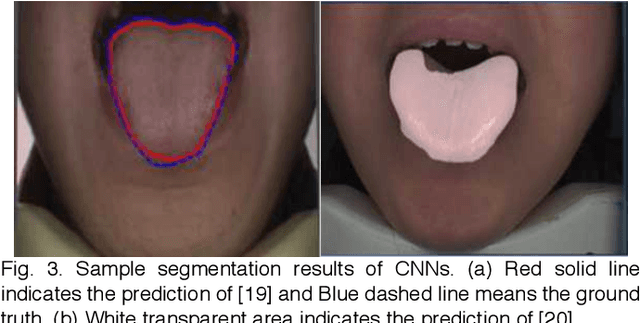
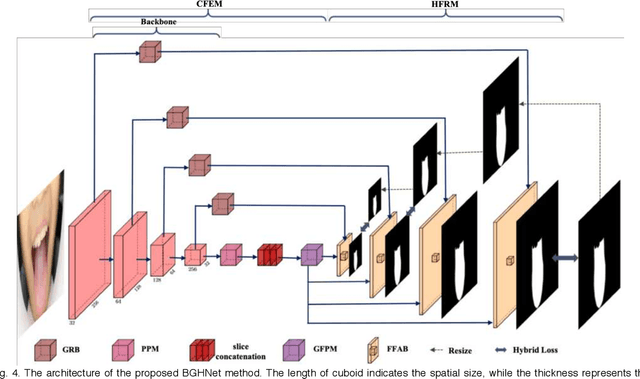
Automated tongue image segmentation in tongue images is a challenging task for two reasons: 1) there are many pathological details on the tongue surface, which affect the extraction of the boundary; 2) the shapes of the tongues captured from various persons (with different diseases) are quite different. To deal with the challenge, a novel end-to-end Boundary Guidance Hierarchical Network (BGHNet) with a new hybrid loss is proposed in this paper. In the new approach, firstly Context Feature Encoder Module (CFEM) is built upon the bottomup pathway to confront with the shrinkage of the receptive field. Secondly, a novel hierarchical recurrent feature fusion module (HRFFM) is adopt to progressively and hierarchically refine object maps to recover image details by integrating local context information. Finally, the proposed hybrid loss in a four hierarchy-pixel, patch, map and boundary guides the network to effectively segment the tongue regions and accurate tongue boundaries. BGHNet is applied to a set of tongue images. The experimental results suggest that the proposed approach can achieve the latest tongue segmentation performance. And in the meantime, the lightweight network contains only 15.45M parameters and performs only 11.22GFLOPS.
Deep Geometric Texture Synthesis
Jun 30, 2020

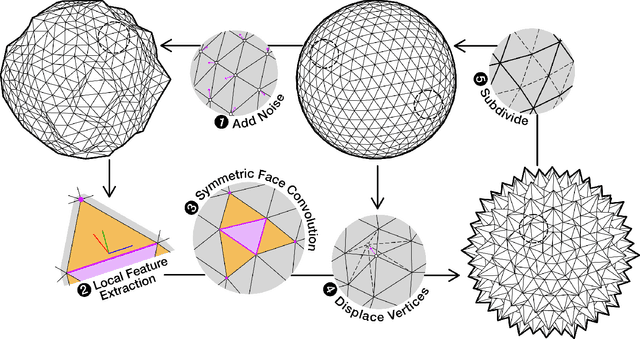
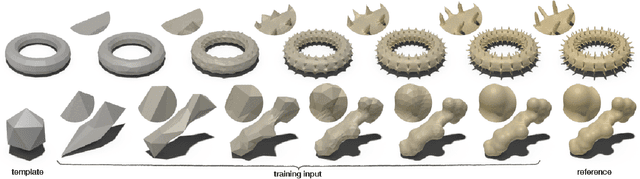
Recently, deep generative adversarial networks for image generation have advanced rapidly; yet, only a small amount of research has focused on generative models for irregular structures, particularly meshes. Nonetheless, mesh generation and synthesis remains a fundamental topic in computer graphics. In this work, we propose a novel framework for synthesizing geometric textures. It learns geometric texture statistics from local neighborhoods (i.e., local triangular patches) of a single reference 3D model. It learns deep features on the faces of the input triangulation, which is used to subdivide and generate offsets across multiple scales, without parameterization of the reference or target mesh. Our network displaces mesh vertices in any direction (i.e., in the normal and tangential direction), enabling synthesis of geometric textures, which cannot be expressed by a simple 2D displacement map. Learning and synthesizing on local geometric patches enables a genus-oblivious framework, facilitating texture transfer between shapes of different genus.