 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Conjugate-gradient-based Adam for stochastic optimization and its application to deep learning
Mar 03, 2020
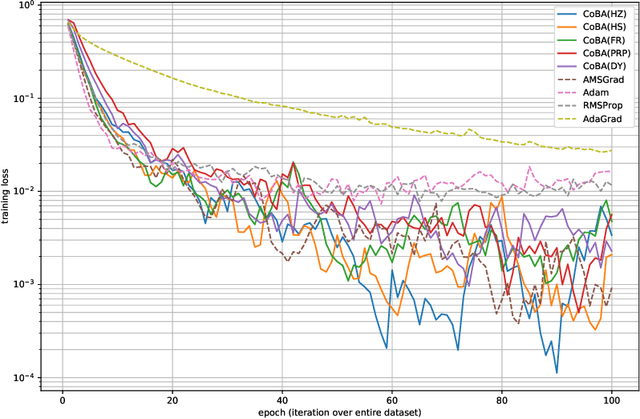
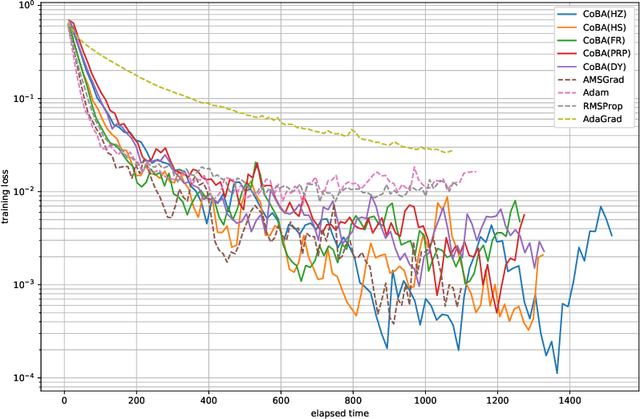
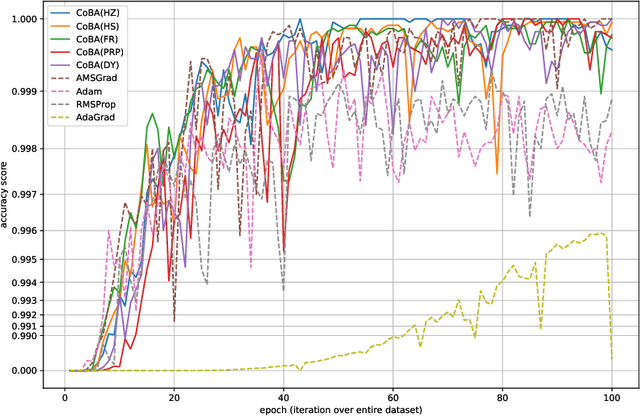
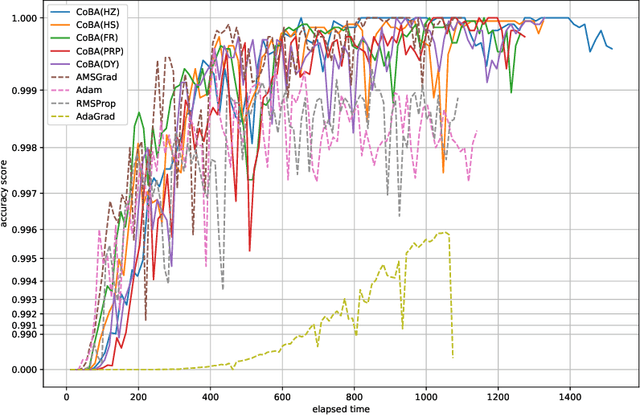
This paper proposes a conjugate-gradient-based Adam algorithm blending Adam with nonlinear conjugate gradient methods and shows its convergence analysis. Numerical experiments on text classification and image classification show that the proposed algorithm can train deep neural network models in fewer epochs than the existing adaptive stochastic optimization algorithms can.
Joint Layout Analysis, Character Detection and Recognition for Historical Document Digitization
Jul 14, 2020
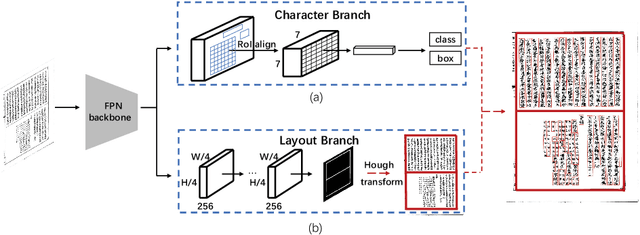
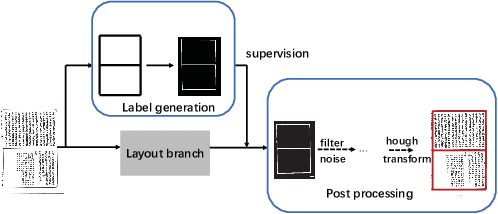
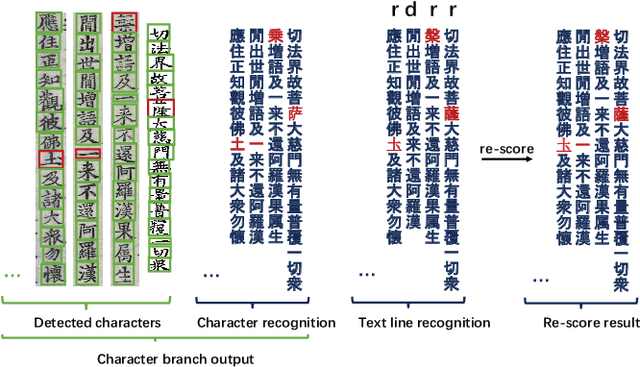
In this paper, we propose an end-to-end trainable framework for restoring historical documents content that follows the correct reading order. In this framework, two branches named character branch and layout branch are added behind the feature extraction network. The character branch localizes individual characters in a document image and recognizes them simultaneously. Then we adopt a post-processing method to group them into text lines. The layout branch based on fully convolutional network outputs a binary mask. We then use Hough transform for line detection on the binary mask and combine character results with the layout information to restore document content. These two branches can be trained in parallel and are easy to train. Furthermore, we propose a re-score mechanism to minimize recognition error. Experiment results on the extended Chinese historical document MTHv2 dataset demonstrate the effectiveness of the proposed framework.
A Total Variation Denoising Method Based on Median Filter and Phase Consistency
Jan 01, 2020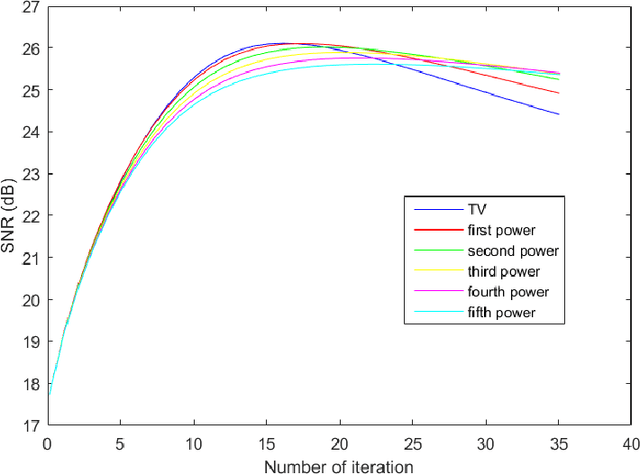

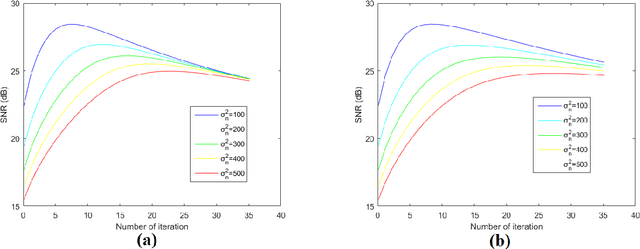

The total variation method is widely used in image noise suppression. However, this method is easy to cause the loss of image details, and it is also sensitive to parameters such as iteration time. In this work, the total variation method has been modified using a diffusion rate adjuster based on the phase congruency and a fusion filter of median filter and phase consistency boundary, which is called the MPC-TV method. Experimental results indicate that MPC-TV method is effective in noise suppression, especially for the removing of speckle noise, and it can also improve the robustness of iteration time of TV method on noise with different variance.
Causality Learning: A New Perspective for Interpretable Machine Learning
Jun 27, 2020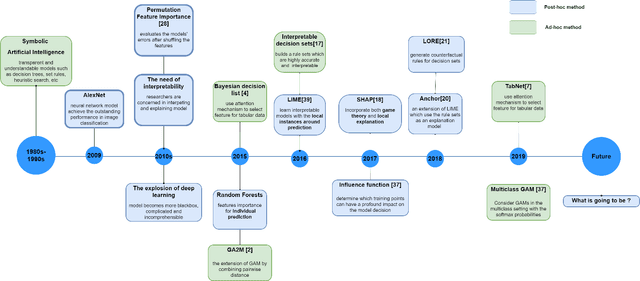
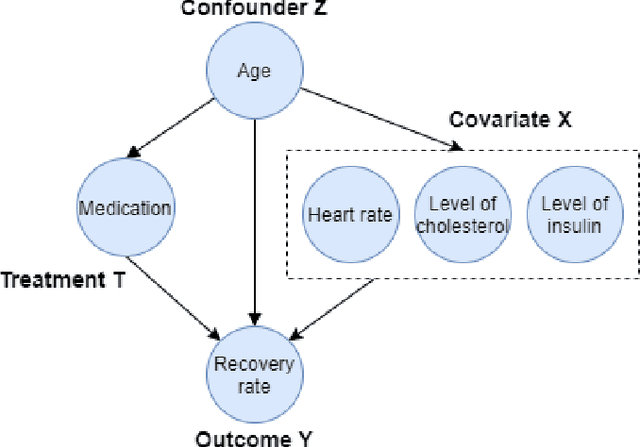
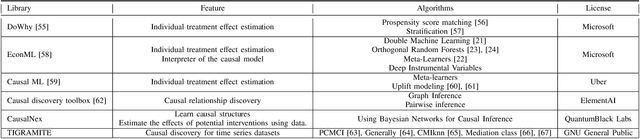
Recent years have witnessed the rapid growth of machine learning in a wide range of fields such as image recognition, text classification, credit scoring prediction, recommendation system, etc. In spite of their great performance in different sectors, researchers still concern about the mechanism under any machine learning (ML) techniques that are inherently black-box and becoming more complex to achieve higher accuracy. Therefore, interpreting machine learning model is currently a mainstream topic in the research community. However, the traditional interpretable machine learning focuses on the association instead of the causality. This paper provides an overview of causal analysis with the fundamental background and key concepts, and then summarizes most recent causal approaches for interpretable machine learning. The evaluation techniques for assessing method quality, and open problems in causal interpretability are also discussed in this paper.
Coronary Artery Segmentation from Intravascular Optical Coherence Tomography Using Deep Capsules
Mar 13, 2020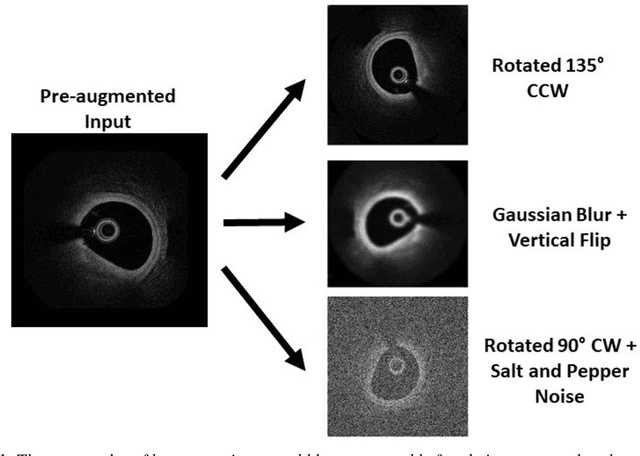

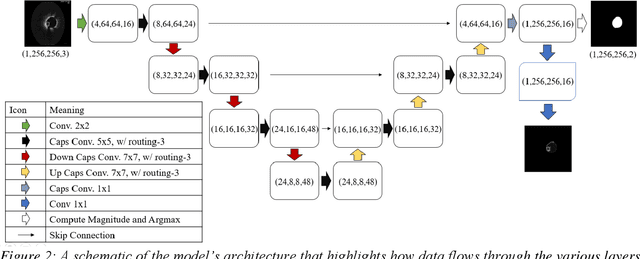
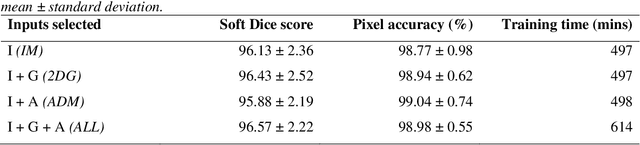
The segmentation and analysis of coronary arteries from intravascular optical coherence tomography (IVOCT) is an important aspect of diagnosing and managing coronary artery disease. However, automated, robust IVOCT image analysis tools are lacking. Current image processing methods are hindered by the time needed to generate these expert-labelled datasets and also the potential for bias during the analysis. Here we present a new deep learning method based on capsules to automatically produce lumen segmentations, built using a large IVOCT dataset of 12,011 images with ground-truth segmentations. This dataset contains images with both blood and light artefacts (22.8%), as well as noise from metallic (23.1%) and bioresorbable stents (2.5%). We trained our model on a dataset containing 9,608 images. We rigorously investigate design variations with respect to upsampling regimes and input selection and validate our deep learning model using 2,403 images. We show that our fully trained and optimized model achieves a mean Soft Dice Score of 97.11% (median of 98.2%), segments 200 IVOCT images in an acceptable timeframe of 12 seconds and outperforms current algorithms.
Multi-Scale Networks for 3D Human Pose Estimation with Inference Stage Optimization
Oct 16, 2020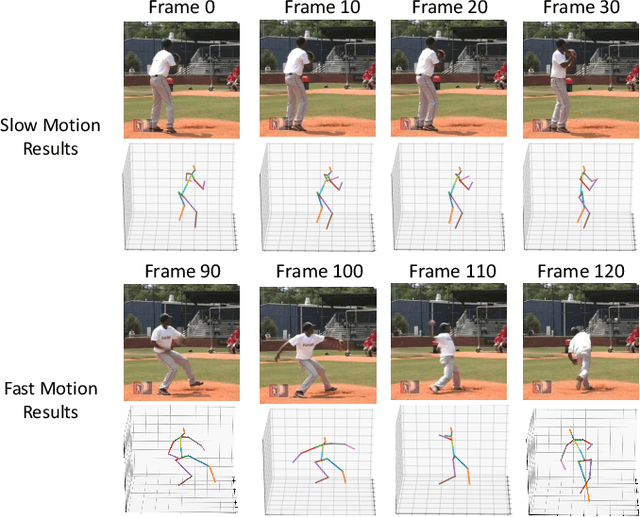
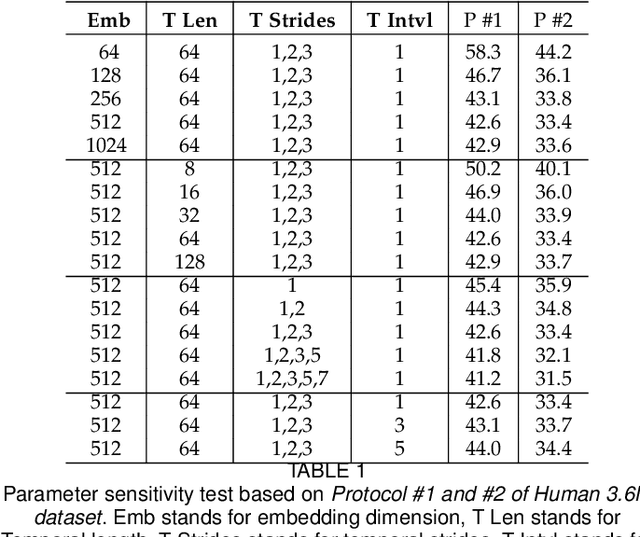
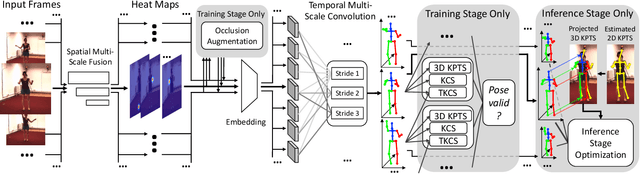
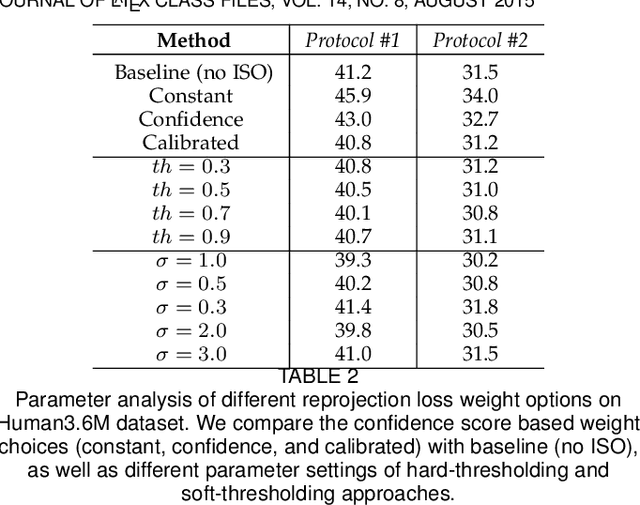
Estimating 3D human poses from a monocular video is still a challenging task. Many existing methods' performance drops when the target person is occluded by other objects, or the motion is too fast/slow relative to the scale and speed of the training data. Moreover, many of these methods are not designed or trained under severe occlusion explicitly, making their performance on handling occlusion compromised. Addressing these problems, we introduce a spatio-temporal network for robust 3D human pose estimation. As humans in videos may appear in different scales and have various motion speeds, we apply multi-scale spatial features for 2D joints or keypoints prediction in each individual frame, and multi-stride temporal convolutional networks (TCNs) to estimate 3D joints or keypoints. Furthermore, we design a spatio-temporal discriminator based on body structures as well as limb motions to assess whether the predicted pose forms a valid pose and a valid movement. During training, we explicitly mask out some keypoints to simulate various occlusion cases, from minor to severe occlusion, so that our network can learn better and becomes robust to various degrees of occlusion. As there are limited 3D ground-truth data, we further utilize 2D video data to inject a semi-supervised learning capability to our network. Moreover, we observe that there is a discrepancy between 3D pose prediction and 2D pose estimation due to different pose variations between video and image training datasets. We, therefore propose a confidence-based inference stage optimization to adaptively enforce 3D pose projection to match 2D pose estimation to further improve final pose prediction accuracy. Experiments on public datasets validate the effectiveness of our method, and our ablation studies show the strengths of our network's individual submodules.
Privacy Analysis of Deep Learning in the Wild: Membership Inference Attacks against Transfer Learning
Sep 10, 2020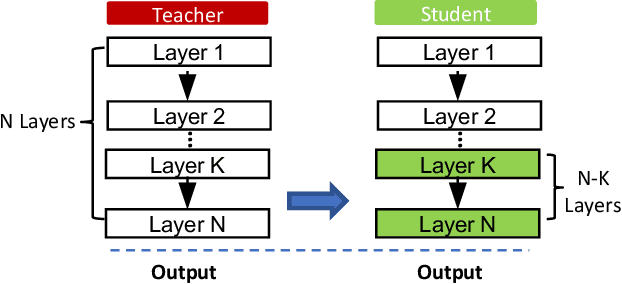

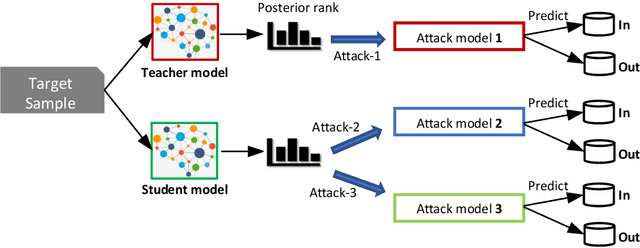

While being deployed in many critical applications as core components, machine learning (ML) models are vulnerable to various security and privacy attacks. One major privacy attack in this domain is membership inference, where an adversary aims to determine whether a target data sample is part of the training set of a target ML model. So far, most of the current membership inference attacks are evaluated against ML models trained from scratch. However, real-world ML models are typically trained following the transfer learning paradigm, where a model owner takes a pretrained model learned from a different dataset, namely teacher model, and trains her own student model by fine-tuning the teacher model with her own data. In this paper, we perform the first systematic evaluation of membership inference attacks against transfer learning models. We adopt the strategy of shadow model training to derive the data for training our membership inference classifier. Extensive experiments on four real-world image datasets show that membership inference can achieve effective performance. For instance, on the CIFAR100 classifier transferred from ResNet20 (pretrained with Caltech101), our membership inference achieves $95\%$ attack AUC. Moreover, we show that membership inference is still effective when the architecture of target model is unknown. Our results shed light on the severity of membership risks stemming from machine learning models in practice.
What Matters in Unsupervised Optical Flow
Jun 08, 2020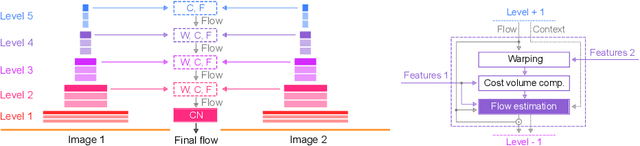
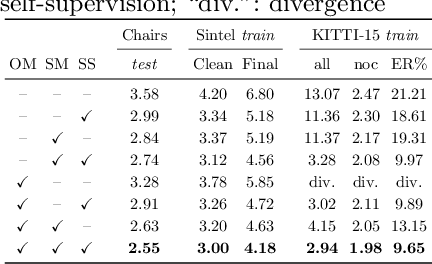

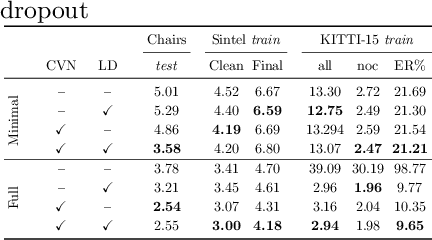
We systematically compare and analyze a set of key components in unsupervised optical flow to identify which photometric loss, occlusion handling, and smoothness regularization is most effective. Alongside this investigation we construct a number of novel improvements to unsupervised flow models, such as cost volume normalization, stopping the gradient at the occlusion mask, encouraging smoothness before upsampling the flow field, and continual self-supervision with image resizing. By combining the results of our investigation with our improved model components, we are able to present a new unsupervised flow technique that significantly outperforms the previous unsupervised state-of-the-art and performs on par with supervised FlowNet2 on the KITTI 2015 dataset, while also being significantly simpler than related approaches.
Learning Multi-Scale Deep Features for High-Resolution Satellite Image Classification
Nov 11, 2016

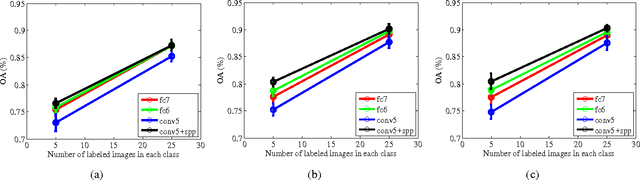
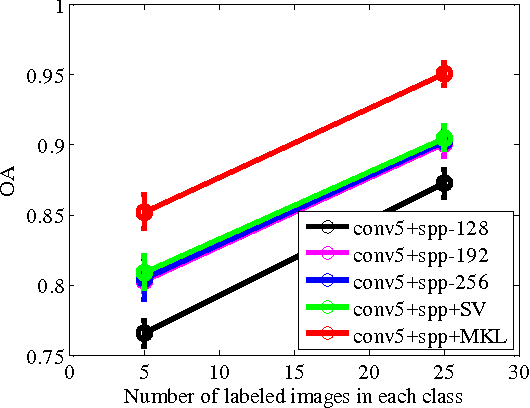
In this paper, we propose a multi-scale deep feature learning method for high-resolution satellite image classification. Specifically, we firstly warp the original satellite image into multiple different scales. The images in each scale are employed to train a deep convolutional neural network (DCNN). However, simultaneously training multiple DCNNs is time-consuming. To address this issue, we explore DCNN with spatial pyramid pooling (SPP-net). Since different SPP-nets have the same number of parameters, which share the identical initial values, and only fine-tuning the parameters in fully-connected layers ensures the effectiveness of each network, thereby greatly accelerating the training process. Then, the multi-scale satellite images are fed into their corresponding SPP-nets respectively to extract multi-scale deep features. Finally, a multiple kernel learning method is developed to automatically learn the optimal combination of such features. Experiments on two difficult datasets show that the proposed method achieves favorable performance compared to other state-of-the-art methods.
ARCH: Animatable Reconstruction of Clothed Humans
Apr 10, 2020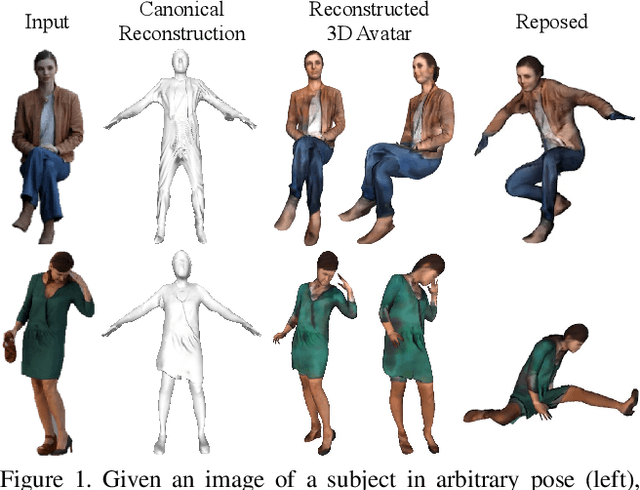
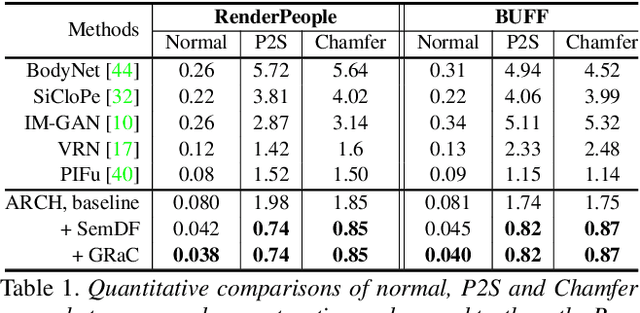
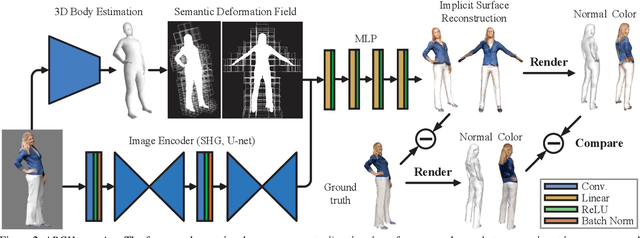
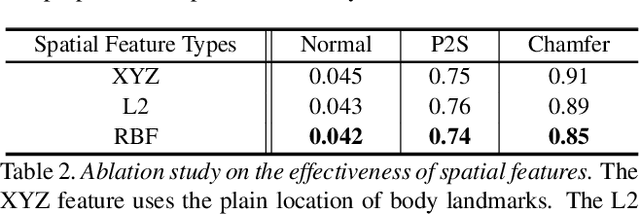
In this paper, we propose ARCH (Animatable Reconstruction of Clothed Humans), a novel end-to-end framework for accurate reconstruction of animation-ready 3D clothed humans from a monocular image. Existing approaches to digitize 3D humans struggle to handle pose variations and recover details. Also, they do not produce models that are animation ready. In contrast, ARCH is a learned pose-aware model that produces detailed 3D rigged full-body human avatars from a single unconstrained RGB image. A Semantic Space and a Semantic Deformation Field are created using a parametric 3D body estimator. They allow the transformation of 2D/3D clothed humans into a canonical space, reducing ambiguities in geometry caused by pose variations and occlusions in training data. Detailed surface geometry and appearance are learned using an implicit function representation with spatial local features. Furthermore, we propose additional per-pixel supervision on the 3D reconstruction using opacity-aware differentiable rendering. Our experiments indicate that ARCH increases the fidelity of the reconstructed humans. We obtain more than 50% lower reconstruction errors for standard metrics compared to state-of-the-art methods on public datasets. We also show numerous qualitative examples of animated, high-quality reconstructed avatars unseen in the literature so far.